Artículos con ejemplos de programación de robots comerciales en el lenguaje MQL5
En el ámbito del trading automático los Asesores Expertos es la cima de la programación y objetivo deseable de cada desarrollador. Usted puede escribir su propio Asesor Experto utilizando los artículos de esta sección. Paso a paso los principiantes podrán pasar todas las fases de creación, depuración y simulación de los sistemas automáticos de trading.
Los artículos no sólo enseñarán a programar en el lenguaje MQL5, sino mostrarán cómo implementar cualquier idea y técnica comercial. Usted conocerá cómo programar el Trailing Stop, cómo realizar la gestión del capital, cómo obtener el valor del indicador y muchas cosas más.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
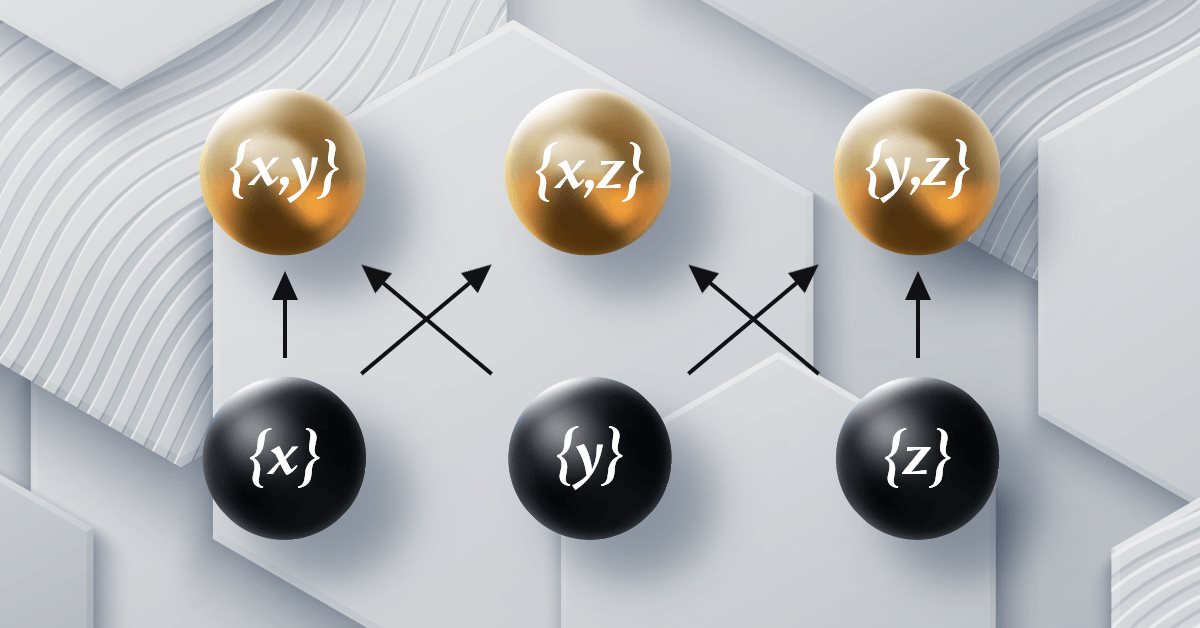
Teoría de categorías en MQL5 (Parte 12): Orden
El artículo forma parte de una serie sobre la implementación de grafos utilizando la teoría de categorías en MQL5 y está dedicado a la relación de orden (Order Theory). Hoy analizaremos dos tipos básicos de orden y exploraremos cómo los conceptos de relación de orden pueden respaldar conjuntos monoides en las decisiones comerciales.

Teoría de Categorías en MQL5 (Parte 10): Grupos monoidales
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. Hoy analizaremos los grupos monoidales como un medio que normaliza conjuntos de monoides y los hace más comparables entre una gama más amplia de conjuntos de monoides y tipos de datos.

Redes neuronales: así de sencillo (Parte 61): El problema del optimismo en el aprendizaje por refuerzo offline
Durante el aprendizaje offline, optimizamos la política del Agente usando los datos de la muestra de entrenamiento. La estrategia resultante proporciona al Agente confianza en sus acciones. No obstante, dicho optimismo no siempre está justificado y puede acarrear mayores riesgos durante el funcionamiento del modelo. Hoy veremos un método para reducir estos riesgos.

Redes neuronales: así de sencillo (Parte 37): Atención dispersa (Sparse Attention)
En el artículo anterior, analizamos los modelos relacionales que utilizan mecanismos de atención en su arquitectura. Una de las características de dichos modelos es su mayor uso de recursos informáticos. Este artículo propondrá uno de los posibles mecanismos para reducir el número de operaciones computacionales dentro del bloque Self-Attention o de auto-atención, lo cual aumentará el rendimiento del modelo en su conjunto.

Trabajando con los precios en la biblioteca DoEasy (Parte 61): Colección de series de tick de los símbolos
Dado que el programa puede utilizar varios símbolos, entonces, es necesario crear su propia lista para cada uno de estos símbolos. En este artículo, vamos a combinar estas listas en una colección de datos de tick. En realidad, se trata de una lista común a base de la clase de la matriz dinámica de punteros a las instancias de la clase CObject y sus herederos de la Biblioteca estándar.

Características del Wizard MQL5 que debe conocer (Parte 6): Transformada de Fourier
La transformada de Fourier, introducida por Joseph Fourier, es un medio para descomponer puntos de datos de ondas complejos en componentes de ondas simples. Esta característica puede resultar útil para los tráders, así que hablaremos de ella en este artículo.

Redes neuronales: así de sencillo (Parte 42): Procrastinación del modelo, causas y métodos de solución
La procrastinación del modelo en el contexto del aprendizaje por refuerzo puede deberse a varias razones, y para solucionar este problema deberemos tomar las medidas pertinentes. El artículo analiza algunas de las posibles causas de la procrastinación del modelo y los métodos para superarlas.

Redes neuronales: así de sencillo (Parte 51): Actor-crítico conductual (BAC)
Los dos últimos artículos han considerado el algoritmo SAC (Soft Actor-Critic), que incorpora la regularización de la entropía en la función de la recompensa. Este enfoque equilibra la exploración del entorno y la explotación del modelo, pero solo es aplicable a modelos estocásticos. El presente material analizará un enfoque alternativo aplicable tanto a modelos estocásticos como deterministas.
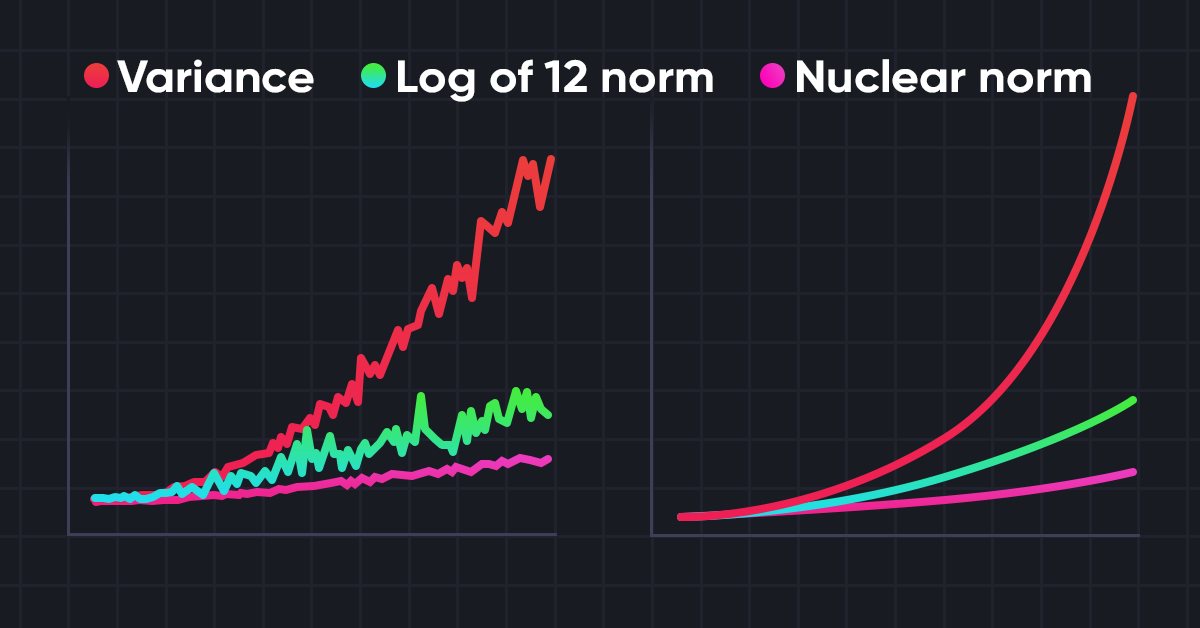
Redes neuronales: así de sencillo (Parte 56): Utilizamos la norma nuclear para incentivar la exploración
La exploración del entorno en tareas de aprendizaje por refuerzo es un problema relevante. Con anterioridad, ya hemos analizado algunos de estos enfoques. Hoy le propongo introducir otro método basado en la maximización de la norma nuclear, que permite a los agentes identificar estados del entorno con un alto grado de novedad y diversidad.

