Artículos sobre automatización de sistemas comerciales en el lenguaje MQL5
Lea los artículos sobre los sistemas de trading basados en las ideas muy variadas. Usted sabrá cómo usar los métodos estadísticos y los patrones en los gráficos de velas japonesas, cómo filtrar las señales y para qué sirven los indicadores semafóricos.
A través del Asistente MQL5 Usted aprenderá a crear los robots sin acudir a la programación para evaluar rápidamente las ideas comerciales, así como sabrá qué es lo que representan los algoritmos genéticos.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Trabajando con los precios en la biblioteca DoEasy (Parte 64): Profundidad del mercado, clases del objeto de instantánea y del objeto de serie de instantáneas del DOM
En este artículo, vamos a crear dos clases: la clase del objeto de instantánea del DOM y la clase del objeto de serie de instantáneas del DOM, además, simularemos la creación de la serie de datos del DOM.
Redes neuronales en el trading: Modelo de doble atención para la previsión de tendencias
Continuamos la conversación sobre el uso de la representación lineal por partes de las series temporales iniciada en el artículo anterior. Y hoy hablaremos de la combinación de este método con otros enfoques del análisis de series temporales para mejorar la calidad de la previsión de la tendencia del movimiento de precios.

Desarrollo de un sistema de repetición (Parte 28): Proyecto Expert Advisor — Clase C_Mouse (I)
Cuando los primeros sistemas capaces de factorizar algo comenzaron a ser producidos, todo requería la intervención de ingenieros con un amplio conocimiento sobre lo que se estaba diseñando. Estamos hablando de los albores de la computación, una época en la que ni siquiera existían terminales que permitieran la programación de algo. A medida que el desarrollo avanzaba y crecía el interés para que más personas pudieran crear algo, surgían nuevas ideas y métodos para programar esas máquinas, que antes dependían de la modificación de la posición de los conectores. Fue entonces cuando aparecieron los primeros terminales.

Experimentos con redes neuronales (Parte 4): Patrones
Las redes neuronales lo son todo. Vamos a comprobar en la práctica si esto es así. MetaTrader 5 como herramienta autosuficiente para el uso de redes neuronales en el trading. Una explicación sencilla.
Visualización de transacciones en un gráfico (Parte 1): Seleccionar un periodo para el análisis
Aquí vamos a desarrollar un script desde cero que simplifica la descarga de pantallas de impresión de transacciones para analizar entradas comerciales. Toda la información necesaria sobre una única operación se puede mostrar cómodamente en un gráfico con la posibilidad de dibujar diferentes marcos temporales.

Redes neuronales: así de sencillo (Parte 23): Creamos una herramienta para el Transfer Learning
En esta serie de artículos, hemos mencionado el Aprendizaje por Transferencia más de una vez, pero hasta ahora no había sido más que una mención. Le propongo rellenar este vacío y analizar más de cerca el Aprendizaje por Transferencia.
Trabajando con los precios en la biblioteca DoEasy (Parte 62): Actualización de las series de tick en tiempo real, preparando para trabajar con la Profundidad del mercado
En este artículo, vamos a desarrollar la actualización de la colección de datos de tick en tiempo real, y prepararemos una clase del objeto de símbolo para manejar la Profundidad del mercado, con la que empezaremos a trabajar a partir del siguiente artículo.
Características del Wizard MQL5 que debe conocer (Parte 5): Cadenas de Markov
Las cadenas de Markov son una poderosa herramienta matemática que se puede usar para modelar y predecir los datos de las series temporales en varios campos, incluido el financiero. En el modelado y la previsión de series temporales financieras, las cadenas de Markov se usan a menudo para modelar la evolución de los activos financieros a lo largo del tiempo, como los precios de las acciones o los tipos de cambio. Una de las principales ventajas de los modelos de cadenas de Markov es su simplicidad y sencillez de uso.

Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 3): Prefijos/sufijos de símbolos y sesión comercial
Últimamente, he recibido comentarios de varios compañeros tráders sobre cómo usar el asesor multidivisa que estamos analizando con brókeres que utilizan prefijos y/o sufijos con nombres de símbolos, así como sobre la forma de implementar zonas horarias comerciales o sesiones comerciales en el asesor.

Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 6): Dos indicadores RSI se cruzan entre sí
Por asesor multidivisa en este artículo nos referimos a un asesor o robot comercial que utiliza dos indicadores RSI con líneas de intersección: un RSI rápido que se cruza con uno lento.
Creación de un modelo de restricción de tendencia de velas (Parte 7): Perfeccionamos nuestro modelo de desarrollo de la EA
En este artículo, profundizaremos en la preparación detallada de nuestro indicador para el desarrollo del Asesor Experto (EA). Nuestro debate abarcará mejoras adicionales en la versión actual del indicador para mejorar su precisión y funcionalidad. Además, introduciremos nuevas características que marcan puntos de salida, abordando una limitación de la versión anterior, que solo identificaba puntos de entrada.

Redes neuronales: así de sencillo (Parte 43): Dominando las habilidades sin función de recompensa
El problema del aprendizaje por refuerzo reside en la necesidad de definir una función de recompensa, que puede ser compleja o difícil de formalizar. Para resolver esto, se están estudiando enfoques basados en la variedad de acciones y la exploración del entorno que permiten aprender habilidades sin una función de recompensa explícita.

Redes neuronales: así de sencillo (Parte 62): Uso del transformador de decisiones en modelos jerárquicos
En artículos recientes, hemos visto varios usos del método Decision Transformer, que permite analizar no solo el estado actual, sino también la trayectoria de los estados anteriores y las acciones realizadas en ellos. En este artículo, veremos una variante del uso de este método en modelos jerárquicos.
Asesor Experto Grid-Hedge Modificado en MQL5 (Parte III): Optimización de una estrategia de cobertura simple (I)
En la tercera parte, volveremos a los Asesores Expertos Simple Hedge y Simple Grid que hemos desarrollado anteriormente. En esta ocasión, mejoraremos el Simple Hedge Expert Advisor usando el análisis matemático y el enfoque de fuerza bruta para utilizar de manera óptima la estrategia. Este artículo profundizará en la optimización matemática de estrategias, sentando las bases para futuras investigaciones sobre la optimización basada en códigos de partes posteriores.

Redes neuronales: así de sencillo (Parte 36): Modelos relacionales de aprendizaje por refuerzo (Relational Reinforcement Learning)
En los modelos de aprendizaje por refuerzo analizados anteriormente, usamos varias opciones de redes convolucionales que pueden identificar varios objetos en los datos originales. La principal ventaja de las redes convolucionales es su capacidad de identificar objetos independientemente de la ubicación de estos. Al mismo tiempo, las redes convolucionales no siempre son capaces de hacer frente a diversas deformaciones de los objetos y al ruido. Pero estos problemas pueden resolverse usando el modelo relacional.

Escribimos el primer modelo de caja de cristal (Glass Box) en Python y MQL5
Los modelos de aprendizaje automático son difíciles de interpretar, y entender por qué los modelos no se ajustan a nuestras expectativas puede ayudarnos mucho a conseguir, en última instancia, el resultado deseado al utilizar técnicas tan avanzadas. Sin un conocimiento exhaustivo del funcionamiento interno del modelo, podría resultar difícil encontrar fallos que degraden el rendimiento. De este modo, podremos dedicar tiempo a crear funciones que no afecten a la calidad de la previsión. La conclusión es que, por muy bueno que sea un modelo, nos perderemos todas sus grandes ventajas por culpa de nuestros propios errores. Afortunadamente, existe una solución sofisticada y bien diseñada que permite ver con claridad lo que sucede bajo el capó del modelo.

Validación cruzada simétrica combinatoria en MQL5
El artículo muestra la implementación de la validación cruzada simétrica combinatoria en MQL5 puro para medir el grado de ajuste tras optimizar la estrategia usando el algoritmo completo lento del simulador de estrategias.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 19): Ajustes necesarios
Lo que vamos a hacer aquí es preparar el terreno para que, cuando sea necesario agregar nuevas funciones al código, esto se haga de manera fluida y sencilla. El código actual aún no puede cubrir o manejar algunas cosas que serán necesarias para un progreso significativo. Necesitamos que todo se construya de manera que el esfuerzo de implementar algunas cosas sea lo más mínimo posible. Si esto se hace adecuadamente, tendremos la posibilidad de tener un sistema realmente muy versátil. Capaz de adaptarse muy fácilmente a cualquier situación que deba ser cubierta.

Previsión y apertura de órdenes basadas en aprendizaje profundo (Deep Learning) con el paquete Python MetaTrader 5 y el archivo modelo ONNX
El proyecto consiste en utilizar Python para realizar previsiones basadas en el aprendizaje profundo en los mercados financieros. Exploraremos los entresijos de la comprobación del rendimiento del modelo utilizando métricas clave como el error medio absoluto (MAE, Mean Absolute Error), el error medio cuadrático (MSE, Mean Squared Error) y R-cuadrado (R2), y aprenderemos a envolverlo todo en un ejecutable. También haremos un fichero modelo ONNX con su EA.

Análisis de sentimientos y aprendizaje profundo para operar con EA y backtesting con Python
En este artículo, presentaremos un análisis de sentimiento y los modelos ONNX con Python para ser utilizados en un asesor experto. Un script ejecuta un modelo ONNX entrenado a partir de TensorFlow para predicciones de aprendizaje profundo, mientras que otro obtiene titulares de noticias y cuantifica el sentimiento utilizando IA.

Cómo construir y optimizar un sistema de trading basado en la volatilidad (Chaikin Volatility - CHV)
En este artículo, proporcionaremos otro indicador basado en la volatilidad llamado Chaikin Volatility. Entenderemos cómo construir un indicador personalizado después de identificar cómo se puede utilizar y construir. Compartiremos algunas estrategias sencillas que se pueden utilizar y luego las pondremos a prueba para entender cuál puede ser mejor.
Perceptrón multicapa y algoritmo de retropropagación (Parte 3): Integración con el simulador de estrategias - Visión general (I)
El perceptrón multicapa es una evolución del perceptrón simple, capaz de resolver problemas separables no linealmente. Junto con el algoritmo de retropropagación, es posible entrenar eficientemente esta red neuronal. En la tercera parte de la serie sobre el perceptrón multicapa y la retropropagación, mostraremos cómo integrar esta técnica con el simulador de estrategias. Esta integración permitirá utilizar análisis de datos complejos y tomar mejores decisiones para optimizar las estrategias de negociación. En este resumen, analizaremos las ventajas y los retos de la aplicación de esta técnica.

Redes neuronales: así de sencillo (Parte 44): Estudiamos las habilidades de forma dinámica
En el artículo anterior, nos familiarizamos con el método DIAYN, que ofrece un algoritmo para el aprendizaje de diversas habilidades. El uso de las habilidades aprendidas puede aprovecharse en diversas tareas, pero estas habilidades pueden resultar bastante impredecibles, lo cual puede dificultar su uso. En este artículo, analizaremos un algoritmo para el aprendizaje de habilidades predecibles.

Creación de un modelo de restricción de tendencia de velas (Parte 8): Desarrollo de un asesor experto (II)
Piense en un asesor experto independiente. Anteriormente, analizamos un Asesor Experto basado en indicadores que también se asoció con un script independiente para dibujar la geometría de riesgo y recompensa. Hoy discutiremos la arquitectura de un Asesor Experto MQL5, que integra todas las características en un solo programa.
Desarrollo de un sistema de repetición (Parte 41): Inicio de la segunda fase (II)
Si hasta ahora todo te ha parecido correcto, significa que no estás pensando realmente a largo plazo. Donde empiezas a desarrollar aplicaciones y, con el tiempo, ya no necesitas programar nuevas aplicaciones. Solo tienes que conseguir que trabajen juntos. Veamos cómo terminar de montar el indicador del ratón.

Redes neuronales: así de sencillo (Parte 50): Soft Actor-Critic (optimización de modelos)
En el artículo anterior, implementamos el algoritmo Soft Actor-Critic (SAC), pero no pudimos entrenar un modelo rentable. En esta ocasión, optimizaremos el modelo creado previamente para obtener los resultados deseados en su rendimiento.

Redes neuronales: así de sencillo (Parte 89): Transformador de descomposición de la frecuencia de señal (FEDformer)
Todos los modelos de los que hemos hablado anteriormente analizan el estado del entorno como una secuencia temporal. Sin embargo, las propias series temporales también pueden representarse como características de frecuencia. En este artículo, presentaremos un algoritmo que utiliza las características de frecuencia de una secuencia temporal para predecir los estados futuros.

Desarrollo de un sistema de repetición (Parte 59): Un nuevo futuro
La correcta comprensión de las cosas nos permite hacer más con menos esfuerzo. En este artículo, explicaré por qué es necesario ajustar la aplicación de la plantilla antes de que el servicio comience a interactuar realmente con el gráfico. Además, ¿qué tal si mejoramos el indicador del mouse para que podamos hacer más cosas con él?
Creación de un panel de indicadores de fuerza relativa (RSI) dinámico, multisímbolo y multiperíodo en MQL5
En este artículo, desarrollamos un panel dinámico de indicadores RSI multisímbolo y multiperiodo en MQL5, que proporciona a los operadores valores RSI en tiempo real a través de varios símbolos y marcos temporales. El panel cuenta con botones interactivos, actualizaciones en tiempo real e indicadores codificados por colores para ayudar a los operadores a tomar decisiones informadas.

Multibot en MetaTrader (Parte II): Plantilla dinámica mejorada
Desarrollando el tema del artículo anterior sobre el multibot, hemos decidido crear una plantilla más flexible y funcional, que tenga grandes posibilidades, y que se pueda utilizar eficazmente en freelance, además de como base para desarrollar asesores de divisa y periodo múltiple con posibilidad de integración con soluciones externas.

Aprendiendo a diseñar un sistema de trading con el oscilador Chaikin
Aquí tenemos un nuevo artículo de nuestra serie destinada al estudio de indicadores técnicos populares y la creación de sistemas comerciales basados en ellos. En este artículo, trabajaremos con el indicador Chaikin Oscillator, el oscilador de Chaikin.
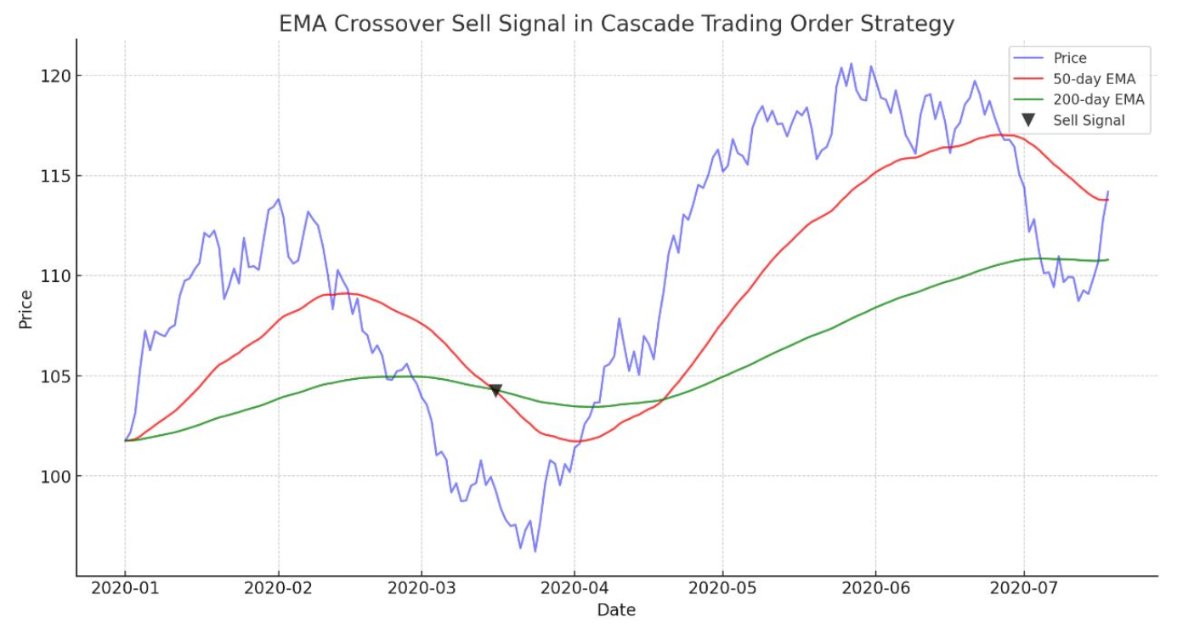
Estrategia de negociación de órdenes en cascada basada en cruces de EMA para MetaTrader 5
El artículo guía en la demostración de un algoritmo automatizado basado en cruces de EMA para MetaTrader 5. Información detallada sobre todos los aspectos de la demostración de un Asesor Experto en MQL5 y su prueba en MetaTrader 5, desde el análisis del comportamiento del rango de precios hasta la gestión de riesgos.

Redes neuronales: así de sencillo (Parte 54): Usamos un codificador aleatorio para una exploración eficiente (RE3)
Siempre que analizamos métodos de aprendizaje por refuerzo, nos enfrentamos al problema de explorar eficientemente el entorno. Con frecuencia, la resolución de este problema hace que el algoritmo se complique, llevándonos al entrenamiento de modelos adicionales. En este artículo veremos un enfoque alternativo para resolver el presente problema.
Trabajando con las series temporales en la biblioteca DoEasy (Parte 53): Clase del indicador abstracto básico
En este artículo, vamos a analizar la creación de la clase del indicador abstracto que a continuación va a usarse como una clase básica para crear objetos de los indicadores estándar y personalizados de la biblioteca.

Desarrollo de un robot de trading en Python (Parte 3): Implementamos un algoritmo comercial basado en el modelo
Hoy vamos a continuar con la serie de artículos sobre la creación de un robot comercial en Python y MQL5. En esta ocasión, resolveremos el problema relacionado con la creación de un algoritmo comercial en Python.

Añadimos un LLM personalizado a un robot comercial (Parte 2): Ejemplo de despliegue del entorno
Los modelos lingüísticos (LLM) son una parte importante de la inteligencia artificial que evoluciona rápidamente, por lo que debemos plantearnos cómo integrar unos LLM potentes en nuestro comercio algorítmico. A la mayoría de la gente le resulta difícil adaptar estos modelos a sus necesidades, implantarlos de forma local y luego aplicarlos al trading algorítmico. En esta serie de artículos abordaremos un enfoque paso a paso para lograr este objetivo.

Creación de un modelo de restricción de tendencia de velas (Parte 2): Fusionar indicadores nativos
Este artículo se centra en el aprovechamiento de los indicadores MetaTrader 5 incorporados para filtrar las señales fuera de tendencia. Avanzando desde el artículo anterior exploraremos cómo hacerlo utilizando código MQL5 para comunicar nuestra idea al programa final.

Experimentos con redes neuronales (Parte 5): Normalización de parámetros de entrada para su transmisión a una red neuronal
Las redes neuronales lo son todo. Vamos a comprobar en la práctica si esto es así. MetaTrader 5 como herramienta autosuficiente para el uso de redes neuronales en el trading. Una explicación sencilla.

Redes neuronales en el trading: Modelos del espacio de estados
Una gran cantidad de los modelos que hemos revisado hasta ahora se basan en la arquitectura del Transformer. No obstante, pueden resultar ineficientes al trabajar con secuencias largas. En este artículo le propongo familiarizarse con una rama alternativa de pronóstico de series temporales basada en modelos del espacio de estados.

Redes neuronales: así de sencillo (Parte 52): Exploración con optimismo y corrección de la distribución
A medida que el modelo se entrena con el búfer de reproducción de experiencias, la política actual del Actor se aleja cada vez más de los ejemplos almacenados, lo cual reduce la eficacia del entrenamiento del modelo en general. En este artículo, analizaremos un algoritmo para mejorar la eficiencia del uso de las muestras en los algoritmos de aprendizaje por refuerzo.