
Programmazione di una rete neurale profonda da zero utilizzando il linguaggio MQL

Introduzione
Poiché l'apprendimento automatico ha recentemente guadagnato popolarità, molti hanno sentito parlare di Deep Learning e desiderano sapere come applicarlo nel linguaggio MQL. Ho visto semplici implementazioni di neuroni artificiali con funzioni di attivazione, ma niente che implementa una vera rete neurale profonda. In questo articolo, ti presenterò una rete neurale profonda implementata nel linguaggio MQL con le sue diverse funzioni di attivazione, come la funzione tangente iperbolica per i livelli nascosti e la funzione Softmax per il livello di output. Ci sposteremo dal primo passo fino alla fine per formare completamente la Deep Neural Network.
1. Realizzare un Neurone Artificiale
Si inizia con l'unità di base di una rete neurale: un singolo neurone. In questo articolo, mi concentrerò sulle diverse parti del tipo di neurone che useremo nella nostra Rete Neurale Profonda, sebbene la più grande differenza tra i tipi di neuroni sia solitamente la funzione di attivazione.
1.1. Parti di un Singolo Neurone
Il neurone artificiale, vagamente modellato su un neurone nel cervello umano, ospita semplicemente i calcoli matematici. Come i nostri neuroni, si attiva quando incontra stimoli sufficienti. Il neurone combina l'input dei dati con una serie di coefficienti, o pesi, che amplificano o smorzano quell'input, assegnando così un significato agli input per il compito che l'algoritmo sta cercando di apprendere. Guarda ogni parte del neurone in azione nell'immagine successiva:

1.1.1. Inputs
L'input è un trigger esterno dall'ambiente o proviene da output di altri neuroni artificiali; deve essere valutato dalla rete. Serve come 'cibo' per il neurone e lo attraversa, diventando così un output che possiamo interpretare grazie all'allenamento che abbiamo impartito al neurone. Possono essere valori discreti o numeri con valori reali.
1.1.2. Pesi
I pesi sono fattori che vengono moltiplicati per le voci ad essi corrispondenti, aumentando o diminuendo il loro valore, conferendo un significato maggiore o minore all'input che entra nel neurone e, quindi, all'output che ne esce. L'obiettivo degli algoritmi di addestramento della rete neurale è determinare il 'migliore' insieme possibile di valori di peso per risolvere il problema.
1.1.3. Funzione di Input Netto
In questa parte del neurone, gli input e i pesi convergono in un prodotto a risultato singolo come somma della moltiplicazione di ciascuna voce per il suo peso. Questo risultato o valore viene passato attraverso la funzione di attivazione, che quindi ci fornisce le misure di influenza che il neurone di input ha sull'output della rete neurale.
1.1.4. Funzione di Attivazione
La funzione di attivazione porta all'output. Ci possono essere diversi tipi di funzione di attivazione (Sigmoid, Tan-h, Softmax, ReLU, tra gli altri). Decide se attivare o meno un neurone. Questo articolo è incentrato sui tipi di funzione Tan-h e Softmax.
1.1.5. Output
Infine, abbiamo l'output. Può essere passato a un altro neurone o campionato dall'ambiente esterno. Questo valore può essere discreto o reale, a seconda della funzione di attivazione utilizzata.
2. Costruire la Rete Neurale
La rete neurale si ispira ai metodi di elaborazione delle informazioni dei sistemi nervosi biologici, come il cervello. È composto da strati di neuroni artificiali, ogni strato connesso al successivo. Pertanto, il livello precedente funge da input per il livello successivo e così via per il livello di output. Lo scopo della rete neurale potrebbe essere il raggruppamento attraverso l'apprendimento non supervisionato, la classificazione attraverso l'apprendimento supervisionato o la regressione. In questo articolo ci concentreremo sulla capacità di classificare in tre stati: ACQUISTA, VENDI o TIENI. Di seguito è una rete neurale con un livello nascosto:

3. Scaling da una rete neurale a una rete neurale profonda
Ciò che distingue una Rete Neurale Profonda dalle più comuni reti neurali a singolo strato nascosto è il numero di strati che ne compongono la profondità. Più di tre livelli (inclusi input e output) si qualificano come apprendimento 'profondo'. Profondo, quindi, è un termine tecnico rigorosamente definito che significa più di uno strato nascosto. Più avanzi nella rete neurale, più complesse sono le caratteristiche che possono essere riconosciute dai tuoi neuroni, poiché aggregano e ricombinano le caratteristiche del livello precedente. Rende reti di apprendimento profondo in grado di gestire set di dati molto grandi e ad alta dimensione con miliardi di parametri che passano attraverso funzioni non lineari. Nell'immagine qui sotto, vedi una rete neurale profonda con 3 livelli nascosti:

3.1. Classe di Rete Neurale Profonda
Ora diamo un'occhiata alla classe che useremo per creare la nostra rete neurale. La rete neurale profonda è incapsulata in una classe definita dal programma denominata DeepNeuralNetwork. Il metodo principale istanzia una rete neurale feed-forward 3-4-5-3 completamente connessa. Successivamente, in una sessione di formazione sulla rete neurale profonda in questo articolo, mostrerò alcuni esempi di voci per alimentare la nostra rete, ma per ora ci concentreremo sulla creazione della rete. La rete è hardcoded per due livelli nascosti. Le reti neurali con tre o più livelli sono molto rare, ma se vuoi creare una rete con più livelli puoi farlo facilmente utilizzando la struttura presentata in questo articolo. I pesi dall'input allo strato A sono archiviati nella matrice iaWeights, i pesi dallo strato A allo strato B sono archiviati nella matrice abWeights e i pesi dallo strato B all'output sono archiviati nella matrice boWeights. Poiché un array multidimensionale può essere statico o dinamico solo nella prima dimensione, con tutte le altre dimensioni statiche, la dimensione della matrice viene dichiarata come variabile costante utilizzando l'istruzione '#define'. Ho rimosso tutte le istruzioni using tranne quella che fa riferimento allo spazio dei nomi di sistema di primo livello per risparmiare spazio. Puoi trovare il codice sorgente completo negli allegati dell'articolo.
Struttura del programma:
#define SIZEI 4 #define SIZEA 5 #define SIZEB 3 //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class DeepNeuralNetwork { private: int numInput; int numHiddenA; int numHiddenB; int numOutput; double inputs[]; double iaWeights[][SIZEI]; double abWeights[][SIZEA]; double boWeights[][SIZEB]; double aBiases[]; double bBiases[]; double oBiases[]; double aOutputs[]; double bOutputs[]; double outputs[]; public: DeepNeuralNetwork(int _numInput,int _numHiddenA,int _numHiddenB,int _numOutput) {...} void SetWeights(double &weights[]) {...} void ComputeOutputs(double &xValues[],double &yValues[]) {...} double HyperTanFunction(double x) {...} void Softmax(double &oSums[],double &_softOut[]) {...} }; //+------------------------------------------------------------------+
I due livelli nascosti e il livello di output singolo hanno ciascuno una matrice di valori di bias associati, denominati rispettivamente aBiases, bBiases e oBiases. Gli output locali per i livelli nascosti sono archiviati in array con ambito di classe denominati aOutputs e bOutputs.
3.2. Elaborazione di Output di Reti Neurali Profonde
Il metodo ComputeOutputs inizia configurando uno scratch array per contenere le somme preliminari (prima dell'attivazione). Successivamente, calcola la somma preliminare dei pesi moltiplicata per gli input per i nodi del livello A, aggiunge i valori di bias, quindi applica la funzione di attivazione. Quindi, vengono calcolati gli output locali del livello B, utilizzando gli output del livello A appena calcolati come input locali e, infine, vengono calcolati gli output finali.
void ComputeOutputs(double &xValues[],double &yValues[]) { double aSums[]; // hidden A nodes sums scratch array double bSums[]; // hidden B nodes sums scratch array double oSums[]; // output nodes sums ArrayResize(aSums,numHiddenA); ArrayFill(aSums,0,numHiddenA,0); ArrayResize(bSums,numHiddenB); ArrayFill(bSums,0,numHiddenB,0); ArrayResize(oSums,numOutput); ArrayFill(oSums,0,numOutput,0); int size=ArraySize(xValues); for(int i=0; i<size;++i) // copy x-values to inputs this.inputs[i]=xValues[i]; for(int j=0; j<numHiddenA;++j) // compute sum of (ia) weights * inputs for(int i=0; i<numInput;++i) aSums[j]+=this.inputs[i]*this.iaWeights[i][j]; // note += for(int i=0; i<numHiddenA;++i) // add biases to a sums aSums[i]+=this.aBiases[i]; for(int i=0; i<numHiddenA;++i) // apply activation this.aOutputs[i]=HyperTanFunction(aSums[i]); // hard-coded for(int j=0; j<numHiddenB;++j) // compute sum of (ab) weights * a outputs = local inputs for(int i=0; i<numHiddenA;++i) bSums[j]+=aOutputs[i]*this.abWeights[i][j]; // note += for(int i=0; i<numHiddenB;++i) // add biases to b sums bSums[i]+=this.bBiases[i]; for(int i=0; i<numHiddenB;++i) // apply activation this.bOutputs[i]=HyperTanFunction(bSums[i]); // hard-coded for(int j=0; j<numOutput;++j) // compute sum of (bo) weights * b outputs = local inputs for(int i=0; i<numHiddenB;++i) oSums[j]+=bOutputs[i]*boWeights[i][j]; for(int i=0; i<numOutput;++i) // add biases to input-to-hidden sums oSums[i]+=oBiases[i]; double softOut[]; Softmax(oSums,softOut); // softmax activation does all outputs at once for efficiency ArrayCopy(outputs,softOut); ArrayCopy(yValues,this.outputs); }Dietro le quinte, la rete neurale utilizza la funzione di attivazione della tangente iperbolica (Tan-h) per il calcolo degli output dei due livelli nascosti e la funzione di attivazione di Softmax per il calcolo dei valori di output finali.
- Tangente iperbolica(Tan-h): come il Sigmoide logistico, anche la funzione Tan-h è sigmoidale, ma genera invece valori che variano (-1, 1). Pertanto, gli input fortemente negativi per il Tan-h verranno mappati sugli output negativi. Inoltre, solo gli input con valore zero vengono mappati su output prossimi allo zero. In questo caso, mostrerò la formula matematica ma anche la sua implementazione nel codice sorgente MQL.
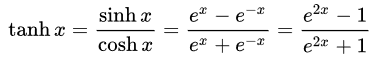
double HyperTanFunction(double x) { if(x<-20.0) return -1.0; // approximation is correct to 30 decimals else if(x > 20.0) return 1.0; else return MathTanh(x); //Use explicit formula for MQL4 (1-exp(-2*x))/(1+exp(-2*x)) }
- Softmax: assegna probabilità decimali a ciascuna classe in caso di classi multiple. Tali probabilità decimali devono aggiungere 1.0. Questa restrizione aggiuntiva consente all'allenamento di convergere più velocemente.

void Softmax(double &oSums[],double &_softOut[]) { // determine max output sum // does all output nodes at once so scale doesn't have to be re-computed each time int size=ArraySize(oSums); double max= oSums[0]; for(int i = 0; i<size;++i) if(oSums[i]>max) max=oSums[i]; // determine scaling factor -- sum of exp(each val - max) double scale=0.0; for(int i= 0; i<size;++i) scale+= MathExp(oSums[i]-max); ArrayResize(_softOut,size); for(int i=0; i<size;++i) _softOut[i]=MathExp(oSums[i]-max)/scale; }
4. Demo Expert Advisor che utilizza la classe Rete Neurale Profonda
Prima di iniziare a sviluppare l'Expert Advisor dobbiamo definire i dati che verranno alimentati alla nostra Rete Neurale Profonda. Poiché una rete neurale è in grado di classificare i modelli, utilizzeremo i valori relativi di una candela giapponese come input. Questi valori sarebbero la dimensione dell'ombra superiore, del corpo, dell'ombra inferiore e la direzione della candela (rialzista o ribassista). Il numero di iscrizioni non deve essere necessariamente piccolo ma in questo caso sarà sufficiente come programma di prova.
Il Demo Expert Advisor:
Una struttura di rete neurale 4-4-5-3 richiede un totale di (4 * 4) + 4 + (4 * 5) + 5 + (5 * 3) + 3 = 63 pesi e valori di bias.
#include <DeepNeuralNetwork.mqh> int numInput=4; int numHiddenA = 4; int numHiddenB = 5; int numOutput=3; DeepNeuralNetwork dnn(numInput,numHiddenA,numHiddenB,numOutput); //--- weight & bias values input double w0=1.0; input double w1=1.0; input double w2=1.0; input double w3=1.0; input double w4=1.0; input double w5=1.0; input double w6=1.0; input double w7=1.0; input double w8=1.0; input double w9=1.0; input double w10=1.0; input double w11=1.0; input double w12=1.0; input double w13=1.0; input double w14=1.0; input double w15=1.0; input double b0=1.0; input double b1=1.0; input double b2=1.0; input double b3=1.0; input double w40=1.0; input double w41=1.0; input double w42=1.0; input double w43=1.0; input double w44=1.0; input double w45=1.0; input double w46=1.0; input double w47=1.0; input double w48=1.0; input double w49=1.0; input double w50=1.0; input double w51=1.0; input double w52=1.0; input double w53=1.0; input double w54=1.0; input double w55=1.0; input double w56=1.0; input double w57=1.0; input double w58=1.0; input double w59=1.0; input double b4=1.0; input double b5=1.0; input double b6=1.0; input double b7=1.0; input double b8=1.0; input double w60=1.0; input double w61=1.0; input double w62=1.0; input double w63=1.0; input double w64=1.0; input double w65=1.0; input double w66=1.0; input double w67=1.0; input double w68=1.0; input double w69=1.0; input double w70=1.0; input double w71=1.0; input double w72=1.0; input double w73=1.0; input double w74=1.0; input double b9=1.0; input double b10=1.0; input double b11=1.0;
Per gli input per la nostra rete neurale utilizzeremo la seguente formula per determinare quale percentuale rappresenta ciascuna parte della candela, rispettando il totale della sua dimensione.

//+------------------------------------------------------------------+ //|percentage of each part of the candle respecting total size | //+------------------------------------------------------------------+ int CandlePatterns(double high,double low,double open,double close,double uod,double &xInputs[]) { double p100=high-low;//Total candle size double highPer=0; double lowPer=0; double bodyPer=0; double trend=0; if(uod>0) { highPer=high-close; lowPer=open-low; bodyPer=close-open; trend=1; } else { highPer=high-open; lowPer=close-low; bodyPer=open-close; trend=0; } if(p100==0)return(-1); xInputs[0]=highPer/p100; xInputs[1]=lowPer/p100; xInputs[2]=bodyPer/p100; xInputs[3]=trend; return(1); }
Now we can process the inputs through our neural network:
MqlRates rates[]; ArraySetAsSeries(rates,true); int copied=CopyRates(_Symbol,0,1,5,rates); //Compute the percent of the upper shadow, lower shadow and body in base of sum 100% int error=CandlePatterns(rates[0].high,rates[0].low,rates[0].open,rates[0].close,rates[0].close-rates[0].open,_xValues); if(error<0)return; dnn.SetWeights(weight); double yValues[]; dnn.ComputeOutputs(_xValues,yValues);
Ora l'opportunità di trading viene elaborata in base al calcolo della rete neurale. Ricorda, la funzione Softmax produrrà 3 uscite basate sulla somma del 100%. I valori vengono memorizzati nell'array 'yValues' e verrà eseguito il valore con un numero superiore al 60%.
//--- if the output value of the neuron is mare than 60% if(yValues[0]>0.6) { if(m_Position.Select(my_symbol))//check if there is an open position { if(m_Position.PositionType()==POSITION_TYPE_SELL) m_Trade.PositionClose(my_symbol);//Close the opposite position if exists if(m_Position.PositionType()==POSITION_TYPE_BUY) return; } m_Trade.Buy(lot_size,my_symbol);//open a Long position } //--- if the output value of the neuron is mare than 60% if(yValues[1]>0.6) { if(m_Position.Select(my_symbol))//check if there is an open position { if(m_Position.PositionType()==POSITION_TYPE_BUY) m_Trade.PositionClose(my_symbol);//Close the opposite position if exists if(m_Position.PositionType()==POSITION_TYPE_SELL) return; } m_Trade.Sell(lot_size,my_symbol);//open a Short position } if(yValues[2]>0.6) { m_Trade.PositionClose(my_symbol);//close any position }
5. Addestrare la Rete Neurale Profonda utilizzando l'ottimizzazione della strategia
Come avrai notato, è stato implementato solo il meccanismo di feed-forward della rete neurale profonda e non esegue alcun addestramento. Questa attività è riservata al tester della strategia. Di seguito, ti mostro come addestrare la rete neurale. Tieni presente che a causa dell'elevato numero di input e della gamma di parametri di addestramento, può essere addestrato solo in MetaTrader 5, ma una volta ottenuti i valori dell'ottimizzazione, può essere facilmente copiato in MetaTrader 4.
La configurazione del Tester di strategia:
I pesi e la distorsione possono utilizzare un intervallo di numeri per l'addestramento, da -1 a 1 e uno step di 0,1, 0,01 o 0,001. Puoi provare questi valori e vedere quale ottiene il miglior risultato. Nel mio caso, ho usato 0.001 per il passaggio come mostrato nell'immagine qui sotto:
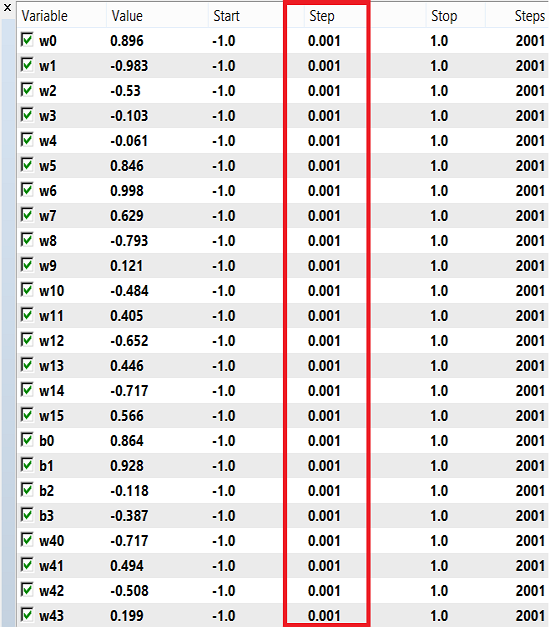
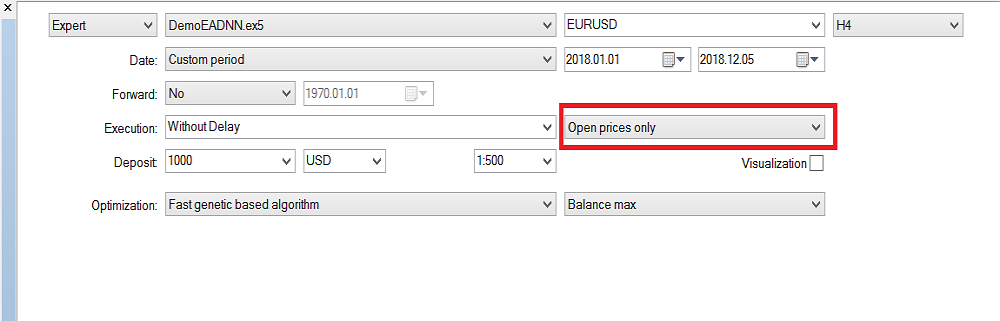
Tieni presente che ho utilizzato 'Solo prezzi d'apertura' perché sto utilizzando l'ultima candela chiusa, quindi non vale la pena eseguirla su ogni tick. Ora ho eseguito l'ottimizzazione sull'intervallo di tempo H4 e nell'ultimo anno ho ottenuto questo risultato sul backtest:

Conclusione
Il codice e la spiegazione presentati in questo articolo dovrebbero fornire una buona base per comprendere le reti neurali con due livelli nascosti. Che ne dici di tre o più livelli nascosti? Il consenso nella letteratura di ricerca è che due strati nascosti sono sufficienti per quasi tutti i problemi pratici. Questo articolo delinea un approccio per lo sviluppo di modelli migliorati per la previsione del tasso di cambio utilizzando Reti Neurali Profonde, motivato dalla capacità delle reti profonde di apprendere caratteristiche astratte dai dati grezzi. I risultati preliminari confermano che la nostra rete profonda produce un'accuratezza predittiva significativamente maggiore rispetto ai modelli di base per i mercati valutari sviluppati.
Tradotto dall’inglese da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/en/articles/5486
 Programmatore Migliore (Parte 07): Note su come diventare uno sviluppatore freelance di successo
Programmatore Migliore (Parte 07): Note su come diventare uno sviluppatore freelance di successo
 Programmatore Migliore (Parte 06): 9 abitudini che portano a una codifica efficace
Programmatore Migliore (Parte 06): 9 abitudini che portano a una codifica efficace
 Scopri perché e come progettare il tuo sistema di trading algoritmico
Scopri perché e come progettare il tuo sistema di trading algoritmico
 Programmatore migliore (Parte 05): Come diventare uno sviluppatore più veloce
Programmatore migliore (Parte 05): Come diventare uno sviluppatore più veloce
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
ci stavo lavorando da un po' di tempo
Non so cosa c'è di sbagliato nel mio codice dato che non sono un esperto sono solo uno studente di informatica che studia in un college comunitario
Vorrei fare il tuo EA in un indicatore personalizzato che fa solo l'etichetta dell'oggetto
(Compra [+1], Vendi[-1], ignora[0] inoltre signore cambio tassi[0].high in tassi[1].high) ma non importa come leggo la documentazione non mostra l'output finale
Aggiornate la seguente funzione per restituire `bool` invece di `void` e vedrete che è stato dato un cattivo numero di pesi.
Nota che devi anche aggiornare i pesi in cima al file (non è sufficiente aggiornarli solo quando inizializzi la rete :P
È una NN hard-coded, non ti consiglio di aumentare il numero di neuroni perché non sarai in grado di allenarla in seguito...
Grazie per i codici che avete condiviso. Come nuovo codificatore, ho alcune domande da porre, spero di poter ottenere aiuto dalla vostra esperienza ragazzi. Grazie in anticipo.
1.Quando compilo il file " DeepNeuralNetwork.mqh", non riesco a capire perché succede. Si prega di vedere lo screenshot qui sotto.
2. In DemoEADNN.mq5, dove sono questi due file? Vedere lo screenshot qui sotto.
Grazie.
1. Quando compilo il file "DeepNeuralNetwork.mqh", ho alcuni errori e non riesco a risolverli.
2. In DemoEADNN.mq5, non ho potuto trovare questi due file, vedere lo screenshot qui sotto.
Grazie.
Un articolo molto utile
Grazie mille