
ニューラルネットワークが簡単に(第60回):Online Decision Transformer (ODT)

はじめに
最後の2つの記事は、望ましい報酬の自己回帰モデルの文脈で行動シーケンスをモデル化するDecision Transformer法に費やされました。覚えていらっしゃるかもしれませんが、2つの記事の実践テストの結果によると、テスト期間の初めには、訓練済みモデル結果の収益性がかなり向上していました。さらに進むと、モデルの性能は低下し、多くの不採算取引が観察され、損失につながります。損失額が以前に受け取った利益を上回ることもあります。
定期的なモデルの追加訓練は、おそらくここで役に立つでしょう。しかし、この方法はモデルの運用を非常に複雑にします。よって、オンラインモデル訓練という選択肢を検討するのは極めて合理的です。ここで私たちは、解決しなければならない多くの問題に直面します。
Decision Transformerオンライン訓練の導入オプションの1つは、「Decision Transformer」稿(2022年2月)で紹介されています。提案された方法は、古典的なDTの一次オフライン訓練を使用していることは注目に値します。オンライン訓練は、その後のモデルの微調整に適用されます。著者の論文で紹介されている実験結果は、ODTがD4RLテスト例において、絶対的なパフォーマンスでリーダーに対抗できることを示しています。そのうえ、微調整の段階でより大きな改善が見られます。
提案された方法を、私たちの問題解決の文脈で見てみましょう。
1. ODTアルゴリズム
Online Decision Transformerアルゴリズムについて考える前に、古典的なDecision Transformerについて簡単に復習しましょう。DTはτの軌跡を複数の入力トークンのシーケンスとして処理します。Return-to-Go (RTG)、状態、行動です。特に、RTGの初期値は軌道全体のリターンに等しくなります。t回の一時的なステップで、DTはK回前のトークンを使用してAt行動を生成します。この場合、KはTransformerのコンテキストの長さを指定するハイパーパラメータです。操作中、コンテキストの長さは訓練中よりも短くなることがあります。
DTはππ(At|St, RTGt)決定論的方針を学習します。ここでStはt-K+1からtまでの最後の状態のK個のシーケンスです。同様に、RTGtはKの最後のReturn-to-Goを意味します。これはK次自動回帰モデルです。 エージェント方策は、標準的なMSE(平均二乗誤差)損失関数を使用して行動を予測するように訓練されます。
動作中は、RTGinit初期状態S0の望ましいパフォーマンスを示します。そして、DTはA0行動を生成します。At行動を生成した後、それを実行し、報酬rtを受け取る次の状態St+1を観察します。これによりRTGt+1が得られます。
![]()
先ほどと同様に、DTはA0、S0、S1、RTG0、RTG1を含む軌道に基づいてA1行動を生成します。このプロセスは、エピソードが完結するまで繰り返されます。
オフラインのデータセットのみで訓練された方策は、訓練セットのデータが限られているため、通常は最適とは言えません。オフラインの軌跡はリターンが少なく、状態空間と行動空間の限られた部分しかカバーしていない可能性があります。パフォーマンスを向上させるための自然な戦略は、RLエージェントをさらに訓練し、環境とオンラインで相互作用させることです。しかし、標準的なDecision Transformerでは、オンライン訓練には不十分です。
Online Decision Transformerアルゴリズムは、Decision Transformerに重要な修正を加え、効果的なオンライン訓練を実現します。最初の手順は、一般化された確率的訓練ゴールです。この文脈では、目標は、軌道を繰り返す確率を最大化する確率的方策を訓練することです。
オンラインRLアルゴリズムの主な特性は、探索と利用のバランスをとる能力です。確率的な方策であっても、伝統的なDTの定式化では探査は考慮されていません。この問題を解決するために、ODT法の著者は、軌跡のデータ分布に依存する方策のエントロピーを通して研究を定義しました。この分布は、オフラインの事前訓練中は静的ですが、オンラインセットアップ中は環境との相互作用中に得られる新しいデータに依存するため動的です。
Soft Actor Criticのような既存の最大エントロピーRLアルゴリズムの多くと同様に、ODT法の作者は、探索を奨励するために、方策エントロピーの下限を明示的に定義しています。
ODTの損失関数とSACや他の古典的なRL手法との違いは、ODTの損失関数が割引収益率ではなく、負の対数尤度であることです。基本的には、リターンを明示的に最大化するのではなく、行動シーケンスのパターンを使用して訓練することだけに集中します。また、目的関数は、オフラインとオンラインの両方の訓練において、適切なActor方策に自動的に適応します。オフライン訓練では、クロスエントロピーが分布の発散度を制御し、オンライン訓練では、クロスエントロピーが探索方策を駆動します。
古典的な最大エントロピーRL手法とのもう1つの重要な違いは、ODTでは、方策エントロピーが遷移ではなくシーケンスのレベルで定義されることです。SACがすべての時間手順で方策エントロピーにβの下限を課すのに対して、ODTは連続するK個の時間手順で平均化されるエントロピーを制限します。したがって、この制約は、K個の時間手順のシーケンスで平均したエントロピーが、指定されたβ値より大きいことを要求するだけです。したがって、遷移レベルの制約を満たす方策は、シーケンスレベルの制約も満たします。したがって、K>1の場合、実行可能な方策空間はより大きくなります。K=1のとき、シーケンスレベルの制約は、SACと同様のトランジションレベルの制約に縮小されます。
モデルの訓練中、再生バッファは、定期的な更新で過去の経験を記録するために使用されます。既存のほとんどのRLアルゴリズムでは、経験レンダリングバッファはトランジションで構成されています。1エポック内のオンライン相互作用の各段階の後、エージェントの方策とQ関数が勾配降下法を用いて更新されます。その後、方策が実行され、新しいトランジションが収集され、経験再生バッファに追加されます。ODTの場合、経験再生バッファは遷移ではなく軌跡で構成されます。予備的なオフライン訓練の後、オフラインデータセットから最大の結果を得た軌道を使用して、経験再生バッファを初期化します。環境と相互作用するたびに、現在の方策でエピソードを完全に実行します。次に、収集した軌跡をFIFO順で使用して、経験再生バッファを更新します。次に、エージェント方策を更新し、新しいエピソードを実行します。平均的な行動を用いて方策を評価すると、通常、より高い報酬が得られるが、無作為な行動を用いる方がより多様な軌跡や行動パターンが生成されるため、オンライン調査には有用です。
さらに、ODTアルゴリズムは、追加のオンラインデータを収集するために、初期RTGの形でハイパーパラメータを必要とします。様々な研究が、オフラインDTの実際の推定リターンは経験的に初期RTGと強い相関があり、オフラインデータセットで観測された最大リターンを超えてRTG値を外挿できることが多いことを示しています。ODTの著者は、このハイパーパラメータを、既存の専門家の結果から小さな固定スケーリングで設定するのが最善であることを発見しました。この方法の著者たちは、2倍のスケーリングを使用しています。原著論文では、もっと大きな値や、訓練中に変化する値(例えば、オフラインとオンラインのデータセットにおける最良推定リターンの分位数)を用いた実験結果が示されています。しかし、実際には固定式RTGほどの効果はありませんでした。
DTと同様に、ODTアルゴリズムは、再生バッファ内の長さKの部分軌跡の均一な標本化を保証するために、2段階の標本化手順を使用します。まず、軌跡をその長さに比例した確率で標本化します。そして、長さKの部分軌道を等確率で選択します。
このメソッドの実用的な実装については、次のセクションで紹介します。
2.MQL5を使用した実装
このメソッドの理論的側面を理解した後は、実践的な実施に移りましょう。このセクションでは、提案されたアプローチの実装に関する私たち自身のビジョンと、過去の記事からの発展を補足して紹介します。特に、ODTアルゴリズムには2段階のモデル訓練が含まれています。
- オフラインでの予備訓練
- 環境とのオンライン相互作用中にモデルを微調整します。
この記事では、前回の記事で訓練済みのモデルを使用します。したがって、先に実施したオフライン訓練の第1段階は省略し、すぐにモデル訓練の第2段階に移ります。
また、前回の記事でDoC法を検討する際、2つのモデルを構築し、オフラインで訓練を実施したことにも留意しておきたいと思います。
- RTG生成
- Actorの方策
RTGモデル生成の使用は、最初のRTGに専門家による評価スケーリングを使用し、その後に得られた実際の結果に合わせて目標を調整することを提案する、オリジナルのODTアルゴリズムとは一線を画しています。
加えて、過去に訓練されたモデルを使用しても、モデルのアーキテクチャを変更することはできませんが、使用されているモデルのアーキテクチャがODTアルゴリズムにどのように対応しているか見てみましょう。
この方法の著者は、確率的Actor方策を使用することを提案しています。これは以前の記事で使用したモデルです。
ODTは、個々の軌跡の代わりに軌跡経験再生バッファを使用することを提案しています。これはまさに私たちが扱っているバッファです。
モデルを訓練する際、環境探索を促すために損失関数のエントロピー成分は使用しませんでした。現段階では、それを追加せず、起こりうるリスクを受け入れます。確率論的Actor方策とRTG生成モデルが、環境とのオンライン相互作用の過程で十分な探索を提供することを期待しています。
私の実装から除外したもう1つのポイントは、経験再生バッファに関するものです。オフライン訓練の後、この方法の著者は、オンライン訓練の最初の段階で使用される、最も収益性の高い軌道の数を選択することを提案しています。当初は、経験再生バッファ内の軌跡の数を制限しました。オンライン訓練に移行する際には、既存の経験再現バッファをすべて使用し、そこに環境との相互作用の過程で新たな軌跡を追加していきます。同時に、新しい軌跡を追加する際には、最も古い軌跡を即座に削除しません。パス完了後にデータをファイルに保存する際には、事前に作成した手段を使用してバッファサイズを制限します。
このように、起こりうるリスクを考慮すれば、前回の記事で訓練したモデルを簡単に使用することができます。そして、ODTアプローチによるモデルのオンライン訓練プロセスを微調整することで、その効率化を図ります。
ここで、いくつかの建設的な問題を解決しなければなりません。取引プロセスは、その性質上、条件付きでエンドレスです。「条件付きで」と言ったのは、さまざまな理由からまだ有限だからです。しかし、予見可能な未来にそのような出来事が起こる確率は非常に小さく、それを無限大と考えています。その結果、この手法の著者が提案するように、エピソードの終了後ではなく、一定の頻度で追加訓練のプロセスを実施します。
ここで、私たちのDTの実装では、最後のバーのデータのみがモデル入力に供給されることを思い出してください。過去のデータコンテキストの全容量は、 埋め込み層の結果バッファに保存されます。このアプローチにより、冗長なデータの再処理にかかるリソース消費を抑えることができました。しかし、これはオンライン訓練の道における「つまずき」の1つとなります。実は、埋め込みバッファのデータは、厳密な歴史的順序で保存されています。定期的な追加訓練の過程でモデルを使用すると、他の軌跡、または同じ軌跡だが異なるセグメントの履歴データでバッファを再充填することになります。このため、モデルの追加訓練後に環境との相互作用を続けた場合、データに歪みが生じます。
この問題を解決するには、実はいくつかの選択肢があります。いずれも、実装の複雑さや運用時のリソース消費はさまざまです。一見したところ、最も単純なのは、バッファのコピーを作成し、環境との相互作用を続ける前に、バッファを訓練開始前の状態に戻すことです。しかし、そのプロセスを詳しく調べてみると、メインモデルの側では、ニューラル層の個々のバッファにアクセスすることなく、モデルの最上位クラスだけで作業がおこなわれていることがわかります。この文脈では、あるバッファのデータをモデルからコピーしてモデルに戻すという単純な作業が、多くの設計変更につながります。これはこの方法の実装を著しく複雑にしています。
モデルに建設的な変更を加えることなく、追加訓練の完了後、過去のデータセット全体をモデルに繰り返し転送することができます。しかし、これではフォワードモデルのパス操作をかなり繰り返すことになります。このような操作の量は、コンテキストのサイズが大きくなるにつれて増えていきます。そのため、このアプローチは非効率的です。データの再処理のための時間とコンピューティングリソースの消費は、ニューラル層のバッファに埋め込みの履歴を保存することによって達成される節約を上回る可能性があります。
この問題のもう1つの解決策は、重複モデルを使用することです。1つは環境との相互作用に必要なものです。2つ目は追加訓練で使用されます。このアプローチは、メモリリソースの点ではより高価ですが、 埋め込み層のバッファのデータの問題を完全に解決します。しかし、モデル間のデータ交換の問題が生じます。結局のところ、追加の訓練の後、環境との相互作用のモデルは、更新されたエージェントの方策を使用する必要があります。RTGの世代交代モデルも同様です。ここで、目標モデルをソフトに更新するSoft Actor-Critic法を思い出すことができます。奇妙に思えるかもしれませんが、これは、埋め込み層の結果のバッファを含む残りのバッファを変更することなく、モデル間で更新された重み付け比率を転送することを可能にするメカニズムです。
このアプローチを使用するには、SACの実装ではこれまで使用されていなかった重み交換法を埋め込み層に追加しなければなりません。
ここで、メソッドを追加するときは、CNeuronEmbeddingOCLクラスに直接追加するだけであると言う必要があります。CNeuronEmbeddingOCLクラスの機能に必要なすべてのAPIは、すでに構築して、CNeuronBaseOCLニューロ層の基本クラスの仮想メソッドの形で実装しているからです。また、指定された修正をおこなわなくても、このモデルの動作がエラーを発生させることはないことに注意すべきです。結局のところ、親クラスのメソッドがデフォルトで使用されます。しかし、この場合の仕事は完全で正しいものではありません。
仮想メソッドの一貫性と正しいオーバーライドを維持するために、パラメータを保存するメソッドを宣言します。メソッド本体では、すぐに親クラスの同様のメソッドを呼び出します。
bool CNeuronEmbeddingOCL::WeightsUpdate(CNeuronBaseOCL *source, float tau) { if(!CNeuronBaseOCL::WeightsUpdate(source, tau)) return false;
何度も言うように、親クラスを呼び出すこのアプローチによって、不必要な重複をすることなく、必要なコントロールを1つの行動で実装し、継承されたオブジェクトで必要な操作を実行することができます。
親クラスのメソッドの操作が成功したら、埋め込みクラスで直接宣言されたオブジェクトの操作に移ります。しかし、ドナークラスの似たようなオブジェクトにアクセスするためには、結果のオブジェクトの型をオーバーライドする必要があります。
//---
CNeuronEmbeddingOCL *temp = source;
次にWeightsEmbeddingバッファのパラメータを転送する必要があります。しかし、操作を続ける前に、現在のオブジェクトとドナーオブジェクトのバッファサイズを比較します。
if(WeightsEmbedding.Total() != temp.WeightsEmbedding.Total()) return false;
そして、あるバッファから別のバッファにコンテンツを転送しなければなりません。しかし、バッファを使用した操作はすべてOpenCLコンテキスト側で実行されることを覚えておきましょう。そのため、データ転送はコンテクスト側でおこないます。「コピー」ではなく、あえて「データ転送」という表現を使用しています。SACアルゴリズムが目標モデルに対して提供したように、比率による「ソフトコピー」の可能性を残しています。OpenCLプログラムカーネルは以前に作成されています。あとは呼び出しを手配するだけです。
重量比バッファのサイズでカーネルタスク空間を定義します。
uint global_work_offset[1] = {0}; uint global_work_size[1] = {WeightsEmbedding.Total()};
次に、使用するパラメータ更新アルゴリズムに応じたアルゴリズムの分岐が続きます。Adam法を使用すると、より多くのバッファとハイパーパラメータが必要になるため、分岐が必要です。これは異なるカーネルを使用することにつながります。
まず、Adam法の分岐を作ります。これを使用するには、2つの条件を満たす必要があります。
- 対応するデータバッファのオブジェクトの作成はこれに依存するため、オブジェクトの作成時にパラメータを更新するための適切な方法を指定します。
- 更新率は1とは異なるべきです。1の場合、使用されるパラメータ更新方法に関係なく、データの完全なコピーが必要になります。
if(tau != 1.0f && optimization == ADAM) { if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_target, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_source, temp.WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_m, FirstMomentumEmbed.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_v, SecondMomentumEmbed.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_tau, (float)tau)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b1, (float)b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b2, (float)b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SoftUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } }
そして、SoftUpdateAdamカーネルを実行キューに送ります。
アルゴリズムの2つ目の分岐でも同様の操作をおこないますが、これはSoftUpdateカーネルに対してです。
else { if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdate, def_k_su_target, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdate, def_k_su_source, temp.WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdate, def_k_su_tau, (float)tau)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SoftUpdate, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
建設的な問題は解決されたので、オンライン訓練法の実践に移ることができます。EA「...\DoC\OnlineStudy.mq5」において、環境との相互作用とモデルの同時追加訓練の過程を整理します。このEAは、訓練のためのデータ収集とモデルの直接的なオフライン訓練のために、以前の記事で説明したEAの一種の共生です。環境と相互作用するために必要なすべての外部パラメータ、特に指標パラメータが含まれています。しかし同時に、オンライン訓練の頻度と反復回数を示すパラメータを追加します。デフォルトのEAには主観的なデータが含まれています。訓練の頻度を120本のローソク足で示しましたが、これはH1時間枠ではおよそ1週間(5日×24時間)に相当します。最適化の際に、モデルにとってより最適な値を選択することができます。
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod= 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price //--- input int StudyIters = 5; //Iterations to Study input int StudyPeriod = 120; //Bars between Studies
EAの初期化メソッドでは、まず、以前に作成した経験再生バッファをアップロードします。Study.mql5訓練EAにおいても、様々なオフライン訓練方法に対して同様の操作をおこないました。データを読み込みめなくてもEAを終了させないようにしました。オフラインモードとは異なり、環境と相互作用する際に収集される新しいデータに対してのみモデルの訓練を許可します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { LoadTotalBase();
次に、先ほどのEAと同じように、環境との相互作用に関する指標を用意します。
if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
モデルを読み込み、ソースデータ層のサイズと結果の適合性を確認してみましょう。必要であれば、事前に定義されたアーキテクチャで新しいモデルを作成します。これはモデルの追加訓練の範囲を少し超えていますが、ユーザーが「ゼロから」オンライン訓練を実施する機会を残しています。
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTG.Load(FileName + "RTG.nnw", dtStudied, true) || !AgentStudy.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTGStudy.Load(FileName + "RTG.nnw", dtStudied, true)) { PrintFormat("Can't load pretrained models"); CArrayObj *agent = new CArrayObj(); CArrayObj *rtg = new CArrayObj(); if(!CreateDescriptions(agent, rtg)) { delete agent; delete rtg; PrintFormat("Can't create description of models"); return INIT_FAILED; } if(!Agent.Create(agent) || !RTG.Create(rtg) || !AgentStudy.Create(agent) || !RTGStudy.Create(rtg)) { delete agent; delete rtg; PrintFormat("Can't create models"); return INIT_FAILED; } delete agent; delete rtg; //--- } //--- Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } AgentResult = vector<float>::Zeros(NActions); //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Agent.Clear(); RTG.Clear();
各モデルのコピーを2つ読み込む(または初期化)ことにご注意ください。1つは環境との相互作用に必要なものです。もう1つは訓練で使用されます。訓練されたモデルにはStudyという接尾辞が付けられます。
次に、グローバル変数を初期化し、メソッドを終了します。
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
EA初期化解除メソッドでは、訓練済みモデルと累積された経験値の再生産バッファを保存します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- AgentStudy.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); RTGStudy.Save(FileName + "RTG.nnw", TimeCurrent(), true); delete Result; int total = ArraySize(Buffer); printf("Saving %d", MathMin(total + 1, MaxReplayBuffer)); SaveTotalBase(); Print("Saved"); }
訓練済みモデルのバッファには、その後のモデルの訓練と操作に必要なすべての情報が含まれているため、訓練済みモデルを保存することにご注意ください。
環境との相互作用のプロセスは、OnTickティック処理メソッドに配置されています。メソッドの冒頭で、新しいバーオープニングイベントの発生を確認し、必要であれば指標パラメータを更新します。また、値動きのデータもダウンロードしています。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
端末から受信したデータを、入力データとして環境との相互作用モデルに送信するために準備します。
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
データバッファに口座ステータスに関する情報を追加してみましょう。
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
次に、タイムスタンプを作成します。
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
現在の状態に至ったエージェントの最新の行動のベクトルを追加します。
//--- Prev action
bState.AddArray(AgentResult);
収集されたデータは、RTG生成モデルのフォワードパスを実行するのに十分です。
//--- Return to go if(!RTG.feedForward(GetPointer(bState))) return;
実際、初期データのベクトルには、現在の期間におけるエージェントの最適な行動を予測するためのデータが欠けているだけです。したがって、最初のモデルのフォワードパスが成功したら、得られた結果をソースデータバッファに追加し、Actorのフォワードパスメソッドを呼び出します。操作の結果を必ず確認します。
RTG.getResults(Result); bState.AddArray(Result); //--- if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
モデルを通してフォワードパスを成功させた後、その結果を解読し、選択した行動を環境で実行します。このプロセスは、先に述べた環境との相互作用モデルのアルゴリズムと完全に一致しています。
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
現在の状態への遷移に対する環境からの報酬を評価します。収集したすべての情報を送信し、現在の軌道を形成します。
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove();
これで環境との相互作用のプロセスは完了しました。しかし、この方法を終了する前に、モデルの追加訓練のプロセスを開始する必要性を確認します。おそらく、メソッドの効率をテストするために最も単純なコントロールを使用しました。単に、訓練期間の分析時間枠における、その商品の全体的な履歴の大きさの倍数を確認します。日常業務では、追加訓練を市場閉鎖や商品のボラティリティが低下する時期にシフトさせるなど、より思慮深いアプローチを用いることが望ましいです。さらに、すべてのポジションがクローズされるまで、モデルパラメータの更新を遅らせることが有効な場合もあります。一般的に、実際のモデルで使用するためには、モデルの追加訓練の頻度と時間の選択について、よりバランスの取れた有意義なアプローチを推奨します。
//--- if((Bars(_Symbol, TimeFrame) % StudyPeriod) == 0) Train(); }
次に、Trainモデルの訓練方法に注目します。ここで注目すべきは、現在の環境との相互作用の過程で得られた経験を考慮して、追加訓練が実施されることです。ティック処理メソッドでは、環境から受け取った情報をすべて別の軌跡に集めました。しかし、この軌跡は経験再生バッファには追加されません。以前は、このような操作はエピソードが終わってからおこなっていましたが、この方法は、パラメータを定期的に更新する場合には受け入れられません。結局のところ、エージェントの方策が過去の経験による固定された軌道のみで訓練されるオフライン訓練に近づきます。そこで、訓練を開始する前に、収集したデータを経験再生バッファに追加します。
あまりに短く情報量の少ない軌跡の記録を防ぐため、保存される軌跡の最小サイズを制限します。与えられた例では、モデルパラメータの更新期間中の軌道の最小サイズを制限しました。
累積された軌跡のサイズが最低条件を満たしていれば、それを経験再生バッファに追加し、累積報酬額を再計算します。
ここで注意しなければならないのは、経験再生バッファに転送された軌跡のコピーに対してのみ、累積報酬量を再計算していることです。現在の軌道に関する情報を累積するための初期バッファでは、報酬はカウントされないままであるべきです。その後の環境との相互作用によって、軌道は補足されます。したがって、更新された軌跡がさらに追加されると、累積報酬の再計算が繰り返され、データが倍増することになります。これを防ぐため、計算されなかった報酬は常に軌跡累積バッファに残しておきます。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); if(Base.Total >= StudyPeriod) if(ArrayResize(Buffer, total_tr + 1) == (total_tr + 1)) { Buffer[total_tr] = Base; Buffer[total_tr].CumRevards(); total_tr++; }
次に、軌跡累積バッファのサイズはBuffer_Size定数によって制限されることを覚えておきましょう。配列の限界を超えてしまうエラーを防ぐため、軌跡の累積バッファに、次の軌跡の保存まで手順を記録するのに十分な空きセルがあることを確認します。必要であれば、古い手順のいくつかを削除します。
一次軌道累積バッファのデータを削除していることにご注意ください。同時に、この情報は経験再生バッファに保存した軌跡のコピーに保存されます。
モデルの定数やパラメータを指定する際には、軌跡バッファのサイズが、モデルの追加訓練の間に少なくとも1期間の履歴を保存できることを確認する必要があります。
int clear = Base.Total + StudyPeriod - Buffer_Size; if(clear > 0) Base.ClearFirstN(clear);
それからもう1つ、不必要に思えるかもしれませんが、コントロールを追加しました。経験再生バッファに短い軌道がないか確認し、見つかれば削除します。一見したところ、経験再現バッファに軌跡を追加する前に同様のコントロールが存在するため、このような軌跡の存在は考えにくいです。しかし、ファイルへの軌跡の読み書きに失敗する可能性はあります。この確認は、その後のエラーを排除するためにおこないます。
//--- int count = 0; for(int i = 0; i < (total_tr + count); i++) { if(Buffer[i + count].Total < StudyPeriod) { count++; i--; continue; } if(count > 0) Buffer[i] = Buffer[i + count]; } if(count > 0) { ArrayResize(Buffer, total_tr - count); total_tr = ArraySize(Buffer); }
次に、モデルの訓練サイクルをアレンジします。このプロセスは前回とほぼ同じです。外部ループは、EAの外部パラメータで指定されたモデル訓練の反復回数に従って構成されます。
ループの本体では、軌道と軌道の要素を無作為に選択し、そこからモデル訓練の次の反復を開始します。
uint ticks = GetTickCount(); //--- bool StopFlag = false; for(int iter = 0; (iter < StudyIters && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
次に、モデル埋め込みバッファと、以前のActor行動のベクトルをクリアします。
vector<float> Actions = vector<float>::Zeros(NActions); AgentStudy.Clear(); RTGStudy.Clear();
この段階で準備作業は完了し、モデルの訓練を開始することができます。ネストされた学習ループをアレンジします。
ループの本体では、上述のティック処理方法と同様に、ソースデータバッファを準備するプロセスを繰り返します。バッファへのデータ書き込みのシーケンスは完全に繰り返されます。ただし、これまでは端末にデータを要求していましたが、これからは経験再生バッファからデータを取得します。
for(int state = i; state < MathMin(Buffer[tr].Total - 2, int(i + HistoryBars * 1.5)); state++) { //--- History data bState.AssignArray(Buffer[tr].States[state].state); //--- Account description float prevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float prevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); bState.Add((Buffer[tr].States[state].account[0] - prevBalance) / prevBalance); bState.Add(Buffer[tr].States[state].account[1] / prevBalance); bState.Add((Buffer[tr].States[state].account[1] - prevEquity) / prevEquity); bState.Add(Buffer[tr].States[state].account[2]); bState.Add(Buffer[tr].States[state].account[3]); bState.Add(Buffer[tr].States[state].account[4] / prevBalance); bState.Add(Buffer[tr].States[state].account[5] / prevBalance); bState.Add(Buffer[tr].States[state].account[6] / prevBalance); //--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(Actions);
初期データの最初の部分を収集した後、RTG生成モデルのフォワードパスを実行します。そして、実際に受け取った報酬との誤差を最小にするために、すぐにダイレクトパスを実行します。従って、過去の状態と行動の軌跡に基づいて、可能性のある報酬を予測するための自己回帰モデルを構築します。
//--- Return to go if(!RTGStudy.feedForward(GetPointer(bState))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } Result.AssignArray(Buffer[tr].States[state + 1].rewards); if(!RTGStudy.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
エージェントの方策の訓練のために、予測RTGの代わりに、ソースデータバッファで実際に受け取った報酬を示し、ダイレクトパスを実行します。
//--- Policy Feed Forward bState.AddArray(Buffer[tr].States[state + 1].rewards); if(!AgentStudy.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
エージェントの方策は、予測された行動と実際に実行された行動との誤差を最小化するように訓練され、報酬を受け取ることになります。
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; AgentStudy.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!AgentStudy.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
これにより、エージェントが過去に訪問した状態と完了した行動の文脈の中で、所望の報酬を得るために最適な行動を選択するための自己回帰モデルを構築することができます。
モデル訓練の反復が正常に完了すると、訓練操作の進捗状況をユーザーに通知し、モデル訓練ループの次の反復に移ります。
モデル訓練プロセスの入れ子ループのすべての繰り返しが完了したら、グラフ上のコメントフィールドを消去し、訓練済みモデルから環境相互作用モデルにパラメータを転送します。上の例では、重み付け係数のデータを完全にコピーしています。このように、訓練と運用に1つのモデルを使用することをエミュレーションます。ただし、データのコピー比率を変えて実験することも認めています。
Comment(""); //--- Agent.WeightsUpdate(GetPointer(AgentStudy), 1.0f); RTG.WeightsUpdate(GetPointer(RTGStudy), 1.0f); //--- }
これで、Transformer Online訓練EAアルゴリズムが終了しました。EAの全コードと全メソッドを添付ファイルでご覧ください。
なお、「...\DoC\OnlineStudy.mq5」EAは、前回のEAと一緒に「DoC」サブディレクトリにあります。機能的には、前回の記事でオフラインEAによって訓練されたモデルの追加訓練をおこなうので、別のサブディレクトリには分けていません。こうすることで、モデルの訓練ファイル一式の整合性を保つことができます。
また、今回の記事と前回の記事で使用したすべてのプログラムを添付ファイルで見ることができます。
3.検証
Online Decision Transformer法の理論的側面を検討し、提案された方法の独自の解釈を構築しました。次の段階は、出来上がった仕事をテストすることです。実際、前回の記事のモデルを微調整しています。この目的のために、ストラテジーテスターで訓練データの履歴に対して、新しいEAの単回実行を繰り返します。
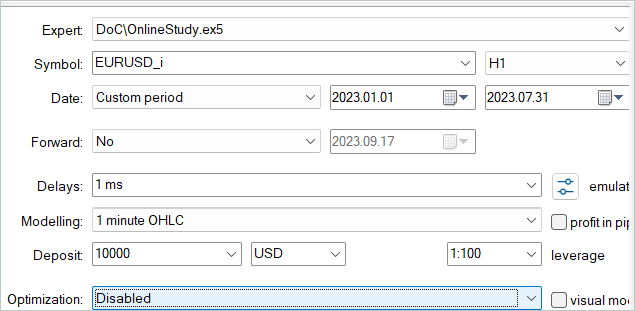
前回の記事では、2023年の最初の7ヶ月間の過去データを使用してモデルのオフライン訓練をおこないました。モデルを微調整するのは、この同じ歴史的な期間です。
モデルを微調整する過程で、ODTはモデル全体の収益性を向上させました。2023年8月のテスト例では、このモデルは約10%の利益を得ることができました。利回りチャートは完璧ではありませんが、すでにいくつかのトレンドが見られます。

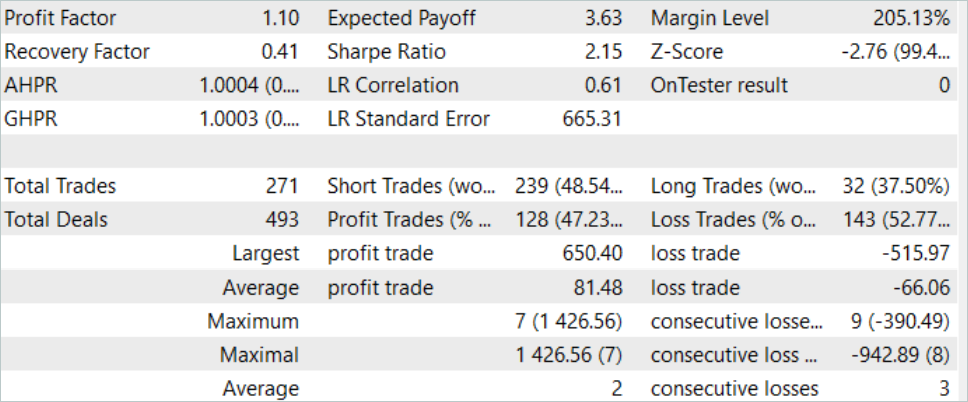
訓練済みモデルのテスト結果は上記の通りです。テスト期間中、合計271件の取引がおこなわれました。そのうち128件が黒字決算となり、47%以上の利益を計上しました。見てわかるように、利益が出ている取引の割合は、負けている取引よりもわずかに少なくなっています。しかし、最大利益の取引は最大損失より26%大きいです。平均的な利益取引は、平均的な負け取引より20%以上高いです。この結果、このモデルの利益率を1.10まで高めることができました。
結論
この記事では、Decision Transformer法の効率を高めるための選択肢を引き続き検討し、Online Decision Transformer (ODT)訓練モードでモデルを微調整するアルゴリズムを紹介しました。この方法により、オフラインで訓練さたモデルの効率を高めることができ、エージェントは環境の変化に適応することができるため、環境との相互作用を通じて方策を改善することができます。
実践編では、MQL5を使用してこの方法を実装し、前回の記事のモデルのオンライン訓練を実施しました。ここで注目すべきは、モデルの最適化は、考慮されたODT法を使用することによってのみ得られたということです。オンライン訓練では、前回の記事でオフラインで訓練したモデルを使用しました。モデルアーキテクチャの設計変更はおこなっていません。追加のオンライン訓練のみが提供されています。これによって、モデルの効率を高めることが可能になり、それ自体がOnline Decision Transformer法の効率の高さを裏付けています。
繰り返しになりますが、この記事で紹介するプログラムはすべて、技術のデモンストレーションを目的としたものであり、実際の取引に使用できるものではないことをお断りしておきます。
リンク
- Decision Transformer:Reinforcement Learning via Sequence Modeling
- Online Decision Transformer
- Dichotomy of Control:Separating What You Can Control from What You Cannot
- ニューラルネットワークが簡単に(第34回):完全にパラメータ化された分位数関数
- ニューラルネットワークが簡単に(第58回):Decision Transformer (DT)
- ニューラルネットワークが簡単に(第59回):コントロールの二分法(DoC)
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練EA |
| 3 | OnlineStudy.mq5 | EA | エージェント向け追加オンライン訓練のEA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13596
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索