
Creación de predicciones de series temporales mediante redes neuronales LSTM: Normalización del precio y tokenización del tiempo
Introducción
Quería explorar el uso de redes neuronales en el desarrollo de una estrategia comercial, así que profundicé en el tema viendo algunos videos de YouTube inicialmente. La mayoría eran relativamente confusos porque comenzaban en un nivel muy básico, como por ejemplo cómo programar en Python: usando cadenas, matrices, programación orientada a objetos y todos los demás conceptos básicos. Cuando el docente llegó al meollo del curso, Redes neuronales y aprendizaje automático, se dio cuenta de que simplemente estaría explicando cómo usar una biblioteca particular o un modelo previamente entrenado sin explicar realmente cómo funcionan. Después de mucho buscar, finalmente encontré videos de Andrej Karpati, que fueron bastante esclarecedores. En particular, su vídeo, Construyamos GPT: Desde cero, en código, explicado detalladamente (Let's build GPT: from scratch, in code, spelled out), me permitió ver cómo se pueden combinar conceptos matemáticos simples con código y dar vida a una inteligencia similar a la humana con solo unos pocos cientos de líneas de código. El video me abrió las puertas al mundo de las redes neuronales de una manera relativamente intuitiva y práctica, lo que me permitió experimentar su poder de primera mano. Acoplando algunos conocimientos básicos de su canal, con la ayuda de cientos de consultas ChatGPT para entender cómo funcionan, cómo escribirlas en Python, etc. Pude idear una metodología para utilizar redes neuronales para hacer predicciones y crear asesores expertos. En este artículo me gustaría no sólo documentar ese viaje, sino también mostrar lo que he aprendido y cómo una red neuronal simple como LSTM se puede utilizar para hacer predicciones de mercado.
Descripción general de LSTM
Cuando comencé a buscar en Internet, me encontré con algunos artículos que describían el uso de LSTM para predicciones de series de tiempo. En concreto, me encontré con una publicación de Christopher Olah, "Entender las redes LSTM" (Understanding LSTM Networks) en El blog de colah (colah's blog). En su blog, Olah explica la estructura y el funcionamiento de las LSTM, las compara con las RNN estándar y analiza diversas variantes de LSTM, como las que tienen conexiones peephole o unidades recurrentes controladas (GRU, Gated Recurrent Units). Olah concluye destacando el importante impacto de las LSTM en las aplicaciones RNN y apuntando hacia futuros avances como los mecanismos de atención.
En esencia, las redes neuronales tradicionales tienen dificultades con las tareas que requieren el contexto de entradas anteriores debido a su falta de memoria. Las RNN solucionan este problema con bucles que permiten que la información persista, pero siguen teniendo dificultades con las dependencias a largo plazo. Por ejemplo, predecir la siguiente palabra de una frase en la que el contexto relevante se encuentra muchas palabras más atrás puede suponer un reto para las RNN estándar. Las redes de memoria a largo plazo (LSTM) son un tipo de red neuronal recurrente (RNN) diseñada para gestionar mejor las dependencias a largo plazo de las que carecen las RNN.
Las LSTM lo solucionan utilizando una arquitectura más compleja, que incluye un estado celular y tres tipos de compuertas (entrada, olvido y salida) que regulan el flujo de información. Este diseño permite a las LSTM recordar información durante largos periodos, lo que las hace muy eficaces para tareas como el modelado del lenguaje, el reconocimiento del habla y el subtitulado de imágenes. Lo que me interesaba explorar era si las LSTM pueden ayudar a predecir la acción del precio hoy basándose en la acción del precio anterior en días con una acción del precio similar debido a su capacidad natural para recordar información durante periodos de tiempo más largos. Encontré otro útil artículo de Adrian Tam, astutamente titulado «LSTM for Time Series Prediction in PyTorch» que me desmitificó las matemáticas y los aspectos de programación con un ejemplo práctico. Me sentí lo suficientemente seguro como para asumir el reto de aplicarlos en un intento de predecir la acción futura de los precios de cualquier par de divisas.
Proceso de tokenización y normalización
Ideé un método para tokenizar el tiempo dentro de un día determinado y normalizar el precio para un marco temporal concreto dentro del día para entrenar la red neuronal; después, encontré una forma de utilizar la red neuronal entrenada para hacer predicciones; y, por último, desnormalizar la predicción para obtener la predicción del precio futuro. Este enfoque se inspiró en el vídeo ChatGPT que mencioné en mi introducción. Los LLM utilizan una estrategia similar para convertir cadenas de texto en representaciones numéricas y vectoriales con el fin de entrenar redes neuronales para el procesamiento del lenguaje y la generación de respuestas. En mi caso, para el precio, quería que la entrada de datos en mi red neuronal fuera relativa al máximo o mínimo del día sobre una base móvil para el día en cuestión. La estrategia de normalización y tokenización que utilicé figura en el siguiente guión y se resume como sigue:
Tokenización del tiempo
-
Conversión a segundos: El script toma la columna de hora (que está en formato datetime) y la convierte en un número total de segundos transcurridos desde el inicio del día. Este cálculo incluye horas, minutos y segundos.
-
Normalización a fracción de día: El número de segundos resultante se divide por el número total de segundos de un día (86400). Esto crea un time_token que representa el tiempo como una fracción de día. Por ejemplo: Mediodía sería 0,5 o el 50% del día completado.
Normalización diaria de precios
-
Agrupación por fecha: Los datos se agrupan por la columna de fecha para garantizar que la normalización se produce de forma independiente para cada día de negociación.
-
Cálculo móvil de máximos y mínimos:
- Para cada grupo (día), el script calcula el máximo en expansión (rolling_high) y el mínimo en expansión (rolling_low) de los precios máximos y mínimos, respectivamente. Esto significa que el máximo/mínimo móvil sólo aumenta/disminuye a medida que se reciben nuevos datos a lo largo del día.
-
Normalización:
- Los precios de apertura, máximo, mínimo y cierre se normalizan mediante la siguiente fórmula: normalized_price = (price - rolling_low) / (rolling_high - rolling_low)
- Esto escala cada precio a un rango entre 0 y 1 relativo a los precios más altos y más bajos vistos hasta el momento ese día.
- La normalización se realiza diariamente, lo que garantiza que se reflejen las relaciones de precios de cada día y evita que la normalización se vea afectada por los movimientos de precios de varios días.
-
Manejo de valores NaN: Los valores NaN pueden producirse al principio de un día antes de que se establezca el máximo/mínimo móvil. Consideré 3 enfoques diferentes para tratar con ellos. El primer enfoque fue eliminarlos, el segundo, rellenarlos y el tercero, sustituirlos por ceros. Decidí reemplazarlos por ceros después de muchas pruebas y luchando con dejarlos caer porque en última instancia mi objetivo es convertir este proceso en una tubería de procesamiento de datos ONNX que se puede utilizar directamente con MQL5 para hacer predicciones sin replicar el código. Me di cuenta de que ONNX es relativamente rígido en lo que se refiere a las formas de entrada y salida y la eliminación de valores NaNs cambia la forma del vector de salida, lo que provoca errores inesperados cuando se utiliza ONNX en MQL. Traté de usar un método de relleno hacia adelante para reemplazar los NaNs también, pero este es un método Pandas/NumPy y no se traduce convenientemente a torch, que es la biblioteca que utilicé principalmente para convertir mi modelo de red neuronal a ONNX. Finalmente, decidí simplemente reemplazar los NaNs con ceros, esto parecía funcionar mejor lo que me permite evitar el problema de las formas variables, crear una tubería para todo el procesamiento de datos e implementar que en MQL a través de ONNX, agilizando así todo el proceso de obtener una predicción dentro de MQL.
En resumen, la normalización se realiza diariamente, lo que garantiza que se reflejen las relaciones de precios de cada día y evita que la normalización se vea afectada por los movimientos de precios de varios días. De este modo, los precios se sitúan en una escala similar, lo que evita que el modelo se incline hacia características con magnitudes mayores. También ayuda a adaptarse a la volatilidad cambiante de cada día.
El código siguiente ayuda a visualizar el proceso descrito anteriormente. Si descarga el archivo ZIP que acompaña a este artículo, encontrará este código en la carpeta titulada: «Visualizing the Normalization and Tokenization Process». El archivo se llama: "visualizing.py"
import torch import torch.nn as nn import numpy as np import pandas as pd from sklearn.preprocessing import MinMaxScaler import MetaTrader5 as mt5 import matplotlib.pyplot as plt import joblib # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 96) # Note: 96 represents 1 day or 15*96= 1440 minutes of data (there are 1440 minutes in a day) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data # Visualize the price before normalization plt.figure(figsize=(15, 10)) plt.subplot(3, 1, 1) data['close'].plot() plt.title('Close Prices') plt.xlabel('Time') plt.ylabel('Price') data = normalize_daily_rolling(data) # Check for NaNs in the data if data.isnull().values.any(): print("Data contains NaNs") print(data.isnull().sum()) # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Visualize the normalized price plt.subplot(3, 1, 2) data['norm_close'].plot() plt.title('Normalized Close Prices') plt.xlabel('Time') plt.ylabel('Normalized Price') # Visualize Time After Tokenization plt.subplot(3, 1, 3) data['time_token'].plot() plt.title('Time Token') plt.xlabel('Time') plt.ylabel('Time Token') plt.tight_layout() plt.show()
Si ejecuta el código anterior, verá el enfoque que se me ocurrió en acción. En el gráfico a continuación, los precios del 12/6/2024 muestran todo el día de negociación superpuesto hasta el 13/6/2024. También fue un día del dato de IPC y de la reunión de la Reserva Federal, dos importantes noticias en rojo en el mismo día, lo que es relativamente raro. Puede ver que la ficha de tiempo se reinicia al final de cada día y aumenta linealmente a lo largo del día. El precio también se reajusta, pero esto es un poco más difícil de ver en las parcelas. Cada vez que se forma un nuevo máximo, el valor de los precios cerrados normalizados pasa a 1. Cuando se forma un nuevo mínimo, el valor de los precios de cierre normalizados pasa a 0.

Entrenamiento y validación: resumen de pasos
El código siguiente entrena un modelo LSTM (Long Short-Term Memory) para predecir precios, centrándose específicamente en el par de divisas EURUSD. El usuario puede cambiar «EURUSD» por cualquier otro par con el que desee trabajar.
Preparación de datos
- Recuperación de datos: Se conecta a la plataforma MetaTrader 5 para obtener datos históricos de precios (máximo, mínimo, apertura, cierre) para EURUSD en intervalos de 15 minutos. De nuevo, puedes elegir el tiempo que prefieras: 1 minuto, 5 minutos, 15 minutos, etc., en función de tu estilo personal.
- Preprocesamiento de datos:
- Convierte los datos en un Pandas DataFrame, establece la marca de tiempo como índice.
- Crea una función 'time_token' que representa el tiempo como una fracción del día.
- Normaliza los precios de cada día basándose en los precios máximos y mínimos de forma continua para tener en cuenta las fluctuaciones diarias.
- Gestiona los valores omitidos (NaN) sustituyéndolos por ceros.
- Elimina columnas innecesarias, como volúmenes de ticks, volumen real y diferencial.
- Crea secuencias: Estructura los datos en secuencias de 60 pasos temporales, donde cada secuencia se convierte en una entrada (X) y el siguiente precio de cierre es el objetivo (y).
- Divide los datos: Divide las secuencias en conjuntos de entrenamiento (80%) y de prueba (20%).
- Convierte a tensores: Transforma los datos en tensores PyTorch para compatibilidad de modelos.
Definición del modelo y formación
- Define el modelo LSTM: Crea una clase para el modelo LSTM con:
- Una capa LSTM que procesa los datos de secuencia.
- Una capa lineal que produce la predicción final.
- Variables de estado internas del LSTM.
- Establece el entrenamiento:
- Define el Error Cuadrático Medio (MSE, Mean Squared Error) como la función de pérdida a minimizar.
- Utiliza el optimizador Adam para ajustar los pesos del modelo.
- Establece una semilla aleatoria para la reproducibilidad.
- Entrena el modelo:
- Itera más de 100 épocas (pasadas completas por los datos de entrenamiento).
- Para cada secuencia del conjunto de entrenamiento:
- Reinicia el estado oculto del LSTM.
- Pasa la secuencia por el modelo para obtener una predicción.
- Calcula la pérdida MSE entre la predicción y el valor real.
- Realiza la retropropagación para actualizar los pesos del modelo.
- Imprime la pérdida cada 10 épocas.
- Guarda el modelo: Conserva los parámetros del modelo entrenado. El archivo se guarda como «lstm_model.pth» en la misma carpeta que la utilizada para ejecutar el archivo LSTM_model_training.py. También convierte el modelo a formato ONNX para su uso con MQL5 directamente. El archivo ONNX se llama «lstm_model.onnx». Nota: Que la forma del vector requerido para la predicción es seq_length, 1, input_size, que es 60, 1, 5 indicando que se requieren 60 barras anteriores de datos de 15 minutos como 1 lote, con 5 valores (time_token, norm_open, norm_high, norm_low, y norm_close) que están todos entre 0 y 1. Lo utilizaremos más adelante en este artículo para crear un canal de procesamiento de datos en ONNX para utilizarlo con nuestro modelo.
Evaluación
- Genera predicciones:
- Cambia el modelo al modo de evaluación.
- Itera sobre secuencias en el conjunto de prueba y genera predicciones.
- Visualiza resultados:
- Grafica los precios normalizados reales y los precios normalizados previstos.
- Calcula y grafica el cambio porcentual en los precios tanto para los valores reales como para los previstos.
Selección de parámetros del modelo:
- La mayor parte de este código está escrito para centrarse en encontrar tendencias intradía. Sin embargo, se puede adaptar fácilmente a otros marcos temporales, como semanal, mensual, etc. El único problema para mí fue la disponibilidad de datos. De lo contrario, podría haber ampliado el código para incluir algunos de estos otros períodos de tiempo también.
- Elegí trabajar con el período de tiempo de 15 minutos porque podía obtener aproximadamente 80.000 barras de datos para alimentar mi red neuronal. Se trata de aproximadamente 3 años de datos comerciales (excluidos los fines de semana), que parecen suficientes para construir una red neuronal LSTM decente que intenta predecir la acción del precio intradía.
- La base general del modelo son los siguientes 5 parámetros: time_token, norm_open, norm_high, norm_low, norm_close. Por lo tanto, input_size = 5. Hay tres parámetros adicionales que elegí ignorar: volúmenes de ticks, volúmenes reales y spread. Excluí los volúmenes de ticks porque no pude encontrar una fuente de datos lo suficientemente confiable para asegurar que fueran confiables y lo suficientemente dignos de confianza. Excluí los volúmenes reales porque mi bróker no los tiene disponibles y siempre se informan como cero. Por último, excluí el spread porque obtuve los datos de una cuenta demo, por lo que no coinciden con los spreads del bróker de la cuenta real.
- Se eligieron 100 capas ocultas. Este es un valor arbitrario que elegí y que pareció funcionar bien.
- El valor para output_size = 1 porque la forma en que este modelo está diseñado, sólo nos importa la predicción para la siguiente barra de 15 minutos.
- Elegí una división del 80% para la formación frente al 20% para las pruebas. Esta también es una elección arbitraria. Algunas personas prefieren una división 50:50, otras prefieren una división 70:30. No estaba muy seguro, así que decidí utilizar un reparto de 80:20.
- Elegí un valor semilla de 42. Mi objetivo principal era tener cierta reproducibilidad en los resultados desde el ensayo hasta el ensayo. Por lo tanto, especifiqué el valor inicial para poder comparar los resultados de manera uniforme en caso de que decida jugar con algún parámetro en el futuro.
- Elegí un valor de tasa de aprendizaje de 0,001. Se trata nuevamente de una elección arbitraria. El usuario es libre de establecer su ritmo de aprendizaje como mejor le parezca.
- Seleccioné la longitud de secuencia (seq_length) de 60. Básicamente, esta es la cantidad de barras de "contexto" que necesita el modelo LSTM para hacer la predicción sobre la siguiente barra. Esta también fue una elección arbitraria. 60 * 15 minutos = 900 minutos o 15 horas. Eso es mucho tiempo para obtener el contexto para poder predecir un compás de 15 minutos y puede ser un poco excesivo. No tengo una gran justificación para elegir este valor; sin embargo, el modelo es flexible y los usuarios son libres de cambiar estos valores como lo consideren conveniente.
- Tiempo de entrenamiento: Se eligieron 100 épocas porque el modelo con 80.000 barras tardaría aproximadamente 8 horas en ejecutarse en mi computadora. Utilicé la CPU para entrenar. Mientras escribía este artículo, realicé varias mejoras en mi código y tuve que volver a ejecutar el modelo varias veces. Así que pude permitirme entrenar durante 8 horas para el modelo.
import torch import torch.nn as nn import numpy as np import pandas as pd import MetaTrader5 as mt5 import matplotlib.pyplot as plt import torch.onnx import torch.nn.functional as F # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 80000) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data data = normalize_daily_rolling(data) # Check for NaNs in the data if data.isnull().values.any(): print("Data contains NaNs") print(data.isnull().sum()) # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Create sequences def create_sequences(data, seq_length): xs, ys = [], [] for i in range(len(data) - seq_length): x = data.iloc[i:(i + seq_length)].values y = data.iloc[i + seq_length]['norm_close'] xs.append(x) ys.append(y) return np.array(xs), np.array(ys) seq_length = 60 X, y = create_sequences(data, seq_length) # Split data split = int(len(X) * 0.8) X_train, X_test = X[:split], X[split:] y_train, y_test = y[:split], y[split:] # Convert to tensors X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) # Set the seed for reproducibility seed_value = 42 torch.manual_seed(seed_value) # Define LSTM model class class LSTMModel(nn.Module): def __init__(self, input_size, hidden_layer_size, output_size): super(LSTMModel, self).__init__() self.hidden_layer_size = hidden_layer_size self.lstm = nn.LSTM(input_size, hidden_layer_size) self.linear = nn.Linear(hidden_layer_size, output_size) def forward(self, input_seq): h0 = torch.zeros(1, input_seq.size(1), self.hidden_layer_size).to(input_seq.device) c0 = torch.zeros(1, input_seq.size(1), self.hidden_layer_size).to(input_seq.device) lstm_out, _ = self.lstm(input_seq, (h0, c0)) predictions = self.linear(lstm_out.view(input_seq.size(0), -1)) return predictions[-1] print(f"Seed value used: {seed_value}") input_size = 5 # time_token, norm_open, norm_high, norm_low, norm_close hidden_layer_size = 100 output_size = 1 model = LSTMModel(input_size, hidden_layer_size, output_size) #model = torch.compile(model) loss_function = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Training epochs = 100 for epoch in range(epochs + 1): for seq, labels in zip(X_train, y_train): optimizer.zero_grad() y_pred = model(seq.unsqueeze(1)) # Ensure both are tensors of shape [1] y_pred = y_pred.view(-1) labels = labels.view(-1) single_loss = loss_function(y_pred, labels) # Print intermediate values to debug NaN loss if torch.isnan(single_loss): print(f'Epoch {epoch} NaN loss detected') print('Sequence:', seq) print('Prediction:', y_pred) print('Label:', labels) single_loss.backward() optimizer.step() if epoch % 10 == 0 or epoch == epochs: # Include the final epoch print(f'Epoch {epoch} loss: {single_loss.item()}') # Save the model's state dictionary torch.save(model.state_dict(), 'lstm_model.pth') # Convert the model to ONNX format model.eval() dummy_input = torch.randn(seq_length, 1, input_size, dtype=torch.float32) onnx_model_path = "lstm_model.onnx" torch.onnx.export(model, dummy_input, onnx_model_path, input_names=['input'], output_names=['output'], dynamic_axes={'input': {0: 'sequence'}, 'output': {0: 'sequence'}}, opset_version=11) print(f"Model has been converted to ONNX format and saved to {onnx_model_path}") # Predictions model.eval() predictions = [] for seq in X_test: with torch.no_grad(): predictions.append(model(seq.unsqueeze(1)).item()) # Evaluate the model plt.plot(y_test.numpy(), label='True Prices (Normalized)') plt.plot(predictions, label='Predicted Prices (Normalized)') plt.legend() plt.show() # Calculate percent changes with a small value added to the denominator to prevent divide by zero error true_prices = y_test.numpy() predicted_prices = np.array(predictions) true_pct_change = np.diff(true_prices) / (true_prices[:-1] + 1e-10) predicted_pct_change = np.diff(predicted_prices) / (predicted_prices[:-1] + 1e-10) # Plot the true and predicted prices plt.figure(figsize=(12, 6)) plt.subplot(2, 1, 1) plt.plot(true_prices, label='True Prices (Normalized)') plt.plot(predicted_prices, label='Predicted Prices (Normalized)') plt.legend() plt.title('True vs Predicted Prices (Normalized)') # Plot the percent change plt.subplot(2, 1, 2) plt.plot(true_pct_change, label='True Percent Change') plt.plot(predicted_pct_change, label='Predicted Percent Change') plt.legend() plt.title('True vs Predicted Percent Change') plt.tight_layout() plt.show()
Resultados de la evaluación del modelo
El tiempo de entrenamiento fue de aproximadamente 8 horas para 100 épocas. El modelo no fue entrenado usando una GPU. Usé mi propio PC, que es una máquina de juegos de 4 años con las siguientes especificaciones: AMD Ryzen 5 4600H con Radeon Graphics a 3,00 GHz y una RAM instalada de 64 GB.
El valor de la semilla y la pérdida de error cuadrático medio para cada 10 épocas se imprimen en la consola.
- Seed value used: 42
- Epoch 0 loss: 0.01435865368694067
- Epoch 10 loss: 0.014593781903386116
- Epoch 20 loss: 0.02026239037513733
- Epoch 30 loss: 0.017134636640548706
- Epoch 40 loss: 0.017405137419700623
- Epoch 50 loss: 0.004391830414533615
- Epoch 60 loss: 0.0210900716483593
- Epoch 70 loss: 0.008576949127018452
- Epoch 80 loss: 0.019675739109516144
- Epoch 90 loss: 0.008747504092752934
- Epoch 100 loss: 0.033280737698078156
Al finalizar el entrenamiento también recibí una advertencia que se muestra a continuación. La advertencia sugiere especificar el modelo de una manera diferente. Estuve jugando un rato intentando arreglarlo. Pero debido al extenso tiempo de entrenamiento, decidí ignorar la advertencia porque las secuencias en nuestro lote no tendrán diferentes longitudes.

Además se generan los siguientes gráficos:
")
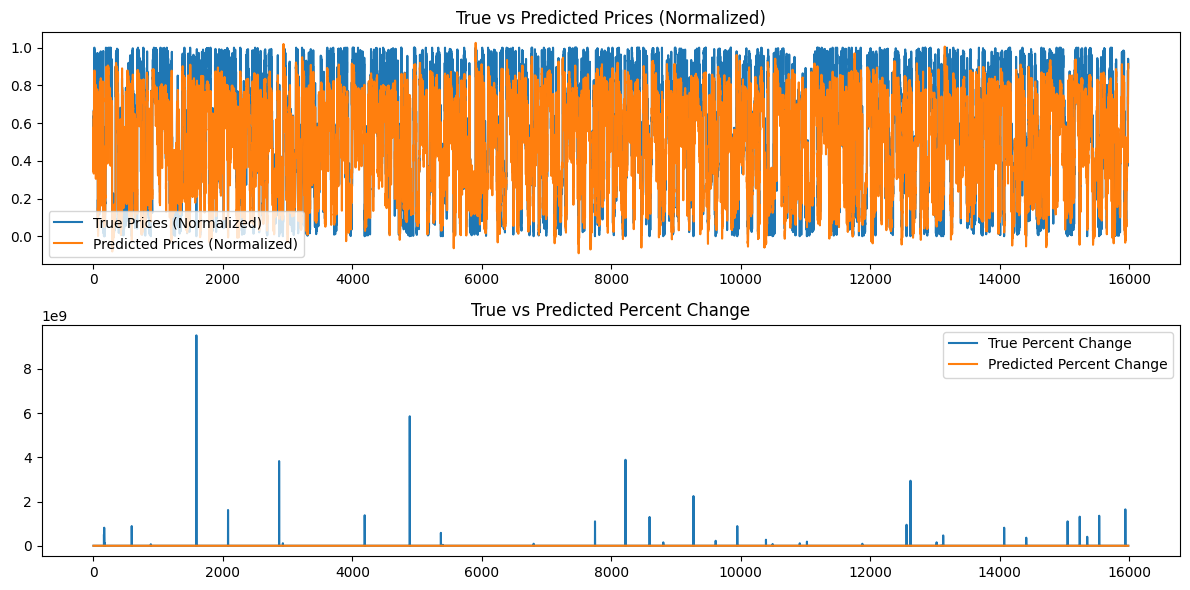
Análisis de los resultados del modelo
Las pérdidas de épocas para un valor de semilla de 42 parecen disminuir de forma errática. Como no son monótonos, quizá el modelo podría beneficiarse de un mayor entrenamiento. Alternativamente, el usuario puede considerar proporcionar un valor de semilla diferente o utilizar un valor de semilla aleatorio generado automáticamente por la librería Torch en Python e imprimir este valor utilizando el comando torch.seed(). Además, el rendimiento del modelo también puede mejorar si se aumenta la cantidad de datos disponibles; sin embargo, al hacerlo, el usuario puede experimentar costes computacionales adicionales asociados a tiempos de entrenamiento más largos y mayores requisitos de memoria de hardware.
Los gráficos generados intentan resumir más de 16000 barras de datos de 15 minutos. Por lo tanto, el sistema de gráficos que he utilizado no es muy eficaz porque la mayoría de los datos quedan aplastados y son difíciles de evaluar. Estos gráficos son representaciones más «globales» de la formación general que ha tenido lugar. Tal como están no añaden ningún valor. Los he incluido como referencia porque también entrené el modelo con conjuntos de datos más pequeños y fueron útiles; sin embargo, para 80.000 barras, no son muy útiles. Abordaremos este problema en la siguiente sección cuando intentemos hacer predicciones basadas en nuestro modelo generado y los datos serán una representación "local", es decir, la acción del precio día a día. Crearemos una predicción continua basada en nuestro modelo en la siguiente sección utilizando nuestra longitud de secuencia de 60 y agregando 100 barras más (160 barras en total de datos de 15 minutos) para hacer una predicción continua desde la barra 100 a 0 y representarla en un gráfico que quizás sea más esclarecedor.
Cómo hacer predicciones usando el modelo entrenado (usando Python)
Para crear un script de predicción, lo ideal sería utilizar los últimos 60 valores de los datos EURUSD en un período de tiempo de 15 minutos para hacer una predicción utilizando el modelo LSTM guardado. Sin embargo, sentí que sería mejor obtener una predicción continua junto con un gráfico en Python para poder validar rápidamente el modelo antes de usarlo. Aquí se presentan las características clave del script de predicción para el caso de uso de Python. A continuación se presenta un resumen del script:
-
Definición del modelo LSTM: El script define la estructura del modelo LSTM. El modelo consta de una capa LSTM seguida de una capa lineal. Esto es idéntico a lo que usamos para entrenar el modelo en el script de entrenamiento anterior.
-
Preparación de datos:
- Se conecta a MetaTrader 5 para recuperar las últimas 160 barras (intervalos de 15 minutos) de datos del EURUSD. Tenga en cuenta que, aunque solo necesitamos 60 barras de datos de 15 minutos para hacer una predicción, extraeremos 160 barras para predecir y comparar las últimas 100 predicciones. Esto nos dará una idea de la tendencia subyacente entre lo previsto y lo real.
- Los datos se convierten en un DataFrame de Pandas y se normalizan utilizando la misma técnica de normalización continua utilizada durante el entrenamiento.
- La tokenización del tiempo se aplica para convertir el tiempo en una representación numérica.
-
Carga del modelo:
- Se carga el modelo LSTM entrenado (desde 'lstm_model.pth'). Este es el modelo que entrenamos durante la fase de entrenamiento.
-
Evaluación:
- El script itera a través de los últimos 100 pasos de los datos.
- Para cada paso, toma las 60 barras anteriores como entrada y utiliza el modelo para predecir el precio de cierre normalizado.
- Los precios verdaderos y previstos se almacenan para su comparación.
-
Próxima predicción:
- Realiza una predicción para el siguiente paso utilizando las 60 barras más recientes.
- Calcula el cambio porcentual para esta predicción.
- Muestra la predicción como un punto rojo en el gráfico.
-
Visualización:
- Se generan dos gráficos:
- Precios verdaderos frente a precios pronosticados (normalizados) con la siguiente predicción resaltada.
- Cambio porcentual del precio verdadero frente al pronosticado, con la siguiente predicción resaltada.
- Los ejes Y están limitados al 100% para una mejor visualización.
- Se generan dos gráficos:
El código que se muestra a continuación se encuentra en el archivo «LSTM_model_prediction.py», que se encuentra en la raíz del archivo LSTM_Files.zip adjunto a este artículo.
import torch import torch.nn as nn import numpy as np import pandas as pd import MetaTrader5 as mt5 import matplotlib.pyplot as plt # Define LSTM model class (same as during training) class LSTMModel(nn.Module): def __init__(self, input_size, hidden_layer_size, output_size): super(LSTMModel, self).__init__() self.hidden_layer_size = hidden_layer_size self.lstm = nn.LSTM(input_size, hidden_layer_size) self.linear = nn.Linear(hidden_layer_size, output_size) self.hidden_cell = (torch.zeros(1, 1, self.hidden_layer_size), torch.zeros(1, 1, self.hidden_layer_size)) def forward(self, input_seq): lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell) predictions = self.linear(lstm_out.view(len(input_seq), -1)) return predictions[-1] # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data[['norm_open', 'norm_high', 'norm_low', 'norm_close']] # Load the saved model input_size = 5 # time_token, norm_open, norm_high, norm_low, norm_close hidden_layer_size = 100 output_size = 1 model = LSTMModel(input_size, hidden_layer_size, output_size) model.load_state_dict(torch.load('lstm_model.pth')) model.eval() # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load the latest 160 bars of market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 bars = 160 # 60 for sequence length + 100 for evaluation steps rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Normalize the new data data[['norm_open', 'norm_high', 'norm_low', 'norm_close']] = normalize_daily_rolling(data) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Fetch the last 100 sequences for evaluation seq_length = 60 evaluation_steps = 100 # Initialize lists for storing evaluation results all_true_prices = [] all_predicted_prices = [] model.eval() for step in range(evaluation_steps, 0, -1): # Get the sequence ending at 'step' seq = data.values[-step-seq_length:-step] seq = torch.tensor(seq, dtype=torch.float32) # Make prediction with torch.no_grad(): model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size), torch.zeros(1, 1, model.hidden_layer_size)) prediction = model(seq).item() all_true_prices.append(data['norm_close'].values[-step]) all_predicted_prices.append(prediction) # Calculate percent changes and convert to percentages true_pct_change = (np.diff(all_true_prices) / np.array(all_true_prices[:-1])) * 100 predicted_pct_change = (np.diff(all_predicted_prices) / np.array(all_predicted_prices[:-1])) * 100 # Make next prediction next_seq = data.values[-seq_length:] next_seq = torch.tensor(next_seq, dtype=torch.float32) with torch.no_grad(): model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size), torch.zeros(1, 1, model.hidden_layer_size)) next_prediction = model(next_seq).item() # Calculate percent change for the next prediction next_true_price = data['norm_close'].values[-1] next_price_pct_change = ((next_prediction - all_predicted_prices[-1]) / all_predicted_prices[-1]) * 100 print(f"Next predicted close price (normalized): {next_prediction}") print(f"Percent change for the next prediction based on normalized price: {next_price_pct_change:.5f}%") print("All Predicted Prices: ", all_predicted_prices) # Plot the evaluation results with capped y-axis plt.figure(figsize=(12, 8)) plt.subplot(2, 1, 1) plt.plot(all_true_prices, label='True Prices (Normalized)') plt.plot(all_predicted_prices, label='Predicted Prices (Normalized)') plt.scatter(len(all_true_prices), next_prediction, color='red', label='Next Prediction') plt.legend() plt.title('True vs Predicted Prices (Normalized, Last 100 Steps)') plt.ylim(min(min(all_true_prices), min(all_predicted_prices))-0.1, max(max(all_true_prices), max(all_predicted_prices))+0.1) plt.subplot(2, 1, 2) plt.plot(true_pct_change, label='True Percent Change') plt.plot(predicted_pct_change, label='Predicted Percent Change') plt.scatter(len(true_pct_change), next_price_pct_change, color='red', label='Next Prediction') plt.legend() plt.title('True vs Predicted Price Percent Change (Last 100 Steps)') plt.ylabel('Percent Change (%)') plt.ylim(-100, 100) # Cap the y-axis at -100% to 100% plt.tight_layout() plt.show()
A continuación se muestra la salida que obtenemos en la consola y los gráficos que obtenemos. Esta predicción se generó justo al comienzo del día 14/06/2024 (Hora aproximada del corredor 00:45 UTC + 3).
Salida de la consola:
Next predicted close price (normalized): 0.9003118872642517
Percent change for the next prediction based on normalized price: 73.64274%
All Predicted Prices: [0.6229779124259949, 0.6659790277481079, 0.6223553419113159, 0.5994003415107727, 0.565409243106842, 0.5767043232917786, 0.5080181360244751, 0.5245669484138489, 0.6399291753768921, 0.5184902548789978, 0.6269711256027222, 0.6532717943191528, 0.7470211386680603, 0.6783792972564697, 0.6942530870437622, 0.6399927139282227, 0.5649009943008423, 0.6392825841903687, 0.6454082727432251, 0.4829435348510742, 0.5231367349624634, 0.17141318321228027, 0.3651347756385803, 0.2568517327308655, 0.41483253240585327, 0.43905267119407654, 0.40459558367729187, 0.25486069917678833, 0.3488359749317169, 0.41225481033325195, 0.13895493745803833, 0.21675345301628113, 0.04991495609283447, 0.28392884135246277, 0.17570143938064575, 0.34913408756256104, 0.17591500282287598, 0.33855849504470825, 0.43142321705818176, 0.5618296265602112, 0.0774659514427185, 0.13539350032806396, 0.4843936562538147, 0.5048894882202148, 0.8364744186401367, 0.782444417476654, 0.7968958616256714, 0.7907949686050415, 0.5655181407928467, 0.6196668744087219, 0.7133172750473022, 0.5095566511154175, 0.3565239906311035, 0.2686333656311035, 0.3386841118335724, 0.5644893646240234, 0.23622554540634155, 0.3433009088039398, 0.3493557274341583, 0.2939424216747284, 0.08992069959640503, 0.33946871757507324, 0.20876094698905945, 0.4227801263332367, 0.4044940173625946, 0.654332160949707, 0.49300187826156616, 0.6266812086105347, 0.807404637336731, 0.5183461904525757, 0.46170246601104736, 0.24424996972084045, 0.3224128782749176, 0.5156376957893372, 0.06813174486160278, 0.1865384578704834, 0.15443122386932373, 0.300825834274292, 0.28375834226608276, 0.4036571979522705, 0.015333771705627441, 0.09899216890335083, 0.16346102952957153, 0.27330827713012695, 0.2869266867637634, 0.21237093210220337, 0.35913240909576416, 0.4736405313014984, 0.3459511995315552, 0.47014304995536804, 0.3305799663066864, 0.47306257486343384, 0.4134630858898163, 0.4199170768260956, 0.5666837692260742, 0.46681761741638184, 0.35662856698036194, 0.3547590374946594, 0.5447400808334351, 0.5184851884841919]

Análisis de los resultados de la predicción
La salida de la consola es 0.9003118872642517, lo que indica que el próximo movimiento del precio probablemente será 0.9 del rango diario actual, que es aproximadamente entre 1.07402 y 1.07336 o ~8 pips. Esto puede no ser suficiente para un cambio de precio, lo cual es comprensible porque en el momento de escribir esto, sólo habíamos tenido ~45 minutos de negociación el 14/6/2024. Sin embargo, el modelo predice que el precio cerrará cerca del extremo superior del rango diario actual.
La siguiente línea es el porcentaje de cambio para la próxima predicción basada en el precio normalizado: 73,64274%. Esto sugiere que el próximo cambio de precio es probable que sea de alrededor de +74% por encima del precio anterior, que cuando se pone en contexto si 8 pips rango diario, puede no ofrecer un número adecuado de pips para colocar un comercio.
En lugar de trabajar con números y fracciones, el usuario puede considerar añadir una línea que tome el valor diario (máximo - mínimo) y lo multiplique por el precio de cierre previsto normalizado, para obtener un valor real de pips que pueda anticipar. No sólo haremos esto cuando convirtamos nuestro script a MQL, sino que también obtendremos una predicción exacta del precio.
Como puede ver en la salida anterior, también se imprime en la consola una lista de 100 predicciones. Podemos utilizar estos valores para la validación, especialmente cuando la transición a MQL5 y empezar a utilizar la secuencia de comandos allí.
Por último, también obtenemos un gráfico de la biblioteca Matplotlib en Python que nos proporciona un conjunto de las últimas 100 predicciones, las representa gráficamente y las compara con los cambios reales en los precios de cierre sobre una base normalizada (escala de 0 a 1). El punto rojo muestra el próximo precio más probable sobre una base normalizada, lo que nos da una indicación de la posible próxima dirección del precio. Con base en este día particular de datos, nuestra predicción parece estar rezagada respecto del mercado, lo que indica que los resultados previstos pueden no estar bien alineados con la acción del precio real del día. En un día así, un operador o usuario discrecional debería considerar mantenerse al margen y no operar porque el modelo no hace predicciones con precisión. Tenga en cuenta que esto no significa necesariamente que las predicciones del modelo sean incorrectas en todo el conjunto de datos, por lo tanto, es posible que tampoco sea necesario volver a entrenarlo.
Transición de Python a ONNX y uso del modelo entrenado con MQL5 directamente.
Creación de una cadena de procesamiento de datos
La idea de crear una cadena de procesamiento de datos para mí era no replicar el código de normalización y tokenización que creé en Python. No quería reescribir ese código en MQL. Así que decidí convertir el script en una cadena de datos, convertirlo a ONNX, y utilizar el ONNX directamente para el procesamiento de datos en MQL. Me llevó varios días descifrar el código para hacerlo debido a mi falta de experiencia previa en la creación de cadenas de procesamiento de datos. La razón de mi dificultad es que Python es relativamente flexible en lo que respecta a los tipos de datos. Pero al convertir a ONNX, hay que ser mucho más rígido y específico. Encontré numerosos errores por el camino. Finalmente, cuando lo resolví me sentí muy feliz y me complace compartir el guión a continuación. He aquí un rápido resumen de cómo funciona el script:
Como ya hemos señalado, el preprocesamiento consta de dos pasos cruciales:
-
Tokenización de la hora: Transforma la hora bruta del día (por ejemplo, 15:45) en un valor fraccionario entre 0 y 1, que representa la parte del día de 24 horas que ha transcurrido.
-
Normalización diaria continua: Este proceso normaliza los datos de precios (apertura, máximo, mínimo, cierre) diariamente. Calcula los precios mínimos y máximos móviles de cada día y normaliza los precios en relación con estos valores. Esta normalización ayuda a entrenar el modelo, ya que garantiza que los datos de precios tengan una escala coherente.
Componentes:
-
TimeTokenizer (Transformador personalizado): Esta clase maneja la tokenización del tiempo. Extrae la columna de tiempo del tensor de entrada, la convierte en una representación fraccionaria del día y luego la combina nuevamente con los demás datos de precios.
-
DailyRollingNormalizer (Transformador personalizado): Esta clase realiza la normalización diaria del proceso. Itera a través de los datos de precios, realizando un seguimiento del máximo y mínimo de cada día. Luego los precios se normalizan utilizando estos valores dinámicos. También incluye un paso para reemplazar cualquier valor potencial de NaN que pueda surgir durante el cálculo.
-
ReplaceNaNs (Transformador personalizado): Reemplaza todos los valores NaN del cálculo con ceros.
-
Cadena (nn.Secuencial): Esto combina los tres transformadores personalizados anteriores en un flujo de trabajo secuencial. Los datos de entrada pasan por el TimeTokenizer, luego por el DailyRollingNormalizer y por último por el ReplaceNaNs en ese orden.
-
Conexión con MetaTrader 5: El script establece una conexión con MetaTrader 5 para recuperar datos históricos de precios del EURUSD.
Ejecución:
-
Carga de datos: El script obtiene 160 barras (puntos de datos de precios) de MetaTrader 5 para el par EURUSD en el marco de tiempo de 15 minutos.
-
Conversión de datos: Los datos en bruto se convierten en un tensor PyTorch para su posterior procesamiento.
-
Procesamiento de la línea de producción: El tensor se pasa a través de la línea de producción definida, aplicando los pasos de tokenización de tiempo y normalización continua diaria.
-
Exportación ONNX: Los datos preprocesados finales se imprimen en la consola para mostrar los resultados antes y después. Además, todo el proceso de preprocesamiento se exporta a un archivo ONNX. ONNX es un formato abierto que permite que los modelos de aprendizaje automático se transfieran fácilmente entre diferentes marcos y entornos, lo que garantiza una compatibilidad más amplia para la implementación y el uso de modelos.
Puntos clave:
- Modularidad: El uso de transformadores personalizados hace que el código sea modular y reutilizable. Cada transformador encapsula un paso de preprocesamiento específico.
- PyTorch: El script se basa en PyTorch, un popular marco de aprendizaje profundo, para operaciones de tensor y gestión de modelos.
- Exportación ONNX: La exportación a ONNX garantiza que los pasos de preprocesamiento se puedan integrar sin problemas con diferentes plataformas o herramientas donde se implementa el modelo entrenado.
import torch import torch.nn as nn import pandas as pd import MetaTrader5 as mt5 # Custom Transformer for tokenizing time class TimeTokenizer(nn.Module): def forward(self, X): time_column = X[:, 0] # Assuming 'time' is the first column time_token = (time_column % 86400) / 86400 time_token = time_token.unsqueeze(1) # Add a dimension to match the input shape return torch.cat((time_token, X[:, 1:]), dim=1) # Concatenate the time token with the rest of the input # Custom Transformer for daily rolling normalization class DailyRollingNormalizer(nn.Module): def forward(self, X): time_tokens = X[:, 0] # Assuming 'time_token' is the first column price_columns = X[:, 1:] # Assuming 'open', 'high', 'low', 'close' are the remaining columns normalized_price_columns = torch.zeros_like(price_columns) rolling_max = price_columns.clone() rolling_min = price_columns.clone() for i in range(1, price_columns.shape[0]): reset_mask = (time_tokens[i] < time_tokens[i-1]).float() rolling_max[i] = reset_mask * price_columns[i] + (1 - reset_mask) * torch.maximum(rolling_max[i-1], price_columns[i]) rolling_min[i] = reset_mask * price_columns[i] + (1 - reset_mask) * torch.minimum(rolling_min[i-1], price_columns[i]) denominator = rolling_max[i] - rolling_min[i] normalized_price_columns[i] = (price_columns[i] - rolling_min[i]) / denominator time_tokens = time_tokens.unsqueeze(1) # Assuming 'time_token' is the first column return torch.cat((time_tokens, normalized_price_columns), dim=1) class ReplaceNaNs(nn.Module): def forward(self, X): X[torch.isnan(X)] = 0 X[X != X] = 0 # replace negative NaNs with 0 return X # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data (reduced sample size for demonstration) symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 160) #intialize with maximum number of bars allowed by your broker mt5.shutdown() # Convert to DataFrame and keep only 'time', 'open', 'high', 'low', 'close' columns data = pd.DataFrame(rates)[['time', 'open', 'high', 'low', 'close']] # Convert the DataFrame to a PyTorch tensor data_tensor = torch.tensor(data.values, dtype=torch.float32) # Create the updated pipeline pipeline = nn.Sequential( TimeTokenizer(), DailyRollingNormalizer(), ReplaceNaNs() ) # Print the data before processing print('Data Before Processing\n', data[:100]) # Process the data processed_data = pipeline(data_tensor) print('Data After Processing\n', processed_data[:100]) # Export the pipeline to ONNX format dummy_input = torch.randn(len(data), len(data.columns)) torch.onnx.export(pipeline, dummy_input, "data_processing_pipeline.onnx", input_names=["input"], output_names=["output"])
La salida del código proporciona los datos antes del procesamiento y después del procesamiento impresos en la consola. No reproduciré esa salida porque no es importante, pero el usuario puede considerar ejecutar el script para ver la salida por sí mismo. Además, la salida crea un archivo: data_processing_pipeline.onnx. Para validar la forma utilizada por este modelo ONNX, creé un script de la siguiente manera:
Este script se puede encontrar en la carpeta de canalización de datos ONNX y se llama "shape_check.py". Estos archivos se encuentran en el archivo LSTM_Files.zip adjunto a este artículo.
import onnx
model = onnx.load("data_processing_pipeline.onnx")
onnx.checker.check_model(model)
for input in model.graph.input:
print(f'Input name: {input.name}')
print(f'Input type: {input.type}')
for dim in input.type.tensor_type.shape.dim:
print(dim.dim_value) Esto da el siguiente resultado:
- 160
- 5
Por lo tanto, la forma requerida por nuestro modelo es 160 barras de 15 minutos y 5 valores (valor de tiempo como entero UNIX, apertura, máximo, mínimo, cierre). Después de procesar los datos, el resultado serán los datos normalizados como time_token, norm_open, norm_high, norm_low y norm_close.
Para probar el procesamiento de datos en MQL, también se me ocurrió un script específico, llamado "LSTM Data Pipeline.mq5", ubicado en la carpeta raíz del archivo ZIP adjunto para validar que los datos se estén transformando de la manera que pretendía originalmente. Este script se puede encontrar a continuación. Las características principales se resumen a continuación:
-
Inicialización (OnInit):
- Carga el modelo ONNX a partir de los datos binarios ("data_processing_pipeline.onnx") incrustados como recurso. Nota: El modelo ONNX se almacena dentro de una carpeta llamada "LSTM", que es una subcarpeta dentro de la carpeta "Experts" como se muestra a continuación.
- Luego configuramos las formas de entrada y salida del modelo en función de nuestro código ONNX. Por lo tanto, el archivo "LSTM Data Pipeline Test.ex5" debe almacenarse dentro de la carpeta Experts porque estamos usando la siguiente ruta. Si decide almacenar el archivo de alguna otra manera, actualice esta línea para asegurarse de que el código funcione adecuadamente.
-
#resource "\\LSTM\\data_processing_pipeline.onnx" as uchar ExtModel[]

-
Manejo de datos de ticks (OnTick):
- Esta función se activa con cada actualización de precio.
- Espera hasta que se forme la siguiente barra (vela de 15 minutos en este caso).
- Llama a la función ProcessData para manejar el procesamiento y la predicción de datos.
-
Procesamiento de datos (ProcessData):
- Obtiene las últimas barras SAMPLE_SIZE (160 en este caso) de datos EURUSD M15.
- Extrae tiempo, precios de apertura, máximos, mínimos y cierre de los datos obtenidos.
- Normaliza el componente de tiempo para representar una fracción de un día (entre 0 y 1).
- Prepara los datos de entrada para el modelo ONNX como un vector unidimensional.
- Ejecuta el modelo ONNX (OnnxRun) con el vector de entrada preparado.
- Recibe la salida procesada del modelo.
- Imprime los datos procesados, que incluyen el token de tiempo y los precios normalizados.
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 160 // Adjusted to match the model's expected input size long ExtHandle=INVALID_HANDLE; datetime ExtNextBar=0; // Expert Advisor initialization int OnInit() { // Load the ONNX model ExtHandle = OnnxCreateFromBuffer(ExtModel, ONNX_DEFAULT); if (ExtHandle == INVALID_HANDLE) { Print("Error creating model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape const long input_shape[] = {SAMPLE_SIZE, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(ExtHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape ", GetLastError()); return(INIT_FAILED); } // Set output shape const long output_shape[] = {SAMPLE_SIZE, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(ExtHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (ExtHandle != INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the ONNX model if (!ProcessData()) { Print("Error processing data"); return; } } // Function to process data using the ONNX model bool ProcessData() { MqlRates rates[SAMPLE_SIZE]; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE, rates); if (copied != SAMPLE_SIZE) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE, ", Copied: ", copied); return false; } else if(copied == SAMPLE_SIZE) { Print("Successfully copied the expected number of rates. Expected: ", SAMPLE_SIZE, ", Copied: ", copied); } double min_time = rates[0].time; double max_time = rates[0].time; for (int i = 1; i < copied; i++) { if (rates[i].time < min_time) min_time = rates[i].time; if (rates[i].time > max_time) max_time = rates[i].time; } float input_data[SAMPLE_SIZE * 5]; int count; for (int i = 0; i < copied; i++) { count++; // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } Print("Count of copied after for loop: ", count); // Resize input vector to match the copied data size vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the ONNX model: ", GetLastError()); return false; } // Process the output data as needed for (int i = 0; i < copied; i++) { float time_token = output_vector[i * 5 + 0]; float norm_open = output_vector[i * 5 + 1]; float norm_high = output_vector[i * 5 + 2]; float norm_low = output_vector[i * 5 + 3]; float norm_close = output_vector[i * 5 + 4]; // Print the processed data PrintFormat("Time Token: %f, Norm Open: %f, Norm High: %f, Norm Low: %f, Norm Close: %f", time_token, norm_open, norm_high, norm_low, norm_close); } return true; }
La salida de este script es la siguiente: valida que la canalización de datos esté funcionando como se esperaba.

Para verificar el resultado anterior, creé un script adicional en Python, llamado "LSTM Data Pipeline Test.py" que básicamente da el mismo resultado. Este script también está incluido en el archivo ZIP adjunto al final de este artículo (ubicado en la carpeta "ONNX Data Pipeline") y se proporciona a continuación para una inspección rápida.
import torch import onnx import onnxruntime as ort import MetaTrader5 as mt5 import pandas as pd import numpy as np # Load the ONNX model onnx_model = onnx.load("data_processing_pipeline.onnx") onnx.checker.check_model(onnx_model) # Initialize MT5 and fetch new data if not mt5.initialize(): print("Initialize failed") mt5.shutdown() symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 160) mt5.shutdown() # Convert the new data to a DataFrame data = pd.DataFrame(rates)[['time', 'open', 'high', 'low', 'close']] data_tensor = torch.tensor(data.values, dtype=torch.float32) # Prepare the input for ONNX input_data = data_tensor.numpy() # Run the ONNX model ort_session = ort.InferenceSession("data_processing_pipeline.onnx") input_name = ort_session.get_inputs()[0].name output_name = ort_session.get_outputs()[0].name processed_data = ort_session.run([output_name], {input_name: input_data})[0] # Convert the output back to DataFrame for easy viewing processed_df = pd.DataFrame(processed_data, columns=['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']) print('Processed Data') print(processed_df)
A continuación se muestra el resultado de ejecutar el script anterior. El formato y la forma de salida coinciden con lo que vimos en la salida MQL anterior.

Uso del modelo entrenado para realizar predicciones en MQL
En esta sección, finalmente quiero conectar las diferentes partes de este artículo (procesamiento de datos y predicción) en un script que permita al usuario obtener una predicción después de entrenar su modelo. Repasemos brevemente lo que se necesita para obtener una predicción en MQL y crear un asesor experto:
- Entrene el modelo ejecutando LSTM_model_training.py. Siéntete libre de ajustar los parámetros como creas conveniente. Al ejecutar este archivo se creará lstm_model.onnx.
- Copie el archivo lstm_model.onnx que se genera al ejecutar LSTM_model_training.py en la carpeta "Experts" dentro de la subcarpeta titulada "LSTM".
- Cree una canalización de procesamiento de datos ejecutando LSTM Data Pipeline.py. Este archivo se encuentra dentro de la "Carpeta de canalización de datos ONNX" en el archivo ZIP adjunto.
- Al ejecutar el archivo se producirá un archivo ONNX para el procesamiento de datos. Copie data_processing_pipeline.onnx en la carpeta "Experts" dentro de la subcarpeta titulada "LSTM".
- Guarde el script que se proporciona a continuación en la carpeta principal "Experts" y adjúntelo al gráfico de 15 minutos del EURUSD para obtener una predicción:
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> //#include <Chart\Chart.mqh> CTrade trade; #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[] #define SAMPLE_SIZE_DATA 160 // Adjusted to match the model's expected input size #define SAMPLE_SIZE_PRED 60 long DataProcessingHandle = INVALID_HANDLE; long PredictionHandle = INVALID_HANDLE; datetime ExtNextBar = 0; // Expert Advisor initialization int OnInit() { // Load the data processing ONNX model DataProcessingHandle = OnnxCreateFromBuffer(DataProcessingModel, ONNX_DEFAULT); if (DataProcessingHandle == INVALID_HANDLE) { Print("Error creating data processing model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for data processing model const long input_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(DataProcessingHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Set output shape for data processing model const long output_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(DataProcessingHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Load the prediction ONNX model PredictionHandle = OnnxCreateFromBuffer(PredictionModel, ONNX_DEFAULT); if (PredictionHandle == INVALID_HANDLE) { Print("Error creating prediction model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for prediction model const long prediction_input_shape[] = {SAMPLE_SIZE_PRED, 1, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(PredictionHandle, ONNX_DEFAULT, prediction_input_shape)) { Print("Error setting the input shape OnnxSetInputShape for prediction model ", GetLastError()); return(INIT_FAILED); } // Set output shape for prediction model const long prediction_output_shape[] = {1}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(PredictionHandle, 0, prediction_output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for prediction model ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (DataProcessingHandle != INVALID_HANDLE) { OnnxRelease(DataProcessingHandle); DataProcessingHandle = INVALID_HANDLE; } if (PredictionHandle != INVALID_HANDLE) { OnnxRelease(PredictionHandle); PredictionHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the data processing ONNX model vectorf input_data = ProcessData(DataProcessingHandle); if (input_data.Size() == 0) { Print("Error processing data"); return; } // Make predictions using the prediction ONNX model double predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1]; for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); //if (prediction < 0) //{ // Print("Error making prediction"); // return; //} // Print the prediction //PrintFormat("Predicted close price (index %d): %f", i, prediction); double min_price = iLow(Symbol(), PERIOD_D1, 0); //price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); //high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); } // Get the actual prices for the last 60 bars double actual_prices[SAMPLE_SIZE_PRED]; for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { actual_prices[i] = iClose(Symbol(), PERIOD_M15, SAMPLE_SIZE_PRED - i); Print(actual_prices[i]); } // Create a label object to display the predicted and actual prices string label_text = "Predicted | Actual\n"; for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { label_text += StringFormat("%.5f | %.5f\n", predictions[i], actual_prices[i]); } label_text += StringFormat("Next prediction: %.5f", predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]); Print(label_text); //int label_handle = ObjectCreate(OBJ_LABEL, 0, 0, 0); //ObjectSetText(label_handle, label_text, 12, clrWhite, clrBlack, ALIGN_LEFT); //ObjectMove(label_handle, 0, ChartHeight() - 20, ChartWidth(), 20); } // Function to process data using the data processing ONNX model vectorf ProcessData(long data_processing_handle) { MqlRates rates[SAMPLE_SIZE_DATA]; vectorf blank_vector; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE_DATA, rates); if (copied != SAMPLE_SIZE_DATA) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE_DATA, ", Copied: ", copied); return blank_vector; } float input_data[SAMPLE_SIZE_DATA * 5]; for (int i = 0; i < copied; i++) { // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(data_processing_handle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the data processing ONNX model: ", GetLastError()); return blank_vector; } return output_vector; } // Function to make predictions using the prediction ONNX model double MakePrediction(const vectorf& input_data, long prediction_handle, int start_index, int size) { vectorf input_subset; input_subset.Resize(size * 5); for (int i = 0; i < size * 5; i++) { input_subset[i] = input_data[start_index * 5 + i]; } vectorf output_vector; output_vector.Resize(1); if (!OnnxRun(prediction_handle, ONNX_NO_CONVERSION, input_subset, output_vector)) { Print("Error running the prediction ONNX model: ", GetLastError()); return -1.0; } // Extract the normalized close price from the output data double norm_close = output_vector[0]; return norm_close; }
Si está utilizando una estructura de carpetas diferente a la que he descrito en este artículo, considere cambiar las siguientes líneas de código para que coincidan con las rutas de archivo deseadas de su propia carpeta.
#resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[]
A modo de repaso, he aquí cómo funciona el script. Funciona con EURUSD en un marco temporal de 15 minutos.
-
Modelo de preprocesamiento de datos: Este modelo («data_processing_pipeline.onnx») se encarga de tareas como la tokenización del tiempo (convertir el tiempo en una representación numérica) y la normalización de los datos de precios, preparándolos para su uso con nuestro modelo LSTM entrenado.
-
Modelo de predicción: Este modelo («lstm_model.onnx») es el modelo de red LSTM (Long Short-Term Memory) entrenado para analizar las 60 barras anteriores de la acción del precio de 15 minutos para darnos una predicción del próximo precio de cierre probable.
Funcionalidad:
-
Inicialización (OnInit):
- Carga ambos modelos ONNX (preprocesamiento de datos y predicción) desde recursos integrados.
- Configura las formas de entrada y salida para ambos modelos según sus requisitos.
-
Manejo de datos de ticks (OnTick):
- Esta función se activa con cada nuevo cambio de precio.
- Espera hasta que se forme la siguiente barra (vela) de 15 minutos.
- Llama a la función ProcessData para preprocesar los datos.
- Itera a través de los datos preprocesados, generando predicciones de precios utilizando la función MakePrediction.
- Convierte las predicciones normalizadas en valores de precios reales. Nota: Para la predicción en MQL5 estamos usando las siguientes líneas de código. Estas líneas de código convierten la predicción que obtuvimos, que se normalizó en relación con el máximo y el mínimo diarios entre 0 y 1, y la convierten nuevamente en un precio objetivo real.
-
double min_price = iLow(Symbol(), PERIOD_D1, 0); //price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); //high of day for max price double price = prediction * (max_price - min_price) + min_price;
- Imprime los precios de cierre previstos y reales para comparar. Los valores se pueden visualizar en la pestaña "Diario".
- Formatea una cadena con la información del precio previsto frente al real.
- Nota: La sección de código comentada parece estar diseñada para crear una etiqueta en el gráfico para mostrar las predicciones y los valores reales. Esta sería una buena ayuda visual para evaluar el rendimiento del modelo en tiempo real. Pero aún no pude completar el código porque todavía estoy pensando en cuál es la mejor manera de usar las predicciones: como indicador o como EA.
-
Procesamiento de datos (ProcessData):
- Obtiene las últimas 160 barras de datos EURUSD M15.
- Prepara los datos de entrada para el modelo de procesamiento de datos (tiempo, apertura, máximo, mínimo, cierre).
- Ejecuta el modelo de procesamiento de datos para normalizar y tokenizar los datos de entrada.
-
Predicción (MakePrediction):
- Toma un subconjunto de los datos preprocesados (una secuencia de 60 puntos de datos) como entrada.
- Ejecuta el modelo de predicción para obtener el precio de cierre previsto normalizado de forma continua.
- Imprime la predicción -> se puede ver en la pestaña "Expertos".
Tenga en cuenta el formato de salida que se indica a continuación:

Como podemos ver, obtenemos algunas cosas diferentes como resultados. Primero están los valores predichos y reales en la columna encima de "Next Prediction". En el formato Predicción | Real (Prediction | Actual) según las líneas del código anterior.
for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { label_text += StringFormat("%.5f | %.5f\n", predictions[i], actual_prices[i]); }
La línea «Next prediction: 1,07333» proviene de las siguientes líneas del código anterior:
label_text += StringFormat("Next prediction: %.5f", predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]); Print(label_text);
Aplicación de modelos entrenados: creación de asesores expertos
Creación de asesores expertos
El enfoque que tomé para convertir la predicción en un asesor experto está inspirado en un artículo de Yevgeniy Koshtenko, titulado «Python, ONNX y MetaTrader 5: Creamos un modelo RandomForest con preprocesamiento de datos RobustScaler y PolynomialFeatures». Se trata de un EA relativamente sencillo que sienta las bases para la creación de EA. Los usuarios pueden, por supuesto, ampliar el enfoque que he descrito a continuación para incluir parámetros adicionales como Trailing Stop o acoplar las predicciones de la red neuronal LSTM con otras herramientas que ya utilizan en el desarrollo de sus Asesores Expertos.
Utilizamos el marco general para procesar los datos y hacer la predicción como lo hicimos anteriormente. Sin embargo, en el script del EA, utilizamos las siguientes modificaciones adicionales:
-
Determinación de señal (DetermineSignal):
- Compara el último precio de cierre previsto con el precio de cierre actual y el spread para determinar la señal comercial.
- Considera un pequeño umbral de dispersión para filtrar señales ruidosas.
-
Gestión de operaciones (CheckForOpen, CheckForClose):
- CheckForOpen: Si no hay ninguna posición abierta y se recibe una señal válida (compra o venta), abre una nueva posición con el tamaño de lote, Stop Loss y Take Profit configurados.
