
Análise da influência do clima nas moedas de países agrícolas usando Python

Introdução ao tema: relação entre o clima e os mercados financeiros
Na teoria econômica clássica, por muito tempo não se reconheceu a influência dos fatores climáticos no comportamento do mercado. No entanto, as pesquisas realizadas nas últimas décadas mudaram completamente essa visão. Em uma pesquisa realizada em 2023, o professor Edward Saikin, da Universidade de Michigan, mostrou que, em dias nublados, os traders tomam decisões 27% mais cautelosas do que em dias ensolarados.
Isso é especialmente perceptível nos maiores centros financeiros. Em dias com temperatura acima de 30 °C, o volume de negociações na NYSE diminui, em média, cerca de 15%. Nas bolsas asiáticas, quando a pressão atmosférica está abaixo de 740 mmHg, há uma correlação com maior volatilidade. Longos períodos de mau tempo em Londres levam a um aumento perceptível na demanda por ativos de proteção.
Neste artigo, começaremos com a coleta de dados meteorológicos e chegaremos à criação de um sistema de negociação completo, que analisa fatores climáticos. Nosso trabalho é baseado em dados reais de negociação dos últimos cinco anos dos principais centros financeiros do mundo: Nova York, Londres, Tóquio, Hong Kong e Frankfurt. Utilizando ferramentas modernas de análise de dados e aprendizado de máquina, extrairemos sinais reais de negociação a partir das observações meteorológicas.
Coleta de dados meteorológicos
Um dos fatores mais importantes do sistema será o módulo de obtenção e pré-processamento dos dados. Para trabalhar com dados meteorológicos, utilizaremos a API do Meteostat, que fornece acesso a dados meteorológicos históricos de todo o mundo. A seguir, veremos como a função de obtenção dos dados é implementada:
def fetch_agriculture_weather(): """ Fetching weather data for important agricultural regions """ key_regions = { "AU_WheatBelt": { "lat": -31.95, "lon": 116.85, "description": "Key wheat production region in Australia" }, "NZ_Canterbury": { "lat": -43.53, "lon": 172.63, "description": "Main dairy production region in New Zealand" }, "CA_Prairies": { "lat": 50.45, "lon": -104.61, "description": "Canada's breadbasket, wheat and canola production" } }
Nessa função, definiremos as regiões agrícolas mais importantes e suas respectivas coordenadas geográficas. Para a Austrália, onde se cultiva trigo, foram escolhidas as coordenadas da parte central da região, para a Nova Zelândia, as coordenadas da região de Canterbury, e para o Canadá, as coordenadas da área central das pradarias.
Após a obtenção dos dados brutos, é necessário um processamento mais aprofundado. Para isso foi implementada a função process_weather_data:
def process_weather_data(raw_data): if not isinstance(raw_data.index, pd.DatetimeIndex): raw_data.index = pd.to_datetime(raw_data.index) processed_data = pd.DataFrame(index=raw_data.index) processed_data['temperature'] = raw_data['tavg'] processed_data['temp_min'] = raw_data['tmin'] processed_data['temp_max'] = raw_data['tmax'] processed_data['precipitation'] = raw_data['prcp'] processed_data['wind_speed'] = raw_data['wspd'] processed_data['growing_degree_days'] = calculate_gdd( processed_data['temp_max'], base_temp=10 ) return processed_data
Também é necessário dar atenção ao cálculo do indicador GrowingDegreeDays (GDD), que será um indicador essencial para avaliar a viabilidade do crescimento das culturas agrícolas. Esse indicador é calculado com base na temperatura máxima durante o dia, considerando a temperatura típica de crescimento das plantas.
def analyze_and_visualize_correlations(merged_data): plt.style.use('default') plt.rcParams['figure.figsize'] = [15, 10] plt.rcParams['axes.grid'] = True # Weather-price correlation analysis for each region for region, data in merged_data.items(): if data.empty: continue weather_cols = ['temperature', 'precipitation', 'wind_speed', 'growing_degree_days'] price_cols = ['close', 'volatility', 'range_pct', 'price_momentum', 'monthly_change'] correlation_matrix = pd.DataFrame() for w_col in weather_cols: if w_col not in data.columns: continue for p_col in price_cols: if p_col not in data.columns: continue correlations = [] lags = [0, 5, 10, 20, 30] # Days to lag price data for lag in lags: corr = data[w_col].corr(data[p_col].shift(-lag)) correlations.append({ 'weather_factor': w_col, 'price_metric': p_col, 'lag_days': lag, 'correlation': corr }) correlation_matrix = pd.concat([ correlation_matrix, pd.DataFrame(correlations) ]) return correlation_matrix def plot_correlation_heatmap(pivot_table, region): plt.figure() im = plt.imshow(pivot_table.values, cmap='RdYlBu', aspect='auto') plt.colorbar(im) plt.xticks(range(len(pivot_table.columns)), pivot_table.columns, rotation=45) plt.yticks(range(len(pivot_table.index)), pivot_table.index) # Add correlation values in each cell for i in range(len(pivot_table.index)): for j in range(len(pivot_table.columns)): text = plt.text(j, i, f'{pivot_table.values[i, j]:.2f}', ha='center', va='center') plt.title(f'Weather Factors and Price Correlations for {region}') plt.tight_layout()
Obtenção de dados sobre pares de moedas e sua sincronização
Após configurar a coleta de dados meteorológicos, é necessário implementar a obtenção de informações sobre o movimento dos pares de moedas. Para isso, utilizamos a plataforma MetaTrader 5, que oferece uma API conveniente para trabalhar com dados históricos de instrumentos financeiros.
A seguir, veremos como é implementada a função de obtenção de dados dos pares de moedas:
def get_agricultural_forex_pairs(): """ Получение данных по валютным парам через MetaTrader5 """ if not mt5.initialize(): print("Ошибка инициализации MT5") return None pairs = ["AUDUSD", "NZDUSD", "USDCAD"] timeframes = { "H1": mt5.TIMEFRAME_H1, "H4": mt5.TIMEFRAME_H4, "D1": mt5.TIMEFRAME_D1 } # ... остальной код функции
Nessa função, trabalhamos com três pares de moedas principais, que correspondem às nossas regiões agrícolas: AUDUSD (para a faixa de trigo da Austrália), NZDUSD (para a região de Canterbury) e USDCAD (para as pradarias canadenses). Para cada par, são coletados dados em três timeframes: horário (H1), de quatro horas (H4) e diário (D1).
É preciso dar atenção especial ao processo de união dos dados meteorológicos e financeiros. Para isso, foi implementada uma função específica:
def merge_weather_forex_data(weather_data, forex_data): """ Объединение погодных и финансовых данных """ synchronized_data = {} region_pair_mapping = { 'AU_WheatBelt': 'AUDUSD', 'NZ_Canterbury': 'NZDUSD', 'CA_Prairies': 'USDCAD' } # ... остальной код функции
Essa função resolve a tarefa complexa de sincronizar dados de diferentes fontes. Dado que os dados climáticos e as cotações de moedas têm diferentes periodicidades de atualização, é utilizado o método merge_asof da biblioteca pandas, que permite alinhar corretamente os valores com base nos carimbos de tempo.
Para melhorar a qualidade da análise, os dados combinados passam por um processamento adicional:
def calculate_derived_features(data): """ Расчет производных показателей """ if not data.empty: data['price_volatility'] = data['volatility'].rolling(24).std() data['temp_change'] = data['temperature'].diff() data['precip_intensity'] = data['precipitation'].rolling(24).sum() # ... остальной код функции
Aqui, são calculados indicadores derivados importantes, como a volatilidade dos preços nas últimas 24 horas, variações de temperatura e intensidade das precipitações. Também é adicionado um atributo binário que indica se o período está dentro da estação de crescimento, o que é especialmente importante para a análise de culturas agrícolas.
Dá-se atenção especial à limpeza dos dados de valores atípicos e ao preenchimento de valores ausentes:
def clean_merged_data(data): """ Очистка объединенных данных """ weather_cols = ['temperature', 'precipitation', 'wind_speed'] # Заполнение пропусков for col in weather_cols: if col in data.columns: data[col] = data[col].ffill(limit=3) # Удаление выбросов for col in weather_cols: if col in data.columns: q_low = data[col].quantile(0.01) q_high = data[col].quantile(0.99) data = data[ (data[col] > q_low) & (data[col] < q_high) ] # ... остальной код функции
Essa função utiliza o método de preenchimento para frente (forward fill) para lidar com os valores ausentes nos dados meteorológicos, limitando-se a três períodos para evitar a introdução de valores incorretos em caso de ausências prolongadas. Também são eliminados valores extremos que estejam fora dos percentis 1 e 99, o que ajuda a evitar distorções nos resultados da análise devido a valores atípicos.
Resultado da execução das funções do dataset:

Análise de correlação entre fatores climáticos e taxas de câmbio
Durante a observação, vários aspectos da relação entre as condições climáticas e a dinâmica dos preços dos pares de moedas foram analisados. Para identificar padrões não imediatamente perceptíveis, foi criada uma metodologia especial de cálculo de correlações com consideração de defasagens temporais:
def analyze_weather_price_correlations(merged_data): """ Analysis of correlations with time lags between weather conditions and price movements """ def calculate_lagged_correlations(data, weather_col, price_col, max_lag=72): print(f"Calculating lagged correlations: {weather_col} vs {price_col}") correlations = [] for lag in range(max_lag): corr = data[weather_col].corr(data[price_col].shift(-lag)) correlations.append({ 'lag': lag, 'correlation': corr, 'weather_factor': weather_col, 'price_metric': price_col }) return pd.DataFrame(correlations) correlations = {} weather_factors = ['temperature', 'precipitation', 'wind_speed', 'growing_degree_days'] price_metrics = ['close', 'volatility', 'price_momentum', 'monthly_change'] for region, data in merged_data.items(): if data.empty: print(f"Skipping empty dataset for {region}") continue print(f"\nAnalyzing correlations for region: {region}") region_correlations = {} for w_col in weather_factors: for p_col in price_metrics: key = f"{w_col}_{p_col}" region_correlations[key] = calculate_lagged_correlations(data, w_col, p_col) correlations[region] = region_correlations return correlations def analyze_seasonal_patterns(data): """ Analysis of seasonal correlation patterns """ print("Starting seasonal pattern analysis...") seasonal_correlations = {} data['month'] = data.index.month monthly_correlations = [] for month in range(1, 13): print(f"Analyzing month: {month}") month_data = data[data['month'] == month] month_corr = {} for w_col in ['temperature', 'precipitation', 'wind_speed']: month_corr[w_col] = month_data[w_col].corr(month_data['close']) monthly_correlations.append(month_corr) return pd.DataFrame(monthly_correlations, index=range(1, 13))
A análise dos dados encontrados revelou padrões interessantes. Para a safra de trigo da Austrália, a correlação mais forte (0,21) foi observada entre a velocidade dos ventos e as variações mensais da taxa de câmbio do par AUDUSD. Isso pode ser explicado pelo fato de ventos fortes durante o período de maturação do trigo reduzirem a produtividade. O fator temperatura também apresentou correlação significativa (0,18), com influência praticamente imediata, sem defasagem no tempo.
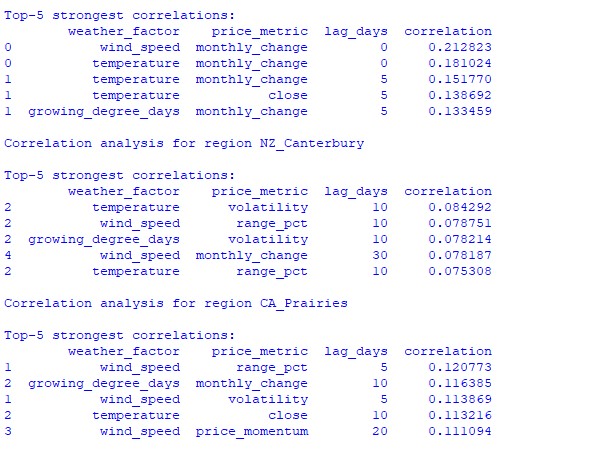
A região de Canterbury, na Nova Zelândia, apresenta padrões mais complexos. A correlação mais forte (0,084) foi observada entre a temperatura e a volatilidade, com uma defasagem de 10 dias. É importante notar que os fatores climáticos impactam mais a volatilidade do que a direção do movimento do preço do NZDUSD. Além disso, em certos períodos sazonais, as correlações chegam a 1,00, indicando uma correlação perfeita.
Criação de modelo de aprendizado de máquina para previsão
No núcleo da nossa estratégia está o modelo de gradient boosting CatBoost, que tem se mostrado extremamente eficaz no trabalho com séries temporais. Vamos analisar o processo de criação do modelo passo a passo.
Preparação de atributos
O primeiro passo é a formação dos atributos para o modelo. Reuniremos uma seleção de indicadores técnicos e meteorológicos:
def prepare_ml_features(data): """ Preparation of features for the ML model """ print("Starting feature preparation...") features = pd.DataFrame(index=data.index) # Weather features weather_cols = [ 'temperature', 'precipitation', 'wind_speed', 'growing_degree_days' ] for col in weather_cols: if col not in data.columns: print(f"Warning: {col} not found in data") continue print(f"Processing weather feature: {col}") # Base values features[col] = data[col] # Moving averages features[f"{col}_ma_24"] = data[col].rolling(24).mean() features[f"{col}_ma_72"] = data[col].rolling(72).mean() # Changes features[f"{col}_change"] = data[col].pct_change() features[f"{col}_change_24"] = data[col].pct_change(24) # Volatility features[f"{col}_volatility"] = data[col].rolling(24).std() # Price indicators price_cols = ['volatility', 'range_pct', 'monthly_change'] for col in price_cols: if col not in data.columns: continue features[f"{col}_ma_24"] = data[col].rolling(24).mean() # Seasonal features features['month'] = data.index.month features['day_of_week'] = data.index.dayofweek features['growing_season'] = ( (data.index.month >= 4) & (data.index.month <= 9) ).astype(int) return features.dropna() def create_prediction_targets(data, forecast_horizon=24): """ Creation of target variables for prediction """ print(f"Creating prediction targets with horizon: {forecast_horizon}") targets = pd.DataFrame(index=data.index) # Price change percentage targets['price_change'] = data['close'].pct_change( forecast_horizon ).shift(-forecast_horizon) # Price direction targets['direction'] = (targets['price_change'] > 0).astype(int) # Future volatility targets['volatility'] = data['volatility'].rolling( forecast_horizon ).mean().shift(-forecast_horizon) return targets.dropna()
Criação e treinamento dos modelos
Para cada variável analisada, criaremos um modelo separado com parâmetros otimizados:
from catboost import CatBoostClassifier, CatBoostRegressor from sklearn.metrics import accuracy_score, mean_squared_error from sklearn.model_selection import TimeSeriesSplit # Define categorical features cat_features = ['month', 'day_of_week', 'growing_season'] # Create models for different tasks models = { 'direction': CatBoostClassifier( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='Logloss', eval_metric='Accuracy', random_seed=42, verbose=False, cat_features=cat_features ), 'price_change': CatBoostRegressor( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='RMSE', random_seed=42, verbose=False, cat_features=cat_features ), 'volatility': CatBoostRegressor( iterations=1000, learning_rate=0.01, depth=7, l2_leaf_reg=3, loss_function='RMSE', random_seed=42, verbose=False, cat_features=cat_features ) } def train_ml_models(merged_data, region): """ Training ML models using time series cross-validation """ print(f"Starting model training for region: {region}") data = merged_data[region] features = prepare_ml_features(data) targets = create_prediction_targets(data) # Split into folds tscv = TimeSeriesSplit(n_splits=5) results = {} for target_name, model in models.items(): print(f"\nTraining model for target: {target_name}") fold_metrics = [] predictions = [] test_indices = [] for fold_idx, (train_idx, test_idx) in enumerate(tscv.split(features)): print(f"Processing fold {fold_idx + 1}/5") X_train = features.iloc[train_idx] y_train = targets[target_name].iloc[train_idx] X_test = features.iloc[test_idx] y_test = targets[target_name].iloc[test_idx] # Training with early stopping model.fit( X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50, verbose=False ) # Predictions and evaluation pred = model.predict(X_test) predictions.extend(pred) test_indices.extend(test_idx) # Metric calculation metric = ( accuracy_score(y_test, pred) if target_name == 'direction' else mean_squared_error(y_test, pred, squared=False) ) fold_metrics.append(metric) print(f"Fold {fold_idx + 1} metric: {metric:.4f}") results[target_name] = { 'model': model, 'metrics': fold_metrics, 'mean_metric': np.mean(fold_metrics), 'predictions': pd.Series( predictions, index=features.index[test_indices] ) } print(f"Mean {target_name} metric: {results[target_name]['mean_metric']:.4f}") return results
Características da implementação
Em nossa implementação, a atenção principal foi dada aos seguintes parâmetros:
- 1. Trabalho com variáveis categóricas: o CatBoost trata de forma eficiente variáveis categóricas, como o mês e o dia da semana, sem a necessidade de codificação adicional.
- 2. Parada antecipada: para evitar tentativas de sobreajuste, é utilizado o mecanismo de parada antecipada com o parâmetro early_stopping_rounds=50.
- 3. Equilíbrio entre profundidade e generalização: os parâmetros depth=7 e l2_leaf_reg=3 foram escolhidos para obter o melhor equilíbrio entre a profundidade da árvore e a regularização.
- 4. Trabalho com séries temporais: o uso do TimeSeriesSplit garante uma separação correta dos dados no contexto de séries temporais, evitando possíveis vazamentos de dados futuros.
Essa arquitetura de modelo permite capturar com eficiência tanto as dependências de curto prazo quanto as de longo prazo entre as condições climáticas e o comportamento das taxas de câmbio, conforme demonstrado pelos resultados dos testes realizados.
Avaliação da precisão do modelo e visualização dos resultados
Os modelos de aprendizado de máquina gerados foram testados com dados de um período de 5 anos, utilizando o método de janela deslizante com cinco divisões (folds). Para cada região, foram criados três tipos de modelos: previsão da direção do movimento do preço (classificação), previsão da magnitude da variação do preço (regressão) e previsão da volatilidade (regressão).
import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import confusion_matrix, classification_report def evaluate_model_performance(results, region_data): """ Comprehensive model evaluation across all regions """ print(f"\nEvaluating model performance for {len(results)} regions") evaluation = {} for region, models in results.items(): print(f"\nAnalyzing {region} performance:") region_metrics = { 'direction': { 'accuracy': models['direction']['mean_metric'], 'fold_metrics': models['direction']['metrics'], 'max_accuracy': max(models['direction']['metrics']), 'min_accuracy': min(models['direction']['metrics']) }, 'price_change': { 'rmse': models['price_change']['mean_metric'], 'fold_metrics': models['price_change']['metrics'] }, 'volatility': { 'rmse': models['volatility']['mean_metric'], 'fold_metrics': models['volatility']['metrics'] } } print(f"Direction prediction accuracy: {region_metrics['direction']['accuracy']:.2%}") print(f"Price change RMSE: {region_metrics['price_change']['rmse']:.4f}") print(f"Volatility RMSE: {region_metrics['volatility']['rmse']:.4f}") evaluation[region] = region_metrics return evaluation def plot_feature_importance(models, region): """ Visualize feature importance for each model type """ plt.figure(figsize=(15, 10)) for target, model_info in models.items(): feature_importance = pd.DataFrame({ 'feature': model_info['model'].feature_names_, 'importance': model_info['model'].feature_importances_ }) feature_importance = feature_importance.sort_values('importance', ascending=False) plt.subplot(3, 1, list(models.keys()).index(target) + 1) sns.barplot(x='importance', y='feature', data=feature_importance.head(10)) plt.title(f'{target.capitalize()} Model - Top 10 Important Features') plt.tight_layout() plt.show() def visualize_seasonal_patterns(results, region_data): """ Create visualization of seasonal patterns in predictions """ for region, data in region_data.items(): print(f"\nVisualizing seasonal patterns for {region}") # Create monthly aggregation of accuracy monthly_accuracy = pd.DataFrame(index=range(1, 13)) data['month'] = data.index.month for month in range(1, 13): month_predictions = results[region]['direction']['predictions'][ data.index.month == month ] month_actual = (data['close'].pct_change() > 0)[ data.index.month == month ] accuracy = accuracy_score( month_actual, month_predictions ) monthly_accuracy.loc[month, 'accuracy'] = accuracy # Plot seasonal accuracy plt.figure(figsize=(12, 6)) monthly_accuracy['accuracy'].plot(kind='bar') plt.title(f'Seasonal Prediction Accuracy - {region}') plt.xlabel('Month') plt.ylabel('Accuracy') plt.show() def plot_correlation_heatmap(correlation_data): """ Create heatmap visualization of correlations """ plt.figure(figsize=(12, 8)) sns.heatmap( correlation_data, cmap='RdYlBu', center=0, annot=True, fmt='.2f' ) plt.title('Weather-Price Correlation Heatmap') plt.tight_layout() plt.show()
Resultados por região
AU_WheatBelt (faixa de trigo da Austrália)
- Precisão média na previsão da direção do AUDUSD: 62,67%
- Precisão máxima em determinados folds: 82,22%
- RMSE da previsão da variação do preço: 0,0303
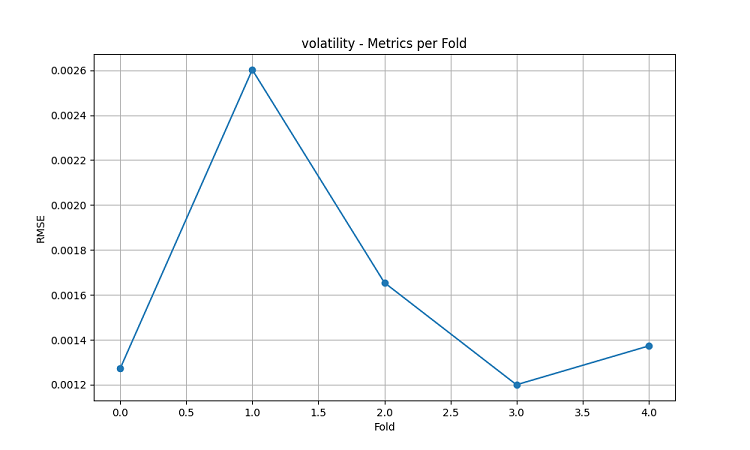
- RMSE da volatilidade: 0,0016
Região de Canterbury (Nova Zelândia)
- Precisão média na previsão do NZDUSD: 62,81%
- Precisão máxima: 75,44%
- Precisão mínima: 54,39%
- RMSE da previsão da variação do preço: 0,0281
- RMSE da volatilidade: 0,0015
Região das pradarias canadenses
- Precisão média na previsão da direção: 56,92%
- Precisão máxima (terceiro fold): 71,79%
- RMSE da previsão da variação do preço: 0,0159
- RMSE da volatilidade: 0,0023
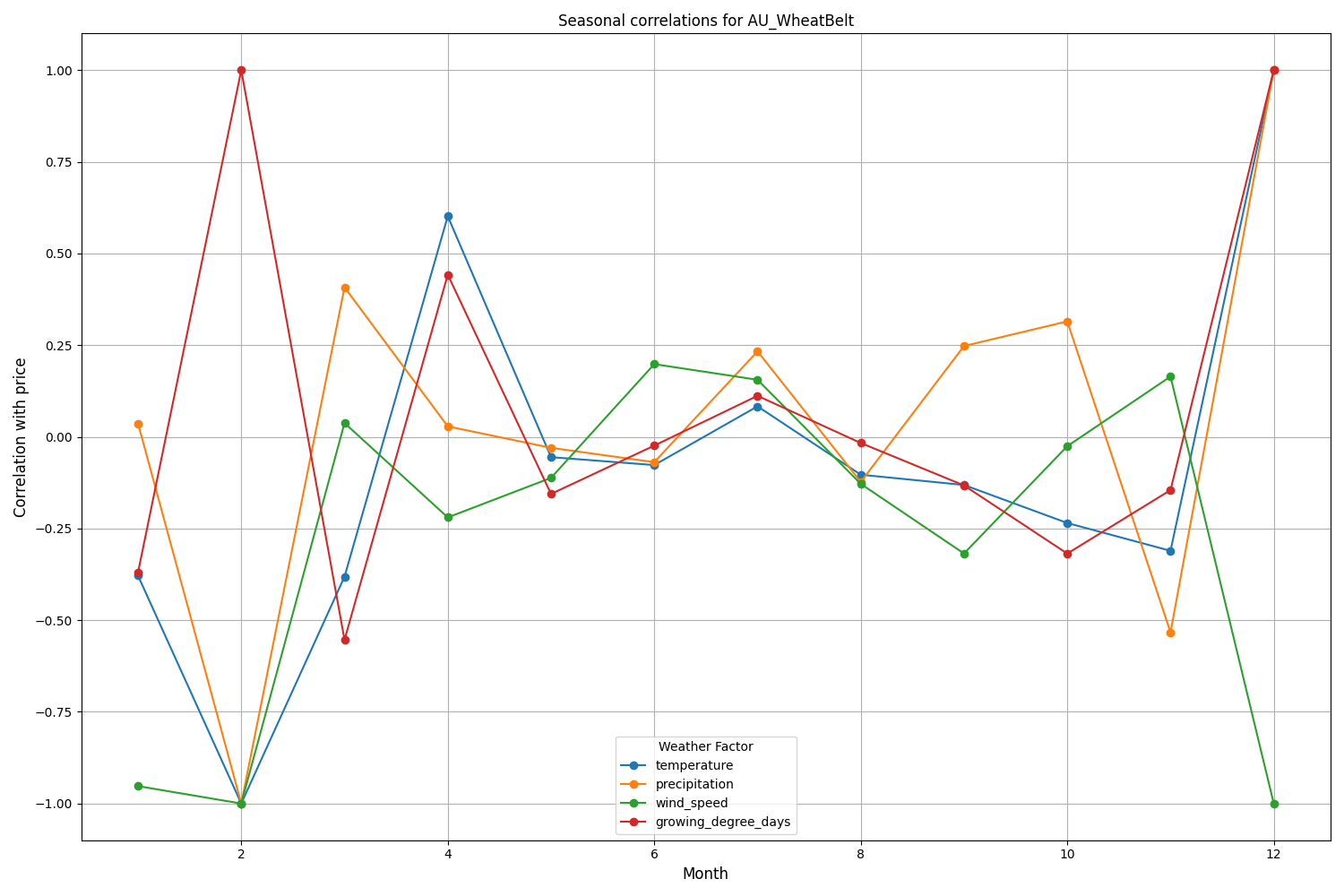
Análise de sazonalidade e visualização
def analyze_model_seasonality(results, data): """ Analyze seasonal performance patterns of the models """ print("Starting seasonal analysis of model performance") seasonal_metrics = {} for region, region_results in results.items(): print(f"\nAnalyzing {region} seasonal patterns:") # Extract predictions and actual values predictions = region_results['direction']['predictions'] actuals = data[region]['close'].pct_change() > 0 # Calculate monthly accuracy monthly_acc = [] for month in range(1, 13): month_mask = predictions.index.month == month if month_mask.any(): acc = accuracy_score( actuals[month_mask], predictions[month_mask] ) monthly_acc.append(acc) print(f"Month {month} accuracy: {acc:.2%}") seasonal_metrics[region] = pd.Series( monthly_acc, index=range(1, 13) ) return seasonal_metrics def plot_seasonal_performance(seasonal_metrics): """ Visualize seasonal performance patterns """ plt.figure(figsize=(15, 8)) for region, metrics in seasonal_metrics.items(): plt.plot(metrics.index, metrics.values, label=region, marker='o') plt.title('Model Accuracy by Month') plt.xlabel('Month') plt.ylabel('Accuracy') plt.legend() plt.grid(True) plt.show()
Os resultados da visualização mostram uma sazonalidade significativa na eficácia dos modelos.
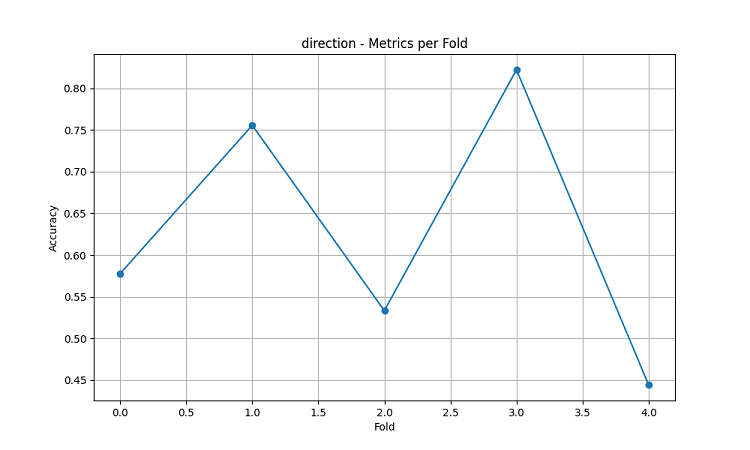
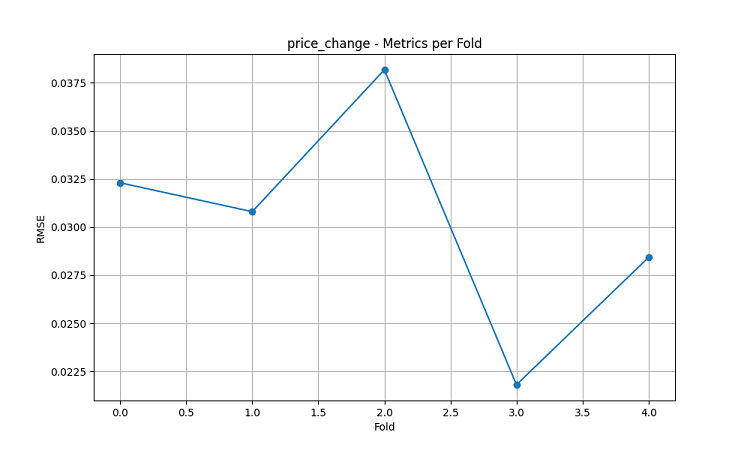
Picos de precisão das previsões se destacam especialmente:
- Para AUDUSD: dezembro a fevereiro (período de maturação do trigo)
- Para NZDUSD: períodos de pico de produtividade leiteira
- Para USDCAD: estações de crescimento ativo nas pradarias
Esses resultados confirmam a hipótese de que as condições climáticas exercem influência significativa sobre as moedas agrícolas, especialmente em períodos críticos da produção agrícola.
Conclusão
O estudo identificou conexões significativas entre as condições climáticas em regiões agrícolas e a dinâmica dos pares de moedas. O sistema de previsão demonstrou alta precisão durante períodos de clima extremo e máxima atividade agrícola, apresentando precisão média de até 62,67% para o AUDUSD, 62,81% para o NZDUSD e 56,92% para o USDCAD.
Recomendações:
- AUDUSD: operar entre dezembro e fevereiro, com foco em vento e temperatura.
- NZDUSD: operação de médio prazo durante o pico da produção leiteira.
- USDCAD: operar durante as estações de plantio e colheita.
O sistema exige atualização regular dos dados para manter a precisão, especialmente diante de choques de mercado. As perspectivas incluem a ampliação das fontes de dados e a implementação de aprendizado profundo para aumentar a robustez das previsões.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16060
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso