
MQL5中的范畴论(第20部分):自我注意的迂回与转换
概述
我认为,在范畴论和自然变换的主题上继续写这些系列文章,而不去碰房间里的大象,也就是 chatGPT,那将是失职的。到目前为止,每个人都以某种形式熟悉了chatGPT和许多其他人工智能平台,并见证和欣赏了变换神经网络(transformer neural network)的潜力,它不仅使我们的研究更容易,而且还能从琐碎的任务中抽走急需的时间。因此,我在这些系列中浏览了一圈,试图解决这样一个问题,即范畴论的自然变换是否在某些方面是 Open AI 所采用的生成预训练变换器(Generative Pretrained Transformer,GPT)算法的关键。
除了用“变换”的措辞检查任何同义词外,我认为在MQL5中查看GPT算法代码的部分,并在证券价格系列的初步分类上测试它们也会很有趣。
正如论文中所介绍的,“注意力就是你所需要的一切”是用于跨口语(如意大利语到法语)进行翻译的神经网络的一项创新,它建议消除递归和卷积。它的建议是?自注意力机制(Self-Attention)。据了解,许多正在使用的人工智能平台都是这一早期努力的大脑产物。
Open AI使用的实际算法当然是保密的,但人们仍然认为它使用单词嵌入(Word-Embedding)、位置编码(Positional Encoding)、自注意力机制(Self-Attention)和前馈网络(Feed-Forward network),作为仅解码转换器(decode-only transformer)中堆栈的一部分。这些都没有得到证实,所以你不应该相信我的话。需要明确的是,这个参考是关于单词/语言翻译部分的算法。是的,由于chatGPT中的大多数输入都是文本,它确实在算法中起着关键的、几乎是基础性的作用,但我们现在知道chatGPT所做的远不止解释文本。例如,如果你上传了一个excel文件,它不仅可以打开它来阅读其内容,还可以绘制图表,甚至对所提供的统计数据发表意见。这里的重点是chatGPT算法显然没有在这里完全呈现,但它可能看起来只是被理解的一部分。
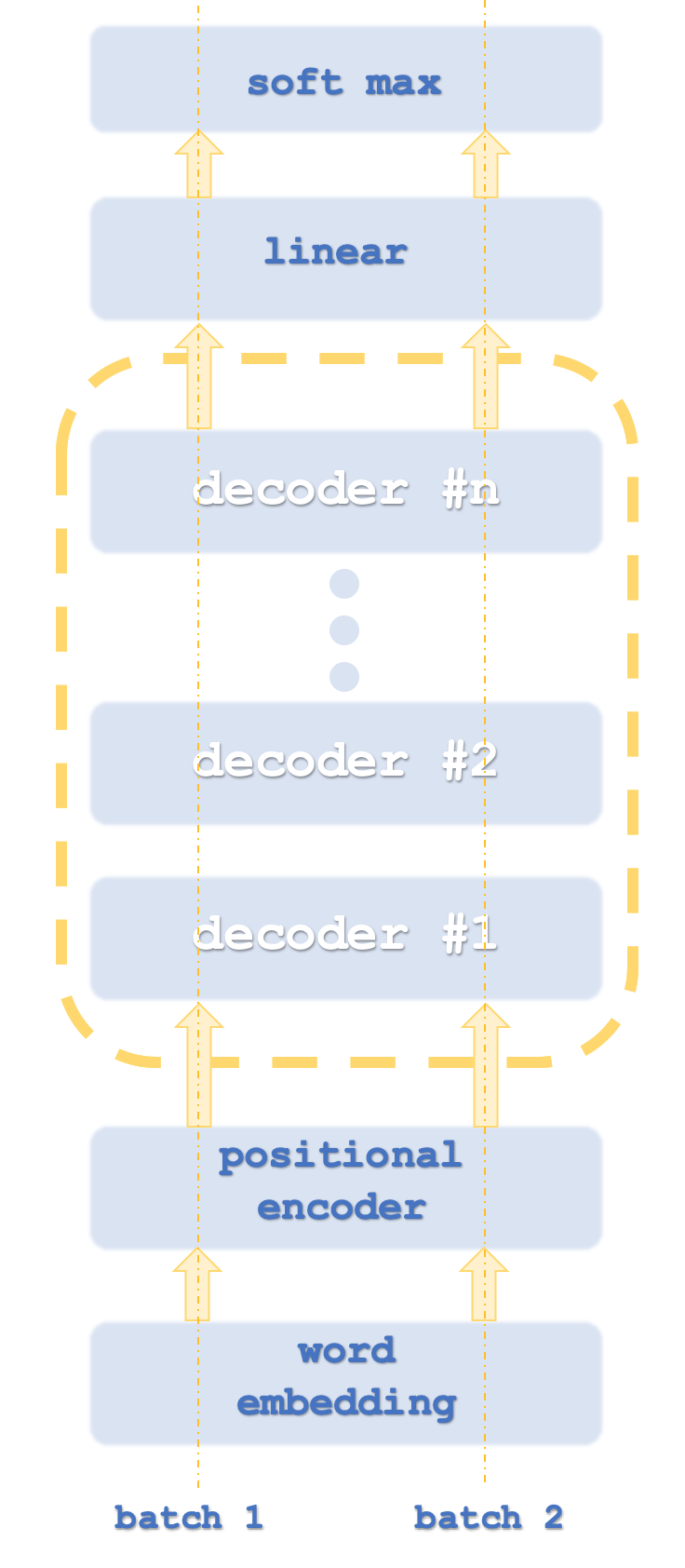
批处理1和2类似于计算机线程,因为转换器通常并行运行网络实例。
由于我们正在对数字进行分类,因此不需要嵌入单词。位置编码是指根据单词的位置来捕捉句子中每个单词的绝对重要性。这方面的算法是直接的,因为每个单词(也称为令牌)都被分配了一个正弦波上的读数,该读数来自不同频率的正弦波阵列。将每个波形的读数相加,得到该标记的位置编码。该值可以是一个矢量,这意味着您要将多个频率阵列的值相加。
这会导致自注意力机制。这样做的目的是计算一个句子中每个单词与该句子中出现在它之前的单词的相对重要性。这种看似微不足道的努力在通常以“it”一词为特征的句子中以及其他情况下都很重要。例如,在下面的句子中:
“The dish washer partly cleaned the glass and it cracked it.”(“洗碗机把玻璃洗得开裂了。”)
它代表什么?对人类来说,这是直接的,但对学习机器来说,不是这样。正如这个问题最初看起来的那样,量化这个词的相对重要性的能力可以说是启动变换神经网络的关键,因为变换神经网络被发现比其前身的递归和卷积网络更具并行性,需要更少的训练时间。
因此,对于本文来说,自注意力机制将是我们测试信号类的关键。有趣的是,尽管自注意算法在单词相互关联的方式上确实与一个范畴有相似之处。用于量化相对重要性(相似性)的词关系可以被认为是词本身形成对象的态射。事实上,这种关系有点怪异,因为每个单词都需要计算其相似性或重要性。这很像身份态射!此外,除了推断态射和对象之外,我们还可以分别关联函子和范畴,正如我们在后面的文章中所看到的那样。
了解变换解码器
通常,变换网络将包含编码和解码堆栈,每个堆栈表示自注意和前馈网络中的重复。它可能类似于下面的内容:
除此之外,每个步骤都用平行的“线程”运行,这意味着,例如,如果自注意和前馈步骤可以由多层感知器表示,那么如果变换器有8个线程,则每个阶段将有8个多层感知机。这显然是资源密集型的,但正是这种方法的优势所在,因为即使使用了这种资源,它仍然比前代复杂网络更高效。
据了解,Open AI所使用的方法为其变体,因为它只是解码。它的步骤大致显示在我们的第一张图中。仅进行解码显然不会影响模型的准确性,但由于只处理了“一半”变换器,因此它肯定会带来更好的性能。这里指出,编码时的自注意映射与解码时的自关注映射不同,因为编码时计算所有单词的相对重要性,而与句子中的相对位置无关。这显然是更耗费资源的,因为正如解码器方面所提到的,只对每个单词本身以及句子中位于其之前的单词进行自关注(也称为相似性计算)。有些人可能会争辩说,这甚至否定了位置编码的必要性,但出于我们的目的,我们将把它包含在源代码中。因此,这种仅解码的方法是我们的重点。
自注意和前馈网络在变换器步骤中的作用是根据堆栈进行位置编码或先前堆栈输出,并为下一解码器步骤的输入中的线性SoftMax步骤产生输入。
位置编码,有些人可能会觉得对我们的信号类和文章来说有些过头了,它包含在这里是为了提供信息。输入价格柱信息的绝对顺序可能与句子中的单词序列一样重要。我们使用的是一个简单的算法,它返回一个 double 型值的4点向量,作为每个输入价格点的“坐标”。
有些人可能会争论为什么不对每个输入使用简单的索引。事实证明,当训练网络时,这会导致梯度消失和爆炸,因此需要一种不太稳定和规范化的格式。你可以认为这相当于一个标准长度的加密密钥,比如128,而不管加密的是什么。是的,它使破解隐藏的密钥变得更加困难,但它也提供了一种更有效的生成和存储密钥的方法。
所以,我们将使用4个不同频率的正弦波。偶尔,尽管有这4种频率,但两个单词可能具有相同的“坐标”,但这应该不是问题,因为如果确实发生了这种情况,那么许多单词(或在我们的情况下是价格点)被用来否定这种轻微的异常。这些坐标值被添加到我们的输入向量的4个价格点上,这代表了我们从单词嵌入中得到的东西,但没有,因为我们已经在处理安全价格形式的数字。我们的信号类将使用价格变化。为了对我们的位置编码进行某种程度的“规范化”,可以在+5.0到-5.0之间波动,有时甚至超过5.0的位置编码值,在被添加到价格变化之前,将被乘以所讨论的证券的点值大小。
您可以从上面的共享超链接中收集到的自注意力机制负责确定3个向量,即查询向量、关键字向量和值向量。这些矢量是通过将位置编码输出矢量乘以权重矩阵得到的。这些权重是怎么来的?来自反向传播。不过,出于我们的目的,我们将使用多层感知器类的实例来初始化和训练这些权重,仅有一层。这一关键阶段的过程图示如下:
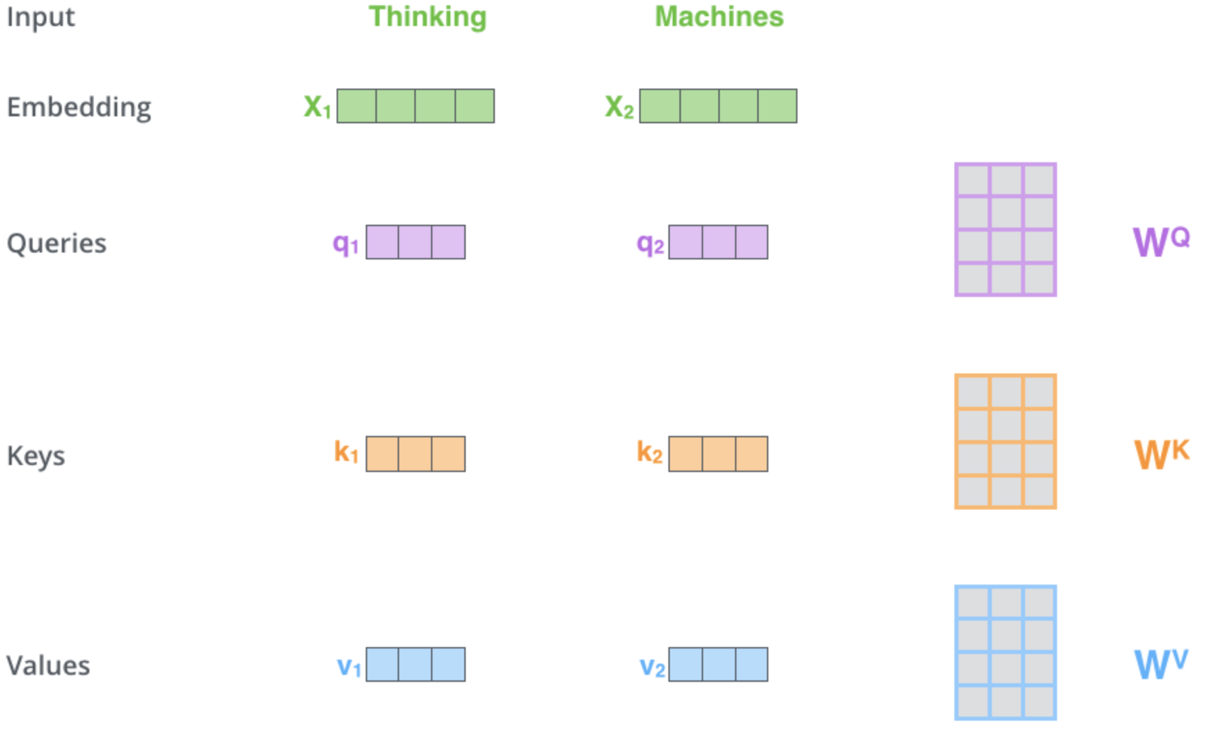
这幅插图和本文中的一些要点来源于网页。上图表示两个单词作为输入(“思考”和“机器” - “Thinking”, “Machines”)。在嵌入时(将它们转换为数字矢量),它们将转换为绿色矢量。右边的矩阵表示我们将通过多层感知器获得的权重,如上所述。
因此,一旦我们的网络执行前向传递,得到查询、关键字和值向量,我们就对查询和关键字进行点积,将结果除以关键字向量基数的平方根,结果就是价格点与查询向量和价格点与关键字向量之间的相似性。这些乘法是在所有价格点上进行的,与我们只将价格点与自身和之前的价格点进行比较的自注意映射保持一致。结果得到了可能广泛的数字,这就是为什么使用SoftMax函数将它们归一化为概率分布的原因。所有这些概率权重的总和如预期的那样达到1,它们正在有效地加权。在最后一步中,将每个权重与其各自的向量值相乘,并将所有这些乘积相加为单个向量,形成自注意层的输出。
前馈网络通过多层感知器处理来自自注意的输出向量,并输出与自注意输入向量大小相似的另一个向量。
在MQL5中实现变换解码器(Transformer Decoder)的理论框架将通过简单的信号类而不是 EA 交易。这个主题目前有点复杂,因为其中一些想法存在还不到十年,所以人们认为测试和熟悉度现在比执行和结果更重要。当然,当读者感到舒适时,他可以自由地进一步接受和采纳这些想法。
MQL5信号类:自注意和前馈网络一瞥
本文附带的信号类可以通过一个只有一个堆栈和一个线程的转换器解码器来预测价格变化!!所附代码可通过调整'__DECODERS'定义参数来增加堆栈数量。如上所述,堆栈通常是多个,并且在多线程设置中常常是多个。事实上,通常在解码器内使用多个堆栈,因此需要残差连接。这也是为了避免消失和爆炸梯度的问题。因此,我们正在使用一个简单的裸机变换器,看看它能做什么。读者可以从这里开始进行进一步的定制,以满足他的实现需求。
位置编码可能是列出的所有函数中最简单的,因为它只返回给定输入大小的坐标向量。代码如下:
//+------------------------------------------------------------------+ //| Positional Encoding vector given length. | //+------------------------------------------------------------------+ vector CSignalCT::PositionalEncoding(int Positions) { vector _positions; _positions.Init(Positions);_positions.Fill(0.0); for(int i=0;i<Positions;i++) { for(int ii=0;ii<Positions;ii++) { _positions[i]+=MathSin((((ii+1)/Positions)*(i+1))*__PI); } } return(_positions); }
因此,我们的信号类引用了许多函数,但其中最主要的是解码函数,其源代码如下所示:
//+------------------------------------------------------------------+ //| Decode Function. | //+------------------------------------------------------------------+ void CSignalCT::Decode(int &DecoderIndex,matrix &Input,matrix &Sum,matrix &Output) { Input.ReplaceNan(0.0); // //output matrices Sum.Init(1,int(Input.Cols()));Sum.Fill(0.0); Ssimilarity _s[]; ArrayResize(_s,int(Input.Cols())); for(int i=int(Input.Rows())-1;i>=0;i--) { matrix _i;_i.Init(1,int(Input.Cols())); for(int ii=0;ii<int(Input.Cols());ii++) { _i[0][ii]=Input[i][ii]; } // SelfAttention(DecoderIndex,_i,_s[i].queries,_s[i].keys,_s[i].values); } for(int i=int(Input.Cols())-1;i>=0;i--) { for(int ii=i;ii>=0;ii--) { matrix _similarity=DotProduct(_s[i].queries,_s[ii].keys); Sum+=DotProduct(_similarity,_s[i].values); } } // Sum.ReplaceNan(0.0); // FeedForward(DecoderIndex,Sum,Output); }
正如您所看到的,它调用了自注意函数和前馈函数,还准备了这两个层函数所需的输入数据。
自注意函数进行实际的矩阵权重计算,以获得查询、键和值的向量。我们已经将这些“向量”表示为矩阵,尽管出于信号类的目的,我们将使用单行矩阵,因为在实践中,多个向量通常通过网络馈送或乘以矩阵权重系统,以产生查询、键和值的矩阵。其源代码如下:
//+------------------------------------------------------------------+ //| Self Attention Function. | //+------------------------------------------------------------------+ void CSignalCT::SelfAttention(int &DecoderIndex,matrix &Input,matrix &Queries,matrix &Keys,matrix &Values) { Input.ReplaceNan(0.0); // Queries.Init(int(Input.Rows()),int(Input.Cols()));Queries.Fill(0.0); Keys.Init(int(Input.Rows()),int(Input.Cols()));Keys.Fill(0.0); Values.Init(int(Input.Rows()),int(Input.Cols()));Values.Fill(0.0); for(int i=0;i<int(Input.Rows());i++) { double _x_inputs[],_q_outputs[],_k_outputs[],_v_outputs[]; vector _i=Input.Row(i);ArrayResize(_x_inputs,int(_i.Size())); for(int ii=0;ii<int(_i.Size());ii++){ _x_inputs[ii]=_i[ii]; } m_base_q[DecoderIndex].MLPProcess(m_mlp_q[DecoderIndex],_x_inputs,_q_outputs); m_base_k[DecoderIndex].MLPProcess(m_mlp_k[DecoderIndex],_x_inputs,_k_outputs); m_base_v[DecoderIndex].MLPProcess(m_mlp_v[DecoderIndex],_x_inputs,_v_outputs); for(int ii=0;ii<int(_q_outputs.Size());ii++){ if(!MathIsValidNumber(_q_outputs[ii])){ _q_outputs[ii]=0.0; }} for(int ii=0;ii<int(_k_outputs.Size());ii++){ if(!MathIsValidNumber(_k_outputs[ii])){ _k_outputs[ii]=0.0; }} for(int ii=0;ii<int(_v_outputs.Size());ii++){ if(!MathIsValidNumber(_v_outputs[ii])){ _v_outputs[ii]=0.0; }} for(int ii=0;ii<int(Queries.Cols());ii++){ Queries[i][ii]=_q_outputs[ii]; } Queries.ReplaceNan(0.0); for(int ii=0;ii<int(Keys.Cols());ii++){ Keys[i][ii]=_k_outputs[ii]; } Keys.ReplaceNan(0.0); for(int ii=0;ii<int(Values.Cols());ii++){ Values[i][ii]=_v_outputs[ii]; } Values.ReplaceNan(0.0); } }
前馈函数是对多层感知器的直接处理,从我们的角度来看,这里没有任何特定于解码变换器的内容。当然,其他实现可以在这里有自定义设置,比如多个隐藏层,甚至不同类型的网络,比如玻尔兹曼机,但就我们的目的而言,这是一个简单的单个隐藏层网络。
点积函数有点有趣,因为它是两个矩阵相乘的自定义实现。我们主要使用它来乘以一行矩阵(也称为向量),但它是可扩展的,并且可能会比较耗资源的,因为对内置矩阵乘法函数的初步测试发现它目前存在缺陷。
SoftMax是维基百科中所列内容的实现。我们所做的只是返回一个给定输入值数组的概率向量。输出向量的所有值都为正,并且总和为1。
因此,综合来看,我们的信号类加载了从 2020.01.01 到 2023.08.01 的外汇货币对 USDJPY 的价格数据。对于每日时间框架,我们将4个价格点的矢量输入位置编码函数,这些价格点只是收盘价格的最后4个变化。如上所述,该函数获取每个价格变化的坐标,通过将其乘以美元兑日元的点大小进行归一化,并将其添加到输入价格变化中。
将其输出矢量输入到Decode函数中,以计算矢量中4个输入中的每个输入的查询、关键字和值矢量。根据自映射,由于只检查每个价格点与其自身的相似性及其之前的价格变化,因此从4个矢量值,我们最终得到10个需要SoftMax规范化的矢量值。
一旦我们通过SoftMax运行此操作,我们就有一个由十个权重组成的数组,其中只有一个权重属于第一个价格点,2个权重属于第二个价格点、3个权重属于三个权重点,4个权重属于四个权重点。因此,对于每个价格点,我们也有一个在自注意函数中得到的值向量,我们将这个向量乘以从SoftMax得到的相应权重,然后将所有这些向量相加为一个输出向量。通过设计,它的幅度应该与输入矢量的幅度相匹配,因为变换堆栈是按顺序排列的。此外,由于我们使用的是多层感知器,因此重要的是要提到,用每个网络初始化的权重将是随机的,并用每个连续的柱进行训练(从而改进)。
我们的信号类被编译为 EA 交易,并在2023年前5个月进行了优化,然后在2021年3月6日至2023月8日期间进行了逐步测试,我们收到了以下报告:


这些报告是由一个具有网络权重读写功能的 EA 交易生成的,这些功能在所附代码中没有共享,因为实现由读者决定。由于初始化时不会从确定的来源读取权重,因此每次运行的结果必然不同。
真实世界的应用程序
该信号类别的潜在应用,特别是而不是变换解码器的潜在应用可以是在寻找与变换解码器进行交易的潜在证券。如果我们在几十年的时间跨度内对多个证券进行测试,我们可能会了解到,通过额外的测试和系统开发,哪些值得进一步研究,哪些应该避免。
在解码转换器的堆栈中,自注意层是关键的,并且一定会给我们带来优势,因为这里使用的前馈网络是非常直接的。因此,每次先前价格变化的相对重要性都可以通过相关函数轻松掩盖的方式来捕捉,因为它们关注的是平均值。使用多层感知器来捕获查询、关键字和值向量的权重矩阵是一种可以使用的方法,因为有很多的其他中间机器学习选项可以实现这一点。总的来说,理解自注意力机制对网络可预测性的敏感性将是关键。
限制和缺点
我们的信号类的网络训练是在每个新的柱上递增地进行的,并且加载预先训练的权重的规定是不可用的,这意味着我们一定会得到很多随机结果。事实上,正因为如此,无论何时运行信号类,读者都应该期待一组不同的结果。
此外,在信号类结束时保存训练权重的能力也不可用,这意味着我们无法在这里学到的基础上进行构建。
这些限制是至关重要的,在我看来,在任何人将我们的变换解码器进一步开发成交易系统之前,都需要解决这些限制。我们不仅应该使用经过训练的权重,还应该能够节省训练权重,在部署系统之前,需要使用经过训练权重对样本外数据进行测试。
结论
那么,为了回答这个问题,chatGPT算法是否与自然转换有关?可能是。这是因为,如果我们将解码器转换器的堆栈视为类别,那么线程(通过转换器运行的并行操作)将是函子。通过这种类比,每个运算的最终结果之间的差异将等效于自然变换。
我们的解码器转换器即使没有适当的权重记录和读取也显示出了一些潜力。这当然是一个有趣的系统,当他建立自己的优势时,可以进一步开发,甚至添加到他的工具包中。
总之,自注意算法善于量化标记(转换器中的输入)之间的相对相似性。在我们的案例中,这些令牌是在不同但连续的时间点上的价格变化。在其他模型中,这可能是多个经济指标、新闻事件或投资者情绪值等,但过程是相同的,然而,这些不同输入的结果必然会揭示这些输入值的复杂动态关系,从而对其进行建模,帮助开发者更好地理解它们。从长远来看,这将使变换器在每个新的训练会话中自适应地从输入令牌中提取相关特征。因此,即使在大量新闻爆料的动荡情况下,该模型也应该筛选出白噪声,并更有弹性。
此外,当面对不同时间点的滞后或输入数据时,自注意算法,就像我们对附加信号类所探索的那样,有助于量化这些不同时期的相对重要性,从而捕获长期依赖性。这导致了在不同时间范围内处理预测的能力,这对交易员来说是另一个优势。因此,为了总结令牌投入的相对权重,如果使用滞后时间指标(或价格),不仅应向交易员提供可能是投入的各种经济指标的见解,还应提供不同时间框架的见解。
其他资源
参考文献大多是维基百科,根据康奈尔大学计算机科学出版物、堆栈交换和本网站的链接。
作者笔记
本文中共享的源代码不是chatGPT使用的代码。它只是一个仅解码变换器的实现。它采用信号类格式,这意味着用户需要使用MQL5向导进行编译,以形成可测试的 EA 交易。这里有一个相关的指南。此外,他还应该实现读写机制,用于读取和存储学习到的网络权重。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/13348