
Erstellung von Zeitreihenvorhersagen mit neuronalen LSTM-Netzen: Normalisierung des Preises und Tokenisierung der Zeit
Einführung
Ich wollte die Verwendung neuronaler Netze bei der Entwicklung einer Handelsstrategie erforschen, also habe ich mich mit dem Thema beschäftigt, indem ich mir zunächst einige Youtube-Videos angesehen habe. Die meisten waren relativ verwirrend, weil sie auf einem sehr grundlegenden Niveau begannen, wie z. B. wie man in Python programmiert: mit Strings, Arrays, OOP und all den anderen Grundlagen. Wenn der Dozent dann zum eigentlichen Kern des Kurses, den neuronalen Netzen und dem maschinellen Lernen, kam, merkte man, dass er einfach nur erklärte, wie man eine bestimmte Bibliothek oder ein vortrainiertes Modell verwendet, ohne wirklich zu erklären, wie sie funktionieren. Nach langem Suchen stieß ich schließlich auf Videos von Andrej Karpathy, die ziemlich aufschlussreich waren. Vor allem sein Video Let's build GPT: from scratch, in code, spelled out erlaubte mir zu sehen, wie man mit codierten einfachen, mathematischen Konzepten menschenähnliche Intelligenz zum Leben erwecken kann, mit nur ein paar hundert Zeilen Code. Das Video hat mir die Welt der neuronalen Netze auf relativ intuitive und praktische Weise erschlossen und mir ermöglicht, ihre Leistungsfähigkeit aus erster Hand zu erfahren. Ich verbinde einige grundlegende Kenntnisse aus seinem Kanal mit der Hilfe von Hunderten von ChatGPT-Abfragen, um zu verstehen, wie sie funktionieren, wie man sie in Python schreibt, usw. Ich war in der Lage, eine Methodik zur Verwendung neuronaler Netze bei der Erstellung von Prognosen und Expertenberatern zu entwickeln. In diesem Artikel möchte ich nicht nur diese Reise dokumentieren, sondern auch zeigen, was ich gelernt habe und wie ein einfaches neuronales Netzwerk wie LSTM für Marktprognosen verwendet werden kann.
LSTM-Übersicht
Bei meiner Suche im Internet bin ich auf einige Artikel gestoßen, in denen die Verwendung von LSTMs für Zeitreihenvorhersagen beschrieben wird. Dabei stieß ich auf einen Blogbeitrag von Christopher Olah, colah's blog, mit dem Titel „Understanding LSTM Networks“. In seinem Blog erklärt Olah die Struktur und Funktion von LSTMs, vergleicht sie mit Standard-RNNs und diskutiert verschiedene LSTM-Varianten, z. B. solche mit Peephole-Verbindungen oder Gated Recurrent Units (GRUs). Abschließend unterstreicht Olah den bedeutenden Einfluss von LSTMs auf RNN-Anwendungen und weist auf künftige Fortschritte wie Aufmerksamkeitsmechanismen hin.
Im Wesentlichen haben herkömmliche neuronale Netze aufgrund ihres fehlenden Gedächtnisses Schwierigkeiten mit Aufgaben, die einen Kontext aus früheren Eingaben erfordern. RNNs lösen dieses Problem durch Schleifen, die es ermöglichen, dass Informationen bestehen bleiben, aber sie haben immer noch Schwierigkeiten mit langfristigen Abhängigkeiten. Zum Beispiel kann die Vorhersage des nächsten Wortes in einem Satz, dessen relevanter Kontext viele Wörter zurückliegt, für Standard-RNNs eine Herausforderung darstellen. Long Short Term Memory (LSTM)-Netzwerke sind eine Art rekurrentes neuronales Netzwerk (RNN), mit dem sich langfristige Abhängigkeiten, die in RNNs fehlen, besser bewältigen lassen.
LSTMs lösen dieses Problem, indem sie eine komplexere Architektur verwenden, die einen Zellzustand und drei Arten von Gattern (Eingabe, Vergessen und Ausgabe) umfasst, die den Informationsfluss regulieren. Dank dieser Konstruktion können sich LSTMs Informationen über lange Zeiträume hinweg merken, was sie für Aufgaben wie Sprachmodellierung, Spracherkennung und Bildunterschriftenerstellung sehr effektiv macht. Ich wollte herausfinden, ob LSTMs aufgrund ihrer natürlichen Fähigkeit, sich Informationen über längere Zeiträume zu merken, dazu beitragen können, das heutige Kursgeschehen auf der Grundlage früherer Kurse an Tagen mit ähnlichem Kursgeschehen vorherzusagen. Ich stieß auf einen weiteren hilfreichen Artikel von Adrian Tam mit dem klugen Titel „LSTM for Time Series Prediction in PyTorch“, der die Mathematik und die Programmieraspekte für mich anhand eines praktischen Beispiels entmystifizierte. Ich fühlte mich zuversichtlich genug, um die Herausforderung anzunehmen, sie bei dem Versuch anzuwenden, die künftige Kursentwicklung für ein bestimmtes Währungspaar vorherzusagen.
Tokenisierung und Normalisierungsprozess
Ich habe eine Methode entwickelt, um die Zeit innerhalb eines bestimmten Tages zu tokenisieren und den Preis für einen bestimmten Zeitrahmen innerhalb des Tages zu normalisieren, um das neuronale Netzwerk zu trainieren; dann habe ich einen Weg gefunden, das trainierte neuronale Netzwerk zu verwenden, um Vorhersagen zu machen; und schließlich die Vorhersage zu denormalisieren, um eine Vorhersage des zukünftigen Preises zu erhalten. Dieser Ansatz wurde durch das ChatGPT-Video inspiriert, das ich in meiner Einleitung erwähnt habe. Eine ähnliche Strategie wird von LLMs verwendet, um Textstrings in numerische und vektorielle Repräsentationen umzuwandeln, um neuronale Netze für die Sprachverarbeitung und die Generierung von Antworten zu trainieren. In meinem Fall wollte ich, dass die Daten, die ich in mein neuronales Netz eingebe, relativ zum Höchst- oder Tiefststand des Tages auf rollierender Basis für den jeweiligen Tag sind. Die Normalisierungs- und Tokenisierungsstrategie, die ich verwendet habe, ist im folgenden Skript dargestellt und wie folgt zusammengefasst:
Tokenisierung der Zeit
-
Umrechnung in Sekunden: Das Skript nimmt die Zeitspalte (im Datumsformat) und konvertiert sie in eine Gesamtzahl von Sekunden, die seit Beginn des Tages vergangen sind. Diese Berechnung umfasst Stunden, Minuten und Sekunden.
-
Normalisierung auf Bruchteile des Tages: Die sich daraus ergebende Anzahl von Sekunden wird dann durch die Gesamtzahl der Sekunden eines Tages (86400) geteilt. Dadurch wird ein time_token erstellt, der die Zeit als Bruchteil eines Tages darstellt. Zum Beispiel: Zu Mittag wären 0,5 oder 50 % des Tages geschafft.
Tägliche rollierende Preisnormalisierung
-
Gruppierung nach Datum: Die Daten werden nach der Datumsspalte gruppiert, um sicherzustellen, dass die Normalisierung unabhängig für jeden Handelstag erfolgt.
-
Rollierende Hoch/Tief-Berechnung:
- Für jede Gruppe (Tag) berechnet das Skript das expandierende Maximum (rolling_high) und das expandierende Minimum (rolling_low) der Höchst- bzw. Tiefstpreise. Das bedeutet, dass der gleitende Höchst-/Tiefstwert nur dann steigt/fällt, wenn im Laufe des Tages neue Daten eintreffen.
-
Normalisierung:
- Die Eröffnungs-, Höchst-, Tiefst- und Schlusskurse werden mit der folgenden Formel normalisiert: normalisierter_Kurs = (Kurs - rollierender_Tiefstkurs) / (rollierender_Höchstkurs - rollierender_Tiefstkurs)
- Damit wird jeder Preis in einen Bereich zwischen 0 und 1 relativ zu den höchsten und niedrigsten Preisen des Tages eingeteilt.
- Die Normalisierung erfolgt auf täglicher Basis, wodurch sichergestellt wird, dass die Preisbeziehungen innerhalb eines Tages erfasst werden und die Normalisierung nicht durch Preisbewegungen über mehrere Tage hinweg beeinflusst wird.
-
Umgang mit NaNs: NaNs („Not a Number“) können zu Beginn eines Tages auftreten, bevor der gleitende Höchst-/Tiefstwert festgelegt wird. Ich habe 3 verschiedene Möglichkeiten in Betracht gezogen, um damit umzugehen. Der erste Ansatz war, sie wegzulassen, der zweite Ansatz war, sie vorwärts zu füllen, und der dritte Ansatz war, sie durch Nullen zu ersetzen. Ich habe beschlossen, sie durch Nullen zu ersetzen, nachdem ich sie ausgiebig getestet und damit gekämpft habe, sie wegzulassen, weil mein Ziel letztendlich darin besteht, diesen Prozess in eine ONNX-Datenverarbeitungspipeline umzuwandeln, die direkt mit MQL5 verwendet werden kann, um Vorhersagen zu treffen, ohne den Code zu replizieren. Ich habe festgestellt, dass ONNX relativ starr ist, wenn es um Eingabe- und Ausgabeformen geht und das Fallenlassen von NaNs die Form des Ausgabevektors verändert, was unerwartete Fehler bei der Verwendung von ONNX in MQL verursacht. Ich habe versucht, eine Vorwärtsfüllmethode zu verwenden, um auch die NaNs zu ersetzen, aber dies ist eine Pandas/NumPy-Methode und lässt sich nicht bequem in Torch übersetzen, die Bibliothek, die ich hauptsächlich verwendet habe, um mein neuronales Netzwerkmodell in ONNX zu konvertieren. Schließlich entschied ich mich, die NaNs einfach durch Nullen zu ersetzen. Dies schien am besten zu funktionieren und erlaubte mir, das Problem der Variablenformen zu umgehen, eine Pipeline für die gesamte Datenverarbeitung zu erstellen und diese in MQL durch ONNX zu implementieren, wodurch der gesamte Prozess des Erhaltens einer Vorhersage innerhalb von MQL rationalisiert wurde.