Redes neuronales: así de sencillo (Parte 66): Problemática de la exploración en el entrenamiento offline
El entrenamiento offline del modelo se realiza sobre los datos de una muestra de entrenamiento previamente preparada. Esto nos ofrecerá una serie de ventajas, pero la información sobre el entorno estará muy comprimida con respecto al tamaño de la muestra de entrenamiento, lo que, a su vez, limitará el alcance del estudio. En este artículo, querríamos familiarizarnos con un método que permite llenar la muestra de entrenamiento con los datos más diversos posibles.

Redes neuronales: así de sencillo (Parte 64): Método de clonación conductual ponderada conservadora (CWBC)
Como resultado de las pruebas realizadas en artículos anteriores, hemos concluido que la optimalidad de la estrategia entrenada depende en gran medida de la muestra de entrenamiento utilizada. En este artículo, nos familiarizaremos con un método bastante sencillo y eficaz para seleccionar trayectorias para el entrenamiento de modelos.

Redes neuronales: así de sencillo (Parte 60): Online Decision Transformer (ODT)
En los 2 últimos artículos nos hemos centrado en el método Decision Transformer, que modela las secuencias de acciones en el contexto de un modelo autorregresivo de recompensas deseadas. En el artículo de hoy, analizaremos otro algoritmo para optimizar este método.

Integración de modelos ML con el simulador de estrategias (Conclusión): Implementación de un modelo de regresión para la predicción de precios
Este artículo describe la implementación de un modelo de regresión de árboles de decisión para predecir precios de activos financieros. Se realizaron etapas de preparación de datos, entrenamiento y evaluación del modelo, con ajustes y optimizaciones. Sin embargo, es importante destacar que el modelo es solo un estudio y no debe ser usado en operaciones reales.
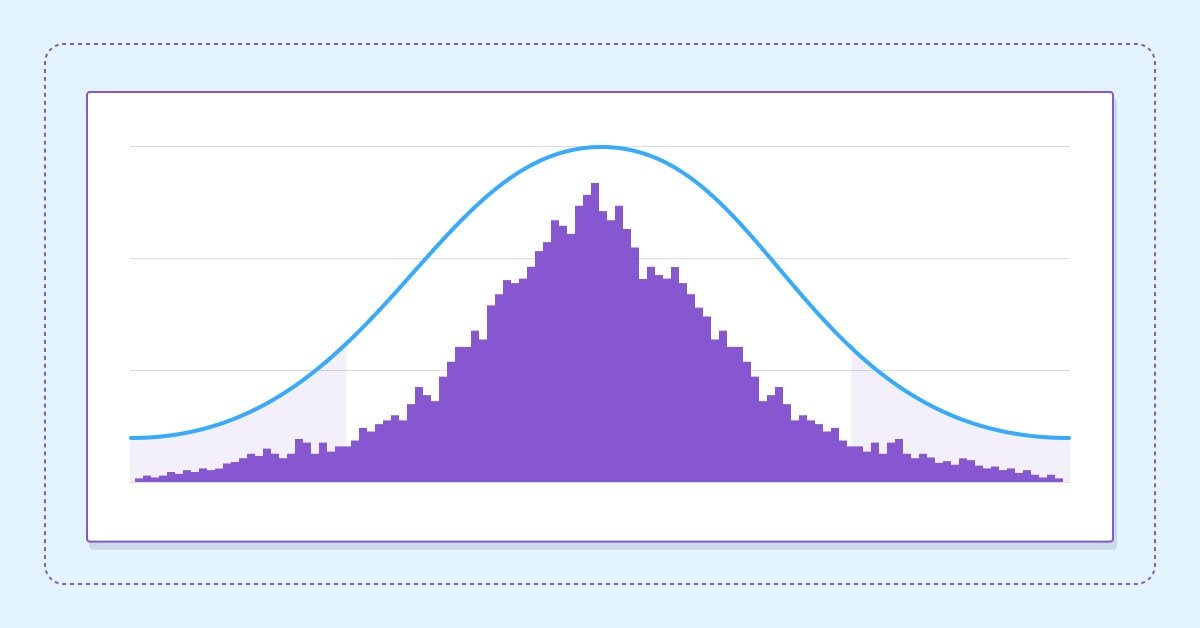
Estimamos la rentabilidad futura usando intervalos de confianza
En este artículo, nos adentraremos en la aplicación de técnicas de bootstrapping como forma de evaluar la rentabilidad futura de una estrategia automatizada.

Redes neuronales: así de sencillo (Parte 40): Enfoques para utilizar Go-Explore con una gran cantidad de datos
Este artículo analizará el uso del algoritmo Go-Explore durante un largo periodo de aprendizaje, ya que la estrategia de elección aleatoria puede no conducir a una pasada rentable a medida que aumenta el tiempo de entrenamiento.

Redes neuronales: así de sencillo (Parte 53): Descomposición de la recompensa
Ya hemos hablado más de una vez de la importancia de seleccionar correctamente la función de recompensa que utilizamos para estimular el comportamiento deseado del Agente añadiendo recompensas o penalizaciones por acciones individuales. Pero la cuestión que sigue abierta es el descifrado de nuestras señales por parte del Agente. En este artículo hablaremos sobre la descomposición de la recompensa en lo que respecta a la transmisión de señales individuales al Agente entrenado.
Preparación de indicadores de símbolo/periodo múltiple
En este artículo analizaremos los principios de la creación de los indicadores de símbolo/periodo múltiple y la obtención de datos de ellos en asesores e indicadores. Asimismo, veremos los principales matices de uso de los indicadores múltiples en asesores e indicadores, y su representación a través de los búferes del indicador personalizado.

Redes neuronales: así de sencillo (Parte 67): Utilizamos la experiencia adquirida para afrontar nuevos retos
En este artículo, seguiremos hablando de los métodos de recopilación de datos en una muestra de entrenamiento. Obviamente, en el proceso de entrenamiento será necesaria una interacción constante con el entorno, aunque con frecuencia se dan situaciones diferentes.
Teoría de Categorías en MQL5 (Parte 6): Productos fibrados monomórficos y coproductos fibrados epimórficos
La teoría de categorías es un apartado diverso y en expansión de las matemáticas, que solo recientemente ha comenzado a ser trabajado por la comunidad MQL5. Esta serie de artículos tiene por objetivo repasar algunos de sus conceptos para crear una biblioteca abierta y seguir usando este maravilloso apartado en la creación de estrategias comerciales.
Indicadores alternativos de riesgo y rentabilidad en MQL5
En este artículo, presentaremos una aplicación de varias medidas de rentabilidad y riesgo consideradas alternativas al ratio de Sharpe e investigaremos diferentes curvas de capital hipotéticas para analizar sus características.

Análisis cuantitativo en MQL5: implementamos un algoritmo prometedor
Hoy veremos qué es el análisis cuantitativo, cómo lo utilizan los grandes jugadores y crearemos uno de los algoritmos de análisis cuantitativo en MQL5.
Redes neuronales: así de sencillo (Parte 55): Control interno contrastado (CIC)
El aprendizaje contrastivo (Contrastive learning) supone un método de aprendizaje de representación no supervisado. Su objetivo consiste en entrenar un modelo para que destaque las similitudes y diferencias entre los conjuntos de datos. En este artículo, hablaremos del uso de enfoques de aprendizaje contrastivo para investigar las distintas habilidades del Actor.

Redes neuronales: así de sencillo (Parte 63): Entrenamiento previo del Transformador de decisiones no supervisado (PDT)
Continuamos nuestra análisis de la familia de métodos del Transformador de decisiones. En artículos anteriores ya hemos observado que entrenar el transformador subyacente en la arquitectura de estos métodos supone todo un reto y requiere una gran cantidad de datos de entrenamiento marcados. En este artículo, analizaremos un algoritmo para utilizar trayectorias no marcadas para el entrenamiento previo de modelos.

Filtrado y extracción de características en el dominio de la frecuencia
En este artículo, analizaremos la aplicación de filtros digitales a series temporales representadas en el dominio de la frecuencia con el fin de extraer características únicas que puedan resultar útiles para los modelos de predicción.

Redes neuronales: así de sencillo (Parte 71): Previsión de estados futuros basada en objetivos (GCPC)
En trabajos anteriores, hemos introducido el método del Decision Transformer y varios algoritmos derivados de él. Asimismo, hemos experimentado con distintos métodos de fijación de objetivos. Durante los experimentos, hemos trabajado con distintas formas de fijar objetivos, pero el aprendizaje de la trayectoria ya recorrida por parte del modelo siempre quedaba fuera de nuestra atención. En este artículo, queremos presentar un método que llenará este vacío.

Redes neuronales: así de sencillo (Parte 70): Mejoramos las políticas usando operadores de forma cerrada (CFPI)
En este trabajo, proponemos introducir un algoritmo que use operadores de mejora de políticas de forma cerrada para optimizar las acciones offline del Agente.

Redes neuronales: así de sencillo (Parte 68): Optimización de políticas offline basada en preferencias
Desde los primeros artículos sobre el aprendizaje por refuerzo, hemos tocado de un modo u otro dos problemas: la exploración del entorno y la definición de la función de recompensa. Los artículos más recientes se han centrado en el problema de la exploración en el aprendizaje offline. En este artículo, queremos presentar un algoritmo cuyos autores han abandonado por completo la función de recompensa.

Introducción a MQL5 (Parte 3): Estudiamos los elementos básicos de MQL5
En este artículo, seguiremos estudiando los fundamentos de la programación MQL5. Hoy veremos los arrays, las funciones definidas por el usuario, los preprocesadores y el procesamiento de eventos. Para una mayor claridad, todos los pasos de cada explicación irán acompañado de un código. Esta serie de artículos sienta las bases para el aprendizaje de MQL5, prestando especial atención a la explicación de cada línea de código.

Trailing stop en el trading
En este artículo, analizaremos el uso del trailing stop en el trading: su utilidad y eficacia, y cómo podemos utilizarlo. La eficacia de un trailing stop depende en gran medida de la volatilidad del precio y de la selección del nivel de stop loss. Para fijar un stop loss pueden usarse diversos métodos.

Redes neuronales: así de sencillo (Parte 69): Restricción de la política de comportamiento basada en la densidad de datos offline (SPOT)
En el aprendizaje offline, utilizamos un conjunto de datos fijo, lo que limita la cobertura de la diversidad del entorno. Durante el proceso de aprendizaje, nuestro Agente puede generar acciones fuera de dicho conjunto. Si no hay retroalimentación del entorno, la corrección de las evaluaciones de tales acciones será cuestionable. Mantener la política del Agente dentro de la muestra de entrenamiento se convierte así en un aspecto importante para garantizar la solidez del entrenamiento. De eso hablaremos en este artículo.

Desarrollamos de un asesor multidivisa (Parte 1): Funcionamiento conjunto de varias estrategias comerciales
Existen bastantes estrategias comerciales distintas. Para diversificar los riesgos y aumentar la estabilidad de los resultados comerciales, puede resultar útil utilizar varias estrategias que funcionen en paralelo. Pero si cada estrategia se implementa como un asesor independiente, se hace mucho más difícil gestionar su trabajo conjunto en una cuenta comercial. Para resolver este problema, es deseable implementar el funcionamiento de diferentes estrategias de negociación en un asesor.

Creamos un asesor multidivisa sencillo utilizando MQL5 (Parte 6): Dos indicadores RSI se cruzan entre sí
Por asesor multidivisa en este artículo nos referimos a un asesor o robot comercial que utiliza dos indicadores RSI con líneas de intersección: un RSI rápido que se cruza con uno lento.

Creación de un algoritmo de creación de mercado en MQL5
¿Cómo funcionan los creadores de mercado? Consideremos esta cuestión y creemos un algoritmo primitivo de creación de mercado.
Trailing stop en el trading
En este artículo, analizaremos el uso del trailing stop en el trading: su utilidad y eficacia, y cómo podemos utilizarlo. La eficacia de un trailing stop depende en gran medida de la volatilidad del precio y de la selección del nivel de stop loss. Para fijar un stop loss pueden usarse diversos métodos.