
Python、ONNX 和 MetaTrader 5:利用 RobustScaler 和 PolynomialFeatures 数据预处理创建 RandomForest 模型

我们要基于什么开发?什么是随机森林?
随机森林方法的发展历史可以追溯到很久以前,与机器学习和统计学领域杰出科学家的工作有关。为了更好地理解这种方法的原理和应用,让我们把它想象成一大群人(决策树,decision trees)在一起工作。
随机森林法源于决策树。决策树是决策算法的图形表示,其中每个节点代表对其中一个属性的测试,每个分支是该测试的结果,叶子是预测的输出。决策树开发于 20 世纪中期,现已成为流行的分类和回归工具。
下一个重要步骤是 Leo Breiman 于 1996 年提出的套袋(bagging,Bootstrap Aggregating)概念。套袋法是指将训练数据集分割成多个自举样本(子样本),并在每个子样本上训练不同的模型。然后对模型的结果进行平均或合并,以得出更可靠、更准确的预测结果。该方法降低了模型方差,提高了模型的泛化能力。
随机森林法由 Leo Breiman 和 Adele Cutler 于 2000 年代初提出。它基于使用套袋法和额外随机性组合多个决策树的理念。每棵树都是从训练数据集的随机子样本中建立的,在建立树中的每个节点时,会随机选择一组特征。这使得每棵树都是唯一的,并减少了树之间的相关性,从而提高了泛化能力。
随机森林因其高性能以及处理分类和回归问题的能力,已迅速成为机器学习领域最流行的方法之一。在分类问题中,它用于决定一个对象属于哪一类;在回归问题中,它用于预测数值。
如今,随机森林技术已广泛应用于金融、医学、数据分析等多个领域。它因其稳健性和处理复杂机器学习问题的能力而备受赞赏。
随机森林是机器学习工具包中的一个强大工具。为了更好地理解它的工作原理,让我们把它想象成一大群人聚在一起集体决策。不过,这个小组中的每个成员都是当前情况的独立分类器或预测器,而不是真实的人。在这个群体中,人是一棵决策树,能够根据某些属性做出决策。当随机森林做出决策时,它会采用民主和投票的方式:每棵树都发表自己的意见,然后根据多张选票做出决策。
随机森林广泛应用于各个领域,其灵活性使其既适用于分类问题,也适用于回归问题。在分类任务中,模型会决定当前状态属于哪个预定义的类别。例如,在金融市场,这可能意味着根据各种指标决定买入(类别1)或卖出(类别0)某项资产。
不过,在本文中,我们将重点讨论回归问题。机器学习中的回归是根据时间序列过去的数值来预测其未来数值的一种尝试。在回归中,我们的目标是预测特定的数字,而不是将对象归入特定的类别。例如,这可以是预测股票价格、预测温度或任何其他数字变量。
创建基本随机森林模型
要创建基本的随机森林模型,我们将使用 Python 中的 sklearn(Scikit-learn)库。下面是一个用于训练随机森林回归模型的简单代码模板。运行此代码前,应使用 Python 软件包安装工具安装运行 sklearn 所需的库。
pip install onnx
pip install skl2onnx
pip install MetaTrader5
接下来,需要导入库并设置参数。我们导入了必要的库,包括用于处理数据的 "pandas"、用于从 Google Drive 加载数据的 "gdown",以及用于数据处理和创建随机森林模型的库。我们还设定了数据序列中的时间步数(n_steps),这取决于具体要求:
import pandas as pd import gdown import numpy as np import joblib import random import onnx import os import shutil from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score from sklearn.utils import shuffle from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler, MinMaxScaler, PolynomialFeatures, PowerTransformer import MetaTrader5 as mt5 from datetime import datetime # Set the number of time steps according to requirements n_steps = 100
下一步,我们将加载和处理数据。在我们的具体示例中,我们从 MetaTrader 5 加载价格数据并进行处理。我们设置时间指数,并只选择收盘价(这就是我们要处理的内容):
下面是代码的一部分,负责将我们的数据分成训练集和测试集,并标记用于模型训练的数据集。我们将数据分为训练集和测试集。然后,我们为回归标记数据,这意味着每个标签都代表未来的实际价格值。Labelling_relabeling_regression 函数用于创建标记数据。mt5.initialize() SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_H1 START_DATE = datetime(2000, 1, 1) STOP_DATE = datetime(2023, 1, 1) # Set the number of time steps according to your requirements n_steps = 100 # Process data data = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START_DATE, STOP_DATE), columns=['time', 'close']).set_index('time') data.index = pd.to_datetime(data.index, unit='s') data = data.dropna() data = data[['close']] # Work only with close prices
# Define train_data_initial training_size = int(len(data) * 0.70) train_data_initial = data.iloc[:training_size] test_data_initial = data.iloc[training_size:] # Function for creating and assigning labels for regression (changes made for regression, not classification) def labelling_relabeling_regression(dataset, min_value=1, max_value=1): future_prices = [] for i in range(dataset.shape[0] - max_value): rand = random.randint(min_value, max_value) future_pr = dataset['<CLOSE>'].iloc[i + rand] future_prices.append(future_pr) dataset = dataset.iloc[:len(future_prices)].copy() dataset['future_price'] = future_prices return dataset # Apply the labelling_relabeling_regression function to raw data to get labeled data train_data_labeled = labelling_relabeling_regression(train_data_initial) test_data_labeled = labelling_relabeling_regression(test_data_initial)
接下来,我们从某些序列中创建训练数据集。重要的是,该模型将我们序列中的所有收盘价格作为特征。序列大小与 ONNX 模型输入数据的大小相同。此阶段不进行归范化处理;归范化处理将在训练管道中进行,作为模型管道操作的一部分。
# Create datasets of features and target variables for training x_train = np.array([train_data_labeled['<CLOSE>'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(train_data_labeled))]) y_train = train_data_labeled['future_price'].iloc[n_steps:].values # Create datasets of features and target variables for testing x_test = np.array([test_data_labeled['<CLOSE>'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(test_data_labeled))]) y_test = test_data_labeled['future_price'].iloc[n_steps:].values # After creating x_train and x_test, define n_features as follows: n_features = x_train.shape[1] # Now use n_features to determine the ONNX input data type initial_type = [('float_input', FloatTensorType([None, n_features]))]
创建数据预处理管道
下一步是创建随机森林模型,该模型应作为一个管道来构建。
scikit-learn(sklearn)库中的管道(Pipeline)是一种为数据分析和机器学习创建连续转换链和模型的方法。管道可将多个数据处理和建模阶段合并为一个对象,以用于高效、有序地操作数据。
在我们的代码示例中,我们创建了以下管道:
# Create a pipeline with MinMaxScaler, RobustScaler, PolynomialFeatures and RandomForestRegressor
pipeline = Pipeline([
('MinMaxScaler', MinMaxScaler()),
('robust', RobustScaler()),
('poly', PolynomialFeatures()),
('rf', RandomForestRegressor(
n_estimators=20,
max_depth=20,
min_samples_split=5000,
min_samples_leaf=5000,
random_state=1,
verbose=2
))
])
# Train the pipeline
pipeline.fit(x_train, y_train)
# Make predictions
predictions = pipeline.predict(x_test)
# Evaluate model using R2
r2 = r2_score(y_test, predictions)
print(f'R2 score: {r2}')
如您所见,管道是将一系列数据处理和建模步骤组合成的一个链条。在本代码中,管道是使用 scikit-learn 库创建的。它包括以下步骤:
-
MinMaxScaler 将数据缩放至 0 至 1 的范围。这有助于确保所有特性的比例相等。
-
RobustScaler 也能进行数据缩放,对数据集中的异常值更具鲁棒性。它使用中位数和四分位数间距进行缩放。
-
PolynomialFeatures 对特征进行多项式变换。这增加了多项式特征,有助于模型解释数据中的非线性关系。
-
RandomForestRegressor 用一组超参数定义了一个随机森林模型:
- n_estimators(森林中树木的数量)。假设你有一群专家,每个人都擅长预测金融市场的价格。随机森林中树的数量(n_estimators)决定了你的小组中有多少这样的专家。树越多,模型做出决策时就会考虑到更多不同的意见和预测。
- max_depth(每棵树的最大深度)。该参数设置了每位专家(树)"深入" 数据分析的程度。例如,如果将最大深度设置为 20,那么每棵树将根据不超过 20 个特征或特性做出决策。
- min_samples_split(分割树节点的最小样本数)。该参数告诉您树节点中有多少样本(观测值)时,树就会继续将其划分为更小的节点。例如,如果将最小分割样本数设置为 5000,那么只有当每个节点的观测值超过 5000 时,树才会分割节点。
- min_samples_leaf(树叶节点中样本的最小数量)。该参数决定了树的叶子节点中必须有多少个样本,该节点才会成为叶子节点,而不会进一步分割。例如,如果将叶节点中的最小样本数设置为 5000,那么树的每片叶子将至少包含 5000 个观测值。
- random_state(设置随机生成的初始状态,确保结果可以重现)。该参数用于控制模型内的随机过程。如果将其设置为一个固定值(例如 1),则每次运行模型的结果都将相同。这对结果的可重复性很有帮助。
- verbose(启用输出有关模型训练过程的信息)。在训练模型时,查看有关过程的信息可能非常有用。通过 "verbose" 参数可以控制信息的详细程度。数值越大(例如 2),训练过程中输出的信息就越多。
创建管道后,我们使用 "fit" 方法在训练数据上对其进行训练。然后,我们使用 "predict" 方法对测试数据进行预测。最后,我们使用 R2 指标来评估模型的质量,该指标衡量模型与数据的拟合程度。
该管道经过训练,然后根据 R2 指标进行评估。我们采用归范化方法,去除数据中的异常值,并创建多项式特征。这些都是最简单的数据预处理方法。在今后的文章中,我们将介绍如何使用函数变换器(Function Transformer)创建自己的预处理函数。
将模型导出到 ONNX,编写导出函数
管道训练完毕后,我们将其保存为 joblib 格式,然后使用 skl2onnx 库将其保存为 ONNX 格式。
# Save the pipeline
joblib.dump(pipeline, 'rf_pipeline.joblib')
# Convert pipeline to ONNX
onnx_model = convert_sklearn(pipeline, initial_types=initial_type)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Connect Google Drive (if you work in Colab and this is necessary)
from google.colab import drive
drive.mount('/content/drive')
# Specify the path to Google Drive where you want to move the model
drive_path = '/content/drive/My Drive/' # Make sure the path is correct
rf_pipeline_onnx_drive_path = os.path.join(drive_path, 'rf_pipeline.onnx')
# Move ONNX model to Google Drive
shutil.move(model_onnx_path, rf_pipeline_onnx_drive_path)
print('The rf_pipeline model is saved in the ONNX format on Google Drive:', rf_pipeline_onnx_drive_path)
我们就是这样训练模型并将其保存在 ONNX 中的。这就是我们在完成训练后将看到的景象:
模型以 ONNX 格式保存在 Google Drive 的基本目录中。ONNX 可以看作是机器学习模型的一种 "软盘"。通过这种格式,您可以保存训练好的模型,并将其转换到各种应用程序中使用。这类似于将文件保存到闪存盘,然后可以在其他设备上读取。在我们的案例中,ONNX 模型将在 MetaTrader 5 环境中用于预测金融市场价格。ONNX "软盘" 本身可通过第三方应用程序读取,例如 MetaTrader 5。这就是我们现在要做的。
在 MetaTrader 5 测试器中检查模型
我们之前在 Google Drive 上保存了 ONNX 模型。现在,让我们从那里下载。要在 MetaTrader 5 中使用该模型,让我们创建一个 EA 交易,读取并应用该模型做出交易决策。在显示的 EA 交易代码中,设置交易参数,如手交易量、止损单的使用、止盈和止损水平。以下是将 "读取" 我们的 ONNX 模型的 EA 代码:
//+------------------------------------------------------------------+ //| ONNX Random Forest.mq5 | //| Copyright 2023 | //| Evgeniy Koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com" #property version "0.90" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Lot volume to open a position input bool InpUseStops = true; // Trade with stop orders input int InpTakeProfit = 500; // Take Profit level input int InpStopLoss = 500; // Stop Loss level #resource "Python/rf_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 100 long ExtHandle=INVALID_HANDLE; int ExtPredictedClass=-1; datetime ExtNextBar=0; datetime ExtNextDay=0; CTrade ExtTrade; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Function for closing all positions void CloseAll(int type=-1) { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetInteger(POSITION_TYPE)==type || type==-1) { trade.PositionClose(PositionGetTicket(i)); } } } } // Expert Advisor initialization int OnInit() { if(_Symbol!="EURUSD" || _Period!=PERIOD_H1) { Print("The model should work with EURUSD, H1"); return(INIT_FAILED); } ExtHandle=OnnxCreateFromBuffer(ExtModel,ONNX_DEFAULT); if(ExtHandle==INVALID_HANDLE) { Print("Error creating model OnnxCreateFromBuffer ",GetLastError()); return(INIT_FAILED); } const long input_shape[] = {1,100}; if(!OnnxSetInputShape(ExtHandle,ONNX_DEFAULT,input_shape)) { Print("Error setting the input shape OnnxSetInputShape ",GetLastError()); return(INIT_FAILED); } const long output_shape[] = {1,1}; if(!OnnxSetOutputShape(ExtHandle,0,output_shape)) { Print("Error setting the output shape OnnxSetOutputShape ",GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if(ExtHandle!=INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle=INVALID_HANDLE; } } // Process the tick function void OnTick() { if(TimeCurrent()<ExtNextBar) return; ExtNextBar=TimeCurrent(); ExtNextBar-=ExtNextBar%PeriodSeconds(); ExtNextBar+=PeriodSeconds(); PredictPrice(); if(ExtPredictedClass>=0) if(PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Check position opening conditions void CheckForOpen(void) { ENUM_ORDER_TYPE signal=WRONG_VALUE; if(ExtPredictedClass==PRICE_DOWN) signal=ORDER_TYPE_SELL; else { if(ExtPredictedClass==PRICE_UP) signal=ORDER_TYPE_BUY; } if(signal!=WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price,sl=0,tp=0; double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); if(signal==ORDER_TYPE_SELL) { price=bid; if(InpUseStops) { sl=NormalizeDouble(bid+InpStopLoss*_Point,_Digits); tp=NormalizeDouble(ask-InpTakeProfit*_Point,_Digits); } } else { price=ask; if(InpUseStops) { sl=NormalizeDouble(ask-InpStopLoss*_Point,_Digits); tp=NormalizeDouble(bid+InpTakeProfit*_Point,_Digits); } } ExtTrade.PositionOpen(_Symbol,signal,InpLots,price,sl,tp); } } // Check position closing conditions void CheckForClose(void) { if(InpUseStops) return; bool tsignal=false; long type=PositionGetInteger(POSITION_TYPE); if(type==POSITION_TYPE_BUY && ExtPredictedClass==PRICE_DOWN) tsignal=true; if(type==POSITION_TYPE_SELL && ExtPredictedClass==PRICE_UP) tsignal=true; if(tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { ExtTrade.PositionClose(_Symbol,3); CheckForOpen(); } } // Function to get the current spread double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Function to predict prices void PredictPrice() { static vectorf output_data(1); static vectorf x_norm(SAMPLE_SIZE); double spread = GetSpreadInPips(_Symbol); if (!x_norm.CopyRates(_Symbol, _Period, COPY_RATES_CLOSE, 1, SAMPLE_SIZE)) { ExtPredictedClass = -1; return; } if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, x_norm, output_data)) { ExtPredictedClass = -1; return; } float predicted = output_data[0]; if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } }
请注意以下输入参数维度:
const long input_shape[] = {1,100};
必须与 Python 模型中的维度相匹配:
# Set the number of time steps to your requirements n_steps = 100
接下来,我们开始在 MetaTrader 5 环境中测试该模型。我们利用模型的预测来确定价格变动的方向。如果模型预测价格会上涨,我们就准备建立多头头寸(买入);反之,如果模型预测价格会下跌,我们就准备建立空头头寸(卖出)。让我们测试一下这个模型,使用参数为,止盈 1000,止损 500:
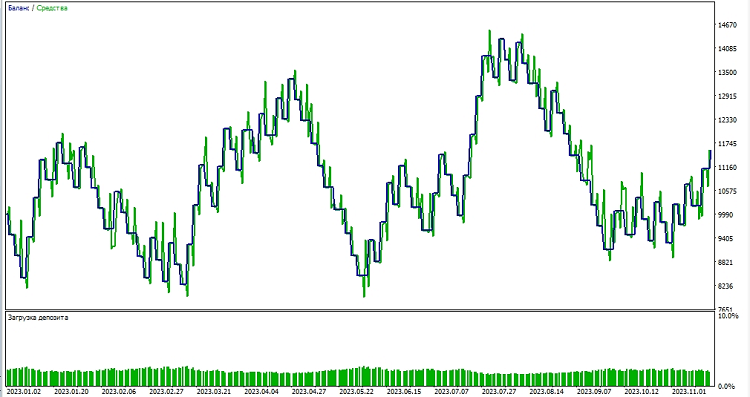
结论
在本文中,我们讨论了如何在 Python 中创建和训练随机森林模型,如何直接在模型中预处理数据,以及如何将其导出到 ONNX 标准,然后在 MetaTrader 5 中打开和使用模型。
ONNX 是一个出色的模型导入导出系统,它既通用又简单。在 ONNX 中保存模型其实比看上去要简单得多。数据预处理也非常简单。
当然,我们的模型只有 20 棵决策树,非常简单,而且随机森林模型本身已经是一个相当古老的解决方案了。在后续的文章中,我们将使用更复杂的数据预处理创建更复杂、更现代的模型。我还想指出,在预处理的同时,可以立即以 sklearn 管道的形式创建一组模型。这可以显著扩展我们的能力,包括分类问题的能力。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/13725
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 开发具有 RestAPI 集成的 MQL5 强化学习代理(第 2 部分):用于与井字游戏 RestAPI 进行 HTTP 交互的 MQL5 函数
开发具有 RestAPI 集成的 MQL5 强化学习代理(第 2 部分):用于与井字游戏 RestAPI 进行 HTTP 交互的 MQL5 函数
只是选择了森林作为一个简单的例子)在下一篇文章中,我将对其进行一些调整。)
好)
如果能进一步探讨传送带及其转换为 ONNX 并随后在 metatrader 中使用的问题,那将会非常有趣。例如,是否有可能在管道中添加自定义转换,以及从这样的管道中获得的 ONNX 模型能否在 Metatrader 中打开?我认为,这个问题值得写几篇文章。
如果能进一步探讨传送带及其转换为 ONNX 并随后在 metatrader 中使用的问题,那将会非常有趣。例如,是否有可能在管道中添加自定义转换,以及从这样的管道中获得的 ONNX 模型能否在 Metatrader 中打开?我认为,这个问题值得写几篇文章。