将 ML 模型与策略测试器集成(第 3 部分):CSV(II)文件管理

概述
在本文中,我们将重点介绍策略测试器与 Python 集成的第三部分。 我们将看到 CFileCSV 类的创建,其可用于有效管理 CSV 文件。 我们将查验一些示例和代码,从而读者能更好地理解如何在实践中实现该类。
那么,什么是 CSV?
CSV(逗号分隔值)是一种简单且广泛使用的文件格式,用于存储和交换数据。 它类似于表格中的每一行表示一组数据,而每列表示该数据中的一个字段。 值由定界符分隔,以便能够跨不同工具和编程语言读取和写入。
CSV 格式出现在 1970 年代初期,首先用在大型机系统。 CSV 无法追溯到特定的创建者,因为它是一种广泛使用的文件类型。
它通常用于在各种应用程序中导入和导出数据,例如电子表格、数据库、数据分析程序、等等。 它的流行程度是由于其易用性和易理解性,以及与许多系统和工具的兼容性。 当我们需要在不同应用程序之间共享数据时,例如将信息从一个系统传输到另一个系统时,这尤其实用。
故此,使用 CSV 的主要优点是易用性和兼容性。 然而,它亦有一些限制,例如缺乏对复杂数据类型的支持,以及处理大量数据的能力降低。 此外,缺少 CSV 格式的通用标准会导致不同应用程序之间的兼容性问题。 此外,您可能会意外丢失或修改数据,因为该格式并未提供验证。 通常,CSV 是存储和共享数据的通用且易于使用的选项。 尽管如此,重要的是要知晓并充分了解其局限性,并采取措施确保数据准确性。
动机
创建 CFileCSV 类是出于将 MetaTrader 5 策略测试器环境与 Python 集成的需求。 在运用机器学习(ML)模型开发交易策略时,我在 Python 中创建模型时遇到了困难。 我要么先用 MQL5 创建一个机器学习库,这超出了我的主要目标;要么彻底用 Python 创建一个智能系统。
尽管 MQL5 语言提供了创建 ML 库的资源,但我不想花时间和精力开发它们,因为我的主要目标是以快速有效的方式分析数据和构建模型。
故此,任务是找到一个中间解决方案。 我想利用 Python 构建 ML 模型的优势,但也希望能够将它们直接应用于我的 MQL5 操作。 故此,我开始寻找一种方法来克服这种限制,并找到集成这两个环境的解决方案。
这个思路是创建一个消息传递系统,让 MetaTrader 5 和 Python 可以及时相互沟通。 这将允许您控制从 MetaTrader 5 到 Python 的数据初始化和传输,以及从 Python 到 MetaTrader 5 的预测发送。 CFileCSV 类设计用于高效的数据存储和加载,从而促进这种交互。
CFileCSV 类概述
CFileCSV 是一个操控 CSV(逗号分隔值)文件的类。 该类派生自 CFile。 故此,它提供了操控 CSV 文件的特定功能。 该类的目的是能够更轻松地处理不同类型的数据,令 CSV 文件更易于读取和写入。
使用 CSV 文件的一大好处是这种类型的文件易于共享,并且提供了一种便捷的导入/导出数据的方法。 这些文件可以在 Excel 或 Google 表格等程序中轻松打开和编辑,并且可供各种编程语言读取。 甚而,由于它们没有特定的格式,因此可以根据不同的需求进行读写。
CFileCSV 类有四个主要的公开方法:Open、WriteHeader、WriteLine 和 Read。 此外,它还有两个私密辅助方法,可将数组或矩阵转换为字符串,并将这些数值写入文件。
class CFileCSV : public CFile { private: template<typename T> string ToString(const int, const T &[][]); template<typename T> string ToString(const T &[]); short m_delimiter; public: CFileCSV(void); ~CFileCSV(void); //--- methods for working with files int Open(const string,const int, const short); template<typename T> uint WriteHeader(const T &values[]); template<typename T> uint WriteLine(const T &values[][]); string Read(void); };
使用此类时,请记住,它设计用于操控特定的 CSV 文件。 如果文件中的数据格式不正确,则结果可能会出乎意外。 非常重要的事项,在尝试写入文件之前,确保文件已打开,并且具有写入权限。
作为使用 CFileCSV 类的示例,我们可以依据数据矩阵创建一个 CSV 文件。 首先,我们将创建一个类的实例,并使用 Open 方法打开文件。 在此方法中,我们指定文件名和 Open 标志。 接下来,我们使用 WriteHeader 方法将标头写入文件,并使用 WriteLine 方法从矩阵写入数据行。 我们用一个示例函数来描绘这些步骤:
#include "FileCSV.mqh" void CreateCSVFile(string fileName, string &headers[], string &data[][]) { // Creates an object of the CFileCSV class CFileCSV csvFile; // Checks if the file can be opened for writing in the ANSI format if(csvFile.Open(fileName, FILE_WRITE|FILE_ANSI)) { int rows = ArrayRange(data, 0); int cols = ArrayRange(data, 1); int headerSize = ArraySize(headers); //Checks if the number of columns in the data matrix is equal to the number if elements in the header array and if the number of rows in the data matrix is greater than zero if(cols != headerSize || rows == 0) { Print("Error: Invalid number of columns or rows. Data array must have the same number of columns as the headers array and at least one row."); return; } // Writes header to file csvFile.WriteHeader(headers); // Writes data rows to file csvFile.WriteLine(data); // Closes the file csvFile.Close(); } else { // Shows an error message if the file cannot be opened Print("Error opening file!"); } }
该方法的目的是依据标头数组和数据数组创建 CSV 文件。 我们从创建 CFileCSV 类的对象开始。 然后,检查是否可以打开文件,并以 ANSI 格式写入。 如果文件可以打开,请确保数据矩阵中的列数等于标题矩阵中的元素数,并且数据矩阵中的行数大于零。 如果满足这些条件,该方法将调用 WriteHeader() 方法将标头写入文件,然后调用 WriteLine() 方法写入数据行。 最后,该方法关闭文件。 如果无法打开该文件,则会显示一条错误消息。
稍后将通过示例演示此方法。 请注意,它的实现可以扩展到执行其它任务。 例如,您可以添加更多验证:在尝试打开文件之前检查文件是否存在,或者添加一个选项来选择要使用的分隔符。
CFileCSV 类提供了一种简单实用的方法来操控 CSV 文件,令数据读取和写入 CSV 文件变得容易。 不过,使用它时应小心:应确保文件采用预期格式,并检查方法返回以确保它们已成功执行。
实现
如上所述,CFileCSV 类有四个主要的公开方法:Open、WriteHeader、WriteLine 和 Read。 它还有两个方法名称重载的私密辅助方法:ToString。
-
方法 Open(const string file_name,const int open_flags, const short delimiter=';') 用于打开 CSV 文件。 该方法接收以下参数:文件名、打开标志(例如,FILE_WRITE 或 FILE_READ)、和要在文件中使用的分隔符(默认值为 ';')。 它调用宏大 CFile 类的 Open 方法,并将指定的分隔符保存在私密变量之中。 它还返回一个整数,指示操作成功或失败。
int CFileCSV::Open(const string file_name,const int open_flags, const short delimiter=';') { m_delimiter=delimiter; return(CFile::Open(file_name,open_flags|FILE_CSV|delimiter)); }
- 方法 WriteHeader(const T &values[]) 将标头写入打开的 CSV 文件。 它接收一个数组参数,其中包含表示文件标头列数值。 它使用 ToString 方法将数组转换为字符串,并调用 CFile 基类的 FileWrite 方法将此字符串写入文件。 它还返回一个整数,指示文件中写入的字节数。
template<typename T> uint CFileCSV::WriteHeader(const T &values[]) { string header=ToString(values); //--- check handle if(m_handle!=INVALID_HANDLE) return(::FileWrite(m_handle,header)); //--- failure return(0); }
-
WriteLine(const T &values[][]) 方法将数据行写入打开的 CSV 文件。 在参数中,此方法接收表示文件中数据行的数值矩阵。 它循环访问矩阵的每一行,调用 ToString 方法将每一行转换为字符串,并将这些字符串连接成单条字符串。 然后,它调用 CFile 基类的 FileWrite 方法将此字符串写入文件。 它还返回一个整数,指示文件中写入的字节数。
template<typename T> uint CFileCSV::WriteLine(const T &values[][]) { int len=ArrayRange(values, 0); if(len<1) return 0; string lines=""; for(int i=0; i<len; i++) if(i<len-1) lines += ToString(i, values) + "\n"; else lines += ToString(i, values); if(m_handle!=INVALID_HANDLE) return(::FileWrite(m_handle, lines)); return 0; }
-
Read(void) 方法从已打开的 CSV 文件里读取内容。 它调用 CFile 基类的 FileReadString 方法逐行读取文件内容,并将其保存在一条字符串当中。 返回包含文件内容的字符串。
string CFileCSV::Read(void) { string res=""; if(m_handle!=INVALID_HANDLE) res = FileReadString(m_handle); return res;
ToString 方法是 CFileCSV 类的私密辅助方法,用于将矩阵或数组转换为字符串,并将这些值写入文件。
-
方法 ToString(const int row, const T &values[][]) 将矩阵转换为字符串。 它接收要转换的字符串,和矩阵本身作为参数。 该方法循环访问矩阵行的每个元素,将其附加到生成的字符串当中。 分隔符将添加到每个元素的末尾,但行中的最后一个元素除外。
template<typename T> string CFileCSV::ToString(const int row, const T &values[][]) { string res=""; int cols=ArrayRange(values, 1); for(int x=0; x<cols; x++) if(x<cols-1) res+=values[row][x] + ShortToString(m_delimiter); else res+=values[row][x]; return res; }
-
方法 ToString(const T &values[]) 将数组转换为字符串。 它遍历数组的每个元素,并将其附加到生成的字符串当中。 定界符附加到每个元素的末尾,数组中的最后一个元素除外。
template<typename T> string CFileCSV::ToString(const T &values[]) { string res=""; int len=ArraySize(values); if(len<1) return res; for(int i=0; i<len; i++) if(i<len-1) res+=values[i] + ShortToString(m_delimiter); else res+=values[i]; return res; }
WriteHeader 和 WriteLine 使用这些方法将作为参数传递的值转换为字符串,并将这些字符串写入打开的文件。 它们会确保数值按预期格式写入文件,并由指定的定界符分隔。 它们是确保数据按有组织的形式正确写入 CSV 文件的基础。
此外,这些方法为 CFileCSV 类提供了更大的灵活性,令它能够处理不同类型的数据,因为它们是作为模板实现的。 这意味着这些方法可以应用到任何能转换为字符串的数据类型,包括整数、浮点数、字符串、等等。 这令 CFileCSV 类应用广泛,且易于使用。
这些方法主要用于确保数值按正确的格式写入文件。 它们在每个元素的末尾都包含一个定界符,但行或矩阵中的最后一个元素除外。 这可确保正确分隔 CSV 文件中的数值,这对于以后读取和解释存储在文件中的数据非常重要。
调用 ToString(const int row, const T &values[][]) 的示例:
int data[2][3] = {{1, 2, 3}, {4, 5, 6}}; string str = csvFile.ToString(1, data); //str -> "4;5;6"
在此示例中,我们将数据矩阵的第二行传递给 ToString 方法。 该方法循环访问字符串中的每个元素,将其追加到生成的字符串,并在除最后一个元素之外,字符串的每个元素的末尾插入分隔符。 成果字符串将为 '4;5;6'。
使用 ToString(const T &values[]) 的示例:
string headers[] = {"Name", "Age", "Gender"}; string str = csvFile.ToString(headers); //str -> "Name;Age;Gender"
在此示例中,'headers' 数组传递给 ToString 方法。 该方法循环访问数组的每个元素,将其追加到结果字符串,并在除数组的最后一个元素之外的每个元素的末尾插入分隔符。 成果字符串将是 'Name;Age;Gender'。
这些只是调用 ToString 方法的示例。 它们可以应用于任何可以转换为字符串的数据类型。 不过,请注意,它们仅在 CFileCSV 类中可用,因为它们被声明为私密。
算法复杂性
我们如何衡量算法的复杂性,并利用这些信息来优化算法和系统的性能?
Big O 注释符是分析算法的重要工具,自从计算机科学早期以来就已得到认可。 Big O 概念在 1960 年代正式定义,但今天仍然广泛使用。 它允许程序员根据算法的输入,以及执行算法所需的操作来粗略估计算法的复杂性。 使用此工具,可以比较不同的算法和这些定义,其为特定任务提供更好的性能。
数据量和问题的复杂性呈指数级增长,这才是必须要解决的。 这就是为什么 Big O 注释符如此重要的原因。 虽然每天都会生成越来越多的数据,但我们需要更有效的算法来处理这些数据。
Big O 概念基于这样一种思想,即对于算法,执行时间根据某个数学函数(通常是多项式)增长。 该函数表示为 Big O 注释符,可以表示为 O(f(n)),其中 f(n) 代表算法的复杂度。
现在来我们看几个使用 Big O 注释符的示例:
- O(1), 这是一种恒定时间算法,即它不会根据数据的大小而变化。
- O(n), 表示线性时间算法,其中执行时间与数据大小成比例增加。
- O(n^2), 对应于二次时间算法,其中执行时间随着数据大小的平方而增长。
- O(log n), 表示对数时间算法,执行时间随着数据大小对数的函数而增长。
Big O 将有助于判定选择哪种算法来解决您的特定问题,并优化系统的性能。
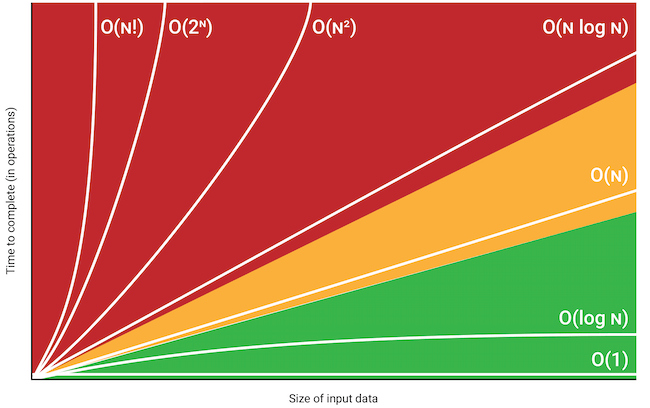
CFileCSV 类当中每个方法的时间复杂度因作为参数提供的数据的大小而异。
- Open 方法具有 O(1) 的复杂性,因为它只执行一个操作来打开文件,故与数据大小无关。
- Read 方法的复杂性为 O(n),其中 n 是文件的大小。 它读取文件的全部内容,并将其保存在字符串之中。
- WriteHeader 方法具有 O(n) 复杂性,其中 n 是作为参数提供的数组的大小。 它将数组转换为字符串,并将其写入文件。
- WriteLine 方法的复杂度为 O(mn),其中 m 是矩阵中的行数,n 是每行中的元素数量。 它循环访问每一行,将其转换为字符串,然后再将其写入文件。
请注意,这些复杂度是估计值,因为它们可能受到其它因素的影响,例如文件写入缓冲区的大小、文件系统、等等。 甚至,Big O 注释符估计到了最坏的情况。 如果向方法提供的数据太多,复杂性可能会增加。
通常,CFileCSV 类具有可接受的时间复杂度,并且对于处理不太大的文件非常有效。 不过,如果您需要处理非常庞大的文件,则可能需要采用其它方法,或优化类来处理特定的用例。
用法示例
//+------------------------------------------------------------------+ //| exemplo_2.mq5 | //| Copyright 2022, Lethan Corp. | //| https://www.mql5.com/pt/users/14134597 | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Lethan Corp." #property link "https://www.mql5.com/pt/users/14134597" #property version "1.00" #include "FileCSV.mqh" CFileCSV csvFile; string fileName = "dados.csv"; string headers[] = {"Timestamp", "Close", "Last"}; string data[1][3]; //The OnInit function int OnStart(void) { //Fill the 'data' array with values timestamp, Bid, Ask, Indicador1 and Indicador2 data[0][0] = TimeToString(TimeCurrent()); data[0][1] = DoubleToString(iClose(Symbol(), PERIOD_CURRENT, 0), 2); data[0][2] = DoubleToString(SymbolInfoDouble(Symbol(), SYMBOL_LAST), 2); //Open the CSV file if(csvFile.Open(fileName, FILE_WRITE|FILE_ANSI)) { //Write the header csvFile.WriteHeader(headers); //Write data rows csvFile.WriteLine(data); //Close the file csvFile.Close(); } else { Print("File opening error!"); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+
此代码是 MQL5 中 CFileCSV 类的实现。 它涵盖以下功能:
- 在无法打开文件的情况下提供错误处理。
- 允许打开指定名称及相应写入权限的 CSV 文件。
- 允许将标头写入文件,定义为字符串数组。
- 提供将数据写入文件,参数定义为字符串数组。
- 写入完成后关闭文件。
结束语
CFileCSV 类为处理 CSV 文件提供了一种实用且有效的方式。 它包括用于打开、写入标头和字符串、以及读取 CSV 文件的方法。 Open、WriteHeader、WriteLine 和 Read 方法可确保对 CSV 文件进行正确操作,确保按可读的方式写入和组织数据。 感谢您花时间阅读! 在下一篇文章中,我们将介绍如何使用本文中介绍的 CFileCSV 类,并通过文件共享来使用 ML 模型。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/12069