
Redes neurais de maneira fácil (Parte 68): Otimização off-line de políticas baseada em preferências

Introdução
O aprendizado por reforço é como um grande esquema para aprender a melhor maneira de agir em um ambiente específico. A ideia é otimizar a política maximizando a recompensa recebida do ambiente durante a interação. Mas aqui está o problema: desenvolver uma boa função de recompensa pode dar um trabalho danado. Além disso, as recompensas podem ser esparsas e não expressar bem o objetivo real do aprendizado. Uma solução para isso é o método Offline Preference-guided Policy Optimization (OPPO), descrito no artigo "Beyond Reward: Offline Preference-guided Policy Optimization". Os autores propõem substituir a recompensa pelas preferências de um anotador humano entre duas trajetórias no ambiente analisado. Vamos dar uma olhada mais de perto nesse algoritmo.
1. Algoritmo OPPO
No aprendizado off-line baseado em preferências, a abordagem geral tem duas etapas: primeiro, otimiza-se o modelo da função de recompensa via aprendizado supervisionado; depois, treina-se a política usando algum algoritmo de RL off-line nos estados redefinidos com essa função de recompensa. Mas treinar a função de recompensa separadamente nem sempre mostra à política a melhor maneira de agir. Como as etiquetas de preferência definem a tarefa, o objetivo é aprender a trajetória mais preferida, não apenas maximizar a recompensa. Em tarefas complexas, recompensas escalonadas podem criar um gargalo na otimização da política, levando a um comportamento não ideal do agente. Além disso, a otimização off-line da política pode explorar falhas nas funções de recompensa erradas, resultando em comportamentos indesejados.
Como alternativa, os autores do método OPPO propõem aprender a estratégia diretamente do conjunto de dados off-line com preferências anotadas. Eles sugerem um algoritmo de uma única etapa que, ao mesmo tempo, modela as preferências off-line e aprende a melhor política de decisão sem precisar treinar uma função de recompensa separada. Isso é feito usando dois objetivos:
- objetivo de correspondência de informações "na ausência" off-line;
- objetivo de modelagem de preferências.
Com a otimização desses objetivos iterativamente, a gente chega a uma política contextual π(A|S,Z) para modelar os dados off-line e a um contexto de preferências ideal Z'. O foco principal do OPPO está no estudo do espaço Z de alta dimensionalidade e na avaliação de políticas nesse espaço. Esse espaço Z capta mais informações sobre a tarefa em questão do que uma recompensa simples, tornando-o perfeito para otimizar políticas. Além disso, a política ideal é obtida modelando a política contextual π(A|S,Z) no contexto ideal aprendido Z'.
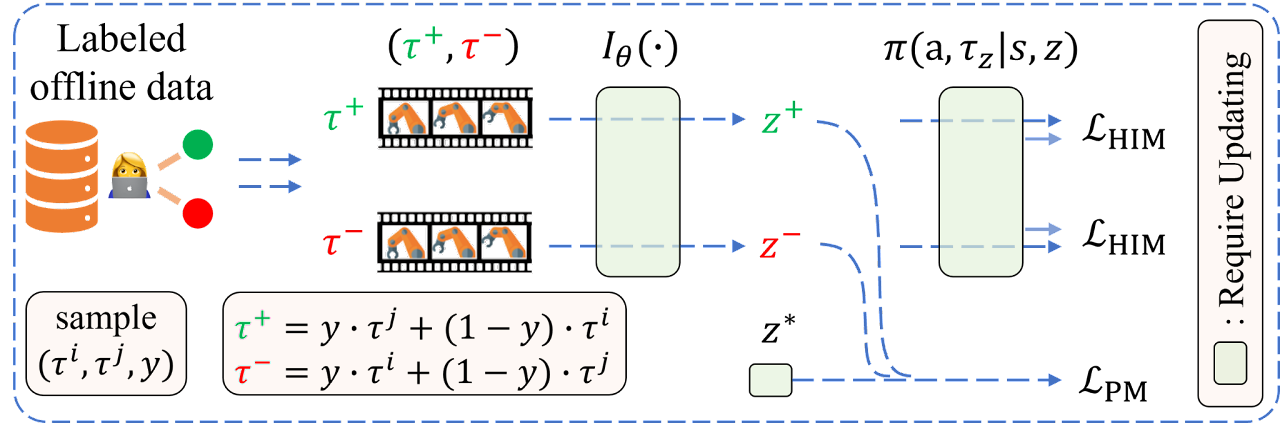
Os autores do algoritmo sugerem que a função de preferências pode ser aproximada por um modelo Iθ, permitindo formular o seguinte objetivo:
![]()
onde Z=Iθ(τ) representa o contexto de preferências. Essa estrutura de codificador-decodificador lembra o aprendizado de imitação off-line. Mas, como não há demonstrações de especialistas, os autores usam etiquetas de preferências para extrair informações retrospectivas.
Para alinhar as informações retrospectivas Iθ(τ) com as preferências nos dados anotados, eles formulam o seguinte objetivo de modelagem de preferências:
![]()
onde z+ e z- representam o contexto da trajetória preferida (positiva) Iθ(yτj+ (1-y)τi) e da menos preferida (negativa) Iθ(yτi+ (1-y)τj), respectivamente. A suposição principal ao formular esse objetivo é que as pessoas geralmente comparam em dois níveis antes de expressar preferências entre duas trajetórias (τi, τj):
- comparam separadamente a semelhança entre a trajetória τi e a trajetória ótima hipotética τ, ou seja, l(z,z+), e a semelhança entre a trajetória τj e a trajetória ótima hipotética τ*, ou seja, l(z,z-);
- depois avaliam as diferenças entre essas duas semelhanças l(z,z+) e l(z,z-), estabelecendo a trajetória mais próxima como a preferida.
Assim, a otimização desse objetivo garante a descoberta do contexto ideal, que é mais parecido com z+ e menos com z-.
Vale lembrar que z* é o contexto da trajetória τ, enquanto a trajetória τ será sempre preferida em relação a qualquer outra trajetória off-line no conjunto de dados.
A probabilidade a posteriori do contexto ótimo z* e a extração de informações retrospectivas de preferências Iθ(•) são atualizadas alternadamente para garantir a estabilidade do treinamento. Uma melhor estimativa da incorporação ideal ajuda o codificador a extrair características às quais os humanos prestam mais atenção ao determinar preferências. Por outro lado, um codificador de informações retrospectivas melhor acelera a busca da trajetória ideal no espaço de alta incorporação. Assim, a função de perda para o codificador tem duas partes:
- erro de correspondência de informações retrospectivas no estilo de aprendizado supervisionado,
- erro para a melhor inclusão de observação binária, fornecida pelo conjunto de dados de preferências anotadas.
A visualização do algoritmo OPPO pelos autores é mostrada abaixo.
2. Implementação com MQL5
Depois de entender a parte teórica do método OPPO, vamos para a parte prática. Vamos ver como implementar o algoritmo na prática. Começaremos com a estrutura de armazenamento de dados SState. Como já mencionei, os autores do método trocam a recompensa tradicional pela etiqueta de preferência da trajetória. Então, não precisamos mais salvar a recompensa em cada transição para um novo estado do ambiente. Ademais, introduzimos o conceito de contexto da trajetória preferida. Seguindo essa lógica, na estrutura que descreve o estado do ambiente, substituímos o array de recompensas rewards pelo array de contexto scheduler.
struct SState { float state[BarDescr * NBarInPattern]; float account[AccountDescr]; float action[NActions]; float scheduler[EmbeddingSize]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- void Clear(void) { ArrayInitialize(state, 0); ArrayInitialize(account, 0); ArrayInitialize(action, 0); ArrayInitialize(scheduler, 0); } //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); ArrayCopy(action, obj.action); ArrayCopy(scheduler, obj.scheduler); } };
Repare que mudamos não só o nome, mas também o tamanho do array.
Além do contexto oculto, o algoritmo traz o conceito de preferência da trajetória. Aqui, é importante notar alguns pontos:
- o foco é na trajetória inteira, não em ações e transições individuais (a política é avaliada);
- as preferências são estabelecidas em pares entre todas as trajetórias no conjunto de dados off-line no intervalo [0: 1];
- as preferências são definidas por um especialista.
Já adianto que não vamos rotular manualmente as preferências de todas as trajetórias do buffer de replay. Nem vamos criar uma tabela de prioridades.
Existem muitos critérios possíveis para definir prioridades. Mas, para este artigo, usei apenas um: o lucro obtido na trajetória. Claro, podemos incluir o drawdown máximo tanto no saldo quanto no Equity. Podemos incluir o fator de lucro e outros fatores. Eu sugiro que você escolha os critérios e seus pesos que considerar ideais. Os critérios escolhidos por você certamente afetarão o resultado final do treinamento da política, mas não mudarão o algoritmo da implementação proposta.
E como a prioridade é definida para a trajetória inteira, é suficiente salvarmos o lucro obtido no final da trajetória. Vamos salvar essa informação na estrutura de descrição da trajetória STrajectory.
struct STrajectory { SState States[Buffer_Size]; int Total; double Profit; //--- STrajectory(void); //--- bool Add(SState &state); void ClearFirstN(const int n); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const STrajectory &obj) { Total = obj.Total; Profit = obj.Profit; for(int i = 0; i < Buffer_Size; i++) States[i] = obj.States[i]; } };
Obviamente, a mudança nos campos das estruturas exigirá ajustes nos métodos de cópia e manipulação dos arquivos dessas estruturas. Mas essas mudanças são tão específicas que sugiro que você as examine por conta própria nos arquivos anexos.
2.1 Arquitetura dos modelos
Para treinar a política, usaremos dois modelos. O Planejador estudará as preferências, enquanto o Agente aprenderá a política de comportamento. Ambos os modelos serão construídos com base no princípio do Transformador de Decisões (DT) e usarão mecanismos de atenção. No entanto, ao contrário da solução original de atualização sequencial dos modelos, criaremos dois Experts Advisors para treinar os modelos. Cada um deles vai treinar apenas um dos modelos. Vamos juntar tudo em um único mecanismo na fase de teste e operação do modelo. Para descrever a arquitetura dos modelos, também criaremos dois métodos:
- CreateSchedulerDescriptions — para descrever a arquitetura do Planejador;
- CreateAgentDescriptions — para descrever a arquitetura do Agente.
Na entrada do planejador, forneceremos:
- dados históricos de movimento de preços e indicadores,
- descrições do estado da conta e das posições abertas,
- rótulo de data/hora,
- última ação do Agente.
bool CreateSchedulerDescriptions(CArrayObj *scheduler) { //--- CLayerDescription *descr; //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Lembro que o Transformador de Decisões usa a arquitetura GPT e mantém em seu estado oculto as incorporações (embeddings) dos dados anteriormente recebidos, permitindo tomar decisões em um único contexto durante todo o episódio. Portanto, na entrada do modelo, fornecemos apenas uma breve descrição do estado atual, focando nas últimas mudanças. Em outras palavras, na entrada do modelo, fornecemos informações apenas sobre a última vela fechada.
Os dados recebidos passam por um pré-processamento na camada de normalização.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Depois, são transformados em um formato comparável na camada de Incorporação (Embedding).
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!scheduler.Add(descr)) { delete descr; return false; }
As incorporações obtidas são normalizadas com a função SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 4; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Os dados pré-processados passam pelo bloco de atenção.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 4; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Os dados resultantes são novamente normalizados com a função SoftMax e passam pelo bloco de camadas totalmente conectadas de tomada de decisão.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
Na saída do modelo, obtemos um vetor de representação latente do contexto, cujo tamanho é determinado pela constante EmbeddingSize.
Desenhamos uma arquitetura semelhante para o nosso Agente. A única diferença é que nos dados de entrada é adicionado o contexto gerado.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateAgentDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + EmbeddingSize); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Os dados também passam por um pré-processamento através das camadas de normalização em lote, incorporação e são normalizados pela função SoftMax.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, EmbeddingSize}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 5; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Repetimos completamente o bloco de atenção com subsequente normalização pela função SoftMax. Aqui, é importante observar apenas a mudança no tamanho do tensor processado.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Em seguida, reduzimos a dimensionalidade dos dados com camadas convolucionais, tentando identificar padrões consistentes.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Depois disso, os dados passam por um bloco de tomada de decisão composto por 4 camadas totalmente conectadas. O tamanho da última camada é igual ao espaço de ações do Agente.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
2.2 Coleta de trajetórias para treinamento
Depois de descrever a arquitetura dos modelos, passamos à construção dos Experts Advisors para o treinamento. Primeiro, construiremos o advisor para interação com o ambiente, a fim de coletar trajetórias e preencher o buffer de replay, que posteriormente será utilizado no processo de aprendizado off-line "...\OPPO\Research.mq5".
Para explorar o ambiente, usaremos a estratégia ε-greedy e adicionaremos um parâmetro externo correspondente ao advisor.
input double Epsilon = 0.5;
Como mencionado anteriormente, no processo de interação com o ambiente, usaremos ambos os modelos. Portanto, precisamos declarar variáveis globais para eles.
CNet Agent; CNet Scheduler;
O método de inicialização do advisor difere pouco do método semelhante dos advisors que examinamos anteriormente, e sugiro não nos aprofundarmos em seu algoritmo agora. Você pode examiná-lo por conta própria no anexo. Vamos examinar o método OnTick, onde está o principal processo de interação com o ambiente e coleta de dados.
No corpo do método, como de costume, verificamos se um novo evento de abertura de barra aconteceu.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Se necessário, carregamos dados históricos dos preços.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return;
Em seguida, atualizamos as leituras dos indicadores que estamos analisando.
RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Os dados obtidos são organizados na estrutura do estado atual e enviados para o buffer de dados, para uso futuro como entrada para nossos modelos.
//--- History data float atr = 0; //--- for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Na próxima etapa, adicionamos informações sobre o saldo da conta e as posições abertas na estrutura do estado atual do ambiente.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Essas informações também são adicionadas ao buffer de dados de entrada.
bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Colocamos no buffer uma marca temporal e a última ação do Agente.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
Neste ponto, temos informações suficientes para a propagação do Planejador. Isso nos permite criar o vetor de contexto necessário para o nosso Agente. Então, realizamos a propagação do Planejador.
if(!Scheduler.feedForward(GetPointer(bState), 1, false)) return; Scheduler.getResults(sState.scheduler); bState.AddArray(sState.scheduler);
Carregamos o resultado obtido e adicionamos ao buffer de dados de entrada. Depois, chamamos o método de propagação do Agente.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat *)NULL)) return;
É importante lembrar de controlar a execução correta das operações em cada etapa.
Aqui, encerramos o trabalho com os modelos, salvamos os dados para operações futuras e passamos a interagir diretamente com o ambiente.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Após receber os dados do nosso Agente, se necessário, adicionamos ruído a eles.
Agent.getResults(AgentResult); if(Epsilon > (double(MathRand()) / 32767.0)) for(ulong i = 0; i < AgentResult.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.03f; float t = AgentResult[i] + rnd; if(t > 1 || t < 0) t = AgentResult[i] - rnd; AgentResult[i] = t; } AgentResult.Clip(0.0f, 1.0f);
Removemos volumes duplicados das posições.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(AgentResult[0] >= AgentResult[3]) { AgentResult[0] -= AgentResult[3]; AgentResult[3] = 0; } else { AgentResult[3] -= AgentResult[0]; AgentResult[0] = 0; }
Depois, corrigimos a posição longa primeiro.
//--- buy control if(AgentResult[0] < 0.9 * min_lot || (AgentResult[1] * MaxTP * Symb.Point()) <= stops || (AgentResult[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double(AgentResult[0] + FLT_EPSILON) - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + AgentResult[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - AgentResult[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
E então fazemos o mesmo para a posição curta.
//--- sell control if(AgentResult[3] < 0.9 * min_lot || (AgentResult[4] * MaxTP * Symb.Point()) <= stops || (AgentResult[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double(AgentResult[3] + FLT_EPSILON) - min_lot) / step_lot) * step_lot; double sell_tp = Symb.NormalizePrice(Symb.Bid() - AgentResult[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + AgentResult[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Neste ponto, geralmente formamos o vetor de recompensas, mas no algoritmo em questão ele não é usado. Então, apenas transferimos os dados das ações realizadas pelo Agente e enviamos os dados para salvar a trajetória.
for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Depois disso, esperamos a abertura da próxima barra.
Aqui, é lógico perguntar: como avaliaremos as preferências?
A resposta é simples: adicionamos informações sobre o desempenho no método OnTester após a conclusão da passagem no testador de estratégias.
//+------------------------------------------------------------------+ //| Tester function | //+------------------------------------------------------------------+ double OnTester() { //--- double ret = 0.0; //--- Base.Profit = TesterStatistics(STAT_PROFIT); Frame[0] = Base; if(Base.Profit >= MinProfit) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), 1, Base.Profit, Frame); //--- return(ret); }
Os outros métodos do EA de interação com o ambiente permaneceram os mesmos, e você pode consultá-los no anexo. Agora, vamos considerar os algoritmos de treinamento direto dos modelos.
2.3 Treinamento do modelo de preferência
Primeiro, vamos ver o EA de treinamento do modelo de preferências "...\OPPO\StudyScheduler.mq5". A arquitetura do EA permanece a mesma, e vamos focar apenas nos métodos envolvidos no treinamento do modelo.
Devo admitir que, no processo de treinamento do modelo, utilizamos desenvolvimentos de artigos anteriores. A combinação com esses desenvolvimentos, na minha opinião, deve aumentar a eficiência do processo de treinamento.
Antes de iniciar o treinamento, formaremos uma distribuição probabilística da escolha de trajetórias com base em sua rentabilidade, como proposto no método CWBC. No entanto, o método descrito anteriormente GetProbTrajectories precisa de ajustes devido à ausência do vetor de recompensas. Primeiro, alteramos a fonte de obtenção das informações sobre o resultado total da trajetória. Ao mesmo tempo, o vetor de recompensas decomposto é substituído por um valor escalar da lucratividade final. Assim, substituímos a matriz por um vetor.
vector<double> GetProbTrajectories(STrajectory &buffer[], float lanbda) { ulong total = buffer.Size(); vector<double> rewards = vector<double>::Zeros(total); for(ulong i = 0; i < total; i++) rewards[i]=Buffer[i].Profit;
Depois, determinamos o nível de rentabilidade máxima e o desvio padrão.
double std = rewards.Std(); double max_profit = rewards.Max();
O próximo passo é classificar os resultados das trajetórias para determinar corretamente o percentil.
vector<double> sorted = rewards; bool sort = true; while(sort) { sort = false; for(ulong i = 0; i < sorted.Size() - 1; i++) if(sorted[i] > sorted[i + 1]) { double temp = sorted[i]; sorted[i] = sorted[i + 1]; sorted[i + 1] = temp; sort = true; } }
O procedimento posterior de construção da distribuição probabilística não mudou e foi transferido conforme descrito anteriormente.
double min = rewards.Min() - 0.1 * std; if(max_profit > min) { double k = sorted.Percentile(90) - max_profit; vector<double> multipl = MathAbs(rewards - max_profit) / (k == 0 ? -std : k); multipl = exp(multipl); rewards = (rewards - min) / (max_profit - min); rewards = rewards / (rewards + lanbda) * multipl; rewards.ReplaceNan(0); } else rewards.Fill(1); rewards = rewards / rewards.Sum(); rewards = rewards.CumSum(); //--- return rewards; }
Neste ponto, podemos considerar a etapa preparatória concluída e passar a analisar o algoritmo do método de treinamento do modelo de preferências, Train.
No corpo do método, primeiro formamos o vetor da distribuição probabilística da escolha de trajetórias a partir do buffer de reprodução de experiências, usando o método GetProbTrajectories mencionado antes.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { vector<double> probability = GetProbTrajectories(Buffer, 0.1f); uint ticks = GetTickCount();
Depois, estruturamos o sistema de ciclos de treinamento do modelo. O número de iterações do ciclo externo é determinado pelo parâmetro externo do EA.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr_p = SampleTrajectory(probability); int tr_m = SampleTrajectory(probability); while(tr_p == tr_m) tr_m = SampleTrajectory(probability);
Dentro do ciclo, amostramos 2 trajetórias como exemplos positivo e negativo. Para manter a máxima objetividade, controlamos a escolha de 2 trajetórias diferentes do buffer de reprodução de experiências.
A amostragem simples não garante que a trajetória positiva seja escolhida primeiro, e vice-versa. Portanto, verificamos a rentabilidade das trajetórias escolhidas e, se necessário, ajustamos os ponteiros para as trajetórias nas variáveis.
if(Buffer[tr_p].Profit < Buffer[tr_m].Profit) { int t = tr_p; tr_p = tr_m; tr_m = t; }
Depois, o algoritmo OPPO prevê o treinamento do modelo de preferências na direção da trajetória negativa para a preferencial. À primeira vista, parece fácil e óbvio. Mas, na prática, encontramos algumas "armadilhas".
Durante a geração de todas as trajetórias, utilizamos um trecho de dados históricos. Portanto, a informação sobre o movimento dos preços e os valores dos indicadores analisados para todas as trajetórias será idêntica. Isso não se aplica a outros parâmetros analisados. Refiro-me ao estado da conta, posições abertas e, claro, ações do Agente. Para uma distribuição correta do gradiente do erro, precisamos realizar a propagação para os estados de ambas as trajetórias de forma sequencial.
Mas isso levanta uma questão. Em nosso modelo, utilizamos a arquitetura GPT, que é sensível à sequência dos dados de entrada. Como manter a sequência de duas trajetórias diferentes em um único modelo? A resposta óbvia é usar 2 modelos em paralelo com fusão periódica dos coeficientes de peso, similar ao método de atualização suave dos modelos alvo nos métodos TD3 e SAC. Mas também há desafios aqui. Nos métodos mencionados, os modelos alvo não eram treinados, e usávamos seus buffers de momentos no processo de treinamento suave. No entanto, neste caso, os modelos são treinados. E os buffers de momentos são usados diretamente. Adicionar informações sobre a atualização suave dos coeficientes de peso pode distorcer o processo de treinamento. É necessário uma análise detalhada e busca de soluções construtivas.
Na minha opinião, a opção mais viável é o treinamento sequencial de um modelo, primeiro com os dados de uma trajetória e, em seguida, com os dados da segunda trajetória, usando os valores inversos dos gradientes de erro. Para a trajetória preferencial, minimizamos a distância, e para a trajetória negativa — maximizamos.
Seguindo essa lógica, amostramos o estado inicial na trajetória preferencial.
//--- Positive int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr_p].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr_p].Total, 20))); if(i < 0) { iter--; continue; }
Limpamos as pilhas do modelo e fazermos o treinamento dentro dessa trajetória.
Scheduler.Clear(); for(int state = i; state < MathMin(Buffer[tr_p].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr_p].States[state].state);
No ciclo principal, preenchemos o buffer de dados de entrada com valores históricos dos preços e indicadores da amostra de treinamento das trajetórias.
Adicionamos dados sobre o estado da conta e as posições abertas.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr_p].States[state].account[0] : Buffer[tr_p].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr_p].States[state].account[1] : Buffer[tr_p].States[state - 1].account[1]); State.Add((Buffer[tr_p].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr_p].States[state].account[1] / PrevBalance); State.Add((Buffer[tr_p].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr_p].States[state].account[2]); State.Add(Buffer[tr_p].States[state].account[3]); State.Add(Buffer[tr_p].States[state].account[4] / PrevBalance); State.Add(Buffer[tr_p].States[state].account[5] / PrevBalance); State.Add(Buffer[tr_p].States[state].account[6] / PrevBalance);
Incluímos harmônicos da marca temporal e o vetor das últimas ações do Agente.
//--- Time label double x = (double)Buffer[tr_p].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr_p].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
Depois de reunir todos os dados necessários, propagamos o modelo em treinamento.
//--- Feed Forward if(!Scheduler.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
O treinamento do modelo é semelhante aos métodos de aprendizado supervisionado, visando minimizar as diferenças entre os valores previstos e os dados correspondentes da trajetória preferencial no buffer de experiências.
//--- Study Result.AssignArray(Buffer[tr_p].States[state].scheduler); if(!Scheduler.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Informamos o usuário sobre o progresso do treinamento e passamos para a próxima iteração com a trajetória preferencial.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheeduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Após concluir as iterações do ciclo na trajetória preferencial, trabalhamos com a segunda trajetória.
Teoricamente, podemos usar o mesmo intervalo de tempo e o estado inicial amostrado para a trajetória positiva. No mesmo trecho histórico, temos o mesmo número de passos em todas as trajetórias, o que pode ser um caso especial. Mas, de forma mais geral, pode haver um número diferente de passos nas trajetórias. Por exemplo, em um intervalo de tempo longo ou com um depósito pequeno, pode ocorrer uma "quebra", levando a um stop-out. Então, decidimos amostrar os estados iniciais dentro das trajetórias de trabalho.
//--- Negotive i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr_m].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr_m].Total, 20))); if(i < 0) { iter--; continue; }
Em seguida, limpamos a pilha do modelo e organizamos o ciclo de treinamento, como fizemos com a trajetória preferencial.
Scheduler.Clear(); for(int state = i; state < MathMin(Buffer[tr_m].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr_m].States[state].state); //--- Account description float PrevBalance = (state == 0 ? Buffer[tr_m].States[state].account[0] : Buffer[tr_m].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr_m].States[state].account[1] : Buffer[tr_m].States[state - 1].account[1]); State.Add((Buffer[tr_m].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr_m].States[state].account[1] / PrevBalance); State.Add((Buffer[tr_m].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr_m].States[state].account[2]); State.Add(Buffer[tr_m].States[state].account[3]); State.Add(Buffer[tr_m].States[state].account[4] / PrevBalance); State.Add(Buffer[tr_m].States[state].account[5] / PrevBalance); State.Add(Buffer[tr_m].States[state].account[6] / PrevBalance); //--- Time label double x = (double)Buffer[tr_m].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr_m].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions)); //--- Feed Forward if(!Scheduler.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Mas há um detalhe na definição dos objetivos. Devemos considerar dois casos. Primeiro, como um caso especial, quando a rentabilidade da trajetória preferencial e da segunda trajetória é a mesma (ou seja, ambas são preferenciais), usamos a mesma abordagem da trajetória preferencial.
//--- Study if(Buffer[tr_p].Profit == Buffer[tr_m].Profit) Result.AssignArray(Buffer[tr_m].States[state].scheduler);
No segundo caso, mais geral, quando a rentabilidade da segunda trajetória é menor, devemos nos afastar dela na direção oposta. Para isso, carregamos o valor previsto e encontramos sua divergência em relação ao contexto da trajetória negativa do buffer de experiências. Aqui, devemos nos mover na direção oposta. Portanto, em vez de adicionar, subtraímos a divergência dos valores previstos. Para priorizar o movimento em direção à trajetória preferencial, reduzo a divergência pela metade no cálculo do valor alvo.
else { vector<float> target, forecast; target.Assign(Buffer[tr_m].States[state].scheduler); Scheduler.getResults(forecast); target = forecast - (target - forecast) / 2; Result.AssignArray(target); }
Agora podemos fazer a retropropagação do modelo usando os métodos existentes para minimizar a divergência com o objetivo ajustado.
if(!Scheduler.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Informamos o usuário sobre o progresso do treinamento e passamos para a próxima iteração do nosso sistema de ciclos.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheeduler", (iter + 0.5) * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após concluir todas as iterações do sistema de treinamento, limpamos os comentários no gráfico. Registramos no diário os resultados e iniciamos a finalização forçada do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); ExpertRemove(); //--- }
Com isso, encerramos a discussão dos métodos do EA de aprendizado de modelo de preferências "...\OPPO\StudyScheduler.mq5". Você pode acessar o código completo dos métodos e funções no anexo.
2.4 Treinamento da política do agente
O próximo passo é construir o EA de treinamento da política do Agente "...\OPPO\StudyAgent.mq5". A estrutura é quase igual ao EA mencionado antes, com algumas diferenças específicas no método de treinamento do modelo Train. É nesse ponto que vamos focar.
Como antes, começamos definindo as probabilidades de escolha de trajetórias chamando o método GetProbTrajectories.
vector<double> probability = GetProbTrajectories(Buffer, 0.1f); uint ticks = GetTickCount();
Depois, configuramos o sistema de ciclos aninhados de treinamento.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
Desta vez, no ciclo externo, amostramos apenas uma trajetória. Aqui, precisamos aprender uma política do Agente que associe o contexto latente a ações específicas, tornando as ações mais previsíveis e controláveis. Portanto, não dividimos as trajetórias em preferenciais e não preferenciais.
Depois, limpamos a pilha do modelo e configuramos o ciclo de treinamento dentro dos estados sequenciais da subtrajetória amostrada.
Agent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
No ciclo, preenchemos o buffer de dados de entrada com dados históricos dos preços e indicadores da amostra de treinamento. Completamos com informações da conta e posições abertas,
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
adicionando harmônicas da marcação temporal e o vetor das últimas ações do Agente.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
Diferente do modelo de preferências, o Agente também precisa do contexto, obtido do buffer de reprodução de experiência.
//--- Scheduler
State.AddArray(Buffer[tr].States[state].scheduler);
Os dados coletados são suficientes para a propagação do modelo do Agente, e chamamos o método correspondente.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Como mencionado antes, treinamos a política do Ator para construir dependências entre o contexto latente e a ação realizada. Isso está de acordo com os objetivos de DT, onde construímos dependências entre objetivos e ações. O contexto latente funciona como uma representação do objetivo. A forma muda, mas a essência permanece, então o processo de treinamento é semelhante. Minimizar o erro entre a ação prevista e a ação real é a meta.
//--- Policy study Result.AssignArray(Buffer[tr].States[state].action); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Depois, informamos o usuário sobre o progresso e passamos para a próxima iteração.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Ao final do processo de treinamento, limpamos os comentários no gráfico, registramos os resultados no diário e finalizamos o EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
Isso encerra o algoritmo dos programas utilizados no artigo. O código completo está no anexo, onde você também encontrará o código do EA de teste do modelo treinado "...\OPPO\Test.mq5", que praticamente repete o algoritmo do EA de interação com o ambiente, só que sem adicionar ruído às ações do Agente. Eliminar o fator aleatório e avaliar completamente a política aprendida é o objetivo.
3. Teste
Houve um grande esforço para implementar o algoritmo Offline Preference-guided Policy Optimization (OPPO). Ressalto que a implementação é minha interpretação pessoal, com algumas operações adicionadas que não estão no algoritmo original descrito pelos autores. De modo algum quero me apropriar dos méritos dos autores do OPPO, mas também não quero atribuir a eles possíveis falhas ou mal-entendidos das minhas implementações.
O treinamento do modelo foi feito com dados históricos do EURUSD, no período H1, nos primeiros 7 meses de 2023. Os testes dos modelos treinados usaram dados históricos de agosto de 2023.
Devido à mudança na estrutura de armazenamento das trajetórias neste trabalho, não pudemos usar exemplos de trajetórias coletadas em trabalhos anteriores. Por isso, foram coletadas novas trajetórias para a amostra de treinamento.
Devo admitir que a coleta de 500 trajetórias dos novos modelos, iniciadas com coeficientes de peso aleatórios, no meu laptop, levou 3 dias de trabalho contínuo. Isso foi inesperado.
Após a coleta da amostra de treinamento, iniciei o treinamento paralelo dos modelos, o que foi possível dividindo o processo em 2 EAs independentes.
Como sempre, o treinamento incluiu a adição iterativa de amostras de treinamento baseadas nas atualizações dos modelos. O processo de treinamento é bastante estável e focado. Mesmo com passagens deficitárias na amostra, o método encontra maneiras de melhorar a política.
Para construir uma estratégia lucrativa, é necessário ter passagens positivas na amostra de treinamento. Isso é alcançado explorando o ambiente e coletando trajetórias adicionais. Também é possível usar trajetórias de especialistas ou copiar negociações de sinais, como mostrado no artigo anterior. No entanto, a presença de passagens lucrativas acelera significativamente o treinamento dos modelos.
Durante o treinamento, obtivemos um modelo capaz de gerar lucro tanto na amostra de treinamento quanto na de teste. Os resultados do desempenho do modelo no intervalo de teste estão apresentados abaixo.


Como pode ser visto nas capturas de tela, a linha de saldo tem subidas acentuadas e quedas. O gráfico de saldo não é estável, mas mostra uma tendência geral de crescimento. Ao final do mês de teste, obtivemos lucro.
No total, durante o período de teste, foram realizadas 180 negociações. Quase 49% delas foram lucrativas. Foi alcançado um equilíbrio entre negociações lucrativas e deficitárias. Com um lucro médio 30% maior que a perda média, obtém-se um crescimento geral do saldo. Além disso, o fator de lucro no trecho histórico de teste foi de 1,25.
Considerações finais
Neste artigo, exploramos um método bem interessante para treinar modelos, o Offline Preference-guided Policy Optimization (OPPO). A principal diferença desse método é que ele não usa uma função de recompensa no treinamento dos modelos. Isso faz com que ele possa ser aplicado em uma variedade muito maior de situações. Às vezes, é difícil definir um objetivo específico de treinamento de forma clara. E fica ainda mais complicado avaliar como cada ação individual afeta o resultado final, especialmente quando as respostas do ambiente são esparsas ou atrasadas. Em vez disso, o OPPO avalia a trajetória inteira, que é o resultado de uma política específica. Assim, em vez de avaliar as ações do Agente, avaliamos sua política em um ambiente específico. E então decidimos se mantemos essa política ou buscamos uma solução mais otimizada.
Na parte prática deste artigo, implementamos o método OPPO usando MQL5, com algumas adaptações. Ainda assim, conseguimos treinar uma política que gera lucro tanto no intervalo histórico de treinamento quanto no teste, que vai além da amostra de treinamento.
Os resultados do treinamento e do teste do modelo mostram que é possível usar esses métodos para criar estratégias de negociação reais.
No entanto, lembro que todos os programas apresentados aqui são apenas para demonstrar tecnologias e não são adequados para operar em mercados financeiros reais.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | StudyAgent.mq5 | EA | EA de treinamento do agente |
| 3 | StudyScheduler.mq5 | EA | EA de treinamento do modelo de preferências |
| 4 | Test.mq5 | EA | EA para testar o modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13912
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso