Perceptron Multicamadas e o Algoritmo Backpropagation (Parte 3): Integrando ao Testador de estratégias - Visão Geral (I)

Introdução
Nos últimos artigos, discutimos como construir e usar modelos de aprendizado de máquina facilmente usando uma conexão entre um cliente e servidor. No entanto, esses modelos só funcionam em ambientes "produtivos", pois o testador não executa funções de rede. Por isso, sempre que iniciei esse estudo, fiz validações dos modelos dentro do ambiente Python, o que não é ruim, mas implica tornar o modelo ou os modelos determinísticos na decisão de comprar ou vender um determinado ativo, ou na implementação de indicadores técnicos no Python, alguns nem sempre podendo ser usados, uma vez que é um código personalizado e fechado, por exemplo. Certo, mas e se quiser usar uma estratégia que envolva alguns indicadores personalizados como filtro, ou se quer apenas testar sua estratégia usando take e stop, ou trailling stop, break even, veja que faz muita falta um testador, e construir um próprio, mesmo que em linguagens mais amigáveis como Python, é uma tarefa árdua.
Visão Geral
Precisava de algo que fosse adaptativo para os modelos de regressão e classificação que podem ser usados facilmente no lado do Python, por isso optei em construir um sistema de troca de mensagens. O sistema irá trabalhar de forma síncrona (bloqueante) na troca de mensagens, onde o Python representa o lado do servidor e o MQL5 o lado do cliente.
Organizando o Desenvolvimento
Eu estava procurando por maneiras de realizar a integração entre os sistemas, e inicialmente pensei em utilizar uma API REST devido à sua simplicidade de construção e gerenciamento. No entanto, ao revisar a documentação da função WebRequest, percebi que essa opção não seria viável, pois a documentação menciona explicitamente que não é possível.
"O WebRequest() não pode ser executada no Testador de Estratégia."
A descoberta da limitação das funções de rede foi um "balde de água fria" em meus planos, mas eu continuei buscando novas formas de fazer essas trocas de informação. Em um primeiro momento, pensei em usar um named pipe para transferir mensagens em arquivos binários, mas, no meu caso, era apenas para algumas experimentações e não seria necessário naquele momento. Entretanto, guardei essa ideia em meu backlog para futuras atualizações.
Ao continuar minhas pesquisas, encontrei alguns textos que me deram uma nova ideia de como resolver esse problema.
"Muitos desenvolvedores encontram o mesmo problema - como chegar ao sandbox do terminal sem utilizar DLLs arriscados.
Um dos métodos mais fáceis e seguros é utilizar pipes nomeados padrão que funcionam como operações de arquivo normais. Eles permitem que você organize a comunicação cliente-servidor interprocessadores entre programas."
Ao pensar de forma mais específica, percebi que poderia aproveitar as trocas de mensagens usando arquivos CSV. Isso porque, do lado do Python, não haveria preocupação com o tratamento de dados do CSV e, as classes padrões do MQL5 que trabalham com arquivos (CFile, CFileTxt, etc) permitem a gravação de dados de todos os tipos e arrays, mas não incluem a opção de gravar o cabeçalho de um arquivo CSV. No entanto, essa limitação seria fácil de resolver.
Diante disso, decidi desenhar uma arquitetura que fizesse essa troca de arquivo antes de desenvolver a solução no lado do MQL5. A comunicação entre processos, ou "Inter-Process-Communication (IPC)" em inglês, é o grupo de mecanismos que permite aos processos transferir informações entre si.
Depois de pensar em como faria isso e nos controles necessários, desenhei a arquitetura que iria implantar. Embora esse processo possa parecer desnecessário ou até mesmo tolo, é muito importante para o desenvolvimento, pois dá um panorama geral do que será feito e das atividades que serão necessárias fazer primeiro.
Com a ajuda da ferramenta Figma, desenhei o que usaria posteriormente como documentação e referência.
