多層パーセプトロンとバックプロパゲーションアルゴリズム(その3):ストラテジーテスターとの統合 - 概要(I)

はじめに
これまでの記事では、クライアントサーバー接続を使った簡略化された方法で、機械学習モデルの構築と使用について説明しました。しかし、テスターはネットワーク機能を実行しないため、これらのモデルは本番環境でしか機能しません。したがって、この研究を始めるにあたって、Python環境でモデルをテストしました。これはそれほど悪いことではありませんが、特定の資産を買うか売るかを決定するときや、Pythonでテクニカル指標を実装するときに、モデルを決定論的にすることを意味します。後者は、カスタムコードや非公開ソースコードのため、必ずしも適用できるとは限りません。ストラテジーテスターがないことは、カスタム指標をフィルターとして利用するストラテジーを使用する場合や、テイクプロフィットやストップロス、トレーリングストップやブレイクイーブンを使用するストラテジーをテストする場合に特に重要です。Pythonのようなアクセスしやすい言語であっても、独自のテスターを作るのはかなり難しいことです。
概要
回帰モデルや分類モデルに適応でき、Pythonで簡単に使えるものが必要だったので、メッセージングシステムを構築することにしました。システムはメッセージのやり取りをしながら同期的に動作します。Pythonがサーバーサイドを表し、MQL5がクライアントサイドを表します。
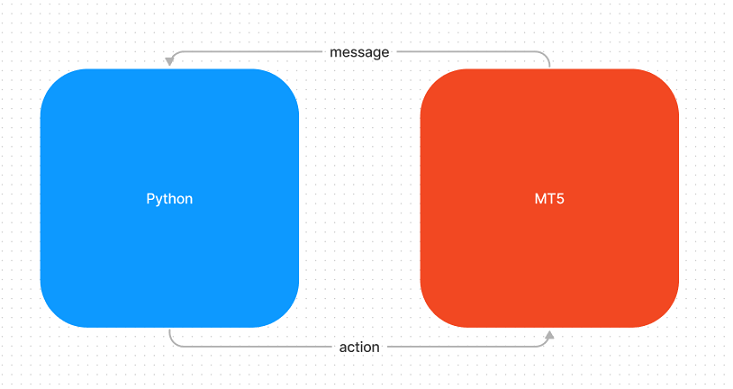
開発の組織化
システムを統合する方法を模索する中で、まず構築も管理も簡単なREST APIを使うことを考えましたが、WebRequest関数のドキュメントを見直したところこのオプションは使えないと明記されていたため、適用できないことに気づきました。
「WebRequest()はストラテジーテスターでは実行できません。
このネットワーク機能の制限にかなり不満を感じましたが、情報を共有する他の方法を模索し続けました。バイナリーファイルでメッセージを送るために名前付きパイプを使うことも考えましたが、私の場合、それは実験のためだけのもので、その時点では必要ありませんでした。ただし、このアイデアは将来のアップデートのために棚上げにしました。
さらに調査を進めると、新たな解決策を与えてくれるメッセージに出くわしました。
「多くの開発者が、安全でないDLLを使用せずに、取引端末のサンドボックスにアクセスする方法という同じ問題に直面しています。
最も簡単で安全な方法の1つは、通常のファイル操作と同じように機能する標準的な名前付きパイプを使うことです。プログラム間のプロセス間クライアントサーバー通信を組織化することができます。」
さらに考えてみると、CSVファイルを使ってメッセージのやり取りを活用できることに気づきました。PythonではCSVデータの処理に問題はないだろうし、ファイルを扱うMQL5の標準クラス(CFile、CFileTxtなど)では、あらゆる型や配列のデータを書き込むことができるが、CSVファイルにヘッダーを書き込むオプションは含まれていないからです。しかし、この制限は簡単に解決できます。
そこで、MQL5側のソリューションを開発する前に、ファイルを共有できるアーキテクチャを開発することにしました。プロセス間通信(Inter-Process-Communication、IPC)は、プロセス間で情報を転送するためのメカニズム群です。
必要なコントロールをどのように実装するかを考えた後、私は展開するためのアーキテクチャを設計しました。このプロセスは不要に思えるかもしれないし、ばかばかしいとさえ思えるかもしれませんが、開発にとって非常に重要なことです。
Figmaを使って、後にドキュメントやリファレンスとして使うものをデザインしました。
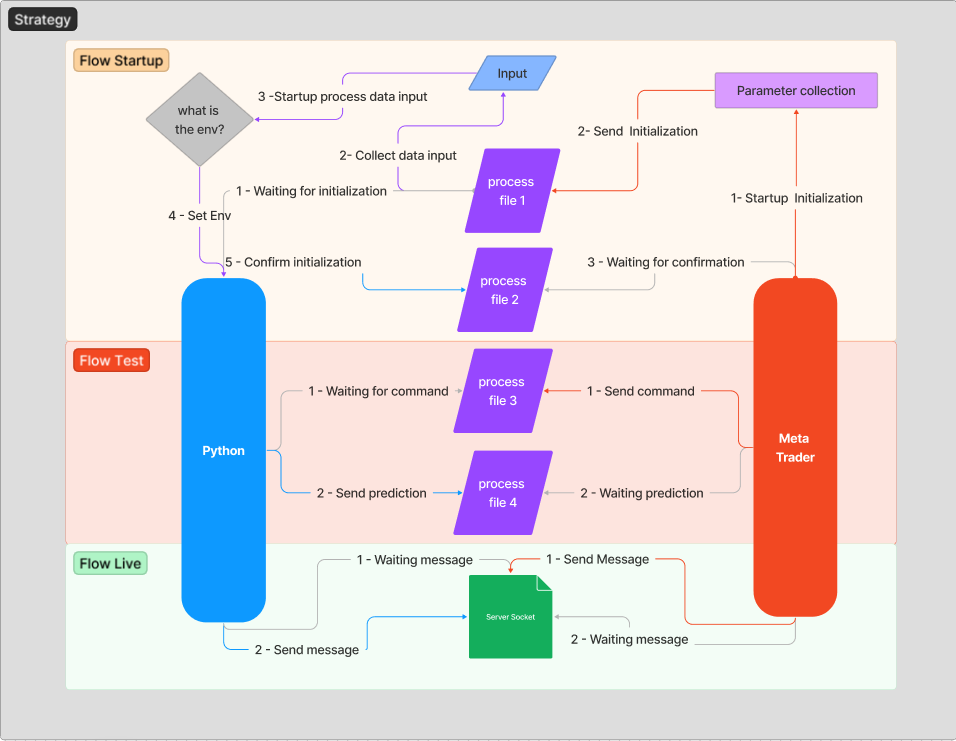
前回のトピックの背景をよりよく理解するために、安定したセキュアなコミュニケーションを実現するために確立するメッセージフローについて説明を残しておきましょう。アーキテクチャを理解しやすくするために、最初は技術的な問題には立ち入らないことです。
サーバー(Python)が初期化されるたびに、初期化メッセージが送信されるのを待ちます。これは、「1 - Waiting for initialization」というフローです。メッセージのやり取りは、EAがチャートに接続された後に開始されます。MetaTraderのタスクは、Pythonにどのホスト、ポート、環境で動作しているかというメッセージを送信することです。
以下のマクロは、初期化メッセージヘッダーの生成を担当します。
#define HEADER_FILE_INIT {"host","port","typerun"} #define LINES_FILE_INT(HOST, PORT, TYPE) {{string(HOST), string(PORT), string(TYPE)}}
環境というのは、EAが稼働している場所、つまりストラテジーテスターかライブ口座のことです。そこで、テスト環境には「Test」を、ライブ環境には「Live」を使うことにします。
EAが「Host」パラメーターと「Port」パラメーターを受信しているのがわかるでしょう。
sinput group "General Configuration" sinput string InpHost = "127.0.0.1"; sinput int InpPort = 8081;
static EtypeRun typerun= (MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_VISUAL_MODE))?TEST:LIVE;
if(!monitor.OnInit(typerun, InpHost, InpPort)) return(INIT_FAILED); bool CMonitor::OnInit(EtypeRun type_run, string host, int port) { ... File.SetCommon(true); File.Open("TransferML/init.csv", FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); string header[3] = HEADER_FILE_INIT; string lines[1][3] = LINES_FILE_INT(host,port,type_run); if((File.WriteHeader(header)<1&File.WriteLine(lines)<1&!Strategy.Config(m_params))!=0) res=false; File.Close(); ... }
上のコードでは、「init」ファイルを読み込み、環境とホストのデータを渡しています。ここでは「1-起動初期化」と「2-送信初期化」をおこないます。
以下は、初期化を受け取り、データを処理し、使用する環境を設定し、クライアントに初期化を確認するPythonコードです。ここでは、「2-データ入力の収集」、「3-プロセスデータ入力の起動」、「4-Envの設定」、「5-初期化の確認」をおこないます。
host, port, typerun = file.check_init_param(PATH_COMMON.format(INIT_ARCHIVE))
file.save_file_csv(PATH_COMMON.format(INIT_OK_ARCHIVE))
これらの手順がすべて完了したら、MetaTraderはサーバー起動確認を受信するのを待っているはずです。このステップは「3-確認待ち」です。
bool CMonitor::OnInit(EtypeRun type_run, string host, int port) { ... while(!File.IsExist("TransferML/init_checked.csv", FILE_COMMON)) { //waiting for startup Comment("waiting for startup"); } ... }
長所と短所
各段階でデータを標準化することにより、システムの安定性が確保されるため、コミュニケーションは明確かつ効率的です。さらに、Python側ではpandasライブラリを使用し、MQL5側では行列とベクトルを使用することで、データ理解が簡素化されています。
メッセージのやり取りが問題の核心なので、データの送受信をCSV形式で標準化することにしました。この作業を単純化するために、私は文字列とヘッダーの作成作業を抽象化するクラスを開発しました。環境間のデータ交換の基礎として使われます。次に、主要なメソッドと属性を含むクラスヘッダーです。
class CFileCSV : public CFile { private: template<typename T> string ToString(const int, const T &[][]); template<typename T> string ToString(const T &[]); short m_delimiter; public: CFileCSV(void); ~CFileCSV(void); //--- methods for working with files int Open(const string,const int, const short); template<typename T> uint WriteHeader(const T &values[]); template<typename T> uint WriteLine(const T &values[][]); string Read(void); };
ご覧のように、行やヘッダーを書き込むメソッドは動的なベクトルや行列を受け付けるので、メインコードで StringAdd()やStringConcatenate()関数を使用してテキストを連結しなくても、実行時にファイルを構築することができます。この作業は、ベクトルや行列を受け取ってCSV形式に変換する「ToString」関数によっておこなわれます。
次は例です。
直近4本のローソク足の値を受信するモデルがあり、送信する必要があると考えられる情報は次のようなものだとします。
data;close;val_ma
10202022;10.55;10.49
10212022;10.95;11.09
10222022;11.55;11.29
10232022;11.15;11.29
この例では、グローバル変数に格納された静的データの使い方を説明します。しかし実際のシステムでは、統合アーキテクチャを示す画像に見られるように、このデータは各戦略のニーズに従って収集されます。戦略がシステムの主要な要素であることを強調することが重要です。なぜなら、モデルが正しく機能するために必要な情報を決定するからです。例えば、価格や指標に関する情報を追加する必要がある場合、これはオプションのひとつとなるでしょう。ただし、送受信されるデータのフォーマットを変更するには、適切なコードサポートが必要であることに留意してください。この問題は簡単に解決できますが、システム開発の計画を立てることが重要です。前述したように、これはあくまで概念実証(POC)の例であり、有望と思われれば将来的に改良される可能性もあります。
上記の例を手動で作成するには、ヘッダーを表す3つの値を持つ配列と、データを含む配列[4][3]が必要です。ご覧の通り、このCSVファイルの書き出しと読み出しは簡単です。
#include "FileCSV.mqh" #define PATH(path) "Test/"+path+".csv" string H[3] = { "data", "close", "val_ma" }; string L[4][3] = {{"10202022", "10.55", "10.49"},{"10212022", "10.95", "11.09"},{"10222022", "11.55", "11.29"},{"10232022", "11.15", "11.29"}}; CFileCSV File; ulong start=0,time=0; void OnStart() { start=0; time=0; start=GetTickCount(); for(int i=0; i<100; i++) { File.Open(PATH("init"), FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); ResetLastError(); if((File.WriteHeader(H)<1&File.WriteLine(L)<1)!=0) Print("Error : ", GetLastError()); File.Close(); while(!File.IsExist(PATH("init_checked"))) { //waiting for startup Comment("waiting for startup"); } File.Delete(PATH("init")); File.Delete(PATH("init_checked")); } time=GetTickCount()-start; Print("Time send 100 archives with transfer message [ms]: ",time); }
この方法の欠点は、データがディスクに書き込まれることで、平均処理速度に影響を与える可能性があります。しかし、ソケットを使用するシステムの処理速度と比較すれば、性能は妥当と思われます。
テスト送信の実施
3つのデータ列と4つのデータ行を含む100個のファイルを送信し、データ転送速度を測定します。
from Services import File PATH_COMMON = r'C:\Users\letha\AppData\Roaming\MetaQuotes\Terminal\B8C209507DCA35B09B2C3483BD67B706\MQL5\Files\Test\{}.csv' INIT_ARCHIVE = 'init' INIT_OK_ARCHIVE = 'init_checked' if __name__ == "__main__": file = File() file.delete_file(PATH_COMMON.format(INIT_ARCHIVE)) file.delete_file(PATH_COMMON.format(INIT_OK_ARCHIVE)) while True: receive = file.check_open_file(PATH_COMMON.format(INIT_ARCHIVE)) file.delete_file(PATH_COMMON.format(INIT_ARCHIVE)) file.save_file_csv(PATH_COMMON.format(INIT_OK_ARCHIVE)) void OnStart() { start=0; time=0; start=GetTickCount(); for(int i=0; i<100; i++) { File.Open(PATH("init"), FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); ResetLastError(); if((File.WriteHeader(H)<1&File.WriteLine(L)<1)!=0) Print("Error : ", GetLastError()); File.Close(); while(!File.IsExist(PATH("init_checked"))) { //waiting for startup Comment("waiting for startup"); } File.Delete(PATH("init")); File.Delete(PATH("init_checked")); } time=GetTickCount()-start; Print("Time send 100 archives with transfer message [ms]: ",time); }
以下が結果です。
testeCSV (EURUSD,M1) Time to send 100 files, transfer message [ms]:5578
このシステムは特別なものではないですが、少量のデータをサーバーに送信するため、その価値はあります。また、データは新しいローソク足が開くたびに一度だけ送信されるので、その点については心配する必要はありません。しかし、気配値やオーダーブックのデータなどをストリーミングするシステムを作るのであれば、このアーキテクチャはお勧めできません。将来的には、このシステムをより精巧なものに進化させる可能性もあります。
また、このプロセスは1つのモデル/ストラテジーに限定されているが、将来的にはより優れたスケーラビリティを提供できるよう改善できるでしょう。
線形回帰を使用します。
線形回帰とは何でしょうか。
線形回帰は、株式、債券、通貨などの金融資産の挙動を予測するために、金融分析で広く使用されている統計手法です。この手法により、金融アナリストは異なる変数間の関係を特定し、資産の将来のパフォーマンスを「予測」することができます。
金融資産に線形回帰を使うには、まず関連する過去のデータを収集する必要があります。これには、資産の終値、取引量、利益、その他関連する経済変数に関する情報が含まれます。このデータは、証券取引所や金融関連のWebサイトなどから入手できます。
データを収集したら、分析に使用する従属変数と独立変数を選択する必要があります。従属変数は予測されるべきものであり、独立変数は従属変数の行動を説明するために使用されるものです。例えば、株価を予測することが目的であれば、従属変数は株価となり、独立変数は取引量や利益等となります。
そして、独立変数と従属変数の関係を表す回帰直線の方程式を求める統計的手法を適用する必要があります。この方程式は、資産の将来の挙動を予測するために使用されます。
線形回帰法を適用した後は、予測結果の質を評価することが重要です。そのためには、予測結果を実際の過去のデータと比較すればいいのです。予測精度が低い場合は、方法論や独立変数の選択を調整する必要があるかもしれません。
線形回帰は、株式、債券、通貨などの金融資産の挙動を予測するために、金融分析で広く使用されている統計手法です。この手法により、金融アナリストは異なる変数間の関係を特定し、資産の将来のパフォーマンスを予測することができます。Pythonでの線形回帰は、scikit-learnライブラリを使って簡単に実装でき、金融資産価格を予測するための貴重なツールとなります。ただし、線形回帰は基本的な手法であり、すべての種類の金融資産や特定の状況に適切であるとは限らないことを覚えておくことが重要です。予測の質を評価し、他の財務分析手法を検討することは常に重要です。そこで、時系列分析や人工知能に基づく予測モデルなど、金融資産の行動を予測するために使用できる他の手法を検討することもできます。
Pythonでの実装
import random import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score from sklearn.preprocessing import OneHotEncoder random.seed(42) encoder = OneHotEncoder() # Create an empty dataframe data = pd.DataFrame(columns=['ticker', 'price', 'volume', 'economic_indicator']) # Fill the dataframe with random values for i in range(500): row = { 'ticker': "FAKE3", 'price': round(random.uniform(100, 200), 2), 'volume': round(random.uniform(10000, 100000), 2), 'economic_indicator': round(random.uniform(1, 100), 2) } data = data.append(row, ignore_index=True) print(data) # apply one-hot encoding of the column "ticker" onehot_encoded = encoder.fit_transform(data[['ticker']]) # add a new one-hot encoded column to the original dataframe data['tiker_encoder'] = onehot_encoded.toarray() # Selecting independent and dependent variables X = data[['tiker_encoder', 'volume', 'economic_indicator']] y = data['price'] # Creating the linear regression model model = LinearRegression() # Training the model on historical data model.fit(X, y) # Making predictions with the trained model y_pred = model.predict(X) # Evaluating prediction quality r2 = r2_score(y, y_pred) print("Determination coefficient:", r2) # Making predictions for new data new_data = [[1, 23228.17, 61.21]] new_price_pred = model.predict(new_data) print("Price prediction for new data:", new_price_pred)
このコードでは、scikit-learn ライブラリを使用して、過去の価格データ、取引量、および1つの指標に基づいて線形回帰モデルを生成します。モデルは過去のデータで学習され、価格の予測に使用されます。決定係数(R²)も予測品質の尺度として計算されます。さらに、新たに提供されたデータを使って予測をおこなうためにも、このモデルが使われます。
このコードは静的なものであり、あくまでも例として役立つものであることにご注意ください。ライブでダイナミックなデータを扱うことができ、本番環境で使用することも容易です。さらに、モデルを訓練するために、市場データと経済指標を入手する必要があります。
これは株価を予測するために使用される線形回帰モデルの基本的な実装に過ぎず、特定のニーズに応じてモデルやデータを調整する必要があるかもしれないことに注意することが重要です。ライブ口座でのモデルの使用は推奨されません。
提供された例は説明のためのものであり、完全な実装とみなされるべきではありません。完全な実装の詳細なデモンストレーションは、次回の記事で紹介します。
結論
提案されたアーキテクチャは、Pythonモデルをテストする際の制約を克服し、多様なテストオプションを提供し、MLモデルの効率性を検証評価する上で効果的でした。次回は、MQL5で使用されるデータ転送の基礎となるCFileCSVクラスの実装について詳しく説明します。
CFileCSVクラスの実装は、MQL5とPython間のデータ交換の基礎となり、両プラットフォーム上で高度なデータ分析やモデリング機能を使用することを可能にし、このアーキテクチャを最大限に活用するための基本的なコンポーネントとなることに留意することが重要です。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/9875
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索