
Redes neuronales: así de sencillo (Parte 44): Estudiamos las habilidades de forma dinámica

Introducción
Cuando se resuelven problemas de predicción en un entorno estocástico complejo, resulta bastante difícil, y a menudo imposible, entrenar un único modelo que muestre un rendimiento aceptable fuera de la muestra de entrenamiento. Al mismo tiempo, dividir la tarea en subtareas más pequeñas mejora significativamente el rendimiento del modelo añadido. En artículos anteriores ya hemos aprendido a construir modelos jerárquicos. Su arquitectura permite dividir la solución de un problema en varias subtareas, y cada subtarea es resuelta por un modelo separado más simple. Y aquí surge la cuestión sobre el correcto entrenamiento de habilidades que puedan ser identificadas fácilmente por el comportamiento del modelo en un estado concreto.
En el artículo anterior, nos familiarizamos con el método DIAYN para entrenar habilidades separables, lo cual nos permite construir un modelo capaz de cambiar el comportamiento del agente según el estado actual. Recordemos que el algoritmo DIAYN recompensa el comportamiento imprevisible, y esto le permite enseñar habilidades con la mayor variedad posible de comportamientos. Sin embargo, debemos considerar la otra cara de la moneda: dichas habilidades se vuelven poco predecibles, y esto complica el proceso de planificación y gestión del agente.
Entonces, dentro de este paradigma, surge la cuestión sobre el entrenamiento de habilidades cuyo comportamiento sería fácilmente predecible. Pero, en este caso, no estamos dispuestos a sacrificar la diversidad de su comportamiento. Los autores del método Dynamics-Aware Discovery of Skills (DADS), presentado al mundo en 2020, se enfrentan a un reto similar. A diferencia de DIAYN, el método DADS busca enseñar habilidades que no solo muestren variedad de comportamiento, sino que también sean predecibles.
1. Panorámica de la arquitectura y pasos básicos del método DADS
El estudio de múltiples comportamientos individuales y de los cambios de entorno correspondientes nos permite usar el control predictivo por modelos para planificar en el espacio del comportamiento en lugar del espacio de la acción. En este contexto, la pregunta clave sería cómo podemos obtener estos comportamientos, dado que pueden ser aleatorios e impredecibles. El método Dynamics-Aware Discovery of Skills (DADS) propone un sistema de aprendizaje por refuerzo no supervisado para entrenar habilidades de bajo nivel con el objetivo explícito de facilitar la gestión basada en modelos.
Las destrezas aprendidas mediante DADS se optimizan directamente para la predictibilidad, lo cual ofrece una mejor representación que permite aprender modelos predictivos. Una característica clave de las habilidades es que se adquieren íntegramente a través de la exploración autónoma. Esto significa que el repertorio de habilidades y su modelo predictivo se aprenderán antes de formular la tarea y desarrollar la función de recompensa. Así pues, si disponemos de tiempo suficiente, podremos aprender bastante sobre el entorno y desarrollar las habilidades de comportamiento en él.
Al igual que el método DIAYN, el algoritmo DADS utiliza 2 modelos en el proceso de aprendizaje de habilidades: un modelo de habilidad (agente) y un discriminador (modelo de dinámica de habilidades).
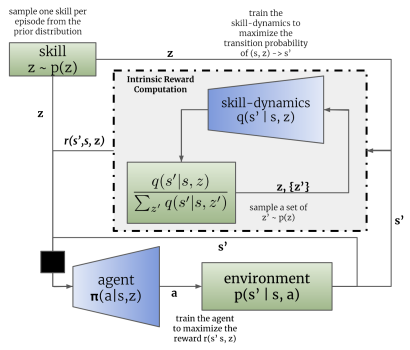
El entrenamiento de los modelos se realizará de forma secuencial e iterativa. En primer lugar, se entrenará un discriminador para predecir un estado futuro basándose en el estado actual y en la habilidad utilizada. Para ello, se suministrarán a la entrada del modelo de agente el estado actual y el vector one-hot de identificación de la habilidad . El agente generará una acción que se ejecuta en el entorno. Al realizar la acción, el agente pasará a un nuevo estado del entorno.
A su vez, el discriminador intentará predecir un nuevo estado del entorno basándose en los mismos datos de entrada. En este caso, el funcionamiento del discriminador se asemejará al funcionamiento del autocodificador anteriormente considerado, solo que en este caso el descodificador recuperará del estado latente no los datos originales, sino que pronosticará el siguiente estado. Y al igual que entrenamos los autocodificadores, entrenaremos el discriminador utilizando el método de descenso de gradiente.
Como podemos ver, aquí radica la primera diferencia entre los algoritmos DIAYN y DADS. En el DIAYN, basándonos en un nuevo estado, identificaremos la habilidad que nos ha llevado a ese estado. El discriminador DADS realiza la función opuesta. A partir de los datos iniciales y de una habilidad conocida, pronosticará el estado posterior del entorno.
Cabe señalar que el proceso es iterativo, así que no intentaremos alcanzar la máxima verosimilitud de inmediato. Al mismo tiempo, necesitaremos al menos una aproximación inicial para entrenar al agente.
Tras la primera serie de iteraciones de entrenamiento del discriminador, procederemos al entrenamiento del agente (modelo de habilidad). Debemos decir de inmediato que se utilizan diferentes paquetes de datos de entrada para el entrenamiento del discriminador y del agente. Sin embargo, esto no nos obligará a crear muestras de entrenamiento aparte. Utilizaremos el mismo búfer de reproducción de experiencia, solo que en cada iteración, generaremos aleatoriamente 2 paquetes de datos de entrenamiento separados de este búfer.
De forma similar al método DIAYN, el modelo de habilidad se entrenará usando métodos de aprendizaje por refuerzo basados en la recompensa generada por el discriminador. La diferencia, como siempre, estará en los detalles. El DADS usará una fórmula matemática diferente para generar la recompensa. No nos detendremos ahora en todas las matemáticas y la justificación del planteamiento. Podrá leerlos en el artículo original. Solo me centraremos en la fórmula de la recompensa final.
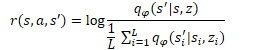
En la fórmula presentada, q(s'|s,z) representa la salida del discriminador para el estado inicial s y la habilidad z tomados por separado, mientras que L determinará el número de habilidades. Así, en el numerador de la fórmula de recompensa veremos el estado previsto para la habilidad analizada, mientras que en el denominador se encontrará el estado medio previsto para todas las habilidades posibles.
El uso de una función de recompensa de este tipo resolverá el problema planteado anteriormente. Como en el numerador utilizaremos el estado previsto para la habilidad actual, recompensaremos la acción del agente que lleve a la consecución del estado previsto. De esta forma conseguiremos predecir el comportamiento de las habilidades.
Al mismo tiempo, el uso del estado medio de todas las habilidades posibles en el denominador nos permitirá recompensar más el comportamiento de la habilidad que sea lo más diferente posible a la media.
Así, el método DADS logra un equilibrio entre previsibilidad y diversidad de habilidades. Esto permitirá enseñar habilidades con comportamientos estructurados y predecibles, al tiempo que se mantiene la capacidad de explorar el entorno.
Así, deberemos prestar atención al hecho de que el comportamiento de la realimentación del discriminador y el entrenamiento del modelo de habilidad provoquen un cambio en el comportamiento del agente, y, en consecuencia, su comportamiento sea distinto de los ejemplos acumulados en el búfer de repetición de experiencia. Por ello, utilizaremos un proceso iterativo con entrenamientos sucesivos del discriminador y el agente para lograr un resultado óptimo en el que el proceso de aprendizaje del modelo se repetirá varias veces. Además, los autores del método proponen usar el coeficiente de importancia a la hora de entrenar el discriminador: este viene determinado por la relación entre la probabilidad de realizar una acción utilizando la política actual del agente y la probabilidad de realizar esta acción en el búfer de repetición de experiencia. Esto permite prestar más atención al comportamiento establecido del agente: de este modo, se nivelará el impacto de las acciones aleatorias.
Cabe señalar que el método DADS se propuso originalmente para enseñar habilidades y crear un modelo del entorno. Como podemos ver, entrenar una habilidad predictiva y un modelo de dinámica para predecir con una probabilidad razonable el nuevo estado del entorno permite realizar la planificación con varios pasos de antelación. En el proceso de planificación, podemos pasar de acciones concretas a una noción más generalizada de las competencias, mientras que las acciones específicas serán determinadas por el agente según la habilidad planificada.
Sin embargo, en esta fase no nos aventuraremos con la planificación a largo plazo: bastará con entrenar al planificador para que defina una habilidad para cada paso individual, tal y como implementamos en el artículo anterior.
2. Implementación usando MQL5
Tras repasar los aspectos teóricos del método Dynamics-Aware Discovery of Skills, vamos a proceder a la aplicación práctica del algoritmo. Eso sí, antes de pasar directamente a la implementación del algoritmo, definiremos la arquitectura de los modelos.
En nuestra implementación, utilizaremos 3 modelos como en el caso del método DIAYN: el agente (modelo de habilidad), el discriminador (modelo de dinámica) y el planeador.
El algoritmo estipula que el agente determinará la acción a realizar según el estado actual y la habilidad seleccionada. Por consiguiente, el tamaño de la capa de datos de entrada deberá ser suficiente para registrar el vector que describa el estado actual y el vector one-hot que identifique la habilidad seleccionada.
A la salida del agente, obtendremos el vector de distribución de probabilidades del espacio de acciones posibles. Como podemos observar, los datos iniciales, la funcionalidad y el resultado del Agente son completamente similares a las características correspondientes del Agente del método DIAYN. En esta implementación, también dejaremos la arquitectura del Agente sin cambios, lo cual nos permitirá comparar de forma práctica el rendimiento de los dos métodos de entrenamiento de habilidades considerados. Sin embargo, esto no significa que no podamos utilizar una arquitectura de modelo diferente.
Recordemos que, en la arquitectura de agentes, usamos una capa de normalización por lotes para convertir los datos originales en una forma comparable.
//--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * BarDescr + AccountDescr + NSkills); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Los datos normalizados se procesan usando un bloque de dos capas de convolución y submuestreo, lo que permite identificar patrones y tendencias individuales en los datos de origen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Los datos procesados tras las capas de convolución pasan a la unidad de decisión, que contiene capas totalmente conectadas y un modelo FQF cuantílico totalmente parametrizado.
El uso de FQF en la salida de la unidad de decisión nos permite obtener predicciones más precisas de las recompensas tras realizar las acciones que consideran no solo su valor medio, sino también su distribución de probabilidad teniendo en cuenta la estocasticidad del entorno.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Como ya hemos dicho, en esta aplicación no hemos creado un modelo de entorno para hacer predicciones con varios pasos de antelación. Al igual que antes, identificaremos la habilidad que se utiliza en cada paso. Por ello, también dejaremos sin cambios la arquitectura y los enfoques de entrenamiento del planificador. Aquí utilizaremos una capa de normalización por lotes para convertir los datos de entrada originales en una forma comparable. El bloque de decisión estará formado por capas totalmente conectadas y un modelo FQF, mientras que sus resultados se transformarán al dominio de la distribución de probabilidades usando una capa SoftMax.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NSkills; descr.window_out = 32; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
En la arquitectura del modelo de discriminador, sin embargo, introduciremos algunos cambios. Recordemos que el algoritmo DADS usa el modelo de Dinámicas como discriminador. Según el algoritmo analizado, deberá predecir un nuevo estado del entorno basándose en el estado actual y en la habilidad seleccionada. Además, el modelo de Dinámicas del método DADS se utilizará para predecir estados futuros a la hora de realizar planificaciones con varios pasos de antelación. Sin embargo, como ya hemos dicho, no haremos planes a largo plazo, lo cual significa que podremos equivocarnos levemente en la predicción de todos las métricas del futuro estado del entorno. Como ya sabe, nuestra descripción del estado del entorno consta de dos grandes bloques:
- los datos históricos de los movimientos de precio y las métricas de los indicadores analizados
- las métricas del estado actual de la cuenta.
La influencia de un solo tráder en el estado del mercado financiero resulta tan insignificante que puede omitirse. Como consecuencia, las acciones de nuestro agente no tendrán ningún efecto sobre los datos históricos. Por ello, resultará lógico excluirlas del entrenamiento de la recompensa interna a la hora de entrenar a nuestro Agente, y, como no vamos a realizar planificaciones a largo plazo, la previsión de estas métricas carecerá de sentido. Así, para generar una recompensa interna, solo necesitaremos pronosticar el futuro rendimiento de la cuenta.
Cabe señalar un punto más: fíjese en la fórmula para generar la recompensa interna del Agente. Además del estado previsto para la habilidad analizada, usaremos el estado medio pronosticado para todas las habilidades posibles, lo cual significa que para determinar una única recompensa tendremos que predecir los estados futuros de todas las habilidades. Para acelerar el proceso de aprendizaje del modelo, hemos optado por un modelo de salida multicabeza. Si se basa únicamente en los datos de entrada, el modelo retornará los estados previstos para todas las habilidades posibles.
Así, la capa de datos de entrada del modelo de Discriminador será comparable a la del modelo de Planificador y debería resultar suficiente para registrar una descripción del estado del sistema sin tener en cuenta la habilidad seleccionada.
//--- Discriminator discriminator.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!discriminator.Add(descr)) { delete descr; return false; }
Los datos de origen obtenidos se someterán a un procesamiento primario en la capa de normalización por lotes y pasarán a la unidad de toma de decisiones, que constará de un perceptrón completamente conectado.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!discriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!discriminator.Add(descr)) { delete descr; return false; }
En la salida del modelo también se utilizará una capa totalmente conectada. Su tamaño será igual al producto del número de habilidades a entrenar por el número de elementos para describir un estado del sistema. En este caso, indicaremos el número de elementos de la descripción del estado de la cuenta.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills*AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!discriminator.Add(descr)) { delete descr; return false; }
Cabe señalar que, aunque en el artículo anterior decidimos utilizar los valores relativos de las métricas de descripción de cuentas, estos valores no parecen estar normalizados, así que no podemos utilizar una única función de activación para predecirlos. Por ello, usaremos una capa neuronal sin función de activación a la salida del modelo discriminador.
El código completo de descripción de las arquitecturas de todos los modelos utilizados se recoge en la función CreateDescriptions, ubicada en el archivo de la biblioteca "Trajectory.mqh". La transferencia de esta función del archivo del asesor al archivo de la biblioteca permite utilizar una arquitectura de modelos en todas las etapas del entrenamiento y evita la necesidad de copiar manualmente las descripciones de la arquitectura de modelos entre los asesores.
En el proceso de entrenamiento de los modelos y la comprobación de los resultados obtenidos, usaremos 3 asesores, de forma similar al entrenamiento de modelos usando el método DIAYN. El asesor experto "Research.mq5", encargado de recopilar los datos de origen para el entrenamiento de modelos, se ha trasladado casi sin cambios. Las únicas modificaciones serán el nombre del archivo para registrar los modelos y las soluciones arquitectónicas descritas anteriormente. El código completo del asesor se encuentra en el archivo adjunto.