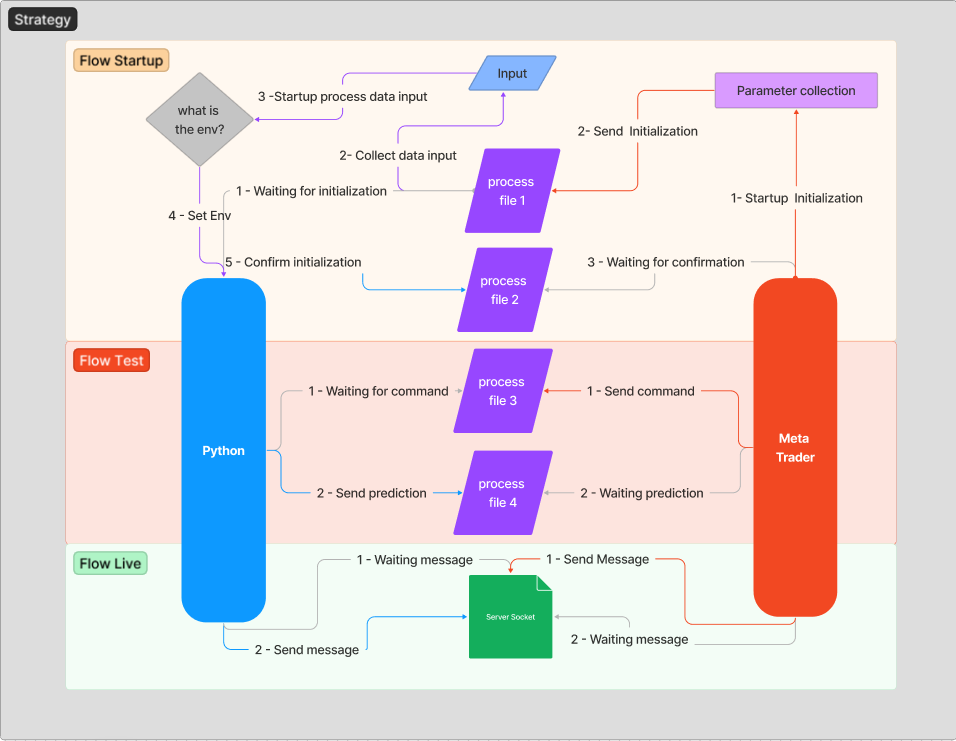
Para contextualizar melhor o fluxo acima, vou deixar uma explicação sobre o fluxo de mensagens que estabeleceremos para gerar uma comunicação estável e segura. A ideia é não entrar tecnicamente em alguns assuntos inicialmente, para facilitar a compreensão da arquitetura que será utilizada.
Sempre que o servidor (Python) for inicializado, ele aguardará o envio de uma mensagem de inicialização, como pode ser visto no fluxo "1 - Waiting for initialization". Somente após anexar o EA ao gráfico, o processo de troca de mensagens começará. O MetaTrader tem a tarefa de enviar ao Python qual é o host, porta e ambiente que está sendo executado.
As macros a seguir são responsáveis por construir o cabeçalho da mensagem de inicialização.
#define HEADER_FILE_INIT {"host","port","typerun"} #define LINES_FILE_INT(HOST, PORT, TYPE) {{string(HOST), string(PORT), string(TYPE)}}
Quando falo de ambiente, me refiro ao local onde o EA está sendo executado, seja no testador de estratégias ou em uma conta ao vivo. Denominaremos o ambiente de teste como "Test" e o ambiente ao vivo como "Live".
Você pode ver abaixo que o EA recebe os parâmetros "Host" e "Port".
sinput group "General Configuration" sinput string InpHost = "127.0.0.1"; sinput int InpPort = 8081;
static EtypeRun typerun= (MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_VISUAL_MODE))?TEST:LIVE;
if(!monitor.OnInit(typerun, InpHost, InpPort)) return(INIT_FAILED);
bool CMonitor::OnInit(EtypeRun type_run, string host, int port) { ... File.SetCommon(true); File.Open("TransferML/init.csv", FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); string header[3] = HEADER_FILE_INIT; string lines[1][3] = LINES_FILE_INT(host,port,type_run); if((File.WriteHeader(header)<1&File.WriteLine(lines)<1&!Strategy.Config(m_params))!=0) res=false; File.Close(); ... }
No trecho acima, realizamos a leitura do arquivo "init" e passamos os dados de ambiente e host. Os passos "1- Startup Initialization" e "2- Send Initialization" são realizados nessa etapa.
Abaixo, vemos o trecho em Python que irá receber a inicialização, processar os dados, definir o ambiente a ser usado e confirmar a inicialização para o cliente. Os passos "2- Collect data input", "3 -Startup process data input", "4 - Set Env" e "5 - Confirm initialization" são realizados nesta etapa.
host, port, typerun = file.check_init_param(PATH_COMMON.format(INIT_ARCHIVE))
file.save_file_csv(PATH_COMMON.format(INIT_OK_ARCHIVE))
Após todos esses passos, o MetaTrader deve estar aguardando para receber uma confirmação de inicialização do Servidor. Este passo é denominado "3 - Waiting for confirmation".
bool CMonitor::OnInit(EtypeRun type_run, string host, int port) { ... while(!File.IsExist("TransferML/init_checked.csv", FILE_COMMON)) { //waiting for startup Comment("waiting for startup"); } ... }
Pros e Contras
Nossa comunicação é clara e eficiente, pois, com a padronização dos dados em cada etapa, garantimos estabilidade no sistema. Além disso, a compreensão dos dados é simplificada tanto no lado Python, utilizando a biblioteca pandas, quanto no lado Mql5, utilizando matrizes e vetores.
A troca de mensagens é o ponto central do problema, por isso, escolhi padronizar o envio e recebimento no formato CSV. Para facilitar essa tarefa, desenvolvi uma classe que abstrai o esforço de criação de linhas e cabeçalhos, sendo usada como base na troca de dados entre os ambientes. A seguir, está o cabeçalho da classe, mostrando os principais métodos e atributos.
class CFileCSV : public CFile { private: template<typename T> string ToString(const int, const T &[][]); template<typename T> string ToString(const T &[]); short m_delimiter; public: CFileCSV(void); ~CFileCSV(void); //--- methods for working with files int Open(const string,const int, const short); template<typename T> uint WriteHeader(const T &values[]); template<typename T> uint WriteLine(const T &values[][]); string Read(void); };
É possível observar que os métodos de gravação de linhas e cabeçalhos aceitam vetores e matrizes dinâmicas, dando a possibilidade de construir o arquivo em tempo de execução, sem precisar de concatenações de texto usando as funções "StringAdd()" ou "StringConcatenate()" no código principal. Esse trabalho é realizado pelas funções "ToString" que recebem um vetor ou matriz e os convertem em texto compatível com o formato CSV.
Exemplo:
Imagine que temos um modelo que recebe o valor dos últimos 4 candles, e as informações que foram julgadas necessárias a serem transmitidas fosse algo como:
data;close;val_ma
10202022;10.55;10.49
10212022;10.95;11.09
10222022;11.55;11.29
10232022;11.15;11.29
Este exemplo ilustra a utilização de dados estáticos armazenados em variáveis globais, no entanto, em um sistema real, esses dados seriam coletados de acordo com as necessidades de cada estratégia, como pode ser visto na imagem que mostra a arquitetura de integração. É importante destacar que a estratégia é o elemento principal do sistema, pois ela determina quais informações são necessárias para o funcionamento do modelo. Por exemplo, se é preciso adicionar informações de preço ou indicadores, essa seria uma possibilidade. No entanto, é importante lembrar que, se houver mudanças no formato dos dados enviados ou recebidos, será necessário realizar manutenção no código. Embora essa seja uma questão fácil de contornar, é importante planejar o desenvolvimento do sistema. Como mencionado anteriormente, este é apenas um exemplo de prova de conceito (POC) e, se for algo promissor, pode ser melhorado no futuro.
Para criar manualmente o exemplo acima, precisamos de um array com três valores que representarão o cabeçalho e uma matriz [4][3] que conterá os dados. Como é possível ver, a gravação e leitura desse arquivo CSV são simples.
#include "FileCSV.mqh" #define PATH(path) "Test/"+path+".csv" string H[3] = { "data", "close", "val_ma" }; string L[4][3] = {{"10202022", "10.55", "10.49"},{"10212022", "10.95", "11.09"},{"10222022", "11.55", "11.29"},{"10232022", "11.15", "11.29"}}; CFileCSV File; ulong start=0,time=0; void OnStart() { start=0; time=0; start=GetTickCount(); for(int i=0; i<100; i++) { File.Open(PATH("init"), FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); ResetLastError(); if((File.WriteHeader(H)<1&File.WriteLine(L)<1)!=0) Print("Error : ", GetLastError()); File.Close(); while(!File.IsExist(PATH("init_checked"))) { //waiting for startup Comment("waiting for startup"); } File.Delete(PATH("init")); File.Delete(PATH("init_checked")); } time=GetTickCount()-start; Print("Time send 100 archives with transfer message [ms]: ",time); }
Um aspecto negativo desta abordagem é que a gravação dos dados ocorre no disco, o que pode resultar em velocidade de processamento mediana. No entanto, se comparado com a velocidade de processamento do sistema utilizando sockets, pode-se notar um desempenho razoável.
Fazendo um teste de envio:
Iremos mandar 100 arquivos contendo 3 colunas e 4 linhas de dados e vamos medir a velocidade em que é transmitido os dados.
from Services import File PATH_COMMON = r'C:\Users\letha\AppData\Roaming\MetaQuotes\Terminal\B8C209507DCA35B09B2C3483BD67B706\MQL5\Files\Test\{}.csv' INIT_ARCHIVE = 'init' INIT_OK_ARCHIVE = 'init_checked' if __name__ == "__main__": file = File() file.delete_file(PATH_COMMON.format(INIT_ARCHIVE)) file.delete_file(PATH_COMMON.format(INIT_OK_ARCHIVE)) while True: receive = file.check_open_file(PATH_COMMON.format(INIT_ARCHIVE)) file.delete_file(PATH_COMMON.format(INIT_ARCHIVE)) file.save_file_csv(PATH_COMMON.format(INIT_OK_ARCHIVE))
void OnStart() { start=0; time=0; start=GetTickCount(); for(int i=0; i<100; i++) { File.Open(PATH("init"), FILE_WRITE|FILE_SHARE_READ|FILE_ANSI); ResetLastError(); if((File.WriteHeader(H)<1&File.WriteLine(L)<1)!=0) Print("Error : ", GetLastError()); File.Close(); while(!File.IsExist(PATH("init_checked"))) { //waiting for startup Comment("waiting for startup"); } File.Delete(PATH("init")); File.Delete(PATH("init_checked")); } time=GetTickCount()-start; Print("Time send 100 archives with transfer message [ms]: ",time); }
Temos o resultado:
testeCSV (EURUSD,M1) Time to send 100 files, transfer message [ms]: 5578
Este sistema não é excepcional, mas tem seu valor, pois enviaremos pequenas quantidades de dados para o servidor e esse envio será realizado uma vez a cada nova abertura de vela, não precisamos nos preocupar com isso. No entanto, se a intenção fosse criar um sistema de streaming de cotações, dados de livro ou qualquer outra coisa, essa arquitetura não seria recomendada. Há a possibilidade de evoluir o sistema para algo mais elaborado no futuro.
Além disso, o processo está limitado a um único modelo/estratégia, mas isso pode ser melhorado para proporcionar mais escalabilidade para o sistema no futuro.
Uso de Regressão Linear:
O que seria Regressão Linear?
A regressão linear é uma técnica estatística amplamente utilizada na análise financeira para prever o comportamento de ativos financeiros, como ações, títulos e moedas. Essa técnica permite que os analistas financeiros identifiquem a relação entre diferentes variáveis e, assim, "prevejam" o desempenho futuro de um ativo.
Para utilizar a regressão linear em ativos financeiros, é preciso primeiro coletar dados históricos relevantes. Isso inclui informações sobre o preço de fechamento de um ativo, volume negociado, rendimento e outros indicadores econômicos relevantes. Esses dados podem ser obtidos a partir de fontes como a Bolsa de Valores ou sites financeiros.
Uma vez coletados os dados, é preciso escolher qual variável dependente e independente serão utilizadas na análise. A variável dependente é aquela que se deseja prever, enquanto as variáveis independentes são aquelas que são utilizadas para explicar o comportamento da variável dependente. Por exemplo, se o objetivo é prever o preço de uma ação, a variável dependente seria o preço da ação e as variáveis independentes poderiam ser o volume negociado, o rendimento e outros indicadores econômicos.
Em seguida, é preciso aplicar uma técnica estatística para encontrar a equação da reta de regressão, que representa a relação entre as variáveis independentes e dependente. Essa equação é utilizada para prever o comportamento futuro de um ativo.
Após aplicar a técnica de regressão linear, é importante avaliar a qualidade da previsão realizada. Isso pode ser feito comparando os resultados previstos com os dados históricos reais. Se a precisão da previsão for baixa, é possível que sejam necessárias ajustes na metodologia ou a seleção de variáveis independentes diferentes.
A regressão linear é uma técnica estatística amplamente utilizada na análise financeira para prever o comportamento de ativos financeiros, como ações, títulos e moedas. Ela permite que os analistas financeiros identifiquem a relação entre diferentes variáveis e, assim, prevejam o desempenho futuro de um ativo. A implementação da regressão linear em Python é fácil de ser feita usando biblioteca scikit-learn e pode ser uma ferramenta valiosa para previsão de preços de ativos financeiros. No entanto, é importante lembrar que a regressão linear é uma técnica básica e pode não ser apropriada para todos os tipos de ativos financeiros ou situações específicas. É sempre importante avaliar a qualidade da previsão e considerar outras técnicas de análise financeira.Além disso, é importante lembrar que a regressão linear é uma técnica estatística básica e pode não ser apropriada para todos os tipos de ativos financeiros ou situações específicas. Outras técnicas, como a análise de séries temporais ou modelos de previsão baseados em inteligência artificial, também podem ser utilizadas para prever o comportamento de ativos financeiros.
Implementação em Python:
import random import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score from sklearn.preprocessing import OneHotEncoder random.seed(42) encoder = OneHotEncoder() # Create an empty dataframe data = pd.DataFrame(columns=['ticker', 'price', 'volume', 'economic_indicator']) # Fill the dataframe with random values for i in range(500): row = { 'ticker': "FAKE3", 'price': round(random.uniform(100, 200), 2), 'volume': round(random.uniform(10000, 100000), 2), 'economic_indicator': round(random.uniform(1, 100), 2) } data = data.append(row, ignore_index=True) print(data) # aplica o one-hot encoding na coluna "ticker" onehot_encoded = encoder.fit_transform(data[['ticker']]) # adiciona as novas colunas one-hot encoded ao dataframe original data['tiker_encoder'] = onehot_encoded.toarray() # Selecionando as variáveis independentes e dependente X = data[['tiker_encoder', 'volume', 'economic_indicator']] y = data['price'] # Criando o modelo de regressão linear model = LinearRegression() # Treinando o modelo com os dados históricos model.fit(X, y) # Fazendo previsões com o modelo treinado y_pred = model.predict(X) # Avaliando a qualidade da previsão r2 = r2_score(y, y_pred) print("Coeficiente de determinação:", r2) # Fazendo previsões para novos dados new_data = [[1, 23228.17, 61.21]] new_price_pred = model.predict(new_data) print("Previsão de preço para novos dados:", new_price_pred)
Este código utiliza a biblioteca scikit-learn para criar um modelo de regressão linear com base nos dados históricos de preço, volume negociado, e um indicador econômico. O modelo é treinado com os dados históricos e é utilizado para fazer previsões de preço. Também é calculado o coeficiente de determinação (R²) como uma medida da qualidade da previsão. Além disso, o modelo também é usado para fazer previsões para novos dados fornecidos.
Vale mencionar que este código é estático e serve apenas como exemplo. Ele pode ser facilmente adaptado para lidar com dados atuais e dinâmicos, e para ser usado em um ambiente de produção. Além disso, é necessário obter os dados de mercado e indicadores econômicos para treinar o modelo.
É importante notar que essa é apenas uma implementação básica de um modelo de regressão linear para prever o preço de uma ação e pode ser necessário ajustar o modelo e os dados de acordo com a sua necessidade específica e não é recomendado a reprodução em conta real.
O exemplo fornecido é apenas para fins ilustrativos e não deve ser considerado como uma implementação completa, uma demonstração detalhada da implementação completa será apresentada no próximo artigo.
Conclusão
A arquitetura proposta foi eficaz em superar as restrições na realização de testes em modelos Python, proporcionando uma variedade de opções de teste e facilitando a validação e avaliação da eficiência dos modelos. No próximo artigo, discutiremos com mais profundidade a implementação da Classe CFileCSV, que será a base para a transferência de dados utilizada no MQL5.
É importante destacar que a implementação da Classe CFileCSV será fundamental para a troca de dados entre o MQL5 e o Python, possibilitando a utilização de recursos avançados de análise de dados e modelagem em ambas as plataformas, e será um componente fundamental para aproveitar ao máximo as vantagens dessa arquitetura.
 Como desenvolver um sistema de negociação baseado no indicador Alligator
Como desenvolver um sistema de negociação baseado no indicador Alligator
 Ciência de Dados e Aprendizado de Máquina (Parte 07): Regressão Polinomial
Ciência de Dados e Aprendizado de Máquina (Parte 07): Regressão Polinomial
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso