De la théorie à la pratique - page 622
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Kolmogorov est un homme plus intelligent que la plupart de ceux qui regardent fixement l'écran. Et ses exigences en matière de prévision BP sont simples : espérance = constante et ACF périodique.
Maintenant, voici ce qu'il faut dire.
Je regarde les distributions incrémentales et la façon dont elles changent leurs moments statistiques en fonction des intervalles de lecture des cotations, et je réalise que les prix du marché n'ont PAS la propriété d'autosimilarité. Cette propriété est propre aux processus dont la distribution des incréments est stable et infiniment divisible (par exemple, normale), comme le mouvement brownien. Ce n'est pas le cas sur le marché.
De toute évidence, Mandelbrot et ses collègues, qui n'ont aucune connaissance de la physique (et pire encore, ils en ont une, mais la cachent soigneusement), ont intentionnellement trompé les personnes désespérées, afin qu'elles se lancent dans le scalping sur des données en tic-tac et de petites échéances, et se remplissent les poches en perdant leurs dépôts.
Eh bien, voilà !
Recherche sur
http://tpq.io/p/rough_volatility_with_python.html
même https://hal.inria.fr/hal-01350915/documentMaintenant, voici ce qu'il faut dire.
Lorsque j'examine les distributions incrémentales et la manière dont elles modifient leurs moments statistiques en fonction des intervalles de lecture des cotations, je me rends compte que les prix du marché n'ont PAS la propriété d'autosimilarité. Cette propriété est propre aux processus dont la distribution des incréments est stable et infiniment divisible (par exemple, normale), comme le mouvement brownien. Ce n'est pas le cas sur le marché.
De toute évidence, Mandelbrot et ses collègues, qui n'ont aucune connaissance de la physique (et pire encore, ils en ont une, mais la cachent soigneusement), ont intentionnellement trompé les personnes désespérées, afin qu'elles se lancent dans le scalping sur des données en ticks et de petites échéances, et se remplissent les poches en perdant leurs dépôts.
C'est ça !
Vous avez déjà introduit des théories de conspiration dans le mélange... un autre tas de conneries.
Lire le sujet :
http://inis.jinr.ru/sl/vol2/Physics/Динамические%20системы%20и%20Хаос/Федер%20Е.,%20Фракталы,%201991.pdf
Juste pour que ce que je vise soit clair.
Je viens de commencer à travailler dans le flux d'ordres 60 d'Erlang (lecture des cotations en tick, en moyenne, une fois par minute).
Nous avons l'histogramme suivant pour les incréments de la paire EURJPY, par exemple :
Statistiques :
Il s'agit pratiquement d'une distribution de Laplace.
La somme des incréments (~prix) et les modules des incréments (~dispersion) ont une distribution normale pour un volume d'échantillon assez important (un jour - pour M1 ou une semaine - pour M5) d'un tel PS.
L'objectif est donc de parvenir à une distribution de Laplace pure, et nous aurons alors vraiment un analogue direct du processus d'Ornstein-Uhlenbeck avec un retour à la moyenne.
J'aimerais également deviner quelles sections de l'histoire il utilise pour construire ses graphiques, il y a des sections de tendance pendant plusieurs mois, et il y a des sections de tendance latérale.
De même que le principe du "saut" de M1 à M5 n'est pas clair, il a besoin de cohérence ou au moins d'une justification. Il y serait d'une valeur inestimable avec de tels talents, ils réussissent également à ajouter des mois, puis des trimestres, puis des saisons = la sortie des bonnes données statistiques.
)))
Juste pour que ce que je vise soit clair.
Je viens de commencer à travailler dans le flux d'ordres 60 d'Erlang (lecture des cotations en tick, en moyenne, une fois par minute).
Nous avons l'histogramme suivant pour les incréments de la paire EURJPY, par exemple :
Statistiques :
Il s'agit pratiquement d'une distribution de Laplace.
La somme des incréments (~prix) et les modules des incréments (~dispersion) ont une distribution normale pour un volume d'échantillon assez important (un jour - pour M1 ou une semaine - pour M5) d'un tel PS.
L'objectif est donc de parvenir à une distribution de Laplace pure, et nous aurons alors vraiment un analogue direct du processus d'Ornstein-Uhlenbeck avec un retour à la moyenne.
En général, je vois que le kurtosis est réduit, les queues sont récupérées ---> de Laplace à normal, de normal à uniforme. Alors qu'est-ce qu'il y a au début ? Pas Laplace ? Parce qu'il est facilement décrit par un exposant, si vous prenez un côté.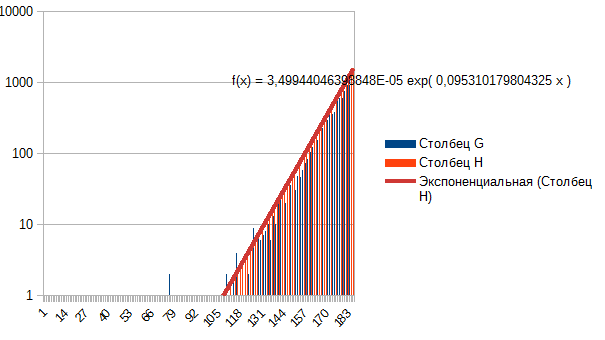 C'est la fenêtre minute-mois de l'EURUSD.
C'est la fenêtre minute-mois de l'EURUSD.