이해했다. 나는 높고 낮음의 기하 평균을 취했습니다. 이제 어떤 차이가 있는지 봅시다. MT4용 코드를 가져 와서 C로 변환하거나 스스로 오류를 찾는 중 어느 것이 더 편리한지 여전히 결정할 수 없습니다.) 내 데이터는 일일 막대(5분)이며 총 78개가 있습니다. 3.4 ... 78i의 값에 따라 포인트 비용이 듭니다. 세그먼트를 영구적으로 반으로 나누는 일종의 옵션도 있습니다. 음, 그리고 Close[i+1]-Close[i]의 차이가 0이고 표준편차가 0인 점은 직선을 구성할 때 단순히 고려하지 않습니까? Hurst 계수 를 계산할 때 일반적인 최소 제곱이 아니라 소위 사용해야한다는 의견도 있습니다. RANSAC( http://en.wikipedia.org/wiki/RANSAC ), 왜냐하면 일반적인 LSM을 사용하면 직선의 기울기 계수가 "총 개수를 벗어난" 점의 영향을 받을 수 있습니다. 전체 질량에서 가장 멀리 떨어져 있습니다.
Disa>> : понял. Я брал среднее геометрическое из High и Low. Сейчас посмотрю что будет на разнице. Я пока не могу решить что целесообразнее - брать код для MT4 и переделывать под Си или искать ошибки у себя ;) У меня данные это дневные бары(5ти минутки), всего их 78. Я точки стоил по значениям для 3,4...78и. - МТ4 моментально обсчитает 78 баров, даже до десятка тысяч считает быстро. А вот для каждого бара расчитывать Херста на многотысячной выборке - это уже долго, если баров тоже тыщи. Есть еще вроде вариант постоянного деления отрезка пополам. - не совсем представляю о чем вы, но если длина выборки - степень двойки, то да, работает. В любом случае предпочтительнее иметь выборку с длиной имеющей как можно больше делителей. Хм, а точки для которых разница Close[i+1]-Close[i] = 0 и среднеквадратичное отклонение 0, просто не рассматриваются при построении прямой? - (Close[i+1]-Close[i]) - это входные данные, прямая строится не по ним, а по коэффициентам, которые получаются из этих данных при R/S анализе. Еще есть мнение что подсчета коэффициента Херста нужно использовать не обычный МНК, а т.н. RANSAC( http://en.wikipedia.org/wiki/RANSAC ), т.к. при обычном МНК на коэффициент наклона прямой могут влиять точки, "выбивающиеся из общего числа", т.е. наиболее удаленные от общей массы. - Не представляю на основании какой модели, можно решить, что некоторые возвраты подлежат выбросу из выборки?
(닫기[i+1]-닫기[i]) = 0 => log(d[i]/d[i-1]) = INF - 이걸 어떻게 해야 할지 모르겠습니다. RS = R/S - S = 0일 때 계산하는 방법, R = 0도 가정합니까? 그런 다음 다시 (R) = INF를 기록하고 다시 무엇을 해야 하는지 이해가 되지 않습니다. 좋은. 다음은 간단한 예입니다. 계수 H는 무엇입니까? 주어진 간격의 모든 i에 대해 (Close[i+1]-Close[i]) = const라면? 어떤 모델을 기반으로 했는지 잘 모르겠습니다. 샘플에서 일부 수익을 버리는 것으로 결정할 수 있습니까? -예를 들어 주식 데이터 스트림의 여러 값 값에 오류가 있는 경우(14.4 대신 54.5)
일반적으로 내 계산 알고리즘을 말로 설명하고 오류가 어디에 있는지 알려주십시오. 그렇지 않으면 오랫동안 서로를 이해하지 못할 것입니다.
RS 함수는 Close[i]-Close[i-1] 의 배열과 배열 요소의 수를 입력으로 사용합니다. 1. S[i-1] = 닫기[i]-닫기[i-1] 0에서 N까지의 모든 i에 대해 2. h[i] = log(S[i]/S[i-1]) 3. Hn = 합 h[i]h_cp = 평균 산술. 엥 4. R = 최대(h[i] - h_cp) - 최소( h[i] - h_cp )S = 1/n * (h[i] - h_cp) RS = R / S 5 . 다음으로, n_min에서 일부 N까지 i에 대해 log RS(i) 및 log i 값을 갖는 m-in 점이 있고 최소 제곱은 직선입니다.
Disa>> : В общем давайте я расскажу свой алгоритм обсчета словами, а вы мне скажете пж где ошибка, а то мы так долго друг друга чуствую не поймем.
функция RS на вход принимает массив из Close[i]-Close[i-1] и число элементов массива 1. S[i-1] = Close[i]-Close[i-1] Для всех i от 0 до N 2. h[i] = log(S[i]/S[i-1]) - не стоит так делать, т.к. п.1 и п.2 в принципе одно и тоже в смысле подготовки данных для алгоритма. Действительно, вместо возвратов на вход можно подавать log(Close[i]/Close[i-1]), но подавать на вход логарифм отношения возвратов - это перебор, по-моему. Достаточно подавать что-нибудь одно - либо разницу цен, либо логарифм их отношений. 3. Hn = Сумма h[i]h_cp = ср.ариф. Hn 4. R = max(h[i] - h_cp) - min( h[i] - h_cp )S = 1/n * (h[i] - h_cp) RS = R / S 5 . Далее стою м-во точек со значением log RS(i) и log i для i от n_min до некоторого N и МНК стоют прямую
в п.3-5 для начала не вижу оператора или описания, что вся выборка делится на N кусков размером M, что для каждого этого куска считается rs = (максимум наращиваемой суммы отклонений от среднего - минимум наращиваемой суммы отклонений от среднего) / сумму квадратов отклонений от среднего, и все они, эти rs, складываются, а потом делятся на N. Теперь Log(RS) и log(N) - это одна точка для МНК, которых надо насобирать побольше, подбирая разные N и М так, чтобы N*M=длина выборки всегда. На мой взгляд, запись п.4 полностью неверна.
나는 주제를 올릴 것이다) 감사합니다 Vita - 나는 C++에서 win32api를 작성했고 모든 것이 제대로 작동합니다. 이 방법을 자주 사용하는 사람들을 위한 질문입니다. 들어오는 데이터 수, 분산, 상관 관계 및 다른 통계의 MB에서 오류 추정치가 있습니까? 내가 알기로는 78개 값에 대한 계수를 계산하는 데 특별한 점은 없는지, 즉 1일 막대에 대해? 일부 값이 0인 경우 어떻게 해야 하는지 여전히 이해가 되지 않습니다. 글쎄요, 예를 들어 가격차이를 입력으로 입력하면 5분차이가 0보다 작거나 같은 것은 분명한데 로그는 취하지 않습니다. 음수(즉, 절대 차이)이면 값의 계수를 취하고 0의 경우에는 이 값을 h 계열에 넣지 마십시오.
테스트 파일 Brown72.txt 의 표시기 zHursttExponent.mq4 는 0.1647을 제공합니다. 무엇을 위한 것입니까? 내가 이해하는 한, 이 표시기는 마지막 2520개 막대에 대한 각 눈금의 허스트 지수를 계산하고 값을 인쇄합니다. 그래서 ? 그렇다면 이 표시기의 4개 버퍼는 무엇을 의미하며 별도의 창에 필요한 이유는 무엇입니까? 그리고 질문 하나 더.
테스트 파일 Brown72.txt 의 표시기 zHursttExponent.mq4 는 0.1647을 제공합니다. 무엇을 위한 것입니까? 내가 이해하는 한, 이 표시기는 마지막 2520개 막대에 대한 각 눈금의 허스트 지수를 계산하고 값을 인쇄합니다. 그래서 ? 그렇다면 이 표시기의 4개 버퍼는 무엇을 의미하며 별도의 창에 필요한 이유는 무엇입니까? 그리고 질문 하나 더.
//---- main loop for(int i=0; i<limit; i++) { }
//---- done
표시기 코드에서 이 조각의 의미는 무엇입니까?
1. 나는 당신의 결과 = 0.1647을 반복할 수 없습니다. 나는 이것을 가지고 있습니다 (= 0.7241) :
2. 예, 이 표시기는 마지막 2520개 막대에 대한 각 눈금에서 Hurst 지수를 계산하고 값을 인쇄하고 r/s 점(흰색 선)을 그립니다. 이를 따라 근사 직선(빨간색 선)이 만들어지고 기울기는 이것은 알고리즘의 정확성에 대한 질적 시각적 평가를 위해 명확성을 위해 원하는 지표입니다. 이 모든 것은 cRSGraphic = true일 때 true이고, 그렇지 않으면 표시기가 마지막 250개 막대에 대한 Hurst 지수를 계산합니다.
3. 4개의 버퍼 - 이것은 명백한 초과이며, 디버깅 및 테스트 시점에서 남겨진 유물입니다. 4. 공허한 순환 - p.3과 같은 문제. 삭제할 수 있습니다.
Disa>> : Подниму ка тему) Спасибо Vita - написал win32api под c++ и все пашет как надо. Вопрос к людям которые часто применяли этот метод - есть какие-нибудь оценки погрешностей от числа входящих данных, дисперсии, корреляции и мб других стат.величин. Как я понял вообще смысла особого нет считать коэффициент для 78 величин - т.е для однодневного бара? Так же по прежнему не понимаю что делать если какие-то величины равны нулю. Ну например если на вход подаю разность цен - понятное дело что разность за 5ть минут мб меньше или равны 0, но log тогда не берется. У меня есть идея брать модуль величины в случае если она отрицательна(т.е абсолютную разницу) а в случае 0 не заносить это значение в ряд h.
다음은 오류를 고려하는 옵션입니다. 불행히도 이 기적을 위해 C 소스 코드를 훔친 곳을 찾을 수 없지만 Feder E. Fractals에 따르면 계산된다고 주장합니다. 그를 위해 동일한 파일에 대해 H=0.6807을 테스트하십시오. 나쁘지 않은 것 같습니다.
78등급 중 가장 무겁습니다. 50개의 관찰에 대해 허스트를 평가하는 방법에 대한 많은 작업이 있습니다. 계산을 이해하지 않고도 다른 저자로부터 매우 다른 결과를 얻습니다. 이것에 놀라운 것은 없습니다. 얼마나 많은 알고리즘 - 많은 지표 :). 그리고 더 많은 문제 - 1000 관찰에 대한 첨부 버전에서 오류를 고려하면 가격에 대해 말할 수 있는 것이 없습니다 - 현재 지속되고 있지 않기 때문입니다. 0.5는 오류 채널(cRSGraphic=false인 빨간색 선) 사이에 있습니다.
세그먼트를 영구적으로 반으로 나누는 일종의 옵션도 있습니다.
음, 그리고 Close[i+1]-Close[i]의 차이가 0이고 표준편차가 0인 점은 직선을 구성할 때 단순히 고려하지 않습니까?
Hurst 계수 를 계산할 때 일반적인 최소 제곱이 아니라 소위 사용해야한다는 의견도 있습니다. RANSAC( http://en.wikipedia.org/wiki/RANSAC ), 왜냐하면 일반적인 LSM을 사용하면 직선의 기울기 계수가 "총 개수를 벗어난" 점의 영향을 받을 수 있습니다. 전체 질량에서 가장 멀리 떨어져 있습니다.
понял. Я брал среднее геометрическое из High и Low. Сейчас посмотрю что будет на разнице. Я пока не могу решить что целесообразнее - брать код для MT4 и переделывать под Си или искать ошибки у себя ;) У меня данные это дневные бары(5ти минутки), всего их 78. Я точки стоил по значениям для 3,4...78и. - МТ4 моментально обсчитает 78 баров, даже до десятка тысяч считает быстро. А вот для каждого бара расчитывать Херста на многотысячной выборке - это уже долго, если баров тоже тыщи.
Есть еще вроде вариант постоянного деления отрезка пополам. - не совсем представляю о чем вы, но если длина выборки - степень двойки, то да, работает. В любом случае предпочтительнее иметь выборку с длиной имеющей как можно больше делителей.
Хм, а точки для которых разница Close[i+1]-Close[i] = 0 и среднеквадратичное отклонение 0, просто не рассматриваются при построении прямой? - (Close[i+1]-Close[i]) - это входные данные, прямая строится не по ним, а по коэффициентам, которые получаются из этих данных при R/S анализе.
Еще есть мнение что подсчета коэффициента Херста нужно использовать не обычный МНК, а т.н. RANSAC( http://en.wikipedia.org/wiki/RANSAC ), т.к. при обычном МНК на коэффициент наклона прямой могут влиять точки, "выбивающиеся из общего числа", т.е. наиболее удаленные от общей массы. - Не представляю на основании какой модели, можно решить, что некоторые возвраты подлежат выбросу из выборки?
(닫기[i+1]-닫기[i]) = 0 => log(d[i]/d[i-1]) = INF - 이걸 어떻게 해야 할지 모르겠습니다. RS = R/S - S = 0일 때 계산하는 방법, R = 0도 가정합니까? 그런 다음 다시 (R) = INF를 기록하고 다시 무엇을 해야 하는지 이해가 되지 않습니다. 좋은. 다음은 간단한 예입니다. 계수 H는 무엇입니까?
주어진 간격의 모든 i에 대해 (Close[i+1]-Close[i]) = const라면?
어떤 모델을 기반으로 했는지 잘 모르겠습니다. 샘플에서 일부 수익을 버리는 것으로 결정할 수 있습니까? - 예를 들어 주식 데이터 스트림의 여러 값 값에 오류가 있는 경우(14.4 대신 54.5)
RS 함수는 Close[i]-Close[i-1] 의 배열과 배열 요소의 수를 입력으로 사용합니다.
1. S[i-1] = 닫기[i]-닫기[i-1] 0에서 N까지의 모든 i에 대해
2. h[i] = log(S[i]/S[i-1])
3. Hn = 합 h[i] h_cp = 평균 산술. 엥
4. R = 최대(h[i] - h_cp) - 최소( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
5 . 다음으로, n_min에서 일부 N까지 i에 대해 log RS(i) 및 log i 값을 갖는 m-in 점이 있고 최소 제곱은 직선입니다.
В общем давайте я расскажу свой алгоритм обсчета словами, а вы мне скажете пж где ошибка, а то мы так долго друг друга чуствую не поймем.
функция RS на вход принимает массив из Close[i]-Close[i-1] и число элементов массива
1. S[i-1] = Close[i]-Close[i-1] Для всех i от 0 до N
2. h[i] = log(S[i]/S[i-1]) - не стоит так делать, т.к. п.1 и п.2 в принципе одно и тоже в смысле подготовки данных для алгоритма. Действительно, вместо возвратов на вход можно подавать log(Close[i]/Close[i-1]), но подавать на вход логарифм отношения возвратов - это перебор, по-моему. Достаточно подавать что-нибудь одно - либо разницу цен, либо логарифм их отношений.
3. Hn = Сумма h[i] h_cp = ср.ариф. Hn
4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
5 . Далее стою м-во точек со значением log RS(i) и log i для i от n_min до некоторого N и МНК стоют прямую
в п.3-5 для начала не вижу оператора или описания, что вся выборка делится на N кусков размером M, что для каждого этого куска считается rs = (максимум наращиваемой суммы отклонений от среднего - минимум наращиваемой суммы отклонений от среднего) / сумму квадратов отклонений от среднего, и все они, эти rs, складываются, а потом делятся на N. Теперь Log(RS) и log(N) - это одна точка для МНК, которых надо насобирать побольше, подбирая разные N и М так, чтобы N*M=длина выборки всегда. На мой взгляд, запись п.4 полностью неверна.
내가 알기로는 78개 값에 대한 계수를 계산하는 데 특별한 점은 없는지, 즉 1일 막대에 대해? 일부 값이 0인 경우 어떻게 해야 하는지 여전히 이해가 되지 않습니다. 글쎄요, 예를 들어 가격차이를 입력으로 입력하면 5분차이가 0보다 작거나 같은 것은 분명한데 로그는 취하지 않습니다. 음수(즉, 절대 차이)이면 값의 계수를 취하고 0의 경우에는 이 값을 h 계열에 넣지 마십시오.
실제 테스트 파일입니다. H~0.72
테스트 파일 Brown72.txt 의 표시기 zHursttExponent.mq4 는 0.1647을 제공합니다. 무엇을 위한 것입니까?
내가 이해하는 한, 이 표시기는 마지막 2520개 막대에 대한 각 눈금의 허스트 지수를 계산하고 값을 인쇄합니다. 그래서 ?
그렇다면 이 표시기의 4개 버퍼는 무엇을 의미하며 별도의 창에 필요한 이유는 무엇입니까?
그리고 질문 하나 더.
for(int i=0; i<limit; i++)
{
}
//---- done
표시기 코드에서 이 조각의 의미는 무엇입니까?
테스트 파일 Brown72.txt 의 표시기 zHursttExponent.mq4 는 0.1647을 제공합니다. 무엇을 위한 것입니까?
내가 이해하는 한, 이 표시기는 마지막 2520개 막대에 대한 각 눈금의 허스트 지수를 계산하고 값을 인쇄합니다. 그래서 ?
그렇다면 이 표시기의 4개 버퍼는 무엇을 의미하며 별도의 창에 필요한 이유는 무엇입니까?
그리고 질문 하나 더.
for(int i=0; i<limit; i++)
{
}
//---- done
표시기 코드에서 이 조각의 의미는 무엇입니까?
1. 나는 당신의 결과 = 0.1647을 반복할 수 없습니다. 나는 이것을 가지고 있습니다 (= 0.7241) :
2. 예, 이 표시기는 마지막 2520개 막대에 대한 각 눈금에서 Hurst 지수를 계산하고 값을 인쇄하고 r/s 점(흰색 선)을 그립니다. 이를 따라 근사 직선(빨간색 선)이 만들어지고 기울기는 이것은 알고리즘의 정확성에 대한 질적 시각적 평가를 위해 명확성을 위해 원하는 지표입니다. 이 모든 것은 cRSGraphic = true일 때 true이고, 그렇지 않으면 표시기가 마지막 250개 막대에 대한 Hurst 지수를 계산합니다.
3. 4개의 버퍼 - 이것은 명백한 초과이며, 디버깅 및 테스트 시점에서 남겨진 유물입니다.
4. 공허한 순환 - p.3과 같은 문제. 삭제할 수 있습니다.
Подниму ка тему) Спасибо Vita - написал win32api под c++ и все пашет как надо. Вопрос к людям которые часто применяли этот метод - есть какие-нибудь оценки погрешностей от числа входящих данных, дисперсии, корреляции и мб других стат.величин.
Как я понял вообще смысла особого нет считать коэффициент для 78 величин - т.е для однодневного бара? Так же по прежнему не понимаю что делать если какие-то величины равны нулю. Ну например если на вход подаю разность цен - понятное дело что разность за 5ть минут мб меньше или равны 0, но log тогда не берется. У меня есть идея брать модуль величины в случае если она отрицательна(т.е абсолютную разницу) а в случае 0 не заносить это значение в ряд h.
다음은 오류를 고려하는 옵션입니다. 불행히도 이 기적을 위해 C 소스 코드를 훔친 곳을 찾을 수 없지만 Feder E. Fractals에 따르면 계산된다고 주장합니다. 그를 위해 동일한 파일에 대해 H=0.6807을 테스트하십시오. 나쁘지 않은 것 같습니다.
78등급 중 가장 무겁습니다. 50개의 관찰에 대해 허스트를 평가하는 방법에 대한 많은 작업이 있습니다. 계산을 이해하지 않고도 다른 저자로부터 매우 다른 결과를 얻습니다. 이것에 놀라운 것은 없습니다. 얼마나 많은 알고리즘 - 많은 지표 :). 그리고 더 많은 문제 - 1000 관찰에 대한 첨부 버전에서 오류를 고려하면 가격에 대해 말할 수 있는 것이 없습니다 - 현재 지속되고 있지 않기 때문입니다. 0.5는 오류 채널(cRSGraphic=false인 빨간색 선) 사이에 있습니다.
가격 차이 또는 가격 비율의 로그가 입력으로 제공되어야 합니다.
1. 나는 당신의 결과 = 0.1647을 반복할 수 없습니다. 나는 이것을 가지고 있습니다 (= 0.7241) :
Brown72.txt 파일을 첨부했습니다. 그러나 표시기는 brown72.csv 파일에서 테스트 중입니다. 다른 지침이 없기 때문에 이름을 바꾸고 \experts\files 폴더에 넣었습니다. 결과는 다음과 같습니다.
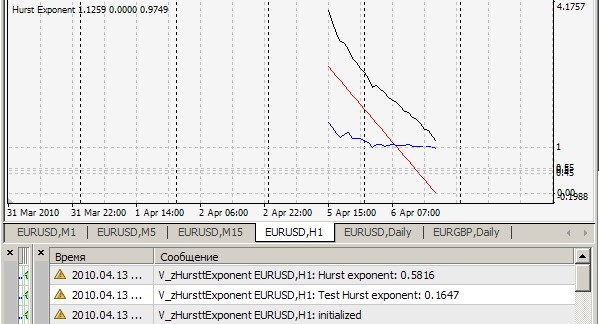
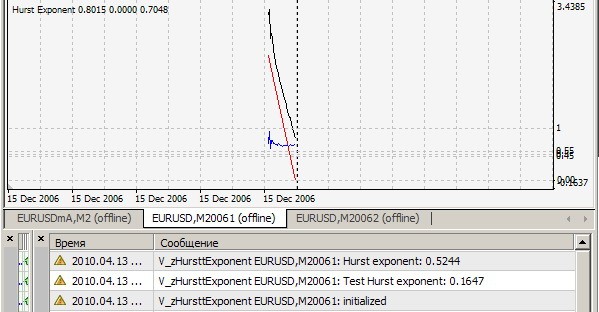
H1:
진드기:
파일에 1024개의 값이 있습니다. 다음은 그 중 처음 4개입니다.
45.47422
42.55601
46.5188
41.61502