多层感知器和反向传播算法(第 3 部分):与策略测试器集成 - 概述(I)

概述
在之前的文章中,我们讨论了按照客户端-服务器连接的简化方式来构建和使用机器学习模型。 然而,这些模型仅适用于生产环境,因为测试器不支持执行网络功能。 因此,在开始这项研究时,我在 Python 脚环境中测试了模型。 还不错,但这意味着在决定是否买入或卖出特定资产,或以 Python 实现技术指标时,需要模型(或多个模型)具有判定力。 由于自定义或封闭源代码,后者并不总能适用。 当用自定义指标作为过滤器的策略,或测试具有止盈和止损、尾随停止或盈亏平衡的策略时,缺乏策略测试器参与尤为重要。 构建自己的测试器,即使是使用更易于访问的语言,如 Python,亦是相当严峻的一个挑战。
概览
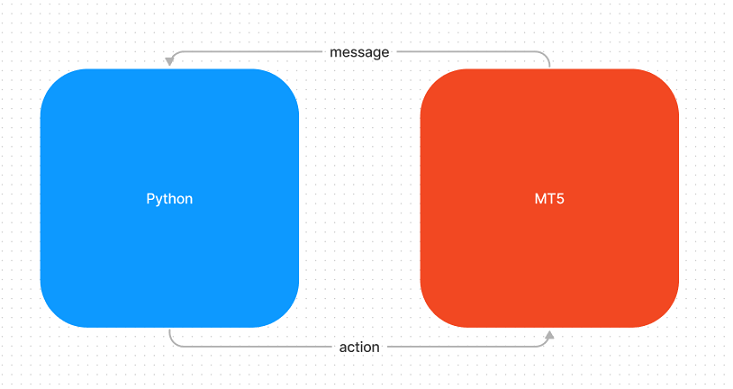
我需要一些适配回归和分类模型的东西,要求它们可在 Python 中轻松使用,如此我决定构建一个消息传递系统。 系统将在交换消息时同步工作。 Python 将代表服务器端,而 MQL5 则代表客户端。
组织开发
在尝试找到一种集成系统的途径时,我首先想到了使用 REST API,它在构建和管理方面相当简单。 然而,在查看了 WebRequest 函数的文档后,我意识到此选项不适用,因为文档明确指出它不能在此场景下使用。
"在策略测试器里 WebRequest() 不能运行"。
我发现这种对网络功能的限制相当令人沮丧,我只好继续探索其它共享信息的方法。 我考虑过使用命名管道以二进制文件形式发送消息,但于我情况而言,它仅用于实验,当时没有必要。 不过,我已经搁置了这个想法以备将来更新。
在我的深入研究中,我遇到了一些消息,给了我一个新的解决方案:
"许多开发人员面临同样的问题 — 如何在不调用不安全的 DLL 的情况下进入交易终端沙箱。
最简单、最安全的方法之一是使用标准命名管道,按照正常文件操作来工作。 它们允许您在进程间组织客户端-服务器程序之间的通信。“
思考更深入,我意识到我可以利用 CSV 文件来交换消息。 这是因为在 Python 中处理 CSV 数据不会有问题,并且处理文件的标准 MQL5 类(CFile、CFileTxt、等等)允许写入所有类型和数组的数据,但它们不包括将消息标头写入 CSV 文件的选项。 但这个限制很容易解决。
因此,我决定在 MQL5 端开发解决方案之前,先开发一个能够共享文件的架构。 进程间通信(IPC)是一组允许在进程之间传输信息的机制。
在研究了如何实现所需的控件后,我设计了要部署的体系结构。 虽然这个过程可能看起来不必要,甚至荒谬,但它对开发非常重要,因为它给出了将要做什么,以及需要首先完成哪些活动的思路。
使用 Figma,我的设计,稍后会用作文档和参考的内容。
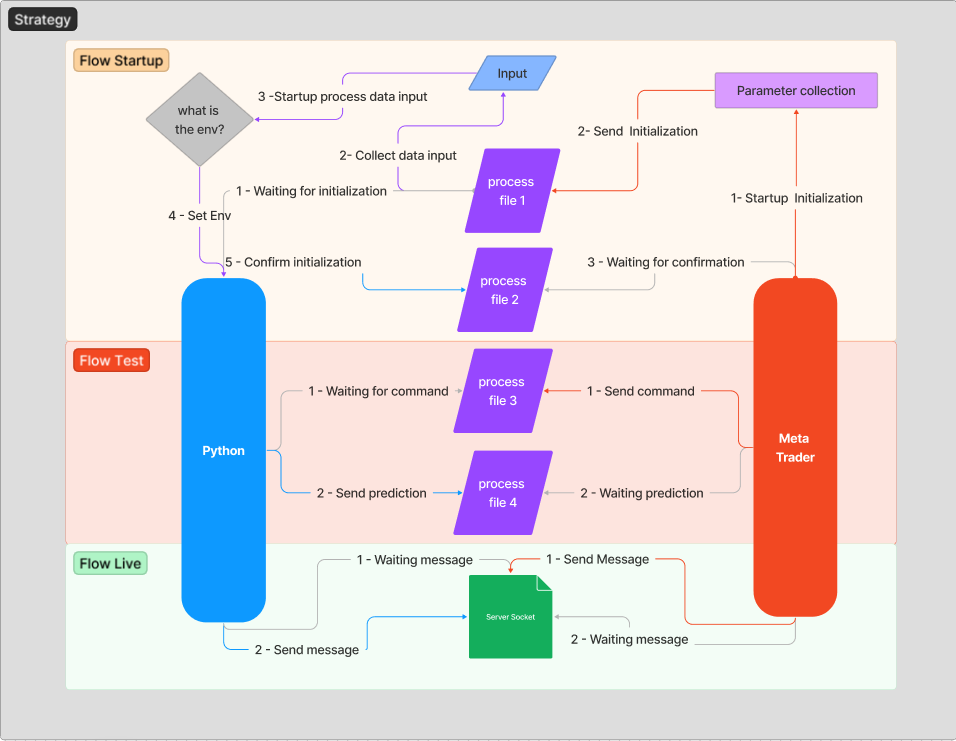
为了更好地理解前一个主题的上下文,我将针对所要建立的消息流进行解释,以便创建稳定和安全的通信。 这个思路最初不涉及一些技术问题,以便令架构更容易理解。
每当服务器(Python)初始化时,它都会等待发送初始化消息,即 "1 - Waiting for initialization" 流。 消息交换过程仅在智能系统加载到图表后开始。 MetaTrader 的任务是向 Python 发送一条消息,告知它在哪台主机、端口和环境上运行。
以下宏负责生成初始化消息标头。
#define HEADER_FILE_INIT {"host","port","typerun"} #define LINES_FILE_INT(HOST, PORT, TYPE) {{string(HOST), string(PORT), string(TYPE)}}
当我谈论环境时,我指的是 EA 运行的所在,无论是策略测试器,亦或真实账户。 如此,我们将使用 “Test” 标签作为测试环境,将 “Live” 用于实时环境。
您可以在下面看到 EA 接收 “Host” 和 “Port” 参数。
sinput group "General Configuration" sinput string InpHost = "127.0.0.1"; sinput int InpPort = 8081;
static EtypeRun typerun= (MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_VISUAL_MODE))?TEST:LIVE;
if(!monitor.OnInit(typerun, InpHost, InpPort)) return(INIT_FAILED); bool CMonitor::OnInit(EtypeRun type_run, string host, int port) { ... File.SetCommon(true); File.Open("TransferML/init.csv", FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); string header[3] = HEADER_FILE_INIT; string lines[1][3] = LINES_FILE_INT(host,port,type_run); if((File.WriteHeader(header)<1&File.WriteLine(lines)<1&!Strategy.Config(m_params))!=0) res=false; File.Close(); ... }
在上面的代码中,我们读取了 “init” 文件,并传送环境和主机数据。 步骤 "1- Startup Initialization" 和 "2- Send Initialization" 在此处执行。
下面是一段 Python 代码,它将接收初始化,处理数据,设置所要使用的环境,并向客户端确认初始化。 于此,执行步骤 "2- Collect data input","3 -Startup process data input","4 - Set Env" 和 "5 - Confirm initialization"。
host, port, typerun = file.check_init_param(PATH_COMMON.format(INIT_ARCHIVE))
file.save_file_csv(PATH_COMMON.format(INIT_OK_ARCHIVE))
完成所有这些步骤后,MetaTrader 应该等待接收服务器启动确认。 这一个步骤是 "3 - Waiting for confirmation"。
bool CMonitor::OnInit(EtypeRun type_run, string host, int port) { ... while(!File.IsExist("TransferML/init_checked.csv", FILE_COMMON)) { //waiting for startup Comment("waiting for startup"); } ... }
优点和缺点
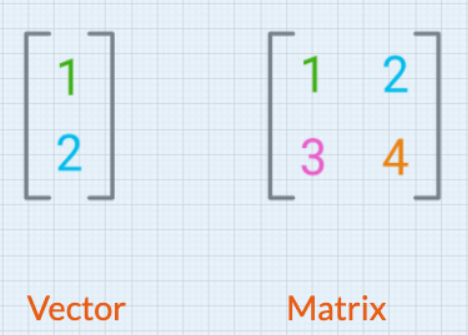
我们的通信清晰高效,因为每个阶段数据的标准化确保了系统的稳定性。 此外,在 Python 端使用 pandas 库,以及在 MQL5 端使用矩阵和向量,两者均简化了数据解析。
消息交换是问题的核心,因此我选择以 CSV 格式标准化数据发送和接收。 为了简化此任务,我开发了一个类来抽象创建字符串和标头的工作。 它在环境间数据交换时被当作基础。 接下来是带有主要方法和属性的类标头。
class CFileCSV : public CFile { private: template<typename T> string ToString(const int, const T &[][]); template<typename T> string ToString(const T &[]); short m_delimiter; public: CFileCSV(void); ~CFileCSV(void); //--- methods for working with files int Open(const string,const int, const short); template<typename T> uint WriteHeader(const T &values[]); template<typename T> uint WriteLine(const T &values[][]); string Read(void); };
如您所见,写入行和标头的方法接受动态向量和矩阵,如此就允许您在运行时构建文件,而无需使用主代码中的 “StringAdd()” 或 “StringConcatenate()” 函数连接文本。 这项工作由 “ToString” 函数完成,该函数接收向量或矩阵,并将其转换为 CSV 文格式。
例如:
假想我们有一个模型,它接收最后 4 根烛条的数值,我们参考需要传输的信息是这样的:
data;close;val_ma
10202022;10.55;10.49
10212022;10.95;11.09
10222022;11.55;11.29
10232022;11.15;11.29
此示例描绘的是存储在全局变量中的静态数据的用法。 然而,在实际系统中,将根据每个策略的需求收集这些数据,正如展示集成架构的图例所示。 重要的是要强调策略是系统的主要元素,因为它才能决定模型正常工作所需的信息。 例如,如果我们需要添加有关价格或指标的信息,这将是选项之一。 不过,请记住,修改正在发送或接收的数据格式,需要相应的代码支持。 尽管这个问题很容易解决,但规划系统开发非常重要。 如前所述,这只是一个概念验证(POC)示例,如果它看起来很有前景,将来可能会得以改进。
若要手动创建上面的示例,我们需要一个包含三个数值的数组来表示标头,以及一个包含数据的数组 [4][3]。 如您所见,编写和读取此 CSV 文件很简单。
#include "FileCSV.mqh" #define PATH(path) "Test/"+path+".csv" string H[3] = { "data", "close", "val_ma" }; string L[4][3] = {{"10202022", "10.55", "10.49"},{"10212022", "10.95", "11.09"},{"10222022", "11.55", "11.29"},{"10232022", "11.15", "11.29"}}; CFileCSV File; ulong start=0,time=0; void OnStart() { start=0; time=0; start=GetTickCount(); for(int i=0; i<100; i++) { File.Open(PATH("init"), FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); ResetLastError(); if((File.WriteHeader(H)<1&File.WriteLine(L)<1)!=0) Print("Error : ", GetLastError()); File.Close(); while(!File.IsExist(PATH("init_checked"))) { //waiting for startup Comment("waiting for startup"); } File.Delete(PATH("init")); File.Delete(PATH("init_checked")); } time=GetTickCount()-start; Print("Time send 100 archives with transfer message [ms]: ",time); }
这种方法的缺点是数据要写入磁盘,这可能会影响平均处理速度。 不过,如果比之用套接字系统的处理速度,则其性能似乎是合理的。
实现测试发送:
我们将发送 100 个包含 3 个数据列和 4 个数据行的文件,然后测量数据传输速度。
from Services import File PATH_COMMON = r'C:\Users\letha\AppData\Roaming\MetaQuotes\Terminal\B8C209507DCA35B09B2C3483BD67B706\MQL5\Files\Test\{}.csv' INIT_ARCHIVE = 'init' INIT_OK_ARCHIVE = 'init_checked' if __name__ == "__main__": file = File() file.delete_file(PATH_COMMON.format(INIT_ARCHIVE)) file.delete_file(PATH_COMMON.format(INIT_OK_ARCHIVE)) while True: receive = file.check_open_file(PATH_COMMON.format(INIT_ARCHIVE)) file.delete_file(PATH_COMMON.format(INIT_ARCHIVE)) file.save_file_csv(PATH_COMMON.format(INIT_OK_ARCHIVE)) void OnStart() { start=0; time=0; start=GetTickCount(); for(int i=0; i<100; i++) { File.Open(PATH("init"), FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); ResetLastError(); if((File.WriteHeader(H)<1&File.WriteLine(L)<1)!=0) Print("Error : ", GetLastError()); File.Close(); while(!File.IsExist(PATH("init_checked"))) { //waiting for startup Comment("waiting for startup"); } File.Delete(PATH("init")); File.Delete(PATH("init_checked")); } time=GetTickCount()-start; Print("Time send 100 archives with transfer message [ms]: ",time); }
此为结果:
testeCSV (EURUSD,M1) Time to send 100 files, transfer message [ms]: 5578
这个系统不出意外,但它有其价值,因为我们会向服务器发送少量数据。 每根新烛条开盘时会发送一次数据,如此我们无需担心。 但如果您要为流式报价、订单簿数据、或其它任何内容创建一个系统,则不建议使用这样的体系结构。 将来该系统有可能会演变成更精细的东西。
此外,该过程仅限于一个模型/策略,但可以对其进行改进,从而在未来提供更好的可扩展性。
使用线性回归:
什么是线性回归?
线性回归是一种广泛应用于金融分析的统计技术,用于预测股票、债券和货币等金融资产的行为。 这种技术允许金融分析师辨别不同变量之间的关系,从而“预测”资产的未来表现。
若要对金融资产应用线性回归,首先我们需要收集相关的历史数据。 这包括有关资产收盘价、交易量、利润和其它相关财经变量的信息。 这些数据可以从证券交易所或金融网站等来源获取。
一旦收集到数据之后,有必要选择我们将在分析中使用的因变量和自变量。 因变量是需要预测的变量,而自变量是解释因变量行为的变量。 例如,如果目标是预测股票的价格,则因变量是股票的价格,而自变量可以是交易量、利润、等等。
然后,需要应用统计技术来查找回归线的方程,该方程表示自变量和因变量之间的关系。 该方程即可用于预测资产的未来行为。
应用线性回归技术后,评估所做预测的品质非常重要。 为此,我们可以将预测结果与实际历史数据进行比较。 如果预测精度较低,则可能需要对方法或所选的自变量进行调整。
线性回归是一种广泛应用于金融分析的统计技术,用于预测股票、债券和货币等金融资产的行为。 该技术允许金融分析师辨别不同变量之间的关系,从而预测资产的未来表现。 使用 scikit-learn 库在 Python 中实现线性回归很容易,并且可以成为预测金融资产价格的宝贵工具。 不过,要记住一个重点,线性回归是一种基本技术,可能不适用于所有类型的金融资产或特定情况。 评估预测品质,并参考其它财务分析技术始终很重要。因此,您可以参考其它技术,例如基于人工智能的时间序列分析或预测模型,这些技术也可用于预测金融资产的行为。
Python 的实现:
import random import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score from sklearn.preprocessing import OneHotEncoder random.seed(42) encoder = OneHotEncoder() # Create an empty dataframe data = pd.DataFrame(columns=['ticker', 'price', 'volume', 'economic_indicator']) # Fill the dataframe with random values for i in range(500): row = { 'ticker': "FAKE3", 'price': round(random.uniform(100, 200), 2), 'volume': round(random.uniform(10000, 100000), 2), 'economic_indicator': round(random.uniform(1, 100), 2) } data = data.append(row, ignore_index=True) print(data) # apply one-hot encoding of the column "ticker" onehot_encoded = encoder.fit_transform(data[['ticker']]) # add a new one-hot encoded column to the original dataframe data['tiker_encoder'] = onehot_encoded.toarray() # Selecting independent and dependent variables X = data[['tiker_encoder', 'volume', 'economic_indicator']] y = data['price'] # Creating the linear regression model model = LinearRegression() # Training the model on historical data model.fit(X, y) # Making predictions with the trained model y_pred = model.predict(X) # Evaluating prediction quality r2 = r2_score(y, y_pred) print("Determination coefficient:", r2) # Making predictions for new data new_data = [[1, 23228.17, 61.21]] new_price_pred = model.predict(new_data) print("Price prediction for new data:", new_price_pred)
这段代码利用 scikit-learn 库根据历史价格数据、交易量和一个指标生成线性回归模型。 该模型根据历史数据进行训练,可用于预测价格。 决定系数 (R²) 也作为预测品质的度量进行计算。 此外,该模型还能依据新提供的数据进行预测。
请注意,此代码是静态的,仅作为示例。 它可以轻松应用在处理实时和动态数据,并在生产环境中使用。 此外,还需要获取市场数据和经济指标来训练模型。
需要注意的重点是,这只是预测股票价格线性回归模型的基本实现,且需要根据您的特定需求调整模型和数据。 不建议在实盘账户上使用该模型。
提供的示例仅用于论述目的,不应当作完整的实现。 完整实现的详细演示将在下一篇文章中介绍。
结束语
所提出的架构有效地克服了在测试模型时 Python 的限制,提供了多种测试选项,并有助于验证和评估 ML 模型的效率。 在下一篇文章中,我们将更深入地讨论 CFileCSV 类的实现,该类将在 MQL5 中作为数据传输的基础。
重点需要注意的是,CFileCSV 类的实现将作为 MQL5 和 Python 之间数据交换的基础,支持在两个平台上依据高级数据分析和建模功能,且作为基础组件,发挥此架构的优势。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/9875