Los principales cambios en la aplicación del algoritmo DADS se han implementado en el asesor de entrenamiento de modelos "Study.mq5". En primer lugar, nos referimos al control de la correspondencia de la arquitectura del modelo con las constantes previamente declaradas, que se efectúa en el método OnInit. Aquí hemos ajustado los controles para adaptarlos a las arquitecturas modificadas de los modelos.
Discriminator.getResults(DiscriminatorResult); if(DiscriminatorResult.Size() != NSkills * AccountDescr) { PrintFormat("The scope of the discriminator does not match the skills count (%d <> %d)", NSkills * AccountDescr, Result.Total()); return INIT_FAILED; } Scheduler.getResults(SchedulerResult); Scheduler.SetUpdateTarget(MathMax(Iterations / 100, 500000 / SchedulerBatch)); if(SchedulerResult.Size() != NSkills) { PrintFormat("The scope of the scheduler does not match the skills count (%d <> %d)", NSkills, Result.Total()); return INIT_FAILED; } Actor.getResults(ActorResult); Actor.SetUpdateTarget(MathMax(Iterations / 100, 500000 / AgentBatch * NSkills)); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Bueno, y por supuesto, hemos introducido algunos cambios bastante sustanciales en el método de entrenamiento de modelos Train. Para empezar, veremos dos nuevos métodos auxiliares. El primero es el método GetNewState. En el cuerpo de este método, formaremos un estado calculado de las métricas del balance basándonos en el estado anterior de la cuenta, la acción prevista y el movimiento "futuro" conocido del precio.
Me gustaría llamar la atención sobre el hecho de que el método determina el estado calculado del balance, y no el previsto. Hay un gran significado detrás de ese cálculo. El valor previsto de las métricas de balance se calculará usando el modelo de Dinámicas (Discriminador), mientras que en el método que estamos considerando, determinaremos el estado calculado del balance basándonos en el conocimiento del movimiento de precios posterior del búfer de reproducción de experiencia. La necesidad de dicho cálculo se debe a la alta probabilidad de discrepancia entre la acción del agente del búfer y la acción generada por el agente considerando la habilidad utilizada y la estrategia de comportamiento actualizada. Los datos del búfer de repetición de experiencia permiten realizar un cálculo razonablemente preciso de las métricas de la cuenta y la posición abierta para cualquier acción del agente sin necesidad de repetir la acción en el simulador de estrategias. Esto nos permitirá ampliar considerablemente la muestra de entrenamiento y mejorar así la calidad del entrenamiento del modelo. Esta funcionalidad ya la implementamos en un artículo anterior. Pero, por el momento, la hemos sacado a un método independiente debido a la multitud de llamadas que se realizan a esta funcionalidad mientras se entrenan los modelos.
En los parámetros, el método recibe el array dinámico con las métricas de la descripción de la cuenta en la etapa de toma de decisiones, el identificador de acción y el valor de ganancia/pérdida del movimiento de precio posterior por 1 lote de una posición larga. Como resultado de dichas operaciones, este método retornará un vector de valores que describirán el estado posterior de la cuenta dada la acción especificada.
En el cuerpo del método, crearemos un vector para registrar los resultados y transferiremos los valores iniciales a él como estado inicial del cáculo.
vector<float> GetNewState(float &prev_account[], int action, double prof_1l) { vector<float> result; //--- result.Assign(prev_account);
Según la acción a realizar, se producirán otras bifurcaciones. Si se abre o aumenta una posición, calcularemos el nuevo valor de las posiciones abiertas en la dirección correspondiente. A continuación, calcularemos el cambio en las ganancias/pérdidas acumuladas para cada dirección, considerando el tamaño de la posición abierta y el posterior movimiento del precio. El valor de las ganancias/pérdidas acumuladas en la cuenta será igual a la suma de las dos métricas calculadas anteriormente. Sumando el valor obtenido con las métricas de balance, obtendremos la equidad de la cuenta.
switch(action) { case 0: result[5] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; case 1: result[6] += (float)SymbolInfoDouble(_Symbol, SYMBOL_VOLUME_MIN); result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break;
Si se cierran todas las posiciones abiertas, simplemente añadiremos el valor del beneficio acumulado al balance actual. El valor obtenido se copiará en la equidad y el margen libre, y luego pondremos a cero el resto de las métricas.
case 2: result[0] += result[4]; result[1] = result[0]; result[2] = result[0]; for(int i = 3; i < AccountDescr; i++) result[i] = 0; break;
El recálculo de las métricas durante la espera (sin acciones del agente) resultará similar a las operaciones de apertura de una posición, salvo por el cambio en el volumen de las posiciones abiertas. Es decir, solo recalcularemos las métricas de las ganancias/pérdidas acumuladas y la equidad de las posiciones abiertas anteriormente.
case 3: result[7] += result[5] * (float)prof_1l; result[8] -= result[6] * (float)prof_1l; result[4] = result[7] + result[8]; result[1] = result[0] + result[4]; break; } //--- return result return result; }
Tras recalcular todas las métricas, retornaremos el vector de valores resultante al programa de llamada.
El segundo método que añadiremos servirá para calcular la recompensa intrínseca del agente según los valores predichos del discriminador, la habilidad seleccionada y el estado de cuenta anterior.
Obsérvese que el agente será recompensado por una acción concreta, pero no especificaremos la acción seleccionada por el agente en los parámetros del método. De hecho, aquí se aprecia cierta brecha entre la predicción del agente y la recompensa obtenida. Después de todo, existe la posibilidad de que la acción elegida por el agente no lleve al estado predicho por el discriminador. Obviamente, a medida que el agente y el discriminador se entrenen, la probabilidad de que se produzca una brecha de este tipo disminuirá, si bien seguirá estando presente. Al mismo tiempo, resulta vital para nosotros que la recompensa se corresponda con la acción que conduce al estado previsto. De lo contrario, no obtendremos el comportamiento previsto de las habilidades. Por eso determinaremos la acción recompensada a partir de dos estados posteriores: el estado actual y el estado previsto para la habilidad seleccionada.
Así, la función GetAgentReward obtendrá en sus parámetros la habilidad seleccionada, el vector de resultados de la pasada directa del discriminador y un array de descripción del estado del balance anterior. Como resultado de la función, planearemos obtener el vector de recompensas de los agentes.
Primero, realizaremos un pequeño trabajo preparatorio. El vector de resultados de la pasada directa del discriminador contendrá los estados previstos para todas las habilidades posibles, mientras que para determinar la recompensa, tendremos que identificar las habilidades individuales y calcular los valores medios en cuanto a las métricas individuales. Las operaciones matriciales nos ayudarán a afrontar esta tarea. En primer lugar, deberemos reformatear el vector de resultados del discriminador para hacer de él una matriz.
Así, crearemos una nueva matriz con un tamaño de una fila y un número de columnas igual al número de elementos del vector de resultados del discriminador. Luego copiaremos los valores del vector en una matriz, después de lo cual, reformatearemos la matriz en una matriz rectangular en la que el número de filas se corresponderá con el número de habilidades, mientras que el número de columnas será igual al tamaño del vector de descripción de un estado. En este caso resultará muy importante utilizar el método Reshape y no el método Resize, ya que el primero redistribuye los valores existentes sobre la matriz de nuevo formato, mientras que el segundo solo cambia el número de filas y columnas sin redistribuir los elementos existentes, y en ese caso, perderemos todos los datos salvo la primera habilidad, mientras que las filas añadidas se rellenarán con valores aleatorios.
vector<float> GetAgentReward(int skill, vector<float> &discriminator, float &prev_account[]) { //--- prepare matrix<float> discriminator_matrix; discriminator_matrix.Init(1, discriminator.Size()); discriminator_matrix.Row(discriminator,0); discriminator_matrix.Reshape(NSkills, AccountDescr); vector<float> forecast = discriminator_matrix.Row(skill);
Ahora, para extraer el vector de estado predictivo de la habilidad que nos interesa, bastará con extraer los valores de la fila correspondiente.
A continuación, deberemos definir la acción por la que el agente recibirá recompensas. El principal indicador de una operación comercial que tenemos es el cambio de posición. Sí, es cierto que aquí puede haber muchas convenciones, pero su uso nos ayudará a identificar las operaciones que nos permitirán acercarnos al estado de pronóstico con una probabilidad razonable. Precisamente esto hace que nuestro modelo sea manejable y predecible.
En primer lugar, identificaremos el cambio de posición para cada dirección. Si tenemos una disminución en el tamaño de las posiciones abiertas en ambas direcciones, consideraremos que la acción de cierre de posiciones es la más probable. De lo contrario, favoreceremos el mayor cambio de posición. Consideraremos que se ha abierto una nueva operación en este sentido o se ha realizado una acción.
Si se da la igualdad de cambios, simplemente esperaremos a que pase. Según la teoría de probabilidades que usa valores de coma flotante, este resultado es el menos probable, y con ello queremos incentivar el modelo para que sea proactivo.
//--- check action int action = 3; float buy = forecast[5] - prev_account[5]; float sell = forecast[6] - prev_account[6]; if(buy < 0 && sell < 0) action = 2; else if(buy > sell) action = 0; else if(buy < sell) action = 1;
Ahora que hemos definido la acción recompensada y preparado los datos para los cálculos, podemos proceder directamente a rellenar el vector de recompensa.
Primero formaremos un vector de valores cero por la dimensionalidad del espacio de acción. Luego dividiremos el vector de valores predichos de la habilidad que nos interesa por el vector de valores predichos medios de todas las habilidades. Del vector resultante tomaremos el valor medio. Tendremos en cuenta la posibilidad de un valor negativo como resultado de estas operaciones. Por lo tanto, tomaremos en el logaritmo su valor absoluto. Esto no contradice en absoluto el objetivo principal. Al fin y al cabo, para nosotros es importante maximizar la recompensa de las acciones más atípicas y alejadas del vector de valores medios. Como solución alternativa, que también ayudará a excluir la división por cero, podemos sugerir el uso de la distancia euclidiana entre el vector de la habilidad analizada y el vector de valores medios. Le proponemos poner a prueba la calidad de los planteamientos en la práctica.
//--- calculate reward vector<float> result = vector<float>::Zeros(NActions); float mean = (forecast / discriminator_matrix.Mean(0)).Mean(); result[action] = MathLog(MathAbs(mean)); //--- return result return result; }
El valor de recompensa obtenido lo anotaremos en el elemento del vector que se corresponde con la acción previamente definida. Al final de las operaciones de la función, retornaremos el vector de recompensa resultante al programa que realiza la llamada.
Una vez finalizado el trabajo preparatorio, vamos a pasar al procedimiento de entrenamiento de nuestros modelos Train. Aquí, primero declararemos una serie de variables locales y definiremos el número de trayectorias de muestras de entrenamiento previamente cargadas.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action; int skill, shift;
A continuación, organizaremos el sistema de ciclos del proceso de entrenamiento de los modelos. Debemos decir de entrada que, según el algoritmo DADS, los modelos se entrenan de forma secuencial e iterativa. Primero entrenaremos el Discriminador (fase 0). Después, el Agente (fase 1). Y por último, el Planificador (fase 2). El proceso completo se repetirá varias iteraciones. El número de iteraciones se establecerá en los parámetros externos del asesor experto. Asimismo, en los parámetros externos del asesor, especificaremos el tamaño del lote de entrenamiento para cada fase.
Ahora declararemos un sistema de ciclos anidados en el cuerpo de la función. El ciclo exterior determinará el número de iteraciones del proceso de aprendizaje, mientras que el ciclo anidado definirá la fase de entrenamiento.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { for(int phase = 0; phase < 3; phase++) {
Debemos decir que el ciclo anidado podría sustituirse por una secuencia de operaciones, pero este enfoque eliminaría el copiado de operaciones comunes, tales como la carga del estado inicial desde el búfer de reproducción antes de las pasadas directas del modelo.
Las operaciones de cada fase del entrenamiento se repetirán en el tamaño del lote de entrenamiento que especifiquemos en los parámetros externos del asesor para cada fase por aparte. Por consiguiente, primero determinamos el tamaño del lote de entrenamiento correspondiente, y luego crearemos otro ciclo anidado con el número de repeticiones requerido.
int batch = 0; switch(phase) { case 0: batch = DiscriminatorBatch; break; case 1: batch = AgentBatch; break; case 2: batch = SchedulerBatch; break; default: PrintFormat("Incorrect phase %d"); batch = 0; break; } for(int batch_iter = 0; batch_iter < batch; batch_iter++) {
A continuación, comenzaremos el proceso de entrenamiento directo de los modelos. Primero deberemos preparar los datos de origen. Los seleccionamos aleatoriamente del búfer de reproducción de experiencia. Aquí seleccionaremos al azar una pasada y un estado de este pasada.
int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Después cargaremos los datos de descripción del estado actual del sistema en el búfer de datos.
State.AssignArray(Buffer[tr].States[i].state);
A continuación, convertiremos a unidades relativas y añadiremos un búfer de datos sobre el estado de la cuenta.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
En esta fase, podremos realizar una pasada directa de los modelos. Pero antes de proceder a ramificar el flujo de operaciones según la fase de entrenamiento actual, seguiremos preparando los datos necesarios en cada fase de operaciones para calcular el estado futuro estimado de la cuenta.
bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Solo después de haber realizado todas las operaciones generales empezaremos a dividir el flujo de operaciones según la fase de entrenamiento en curso.
Como ya hemos mencionado, el proceso de aprendizaje comenzará con el entrenamiento del modelo de discriminador. Primero realizaremos una pasada directa del modelo a partir de los datos de entrada previamente preparados y comprobaremos que las operaciones sean correctas.
switch(phase) { case 0: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Recordemos que a la salida del discriminador obtendremos el vector de estados predichos para todas las habilidades aprendidas. Por ello, para preparar los valores objetivo, también deberemos generar estados objetivo para todas las habilidades. Para ello, organizaremos el ciclo por el número de habilidades que hay que aprender, y ya en el cuerpo del ciclo, implementaremos la pasada directa de nuestro agente para cada habilidad individual.
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Basándonos en los resultados de la pasada directa, muestrearemos la acción del agente. Quiero centrarme específicamente en el muestreo de la acción: esto nos ayudará a maximizar la variedad de acciones del agente y fomentará una exploración exhaustiva del entorno.
Basándonos en el estado inicial del sistema, la acción muestreada y la experiencia del movimiento posterior del precio conocido por el búfer de reproducción de experiencia, determinaremos con los cálculos correspondientes el siguiente estado de la cuenta y rellenaremos el bloque correspondiente de valores objetivo del discriminador, pasando a trabajar con la siguiente habilidad.
action = Actor.getSample(); account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); shift = skill * AccountDescr; DiscriminatorResult[shift] = (account[0] - PrevBalance) / PrevBalance; DiscriminatorResult[shift + 1] = account[1] / PrevBalance; DiscriminatorResult[shift + 2] = (account[1] - PrevEquity) / PrevEquity; DiscriminatorResult[shift + 3] = account[2] / PrevBalance; DiscriminatorResult[shift + 4] = account[4] / PrevBalance; DiscriminatorResult[shift + 5] = account[5]; DiscriminatorResult[shift + 6] = account[6]; DiscriminatorResult[shift + 7] = account[7] / PrevBalance; DiscriminatorResult[shift + 8] = account[8] / PrevBalance; }
Tras preparar los datos del objetivo, realizaremos una pasada inversa del discriminador.
if(!Result) { Result = new CBufferFloat(); if(!Result) { PrintFormat("Error of create buffer %d", GetLastError()); ExpertRemove(); break; } } Result.AssignArray(DiscriminatorResult); if(!Discriminator.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
En el siguiente bloque, analizaremos las iteraciones de la siguiente fase del proceso de aprendizaje: el entrenamiento de agentes. Recordemos que estamos preparando los datos originales antes de dividir el flujo de operaciones según la fase de aprendizaje, y esto significa que a estas alturas ya tendremos un búfer generado de datos de origen. Por lo tanto, podemos realizar tranquilamente una pasada directa del discriminador y extraer los resultados de las operaciones, ya que los necesitaremos para generar la recompensa interna.
case 1: if(!Discriminator.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Discriminator.getResults(DiscriminatorResult);
A continuación, al igual que en la anterior fase de aprendizaje, organizaremos un proceso cíclico de iteración secuencial de las habilidades para el estado actual.
for(skill = 0; skill < NSkills; skill++) { SchedulerResult = vector<float>::Zeros(NSkills); SchedulerResult[skill] = 1; StateSkill.AssignArray(GetPointer(State)); StateSkill.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
En el cuerpo del ciclo, organizaremos las operaciones de pasada directa del agente, la generación del vector de recompensa y la pasada inversa del modelo.
reward = GetAgentReward(skill, DiscriminatorResult, Buffer[tr].States[i].account); Result.AssignArray(reward); StateSkill.AssignArray(Buffer[tr].States[i + 1].state); account = GetNewState(Buffer[tr].States[i].account, Actor.getAction(), prof_1l); shift = skill * AccountDescr; StateSkill.Add((account[0] - PrevBalance) / PrevBalance); StateSkill.Add(account[1] / PrevBalance); StateSkill.Add((account[1] - PrevEquity) / PrevEquity); StateSkill.Add(account[2] / PrevBalance); StateSkill.Add(account[4] / PrevBalance); StateSkill.Add(account[5]); StateSkill.Add(account[6]); StateSkill.Add(account[7] / PrevBalance); StateSkill.Add(account[8] / PrevBalance); if(!Actor.backProp(Result, DiscountFactor, GetPointer(StateSkill), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } } break;
Como podemos ver, la enumeración completa de habilidades resulta un poco incoherente con el paradigma común utilizado antes de usar los estados aleatorios. Las partes de la trayectoria y la definición del estado inicial permanecen fieles al muestreo, pero con la enumeración completa de las habilidades para un solo estado, queremos destacar la atención del modelo precisamente en las métricas de identificación de las habilidades. Al fin y al cabo, es precisamente el cambio en la habilidad lo que debe suponer la señal para que el modelo modifique la estrategia de comportamiento.
El siguiente paso en nuestra implementación del algoritmo DADS será el proceso de entrenamiento del planificador. Este proceso repetirá prácticamente la misma funcionalidad en la aplicación del método DIAYN. En primer lugar, realizaremos la pasada directa del planificador y obtendremos la distribución de probabilidad de las habilidades, pero, a diferencia de la implementación anterior, no muestrearemos ni realizaremos una selección codiciosa de habilidades. Somos conscientes de que en un contexto real no existen límites claros de diferenciación entre una estrategia y otra. Estos límites son muy difusos, y todas las divisiones están abarrotadas de diversos permisos y compromisos. En tales condiciones, resultará razonable pasar la distribución de probabilidad completa al agente para la toma de decisiones.
case 2: if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Scheduler.getResults(SchedulerResult);
Me gustaría señalar que durante el entrenamiento hemos transmitido al agente identificadores explícitos de habilidades, por lo que el experimento de transferencia de la distribución de probabilidades al completo a un agente de decisión posterior resulta más interesante aún. Al fin y al cabo, esos datos de entrada están fuera del alcance de la muestra de entrenamiento, lo cual hace impredecible el comportamiento del modelo.
State.AddArray(SchedulerResult); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(!Actor.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } action = Actor.getAction();
Basándonos en los resultados de la pasada directa, realizaremos una selección codiciosa de la acción del agente. Después de todo, nuestro objetivo es entrenar al planificador para que gestione la política de decisiones al nivel de las habilidades, y esto solo resulta posible con habilidades predecibles cuyo comportamiento esté impulsado por una estrategia significativa y coherente.
A continuación, determinaremos el estado posterior calculado de las métricas de descripción de la cuenta y formaremos el vector de recompensas del modelo basándose en ellas. Recordemos que estamos utilizando la variación relativa del balance de la cuenta como recompensa externa del modelo.
account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); SchedulerResult = SchedulerResult * (account[0] / PrevBalance - 1.0); Result.AssignArray(SchedulerResult); State.AssignArray(Buffer[tr].States[i + 1].state); State.Add((account[0] - PrevBalance) / PrevBalance); State.Add(account[1] / PrevBalance); State.Add((account[1] - PrevEquity) / PrevEquity); State.Add(account[2] / PrevBalance); State.Add(account[4] / PrevBalance); State.Add(account[5]); State.Add(account[6]); State.Add(account[7] / PrevBalance); State.Add(account[8] / PrevBalance); if(!Scheduler.backProp(Result, DiscountFactor, GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } break;
Tras preparar el vector de recompensas del modelo y el estado posterior del sistema, realizaremos una pasada inversa del modelo del planificador.
default: PrintFormat("Wrong phase %d", phase); break; } } } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Discriminator", iter * 100.0 / (double)(Iterations), Discriminator.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Tras finalizar las operaciones en el cuerpo del sistema de ciclos de entrenamiento de los modelos, mostraremos un mensaje que informará al usuario sobre el progreso del proceso de aprendizaje de los modelos.
Los otros métodos y funciones del asesor experto, así como el asesor para probar el modelo entrenado se han transferido sin cambios. El código completo de todos los programas utilizados en este artículo se encuentra en el directorio "MQL5\Experts\DADS".
3. Simulación
Los modelos se entrenaron con los datos históricos de los 4 primeros meses de 2023 del marco temporal H1 de EURUSD. Los parámetros de todos los indicadores se han usado por defecto. Como podemos ver, los parámetros de prueba se han tomado sin cambios del artículo anterior. Esto nos permite comparar el rendimiento de los dos métodos de entrenamiento de habilidades.
Para verificar el rendimiento del modelo entrenado, hemos realizado pruebas en el simulador de estrategias en el segmento temporal de mayo de 2023. Es decir, hemos realizado la prueba del modelo entrenado fuera de la muestra de entrenamiento en un intervalo temporal del 25% de la muestra de entrenamiento.
Como resultado de estas pruebas, el modelo ha demostrado la capacidad de generar ganancias con un factor de beneficio de 1,75 y un factor de recuperación de 0,85. La proporción de operaciones rentables ha sido del 52,64%. Al mismo tiempo, la media de las operaciones con ganancias es un 57,37% superior a la media de las operaciones con pérdidas (2,99 frente a -1,90).



El uso casi uniforme de las habilidades también puede observarse del mismo modo. Todas las habilidades han participado en el proceso de prueba.
Debemos decir que en el proceso de prueba del modelo entrenado, al agente no se le ha transmitido ni una sola habilidad de selección codiciosa, sino la distribución de probabilidad completa generada por el planificador. En este caso, la acción de cada agente se ha seleccionado utilizando una estrategia codiciosa para maximizar la recompensa prevista. Este enfoque ofrece al programador el máximo control sobre el funcionamiento del modelo y elimina la estocasticidad de las acciones del agente, que es posible con el muestreo. Recordemos que así es como entrenamos el modelo de Planificador.
Cabe destacar que el experimento de selección codiciosa de habilidades ha mostrado resultados similares. La selección codiciosa de habilidades ha aumentado el factor de beneficio a 1,80, mientras que la proporción de operaciones rentables ha aumentado un 0,91%, hasta el 53,55%. Aquí también vemos un aumento de la operación rentable media a 3,08.

Conclusión
En este artículo, se nos presenta otro método de aprendizaje no supervisado, el método Dynamics-Aware Discovery of Skills (DADS). Con este método, podemos entrenar diversas habilidades para explorar eficazmente el entorno. Al mismo tiempo, las habilidades entrenadas con el método propuesto tienen un comportamiento bastante predecible, lo cual facilita el aprendizaje del planificador, y, en general, mejora la estabilidad del modelo entrenado.
En la parte práctica del artículo, hemos implementado el algoritmo analizado utilizando herramientas MQL5, y también hemos probado el modelo construido. Como conclusión, nuestras pruebas han arrojado resultados alentadores que demuestran la capacidad del modelo para generar beneficios más allá de la muestra de entrenamiento.
No obstante lo dicho, todos los programas presentados y utilizados en este artículo tienen como fin exclusivo demostrar el funcionamiento de los enfoques y no están preparados para su uso en el comercio real.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mql5 | Asesor | Asesor de entrenamiento de modelos |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | FQF.mqh | Biblioteca de clases | Biblioteca de clases de organización de modelos completamente parametrizada |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/12750
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
al iniciar el comprobador de estrategias.
He buscado mucho, ¿tengo que crear el archivo yo mismo? y si es así, ¿dónde debo hacerlo?
He buscado mucho, ¿tengo que crear el archivo yo mismo? y si es así, ¿dónde debo hacerlo?
Hola, ¿qué es el error de EA back?
En primer lugar debe ejecutar Research.mq5 en el probador de estrategias. Y luego ejecutar Study.mq5 en modo real.