有关 MQL5 编程和自动交易使用的文章

让开发者为交易者进行服务?
算法交易变得越来越流行并需求旺盛,这自然导致了对于精致算法以及不同寻常任务的需求。从某种程度上说,这些复杂的应用程序都已经在代码库或市场中提供。尽管交易者只需几次简单的点击就可以访问这些应用, 但是这些应用也许不能完全满足所有的需要。为此, 交易者可以在 MQL5 的自由职业者板块分派订单,并寻找开发者来为他们编写期望的应用。

构建和测试肯特纳通道交易系统
在本文中,我们将尝试使用金融市场中一个非常重要的概念 - 波动性 - 来构建交易系统。我们将在了解肯特纳通道(Keltner Channel)指标后提供一个基于该指标的交易系统,并介绍如何对其进行编码,以及如何根据简单的交易策略创建一个交易系统,然后在不同的资产上进行测试。

神经网络变得轻松(第四十四部分):动态学习技能
在上一篇文章中,我们讲解了 DIAYN 方法,它提供了学习各种技能的算法。 获得的技能可用在各种任务。 但这些技能可能非常难以预测,而这可能令它们难以运用。 在本文中,我们要研究一种针对学习可预测技能的算法。
DoEasy 库中的其他类(第六十九部分):图表对象集合类
在本文里,我启动图表对象集合类的开发。 该类存储图表对象及其子窗口和指标的集合列表,从而提供操控任何选定图表及其子窗口的能力,亦或同时处理多个图表列表。


学习如何基于柴金(Chaikin)振荡器设计交易系统
欢迎阅读我们系列的新篇章,学习如何基于最流行的技术指标设计交易系统。 通读这篇新文章,我们将学习如何基于柴金(Chaikin)振荡器指标设计交易系统。


神经网络变得轻松(第三十六部分):关系强化学习
在上一篇文章中讨论的强化学习模型中,我们用到了卷积网络的各种变体,这些变体能够识别原始数据中的各种对象。 卷积网络的主要优点是能够识别对象,无关它们的位置。 与此同时,当物体存在各种变形和噪声时,卷积网络并不能始终表现良好。 这些是关系模型可以解决的问题。

神经网络变得轻松(第十九部分):使用 MQL5 的关联规则
我们继续研究关联规则。 在前一篇文章中,我们讨论了这种类型问题的理论层面。 在本文中,我将展示利用 MQL5 实现 FP-Growth 方法。 我们还将采用真实数据测试所实现的解决方案。
在MQL5中创建动态多品种、多周期相对强弱指数(RSI)指标仪表盘
本文中,我们将在MQL5中开发一个动态多品种、多周期相对强弱指数(RSI)指标仪表盘,为交易者提供跨不同品种和时间段的实时RSI值。该仪表盘具备交互式按钮、实时更新功能和有色编码的指标,以帮助交易者做出明智的决策。


数据科学和机器学习(第 04 部分):预测当前股市崩盘
在本文中,我将尝试运用我们的逻辑模型,基于美国经济的基本面,来预测股市崩盘,我们将重点关注 NETFLIX 和苹果。利用 2019 年和 2020 年之前的股市崩盘,我们看看我们的模型在当前的厄运和低迷中会表现如何。
数据科学与机器学习 — 神经网络(第 02 部分):前馈神经网络架构设计
在我们透彻之前,还有一些涵盖前馈神经网络的次要事情,设计就是其中之一。 针对我们的输入,看看我们如何构建和设计一个灵活的神经网络、隐藏层的数量、以及每个网络的节点。

MQL5 简介(第 2 部分):浏览预定义变量、通用函数和控制流语句
通过我们的 MQL5 系列第二部分,开启一段启迪心灵的旅程。这些文章不仅是教程,还是通往魔法世界的大门,在那里,编程新手和魔法师将团结在一起。是什么让这段旅程变得如此神奇?我们的 MQL5 系列第二部分以令人耳目一新的简洁性脱颖而出,使复杂的概念变得通俗易懂。与我们互动,我们会回答您的问题,确保您获得丰富和个性化的学习体验。让我们建立一个社区,让理解 MQL5 成为每个人的冒险。欢迎来到魔法世界!

神经网络实验(第 3 部分):实际应用
在本系列文章中,我会采用实验和非标准方法来开发一个可盈利的交易系统,并检查神经网络是否对交易者有任何帮助。 若在交易中运用神经网络,MetaTrader 5 则可作为近乎自给自足的工具。




从头开始开发智能交易系统(第 16 部分):访问 web 上的数据(II)
掌握如何从网络向智能交易系统输入数据并非那么轻而易举。 如果不了解 MetaTrader 5 提供的所有可能性,就很难做到这一点。

如何将“聪明钱”概念(OB)与斐波那契指标相结合,实现最优进场策略
SMC(订单块)是机构交易者发起大规模买入或卖出的关键区域。当价格出现显著波动后,借助斐波那契数字可识别从近期波段高点至波段低点的潜在回撤,从而锁定最佳进场位。

使用 Python 的深度学习 GRU 模型到使用 EA 的 ONNX,以及 GRU 与 LSTM 模型的比较
我们将指导您完成使用 Python 进行 DL 制作 GRU ONNX 模型的整个过程,最终创建一个用于交易的专家顾问 (EA),然后将 GRU 模型与 LSTM 模型进行比较。



从头开始开发智能交易系统(第 21 部分):新订单系统 (IV)
最后,视觉系统将开始工作,尽管它尚未完工。 在此,我们将完成主要更改。 这只是它们当中很少一部份,但都是必要的。 嗯,整个工作将非常有趣。
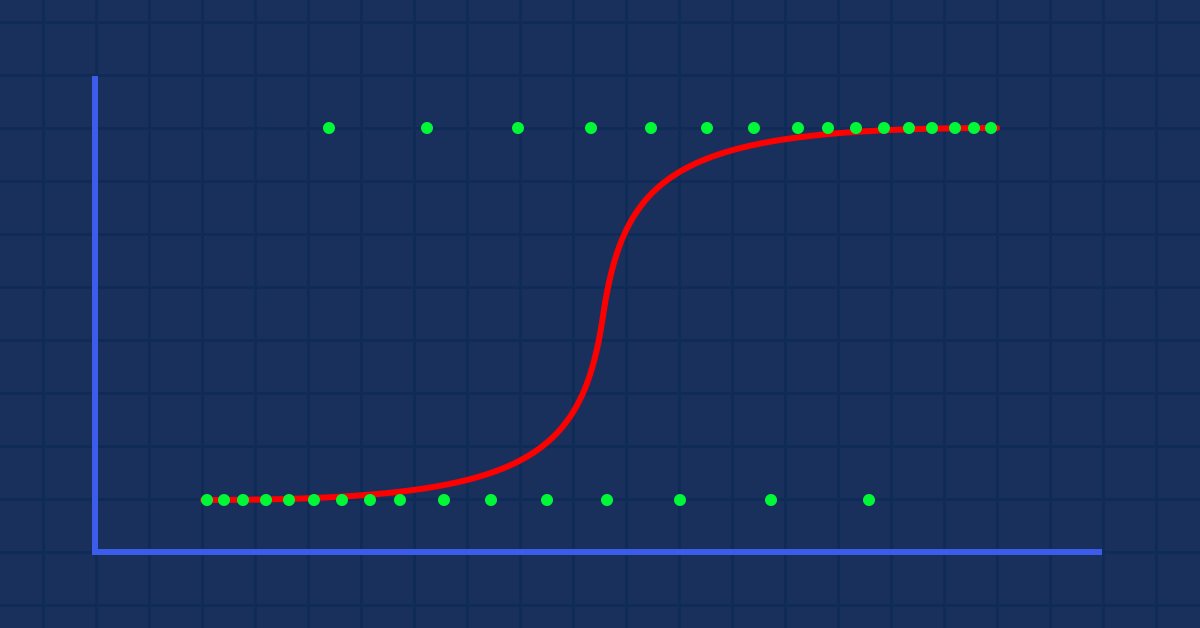
数据科学与机器学习(第 02 部分):逻辑回归
数据分类对于算法交易者和程序员来说是至关重要的。 在本文中,我们将重点关注一种分类逻辑算法,它有帮于我们识别“确定或否定”、“上行或下行”、“做多或做空”。

从头开始开发智能交易系统(第 24 部分):提供系统健壮性(I)
在本文中,我们将令系统更加可靠,来确保健壮和安全的使用。 实现所需健壮性的途径之一是尝试尽可能多地重用代码,从而能在不同情况下不断对其进行测试。 但这只是其中一种方式。 另一个是采用 OOP。

神经网络变得轻松(第四十三部分):无需奖励函数精通技能
强化学习的问题在于需要定义奖励函数。 它可能很复杂,或难以形式化。 为了定解这个问题,我们正在探索一些基于行动和基于环境的方式,无需明确的奖励函数即可学习技能。

从头开始开发智能交易系统(第 19 部分):新订单系统 (II)
在本文中,我们将开发一个“看看发生了什么”类型的图形订单系统。 请注意,我们这次不是从头开始,只不过我们将修改现有系统,在我们交易的资产图表上添加更多对象和事件。

数据科学和机器学习(第 27 部分):MetaTrader 5 中训练卷积神经网络(CNN)交易机器人 — 值得吗?
卷积神经网络(CNN)以其在检测图像和视频形态方面的出色能力而闻名,其应用涵盖众多领域。在本文中,我们探讨了 CNN 在金融市场中识别有价值形态,并为 MetaTrader 5 交易机器人生成有效交易信号的潜力。我们来发现这种深度机器学习技术如何能撬动更聪明的交易决策。
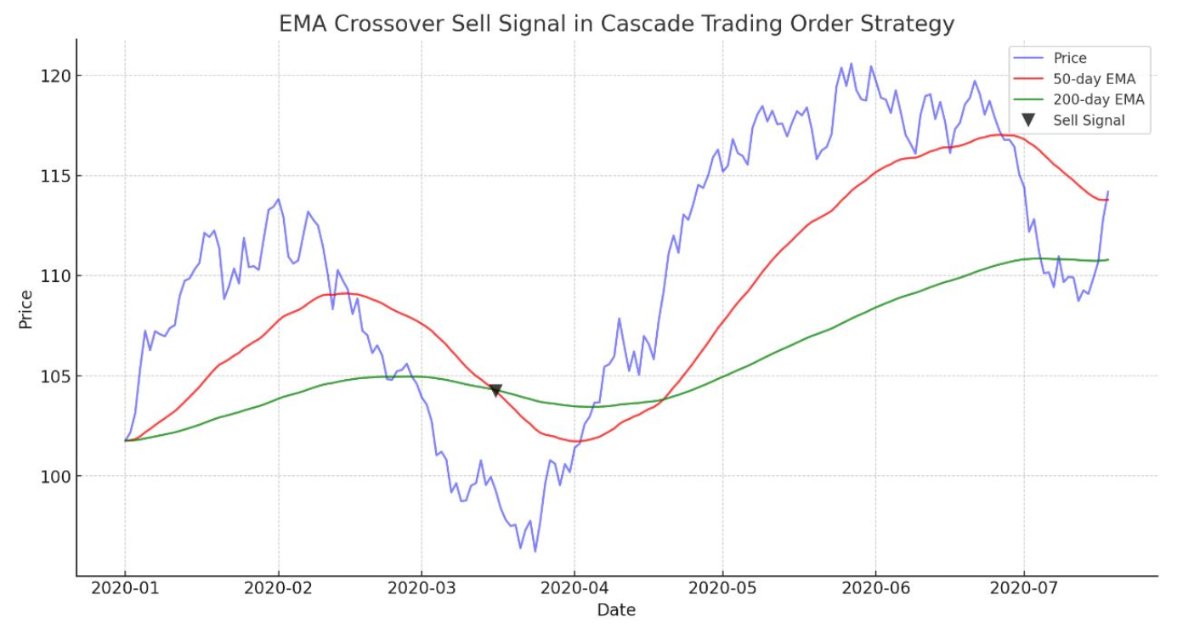
在MetaTrader 5中实现基于EMA交叉的级联订单交易策略
本文介绍一个基于EMA交叉信号的自动交易算法,该算法适用于MetaTrader 5平台。文章详细阐述了在MQL5中开发一个EA所需的方方面面,以及在MetaTrader 5中进行测试的过程——从分析价格区间行为到风险管理。
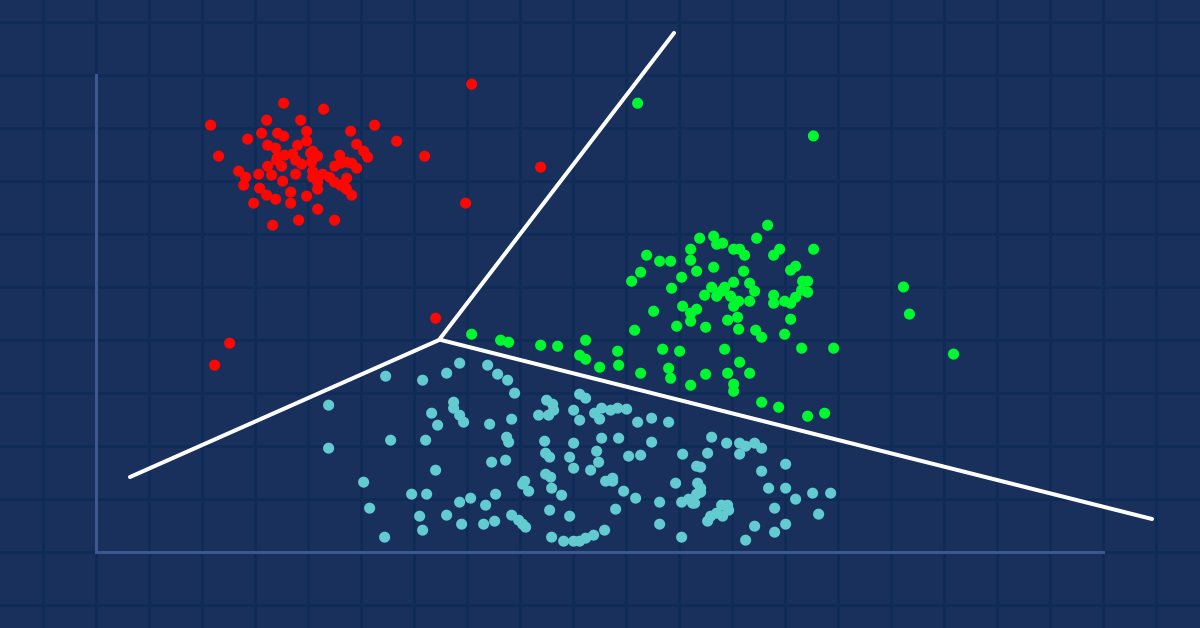
数据科学与机器学习(第 09 部分):以 MQL5 平铺直叙 K-均值聚类
数据挖掘在数据科学家和交易者看来至关重要,因为很多时候,数据并非如我们想象的那么简单。 人类的肉眼无法理解数据集中的不显眼底层形态和关系,也许 K-means 算法可以帮助我们解决这个问题。 我们来发掘一下...


将您自己的LLM集成到EA中(第2部分):环境部署示例
随着人工智能的快速发展,语言模型(LLMs)是人工智能的重要组成部分,因此我们应该思考如何将强大的语言模型集成到我们的算法交易中。对大多数人来说,很难根据他们的需求对这些强大的模型进行微调,在本地部署,然后将其应用于算法交易。本系列文章将采取循序渐进的方法来实现这一目标。

神经网络变得轻松(第十五部分):利用 MQL5 进行数据聚类
我们继续研究聚类方法。 在本文中,我们将创建一个新的 CKmeans 类来实现最常见的聚类方法之一:k-均值。 在测试期间,该模型成功地识别了大约 500 种形态。
MQL5自动化交易策略(第十一部分):开发多层级网格交易系统
在本文中,我们将使用MQL5开发一款多层级网格交易系统EA,重点探讨网格交易策略背后的架构与算法设计。我们将研究多层网格逻辑的实现方式以及应对不同市场状况的风险管理技术。最后,我们将提供详尽的解释和实用技巧,指导您完成自动化交易系统的构建、测试与优化。
DoEasy 库中的其他类(第六十七部分):图表对象类
在本文中,我将创建图表对象类(单个交易金融产品图表),并改进 MQL5 信号对象的集合类,以便在更新列表时也能为存储在集合中的每个信号对象更新其所有参数。


神经网络变得轻松(第三十九部分):Go-Explore,一种不同的探索方式
我们继续在强化学习模型中研究环境。 在本文中,我们将见识到另一种算法 — Go-Explore,它允许您在模型训练阶段有效地探索环境。