
Desenvolvendo um EA multimoeda (Parte 18): Automação da seleção de grupos considerando o período forward
Introdução
Em uma das partes anteriores desta série de artigos (na parte 7), discutimos a seleção de grupos de instâncias individuais de estratégias de negociação para melhorar os resultados ao serem utilizadas em conjunto. Aplicamos dois métodos para essa seleção. No primeiro, a escolha do grupo era feita com base nos resultados da otimização em todo o intervalo de tempo analisado. Tentávamos incluir no grupo aquelas instâncias que apresentaram os melhores resultados nesse intervalo. No segundo método, uma parte menor do intervalo de tempo era separada, onde a otimização das instâncias não era realizada. Essa parte separada era então usada na seleção do grupo: procurávamos incluir aquelas instâncias que apresentavam bons (mas não os melhores) resultados no intervalo de otimização e resultados semelhantes na parte separada do intervalo.
Os resultados foram os seguintes:
- Não observamos uma vantagem clara da seleção pelo primeiro método em relação ao segundo. Isso pode estar relacionado ao curto intervalo de histórico analisado, onde comparamos os dois métodos. Três meses são insuficientes para avaliar uma estratégia que pode ter períodos mais longos de estagnação.
- O segundo método mostrou que, na parte separada do intervalo de tempo, os resultados são melhores quando aplicamos o método descrito no artigo para encontrar instâncias individuais de estratégias de negociação com resultados semelhantes. Quando as instâncias eram selecionadas apenas pelos melhores resultados no intervalo de otimização (como no primeiro método, mas em um intervalo mais curto), os resultados do grupo selecionado eram visivelmente piores.
- É possível combinar ambos os métodos, ou seja, formar dois grupos selecionados de formas diferentes e depois unir os dois em um único grupo.
Na parte 13, implementamos a automação da segunda etapa da otimização, que envolvia justamente a seleção de instâncias individuais de estratégias de negociação obtidas na primeira etapa. Utilizamos uma busca simples com um algoritmo genético do otimizador padrão no testador de estratégias. Não realizamos qualquer pré-clusterização das instâncias (descrita na parte 6). Assim, automatizamos a seleção de grupos pelo primeiro método. Naquele momento, não chegamos a implementar a seleção de grupos pelo segundo método, mas agora é o momento certo para abordar essa questão. Nesta parte, tentaremos automatizar a seleção de instâncias individuais de estratégias de negociação em grupos, considerando seu comportamento no período forward.
Traçando o caminho
Como sempre, começaremos analisando o que já temos e o que ainda falta para resolver a tarefa proposta. Podemos definir a tarefa de otimizar uma estratégia de negociação para qualquer intervalo de tempo necessário. A expressão "definir a tarefa" deve ser interpretada literalmente: para isso, criamos os registros necessários na tabela de tarefas (tasks) do nosso banco de dados. Assim, podemos realizar a otimização inicialmente em um intervalo de tempo (por exemplo, de 2018 a 2022), e depois em outro intervalo (por exemplo, o ano de 2023).
Entretanto, com esse método, não conseguimos utilizar os resultados obtidos da maneira desejada. Em cada um dos dois intervalos de tempo, a otimização será realizada de forma independente, impossibilitando a comparação direta: as passagens da segunda otimização não replicarão as da primeira em relação aos valores dos parâmetros de entrada. Isso é válido para a otimização genética, que utilizamos. Para uma otimização completa, isso não se aplica, mas nunca a utilizamos e, provavelmente, não usaremos devido à grande quantidade de combinações de parâmetros a serem otimizados.
Portanto, será necessário iniciar o processo de otimização especificando o período forward. Nesse caso, no período forward, o testador usará as mesmas combinações de parâmetros de entrada que no período principal. Porém, ainda não experimentamos iniciar a otimização automatizada com um período forward e não sabemos como esses resultados serão armazenados em nosso banco de dados. Será possível distinguir as passagens do período principal das do período forward? Isso precisará ser verificado.
Uma vez garantida a presença no banco de dados de todas as informações necessárias sobre as passagens, tanto para o período principal quanto para o período forward, podemos avançar para a próxima etapa. Na parte 7, após obter esses resultados, realizamos manualmente sua análise e seleção, utilizando o Excel para isso. No entanto, no contexto de automação, o uso de Excel não é eficiente. Estamos buscando eliminar quaisquer manipulações manuais com os dados durante o processo de obtenção do EA final. Felizmente, todas as operações que realizávamos no Excel (recalcular certos resultados, calcular relações de métricas entre diferentes períodos de teste, determinar a avaliação final para cada grupo de estratégias e classificá-los) podem ser executadas no MQL5 através de consultas SQL ao nosso banco de dados ou utilizando um script em Python.
Após a classificação com base na avaliação final, incluiremos no EA final apenas o grupo mais bem classificado. Realizaremos ações semelhantes para todas as combinações de símbolos e timeframes escolhidos. Após normalizar o grupo geral, que incluirá os melhores grupos para todos os pares símbolo-timeframe, o EA final estará pronto.
Vamos começar a implementação, mas primeiro corrigiremos um erro que foi identificado.
Correção do erro de salvamento
Ao desenvolvermos o EA para automatizar a primeira etapa (otimização de instâncias individuais de estratégias de negociação), utilizávamos apenas um banco de dados. Assim, não havia dúvidas sobre qual banco de dados utilizar para recuperar ou salvar os dados. Na segunda etapa da otimização, foi adicionado um novo banco de dados auxiliar, que continha apenas um resumo mínimo necessário do banco de dados principal. Esse banco de dados reduzido era enviado aos agentes de teste na segunda etapa da otimização.
Devido à abordagem já escolhida ao implementar a classe estática para trabalhar com o banco de dados, fomos obrigados a adotar uma solução um pouco inconveniente que permitisse alterar o nome do banco de dados conforme necessário. Após a alteração do nome, todas as chamadas subsequentes do método de conexão ao banco de dados passavam a usar o novo nome. Isso resultou no erro ao adicionar os resultados das passagens na segunda e terceira etapas. O problema estava na ausência de um retorno ao banco de dados principal em todos os locais necessários.
Para corrigir isso, adicionamos ao EA de cada etapa e ao EA de otimização automática de projetos um parâmetro de entrada adicional que define o nome do banco de dados principal. Além de corrigir o erro, isso também é útil para separar melhor os bancos de dados usados em diferentes partes do projeto. Por exemplo, nesta parte, utilizamos um novo banco de dados principal, já que decidimos reduzir o conjunto de tarefas de otimização, mas não queríamos limpar o banco de dados existente:
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ sinput string fileName_ = "database683.sqlite"; // - Файл с основной базой данных
Na função OnInit() do EA da segunda etapa (SimpleVolumesStage2.mq5),SimpleVolumesStage2.mq5 dentro da chamada da função LoadParams(), ocorria a conexão ao banco de dados auxiliar, pois os dados dos parâmetros de entrada das instâncias individuais das estratégias de negociação, necessários para combiná-las em um grupo, precisavam ser obtidos desse banco. Após a conclusão da passagem, a função OnTester() era chamada, onde os resultados do grupo deveriam ser salvos no banco de dados principal. No entanto, como não havia retorno ao banco de dados principal, os resultados completos da passagem (48 colunas) eram inseridos na tabela do banco auxiliar (2 colunas).
Portanto, adicionamos o retorno ao banco de dados principal que estava faltando na função OnInit() do EA da segunda etapa (SimpleVolumesStage2.mq5).
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Загружаем наборы параметров стратегий string strategiesParams = LoadParams(indexes); // Подключаемся к основной базе данных DB::Connect(fileName_); DB::Close(); ... // Создаем эксперта, работающего с виртуальными позициями expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Nos EAs de otimização da primeira e terceira etapas, onde o banco de dados auxiliar não é usado, adicionamos o nome do banco, retirado do novo parâmetro de entrada do EA, na primeira chamada do método de conexão ao banco de dados:
DB::Connect(fileName_)
Outro tipo de erro identificado ocorria quando, após a conclusão, desejávamos executar separadamente uma das passagens favoritas. A execução iniciava e funcionava normalmente, mas seus resultados não eram gravados no banco de dados. Descobriu-se que, nesse tipo de execução, o identificador da tarefa permanecia igual a 0, e, no banco de dados, a tabela de passagens (passes) só pode aceitar registros com um identificador de tarefa existente na tabela de tarefas (tasks).
Corrigir isso poderia ser feito de duas formas: ou configurando o identificador da tarefa para ser extraído dos parâmetros de entrada do EA (como acontece durante a otimização), ou adicionando ao banco de dados uma tarefa fictícia com identificador 0. Optamos pela segunda abordagem para que as passagens iniciadas manualmente não fossem tratadas como parte de uma tarefa específica de otimização. Para a tarefa fictícia, era necessário atribuir a ela um identificador de uma tarefa existente e configurar seu status como 'Done', garantindo que ela não fosse executada durante a otimização automática.
Após essas correções, voltamos ao objetivo principal.
Preparação do código e do banco de dados
Começamos criando uma cópia do banco de dados existente, limpando os registros relacionados a passagens, tarefas e trabalhos. Em seguida, modificamos os dados do primeiro estágio, adicionando a data de início do período forward. O segundo estágio foi removido da tabela de estágios (stages). Para o primeiro estágio, criamos um registro na tabela de trabalhos (jobs), especificando o símbolo, o período (EURGBP H1) e os parâmetros para o testador de estratégias, limitando a otimização a um único parâmetro. Isso reduziu o número de passagens, permitindo resultados mais rápidos. Para este trabalho, adicionamos uma tarefa na tabela de tarefas (tasks) com um critério de otimização abrangente.
Ao iniciar o EA de otimização automática de projetos, especificamos o banco de dados recém-criado como parâmetro de entrada. Após a primeira execução, identificamos que o EA precisava de ajustes, pois ele não recebia informações do banco de dados sobre a necessidade de utilizar o período forward. Após as alterações, o código da função que obtém a próxima tarefa de otimização do banco de dados passou a incluir as seguintes linhas adicionais:
//+------------------------------------------------------------------+ //| Получение очередной задачи оптимизации из очереди | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Результат ulong res = 0; // Запрос на получение очередной задачи оптимизации из очереди string query = "SELECT s.expert," " s.optimization," " s.from_date," " s.to_date," " s.forward_mode," " s.forward_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Processing')" " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // Открываем базу данных if(DB::Connect()) { // Выполняем запрос int request = DatabasePrepare(DB::Id(), query); // Если нет ошибки if(request != INVALID_HANDLE) { // Структура данных для чтения одной строки результата запроса struct Row { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Читаем данные из первой строки результата if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(row.expert), row.symbol, row.period, row.optimization, row.from_date, row.to_date, row.forward_mode, row.forward_date, row.optimization_criterion, row.id_task, fileName_, row.tester_inputs ); res = row.id_task; } else { // Сообщаем об ошибке при необходимости PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Сообщаем об ошибке при необходимости PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Закрываем базу данных DB::Close(); } return res; }
Adicionamos também uma função para determinar o caminho do arquivo do EA a ser otimizado a partir da pasta atual, relativa à pasta raiz de EAs do terminal:
//+------------------------------------------------------------------+ //| Получение пути к файлу оптимизируемого советника из текущей | //| папки относительно корневой папки советников терминала | //+------------------------------------------------------------------+ string GetProgramPath(string name) { string path = MQLInfoString(MQL_PROGRAM_PATH); string programName = MQLInfoString(MQL_PROGRAM_NAME) + ".ex5"; string terminalPath = TerminalInfoString(TERMINAL_DATA_PATH) + "\\MQL5\\Experts\\"; path = StringSubstr(path, StringLen(terminalPath), StringLen(path) - (StringLen(terminalPath) + StringLen(programName))); return path + name; }
Isso permitiu que a tabela de estágios incluísse apenas o nome do arquivo do EA otimizado, sem listar as pastas nas quais ele está armazenado em relação à raiz (\MQL5\Experts).
As execuções subsequentes do EA de otimização automática confirmaram que os resultados das passagens forward estavam sendo adicionados corretamente à tabela de passagens (passes), juntamente com as passagens normais. No entanto, distinguir entre períodos principal e forward era complicado. Embora fosse possível supor que as passagens forward sempre seguissem as normais, isso não funcionava quando a tabela passes incluía resultados de múltiplas tarefas com períodos forward. Assim, adicionamos uma coluna is_forward à tabela passes para identificar passagens forward e, paralelamente, uma coluna is_optimization para diferenciar passagens normais de otimizações.
Durante esse processo, identificamos outra inconsistência: o número da passagem era inserido como um inteiro com sinal, usando o especificador %d. Como esse número é um inteiro longo sem sinal, corrigimos a substituição para %I64u no SQL.
Adicionamos o valor correspondente ao indicador de período forward na formação do SQL para inserir os dados da passagem:
string CTesterHandler::GetInsertQuery(string values, string inputs, ulong pass) { return StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %I64u, %d, %s,\n'%s',\n'%s') RETURNING rowid;", s_idTask, pass, (int) MQLInfoInteger(MQL_FORWARD), values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); }
Contudo, descobrimos que isso não funcionava conforme esperado. Isso ocorre porque a função é chamada do EA executado no terminal principal em modo de coleta de dados, onde o retorno de MQLInfoInteger(MQL_FORWARD) é sempre falso.
Assim, o indicador de período forward precisava ser obtido no código dos agentes de teste, não no terminal principal no gráfico, ou seja, no manipulador de eventos de término da passagem de teste. O mesmo foi feito para o indicador de otimização.
//+------------------------------------------------------------------+ //| Обработка завершения прохода тестера для агента | //+------------------------------------------------------------------+ void CTesterHandler::Tester(double custom, // Пользовательский критерий string params // Описание параметров советника в текущем проходе ) { ... // Формируем строку с данными о проходе data = StringFormat("%d, %d, %s,'%s'", MQLInfoInteger(MQL_OPTIMIZATION), MQLInfoInteger(MQL_FORWARD), data, params); ... }
Com essas modificações, reiniciamos o EA de otimização automática e, finalmente, os resultados na tabela de passagens estavam corretos:
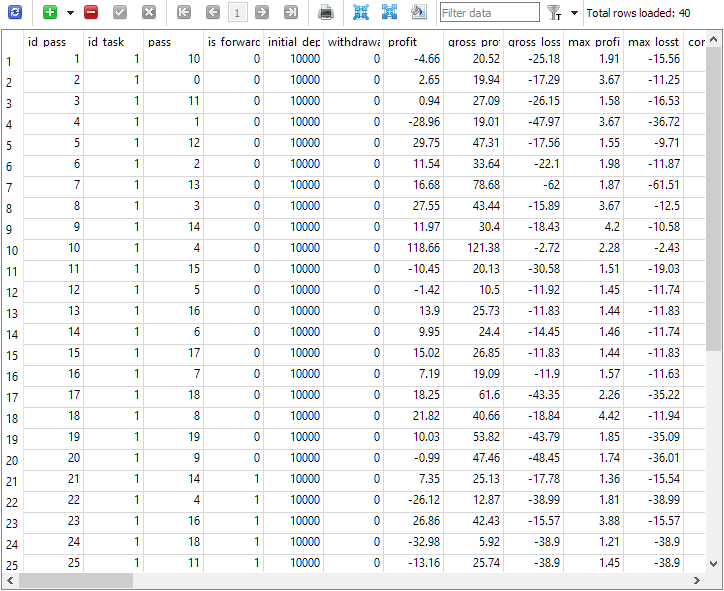
Fig. 1. Tabela de passagens passes após a execução da tarefa de otimização com período forward
Na tarefa de otimização com id_task = 1, foram realizadas 40 passagens no total. Destas, 20 foram normais (as primeiras 20 linhas com is_forward = 0), e as outras 20 foram passagens no período forward (is_forward = 1). Os números de passagem no testador na coluna pass variam de 1 a 20, e cada um aparece exatamente duas vezes (uma vez para o período principal e outra para o forward).
Preparação para a otimização completa
Após verificar que os resultados com períodos forward estavam sendo registrados corretamente, realizamos um teste mais próximo de condições reais. Para isso, adicionamos dois estágios a um banco de dados limpo. No primeiro estágio, otimizamos uma instância individual da estratégia de negociação em um único símbolo e período (EURGBP H1) entre 2018 e 2023. O período forward não será usado neste estágio. No segundo estágio, otimizamos um grupo de instâncias selecionadas no primeiro estágio. Agora com o período forward cobrindo todo o ano de 2023.

Fig. 2. Tabela de estágios stages com dois estágios
Para cada estágio, na tabela de trabalhos jobs, criamos trabalhos que serão executados no âmbito desse estágio. Nesta tabela, além do símbolo e período, especificamos os parâmetros de entrada para os EAs a serem otimizados, com intervalos e passos de alteração.
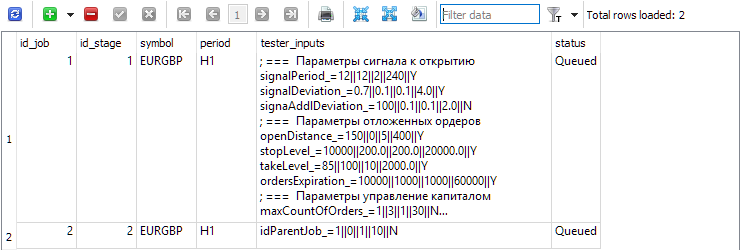
Fig. 3. Tabela de trabalhos jobs com dois trabalhos para o primeiro e segundo estágios, respectivamente
Para o primeiro trabalho (id_job = 1), criamos várias tarefas de otimização, diferenciadas pelo valor do critério de otimização (optimization_criterion = 0 ... 7). Iteramos por todos os critérios, usando o critério abrangente duas vezes: no início e no final do primeiro trabalho (optimization_criterion = 7). Para a tarefa do segundo trabalho (id_job = 2), utilizamos um critério de otimização personalizado (optimization_criterion = 6).
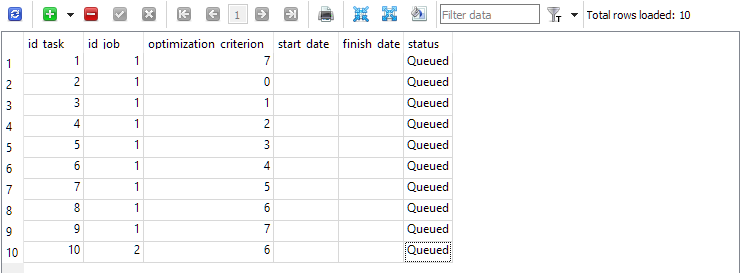
Fig. 4. Tabela de tarefas tasks com tarefas para o primeiro e segundo trabalhos
Executamos o EA de otimização automática em qualquer gráfico do terminal e aguardamos a conclusão de todas as tarefas. O processo, utilizando os agentes disponíveis, levou aproximadamente 4 horas.
Análise preliminar dos resultados
Durante o processo de otimização automática, havia apenas uma tarefa de otimização que utilizava o período forward. O critério de otimização escolhido foi o critério personalizado, que calcula o lucro médio anual normalizado para a passagem. Vamos observar o gráfico de dispersão dos valores desse critério no período principal.
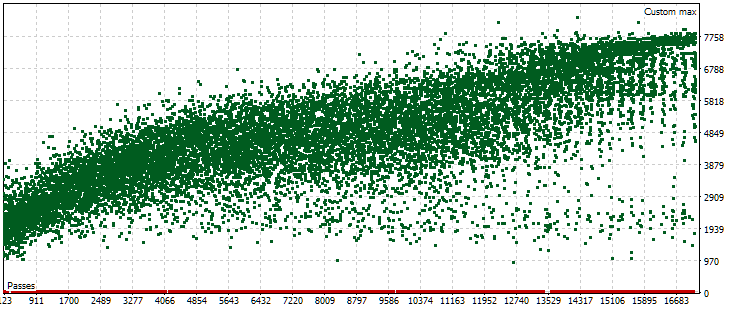
Fig. 5. O gráfico de dispersão dos valores do lucro médio anual normalizado para diferentes passagens no período principal
No gráfico, o valor do critério varia de $1000 a $8000. Os pontos vermelhos, correspondentes ao valor 0, surgem porque algumas combinações de índices das instâncias individuais nos parâmetros de entrada resultam em valores repetidos. Esses parâmetros de entrada são considerados como grupos de estratégias inválidos, e os resultados dessas passagens não são contabilizados. Nota-se uma tendência geral de aumento do lucro médio anual normalizado nas passagens mais avançadas. Em média, os melhores resultados alcançados são aproximadamente o dobro dos resultados iniciais, quando os parâmetros eram escolhidos quase aleatoriamente.
Agora, analisemos o gráfico de dispersão dos resultados das passagens no período forward. O número de passagens aqui será menor (cerca de 13.000 em vez de 17.000), devido às combinações de parâmetros consideradas inválidas na etapa principal.
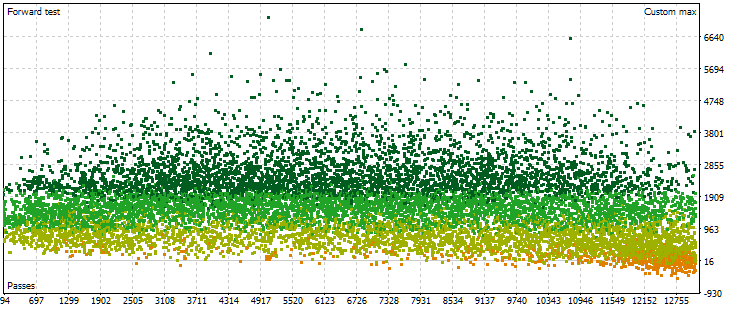
Fig. 6. O gráfico de dispersão dos valores do lucro médio anual normalizado para diferentes passagens no período forward
A distribuição dos pontos neste gráfico é diferente. Não há um aumento contínuo nos resultados conforme o número da passagem cresce. Pelo contrário, inicialmente, os resultados aumentam à medida que o número da passagem cresce, alcançando valores mais altos do que no início, mas, posteriormente, a tendência se inverte. Conforme o número da passagem aumenta, os resultados médios começam a diminuir, e a taxa de redução aumenta à medida que se aproxima da extremidade direita do gráfico.
Contudo, descobrimos que essa configuração nem sempre ocorre. Com outras configurações nos intervalos de parâmetros otimizados, os gráficos de dispersão para o período principal e o forward podem apresentar diferentes características.
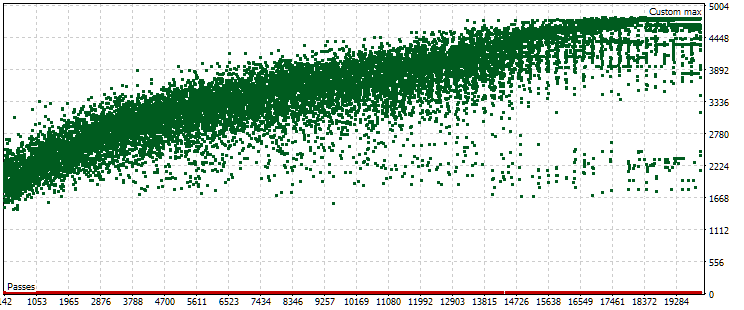
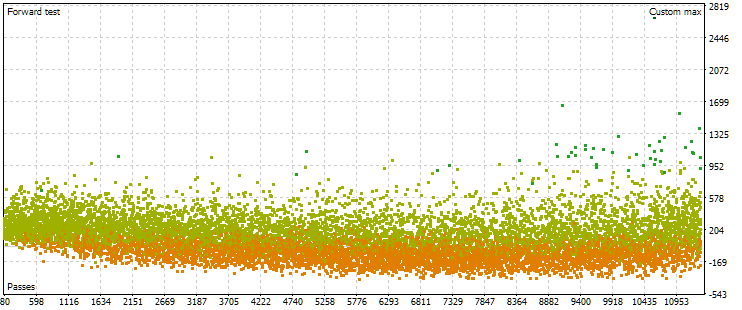
Fig. 7. O gráfico de dispersão dos valores do lucro médio anual normalizado no período principal e forward com outras configurações de otimização
Por exemplo, no período principal, o padrão é semelhante, mas o intervalo do critério agora é ligeiramente diferente: de $1500 a $5000. No entanto, no período forward, o padrão do gráfico de dispersão é completamente distinto. Os valores máximos não são alcançados no meio do processo de otimização, mas apenas próximo ao final. Além disso, em média, os valores do critério no período forward são cerca de 10 vezes menores do que os do período principal, em vez de 3 vezes, como observado no primeiro processo de otimização.
A intuição sugeria que, para aumentar a consistência dos resultados em diferentes períodos, deveríamos selecionar um grupo cujos resultados no período principal e no período forward fossem aproximadamente iguais. Contudo, os resultados obtidos levantaram dúvidas significativas sobre a utilidade dessa abordagem, especialmente quando os valores máximos do critério no período forward são visivelmente menores do que até mesmo os valores medianos no período principal. Apesar disso, seguiremos em frente. Procuraremos passagens "aproximadamente equivalentes" nos períodos principal e forward e analisaremos seus resultados em 2024.
Seleção das passagens
Vamos relembrar como selecionamos o melhor grupo considerando os resultados no período forward na parte 7. Aqui está um resumo do algoritmo, com algumas adaptações:
- Ajustamos o valor do lucro anual normalizado para as passagens no período forward, usando o maior rebaixamento (drawdown) entre os períodos principal e forward para o cálculo. Isso nos fornece o valor corrigido: OOS_ForwardResultCorrected.
- Na tabela consolidada com os resultados de otimização de 2018-2022 (período principal) e 2023 (período forward), calculamos as razões entre os valores de diversos indicadores nos dois períodos.
Por exemplo, para o número de operações: TradesRatio = OOS_Trades / IS_Trades, e para o lucro anual normalizado: ResultRatio = OOS_ForwardResultCorrected / IS_BackResult.
Quanto mais próximos esses valores estiverem de 1, mais semelhantes são os indicadores nos dois períodos. - Calculamos a soma das diferenças absolutas entre os valores das razões e 1 para todos os indicadores. Essa soma será a medida de diferença dos resultados de cada grupo nos períodos principal e forward:
SumDiff = |1 - ResultRatio| + ... + |1 - TradesRatio|. -
Considerando que o rebaixamento pode variar entre os períodos, escolhemos o valor máximo e calculamos um fator de escala para ajustar o tamanho das posições visando alcançar um rebaixamento normalizado de 10%:
Scale = 10 / MAX(OOS_EquityDD, IS_EquityDD).
-
Desejamos selecionar grupos onde SumDiff seja o menor possível e Scale o maior. Para isso, calculamos uma métrica final:
Res = Scale / SumDiff.
-
Classificamos os grupos em ordem decrescente de Res. Assim, no topo da tabela estarão os grupos com resultados mais consistentes entre os períodos principal e forward, e com menor rebaixamento em ambos os períodos.
Na parte 7, sugerimos repetir a seleção várias vezes, removendo previamente os grupos que continham índices de instâncias individuais já presentes nos grupos selecionados. Essa etapa seria especialmente relevante caso houvesse uma pré-clusterização das instâncias individuais, garantindo que diferentes índices representassem instâncias com resultados distintos. Como ainda não implementamos a clusterização na otimização automática, podemos ignorar esse passo por enquanto.
Em vez da etapa de exclusão, podemos adicionar um segundo nível de agrupamento para diferentes timeframes de cada símbolo e, em seguida, um terceiro nível para diferentes símbolos.
O algoritmo apresentado será ligeiramente refinado. Essencialmente, queremos entender o quão distantes estão dois conjuntos de resultados em um espaço cuja dimensionalidade é igual ao número de métricas comparadas. Até agora, usamos a norma de primeira ordem com um fator de escala para calcular a distância de um ponto, cujas coordenadas correspondem às razões dos resultados comparados, a partir de um ponto fixo com coordenadas unitárias. No entanto, entre essas razões, podem haver valores próximos a 1 e outros extremamente distantes. Esses valores mais distantes podem desproporcionalmente afetar a avaliação geral da distância. Portanto, tentaremos substituir essa abordagem por um cálculo da distância euclidiana padrão entre dois vetores de resultados, aplicando previamente a normalização min-max.
Será necessário elaborar uma consulta SQL relativamente complexa (embora existam consultas bem mais complicadas). Vamos detalhar o processo de criação da consulta necessária. Começaremos com consultas simples, adicionando complexidade gradualmente. Alguns dos resultados serão armazenados em tabelas temporárias para uso em consultas subsequentes. Após cada consulta, mostraremos como ficam os resultados.
Os dados de origem necessários estão, em sua maioria, na tabela passes. Confirmaremos que os registros estão presentes e filtraremos apenas as passagens relacionadas à tarefa de otimização desejada. No caso específico, o identificador da tarefa (id_task) correspondente à otimização da segunda etapa para EURGBP H1 é 10. Usaremos esse valor na consulta:
-- Запрос 1
SELECT *
FROM passes p0
WHERE p0.id_task = 10; 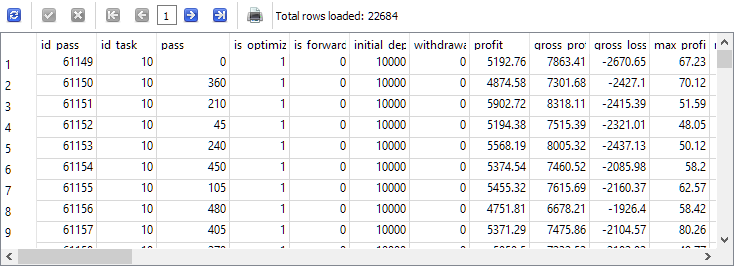
Verificamos que a tabela passes contém mais de 22 mil registros para a tarefa com id_task = 10.
No próximo passo, combinaremos em uma única linha os resultados de duas linhas desse conjunto de dados que correspondem ao mesmo número de passagem no testador, mas pertencem a diferentes períodos: principal e forward. Inicialmente, limitaremos o número de colunas exibidas no resultado. Mantendo apenas aquelas que permitem verificar a correta seleção das linhas. Nomearemos as colunas usando o seguinte padrão: adicionaremos o prefixo I_ para o período principal (In-Sample) e o prefixo O_ para o período forward (Out-Of-Sample):
-- Запрос 2 SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, p0.custom_ontester AS I_custom_ontester, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, p1.custom_ontester AS O_custom_ontester FROM passes p0 JOIN passes p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 WHERE p0.id_task = 10 AND p1.id_task = 10
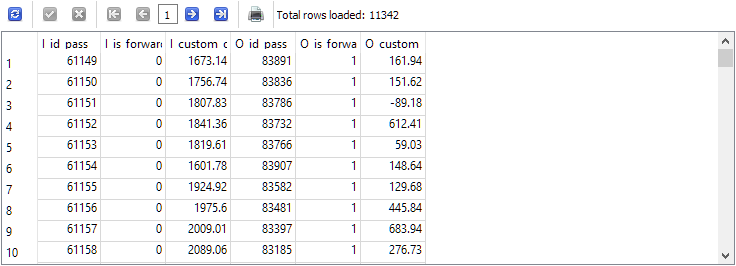
O número de linhas no resultado foi reduzido exatamente à metade, ou seja, para cada passagem no período principal, havia uma passagem correspondente no período forward na tabela passes, e vice-versa.
Agora, retornemos à normalização no primeiro conjunto de consultas. Se deixarmos a normalização para um estágio posterior, quando já tivermos colunas separadas para o mesmo parâmetro nos períodos principal e forward, será mais difícil calcular os valores mínimo e máximo para ambos os períodos simultaneamente. Escolheremos inicialmente um número reduzido de parâmetros para avaliar a "distância" entre os resultados nos dois períodos. Por exemplo, faremos o cálculo da distância com base em três parâmetros: custom_ontester, equity_dd_relative, profit_factor.
Precisamos transformar os valores dos parâmetros em colunas que contenham valores no intervalo de 0 a 1. Para isso, utilizaremos funções de janela (window functions) para obter os valores mínimo e máximo de cada coluna dentro da consulta. Para os nomes das colunas com valores escalonados, adicionaremos o prefixo s_ ao nome das colunas originais. Com os resultados retornados por esta consulta, criaremos e preencheremos uma nova tabela usando o comando adequado.
CREATE TABLE ... AS SELECT ... ;
Vamos examinar o conteúdo da tabela recém-criada e preenchida:
-- Запрос 3
DROP TABLE IF EXISTS t0;
CREATE TABLE t0 AS
SELECT id_pass,
pass,
is_forward,
custom_ontester,
(custom_ontester - MIN(custom_ontester) OVER () ) / (MAX(custom_ontester) OVER () - MIN(custom_ontester) OVER () ) AS s_custom_ontester,
equity_dd_relative,
(equity_dd_relative - MIN(equity_dd_relative) OVER () ) / (MAX(equity_dd_relative) OVER () - MIN(equity_dd_relative) OVER () ) AS s_equity_dd_relative,
profit_factor,
(profit_factor - MIN(profit_factor) OVER () ) / (MAX(profit_factor) OVER () - MIN(profit_factor) OVER () ) AS s_profit_factor
FROM passes
WHERE id_task=10;
SELECT * FROM t0; 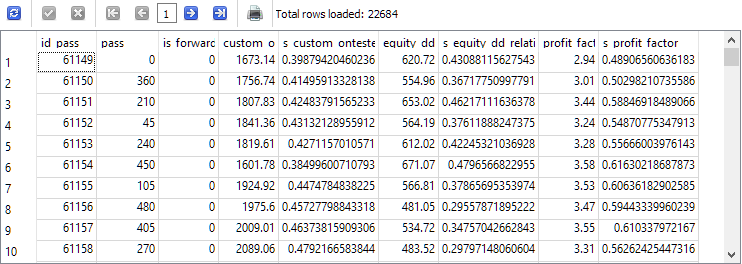
Como é possível observar, ao lado de cada parâmetro avaliado, aparece uma nova coluna contendo o valor escalonado desse parâmetro no intervalo de 0 a 1.
Agora, ajustaremos o texto da segunda consulta para que os dados sejam obtidos da nova tabela t0 em vez de passes e que os resultados sejam armazenados em outra nova tabela, chamada t1. Utilizaremos os valores já escalonados e os arredondaremos para maior conveniência. Também manteremos apenas as linhas em que os valores de lucro normalizado nos períodos principal e forward sejam positivos:
-- Запрос 4 DROP TABLE IF EXISTS t1; CREATE TABLE t1 AS SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, ROUND(p0.s_custom_ontester, 4) AS I_custom_ontester, ROUND(p0.s_equity_dd_relative, 4) AS I_equity_dd_relative, ROUND(p0.s_profit_factor, 4) AS I_profit_factor, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, ROUND(p1.s_custom_ontester, 4) AS O_custom_ontester, ROUND(p1.s_equity_dd_relative, 4) AS O_equity_dd_relative, ROUND(p1.s_profit_factor, 4) AS O_profit_factor FROM t0 p0 JOIN t0 p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 AND p0.custom_ontester > 0 AND p1.custom_ontester > 0; SELECT * FROM t1;
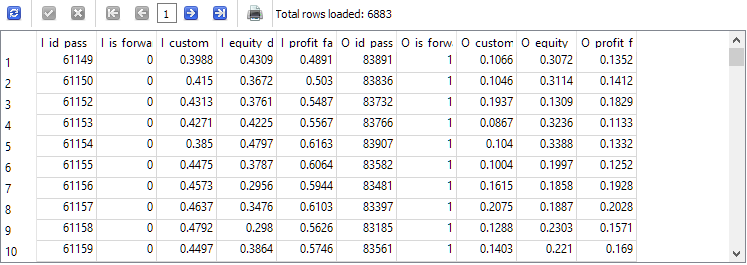
O número de linhas foi reduzido em aproximadamente um terço em relação à segunda consulta, mas agora temos apenas passagens nas quais houve lucro em ambos os períodos.
Finalmente, chegamos ao último passo no desenvolvimento da consulta. Precisamos calcular a distância entre as combinações de parâmetros para os períodos principal e forward em cada linha da tabela t1 e classificá-las em ordem crescente de distância:
-- Запрос 5 SELECT ROUND(POW((I_custom_ontester - O_custom_ontester), 2) + POW( (I_equity_dd_relative - O_equity_dd_relative), 2) + POW( (I_profit_factor - O_profit_factor), 2), 4) AS dist, * FROM t1 ORDER BY dist ASC;
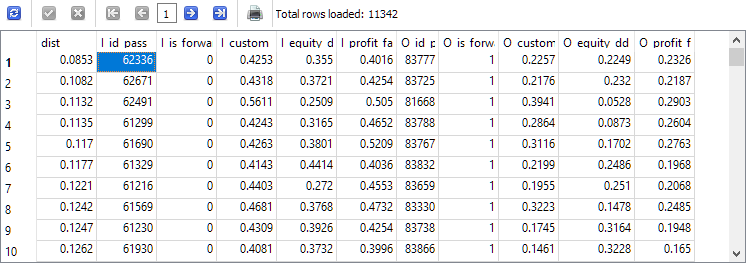
O identificador da passagem I_id_pass na primeira linha dos resultados obtidos corresponderá à passagem com a menor distância entre os valores dos resultados nos períodos principal e forward.
Selecionamos esse identificador e o do melhor resultado de lucro normalizado no período principal. Como eles não coincidem, criaremos a biblioteca de parâmetros para o EA final com base em ambos, conforme descrito no artigo anterior. Foi necessário fazer pequenas alterações nos arquivos adicionados na parte anterior para permitir a especificação de um banco de dados específico ao criar e exportar a biblioteca de conjuntos de parâmetros.
Resultados
Agora, a biblioteca contém duas configurações. A primeira configuração, chamada "Best for dist(IS, OS) (2018-2023)" — corresponde à melhor passagem de otimização com a menor distância entre os valores dos parâmetros. A segunda configuração, chamada "Best on IS (2018-2022)" — corresponde à melhor passagem de otimização com base no lucro normalizado no período principal de 2018 a 2022.
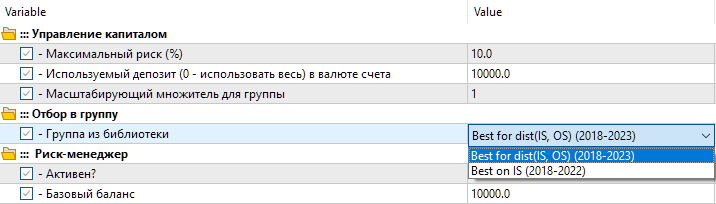
Fig. 8. Escolha do grupo de configurações da biblioteca no EA final
Vamos observar os resultados dessas duas configurações no período de 2018 a 2023, que foi totalmente utilizado na otimização.
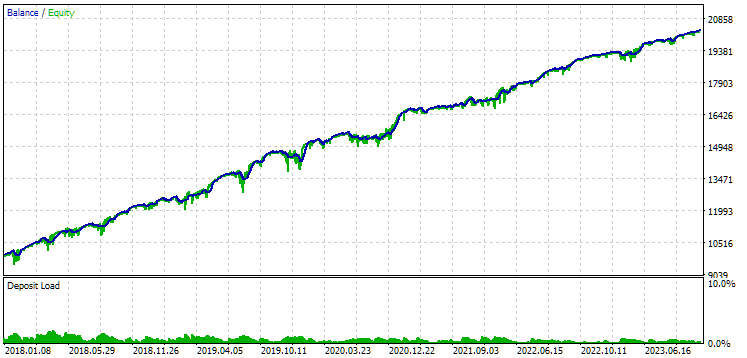
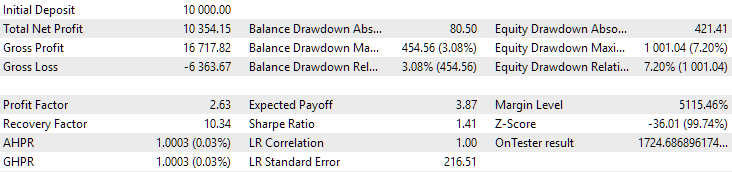
Fig. 9. Resultados da primeira configuração (melhor em distância) no período de 2018-2023
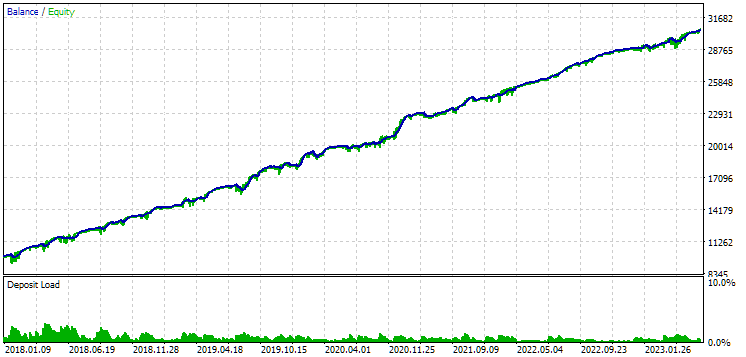
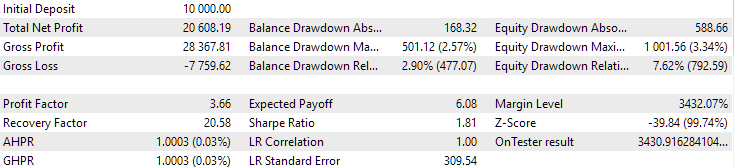
Fig. 10. Resultados da segunda configuração (melhor em lucro) no período de 2018-2023
Vemos que ambas as configurações estão bem normalizadas neste período de tempo (a máxima redução do saldo é de $1000 em ambos os casos). No entanto, a primeira configuração apresenta um lucro médio anual cerca de duas vezes menor que o da segunda ($1724 contra $3430). Por enquanto, as vantagens da primeira configuração não são evidentes.
Agora vamos analisar os resultados dessas duas configurações no ano de 2024 (até outubro), período que não foi utilizado na otimização.
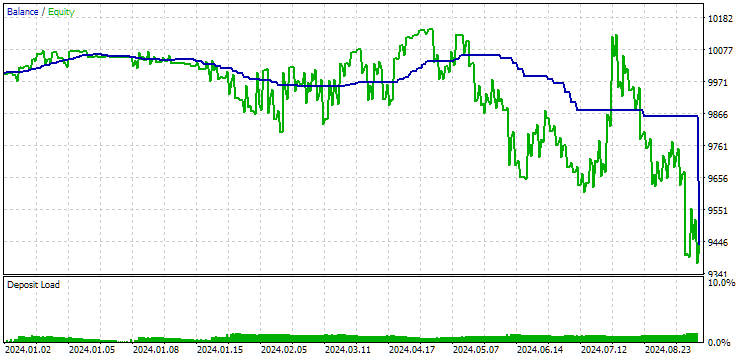
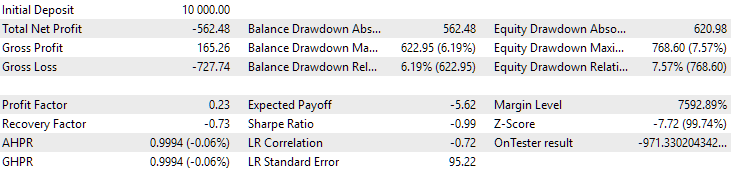
Fig. 11. Resultados da primeira configuração (melhor em distância) no período de 2024
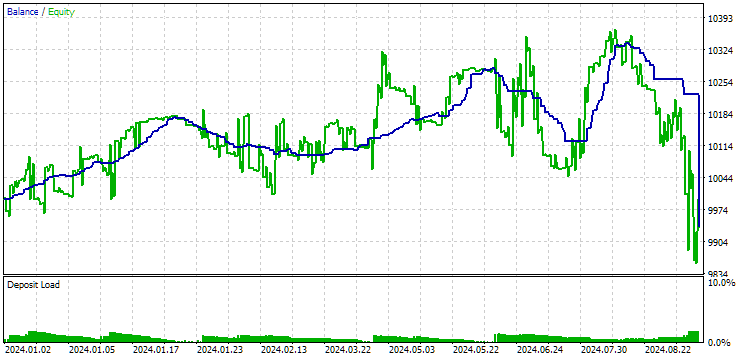
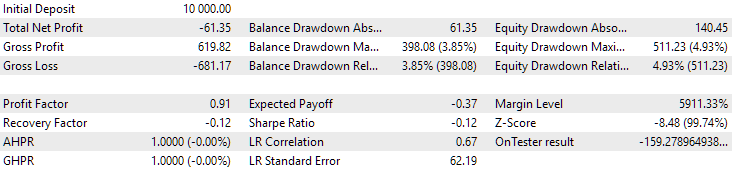
Fig. 12. Resultados da segunda configuração (melhor em lucro) no período de 2024
Neste período, ambos os resultados foram negativos, mas a segunda configuração ainda se mostrou melhor que a primeira. É importante notar que, neste intervalo, o rebaixamento máximo permaneceu sempre abaixo de $1000.
Como 2024 não foi um ano particularmente favorável para este símbolo, examinemos os resultados em um período anterior à otimização. Aproveitaremos para escolher um intervalo mais longo (três anos, de 2015 a 2017).
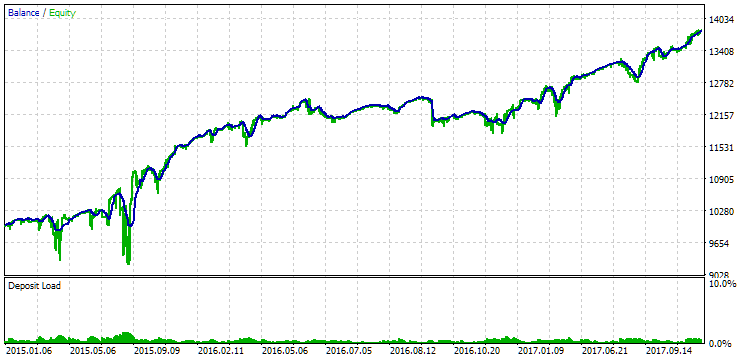
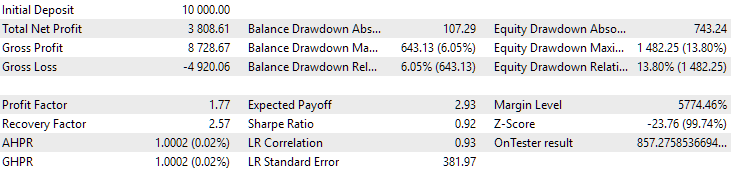
Fig. 13. Resultados da primeira configuração (melhor em distância) no período de 2015-2017
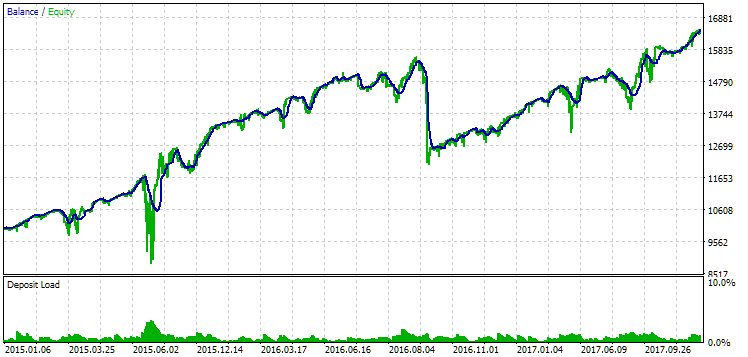
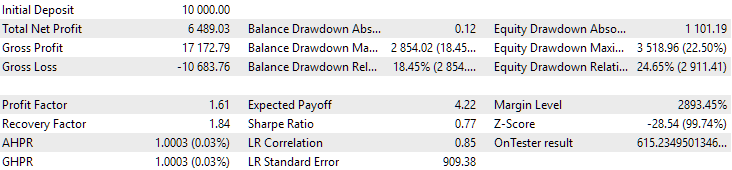
Fig. 14. Resultados da segunda configuração (melhor em lucro) no período de 2015-2017
Neste intervalo, o rebaixamento já excedeu o limite calculado. No primeiro caso, foi cerca de 1,5 vezes maior, enquanto no segundo, ultrapassou em aproximadamente 3,5 vezes. Nesse aspecto, o primeiro caso é um pouco melhor, pois o excesso de rebaixamento é significativamente menor e, em geral, aceitável. Além disso, na primeira configuração, não há uma queda acentuada no gráfico no meio do período, como ocorre na segunda configuração. Assim, o primeiro caso demonstrou uma adaptabilidade melhor a um período histórico desconhecido. Entretanto, em termos de lucro médio anual normalizado, a diferença entre as duas configurações não é tão grande ($857 contra $615). No entanto, essa métrica para um período desconhecido não pode ser antecipada.
Portanto, neste intervalo, a preferência é dada ao primeiro caso. Vamos às conclusões.
Considerações finais
Implementamos a automação do segundo estágio de otimização utilizando o período forward. Mais uma vez, não foram identificadas vantagens claras. A tarefa acabou sendo muito mais abrangente e exigiu mais tempo do que inicialmente previsto. Durante o processo, surgiram várias novas questões que ainda aguardam respostas.
Observamos que, se o período forward coincidir com um intervalo de desempenho desfavorável do EA, parece improvável que ele permita selecionar boas combinações de parâmetros.
Se a duração das operações for longa, os resultados de passagens interrompidas na fronteira entre os períodos principal e forward podem diferir significativamente dos resultados de passagens contínuas. Isso também coloca em dúvida a eficácia do uso do período forward nesse formato. Não estamos questionando o conceito de período forward em si, mas sim sua aplicação como um método para selecionar automaticamente parâmetros que provavelmente apresentam resultados consistentes no futuro.
Neste estudo, utilizamos um método simples para calcular a distância entre os resultados das passagens. É possível que a complexidade desse cálculo melhore os resultados. Além disso, ainda não implementamos a automação para selecionar automaticamente as melhores passagens para inclusão nos grupos de conjuntos para diferentes símbolos e timeframes. Quase tudo está pronto para isso; bastaria que o EA executasse os SQL criados. No entanto, como esses scripts ainda devem passar por ajustes, essa automação será deixada para o futuro.
Obrigado pela atenção e até a próxima!
Aviso importante
Todos os resultados apresentados neste artigo e nos artigos anteriores desta série baseiam-se exclusivamente em dados de teste histórico e não garantem qualquer lucro futuro. O trabalho neste projeto é de caráter exploratório. Todos os resultados publicados podem ser utilizados por qualquer pessoa, sob sua inteira responsabilidade.
Conteúdo do arquivo
| # | Nome | Versão | Descrição | Últimas alterações |
|---|---|---|---|---|
| MQL5/Experts/Article.15683 | ||||
| 1 | Advisor.mqh | 1.04 | Classe base do EA | Parte 10 |
| 2 | Database.mqh | 1.05 | Classe para trabalho com banco de dados | Parte 18 |
| 3 | database.sqlite.schema.sql | — | Esquema do banco de dados | Parte 18 |
| 4 | ExpertHistory.mqh | 1.00 | Classe para exportação do histórico de negociações para arquivo | Parte 16 |
| 5 | ExportedGroupsLibrary.mqh | — | Arquivo gerado com a lista de nomes de grupos de estratégias e o array de suas strings de inicialização | Parte 17 |
| 6 | Factorable.mqh | 1.01 | Classe base para objetos criados a partir de strings | Parte 10 |
| 7 | GroupsLibrary.mqh | 1.01 | Classe para gerenciamento da biblioteca de grupos selecionados de estratégias | Parte 18 |
| 8 | HistoryReceiverExpert.mq5 | 1.00 | EA para reprodução do histórico de negociações com gerenciador de risco | Parte 16 |
| 9 | HistoryStrategy.mqh | 1.00 | Classe de estratégia de negociação para reprodução do histórico | Parte 16 |
| 10 | Interface.mqh | 1.00 | Classe base para visualização de vários objetos | Parte 4 |
| 11 | LibraryExport.mq5 | 1.01 | EA que salva strings de inicialização de passes selecionados da biblioteca no arquivo ExportedGroupsLibrary.mqh | Parte 18 |
| 12 | Macros.mqh | 1.02 | Macros úteis para operações com arrays | Parte 16 |
| 13 | Money.mqh | 1.01 | Classe base para gerenciamento de capital | Parte 12 |
| 14 | NewBarEvent.mqh | 1.00 | Classe para definição de novos bares para símbolos específicos | Parte 8 |
| 15 | Optimization.mq5 | 1.02 | EA que gerencia a execução de tarefas de otimização | Parte 18 |
| 16 | Receiver.mqh | 1.04 | Classe base para tradução de volumes abertos em posições de mercado | Parte 12 |
| 17 | SimpleHistoryReceiverExpert.mq5 | 1.00 | EA simplificado para reprodução do histórico de negociações | Parte 16 |
| 18 | SimpleVolumesExpert.mq5 | 1.20 | EA para operação paralela de múltiplos grupos de estratégias modelo. Os parâmetros serão retirados da biblioteca embutida de grupos. | Parte 17 |
| 19 | SimpleVolumesStage1.mq5 | 1.17 | EA para otimização de instância única de estratégia de negociação (Etapa 1) | Parte 18 |
| 20 | SimpleVolumesStage2.mq5 | 1.01 | EA para otimização de grupo de instâncias de estratégias de negociação (Etapa 2) | Parte 18 |
| 21 | SimpleVolumesStage3.mq5 | 1.01 | EA que salva o grupo normalizado de estratégias na biblioteca de grupos com nome especificado. | Parte 18 |
| 22 | SimpleVolumesStrategy.mqh | 1.09 | Classe de estratégia de negociação utilizando volumes em ticks | Parte 15 |
| 23 | Strategy.mqh | 1.04 | Classe base para estratégias de negociação | Parte 10 |
| 24 | TesterHandler.mqh | 1.04 | Classe para gerenciamento de eventos de otimização | Parte 18 |
| 25 | VirtualAdvisor.mqh | 1.07 | Classe do EA que opera com posições virtuais (ordens) | Parte 18 |
| 26 | VirtualChartOrder.mqh | 1.01 | Classe de posição virtual gráfica | Parte 18 |
| 27 | VirtualFactory.mqh | 1.04 | Classe fábrica de objetos | Parte 16 |
| 28 | VirtualHistoryAdvisor.mqh | 1.00 | Classe do EA para reprodução do histórico de negociações | Parte 16 |
| 29 | VirtualInterface.mqh | 1.00 | Classe de interface gráfica do EA | Parte 4 |
| 30 | VirtualOrder.mqh | 1.04 | Classe de ordens e posições virtuais | Parte 8 |
| 31 | VirtualReceiver.mqh | 1.03 | Classe para conversão de volumes abertos em posições de mercado (receptor) | Parte 12 |
| 32 | VirtualRiskManager.mqh | 1.02 | Classe de gerenciamento de risco (gerenciador de risco) | Parte 15 |
| 33 | VirtualStrategy.mqh | 1.05 | Classe de estratégia de negociação com posições virtuais | Parte 15 |
| 34 | VirtualStrategyGroup.mqh | 1.00 | Classe de grupo de estratégias de negociação ou grupos de estratégias | Parte 11 |
| 35 | VirtualSymbolReceiver.mqh | 1.00 | Classe de receptor simbólico | Parte 3 |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/15683
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso