
MQL5の圏論(第7回):多重集合、相対集合、添字集合
序章
前回の記事では、錐と合成の変更が感度分析の結果にどのような影響を与える可能性があるかを検討しました。これにより、取引できる指標や証券に応じてシステム設計の機会が得られます。今回は、遭遇する可能性のあるさまざまなタイプの特別/固有の始域を詳しく調べ、それらの関係を価格変動の期待を緩和するためにどのように利用できるかを探っていきます。
多重集合
圏論における多重集合(別名バッグまたはヒープ)は、同じ要素が複数出現することを可能にする始域を一般化したものです。第1回で、始域の厳密な定義では、すべての要素が一意である必要があることを思い出してください。多重集合は、始域内の要素のすべてのメタデータを適切に取得するために、始域内の要素の繰り返しが必要な状況に対応します。たとえば、次の文の単語で構成される始域を考えてみましょう。
「Sets theory deals with sets, while category theory deals with sets of sets, sets of sets of sets, and so on.」
通常、これは始域内で次のように表現されます。
{sets, theory, deals, with, while, category, of, and, so, on}
ただし、ご覧のとおり、文の完全な意味は失われています。この追加情報を取得するために、多重集合Xは正式に次のように定義されます。
X:=(N,π)
- Nは、Xの要素を反復せずに列挙するだけであるため、Xの典型的な始域表現です。
- そしてπはXからNへの準同型性です。
π:X→N、
NはX内の名前のセット、πはXの命名関数と呼ばれることが多いです。名前x ∈ Nが与えられ、π -1(x) ∈ Xが原像として使用されます。π -1(x) の要素の数は x の多重度と呼ばれます。
これらをすべてまとめると、次の図が得られます。
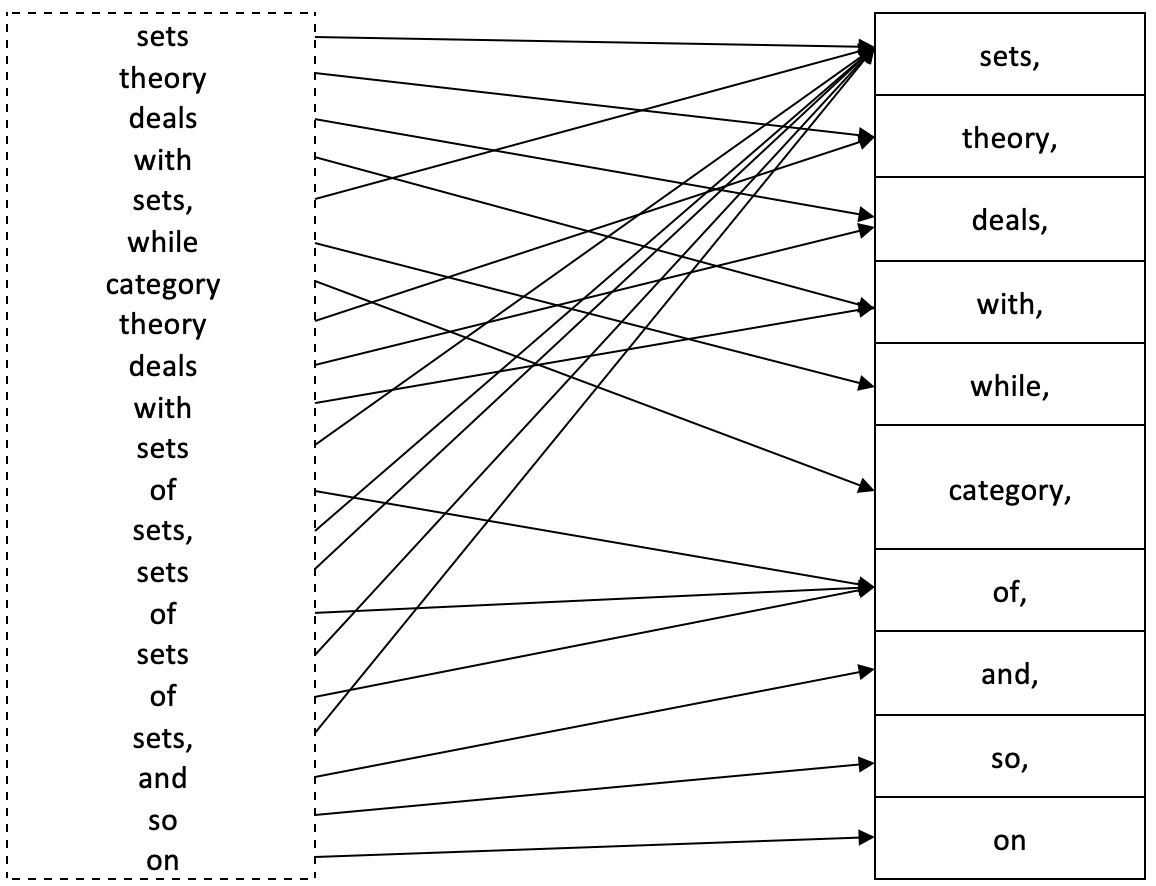
したがって、「sets」の多重度は8、「deals」の多重度は2、「category」の多重度は1、などとなります。
トレーダー向けにこれをさらに説明するために、価格の時系列を考えてみましょう。価格バー範囲の変化に興味があり、以前の価格バーのアクションを使用してこれらの変化を予測したい場合、この関係を説明する2つの領域を思いつくことができます。
以前の価格行動を多次元のデータセットとして、予測したい変化を1次元として捉える場合、この2つの間の準同型性により、トレーニングラグ(たとえば1つの価格バー)を超えて両方の領域が接続されます。以下の図は、これをわかりやすく示します。

この準同型性セットは多次元領域を表します。これは、複数のデータ点(場合によっては1つだけ)を扱う場合、始域で必ず繰り返しが発生するためです。終域の場合、すべてのデータポイントを、結果として生じる価格範囲の変化の大きさをパーセントで表す-100から+100の範囲の整数として正規化できます。この正規化は、繰り返しがないことを意味するため、終域内の要素は以下のように推測できます。
{-100、-80、-60、-40、-20、0、20、40、60、80、100}
全体のサイズは11です。 2次元を超える領域データを考慮することで、この準同型性セットをさらに一歩進めることができます。価格バー範囲の変化を予測する際に複数のラグを考慮したと仮定する場合、以下の図を見てみましょう。

これは上記のものと似ていますが、唯一の違いはデータポイントの追加です。理想的には、始域と終域に十分なデータポイントを蓄積するようにモデルをトレーニングする必要があり、それを使用するには、終域にマッピングするときに多くのメソッドを使用できます。この記事では、終域予測を選択するために勝者総取りのアプローチを使用することを検討できます。勝者総取りは、新しいまたは現在の入力データからの距離が始域内のすべてのデータ点の中で最も近い多次元データ点 (要素クラスは配列であるため、単純にベクトルまたは配列として表されます) になります。これは、以下のコードに示すようにキャプチャされます。
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int CTrailingCT::Morphisms_A(CHomomorphism<double,double> &H,CDomain<double> &D,CElement<double> &E,int CardinalCheck=4) { int _domain_index=-1,_codomain_index=-1; if(E.Cardinality()!=CardinalCheck){ return(_domain_index); } double _least_radius=DBL_MAX; for(int c=0;c<D.Cardinality();c++) { double _radius=0.0; m_element_a.Let(); if(D.Get(c,m_element_a)) { for(int cc=0;cc<E.Cardinality();cc++) { double _e=0.0,_d=0.0; if(E.Get(cc,_e) && m_element_a.Get(cc,_d)) { _radius+=pow(_e-_d,2.0); } } } _radius=sqrt(_radius); if(_least_radius>_radius) { _least_radius=_radius; _domain_index=c; } } // for(int m=0;m<H.Morphisms();m++) { m_morphism_ab.Let(); if(H.Get(m,m_morphism_ab)) { if(m_morphism_ab.Domain()==_domain_index) { _codomain_index=m_morphism_ab.Codomain(); break; } } } return(_codomain_index); }
このモデルに圏理論を適用するには、以前の記事ですでに触れた可換性の概念を考慮します。以下に示す図を適応させると、準同型写像πとπ'で多重集合の配置が得られ、可換性があるということは、価格帯の変化を予測する2つの方法があることを意味します。
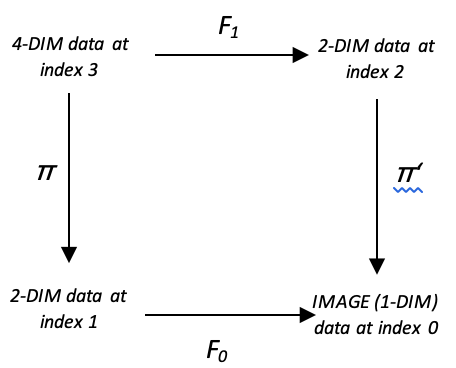
これを使用して予測を取得する方法は、次のようにして実現できます。
- 2つの投影の平均を取る
- 最大値を取るか、
- 最小値を使用する
共有コードについては、以下のコードスニペットに示すように、最小値、平均値、最大値の間で選択するオプションが提供されています。
//+------------------------------------------------------------------+ //| Checking trailing stop and/or profit for short position. | //+------------------------------------------------------------------+ bool CTrailingCT::CheckTrailingStopShort(CPositionInfo *position,double &sl,double &tp) { //--- check if(position==NULL) return(false); Refresh(); m_element_a.Let(); m_element_b.Let(); m_element_c.Let(); m_element_bd.Let(); m_element_cd.Let(); SetElement_A(StartIndex(),m_element_a); int _b_index=Morphisms_A(m_multi_domain.ab,m_multi_domain.ab.domain,m_element_a,4); int _c_index=Morphisms_A(m_multi_domain.ac,m_multi_domain.ac.domain,m_element_a,2); SetElement_B(StartIndex(),m_element_b); SetElement_C(StartIndex(),m_element_c); int _b_d_index=Morphisms_D(m_multi_domain.bd,m_multi_domain.bd.domain,m_element_b,2); int _c_d_index=Morphisms_D(m_multi_domain.cd,m_multi_domain.cd.domain,m_element_c,2); int _bd=0,_cd=0; if(m_multi_domain.bd.codomain.Get(_b_d_index,m_element_bd) && m_element_bd.Get(0,_bd) && m_multi_domain.cd.codomain.Get(_c_d_index,m_element_cd) && m_element_cd.Get(0,_cd)) { m_high.Refresh(-1); m_low.Refresh(-1); int _x=StartIndex(); double _type=0.5*((_bd+_cd)/100.0); //for mean if(m_type==0){ _type=fmin(_bd,_cd)/100.0; } //for minimum else if(m_type==2){ _type=fmax(_bd,_cd)/100.0; } //for maximum double _atr=fmax(2.0*m_spread.GetData(_x)*m_symbol.Point(),m_high.GetData(_x)-m_low.GetData(_x))*(_type); double _sl=m_high.GetData(_x)+(m_step*_atr); double level =NormalizeDouble(m_symbol.Ask()+m_symbol.StopsLevel()*m_symbol.Point(),m_symbol.Digits()); double new_sl=NormalizeDouble(_sl,m_symbol.Digits()); double pos_sl=position.StopLoss(); double base =(pos_sl==0.0) ? position.PriceOpen() : pos_sl; sl=EMPTY_VALUE; tp=EMPTY_VALUE; if(new_sl<base && new_sl>level) sl=new_sl; } //--- return(sl!=EMPTY_VALUE); }
2022.01.01から2022.08.01までの毎日の時間枠でEURGBPのテストを実行し、組み込みのAwesome Oscillator (‘SignalAO.mqh’)のような単純なシグナルを使用すると、次のレポートが得られます。

コントロールとして、同じシグナルを同様に実行しますが、同じポジションサイジングクラス(固定証拠金)で同じ期間および同じ毎日の時間枠にわたる移動平均を使用する組み込みのトレーリングクラスの1つを使用すると、次のレポートが得られます。

これは、トレーリングストップの決定を通知するために価格バー範囲の変化を予測するだけでなく、場合によってはシグナルや資金管理の決定にさえ多重集合を使用できる可能性を物語っています。この記事ではトレーリングストップについてのみ説明したので、他の2つの適応については時間のあるときに探索してください。
相対領域
相対領域は、多重集合に関する上記の概念を拡張したものですが、Wikipediaにはこの主題に関する参照ページがまだありません。ただし、多重領域を定義するために単純な文を使用した上記の最初の例をもう一度見てみると、終域Nをすべての英単語の辞書として使用することで、さらに一歩進めることになります。これは、どの英文にもNとの準同型性があることを意味します。文Aから文Bへの準同型性は、Aのどこかにある各単語を、Bのどこかにある同じ単語に送信します。
ただし、形式的には、 f: (E,π) à (E’,π’) として表されるN上の相対領域のマッピングは、次の三角形が可換となるような関数 f: E àE’です。
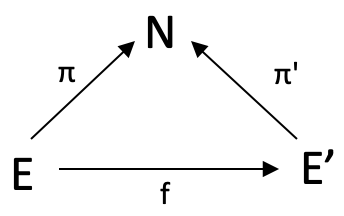
これをトレーダー向けに説明するには、上で使用した平方通勤をD始域のない単純なトリングルに変更することで射fを利用します。fを利用する場合、2つの始域EとE'の間の射の重みを求めます。これは、デモンストレーションの目的では、上記のように、インデックス0とインデックス1の多次元データです。「多次元性」とは、単に複数のデータポイントを測定および記録していることを意味します。私たちの場合、これは高値の変化と安値の変化です。したがって、インデックス1のバーの価格帯の最終的な変化(ラグ)はすでにわかっているため、射fを使用して、最終的な変化がまだ分からない現在のデータポイントを変換し、E'のどの要素がそれを表すかを見つけます。が一致に最も近いです。π'にわたる最も近い一致の終域要素が、予測される変化を示します。
以前と同様にテストを実行すると、次のレポートが得られます。

ご覧のとおり、このレポートは最初のものと同じです。ここでは共有しませんが、私が実行した追加のテストでは若干の改善が見られました。EAは全部同じエントリシグナル(内蔵のAwesome Oscillatorのシグナル)を使用しており、トレーリングストップの実装のみが変更されています。
添字集合
添字集合は、上記の始域Nの要素を取得して、これらの新しい始域のそれぞれが、EとE'の要素。クラス(N)のコレクションを持つ学校を考慮した場合に、これがどうなるかを示す簡単な例です。各クラスには出席する生徒の始域(E)があり、各クラスには始域の椅子(E’)もあります。したがって、始域EおよびE'は、クラスとの関係からN-Indexed始域と呼ばれます。
トレーダーの場合は、11個の値を持っていた始域Nを11個の始域にスケールアップします。各始域は、価格帯の変化のより細かい増分を捕捉します。たとえば、40(40%の変更)で表される要素の代わりに、始域内に9つの新しい変更を加えることができます。
{32.5、35.0、37.5、40.0、42.5、45.0、47.5、50.0}
次に、この始域はEとE'のすべての要素にマップされます。最後の例では、1ラグでの変化と2ラグでの変化をキャプチャする多次元データでした。一歩下がって、トレーダーに対する添字集合のより一般的なアプリケーションを検討してみると、かなりのリストが思いつくでしょう。考えられる用途を5つ紹介します。
移動平均は、市場データの短期的な変動を平準化し、資産価格の傾向を特定するためにトレーダーによって使用される一般的な指標です。この手法には、一定の時間枠にわたる資産の平均価格を算出し、パターンと傾向を明らかにするためにチャート上にプロットすることが含まれます。
添字集合と圏論は、移動平均を別の方法で見る手段を提供します。すでに述べたように、添字集合は、別の始域によってインデックスが付けられた要素のコレクションです。移動平均のコンテキストでは、各期間が始域として考えることができる移動平均期間のバッファを構成するため、添字集合は移動平均を計算するための異なる期間を構成することができます。
EとE'は、それぞれ典型的な価格から計算される移動平均と中央価格から計算される移動平均になります。この記事全体で検討した2つ以外にも、このような始域が存在する可能性があります。たとえば、この場合は終値によるMA、または加重平均価格などです。この部分始域の分類は圏論以外でも研究できると言えば十分でしょう。ただし、圏論がこの研究に貢献しているのは、相対領域関係に焦点を当てていることです。期間21での中央価格MAと周期34での中央価格MAの間など、EとE'(f)の間の射には多くの用途があります。その1つは、移動平均リボンをマッピングすることです。これにより、これらの射の重みの変化を追跡すると、トレンドがどれだけ継続するか、または反転がすぐに起こるかどうかを定量化できます。
価格変動を分類して予測することによるトレーリングポジションへの応用に加えて、トレーダーにとって圏論における多重集合と添字集合の他の応用例をいくつか挙げておくと役立つかもしれません。エントリシグナルの選択に関する限り、いくつかを以下に示します。
- オーダーブック分析:オーダーブックに買い注文と売り注文を多重集合として記録する場合(特定の証券が異なる時間および異なる割り当てで売買される可能性があるため、証券の始域に「繰り返し」があることを意味します)、トレーダーは証券の需要と供給がどこで集中しているかを特定できます。買い多重集合が売り多重集合よりも大きい場合は買いのシグナルである可能性があり、売り多重集合の方が大きい場合は売りのシグナルである可能性があります。
- ポートフォリオ分析:多重集合はトレーダーのポートフォリオを表すことができ、各要素は特定の証券または資産を表します(各証券はオプション契約またはその他のデリバティブ商品によってヘッジされる可能性があるため、複数回出現することを意味するため)。このような多重集合の証券を分析し、そのパフォーマンスに焦点を当てることにより、トレーダーは、パフォーマンスの高い銘柄をより多く割り当て、ポジションを決済したり、パフォーマンスの低い銘柄を売ったりすることを決定する場合があります。
- リスク管理:多重集合は、過去の取引セッションでのパフォーマンスのドローダウンを調べるときに、トレーダーのポートフォリオ全体のリスクの分布を表すことができます(各正規化されたドローダウン範囲は、多重集合の適用につながるさまざまなセッションにわたって複数回表示される可能性があります)。高リスク証券の多重集合が低リスク証券の多重集合よりも大きい場合、これは高リスク証券の一部を売却し、低リスク証券の一部を購入するシグナルである可能性があります。
- 取引戦略:多重集合は取引戦略を表すことができ、各要素は成行注文の発注、指値注文、ストップアウトまたはテイクプロフィットなどの特定の取引決定を表します(このような決定は必ず繰り返されるものであり、決定が行われる順序が重要であるため、多重集合はこの順序情報を取得し、さらなる分析に役立ちます)。成功した取引の多重集合を分析することにより、トレーダーはそれらの取引に対して同様の買い戦略を実装することを決定できます。
- テクニカル指標:多重集合は、調査対象の期間にわたって正規化された値を記録することによって、移動平均やボリンジャーバンドなどのテクニカル指標を表すことができます(各区間の正規化された値は研究区間全体で必ず繰り返されるため、多重集合内でのこれらの繰り返しの順序に注目することで、分析がより完全になります)。特定のテクニカル指標の多重集合の値が特定のしきい値を上回るか下回る場合、これを売買のシグナルとして使用できます。
- 相関関係:多重集合は、異なる証券または資産間の相関関係を表すことができます。相関値は通常、-1.0から+1.0の範囲であり、これらの値が小数点以下1桁に正規化されると、{1.0、0.4、-0.7、0.1、…}などの値が得られます。このような相関関係は、資産全体または同じ資産の時間枠全体で測定できます。この場合も、繰り返しは必ず発生します。証券名をリストする終域との関係を示す多重集合でこれらの繰り返しを調整することにより、分析では各相関値の重要性を見逃すことがなくなります。強気モメンタム証券と高度に相関する証券の多重集合が弱気モメンタム証券よりも大きい場合、これは買いのシグナルとなり、逆の状況は売りのシグナルとなる可能性があります。
- 時系列分析:多重集合は時系列データを表すことができるため、トレーダーは時間の経過に伴う傾向やパターンを分析できます。繰り返しますが、時間の経過とともに、同じトレンドパターンが繰り返されることは間違いありません。そのため、始域内で各パターンを1回リストしただけでは、時系列内で各パターンがどのような順序で続いたかがわかりません。したがって、ここでは多重集合が有効であり、アプリケーションでは、特定の期間の値が平均を上回るか下回る場合、これは売られ過ぎの状況を示しており、これが逆転したり、戦略に応じて追加の要因が考慮されたりした場合に売買のシグナルとなる可能性があります。
- 感情分析:多重集合は市場参加者の感情を示すことができます。参加者の大多数の感情に注目すると、この値が適切に定量化および正規化されていれば(CBOEボラティリティ指数(VIX)など)、分析期間中に必ず同じ値が繰り返されます。多重集合がこれらすべての値を順番に取得し、現在のプラスの感情がマイナスの感情よりも大きい場合、これは、個別の値のみを使用した場合よりも、多重集合内に追加のログ情報が記録されるため、より確実な買いシグナルとなる可能性があります。
- 取引シグナル:複数のデモ口座があり、それぞれがサブスクリプション契約に基づいてシグナルを受信するように設定されている場合、多重集合は取引シグナルを表すことができます。さまざまな出来高での売買の各シグナルのアクションを表にすると必ず反復されます。このような繰り返しを省略した典型的な始域では、各シグナルの決定に付随する取引量などの情報が失われ、これにより、これらのシグナルの相対的なパフォーマンスの分析が歪められる可能性があります。
- 市場データ:多重集合は、特に出来高契約金額が解釈を容易にするために四分位に正規化されている場合、時間枠設定間隔での出来高などの市場データを表すことができます。これらの正規化された金額は、証券が検査されている期間にわたって必ず繰り返されます。多重集合はこの繰り返しに対応するため、このボリューム始域と組み合わせるために選択したどの終域でもより簡潔な分析を行うことが容易になります。
同様に、トレーダーの資金管理に対する添字集合の可能な用途をリストすることも役立つかもしれないので、ここにリストを示します。
- 時価総額の重み付け:添字集合は、ポートフォリオ内のさまざまな株式の時価総額を表すことができます。上の図から、これは始域Nにあり、始域E、E'および残りは特定の時価総額内の株式を表します。関数fは、フォリオ内の株式の相対的なサイズを決定します。
- ファクター投資:添字集合では、価値、勢い、成長など、株式やポートフォリオのパフォーマンスに影響を与えるさまざまな要因を調べることができます。上の図から、正規化されたパフォーマンスベンチマークはNにあり、E、E'、およびその他の領域が要因を表します。射影fは各因子の相対的な重要性を設定します。
- リスクパリティ:ポートフォリオ構築に対するリスクパリティアプローチは、ポートフォリオ全体のリスクとリターンを1つとして捉え、投資を最適に分散するためにリスク加重ベースで投資資本を配分することを目指します。この場合、リスクの重み付けはNになり、個々の資産はE、E'、...を占め、関数fは資産間の相対的な重み付けを定義します。
- スマートベータ:スマートベータは、従来の時価総額ベースの指数に代わる指数構築ルールを使用することで、パッシブ投資のメリットとアクティブ投資戦略のメリットを組み合わせることを目指しています。これは、ルールに基づいた透明性のある方法で市場の非効率性を捉えることに重点を置いています。始域Nは正規化されたパフォーマンスリターンベンチマークを特徴とし、始域EとE'はそれぞれアクティブETFとパッシブETFとなる可能性があります。関数fは、相対的な重み付けをガイドします。
- バリュー・アット・リスク(VaR):バリュー・アット・リスク(VaR)は、取引ポジションの潜在的な損失のリスクを定量化する方法です。この指標は、分散共分散法またはモンテカルロ法のいずれかを使用して履歴的に計算できます。投資銀行は通常、独立したトレーディングデスクが企業を相関性の高い資産に意図せずさらしてしまう可能性があるため、VaRモデリングを全社的なリスクに適用します。最大損失のスケールは始域N、E、E'にあり、株式や債券などのさまざまな種類の資産になります。一方、fは過去の取引実績から得られる相対的なポートフォリオの重み付けになります。
結論
結論として、多重集合、相対集合、添字集合と、価格変動の分類と予測におけるそれらの潜在的な応用について検討してきました。これまでのところ、始域を集合と呼ぶことは避けてきましたが、おそらく次の記事では始域を集合と呼ぶことになるでしょう。なぜなら、始域は他の位相幾何学、複体、およびその他の形式のような「集合のタイプ」を包括する用語であるため、より適切ではあるものの、始域として理解するほうがよいからです。この連載にはそのような応用や例は含まれません。したがって、今後は、この記事と以前の記事で始域と呼んでいたものを参照するために「集合」を使用します。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/12470
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索