Zusammenfassend lässt sich sagen, dass die Normalisierung auf täglicher Basis erfolgt, wodurch sichergestellt wird, dass Preisbeziehungen innerhalb eines Tages erfasst werden und die Normalisierung nicht durch Preisbewegungen über mehrere Tage hinweg beeinflusst wird. Auf diese Weise werden die Preise auf eine ähnliche Skala gebracht, was verhindert, dass das Modell auf Merkmale mit größeren Größenordnungen ausgerichtet ist. Es hilft auch, sich an die wechselnde Volatilität des Tages anzupassen.
Der nachstehende Code hilft, den oben beschriebenen Prozess zu veranschaulichen. Wenn Sie die Zip-Datei zu diesem Artikel herunterladen, finden Sie diesen Code im Ordner mit dem Titel: „Visualizing the Normalization and Tokenization Process“. Die Datei heißt: „visualizing.py“.
import torch import torch.nn as nn import numpy as np import pandas as pd from sklearn.preprocessing import MinMaxScaler import MetaTrader5 as mt5 import matplotlib.pyplot as plt import joblib # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 96) # Note: 96 represents 1 day or 15*96= 1440 minutes of data (there are 1440 minutes in a day) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data # Visualize the price before normalization plt.figure(figsize=(15, 10)) plt.subplot(3, 1, 1) data['close'].plot() plt.title('Close Prices') plt.xlabel('Time') plt.ylabel('Price') data = normalize_daily_rolling(data) # Check for NaNs in the data if data.isnull().values.any(): print("Data contains NaNs") print(data.isnull().sum()) # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Visualize the normalized price plt.subplot(3, 1, 2) data['norm_close'].plot() plt.title('Normalized Close Prices') plt.xlabel('Time') plt.ylabel('Normalized Price') # Visualize Time After Tokenization plt.subplot(3, 1, 3) data['time_token'].plot() plt.title('Time Token') plt.xlabel('Time') plt.ylabel('Time Token') plt.tight_layout() plt.show()
Wenn Sie den obigen Code ausführen, sehen Sie den Ansatz, den ich entwickelt habe, in Aktion. In der nachstehenden Darstellung der Kurse vom 12.6.2024 überschneidet sich der gesamte Handelstag mit dem 13.6.2024. Dies war auch ein Tag des Verbraucherpreisindex und ein Tag der Fed-Sitzung, also zwei wichtige rote Nachrichten am selben Tag, was relativ selten vorkommt. Sie können sehen, dass die Zeitmarke am Ende eines jeden Tages zurückgesetzt wird und im Laufe des Tages linear ansteigt. Der Preis wird ebenfalls zurückgesetzt, aber das ist in den Plots etwas schwieriger zu erkennen. Jedes Mal, wenn sich ein neues Hoch bildet, geht der Wert der normalisierten geschlossenen Preise auf 1. Wenn sich ein neues Tief bildet, geht der Wert der normalisierten Schlusskurse auf 0.

Training und Validierung Zusammenfassung der Schritte
Der nachstehende Code trainiert ein LSTM-Modell (Long Short-Term Memory) zur Preisvorhersage, wobei der Schwerpunkt auf dem Währungspaar EURUSD liegt. Der Nutzer kann „EURUSD“ in jedes andere Paar ändern, mit dem er arbeiten möchte.
Vorbereitung der Daten
- Abruf der Daten: Stellt eine Verbindung zur MetaTrader 5-Plattform her, um historische Kursdaten (Höchst-, Tiefst-, Eröffnungs- und Schlusskurs) für EURUSD in 15-Minuten-Intervallen abzurufen. Auch hier können Sie Ihren bevorzugten Zeitrahmen wählen: 1 Minute, 5 Minuten, 15 Minuten usw., je nach Ihrem persönlichen Stil.
- Vorverarbeitet Daten:
- Die Daten werden in einen Pandas DataFrame konvertiert und es wird der Zeitstempel als Index gesetzt.
- Es wird eit ein Merkmal „time_token“ erstell, das die Zeit als Bruchteil des Tages darstellt.
- Es werden die Preise innerhalb eines jeden Tages auf der Grundlage der rollierenden Höchst-/Tiefstwerte auf kontinuierlicher Basis normalisiert, um tägliche Schwankungen zu berücksichtigen.
- Die fehlende Werte (NAN) werden behandelt, indem sie durch Nullen ersetzt werden.
- Unnötige Spalten, wie z. B. Tick-Volumen, echtes Volumen und Spread, werden entfernt.
- Es werden Sequenzen erzeugt: Die Daten werden in Sequenzen von 60 Zeitschritten strukturiert, wobei jede Sequenz eine Eingabe (X) und der folgende Schlusskurs das Ziel (y) darstellt.
- Datenaufteilung: Die Sequenzen werden in Trainings- (80 %) und Testdaten (20 %) aufgeteilt.
- Konvertierung in Tensoren: Transformieren der Daten in PyTorch-Tensoren für eine Modellkompatibilität.
Modelldefinition und Training
- Definieren des LSTM-Modells: Erzeugt eine Klasse für das LSTM-Modell mit:
- Einer LSTM-Schicht, die die Sequenzdaten verarbeitet,
- einer lineare Schicht, die die endgültige Vorhersage erstellt,
- interner Zustandsvariablen für LSTM.
- Einrichten des Trainings:
- Definieren des mittleren quadratischen Fehlers (MSE) als die zu minimierende Verlustfunktion.
- Verwendung des Adam-Optimierer zur Anpassung der Modellgewichte.
- Setzen eines Zufallsanfangswerts (seed value) für die Reproduzierbarkeit.
- Trainieren des Modells:
- Iteration von über 100 Epochen (vollständige Durchläufe durch die Trainingsdaten).
- Für jede Sequenz im Trainingssatz:
- Setzte den verborgenen Zustand des LSTMs zurück.
- Lass die Sequenz durch das Modell laufen, um eine Vorhersage zu erhalten.
- Berechne den MSE-Verlust zwischen der Vorhersage und dem tatsächlichen Wert.
- Führe einen Rückwärtsdurchgang zur Aktualisierung der Modellgewichte durch.
- Drucke den Verlust alle 10 Epochen aus.
- Sichern des Modells: Die Parameter des trainierten Modells werden beibehalten. Die Datei wird unter dem Namen „lstm_model.pth“ in demselben Ordner gespeichert, in dem auch die Datei LSTM_model_training.py ausgeführt wird. Außerdem wird das Modell in das ONNX-Format umgewandelt, damit es direkt mit MQL5 verwendet werden kann. Die ONNX-Datei heißt „lstm_model.onnx“. Hinweis: Die Form des für die Vorhersage erforderlichen Vektors ist seq_length, 1, input_size, also 60, 1, 5, was bedeutet, dass 60 frühere Balken von 15-Minuten-Daten als 1 Stapel mit 5 Werten (time_token, norm_open, norm_high, norm_low und norm_close), die alle zwischen 0 und 1 liegen, erforderlich sind. Wir werden dies später in diesem Artikel verwenden, um eine Datenverarbeitungspipeline in ONNX zur Verwendung mit unserem Modell zu erstellen.
Auswertung
- Erzeugen von Vorhersagen:
- Schalte das Modell in den Evaluierungsmodus.
- Iteriere über die Sequenzen im Testsatz und erstellt Vorhersagen.
- Visualisieren der Ergebnisse:
- Darstellen der tatsächlichen normalisierten Preise und die vorhergesagten normalisierten Preise.
- Berechnen und darstellen der prozentuale Veränderung der Preise sowohl für die tatsächlichen als auch für die vorhergesagten Werte dar.
Auswahl der Modellparameter:
- Ein Großteil dieses Codes ist darauf ausgerichtet, Trends im Tagesverlauf zu finden. Sie kann jedoch leicht an andere Zeitrahmen angepasst werden, z. B. wöchentlich, monatlich usw. Das einzige Problem war für mich die Verfügbarkeit der Daten. Andernfalls hätte ich den Code erweitern können, um auch einige dieser anderen Zeitrahmen einzubeziehen.
- Ich habe mich für den 15-Minuten-Zeitrahmen entschieden, weil ich so etwa 80.000 Balken an Daten in mein neuronales Netzwerk einspeisen konnte. Das sind etwa 3 Jahre Handelsdaten (ohne Wochenenden), die ausreichen, um ein anständiges neuronales LSTM-Netz zu erstellen, das versucht, die Preisentwicklung innerhalb eines Tages vorherzusagen.
- Die allgemeine Grundlage für das Modell bilden die folgenden 5 Parameter: time_token, norm_open, norm_high, norm_low, norm_close. Daher ist die Eingabegröße = 5. Es gibt drei zusätzliche Parameter, die ich nicht berücksichtigt habe: Tick-Volumen, reales Volumen und Spread. Ich habe Tickvolumina ausgeschlossen, weil ich keine vertrauenswürdige Datenquelle finden konnte, um sicherzustellen, dass sie zuverlässig und vertrauenswürdig genug sind. Ich habe die realen Volumina ausgeschlossen, da mein Broker sie nicht zur Verfügung hat und sie immer mit Null angegeben werden. Schließlich habe ich die Spreads ausgeschlossen, weil ich die Daten von einem Demokonto abgerufen habe, sodass sie nicht mit den Spreads eines Live-Kontos übereinstimmen.
- Hidden Layers wurde auf 100 festgelegt. Dies ist ein willkürlicher Wert, den ich gewählt habe und der gut zu funktionieren schien.
- Der Wert für output_size = 1, weil dieses Modell so konzipiert ist, dass wir uns nur für die Vorhersage des nächsten 15-Minuten-Balkens interessieren.
- Ich habe mich entschieden für eine Aufteilung von 80% für das Training und 20% für Tests. Auch dies ist eine willkürliche Entscheidung. Manche Menschen bevorzugen eine 50:50-Aufteilung, andere eine 70:30-Aufteilung. Ich war mir einfach nicht sicher, also habe ich mich für einen Split von 80:20 entschieden.
- Ich habe einen „Seed-Wert“ von 42 gewählt. Mein Hauptziel war es, eine gewisse Reproduzierbarkeit der Ergebnisse von Versuch zu Versuch zu erreichen. Deshalb habe ich den Seed-Wert angegeben, damit ich die Ergebnisse auf einer gleichmäßigen Basis vergleichen kann, falls ich in Zukunft mit irgendwelchen Parametern spielen möchte.
- Ich habe eine Lernrate von 0,001 gewählt. Auch dies ist eine willkürliche Entscheidung. Der Nutzer kann sein Lerntempo nach eigenem Ermessen festlegen.
- Ich habe eine Sequenzlänge (seq_length) von 60 gewählt. Im Grunde ist dies die Anzahl der Balken, die das LSTM-Modell benötigt, um eine Vorhersage für den nächsten Takt zu treffen. Auch dies war eine willkürliche Entscheidung. 60 * 15 Minuten = 900 Minuten oder 15 Stunden. Das ist eine Menge Zeit, um einen Kontext zu erhalten, um einen 15-Minuten-Balken vorhersagen zu können, und könnte ein wenig übertrieben sein. Ich habe keine gute Begründung für die Wahl dieses Wertes; das Modell ist jedoch flexibel, und es steht den Nutzern frei, diese Werte nach eigenem Ermessen zu ändern.
- Trainingszeit: 100 Epochen wurden gewählt, weil das Modell mit 80.000 Balken auf meinem Computer etwa 8 Stunden dauern würde. Ich habe CPU für das Training verwendet. Während ich diesen Artikel schrieb, nahm ich mehrere Verfeinerungen an meinem Code vor und musste das Modell mehrere Male neu ausführen. Also 8 Stunden Trainingszeit konnte ich mir für das Modell leisten.
import torch import torch.nn as nn import numpy as np import pandas as pd import MetaTrader5 as mt5 import matplotlib.pyplot as plt import torch.onnx import torch.nn.functional as F # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 80000) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data data = normalize_daily_rolling(data) # Check for NaNs in the data if data.isnull().values.any(): print("Data contains NaNs") print(data.isnull().sum()) # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Create sequences def create_sequences(data, seq_length): xs, ys = [], [] for i in range(len(data) - seq_length): x = data.iloc[i:(i + seq_length)].values y = data.iloc[i + seq_length]['norm_close'] xs.append(x) ys.append(y) return np.array(xs), np.array(ys) seq_length = 60 X, y = create_sequences(data, seq_length) # Split data split = int(len(X) * 0.8) X_train, X_test = X[:split], X[split:] y_train, y_test = y[:split], y[split:] # Convert to tensors X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) # Set the seed for reproducibility seed_value = 42 torch.manual_seed(seed_value) # Define LSTM model class class LSTMModel(nn.Module): def __init__(self, input_size, hidden_layer_size, output_size): super(LSTMModel, self).__init__() self.hidden_layer_size = hidden_layer_size self.lstm = nn.LSTM(input_size, hidden_layer_size) self.linear = nn.Linear(hidden_layer_size, output_size) def forward(self, input_seq): h0 = torch.zeros(1, input_seq.size(1), self.hidden_layer_size).to(input_seq.device) c0 = torch.zeros(1, input_seq.size(1), self.hidden_layer_size).to(input_seq.device) lstm_out, _ = self.lstm(input_seq, (h0, c0)) predictions = self.linear(lstm_out.view(input_seq.size(0), -1)) return predictions[-1] print(f"Seed value used: {seed_value}") input_size = 5 # time_token, norm_open, norm_high, norm_low, norm_close hidden_layer_size = 100 output_size = 1 model = LSTMModel(input_size, hidden_layer_size, output_size) #model = torch.compile(model) loss_function = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Training epochs = 100 for epoch in range(epochs + 1): for seq, labels in zip(X_train, y_train): optimizer.zero_grad() y_pred = model(seq.unsqueeze(1)) # Ensure both are tensors of shape [1] y_pred = y_pred.view(-1) labels = labels.view(-1) single_loss = loss_function(y_pred, labels) # Print intermediate values to debug NaN loss if torch.isnan(single_loss): print(f'Epoch {epoch} NaN loss detected') print('Sequence:', seq) print('Prediction:', y_pred) print('Label:', labels) single_loss.backward() optimizer.step() if epoch % 10 == 0 or epoch == epochs: # Include the final epoch print(f'Epoch {epoch} loss: {single_loss.item()}') # Save the model's state dictionary torch.save(model.state_dict(), 'lstm_model.pth') # Convert the model to ONNX format model.eval() dummy_input = torch.randn(seq_length, 1, input_size, dtype=torch.float32) onnx_model_path = "lstm_model.onnx" torch.onnx.export(model, dummy_input, onnx_model_path, input_names=['input'], output_names=['output'], dynamic_axes={'input': {0: 'sequence'}, 'output': {0: 'sequence'}}, opset_version=11) print(f"Model has been converted to ONNX format and saved to {onnx_model_path}") # Predictions model.eval() predictions = [] for seq in X_test: with torch.no_grad(): predictions.append(model(seq.unsqueeze(1)).item()) # Evaluate the model plt.plot(y_test.numpy(), label='True Prices (Normalized)') plt.plot(predictions, label='Predicted Prices (Normalized)') plt.legend() plt.show() # Calculate percent changes with a small value added to the denominator to prevent divide by zero error true_prices = y_test.numpy() predicted_prices = np.array(predictions) true_pct_change = np.diff(true_prices) / (true_prices[:-1] + 1e-10) predicted_pct_change = np.diff(predicted_prices) / (predicted_prices[:-1] + 1e-10) # Plot the true and predicted prices plt.figure(figsize=(12, 6)) plt.subplot(2, 1, 1) plt.plot(true_prices, label='True Prices (Normalized)') plt.plot(predicted_prices, label='Predicted Prices (Normalized)') plt.legend() plt.title('True vs Predicted Prices (Normalized)') # Plot the percent change plt.subplot(2, 1, 2) plt.plot(true_pct_change, label='True Percent Change') plt.plot(predicted_pct_change, label='Predicted Percent Change') plt.legend() plt.title('True vs Predicted Percent Change') plt.tight_layout() plt.show()
Ergebnisse der Modellauswertung
Die Trainingszeit betrug etwa 8 Stunden für 100 Epochen. Das Modell wurde nicht mit einer GPU trainiert. Ich habe meinen eigenen PC verwendet, einen 4 Jahre alten Gaming-Rechner mit den folgenden Spezifikationen: AMD Ryzen 5 4600H mit Radeon Graphics 3,00 GHz und 64 GB installiertem RAM.
Der Seed-Wert und der mittlere quadratische Fehlerverlust für alle 10 Epochen werden auf der Konsole ausgegeben
- Seed value used: 42
- Epoch 0 loss: 0.01435865368694067
- Epoch 10 loss: 0.014593781903386116
- Epoch 20 loss: 0.02026239037513733
- Epoch 30 loss: 0.017134636640548706
- Epoch 40 loss: 0.017405137419700623
- Epoch 50 loss: 0.004391830414533615
- Epoch 60 loss: 0.0210900716483593
- Epoch 70 loss: 0.008576949127018452
- Epoch 80 loss: 0.019675739109516144
- Epoch 90 loss: 0.008747504092752934
- Epoch 100 loss: 0.033280737698078156
Am Ende des Training erhielt ich außerdem die unten abgebildete Warnung. Die Warnung schlägt vor, das Modell auf eine andere Weise zu spezifizieren. Ich habe versucht, das Problem zu beheben. Aufgrund der langen Einarbeitungszeit habe ich mich jedoch entschlossen, die Warnung zu ignorieren, da die Sequenzen in unserem Stapel keine unterschiedlichen Längen haben werden.

Zusätzlich werden die folgenden Diagramme erstellt:
")
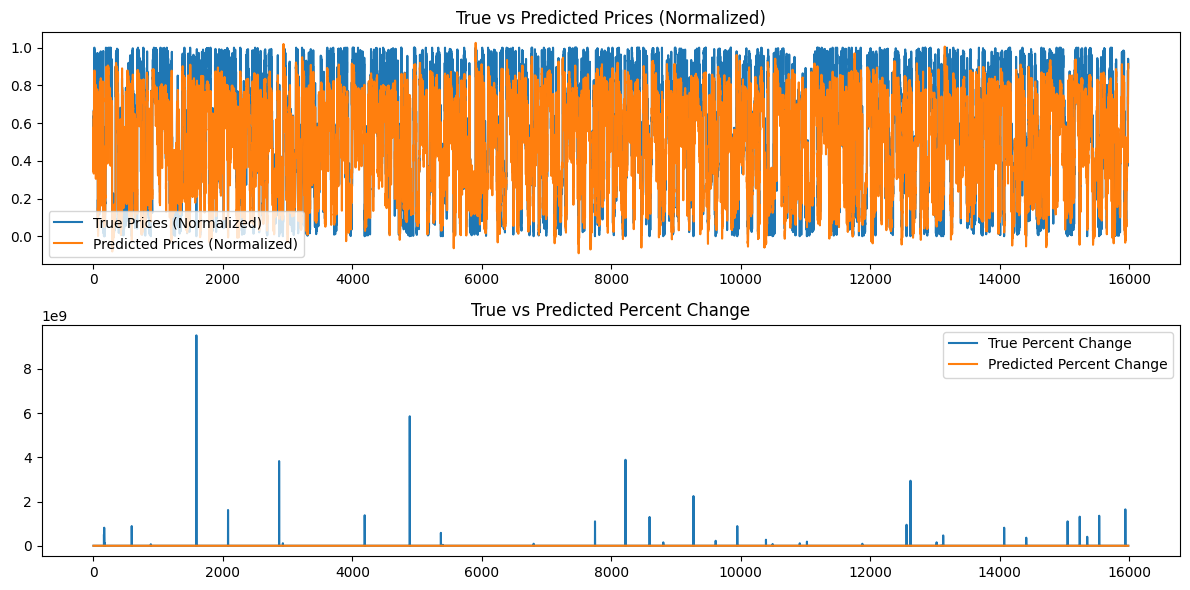
Analyse der Modellergebnisse
Die Epochenverluste bei einem Seed-Wert von 42 scheinen unregelmäßig abzunehmen. Da sie nicht monoton sind, könnte das Modell vielleicht von einem weiteren Training profitieren. Alternativ kann der Nutzer auch einen anderen Seed-Wert angeben oder einen zufälligen Seed-Wert verwenden, der automatisch von der Torch-Bibliothek in Python generiert wird, und diesen Wert mit dem Befehl torch.seed() ausdrucken. Darüber hinaus kann sich die Leistung des Modells auch verbessern, wenn die Menge der verfügbaren Daten erhöht wird; allerdings können dem Nutzer dadurch zusätzliche Rechenkosten entstehen, die mit längeren Trainingszeiten und einem größeren Hardware-Speicherbedarf verbunden sind.
Die erstellten Diagramme versuchen, über 16000 Balken von 15-Minuten-Daten zusammenzufassen. Daher ist das von mir verwendete Diagrammsystem nicht sehr effektiv, da die meisten Daten gequetscht werden und schwer zu beurteilen sind. Diese Diagramme sind eher „globale“ Darstellungen des gesamten Trainings, das stattgefunden hat. So wie sie sind, bringen sie keinen Mehrwert. Ich habe sie als Referenz aufgenommen, weil ich das Modell auch mit kleineren Datensätzen trainiert habe und sie hilfreich waren; für 80.000 Balken sind sie jedoch nicht sehr nützlich. Wir werden uns mit diesem Problem im nächsten Abschnitt befassen, wenn wir versuchen werden, auf der Grundlage des von uns erstellten Modells Vorhersagen zu treffen, und die Daten eine „lokale“ Darstellung darstellen, d. h. die Preisentwicklung von Tag zu Tag. Im nächsten Abschnitt werden wir eine kontinuierliche Vorhersage auf der Grundlage unseres Modells erstellen, indem wir unsere Sequenzlänge von 60 verwenden und 100 weitere Balken hinzufügen (insgesamt 160 Balken mit 15-Minuten-Daten), um eine kontinuierliche Vorhersage von Balken 100 bis 0 zu erstellen und diese in einem Diagramm darzustellen, das vielleicht aufschlussreicher ist.
Erstellen von Vorhersagen mit dem trainierten Modell (mit Python)
Um ein Vorhersageskript zu erstellen, würden wir idealerweise die letzten 60 Werte der EURUSD-Daten in einem 15-Minuten-Zeitrahmen verwenden, um mit dem gespeicherten LSTM-Modell eine Vorhersage zu treffen. Ich hielt es jedoch für besser, eine rollierende Vorhersage zusammen mit einem Diagramm in Python zu erhalten, damit ich das Modell schnell validieren kann, bevor ich es verwende. Hier sind die wichtigsten Merkmale des Vorhersageskripts für den Anwendungsfall Python. Nachstehend finden Sie eine Zusammenfassung des Skripts:
-
LSTM-Modell-Definition: Das Skript definiert die Struktur des LSTM-Modells. Das Modell besteht aus einer LSTM-Schicht, gefolgt von einer linearen Schicht. Dies ist identisch mit dem, was wir für das Training des Modells im Trainingsskript oben verwendet haben.
-
Vorbereitung der Daten:
- Es stellt eine Verbindung zum MetaTrader 5 her, um die letzten 160 Bars (15-Minuten-Intervalle) der EURUSD-Daten abzurufen. Beachten Sie, dass wir zwar nur 60 Balken der 15-Minuten-Daten benötigen, um eine Vorhersage zu treffen, aber 160 Balken zur Vorhersage heranziehen und die letzten 100 Vorhersagen vergleichen. Dies wird uns einen Eindruck von der zugrunde liegenden Tendenz zwischen Vorhersage und Wirklichkeit vermitteln.
- Die Daten werden in einen Pandas DataFrame konvertiert und mit der gleichen Technik der rollierenden Normalisierung normalisiert, die auch beim Training verwendet wurde.
- Tokenisierung der Zeit wird angewendet, um die Zeit in eine numerische Darstellung umzuwandeln.
-
Das Modell laden:
- Das trainierte LSTM-Modell (aus „lstm_model.pth“) wird geladen. Dies ist das Modell, das wir in der Trainingsphase trainiert haben.
-
Auswertung:
- Das Skript iteriert durch die letzten 100 Schritte der Daten.
- Für jeden Schritt werden die 60 vorangegangenen Bars als Eingabe verwendet und das Modell zur Vorhersage des normalisierten Schlusskurses eingesetzt.
- Die tatsächlichen und die voraussichtlichen Preise werden zum Vergleich gespeichert.
-
Nächste Vorhersage:
- Er macht eine Vorhersage für den nächsten Schritt anhand der letzten 60 Balken.
- Berechnet die prozentuale Veränderung für diese Vorhersage.
- Zeigt die Vorhersage als roten Punkt im Chart an.
-
Visualisierung:
- Es werden zwei Diagramme erstellt:
- Tatsächliche gegen vorhergesagten Preise (normalisiert), wobei die nächste Vorhersage hervorgehoben ist.
- Tatsächliche gegen vorhergesagten prozentuale Preisänderung, wobei die nächste Vorhersage hervorgehoben ist.
- Die Y-Achsen sind zur besseren Visualisierung auf 100% begrenzt.
- Es werden zwei Diagramme erstellt:
Der folgende Code befindet sich in der Datei „LSTM_model_prediction.py“, die sich im Stammverzeichnis der diesem Artikel beigefügten Datei LSTM_Files.zip befindet.
import torch import torch.nn as nn import numpy as np import pandas as pd import MetaTrader5 as mt5 import matplotlib.pyplot as plt # Define LSTM model class (same as during training) class LSTMModel(nn.Module): def __init__(self, input_size, hidden_layer_size, output_size): super(LSTMModel, self).__init__() self.hidden_layer_size = hidden_layer_size self.lstm = nn.LSTM(input_size, hidden_layer_size) self.linear = nn.Linear(hidden_layer_size, output_size) self.hidden_cell = (torch.zeros(1, 1, self.hidden_layer_size), torch.zeros(1, 1, self.hidden_layer_size)) def forward(self, input_seq): lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell) predictions = self.linear(lstm_out.view(len(input_seq), -1)) return predictions[-1] # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data[['norm_open', 'norm_high', 'norm_low', 'norm_close']] # Load the saved model input_size = 5 # time_token, norm_open, norm_high, norm_low, norm_close hidden_layer_size = 100 output_size = 1 model = LSTMModel(input_size, hidden_layer_size, output_size) model.load_state_dict(torch.load('lstm_model.pth')) model.eval() # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load the latest 160 bars of market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 bars = 160 # 60 for sequence length + 100 for evaluation steps rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Normalize the new data data[['norm_open', 'norm_high', 'norm_low', 'norm_close']] = normalize_daily_rolling(data) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Fetch the last 100 sequences for evaluation seq_length = 60 evaluation_steps = 100 # Initialize lists for storing evaluation results all_true_prices = [] all_predicted_prices = [] model.eval() for step in range(evaluation_steps, 0, -1): # Get the sequence ending at 'step' seq = data.values[-step-seq_length:-step] seq = torch.tensor(seq, dtype=torch.float32) # Make prediction with torch.no_grad(): model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size), torch.zeros(1, 1, model.hidden_layer_size)) prediction = model(seq).item() all_true_prices.append(data['norm_close'].values[-step]) all_predicted_prices.append(prediction) # Calculate percent changes and convert to percentages true_pct_change = (np.diff(all_true_prices) / np.array(all_true_prices[:-1])) * 100 predicted_pct_change = (np.diff(all_predicted_prices) / np.array(all_predicted_prices[:-1])) * 100 # Make next prediction next_seq = data.values[-seq_length:] next_seq = torch.tensor(next_seq, dtype=torch.float32) with torch.no_grad(): model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size), torch.zeros(1, 1, model.hidden_layer_size)) next_prediction = model(next_seq).item() # Calculate percent change for the next prediction next_true_price = data['norm_close'].values[-1] next_price_pct_change = ((next_prediction - all_predicted_prices[-1]) / all_predicted_prices[-1]) * 100 print(f"Next predicted close price (normalized): {next_prediction}") print(f"Percent change for the next prediction based on normalized price: {next_price_pct_change:.5f}%") print("All Predicted Prices: ", all_predicted_prices) # Plot the evaluation results with capped y-axis plt.figure(figsize=(12, 8)) plt.subplot(2, 1, 1) plt.plot(all_true_prices, label='True Prices (Normalized)') plt.plot(all_predicted_prices, label='Predicted Prices (Normalized)') plt.scatter(len(all_true_prices), next_prediction, color='red', label='Next Prediction') plt.legend() plt.title('True vs Predicted Prices (Normalized, Last 100 Steps)') plt.ylim(min(min(all_true_prices), min(all_predicted_prices))-0.1, max(max(all_true_prices), max(all_predicted_prices))+0.1) plt.subplot(2, 1, 2) plt.plot(true_pct_change, label='True Percent Change') plt.plot(predicted_pct_change, label='Predicted Percent Change') plt.scatter(len(true_pct_change), next_price_pct_change, color='red', label='Next Prediction') plt.legend() plt.title('True vs Predicted Price Percent Change (Last 100 Steps)') plt.ylabel('Percent Change (%)') plt.ylim(-100, 100) # Cap the y-axis at -100% to 100% plt.tight_layout() plt.show()
Nachfolgend sehen Sie die Ausgabe auf der Konsole und die Grafiken, die wir erhalten. Diese Vorhersage wurde gleich zu Beginn des Tages am 14.6.2024 erstellt (ca. Broker-Zeit 00:45 UTC + 3)
Konsolenausgabe:
Nächster voraussichtlicher Schlusskurs (normalisiert): 0.9003118872642517
Prozentuale Veränderung für die nächste Vorhersage auf Basis des normalisierten Preises: 73.64274%
Alle vorhergesagten Preise: [0.6229779124259949, 0.6659790277481079, 0.6223553419113159, 0.5994003415107727, 0.565409243106842, 0.5767043232917786, 0.5080181360244751, 0.5245669484138489, 0.6399291753768921, 0.5184902548789978, 0.6269711256027222, 0.6532717943191528, 0.7470211386680603, 0.6783792972564697, 0.6942530870437622, 0.6399927139282227, 0.5649009943008423, 0.6392825841903687, 0.6454082727432251, 0.4829435348510742, 0.5231367349624634, 0.17141318321228027, 0.3651347756385803, 0.2568517327308655, 0.41483253240585327, 0.43905267119407654, 0.40459558367729187, 0.25486069917678833, 0.3488359749317169, 0.41225481033325195, 0.13895493745803833, 0.21675345301628113, 0.04991495609283447, 0.28392884135246277, 0.17570143938064575, 0.34913408756256104, 0.17591500282287598, 0.33855849504470825, 0.43142321705818176, 0.5618296265602112, 0.0774659514427185, 0.13539350032806396, 0.4843936562538147, 0.5048894882202148, 0.8364744186401367, 0.782444417476654, 0.7968958616256714, 0.7907949686050415, 0.5655181407928467, 0.6196668744087219, 0.7133172750473022, 0.5095566511154175, 0.3565239906311035, 0.2686333656311035, 0.3386841118335724, 0.5644893646240234, 0.23622554540634155, 0.3433009088039398, 0.3493557274341583, 0.2939424216747284, 0.08992069959640503, 0.33946871757507324, 0.20876094698905945, 0.4227801263332367, 0.4044940173625946, 0.654332160949707, 0.49300187826156616, 0.6266812086105347, 0.807404637336731, 0.5183461904525757, 0.46170246601104736, 0.24424996972084045, 0.3224128782749176, 0.5156376957893372, 0.06813174486160278, 0.1865384578704834, 0.15443122386932373, 0.300825834274292, 0.28375834226608276, 0.4036571979522705, 0.015333771705627441, 0.09899216890335083, 0.16346102952957153, 0.27330827713012695, 0.2869266867637634, 0.21237093210220337, 0.35913240909576416, 0.4736405313014984, 0.3459511995315552, 0.47014304995536804, 0.3305799663066864, 0.47306257486343384, 0.4134630858898163, 0.4199170768260956, 0.5666837692260742, 0.46681761741638184, 0.35662856698036194, 0.3547590374946594, 0.5447400808334351, 0.5184851884841919]

Analyse der Vorhersageergebnisse
Die Konsolenausgabe lautet 0,9003118872642517, was darauf hinweist, dass die nächste Kursbewegung wahrscheinlich 0,9 der aktuellen Tagesspanne betragen wird, was ungefähr zwischen 1,07402 und 1,07336 oder ~8 Pips liegt. Dies ist vielleicht nicht ausreichend für eine Kursänderung, was verständlich ist, da zum Zeitpunkt der Erstellung dieses Artikels nur ~45 Minuten am 14.6.2024 gehandelt wurden. Das Modell sagt jedoch voraus, dass der Kurs nahe dem oberen Ende der aktuellen Tagesspanne schließen wird.
Die nächste Zeile lautet: Prozentuale Veränderung für die nächste Vorhersage auf Basis des normalisierten Preises: 73,64274%. Dies deutet darauf hin, dass die nächste Preisänderung wahrscheinlich etwa +74% über dem vorherigen Preis liegen wird, was bei einer täglichen Spanne von 8 Pips nicht unbedingt eine ausreichende Anzahl von Pips für einen Handel bietet.
Anstatt mit Zahlen und Brüchen zu arbeiten, kann der Nutzer eine Linie hinzufügen, die den Tageswert (Höchst- und Tiefstwert) mit dem normalisierten prognostizierten Schlusskurs multipliziert, um einen tatsächlichen Wert von Pips zu erhalten, den er erwarten kann. Wir werden dies nicht nur tun, wenn wir unser Skript in MQL umwandeln, sondern wir werden auch eine genaue Preisvorhersage erhalten.
Wie Sie in der obigen Ausgabe sehen können, wird auch eine Liste von 100 Vorhersagen auf der Konsole ausgegeben. Wir können diese Werte zur Validierung verwenden, insbesondere wenn wir zu MQL5 übergehen und das Skript dort verwenden.
Schließlich erhalten wir auch ein Diagramm aus der Matplotlib-Bibliothek in Python, das uns eine Reihe der letzten 100 Vorhersagen liefert, sie grafisch darstellt und sie mit den tatsächlichen Änderungen der Schlusskurse auf einer normalisierten Basis vergleicht (Skala 0 bis 1). Der rote Punkt zeigt den nächstwahrscheinlichen Kurs auf einer normalisierten Basis an und gibt uns einen Hinweis auf die mögliche nächste Kursrichtung. Auf der Grundlage der Daten dieses Tages scheint unsere Vorhersage hinter dem Markt zurückzubleiben, was darauf hindeutet, dass die vorhergesagten Ergebnisse möglicherweise nicht gut mit dem tatsächlichen Kursverlauf des Tages übereinstimmen. An einem solchen Tag sollte ein diskretionärer Händler oder Nutzer in Erwägung ziehen, an der Seitenlinie zu bleiben und nicht zu handeln, weil das Modell keine genauen Vorhersagen macht. Dies bedeutet nicht zwangsläufig, dass die Modellvorhersagen für den gesamten Datensatz falsch sind, sodass ein erneutes Training nicht unbedingt erforderlich ist.
Übergang von Python zu ONNX und direkte Verwendung des trainierten Modells mit MQL5
Erstellen einer Datenverarbeitungspipeline
Die Idee für die Erstellung einer Datenverarbeitungspipeline war für mich, den Normalisierungs- und Tokenisierungscode, den ich in Python erstellt habe, nicht zu replizieren. Ich wollte diesen Code nicht in MQL umschreiben. Also beschloss ich, das Skript in eine Datenpipeline umzuwandeln, es in ONNX zu konvertieren und ONNX direkt für die Datenverarbeitung in MQL zu verwenden. Ich habe mehrere Tage gebraucht, um den Code dafür zu finden, da ich keine Erfahrung mit der Erstellung von Datenverarbeitungspipelines habe. Der Grund dafür ist, dass Python relativ flexibel ist, wenn es um Datentypen geht. Bei der Umstellung auf ONNX müssen Sie jedoch sehr viel rigider und spezifischer vorgehen. Auf dem Weg dorthin bin ich auf zahlreiche Fehler gestoßen. Als ich es schließlich herausfand, war ich sehr glücklich und ich freue mich, das Skript unten zu teilen. Hier ist eine kurze Zusammenfassung, wie das Skript funktioniert:
Wie wir bereits erwähnt haben, besteht die Vorverarbeitung aus zwei entscheidenden Schritten:
-
Zeit-Tokenisierung: Sie wandelt die rohe Tageszeit (z. B. 15:45 Uhr) in eine reelle Zahl zwischen 0 und 1 um, der den Teil des 24-Stunden-Tages angibt, der bereits verstrichen ist.
-
Tägliche rollierende Normalisierung: Dieses Verfahren standardisiert die Kursdaten (Eröffnungs-, Höchst-, Tiefst- und Schlusskurs) auf täglicher Basis. Es berechnet die rollierenden Minimal- und Maximalpreise innerhalb jedes Tages und normalisiert die Preise relativ zu diesen Werten. Diese Normalisierung hilft bei der Modelltraining, indem sie sicherstellt, dass die Preisdaten eine einheitliche Skala haben.
Bestandteile:
-
TimeTokenizer (Custom Transformer): Diese Klasse behandelt die Zeit-Tokenisierung. Es extrahiert die Zeitspalte aus dem Eingabetensor, konvertiert sie in eine reellen Tagesanteil und kombiniert sie dann wieder mit den anderen Preisdaten.
-
DailyRollingNormalizer (Custom Transformer): Diese Klasse führt die tägliche rollierende Normalisierung durch. Er durchläuft die Preisdaten und verfolgt dabei das rollierende Maximum und Minimum für jeden Tag. Die Preise werden dann anhand dieser dynamischen Werte normalisiert. Es enthält auch einen Schritt, um alle potenziellen NaN-Werte zu ersetzen, die während der Berechnung auftreten könnten.
-
ReplaceNaNs (Custom Transformer): Ersetzt alle NaN-Werte aus der Berechnung durch Nullen.
-
Pipeline (nn.Sequential): Dies kombiniert die drei oben genannten nutzerdefinierten Transformatoren in einem sequentiellen Arbeitsablauf. Die Eingabedaten durchlaufen den TimeTokenizer, dann den DailyRollingNormalizer und zuletzt den ReplaceNaNs in dieser Reihenfolge.
-
MetaTrader5 Verbindung: Das Skript stellt eine Verbindung zum MetaTrader 5 her, um historische EUR/USD-Kursdaten abzurufen.
Ausführung:
-
Laden von Daten: Das Skript holt sich 160 Balken (Preisdatenpunkte) vom MetaTrader 5 für das EURUSD-Paar auf dem 15-Minuten-Zeitrahmen.
-
Datenkonvertierung: Die Rohdaten werden zur weiteren Verarbeitung in einen PyTorch-Tensor umgewandelt.
-
Pipeline-Verarbeitung: Der Tensor durchläuft die definierte Pipeline, in der die Zeit-Tokenisierung und die tägliche rollierende Normalisierung vorgenommen werden.
-
ONNX Export: Die endgültigen, vorverarbeiteten Daten werden auf der Konsole ausgedruckt, um die Ergebnisse vor und nach der Verarbeitung anzuzeigen. Außerdem wird die gesamte Vorverarbeitungspipeline in eine ONNX-Datei exportiert. ONNX ist ein offenes Format, mit dem Modelle für maschinelles Lernen problemlos zwischen verschiedenen Frameworks und Umgebungen übertragen werden können, wodurch eine breitere Kompatibilität bei der Bereitstellung und Verwendung von Modellen gewährleistet wird.
Wichtige Punkte:
- Modularität: Die Verwendung von nutzerdefinierten Transformatoren macht den Code modular und wiederverwendbar. Jeder Transformator kapselt einen bestimmten Vorverarbeitungsschritt.
- PyTorch: Das Skript stützt sich auf PyTorch, ein beliebtes Deep-Learning-Framework, für Tensor-Operationen und Modellverwaltung.
- ONNX Export: Durch den Export in ONNX wird sichergestellt, dass die Vorverarbeitungsschritte nahtlos in verschiedene Plattformen oder Tools integriert werden können, auf denen das trainierte Modell eingesetzt wird.
import torch import torch.nn as nn import pandas as pd import MetaTrader5 as mt5 # Custom Transformer for tokenizing time class TimeTokenizer(nn.Module): def forward(self, X): time_column = X[:, 0] # Assuming 'time' is the first column time_token = (time_column % 86400) / 86400 time_token = time_token.unsqueeze(1) # Add a dimension to match the input shape return torch.cat((time_token, X[:, 1:]), dim=1) # Concatenate the time token with the rest of the input # Custom Transformer for daily rolling normalization class DailyRollingNormalizer(nn.Module): def forward(self, X): time_tokens = X[:, 0] # Assuming 'time_token' is the first column price_columns = X[:, 1:] # Assuming 'open', 'high', 'low', 'close' are the remaining columns normalized_price_columns = torch.zeros_like(price_columns) rolling_max = price_columns.clone() rolling_min = price_columns.clone() for i in range(1, price_columns.shape[0]): reset_mask = (time_tokens[i] < time_tokens[i-1]).float() rolling_max[i] = reset_mask * price_columns[i] + (1 - reset_mask) * torch.maximum(rolling_max[i-1], price_columns[i]) rolling_min[i] = reset_mask * price_columns[i] + (1 - reset_mask) * torch.minimum(rolling_min[i-1], price_columns[i]) denominator = rolling_max[i] - rolling_min[i] normalized_price_columns[i] = (price_columns[i] - rolling_min[i]) / denominator time_tokens = time_tokens.unsqueeze(1) # Assuming 'time_token' is the first column return torch.cat((time_tokens, normalized_price_columns), dim=1) class ReplaceNaNs(nn.Module): def forward(self, X): X[torch.isnan(X)] = 0 X[X != X] = 0 # replace negative NaNs with 0 return X # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data (reduced sample size for demonstration) symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 160) #intialize with maximum number of bars allowed by your broker mt5.shutdown() # Convert to DataFrame and keep only 'time', 'open', 'high', 'low', 'close' columns data = pd.DataFrame(rates)[['time', 'open', 'high', 'low', 'close']] # Convert the DataFrame to a PyTorch tensor data_tensor = torch.tensor(data.values, dtype=torch.float32) # Create the updated pipeline pipeline = nn.Sequential( TimeTokenizer(), DailyRollingNormalizer(), ReplaceNaNs() ) # Print the data before processing print('Data Before Processing\n', data[:100]) # Process the data processed_data = pipeline(data_tensor) print('Data After Processing\n', processed_data[:100]) # Export the pipeline to ONNX format dummy_input = torch.randn(len(data), len(data.columns)) torch.onnx.export(pipeline, dummy_input, "data_processing_pipeline.onnx", input_names=["input"], output_names=["output"])
Die Ausgabe des Codes zeigt die Daten vor der Verarbeitung und nach der Verarbeitung auf der Konsole an. Ich werde diese Ausgabe nicht reproduzieren, weil sie nicht wichtig ist, aber der Nutzer kann das Skript ausführen, um die Ausgabe selbst zu sehen. Außerdem wird bei der Ausgabe eine Datei erstellt: data_processing_pipeline.onnx. Um die von diesem ONNX-Modell verwendete Form zu validieren, habe ich ein Skript wie folgt erstellt:
Dieses Skript befindet sich im ONNX Data Pipeline Folder und heißt „shape_check.py“. Diese Dateien befinden sich in der Datei LSTM_Files.zip im Anhang zu diesem Artikel.
import onnx
model = onnx.load("data_processing_pipeline.onnx")
onnx.checker.check_model(model)
for input in model.graph.input:
print(f'Input name: {input.name}')
print(f'Input type: {input.type}')
for dim in input.type.tensor_type.shape.dim:
print(dim.dim_value) Daraus ergibt sich das folgende Ergebnis:
- 160
- 5
Die von unserem Modell benötigte Form ist daher 160 - 15 Minuten-Balken und 5 Werte (Zeitwert als UNIX Integer, Open, High, Low, Close). Nach der Verarbeitung der Daten werden als Ergebnis die normalisierten Daten als time_token, norm_open, norm_high, norm_low und norm_close angezeigt.
Um die Datenverarbeitung in MQL zu testen, habe ich auch ein spezielles Skript mit dem Namen „LSTM Data Pipeline.mq5“ entwickelt, das sich im Stammverzeichnis der angehängten Zip-Datei befindet, um zu überprüfen, ob die Daten so umgewandelt werden, wie ich es ursprünglich beabsichtigt hatte. Dieses Skript ist unten zu finden. Die wichtigsten Merkmale lassen sich wie folgt zusammenfassen:
-
Initialisierung (OnInit):
- Lädt das ONNX-Modell aus den als Ressource eingebundenen Binärdaten („data_processing_pipeline.onnx“). Beachten Sie , dass das ONNX-Modell in einem Ordner namens „LSTM“ gespeichert ist, der ein Unterordner innerhalb des Ordners „Experts“ ist (siehe unten).
- Dann konfigurieren wir die Eingangs- und Ausgangsformen des Modells auf der Grundlage unseres ONNX-Codes. Die Datei „LSTM Data Pipeline Test.ex5“ sollte also im Ordner Experts gespeichert werden, da wir den folgenden Pfad verwenden. Wenn Sie sich entscheiden, die Datei auf eine andere Art und Weise zu speichern, aktualisieren Sie bitte diese Zeile, um sicherzustellen, dass der Code ordnungsgemäß funktioniert.
-
#resource "\\LSTM\\data_processing_pipeline.onnx" as uchar ExtModel[]

-
Behandlung von Tick-Daten (OnTick):
- Diese Funktion wird bei jeder Preis-Tick-Aktualisierung ausgelöst.
- Es wird gewartet, bis sich der nächste Balken (in diesem Fall eine 15-Minuten-Balken) bildet.
- Ruft die Funktion ProcessData auf, um die Datenverarbeitung und -vorhersage durchzuführen.
-
Datenverarbeitung (ProcessData):
- Holt die letzten SAMPLE_SIZE (in diesem Fall 160) Balken der EURUSD M15-Daten.
- Extrahiert Zeit, Eröffnungs-, Höchst-, Tiefst- und Schlusskurs aus den abgerufenen Daten.
- Normalisiert die Zeitkomponente so, dass sie einen Bruchteil eines Tages darstellt (zwischen 0 und 1).
- Bereitet die Eingabedaten für das ONNX-Modell als eindimensionalen Vektor vor.
- Führt das ONNX-Modell ( OnnxRun ) mit dem vorbereiteten Eingabevektor aus.
- Empfängt die verarbeitete Ausgabe des Modells.
- Druckt die verarbeiteten Daten, einschließlich des Zeit-Tokens und der normalisierten Preise.
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 160 // Adjusted to match the model's expected input size long ExtHandle=INVALID_HANDLE; datetime ExtNextBar=0; // Expert Advisor initialization int OnInit() { // Load the ONNX model ExtHandle = OnnxCreateFromBuffer(ExtModel, ONNX_DEFAULT); if (ExtHandle == INVALID_HANDLE) { Print("Error creating model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape const long input_shape[] = {SAMPLE_SIZE, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(ExtHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape ", GetLastError()); return(INIT_FAILED); } // Set output shape const long output_shape[] = {SAMPLE_SIZE, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(ExtHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (ExtHandle != INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the ONNX model if (!ProcessData()) { Print("Error processing data"); return; } } // Function to process data using the ONNX model bool ProcessData() { MqlRates rates[SAMPLE_SIZE]; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE, rates); if (copied != SAMPLE_SIZE) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE, ", Copied: ", copied); return false; } else if(copied == SAMPLE_SIZE) { Print("Successfully copied the expected number of rates. Expected: ", SAMPLE_SIZE, ", Copied: ", copied); } double min_time = rates[0].time; double max_time = rates[0].time; for (int i = 1; i < copied; i++) { if (rates[i].time < min_time) min_time = rates[i].time; if (rates[i].time > max_time) max_time = rates[i].time; } float input_data[SAMPLE_SIZE * 5]; int count; for (int i = 0; i < copied; i++) { count++; // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } Print("Count of copied after for loop: ", count); // Resize input vector to match the copied data size vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the ONNX model: ", GetLastError()); return false; } // Process the output data as needed for (int i = 0; i < copied; i++) { float time_token = output_vector[i * 5 + 0]; float norm_open = output_vector[i * 5 + 1]; float norm_high = output_vector[i * 5 + 2]; float norm_low = output_vector[i * 5 + 3]; float norm_close = output_vector[i * 5 + 4]; // Print the processed data PrintFormat("Time Token: %f, Norm Open: %f, Norm High: %f, Norm Low: %f, Norm Close: %f", time_token, norm_open, norm_high, norm_low, norm_close); } return true; }
Die Ausgabe dieses Skripts sieht wie folgt aus: Es überprüft, ob die Datenleitung wie erwartet funktioniert.

Um die obige Ausgabe zu überprüfen, habe ich ein zusätzliches Skript in Python mit dem Namen „LSTM Data Pipeline Test.py“ erstellt, das im Wesentlichen die gleiche Ausgabe liefert. Dieses Skript ist auch in der Zip-Datei enthalten, die am Ende dieses Artikels angehängt ist (im Ordner „ONNX Data Pipeline“), und wird im Folgenden zur schnellen Einsichtnahme wiedergegeben.
import torch import onnx import onnxruntime as ort import MetaTrader5 as mt5 import pandas as pd import numpy as np # Load the ONNX model onnx_model = onnx.load("data_processing_pipeline.onnx") onnx.checker.check_model(onnx_model) # Initialize MT5 and fetch new data if not mt5.initialize(): print("Initialize failed") mt5.shutdown() symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 160) mt5.shutdown() # Convert the new data to a DataFrame data = pd.DataFrame(rates)[['time', 'open', 'high', 'low', 'close']] data_tensor = torch.tensor(data.values, dtype=torch.float32) # Prepare the input for ONNX input_data = data_tensor.numpy() # Run the ONNX model ort_session = ort.InferenceSession("data_processing_pipeline.onnx") input_name = ort_session.get_inputs()[0].name output_name = ort_session.get_outputs()[0].name processed_data = ort_session.run([output_name], {input_name: input_data})[0] # Convert the output back to DataFrame for easy viewing processed_df = pd.DataFrame(processed_data, columns=['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']) print('Processed Data') print(processed_df)
Die Ausgabe des Skripts ist unten aufgeführt. Das Ausgabeformat und die Form entsprechen dem, was wir oben in der MQL-Ausgabe gesehen haben.

Verwendung des trainierten Modells zur Erstellung von Vorhersagen in MQL
In diesem Abschnitt möchte ich schließlich die verschiedenen Teile dieses Artikels - Datenverarbeitung und Vorhersage - zu einem Skript verbinden, das es dem Nutzer ermöglicht, nach dem Training seines Modells eine Vorhersage zu erhalten. Schauen wir uns kurz an, was nötig ist, um eine Vorhersage in MQL zu erhalten und einen Expertenberater zu erstellen:
- Trainieren Sie das Modell mit LSTM_model_training.py. Sie können die Parameter nach eigenem Ermessen anpassen. Wenn Sie diese Datei ausführen, wird lstm_model.onnx erstellt.
- Kopieren Sie die Datei lstm_model.onnx, die beim Ausführen von LSTM_model_training.py ausgegeben wird, in den Ordner MQL Experts im Unterordner „LSTM“.
- Erstellen Sie eine Datenverarbeitungspipeline, indem Sie LSTM Data Pipeline.py ausführen. Diese Datei befindet sich im „ONNX Data Pipeline Folder“ in der angehängten Zip-Datei.
- Wenn Sie die Datei ausführen, wird eine ONNX-Datei für die Datenverarbeitung erstellt. Kopieren Sie die Datei data_processing_pipeline.onnx in den Ordner MQL Experts innerhalb des Unterordners mit dem Titel LSTM
- Speichern Sie das unten angegebene Skript im Hauptordner „Experts“ und fügen Sie es an den 15-Minuten-Chart des EURUSD an, um eine Vorhersage zu erhalten:
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> //#include <Chart\Chart.mqh> CTrade trade; #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[] #define SAMPLE_SIZE_DATA 160 // Adjusted to match the model's expected input size #define SAMPLE_SIZE_PRED 60 long DataProcessingHandle = INVALID_HANDLE; long PredictionHandle = INVALID_HANDLE; datetime ExtNextBar = 0; // Expert Advisor initialization int OnInit() { // Load the data processing ONNX model DataProcessingHandle = OnnxCreateFromBuffer(DataProcessingModel, ONNX_DEFAULT); if (DataProcessingHandle == INVALID_HANDLE) { Print("Error creating data processing model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for data processing model const long input_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(DataProcessingHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Set output shape for data processing model const long output_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(DataProcessingHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Load the prediction ONNX model PredictionHandle = OnnxCreateFromBuffer(PredictionModel, ONNX_DEFAULT); if (PredictionHandle == INVALID_HANDLE) { Print("Error creating prediction model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for prediction model const long prediction_input_shape[] = {SAMPLE_SIZE_PRED, 1, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(PredictionHandle, ONNX_DEFAULT, prediction_input_shape)) { Print("Error setting the input shape OnnxSetInputShape for prediction model ", GetLastError()); return(INIT_FAILED); } // Set output shape for prediction model const long prediction_output_shape[] = {1}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(PredictionHandle, 0, prediction_output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for prediction model ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (DataProcessingHandle != INVALID_HANDLE) { OnnxRelease(DataProcessingHandle); DataProcessingHandle = INVALID_HANDLE; } if (PredictionHandle != INVALID_HANDLE) { OnnxRelease(PredictionHandle); PredictionHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the data processing ONNX model vectorf input_data = ProcessData(DataProcessingHandle); if (input_data.Size() == 0) { Print("Error processing data"); return; } // Make predictions using the prediction ONNX model double predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1]; for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); //if (prediction < 0) //{ // Print("Error making prediction"); // return; //} // Print the prediction //PrintFormat("Predicted close price (index %d): %f", i, prediction); double min_price = iLow(Symbol(), PERIOD_D1, 0); //price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); //high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); } // Get the actual prices for the last 60 bars double actual_prices[SAMPLE_SIZE_PRED]; for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { actual_prices[i] = iClose(Symbol(), PERIOD_M15, SAMPLE_SIZE_PRED - i); Print(actual_prices[i]); } // Create a label object to display the predicted and actual prices string label_text = "Predicted | Actual\n"; for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { label_text += StringFormat("%.5f | %.5f\n", predictions[i], actual_prices[i]); } label_text += StringFormat("Next prediction: %.5f", predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]); Print(label_text); //int label_handle = ObjectCreate(OBJ_LABEL, 0, 0, 0); //ObjectSetText(label_handle, label_text, 12, clrWhite, clrBlack, ALIGN_LEFT); //ObjectMove(label_handle, 0, ChartHeight() - 20, ChartWidth(), 20); } // Function to process data using the data processing ONNX model vectorf ProcessData(long data_processing_handle) { MqlRates rates[SAMPLE_SIZE_DATA]; vectorf blank_vector; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE_DATA, rates); if (copied != SAMPLE_SIZE_DATA) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE_DATA, ", Copied: ", copied); return blank_vector; } float input_data[SAMPLE_SIZE_DATA * 5]; for (int i = 0; i < copied; i++) { // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(data_processing_handle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the data processing ONNX model: ", GetLastError()); return blank_vector; } return output_vector; } // Function to make predictions using the prediction ONNX model double MakePrediction(const vectorf& input_data, long prediction_handle, int start_index, int size) { vectorf input_subset; input_subset.Resize(size * 5); for (int i = 0; i < size * 5; i++) { input_subset[i] = input_data[start_index * 5 + i]; } vectorf output_vector; output_vector.Resize(1); if (!OnnxRun(prediction_handle, ONNX_NO_CONVERSION, input_subset, output_vector)) { Print("Error running the prediction ONNX model: ", GetLastError()); return -1.0; } // Extract the normalized close price from the output data double norm_close = output_vector[0]; return norm_close; }
Wenn Sie eine andere Ordnerstruktur verwenden als die, die ich in diesem Artikel beschrieben habe, sollten Sie die folgenden Codezeilen ändern, um die gewünschten Dateipfade an Ihre eigenen Ordner anzupassen.
#resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[]
Das Skript funktioniert folgendermaßen. Es funktioniert mit EURUSD auf einem 15-Minuten-Zeitrahmen.
-
Datenvorverarbeitungsmodell: Dieses Modell („data_processing_pipeline.onnx“) übernimmt Aufgaben wie die Tokenisierung der Zeit (Umwandlung der Zeit in eine numerische Darstellung) und die Normalisierung der Preisdaten und bereitet sie für die Verwendung mit unserem trainierten LSTM-Modell vor.
-
Vorhersagemodell: Bei diesem Modell („lstm_model.onnx“) handelt es sich um ein LSTM-Modell (Long Short-Term Memory), das darauf trainiert wurde, die 60 vorangegangenen 15-Minuten-Balken zu analysieren, um eine Vorhersage des nächsten wahrscheinlichen Schlusskurses zu treffen.
Funktionsweise:
-
Initialisierung (OnInit):
- Lädt beide ONNX-Modelle (Datenvorverarbeitung und Vorhersage) aus eingebetteten Ressourcen.
- Konfiguriert die Eingabe- und Ausgabeformen für beide Modelle auf der Grundlage ihrer Anforderungen.
-
Behandlung von Tick-Daten (OnTick):
- Diese Funktion wird bei jedem neuen Kurs-Tick ausgelöst.
- Er wartet, bis der nächste 15-Minuten-Balken (Kerze) gebildet wird.
- Ruft die Funktion ProcessData auf, um die Daten vorzuverarbeiten.
- Iteriert durch die vorverarbeiteten Daten und erstellt mithilfe der Funktion MakePrediction Preisprognosen.
- Konvertiert die normalisierten Vorhersagen zurück in tatsächliche Preiswerte. HINWEIS: IIn MQL verwenden wir für die Vorhersage jetzt die folgenden Codezeilen. Diese Codezeilen wandeln die Vorhersage, die wir erhalten haben und die relativ zum Tageshoch und -tief zwischen 0 und 1 normalisiert wurde, in ein tatsächliches Kursziel um.
-
double min_price = iLow(Symbol(), PERIOD_D1, 0); //price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); //high of day for max price double price = prediction * (max_price - min_price) + min_price;
- Druckt die vorhergesagten und tatsächlichen Schlusskurse zum Vergleich aus. Die Werte können auf der Registerkarte „Journal“ eingesehen werden.
- Formatiert eine Zeichenkette mit den Informationen über den prognostizierten und den tatsächlichen Preis.
- Anmerkung: Der kommentierte Codeabschnitt scheint dazu gedacht zu sein, eine Kennzeichnung im Chart zu erstellen, um die Vorhersagen und die tatsächlichen Werte anzuzeigen. Dies wäre eine gute visuelle Hilfe für die Bewertung der Modellleistung in Echtzeit. Aber ich konnte den Code noch nicht fertigstellen, weil ich noch überlege, wie ich die Vorhersagen am besten nutzen kann - als Indikator oder als EA.
-
Datenverarbeitung (ProcessData):
- Abrufen der letzten 160 Balken der EURUSD M15-Daten.
- Vorbereitung der Eingabedaten für das Datenverarbeitungsmodell (Zeit, Open, High, Low, Close).
- Ausführen der Datenverarbeitungsmodell, um die Eingabedaten zu normalisieren und zu tokenisieren.
-
Vorhersage (MakePrediction):
- Nimmt eine Teilmenge der vorverarbeiteten Daten (eine Folge von 60 Datenpunkten) als Eingabe.
- Führt das Vorhersagemodell aus, um den normalisierten vorhergesagten Schlusskurs auf kontinuierlicher Basis zu erhalten.
- Druckt die Vorhersage aus -> kann auf der Registerkarte „Experten“ eingesehen werden.
Beachten Sie das unten angegebene Ausgabeformat:

Wie wir sehen können, sind die erhalten Dinge etwas anders, als Ausgaben. Zunächst werden die vorhergesagten und tatsächlichen Werte in der Spalte über der „nächsten Vorhersage“ im Format vorhergesagt | wirklich gemäß den Zeilen des obigen Codes angezeigt.
for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { label_text += StringFormat("%.5f | %.5f\n", predictions[i], actual_prices[i]); }
Die Zeile „Next prediction: 1.07333“ stammt aus den folgenden Zeilen des obigen Codes:
label_text += StringFormat("Next prediction: %.5f", predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]); Print(label_text);
Anwendung der trainierten Modelle: Erstellen des Expert Advisors
Erstellen des Expert Advisors
Der Ansatz, den ich gewählt habe, um die Vorhersage in einen Expert Advisor umzuwandeln, ist inspiriert von einem Artikel von Yevgeniy Koshtenko mit dem Titel „Python, ONNX and MetaTrader 5: Creating a RandomForest model with RobustScaler and PolynomialFeatures data preprocessing“. Es handelt sich um einen relativ einfachen EA, der die Grundlage für die Erstellung von EAs bildet. Die Nutzer können den unten beschriebenen Ansatz natürlich erweitern, um zusätzliche Parameter wie Trailing-Stop einzubeziehen oder die Vorhersagen des neuronalen Netzwerks LSTM mit anderen Instrumenten zu koppeln, die sie bereits für die Entwicklung ihrer Expert Advisors verwenden.
Wir verwenden den allgemeinen Rahmen für die Verarbeitung der Daten und die Erstellung der Vorhersage wie oben beschrieben. Im EA-Skript verwenden wir jedoch die folgenden zusätzlichen Änderungen:
-
Signalermittlung (DetermineSignal):
- Vergleicht den letzten vorhergesagten Schlusskurs mit dem aktuellen Schlusskurs und dem Spread, um das Handelssignal zu bestimmen.
- Berücksichtigt eine kleine Schwellle für den Spread, um verrauschte Signale herauszufiltern.
-
Handelsmanagement (CheckForOpen, CheckForClose):
- CheckForOpen : Wenn keine Position geöffnet ist und ein gültiges Signal (Kauf oder Verkauf) empfangen wird, wird eine neue Position mit der konfigurierten Losgröße, dem Stop-Loss und dem Take-Profit eröffnet.
- CheckForClose : Wenn eine Position offen ist und ein Signal in die entgegengesetzte Richtung empfangen wird, wird die Position geschlossen. Dies geschieht nur, wenn InpUseStops „false“ ist, und zwar aufgrund der folgenden Zeilen im Code:
// Check position closing conditions void CheckForClose(void) { if (InpUseStops) return; //...rest of code }Andernfalls, wenn InpUseStops auf true gesetzt ist, wird die Position nur geschlossen, wenn entweder der Stop-Loss oder der Take-Profit ausgelöst wird. Der vollständige Code für den EA mit allem, was implementiert ist, befindet sich im Stammordner in der an diesen Artikel angehängten Datei LSTM_Files.zip. Die Datei heißt LSTM_Simple_EA.mq5
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Lot volume to open a position input bool InpUseStops = true; // Trade with stop orders input int InpTakeProfit = 500; // Take Profit level input int InpStopLoss = 500; // Stop Loss level #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[] #define SAMPLE_SIZE_DATA 160 // Adjusted to match the model's expected input size #define SAMPLE_SIZE_PRED 60 long DataProcessingHandle = INVALID_HANDLE; long PredictionHandle = INVALID_HANDLE; datetime ExtNextBar = 0; int ExtPredictedClass = -1; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Expert Advisor initialization int OnInit() { // Load the data processing ONNX model DataProcessingHandle = OnnxCreateFromBuffer(DataProcessingModel, ONNX_DEFAULT); if (DataProcessingHandle == INVALID_HANDLE) { Print("Error creating data processing model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for data processing model const long input_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(DataProcessingHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Set output shape for data processing model const long output_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(DataProcessingHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Load the prediction ONNX model PredictionHandle = OnnxCreateFromBuffer(PredictionModel, ONNX_DEFAULT); if (PredictionHandle == INVALID_HANDLE) { Print("Error creating prediction model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for prediction model const long prediction_input_shape[] = {SAMPLE_SIZE_PRED, 1, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(PredictionHandle, ONNX_DEFAULT, prediction_input_shape)) { Print("Error setting the input shape OnnxSetInputShape for prediction model ", GetLastError()); return(INIT_FAILED); } // Set output shape for prediction model const long prediction_output_shape[] = {1}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(PredictionHandle, 0, prediction_output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for prediction model ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (DataProcessingHandle != INVALID_HANDLE) { OnnxRelease(DataProcessingHandle); DataProcessingHandle = INVALID_HANDLE; } if (PredictionHandle != INVALID_HANDLE) { OnnxRelease(PredictionHandle); PredictionHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the data processing ONNX model vectorf input_data = ProcessData(DataProcessingHandle); if (input_data.Size() == 0) { Print("Error processing data"); return; } // Make predictions using the prediction ONNX model double predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1]; for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); double min_price = iLow(Symbol(), PERIOD_D1, 0); // price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); // high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); } // Determine the trading signal DetermineSignal(predictions); // Execute trades based on the signal if (ExtPredictedClass >= 0) if (PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Function to determine the trading signal void DetermineSignal(double &predictions[]) { double spread = GetSpreadInPips(_Symbol); double predicted = predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]; // Use the last prediction for decision making if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_M15, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_M15, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } } // Check position opening conditions void CheckForOpen(void) { ENUM_ORDER_TYPE signal = WRONG_VALUE; if (ExtPredictedClass == PRICE_DOWN) signal = ORDER_TYPE_SELL; else if (ExtPredictedClass == PRICE_UP) signal = ORDER_TYPE_BUY; if (signal != WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price, sl = 0, tp = 0; double bid = SymbolInfoDouble(_Symbol, SYMBOL_BID); double ask = SymbolInfoDouble(_Symbol, SYMBOL_ASK); if (signal == ORDER_TYPE_SELL) { price = bid; if (InpUseStops) { sl = NormalizeDouble(bid + InpStopLoss * _Point, _Digits); tp = NormalizeDouble(ask - InpTakeProfit * _Point, _Digits); } } else { price = ask; if (InpUseStops) { sl = NormalizeDouble(ask - InpStopLoss * _Point, _Digits); tp = NormalizeDouble(bid + InpTakeProfit * _Point, _Digits); } } trade.PositionOpen(_Symbol, signal, InpLots, price, sl, tp); } } // Check position closing conditions void CheckForClose(void) { if (InpUseStops) return; bool tsignal = false; long type = PositionGetInteger(POSITION_TYPE); if (type == POSITION_TYPE_BUY && ExtPredictedClass == PRICE_DOWN) tsignal = true; if (type == POSITION_TYPE_SELL && ExtPredictedClass == PRICE_UP) tsignal = true; if (tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { trade.PositionClose(_Symbol, 3); CheckForOpen(); } } // Function to get the current spread double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Function to process data using the data processing ONNX model vectorf ProcessData(long data_processing_handle) { MqlRates rates[SAMPLE_SIZE_DATA]; vectorf blank_vector; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE_DATA, rates); if (copied != SAMPLE_SIZE_DATA) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE_DATA, ", Copied: ", copied); return blank_vector; } float input_data[SAMPLE_SIZE_DATA * 5]; for (int i = 0; i < copied; i++) { // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(data_processing_handle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the data processing ONNX model: ", GetLastError()); return blank_vector; } return output_vector; } // Function to make predictions using the prediction ONNX model double MakePrediction(const vectorf& input_data, long prediction_handle, int start_index, int size) { vectorf input_subset; input_subset.Resize(size * 5); for (int i = 0; i < size * 5; i++) { input_subset[i] = input_data[start_index * 5 + i]; } vectorf output_vector; output_vector.Resize(1); if (!OnnxRun(prediction_handle, ONNX_NO_CONVERSION, input_subset, output_vector)) { Print("Error running the prediction ONNX model: ", GetLastError()); return -1.0; } // Extract the normalized close price from the output data double norm_close = output_vector[0]; return norm_close; }
Tests des Expert Advisors
Nach der Erstellung des Expertenberaters habe ich den Optimierer mit den folgenden Einstellungen ausgeführt:

Ich habe die folgenden Optimierungsparameter in weniger als 1 Stunde gefunden. Zur Veranschaulichung zeige ich nur das erste Ergebnis, das angezeigt wird. Ich habe den Optimierungszyklus nicht vollständig durchlaufen, weil ich nur zeigen wollte, wie gut die Vorhersagen auch mit wenig Optimierung und einem relativ einfachen EA, den wir oben erstellt haben, funktionieren:

Die Ergebnisse über die Testdauer unter Verwendung der angegebenen Einstellungen sind unten zu sehen. Der vollständige Bericht des Rückwärtsdurchlaufs ist ebenfalls als Zip-Datei zur weiteren Beurteilung beigefügt.

Schlussfolgerung
In diesem Artikel habe ich meine gesamte Reise von der Übertragung von Daten aus Metatrader in Python bis zur Erstellung eines Expert Advisors mit einem trainierten neuronalen LSTM-Netzwerk, das in MQL verwendet werden kann, beschrieben. Dabei dokumentiere ich, wie ich bei der Tokenisierung der Zeit, der Normalisierung des Preises, der Validierung der Daten und der Erstellung von Vorhersagen mit Python und MQL vorgegangen bin. Ich musste diesen Artikel über 200 Mal überarbeiten, da ich neue Dinge gelernt und beschlossen hatte, sie in den Artikel einzubauen. Ich hoffe nur, dass die Leser meine Arbeit nutzen und sich schnell mit den leistungsstarken neuronalen Netzen, die in Python verfügbar sind, vertraut machen und sie mit ONNX in MQL implementieren können. Ich wollte den Nutzern auch die Möglichkeit geben, Datenverarbeitungspipelines zu nutzen, um die Daten nach ihren Vorstellungen umzuwandeln und diese Funktionalität auch in ihre MQL-Skripte mit ONNX zu implementieren. Ich hoffe, dass dieser Artikel den Lesern gefällt, und freue mich auf alle Fragen und Empfehlungen, die sie an mich richten können.
Zusätzliche Hinweise:
- LSTM_Files.zip enthält eine Datei, requirements.txt, mit den erforderlichen Python-Paketen. Verwenden Sie einfach den Befehl pip install -r requirements.txt in Ihrem Terminal. Damit werden alle Pakete installiert, die in der Datei requirements.txt aufgeführt sind.
- Wenn Sie diesen Code etwas genauer untersuchen, werden Sie feststellen, dass die Skalierung auf dem Höchst- und Tiefststand des aktuellen Tages basiert, während das Vorhersage-Array auch die Daten des Vortages enthalten kann, da es, wie wir gesehen haben, 60 kontinuierliche Vorhersagen verwendet, die sich insbesondere während der Asien-Sitzung mit dem Vortag überschneiden können.
for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); double min_price = iLow(Symbol(), PERIOD_D1, 0); // price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); // high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); }
Es wäre also genauer, für einen Teil der Vorhersage den Preis des Vortages zu verwenden, um die tatsächlich vorhergesagten Preise zu erhalten.
double min_price = iLow(Symbol(), PERIOD_D1, 1 ); // previous day's low double max_price = iHigh(Symbol(), PERIOD_D1, 1 ); // previous day's high
- Der obige Code selbst ist nicht sehr genau, da man für eine genaue Vorhersage die rollenden Höchst- und Tiefstwerte bis zu diesem Zeitpunkt berücksichtigen müsste.
- Ich habe das so belassen, weil mein Ziel war, meinen Code in einen EA umzuwandeln, der in erster Linie Zukunftsprognosen auf der Grundlage der jüngsten, tokenisierten Werte des aktuellen Tages erstellen wird, was die data_processing_pipeline.onnx tut. Diejenigen, die einen Indikator entwickeln, sollten jedoch in Erwägung ziehen, die Höchst-/Tiefstwerte des Vortags auf rollierender Basis zu verwenden, um die Prognosen der Vergangenheit, die sich mit dem Vortag überschneiden, zu skalieren. Vielleicht wäre es logisch, eine Umkehrung der data_processing_pipeline.onnx zu erstellen, die dies in umgekehrter Weise tut.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/15063
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.