- CheckForClose: Si una posición está abierta y se recibe una señal en la dirección opuesta, cierra la posición. Esto solo sucederá si InpUseStops es "False" debido a las siguientes líneas en el código:
// Check position closing conditions void CheckForClose(void) { if (InpUseStops) return; //...rest of code }De lo contrario, si InpUseStops se establece como "True", la posición solo se cerrará cuando se active el Stop Loss o el Take Profit. El código completo del EA con todo implementado se puede encontrar en la carpeta raíz dentro de LSTM_Files.zip adjunto a este artículo. El archivo se llama LSTM_Simple_EA.mq5
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Lot volume to open a position input bool InpUseStops = true; // Trade with stop orders input int InpTakeProfit = 500; // Take Profit level input int InpStopLoss = 500; // Stop Loss level #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[] #define SAMPLE_SIZE_DATA 160 // Adjusted to match the model's expected input size #define SAMPLE_SIZE_PRED 60 long DataProcessingHandle = INVALID_HANDLE; long PredictionHandle = INVALID_HANDLE; datetime ExtNextBar = 0; int ExtPredictedClass = -1; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Expert Advisor initialization int OnInit() { // Load the data processing ONNX model DataProcessingHandle = OnnxCreateFromBuffer(DataProcessingModel, ONNX_DEFAULT); if (DataProcessingHandle == INVALID_HANDLE) { Print("Error creating data processing model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for data processing model const long input_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(DataProcessingHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Set output shape for data processing model const long output_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(DataProcessingHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Load the prediction ONNX model PredictionHandle = OnnxCreateFromBuffer(PredictionModel, ONNX_DEFAULT); if (PredictionHandle == INVALID_HANDLE) { Print("Error creating prediction model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for prediction model const long prediction_input_shape[] = {SAMPLE_SIZE_PRED, 1, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(PredictionHandle, ONNX_DEFAULT, prediction_input_shape)) { Print("Error setting the input shape OnnxSetInputShape for prediction model ", GetLastError()); return(INIT_FAILED); } // Set output shape for prediction model const long prediction_output_shape[] = {1}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(PredictionHandle, 0, prediction_output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for prediction model ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (DataProcessingHandle != INVALID_HANDLE) { OnnxRelease(DataProcessingHandle); DataProcessingHandle = INVALID_HANDLE; } if (PredictionHandle != INVALID_HANDLE) { OnnxRelease(PredictionHandle); PredictionHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the data processing ONNX model vectorf input_data = ProcessData(DataProcessingHandle); if (input_data.Size() == 0) { Print("Error processing data"); return; } // Make predictions using the prediction ONNX model double predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1]; for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); double min_price = iLow(Symbol(), PERIOD_D1, 0); // price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); // high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); } // Determine the trading signal DetermineSignal(predictions); // Execute trades based on the signal if (ExtPredictedClass >= 0) if (PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Function to determine the trading signal void DetermineSignal(double &predictions[]) { double spread = GetSpreadInPips(_Symbol); double predicted = predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]; // Use the last prediction for decision making if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_M15, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_M15, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } } // Check position opening conditions void CheckForOpen(void) { ENUM_ORDER_TYPE signal = WRONG_VALUE; if (ExtPredictedClass == PRICE_DOWN) signal = ORDER_TYPE_SELL; else if (ExtPredictedClass == PRICE_UP) signal = ORDER_TYPE_BUY; if (signal != WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price, sl = 0, tp = 0; double bid = SymbolInfoDouble(_Symbol, SYMBOL_BID); double ask = SymbolInfoDouble(_Symbol, SYMBOL_ASK); if (signal == ORDER_TYPE_SELL) { price = bid; if (InpUseStops) { sl = NormalizeDouble(bid + InpStopLoss * _Point, _Digits); tp = NormalizeDouble(ask - InpTakeProfit * _Point, _Digits); } } else { price = ask; if (InpUseStops) { sl = NormalizeDouble(ask - InpStopLoss * _Point, _Digits); tp = NormalizeDouble(bid + InpTakeProfit * _Point, _Digits); } } trade.PositionOpen(_Symbol, signal, InpLots, price, sl, tp); } } // Check position closing conditions void CheckForClose(void) { if (InpUseStops) return; bool tsignal = false; long type = PositionGetInteger(POSITION_TYPE); if (type == POSITION_TYPE_BUY && ExtPredictedClass == PRICE_DOWN) tsignal = true; if (type == POSITION_TYPE_SELL && ExtPredictedClass == PRICE_UP) tsignal = true; if (tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { trade.PositionClose(_Symbol, 3); CheckForOpen(); } } // Function to get the current spread double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Function to process data using the data processing ONNX model vectorf ProcessData(long data_processing_handle) { MqlRates rates[SAMPLE_SIZE_DATA]; vectorf blank_vector; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE_DATA, rates); if (copied != SAMPLE_SIZE_DATA) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE_DATA, ", Copied: ", copied); return blank_vector; } float input_data[SAMPLE_SIZE_DATA * 5]; for (int i = 0; i < copied; i++) { // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(data_processing_handle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the data processing ONNX model: ", GetLastError()); return blank_vector; } return output_vector; } // Function to make predictions using the prediction ONNX model double MakePrediction(const vectorf& input_data, long prediction_handle, int start_index, int size) { vectorf input_subset; input_subset.Resize(size * 5); for (int i = 0; i < size * 5; i++) { input_subset[i] = input_data[start_index * 5 + i]; } vectorf output_vector; output_vector.Resize(1); if (!OnnxRun(prediction_handle, ONNX_NO_CONVERSION, input_subset, output_vector)) { Print("Error running the prediction ONNX model: ", GetLastError()); return -1.0; } // Extract the normalized close price from the output data double norm_close = output_vector[0]; return norm_close; }
Pruebas de Asesores Expertos
Después de crear el asesor experto, ejecuté el optimizador con la siguiente configuración:

Se me ocurrieron los siguientes parámetros de optimización en menos de una hora. Para fines demostrativos, solo muestro el primer resultado que apareció. No completé todo el ciclo de optimización porque solo quería ilustrar qué tan bien funcionan las predicciones incluso con poca optimización y un EA relativamente simple que hicimos anteriormente:

Los resultados a lo largo de la duración de la prueba utilizando la configuración especificada se pueden ver a continuación. El informe completo de pruebas retrospectivas también se adjunta como un archivo ZIP para su posterior revisión.

Conclusión
En este artículo, compartí mi recorrido completo desde la extracción de datos de MetaTrader a Python hasta la creación de un asesor experto utilizando una red neuronal LSTM entrenada que se puede usar en MQL5. A lo largo del camino documento cómo abordé la tokenización del tiempo, la normalización del precio, la validación de datos y la obtención de predicciones utilizando Python y MQL5. Tuve que hacer más de 200 revisiones a este artículo porque aprendí cosas nuevas y decidí incorporarlas al artículo. Mi única esperanza es que los lectores puedan usar mi trabajo y aprender rápidamente a usar las poderosas redes neuronales disponibles en Python e implementarlas en MQL5 usando ONNX. También quería permitir a los usuarios aprovechar los canales de procesamiento de datos para transformar los datos de la forma que consideren adecuada e implementar esa funcionalidad en sus scripts MQL5 usando ONNX también. Espero que los lectores disfruten de este artículo y espero cualquier pregunta y recomendación que puedan tener para mí.
Notas adicionales:
- LSTM_Files.zip incluye un archivo requirements.txt con los paquetes de Python necesarios. Simplemente use el comando pip install -r requirements.txt en su terminal. Esto instalará todos los paquetes enumerados en el archivo requirements.txt.
- Si examina este código con un poco de atención, notará que la escala se basa en los máximos y mínimos del día actual, mientras que la matriz de predicción también puede contener datos del día anterior porque utiliza 60 predicciones continuas como vimos, que pueden superponerse con el día anterior, especialmente durante la sesión de Asia.
for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); double min_price = iLow(Symbol(), PERIOD_D1, 0); // price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); // high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); }
Por lo tanto, sería más preciso utilizar el precio del día anterior para una parte de la predicción para obtener los precios reales previstos.
double min_price = iLow(Symbol(), PERIOD_D1, 1 ); // previous day's low double max_price = iHigh(Symbol(), PERIOD_D1, 1 ); // previous day's high
- Incluso el código anterior no es muy preciso porque sería necesario tener en cuenta los máximos y mínimos acumulados hasta ese momento del día para obtener una predicción precisa.
- Lo dejé así porque mi objetivo era convertir mi código en un EA, que principalmente realizará predicciones futuras basadas en los valores tokenizados del día actual más reciente, que es lo que hace data_processing_pipeline.onnx. Pero quienes desarrollen un indicador deberían considerar implementar el uso de los máximos y mínimos del día anterior en rangos continuos para escalar las predicciones pasadas que se superponen con el día anterior. Quizás crear un inverso de data_processing_pipeline.onnx que haga esto a la inversa sería una opción lógica.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/15063
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso