
Fundamentos de programación en MQL5 - Listas

Introducción
La nueva versión del lenguaje MQL5 ha proporcionado al programador que trabaja en los proyectos de sistemas automáticos de trading las eficaces herramientas para la implementación de complejas tareas. No se puede negar el hecho de que las capacidades de programación del lenguaje han sido ampliadas considerablemente. ¡La presencia de los recursos de la programación orientada a objetos (POO) en MQL5 ya vale bastante! Es más, no podemos olvidar mencionar la Librería estándar. A juzgar por la presencia del error con el código 359, muy pronto aparecerán las plantillas de las clases.
En este artículo me gustaría abordar el tema que puede ser de alguna manera la ampliación o continuación de los temas que describen los tipos de datos y sus conjuntos. Aquí, voy a hacer referencia a un artículo publicado en la web de MQL5.community. La descripción muy detallada y sistémica de los principios y la lógica del trabajo con los arrays ha sido propuesta por Dmitry Fedoseev (Integer) en su artículo «Fundamentos de programación en MQL5 - Arrays».
Bien, hoy propongo ocuparnos de las listas, o para ser más exacto de las listas enlazadas lineales. Empezaremos con la estructura, propósito y lógica de la construcción de la lista. Luego veremos las herramientas que ofrece la Librería estándar referentes a nuestro tema. A continuación, les mostraré los ejemplos de aplicación de las listas en su trabajo con el lenguaje MQL5.
- Concepto de la "Lista" y el "Nodo": teoría
- 1.1 Nodo para una lista simplemente enlazada
- 1.2 Nodo para una lista doblemente enlazada
- 1.3 Nodo para una lista circular doblemente enlazada
- 1.4 Operaciones básicas en la lista
- Concepto de la "Lista" y el "Nodo": programación
- 2.1 Nodo para una lista simplemente enlazada
- 2.2 Nodo para una lista doblemente enlazada
- 2.3 Nodo para una lista doblemente enlazada usando nodos de arrays
- 2.4 Lista simplemente enlazada
- 2.5 Lista doblemente enlazada
- 2.6 Lista doblemente enlazada usando nodos de arrays
- 2.7 Lista circular doblemente enlazada
- Listas en la Librería estándar MQL5
- Ejemplos del uso de las listas en MQL5
1. Concepto de la "Lista" y el "Nodo": teoría
Pues bien, ¿qué es una lista para un programador y cómo manejarla? Voy a recurrir a la fuente pública Wikipedia para la definición general de este término:
En Ciencias de la Computación, una lista (en inglés list) es un tipo de datos abstracto que representa un conjunto ordenado de valores en el que un valor puede encontrarse más de una vez. La instancia de una lista es la representación computacional del concepto matemático de una secuencia finita: la tupla. Las instancias de los valores de la lista se llaman los elementos de la lista (en inglés item, entry o element). Si un valor se encuentra varias veces, cada entrada se considera un elemento separado.
El término «la lista» también determina ciertas estructuras de datos concretas que se utilizan para la implementación de las listas abstractas, sobre todo, listas enlazadas.
Espero que estén de acuerdo conmigo en que la definición es algo abstrusa.
Para los propósitos del presente artículo, estamos más interesados en la última frase de la definición. Por eso vamos a hacer hincapié en esta frase:
En Ciencias de la Computación, una lista enlazada es una estructura de datos dinámica fundamental que consiste en una secuencia de nodos cada uno de los cuales guarda tanto los datos, como una o dos referencias («enlaces») al nodo anterior o posterior de la lista. [1] La principal ventaja de las listas enlazadas respecto a los arrays es la flexibilidad estructural: el orden de los elementos de la lista enlazada puede ser diferente del orden de almacenamiento de los elementos en la memoria, y el orden de recorrido de la lista se establece explicitamente por sus enlaces internos.
Vamos a estudiarlos paso a paso.
En programación, la lista por sí misma ya es algún tipo de datos. Bien, eso ya lo hemos aclarado. Es más bien un tipo sintético porque incluye otros tipos de datos. Las listas parecen en cierta medida a los arrays. Si un array de datos del mismo tipo fuera clasificado como un tipo de datos nuevo, obtendríamos una lista. Pero no es exactamente así.
La principal ventaja de la lista consiste en su posibilidad de crecer o reducirse cuando es necesario. Y en eso la lista parece al array dinámico. Lo único, para la lista no hace falta aplicar constantemente la función ArrayResize().
Hablando del orden de almacenamiento de los elementos en la memoria, los nodos de la lista no se almacenan o no necesitan almacenarse del mismo modo como se almacenan los elementos del array en las zonas adyacentes de la memoria.
Pues, eso es todo más o menos. Seguimos adelante según la lista.
1.1 Nodo para una lista simplemente enlazada
La lista permite almacenar nodos en vez de elementos. El nodo es un tipo de datos compuesto de dos partes.
La primera parte es el campo de datos, la segunda se utiliza para los enlaces con otro(s) nodo(s) (Fig. 1). El primer nodo de la lista se llama head (la cabeza), y el último lleva el nombre tail (la cola). El puntero de la cola es NULL. Básicamente, se utiliza para apuntar al nodo fuera de la lista. En otros recursos especializados la cola la llaman al resto de la lista a excepción de la cabeza.

Fig. 1 "Nodos para la lista enlazada simple"
Además del nodo para la lista simplemente enlazada hay otros tipos de nodos. Quizá el nodo para la lista doblemente enlazada sea el más popular.
1.2 Nodo para una lista doblemente enlazada
Además, vamos a necesitar un nodo que va a servir para las necesidades de la lista doblemente enlazada. A diferencia del tipo anterior, éste contiene un puntero más que hace referencia al nodo anterior. Y naturalmente, este nodo de la cabeza de la lista va a ser NULL. En el esquema se muestra la estructura de la lista que contiene este tipo de nodos (Fig. 2), y los punteros que se apuntan a los nodos anteriores se muestran con flechas rojas.

Fig.2 Nodos para la lista doblemente enlazada
En conclusión, las posibilidades del nodo para la lista doblemente enlazada van a ser las mismas que tiene el nodo para las listas simplemente enlazadas, a menos que surja la necesidad de procesar el puntero al nodo anterior.
1.3 Nodo para una lista circular doblemente enlazada
Hay casos cuando los nodos arriba mencionados pueden ser utilizados para las listas no lineales. Aunque este artículo va a tratar principalmente de las listas lineales, pondré un ejemplo de una lista circular.

Fig.3 Nodos para la lista circular doblemente enlazada
En el diagrama de la lista circular doblemente enlazada (Fig. 3) se puede observar que los nodos con dos punteros simplemente están ciclados. Esto ha sido hecho usando la flecha naranja y verde. Así, el nodo de cabeza va a usar uno de los punteros para referirse a la cola (como a un elemento anterior). Y el campo del enlace en el nodo de la cola tampoco va a estar vacío, ya que tendrá el puntero a la cabeza.
1.4 Operaciones básicas en la lista
Según la literatura especializada, todas las operaciones en la lista se puede dividir en 3 grupos básicos:
- Inserción (en la lista aparece un nodo nuevo);
- Eliminación (se elimina algún nodo de la lista);
- Comprobación (se solicitan los datos de algún nodo).
Los métodos de inserción incluyen los siguientes:
- insertar nuevo nodo al principio de la lista;
- insertar nuevo nodo al final de la lista;
- insertar nuevo nodo en la posición especificada de la lista;
- insertar nuevo nodo en la lista vacía;
- constructor paramétrico.
Respecto a las operaciones de eliminación, pues es prácticamente el espejo virtual de las operaciones de inserción:
- eliminar el nodo de cabeza;
- eliminar el nodo de cola;
- eliminar el nodo de la posición especificada;
- destructor.
Aquí podría destacar el destructor que no sólo tiene que finalizar el trabajo de la lista de forma correcta, sino también eliminar correctamente todos sus elementos.
Y el tercer grupo relacionado con diferentes tipos de comprobaciones, en realidad, proporciona el acceso a los nodos o a los valores de los nodos de la lista:
- buscar el valor establecido;
- comprobar si la lista está vacía;
- obtener el valor del nodo i de la lista;
- obtener el puntero al nodo i en la lista;
- obtener el tamaño de la lista;
- imprimir los valores de elementos de la lista.
En adición a los grupos principales, me gustaría mencionar el cuarto grupo (grupo de servicio). Es un grupo auxiliar para los arriba mencionados:
- operador de asignación;
- constructor de copiado;
- trabajo con puntero dinámico;
- copiado de la lista por valores;
- ordenación.
Pues, eso es todo. Desde luego, si el programador lo desea, puede ampliar las posibilidades y la funcionalidad de la clase de listas en cualquier momento.
2. Concepto de la "Lista" y el "Nodo": programación
En esta parte del artículo, propongo pasar directamente a la programación de nodos y listas. Voy a ilustrar el código con diagramas en la medida en que fuera necesario.
2.1 Nodo para una lista simplemente enlazada
Vamos a crear una base para la clase del nodo (Fig. 4) que va a servir para las necesidades de la lista simplemente enlazada. Puede familiarizarse con la notación (maqueta) de la clase en el artículo "Cómo desarrollar un Asesor Experto usando las herramientas de UML" (ver Fig. 5. Modelo UML de la clase CTradeExpert).

Fig.4 Modelo de la clase CiSingleNode
Ahora vamos a intentar trabajar con el código. Está basado en un ejemplo del libro de Art Friedman y otros autores "C/C+. Archivo de programas".
//+------------------------------------------------------------------+ //| Clase CiSingleNode | //+------------------------------------------------------------------+ class CiSingleNode { protected: int m_val; // datos CiSingleNode *m_next; // puntero al siguiente nodo public: void CiSingleNode(void); // constructor por defecto void CiSingleNode(int _node_val); // constructor paramétrico void ~CiSingleNode(void); // destructor void SetVal(int _node_val); // método set para los datos void SetNextNode(CiSingleNode *_ptr_next); // método set para el siguiente nodo virtual void SetPrevNode(CiSingleNode *_ptr_prev){}; // método set para el nodo anterior virtual CiSingleNode *GetPrevNode(void) const {return NULL;}; // método get para el nodo anterior CiSingleNode *GetNextNode(void) const; // método get para el siguiente nodo int GetVal(void){TRACE_CALL(_t_flag) return m_val;} // método get para los datos };
No voy a explicar cada método de la clase CiSingleNode. Puede conseguir la información más detallada en el archivo CiSingleNode.mqh. Pues, me gustaría matizar una cosa interesante. La clase tiene métodos virtuales que trabajan con nodos anteriores. En realidad, son ficticios y su presencia se explica con los propósitos de polimorfismo para los futuros descendentes.
En el código se utiliza la directiva del preprocesador TRACE_CALL(f). Es necesaria para el emplazamiento de la llamada de cada método utilizado.
#define TRACE_CALL(f) if(f) Print("Calling: "+__FUNCSIG__);
Teniendo sólo la clase CiSingleNode ya podemos crear una lista enlazada simple. El ejemplo del código.
//=========== Example 1 (processing the CiSingleNode type ) CiSingleNode *p_sNodes[3]; // #1 p_sNodes[0]=NULL; srand(GetTickCount()); // initialize a random values generator //--- create nodes for(int i=0;i<ArraySize(p_sNodes);i++) p_sNodes[i]=new CiSingleNode(rand()); // #2 //--- links for(int j=0;j<(ArraySize(p_sNodes)-1);j++) p_sNodes[j].SetNextNode(p_sNodes[j+1]); // #3 //--- check values for(int i=0;i<ArraySize(p_sNodes);i++) { int val=p_sNodes[i].GetVal(); // #4 Print("Node #"+IntegerToString(i+1)+ // #5 " value = "+IntegerToString(val)); } //--- check next-nodes for(int j=0;j<(ArraySize(p_sNodes)-1);j++) { CiSingleNode *p_sNode_next=p_sNodes[j].GetNextNode(); // #9 int snode_next_val=p_sNode_next.GetVal(); // #10 Print("Next-Node #"+IntegerToString(j+1)+ // #11 " value = "+IntegerToString(snode_next_val)); } //--- delete nodes for(int i=0;i<ArraySize(p_sNodes);i++) delete p_sNodes[i]; // #12
En la cadena #1 declaramos el array de punteros a los objetos del tipo CiSingleNode. En la cadena #2 llenamos el array con punteros creados. Para los datos de cada nodo cogemos un número pseudoaleatorio entero de 0 a 32767 usando la función rand(). En la cadena #3 enlazamos los nodos a través del puntero next. En las cadenas #4-5 comprobamos los valores de los nodos. En las cadenas #9-11 comprobamos el resultado de ejecución de los enlaces. Eliminamos los punteros en la cadena #12.
Es lo que tendremos en el log.
DH 0 23:23:10 test_nodes (EURUSD,H4) Node #1 value = 3335 KP 0 23:23:10 test_nodes (EURUSD,H4) Node #2 value = 21584 GI 0 23:23:10 test_nodes (EURUSD,H4) Node #3 value = 917 HQ 0 23:23:10 test_nodes (EURUSD,H4) Next-Node #1 value = 21584 HI 0 23:23:10 test_nodes (EURUSD,H4) Next-Node #2 value = 917
Gráficamente, la estructura de los nodos obtenidos se puede representar de la siguiente manera (Fig. 5).
!["Enlaces entre los nodos en el array CiSingleNode *p_sNodes[3]"](https://c.mql5.com/2/6/4.png "\"Enlaces entre los nodos en el array CiSingleNode *p_sNodes[3]\"")
Fig. 5 "Enlaces entre los nodos en el array CiSingleNode *p_sNodes[3]"
Ahora nos centramos en el nodo para la lista doblemente enlazada.
2.2 Nodo para una lista doblemente enlazada
Primero, vamos a recordar que el nodo en una lista doblemente enlazada se diferencia con que tiene 2 punteros: uno al nodo next (siguiente), y el otro al nodo previous (anterior). Es decir, a un nodo de la lista simplemente enlazada hay que añadirle un puntero al nodo anterior.
Propongo utilizar en este caso la herencia como relación de las clases. Entonces, el modelo para la clase del nodo de la lista doblemente enlazada será el siguiente (Fig. 6).

Fig.6 Modelo de la clase CDoubleNode
Ahora nos toca estudiar el código.
//+------------------------------------------------------------------+ //| Clase CDoubleNode | //+------------------------------------------------------------------+ class CDoubleNode : public CiSingleNode { protected: CiSingleNode *m_prev; // puntero al nodo anterior public: void CDoubleNode(void); // constructor por defecto void CDoubleNode(int node_val); // constructor paramétrico void ~CDoubleNode(void){TRACE_CALL(_t_flag)};// destructor virtual void SetPrevNode(CiSingleNode *_ptr_prev); // método set para el nodo anterior virtual CiSingleNode *GetPrevNode(void) const; // método get para el nodo anterior CDoubleNode };
Aquí hay muy pocos métodos adicionales- son virtuales y están relacionados con el trabajo con el nodo anterior. La descripción completa de la clase se encuentra en el archivo CDoubleNode.mqh.
Vamos a intentar crear una lista doblemente enlazada a base de la clase CDoubleNode. Aquí tenemos el ejemplo del código.
//=========== Example 2 (processing the CDoubleNode type) CiSingleNode *p_dNodes[3]; // #1 p_dNodes[0]=NULL; srand(GetTickCount()); // initialize a random values generator //--- create nodes for(int i=0;i<ArraySize(p_dNodes);i++) p_dNodes[i]=new CDoubleNode(rand()); // #2 //--- links for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { p_dNodes[j].SetNextNode(p_dNodes[j+1]); // #3 p_dNodes[j+1].SetPrevNode(p_dNodes[j]); // #4 } //--- check values for(int i=0;i<ArraySize(p_dNodes);i++) { int val=p_dNodes[i].GetVal(); // #4 Print("Node #"+IntegerToString(i+1)+ // #5 " value = "+IntegerToString(val)); } //--- check next-nodes for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { CiSingleNode *p_sNode_next=p_dNodes[j].GetNextNode(); // #9 int snode_next_val=p_sNode_next.GetVal(); // #10 Print("Next-Node #"+IntegerToString(j+1)+ // #11 " value = "+IntegerToString(snode_next_val)); } //--- check prev-nodes for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { CiSingleNode *p_sNode_prev=p_dNodes[j+1].GetPrevNode(); // #12 int snode_prev_val=p_sNode_prev.GetVal(); // #13 Print("Prev-Node #"+IntegerToString(j+2)+ // #14 " value = "+IntegerToString(snode_prev_val)); } //--- delete nodes for(int i=0;i<ArraySize(p_dNodes);i++) delete p_dNodes[i]; // #15
Prácticamente, es lo mismo que sucede durante la creación de la lista simplemente enlazada a diferencia de unas peculiaridades. Fíjense, en la cadena #1 se declara el array de punteros p_dNodes[]. El tipo de punteros puede ser el mismo que tiene la clase base. El principio de polimorfismo en la cadena #2 ayudará reconocerlos en el futuro. En las cadenas #12-14 se comprueban los nodos prev (anteriores).
En el log va a figurar la siguiente información.
GJ 0 16:28:12 test_nodes (EURUSD,H4) Node #1 value = 17543 IQ 0 16:28:12 test_nodes (EURUSD,H4) Node #2 value = 1185 KK 0 16:28:12 test_nodes (EURUSD,H4) Node #3 value = 23216 DS 0 16:28:12 test_nodes (EURUSD,H4) Next-Node #1 value = 1185 NH 0 16:28:12 test_nodes (EURUSD,H4) Next-Node #2 value = 23216 FR 0 16:28:12 test_nodes (EURUSD,H4) Prev-Node #2 value = 17543 LI 0 16:28:12 test_nodes (EURUSD,H4) Prev-Node #3 value = 1185
Gráficamente, la estructura de los nodos obtenidos se puede representar de la siguiente manera (Fig. 7).
!["Enlaces entre los nodos en el array CDoubleNode *p_sNodes[3]"](https://c.mql5.com/2/6/5.png "\"Enlaces entre los nodos en el array CDoubleNode *p_sNodes[3]\"")
Fig. 7 Enlaces entre los nodos en el array CDoubleNode *p_sNodes[3]
Ahora propongo pasar al nodo que será útil para "construir" una lista doblemente enlazada usando nodos de arrays.
2.3 Nodo para una lista doblemente enlazada usando nodos de arrays
Imagínese que hay un nodo que contiene un miembro de datos que no se refiere a un valor, sino a un array entero. Es decir, contiene y describe un array entero. Entonces se puede utilizar el nodo de este tipo para formar una lista enlazada con nodos de arrays. No lo he mostrado gráficamente porque es exactamente idéntico a un nodo estándar para una lista doblemente enlazada. La única diferencia es que el atributo "datos" incluye un array entero.
Volvemos a utilizar la herencia. La clase base para el nodo de la lista doblemente enlazada usando nodos de arrays (unrolled doubly linked list) será la clase CDoubleNode. El modelo para la clase del nodo de este tipo de la lista enlazada será el siguiente (Fig. 8).

Fig.8 Modelo de la clase CiUnrollDoubleNode
La clase CiUnrollDoubleNode puede ser definida usando el siguiente código:
//+------------------------------------------------------------------+ //| Clase CiUnrollDoubleNode | //+------------------------------------------------------------------+ class CiUnrollDoubleNode : public CDoubleNode { private: int m_arr_val[]; // array de datos public: void CiUnrollDoubleNode(void); // constructor por defecto void CiUnrollDoubleNode(int &_node_arr[]); // constructor paramétrico void ~CiUnrollDoubleNode(void); // destructor bool GetArrVal(int &_dest_arr_val[])const; // método get para el array de datos bool SetArrVal(const int &_node_arr_val[]); // método set para el array de datos };
El archivo CiUnrollDoubleNode.mqh contiene la descripción detallada de cada método.
Vamos a ver un constructor paramétrico como ejemplo.
//+------------------------------------------------------------------+ //| Constructor paramétrico | //+------------------------------------------------------------------+ void CiUnrollDoubleNode::CiUnrollDoubleNode(int &_node_arr[]) : CDoubleNode(ArraySize(_node_arr)) { ArrayCopy(this.m_arr_val,_node_arr); TRACE_CALL(_t_flag) }
Aquí, utilizando las lista de inicialización, introducimos el tamaño del array unidimensional en el miembro de datos this.m_val.
Después, crearemos "manualmente" una lista doblemente enlazada usando nodos de arrays y comprobaremos sus enlaces.
//=========== Example 3 (processing the CiUnrollDoubleNode type) //--- data arrays int arr1[],arr2[],arr3[]; // #1 int arr_size=15; ArrayResize(arr1,arr_size); ArrayResize(arr2,arr_size); ArrayResize(arr3,arr_size); srand(GetTickCount()); // initialize a random values generator //--- fill the arrays with pseudorandom integers for(int i=0;i<arr_size;i++) { arr1[i]=rand(); // #2 arr2[i]=rand(); arr3[i]=rand(); } //--- create nodes CiUnrollDoubleNode *p_udNodes[3]; // #3 p_udNodes[0]=new CiUnrollDoubleNode(arr1); p_udNodes[1]=new CiUnrollDoubleNode(arr2); p_udNodes[2]=new CiUnrollDoubleNode(arr3); //--- links for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { p_udNodes[j].SetNextNode(p_udNodes[j+1]); // #4 p_udNodes[j+1].SetPrevNode(p_udNodes[j]); // #5 } //--- check values for(int i=0;i<ArraySize(p_udNodes);i++) { int val=p_udNodes[i].GetVal(); // #6 Print("Node #"+IntegerToString(i+1)+ // #7 " value = "+IntegerToString(val)); } //--- check arrays values for(int i=0;i<ArraySize(p_udNodes);i++) { int t_arr[]; // destination array bool isCopied=p_udNodes[i].GetArrVal(t_arr); // #8 if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Node #"+IntegerToString(i+1)+ // #9 " array values = "+arr_str); } } //--- check next-nodes for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { int t_arr[]; // destination array CiUnrollDoubleNode *p_udNode_next=p_udNodes[j].GetNextNode(); // #10 bool isCopied=p_udNode_next.GetArrVal(t_arr); if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Next-Node #"+IntegerToString(j+1)+ " array values = "+arr_str); } } //--- check prev-nodes for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { int t_arr[]; // destination array CiUnrollDoubleNode *p_udNode_prev=p_udNodes[j+1].GetPrevNode(); // #11 bool isCopied=p_udNode_prev.GetArrVal(t_arr); if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Prev-Node #"+IntegerToString(j+2)+ " array values = "+arr_str); } } //--- delete nodes for(int i=0;i<ArraySize(p_udNodes);i++) delete p_udNodes[i]; // #12 }
El número de las cadenas del código ha crecido un poco. Eso se debe a la necesidad de crear y llenar el array para cada uno de los nodos.
El trabajo con los arrays de datos empieza en la cadena #1. Básicamente, tenemos lo mismo que pasaba con los nodos anteriores. Lo único que ahora tendremos que imprimir los valores de datos de cada nodo para el array entero (por ejemplo, la cadena #9).
Es lo que me ha salido:
IN 0 00:09:13 test_nodes (EURUSD.m,H4) Node #1 value = 15 NF 0 00:09:13 test_nodes (EURUSD.m,H4) Node #2 value = 15 CI 0 00:09:13 test_nodes (EURUSD.m,H4) Node #3 value = 15 FQ 0 00:09:13 test_nodes (EURUSD.m,H4) Node #1 array values = 31784, 4837, 25797, 29079, 4223, 27234, 2155, 32351, 12010, 10353, 10391, 22245, 27895, 3918, 12069 EG 0 00:09:13 test_nodes (EURUSD.m,H4) Node #2 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756 MK 0 00:09:13 test_nodes (EURUSD.m,H4) Node #3 array values = 18100, 26358, 31020, 23881, 11256, 24798, 31481, 14567, 13032, 4701, 21665, 1434, 1622, 16377, 25778 RP 0 00:09:13 test_nodes (EURUSD.m,H4) Next-Node #1 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756 JD 0 00:09:13 test_nodes (EURUSD.m,H4) Next-Node #2 array values = 18100, 26358, 31020, 23881, 11256, 24798, 31481, 14567, 13032, 4701, 21665, 1434, 1622, 16377, 25778 EH 0 00:09:13 test_nodes (EURUSD.m,H4) Prev-Node #2 array values = 31784, 4837, 25797, 29079, 4223, 27234, 2155, 32351, 12010, 10353, 10391, 22245, 27895, 3918, 12069 NN 0 00:09:13 test_nodes (EURUSD.m,H4) Prev-Node #3 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756
Pues, propongo terminar con los nodos y pasar directamente a la definición de las clases de diferentes listas. Los ejemplos 1-3 se encuentran en el script test_nodes.mq5.
2.4 Lista simplemente enlazada
Ha llegado el momento para que hagamos el modelo de la clase de la lista simplemente enlazada usando los grupos de operaciones principales (Fig. 9).

Fig.9 Modelo de la clase CiSingleList
Es fácil de notar que la clase CiSingleList utiliza el nodo del tipo CiSingleNode. Hablando de los tipos de relaciones entre las clases, podemos decir que:
- la clase CiSingleList incluye la clase CiSingleNode (composición);
- la clase CiSingleList utiliza los métodos de la clase CiSingleNode (dependencia).
El esquema de relaciones mencionadas se muestra en la Fig. 10.

Fig.10 Tipos de relaciones entre la clase CiSingleList y CiSingleNode
Vamos a crear la nueva clase CiSingleList. Adelantándose, quiero decir que esta clase va a servir de base para todas las clases de la lista utilizadas en este artículo. Por eso es tan «cargado».
//+------------------------------------------------------------------+ //| Clase CiSingleList | //+------------------------------------------------------------------+ class CiSingleList { protected: CiSingleNode *m_head; // cabeza CiSingleNode *m_tail; // cola uint m_size; // número de nodos en la lista public: //--- constructor y destructor void CiSingleList(); // constructor por defecto void CiSingleList(int _node_val); // constructor paramétrico void ~CiSingleList(); // destructor //--- añadir nodos void AddFront(int _node_val); // nuevo nodo al principio de la lista void AddRear(int _node_val); // nuevo nodo al final de la lista virtual void AddFront(int &_node_arr[]){TRACE_CALL(_t_flag)}; // nuevo nodo al principio de la lista virtual void AddRear(int &_node_arr[]){TRACE_CALL(_t_flag)}; // nuevo nodo al final de la lista //--- eliminar nodos int RemoveFront(void); // eliminar el nodo de cabeza int RemoveRear(void); // eliminar el nodo de cola void DeleteNodeByIndex(const uint _idx); // eliminar el nodo i en la lista //--- prueba virtual bool Find(const int _node_val) const; // buscar valor especificado bool IsEmpty(void) const; // comprobar si la lista está vacía virtual int GetValByIndex(const uint _idx) const; // valor del nodo i de la lista virtual CiSingleNode *GetNodeByIndex(const uint _idx) const; // obtener el nodo i en la lista virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insertar nuevo nodo i en la lista CiSingleNode *GetHeadNode(void) const; // obtener el nodo de cabeza CiSingleNode *GetTailNode(void) const; // obtener el nodo de cola virtual uint Size(void) const; // tamaño de la lista //--- servicio virtual void PrintList(string _caption=NULL); // imprimir la lista virtual bool CopyByValue(const CiSingleList &_sList); // copiado de la lista por valores virtual void BubbleSort(void); // ordenación por método de la burbuja //---plantillas template<typename dPointer> bool CheckDynamicPointer(dPointer &_p); // plantilla de comprobación del puntero dinámico template<typename dPointer> bool DeleteDynamicPointer(dPointer &_p); // plantilla de eliminación del puntero dinámico protected: void operator=(const CiSingleList &_sList) const; // operador de asignación void CiSingleList(const CiSingleList &_sList); // constructor de copiado virtual bool AddToEmpty(int _node_val); // insertar nuevo nodo en la lista vacía virtual void addFront(int _node_val); // nuevo nodo "nativo" al principio de la lista virtual void addRear(int _node_val); // nuevo nodo "nativo" al finalde la lista virtual int removeFront(void); // eliminar nodo "nativo" de cabeza virtual int removeRear(void); // eliminar nodo "nativo" del final de la lista virtual void deleteNodeByIndex(const uint _idx); // eliminar nodo "nativo" número i de la lista virtual CiSingleNode *newNode(int _val); // nuevo nodo "nativo" virtual void CalcSize(void) const; // calcular el tamaño de la lista };
La descripción completa de los métodos de la clase se encuentra en el archivo CiSingleList.mqh.
Cuando estaba desarrollando esta clase, al principio había sólo 3 miembros de datos y apenas algunos métodos. En vista de que esta clase sirve de base para las demás, he tenidos que añadir unas funciones miembro virtuales. No voy poner la descripción detallada de los métodos. En el script test_sList.mq5 se puede ver el ejemplo del uso de esta clase de la lista simplemente enlazada.
Si lo inicia sin la bandera de emplazamiento (trace flag), en el log aparecerán las siguientes entradas:
KG 0 12:58:32 test_sList (EURUSD,H1) =======List #1======= PF 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=14 RL 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=666 MD 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=13 DM 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=11 QE 0 12:58:32 test_sList (EURUSD,H1) KN 0 12:58:32 test_sList (EURUSD,H1) LR 0 12:58:32 test_sList (EURUSD,H1) =======List #2======= RE 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=14 DQ 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=666 GK 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=13 FP 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=11 KF 0 12:58:32 test_sList (EURUSD,H1) MK 0 12:58:32 test_sList (EURUSD,H1) PR 0 12:58:32 test_sList (EURUSD,H1) =======renewed List #2======= GK 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=11 JP 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=13 JI 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=14 CF 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=34 QL 0 12:58:32 test_sList (EURUSD,H1) Node #5, val=35 OE 0 12:58:32 test_sList (EURUSD,H1) Node #6, val=36 MR 0 12:58:32 test_sList (EURUSD,H1) Node #7, val=37 KK 0 12:58:32 test_sList (EURUSD,H1) Node #8, val=38 MS 0 12:58:32 test_sList (EURUSD,H1) Node #9, val=666 OF 0 12:58:32 test_sList (EURUSD,H1) QK 0 12:58:32 test_sList (EURUSD,H1)
El script ha llenado dos listas simplemente enlazadas, luego ha ampliado y ha ordenado la segunda lista.
2.5 Lista doblemente enlazada
Intentaremos crear ahora una lista doblemente enlazada a base de la lista del tipo anterior. En la Fig. 11 se muestra el modelo de la clase de la lista doblemente enlazada:

Fig. 11 Modelo de la clase CDoubleList
La clase derivada (heredero) contiene menos métodos, y los miembros de datos no están presentes en absoluto. Abajo viene la definición de la clase CDoubleList.
//+------------------------------------------------------------------+ //| Clase CDoubleList | //+------------------------------------------------------------------+ class CDoubleList : public CiSingleList { public: void CDoubleList(void); // constructor por defecto void CDoubleList(int _node_val); // constructor paramétrico void ~CDoubleList(void){}; // destructor virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insertar nuevo nodo i en la lista protected: virtual bool AddToEmpty(int _node_val); // insertar nuevo nodo en la lista vacía virtual void addFront(int _node_val); // nuevo nodo "nativo" al principio de la lista virtual void addRear(int _node_val); // nuevo nodo "nativo" al final de la lista virtual int removeFront(void); // eliminar nodo "nativo" de la cabeza virtual int removeRear(void); // eliminar nodo "nativo" de la cola virtual void deleteNodeByIndex(const uint _idx); // eliminar nodo "nativo" número i en la lista virtual CiSingleNode *newNode(int _node_val); // nuevo nodo "nativo" };
La descripción completa de los métodos de la clase CDoubleList se encuentra en el archivo CDoubleList.mqh.
Hablando en general, las funciones virtuales se utilizan aquí sólo para servir a las necesidades del puntero al nodo anterior que no está presente en la lista simplemente enlazada.
El ejemplo del uso de la lista del tipo CDoubleList se puede encontrar en el script test_dList.mq5. Ahí se demuestran todas las operaciones comunes con las listas de este tipo. El código del script contiene una cadena muy interesante:
CiSingleNode *_new_node=new CDoubleNode(666); // crear nuevo nodo del tipo CDoubleNode
No habrá ningún error porque esta construcción es totalmente aceptable en el caso cuando el puntero de la clase base describe un objeto de la clase derivada. En eso consiste una de las ventajas de la herencia.
En MQL5, igual que en С++, el puntero a la clase base puede apuntar a un objeto de la subclase derivada de esta clase base. Pero la construcción inversa será incorrecta.
Si escribimos la cadena de la siguiente manera:
CDoubleNode*_new_node=new CiSingleNode(666);
el compilador no va a poner pegas o informar sobre el error, y el programa va a funcionar hasta que se encuentre precisamente con esta cadena. En este caso saltará un mensaje sobre la conversión errónea de tipos a los que hacen referencia los punteros. Puesto que el mecanismo de vinculación tardía se pone en acción sólo en la fase de ejecución del programa, hay que prestar mucha atención a la jerarquía de las relaciones entre las clases.
Después de iniciar el script, veremos las siguientes entras en el log:
DN 0 13:10:57 test_dList (EURUSD,H1) =======List #1======= GO 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=14 IE 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=666 FM 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=13 KD 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=11 JL 0 13:10:57 test_dList (EURUSD,H1) DG 0 13:10:57 test_dList (EURUSD,H1) CK 0 13:10:57 test_dList (EURUSD,H1) =======List #2======= IL 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=14 KH 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=666 PR 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=13 MI 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=11 DO 0 13:10:57 test_dList (EURUSD,H1) FR 0 13:10:57 test_dList (EURUSD,H1) GK 0 13:10:57 test_dList (EURUSD,H1) =======renewed List #2======= PR 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=11 QI 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=13 QP 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=14 LO 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=34 JE 0 13:10:57 test_dList (EURUSD,H1) Node #5, val=35 HL 0 13:10:57 test_dList (EURUSD,H1) Node #6, val=36 FK 0 13:10:57 test_dList (EURUSD,H1) Node #7, val=37 DR 0 13:10:57 test_dList (EURUSD,H1) Node #8, val=38 FJ 0 13:10:57 test_dList (EURUSD,H1) Node #9, val=666 HO 0 13:10:57 test_dList (EURUSD,H1) JR 0 13:10:57 test_dList (EURUSD,H1)
Igual que en el caso con la lista enlazada simple, el script ha llenado la primera lista (doblemente enlazada), ha hecho su copia y la ha pasado a la segunda lista. Luego ha aumentado el número de nodos en la segunda lista, ha ordenado y ha imprimido la lista.
2.6 Lista doblemente enlazada usando nodos de arrays
Esta lista es bastante cómoda porque permite guardar en su nodo no sólo un valor cualquiera, sino un array entero.
Creamos la base para la lista del tipo CiUnrollDoubleList (Fig. 12).

Fig. 12 Modelo de la clase CiUnrollDoubleList
Aquí, puesto que vamos a tratar un array de datos, tendremos que redefinir los métodos que han sido definidos antes en la clase base indirecta CiSingleList.
Tenemos la siguiente definición de la clase CiUnrollDoubleList.
//+------------------------------------------------------------------+ //| Clase CiUnrollDoubleList | //+------------------------------------------------------------------+ class CiUnrollDoubleList : public CDoubleList { public: void CiUnrollDoubleList(void); // constructor por defecto void CiUnrollDoubleList(int &_node_arr[]); // constructor paramétrico void ~CiUnrollDoubleList(void){TRACE_CALL(_t_flag)}; // destructor //--- virtual void AddFront(int &_node_arr[]); // nuevo nodo al principio de la lista virtual void AddRear(int &_node_arr[]); // nuevo nodo al final de la lista virtual bool CopyByValue(const CiSingleList &_udList); // copiado por valores virtual void PrintList(string _caption=NULL); // imprimir la lista virtual void BubbleSort(void); // ordenación por método de la burbuja protected: virtual bool AddToEmpty(int &_node_arr[]); // insertar nodo en la lista vacía virtual void addFront(int &_node_arr[]); // nuevo nodo "nativo" al principio de la lista virtual void addRear(int &_node_arr[]); // nuevo nodo "nativo" al final de la lista virtual int removeFront(void); // eliminar nodo "nativo" del principio de la lista virtual int removeRear(void); // eliminar nodo "nativo" del final de la lista virtual void deleteNodeByIndex(const uint _idx); // eliminar nodo "nativo" con el número i en la lista virtual CiSingleNode *newNode(int &_node_arr[]); // nuevo nodo "nativo" };
La descripción completa de los métodos de la clase se encuentra en el archivo CiUnrollDoubleList.mqh.
Iniciamos el script test_UdList.mq5 para ver cómo funcionan los métodos de la clase. Aquí las operaciones con los nodos son las mismas que han sido utilizadas en los scripts anteriores. Tal vez habría que decir unas palabras aparte sobre los métodos de ordenación e impresión. El método de ordenación ordena los nodos según el número de elementos. El nodo que contiene el array de valores de menor tamaño se pone a la cabeza de la lista.
El método de impresión se encarga de visualizar (imprimir) en una cadena los valores del array que forma parte de un cierto nodo.
Después de iniciar el script, veremos las siguientes entras en el log:
II 0 13:22:23 test_UdList (EURUSD,H1) =======List #1======= FN 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 OO 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 GG 0 13:22:23 test_UdList (EURUSD,H1) GP 0 13:22:23 test_UdList (EURUSD,H1) GR 0 13:22:23 test_UdList (EURUSD,H1) =======List #2 before sorting======= JO 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 CH 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 CF 0 13:22:23 test_UdList (EURUSD,H1) List node #3, array: -89, -131, -141, -139, -129, -25, -105, -24, -122, -120, -118, -116, -114, -112, -110 GD 0 13:22:23 test_UdList (EURUSD,H1) GQ 0 13:22:23 test_UdList (EURUSD,H1) LJ 0 13:22:23 test_UdList (EURUSD,H1) =======List #2 after sorting======= FN 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 CJ 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 II 0 13:22:23 test_UdList (EURUSD,H1) List node #3, array: -89, -131, -141, -139, -129, -25, -105, -24, -122, -120, -118, -116, -114, -112, -110 MD 0 13:22:23 test_UdList (EURUSD,H1) MQ 0 13:22:23 test_UdList (EURUSD,H1)
Como podemos ver, después de la ordenación la lista udList2 imprime del nodo con el menor tamaño del array hasta el nodo con el mayor tamaño.
2.7 Lista circular doblemente enlazada
Las listas no lineales no se consideran en este artículo, pero a pesar de eso vamos a trabajar con ellas también. Cómo se hace el ciclo de los nodos ha sido mostrado en el diagrama de arriba (Fig. 3).
Creamos el modelo de la clase CiCircleDoubleList (Fig. 13). Esta clase va a ser heredero de la clase CDoubleList.

Fig. 13 Modelo de la clase CiCircleDoubleList
Puesto que los nodos en esta lista tienen un carácter específico (la cabeza y la cola están enlazadas), tendremos que hacer virtuales casi todos los métodos de la clase base CiSingleList.
//+------------------------------------------------------------------+ //| Clase CiCircleDoubleList | //+------------------------------------------------------------------+ class CiCircleDoubleList : public CDoubleList { public: void CiCircleDoubleList(void); // constructor por defecto void CiCircleDoubleList(int _node_val); // constructor paramétrico void ~CiCircleDoubleList(void){TRACE_CALL(_t_flag)}; // destructor //--- virtual uint Size(void) const; // tamaño de la lista virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insertamos el nuevo nodo i en la lista virtual int GetValByIndex(const uint _idx) const; // el valor del nodo i en la lista virtual CiSingleNode *GetNodeByIndex(const uint _idx) const; // obtener el nodo i en la lista virtual bool Find(const int _node_val) const; // buscar el valor establecido virtual bool CopyByValue(const CiSingleList &_sList); // copiado de la lista por valores protected: virtual void addFront(int _node_val); // nuevo nodo "nativo" al principio de la lista virtual void addRear(int _node_val); // nuevo nodo "nativo" al final de la lista virtual int removeFront(void); // eliminar el nodo "nativo" de la cabeza virtual int removeRear(void); // eliminar el nodo "nativo" de la cola virtual void deleteNodeByIndex(const uint _idx); // eliminar el nodo "nativo" i en la lista protected: void CalcSize(void) const; // calcular el tamaño de la lista void LinkHeadTail(void); // enlazar la cabeza con la cola };
La descripción completa de la clase se encuentra en el archivo CiCircleDoubleList.mqh.
Vamos a ver algunos métodos de la clase. El método CiCircleDoubleList::LinkHeadTail() se encarga de enlazar el nodo de la cabeza con el de la cola. Se puede llamarlo cuando aparece la nueva cabeza o la cola, y el enlace anterior se pierde.
//+------------------------------------------------------------------+ //| Enlazar la cabeza con la cola | //+------------------------------------------------------------------+ void CiCircleDoubleList::LinkHeadTail(void) { TRACE_CALL(_t_flag) this.m_head.SetPrevNode(this.m_tail); // enlace de la cabeza con la cola this.m_tail.SetNextNode(this.m_head); // enlace de la cola con la cabeza }
Piense en cómo sería este método si trataramos con una lista circular simplemente enlazada.
Veremos, por ejemplo, el método CiCircleDoubleList::addFront().
//+------------------------------------------------------------------+ //| Nuevo nodo "nativo" al principio de la lista | //+------------------------------------------------------------------+ void CiCircleDoubleList::addFront(int _node_val) { TRACE_CALL(_t_flag) CDoubleList::addFront(_node_val); // llamada al método similar de la clase base this.LinkHeadTail(); // enlazar la cabeza y la cola }
Podemos ver que en el cuerpo del método se invoca el mismo método de la clase base CDoubleList. Con eso podríamos terminar el trabajo del método (prácticamente, aquí el método es innecesario) si no hubiera un "pero". Entre la cabeza y la cola se pierde el enlazamiento, y sin ella la lista no será circular. Por eso tenemos que llamar al método de enlazamiento de la cabeza y la coal.
El trabajo con la lista circular doblemente enlazada se verifica en el script test_UdList.mq5.
En términos de las tareas y objetivos, se utilizan los mismos métodos que han sido utilizados en los ejemplos anteriores.
Como resultado, veremos en el log las siguientes entradas:
PR 0 13:34:29 test_CdList (EURUSD,H1) =======List #1======= QS 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=14 QI 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=666 LQ 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=13 OH 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=11 DP 0 13:34:29 test_CdList (EURUSD,H1) DK 0 13:34:29 test_CdList (EURUSD,H1) DI 0 13:34:29 test_CdList (EURUSD,H1) =======List #2 before sorting======= MS 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=38 IJ 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=37 IQ 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=36 EH 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=35 EO 0 13:34:29 test_CdList (EURUSD,H1) Node #5, val=34 FF 0 13:34:29 test_CdList (EURUSD,H1) Node #6, val=14 DN 0 13:34:29 test_CdList (EURUSD,H1) Node #7, val=666 GD 0 13:34:29 test_CdList (EURUSD,H1) Node #8, val=13 JK 0 13:34:29 test_CdList (EURUSD,H1) Node #9, val=11 JM 0 13:34:29 test_CdList (EURUSD,H1) JH 0 13:34:29 test_CdList (EURUSD,H1) MS 0 13:34:29 test_CdList (EURUSD,H1) =======List #2 after sorting======= LE 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=11 KL 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=13 QS 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=14 NJ 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=34 NQ 0 13:34:29 test_CdList (EURUSD,H1) Node #5, val=35 NH 0 13:34:29 test_CdList (EURUSD,H1) Node #6, val=36 NO 0 13:34:29 test_CdList (EURUSD,H1) Node #7, val=37 NF 0 13:34:29 test_CdList (EURUSD,H1) Node #8, val=38 JN 0 13:34:29 test_CdList (EURUSD,H1) Node #9, val=666 RJ 0 13:34:29 test_CdList (EURUSD,H1) RE 0 13:34:29 test_CdList (EURUSD,H1)
En fin, el diagrama final de la herencia entre las clases de las listas presentadas se ve de la siguiente manera (Fig. 14).
No estoy seguro de que merece la pena relacionar todas las clases entre sí con las relaciones de la herencia, pero he decidido dejarlo tal como está.

Fig. 14 Herencia entre las clases de las listas
Terminando este apartado del artículo en el que han sido mostradas las listas personalizadas, me gustaría señalar que no hemos tocado prácticamente el grupo de las listas no lineales, las multilistas, etc. Según vaya acumulando el material y la experiencia de trabajo con este tipo de estructuras dinámicas, intentaré escribir otro artículo.
3. Listas en la Librería estándar MQL5
Echemos un vistazo a la clase de listas que está disponible en la Librería estándar (Fig. 15).
Pertenece a la sección Clases para organización de datos (Data Structures).

Fig. 15 Modelo de la clase CList
Es curioso que la clase CList se deriva de la clase CObject. Es decir, la lista hereda los datos y los métodos de la clase que figura como nodo.
La clase de listas contiene un importante conjunto de métodos. La verdad es que no esperaba encontrar una clase tan grande en la Librería estándar.
La clase CList tiene 8 miembros de datos. Me gustaría remarcar unos momentos. Los atributos de la clase contienen el índice del nodo actual (int m_curr_idx) y el puntero al nodo actual (CObject* m_curr_node). Podemos decir que la lista es «inteligente»: puede indicar el lugar en el que está localizado el control. Además, consta de las siguientes herramientas: mecanismo de trabajo con la memoria (podemos eliminar el nodo físicamente o simplemente excluirlo de la lista), bandera de la lista ordenada, modo de ordenación de la lista.
En cuanto a los métodos, todos los métodos de la clase CList se dividen en siguientes grupos:
- atributos;
- creación del nuevo elemento;
- inserción;
- eliminación;
- navegación;
- desplazamiento de elementos;
- comparación;
- búsqueda;
- entrada/salida.
Hay un constructor y un destructor estándar.
El primero vacía (NULL) todos los punteros. La bandera de control de la memoria se pone en la posición «eliminar físicamente». La nueva lista no estará ordenada.
El destructor en su cuerpo sólo llama al método Clear() y vacía la lista de los nodos. No siempre el fin de la existencia de la lista tiene que provocar la «muerte» de sus elementos (nodos). De esta manera, el establecimiento de la bandera de control de la memoria, a la hora de eliminar los elementos de la lista, produce que le relación «composición» entre las clases se convierte en la relación «agregación».
Pues, podemos manejar esta bandera usando los métodos set y get de FreeMode().
En la clase hay 2 métodos que permiten aumentar la lista: Add() y Insert(). El primero parece al método AddRear() que he utilizado en la primera sección del artículo, y el segundo parece al método SetNodeByIndex().
Empezamos nuestro trabajo con un pequeño ejemplo. Pero primero tenemos que crear la clase del nodo CNodeInt que se deriva de la clase de interfaz CObject. Vamos a almacenar en él los valores del tipo integer.
//+------------------------------------------------------------------+ //| Clase CNodeInt | //+------------------------------------------------------------------+ class CNodeInt : public CObject { private: int m_val; // datos del nodo public: void CNodeInt(void){this.m_val=WRONG_VALUE;}; // constructor por defecto void CNodeInt(int _val); // constructor paramétrico void ~CNodeInt(void){}; // destructor int GetVal(void){return this.m_val;}; // método get para los datos del nodo void SetVal(int _val){this.m_val=_val;}; // método set para los datos del nodo }; //+------------------------------------------------------------------+ //| Constructor paramétrico | //+------------------------------------------------------------------+ void CNodeInt::CNodeInt(int _val):m_val(_val) { };
De esta forma, vamos a trabajar con la lista CList en el script test_MQL5_List.mq5.
En el Ejemplo 1 la lista y los nodos se crean de forma dinámica. Luego los nodos llenan la lista, se comprueban los valores del primer nodo antes y después de la eliminación de la lista.
//--- Example 1 (testing memory management) CList *myList=new CList; // myList.FreeMode(false); // reset flag bool _free_mode=myList.FreeMode(); PrintFormat("\nList \"myList\" - memory management flag: %d",_free_mode); CNodeInt *p_new_nodes_int[10]; p_new_nodes_int[0]=NULL; for(int i=0;i<ArraySize(p_new_nodes_int);i++) { p_new_nodes_int[i]=new CNodeInt(rand()); myList.Add(p_new_nodes_int[i]); } PrintFormat("List \"myList\" has as much nodes as: %d",myList.Total()); Print("=======Before deleting \"myList\"======="); PrintFormat("The 1st node value is: %d",p_new_nodes_int[0].GetVal()); delete myList; int val_to_check=WRONG_VALUE; if(CheckPointer(p_new_nodes_int[0])) val_to_check=p_new_nodes_int[0].GetVal(); Print("=======After deleting \"myList\"======="); PrintFormat("The 1st node value is: %d",val_to_check);
Si la cadena de reinicio de la bandera se queda sin comentar (inactiva), en el log aparecen las siguientes entradas:
GS 0 14:00:16 test_MQL5_List (EURUSD,H1) EO 0 14:00:16 test_MQL5_List (EURUSD,H1) List "myList" - memory management flag: 1 FR 0 14:00:16 test_MQL5_List (EURUSD,H1) List "myList" has as much nodes as: 10 JH 0 14:00:16 test_MQL5_List (EURUSD,H1) =======Before deleting "myList"======= DO 0 14:00:16 test_MQL5_List (EURUSD,H1) The 1st node value is: 7189 KJ 0 14:00:16 test_MQL5_List (EURUSD,H1) =======After deleting "myList"======= QK 0 14:00:16 test_MQL5_List (EURUSD,H1) The 1st node value is: -1
Quiero indicar que la eliminación dinámica de la lista myList provoca la eliminación física de todos los nodos de la memoria.
Pero si descomentamos la cadena:
// myList.FreeMode(false); // reset flagel resultado en el log será el siguiente:
NS 0 14:02:11 test_MQL5_List (EURUSD,H1) CN 0 14:02:11 test_MQL5_List (EURUSD,H1) List "myList" - memory management flag: 0 CS 0 14:02:11 test_MQL5_List (EURUSD,H1) List "myList" has as much nodes as: 10 KH 0 14:02:11 test_MQL5_List (EURUSD,H1) =======Before deleting "myList"======= NL 0 14:02:11 test_MQL5_List (EURUSD,H1) The 1st node value is: 20411 HJ 0 14:02:11 test_MQL5_List (EURUSD,H1) =======After deleting "myList"======= LI 0 14:02:11 test_MQL5_List (EURUSD,H1) The 1st node value is: 20411 QQ 1 14:02:11 test_MQL5_List (EURUSD,H1) 10 undeleted objects left DD 1 14:02:11 test_MQL5_List (EURUSD,H1) 10 objects of type CNodeInt left DL 1 14:02:11 test_MQL5_List (EURUSD,H1) 400 bytes of leaked memory
No resulta difícil de notar que antes de la eliminación de la lista y después, el nodo que se encuentra y se encontraba en la cabeza no pierde su valor. En este caso, quedarán objetos sin eliminar si el script no va a contener el código que procese su correcta eliminación.
Ahora vamos a probar el método de ordenación.
//--- Example 2 (sorting) CList *myList=new CList; CNodeInt *p_new_nodes_int[10]; p_new_nodes_int[0]=NULL; for(int i=0;i<ArraySize(p_new_nodes_int);i++) { p_new_nodes_int[i]=new CNodeInt(rand()); myList.Add(p_new_nodes_int[i]); } PrintFormat("\nList \"myList\" has as much nodes as: %d",myList.Total()); Print("=======List \"myList\" before sorting======="); for(int i=0;i<myList.Total();i++) { CNodeInt *p_node_int=myList.GetNodeAtIndex(i); int node_val=p_node_int.GetVal(); PrintFormat("Node #%d is equal to: %d",i+1,node_val); } myList.Sort(0); Print("\n=======List \"myList\" after sorting======="); for(int i=0;i<myList.Total();i++) { CNodeInt *p_node_int=myList.GetNodeAtIndex(i); int node_val=p_node_int.GetVal(); PrintFormat("Node #%d is equal to: %d",i+1,node_val); } delete myList;
El log contiene las siguientes entradas:
OR 0 22:47:01 test_MQL5_List (EURUSD,H1) FN 0 22:47:01 test_MQL5_List (EURUSD,H1) List "myList" has as much nodes as: 10 FH 0 22:47:01 test_MQL5_List (EURUSD,H1) =======List "myList" before sorting======= LG 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #1 is equal to: 30511 CO 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #2 is equal to: 17404 GF 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #3 is equal to: 12215 KQ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #4 is equal to: 31574 NJ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #5 is equal to: 7285 HP 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #6 is equal to: 23509 IH 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #7 is equal to: 26991 NS 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #8 is equal to: 414 MK 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #9 is equal to: 18824 DR 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #10 is equal to: 1560 OR 0 22:47:01 test_MQL5_List (EURUSD,H1) OM 0 22:47:01 test_MQL5_List (EURUSD,H1) =======List "myList" after sorting======= QM 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #1 is equal to: 26991 RE 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #2 is equal to: 23509 ML 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #3 is equal to: 18824 DD 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #4 is equal to: 414 LL 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #5 is equal to: 1560 IG 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #6 is equal to: 17404 PN 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #7 is equal to: 30511 II 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #8 is equal to: 31574 OQ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #9 is equal to: 12215 JH 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #10 is equal to: 7285
Si al fin y al cabo se ha realizado alguna ordenación, su metodología se ha quedado bastante misteriosa para mí. Y el asunto es el siguiente. No voy a entrar en los detalles del orden de la llamada pero el método CList::Sort() llama al método virtual CObject::Compare() que no está implementado de ninguna manera en la clase base. Entonces, el mismo programador tiene que encargarse de la implementación del método de ordenación.
Algunas palabras sobre el método Total(). Él devuelve el número de elementos (nodos) del que se responsabiliza el miembro de datos m_data_total. Es un método muy corto y conciso. En esta versión el recuento de elementos va a funcionar mucho más rápido en comparación con la versión que he propuesto yo. Efectivamente, para qué tenemos que recorrer cada vez la lista y contar los nodos si el número exacto de los nodos podemos establecer al añadir o eliminar los nodos.
El Ejemplo 3 nos muestra la comparación de la velocidad de relleno de la lista del tipo CList y CiSingleList. Además, se calcula el tiempo en que se tarda obtener el tamaño de cada lista.
//--- Example 3 (nodes number) int iterations=1e7; // 10 million iterations //--- the new CList CList *p_mql_List=new CList; uint start=GetTickCount(); // starting value for(int i=0;i<iterations;i++) { CNodeInt *p_node_int=new CNodeInt(rand()); p_mql_List.Add(p_node_int); } uint time=GetTickCount()-start; // spent time, msec Print("\n=======the CList type list======="); PrintFormat("Filling the list of %.3e nodes has taken %d msec",iterations,time); //--- get the size start=GetTickCount(); int list_size=p_mql_List.Total(); time=GetTickCount()-start; PrintFormat("Getting the size of the list has taken %d msec",time); delete p_mql_List; //--- the new CiSingleList CiSingleList *p_sList=new CiSingleList; start=GetTickCount(); // starting value for(int i=0;i<iterations;i++) p_sList.AddRear(rand()); time=GetTickCount()-start; // spent time, msec Print("\n=======the CiSingleList type list======="); PrintFormat("Filling the list of %.3e nodes has taken %d msec",iterations,time); //--- get the size start=GetTickCount(); list_size=(int)p_sList.Size(); time=GetTickCount()-start; PrintFormat("Getting the size of the list has taken %d msec",time); delete p_sList;
Es lo que me ha salido en el log:
KO 0 22:48:24 test_MQL5_List (EURUSD,H1) CK 0 22:48:24 test_MQL5_List (EURUSD,H1) =======the CList type list======= JL 0 22:48:24 test_MQL5_List (EURUSD,H1) Filling the list of 1.000e+007 nodes has taken 2606 msec RO 0 22:48:24 test_MQL5_List (EURUSD,H1) Getting the size of the list has taken 0 msec LF 0 22:48:29 test_MQL5_List (EURUSD,H1) EL 0 22:48:29 test_MQL5_List (EURUSD,H1) =======the CiSingleList type list======= KK 0 22:48:29 test_MQL5_List (EURUSD,H1) Filling the list of 1.000e+007 nodes has taken 2356 msec NF 0 22:48:29 test_MQL5_List (EURUSD,H1) Getting the size of the list has taken 359 msec
El método del obtención del tamaño en la lista CList funciona momentáneamente. Por cierto, la inserción de los nodos en la lista también se hace bastante rápido.
En el siguiente bloque (Ejemplo 4) quiero que preste atención a una de las mayores desventajas del contenedor de datos como la lista: se trata de la velocidad de acceso a los elementos. Es que el acceso a los elementos de la lista se realiza de forma lineal, y en caso de la clase de listas CList este acceso se hace con un coeficiente reducido (N/2), lo que a su vez reduce la intensidad en el uso del algoritmo.
Durante la búsqueda lineal, la intensidad en el uso es O(N).
Éste es el ejemplo del código para el acceso a los elementos del conjunto de datos:
//--- Example 4 (speed of accessing the node) const uint Iter_arr[]={1e3,3e3,6e3,9e3,1e4,3e4,6e4,9e4,1e5,3e5,6e5}; for(uint i=0;i<ArraySize(Iter_arr);i++) { const uint cur_iterations=Iter_arr[i]; // iterations number uint randArr[]; // randoms array uint idxArr[]; // indexes array //--- set the arrays size ArrayResize(randArr,cur_iterations); ArrayResize(idxArr,cur_iterations); CRandom myRand; // randoms generator //--- fill the randoms array for(uint t=0;t<cur_iterations;t++) randArr[t]=myRand.int32(); //--- fill the indexes array with the randoms (from 0 to 10 million) int iter_log10=(int)log10(cur_iterations); for(uint r=0;r<cur_iterations;r++) { uint rand_val=myRand.int32(); // random value (from 0 to 4 294 967 295) if(rand_val>=cur_iterations) { int val_log10=(int)log10(rand_val); double log10_remainder=val_log10-iter_log10; rand_val/=(uint)pow(10,log10_remainder+1); } //--- check the limit if(rand_val>=cur_iterations) { Alert("Random value error!"); return; } idxArr[r]=rand_val; } //--- time spent for the array uint start=GetTickCount(); //--- accessing the array elements for(uint p=0;p<cur_iterations;p++) uint random_val=randArr[idxArr[p]]; uint time=GetTickCount()-start; // spent time, msec Print("\n=======the uint type array======="); PrintFormat("Random accessing the array of elements %.1e has taken %d msec",cur_iterations,time); //--- the CList type list CList *p_mql_List=new CList; //--- fill the list for(uint q=0;q<cur_iterations;q++) { CNodeInt *p_node_int=new CNodeInt(randArr[q]); p_mql_List.Add(p_node_int); } start=GetTickCount(); //--- accessing the list nodes for(uint w=0;w<cur_iterations;w++) CNodeInt *p_node_int=p_mql_List.GetNodeAtIndex(idxArr[w]); time=GetTickCount()-start; // spent time, msec Print("\n=======the CList type list======="); PrintFormat("Random accessing the list of nodes %.1e has taken %d msec",cur_iterations,time); //--- free the memory ArrayFree(randArr); ArrayFree(idxArr); delete p_mql_List; }
Basándose en los resultados de trabajo de este bloque, en el log se imprimen las siguientes entradas:
MR 0 22:51:22 test_MQL5_List (EURUSD,H1) QL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= IG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+003 has taken 0 msec QF 0 22:51:22 test_MQL5_List (EURUSD,H1) IQ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= JK 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+003 has taken 0 msec MJ 0 22:51:22 test_MQL5_List (EURUSD,H1) QD 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= GO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+003 has taken 0 msec QN 0 22:51:22 test_MQL5_List (EURUSD,H1) II 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= EP 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+003 has taken 16 msec OR 0 22:51:22 test_MQL5_List (EURUSD,H1) OL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= FG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+003 has taken 0 msec CF 0 22:51:22 test_MQL5_List (EURUSD,H1) GQ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= CH 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+003 has taken 31 msec QJ 0 22:51:22 test_MQL5_List (EURUSD,H1) MD 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= MO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 9.0e+003 has taken 0 msec EN 0 22:51:22 test_MQL5_List (EURUSD,H1) MJ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= CP 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 9.0e+003 has taken 47 msec CR 0 22:51:22 test_MQL5_List (EURUSD,H1) KL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= JG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+004 has taken 0 msec GF 0 22:51:22 test_MQL5_List (EURUSD,H1) KR 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= MK 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+004 has taken 343 msec GJ 0 22:51:22 test_MQL5_List (EURUSD,H1) GG 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= LO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+004 has taken 0 msec QO 0 22:51:24 test_MQL5_List (EURUSD,H1) MJ 0 22:51:24 test_MQL5_List (EURUSD,H1) =======the CList type list======= NP 0 22:51:24 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+004 has taken 1217 msec OS 0 22:51:24 test_MQL5_List (EURUSD,H1) KO 0 22:51:24 test_MQL5_List (EURUSD,H1) =======the uint type array======= CP 0 22:51:24 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+004 has taken 0 msec MG 0 22:51:26 test_MQL5_List (EURUSD,H1) ER 0 22:51:26 test_MQL5_List (EURUSD,H1) =======the CList type list======= PG 0 22:51:26 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+004 has taken 2387 msec GK 0 22:51:26 test_MQL5_List (EURUSD,H1) OG 0 22:51:26 test_MQL5_List (EURUSD,H1) =======the uint type array======= NH 0 22:51:26 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 9.0e+004 has taken 0 msec JO 0 22:51:30 test_MQL5_List (EURUSD,H1) NK 0 22:51:30 test_MQL5_List (EURUSD,H1) =======the CList type list======= KO 0 22:51:30 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 9.0e+004 has taken 3619 msec HS 0 22:51:30 test_MQL5_List (EURUSD,H1) DN 0 22:51:30 test_MQL5_List (EURUSD,H1) =======the uint type array======= RP 0 22:51:30 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+005 has taken 0 msec OD 0 22:52:05 test_MQL5_List (EURUSD,H1) GS 0 22:52:05 test_MQL5_List (EURUSD,H1) =======the CList type list======= DE 0 22:52:05 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+005 has taken 35631 msec NH 0 22:52:06 test_MQL5_List (EURUSD,H1) RF 0 22:52:06 test_MQL5_List (EURUSD,H1) =======the uint type array======= FI 0 22:52:06 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+005 has taken 0 msec HL 0 22:54:20 test_MQL5_List (EURUSD,H1) PD 0 22:54:20 test_MQL5_List (EURUSD,H1) =======the CList type list======= FN 0 22:54:20 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+005 has taken 134379 msec RQ 0 22:54:20 test_MQL5_List (EURUSD,H1) JI 0 22:54:20 test_MQL5_List (EURUSD,H1) =======the uint type array======= MR 0 22:54:20 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+005 has taken 15 msec NE 0 22:58:48 test_MQL5_List (EURUSD,H1) FL 0 22:58:48 test_MQL5_List (EURUSD,H1) =======the CList type list======= GE 0 22:58:48 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+005 has taken 267589 msec
Podemos observar que según vaya aumentando el tamaño de la lista, aumenta el tiempo de acceso aleatorio a los elementos de la lista (Fig. 16).

Fig. 16 El tiempo tardado para el acceso aleatorio a los elementos del array y de la lista
Ahora hablaremos sobre los métodos de guardar y cargar los datos.
En la clase base de listas CList estos métodos existen pero son virtuales. Por eso tendremos que realizar un pequeño trabajo preparatorio para poder probar su trabajo en un ejemplo.
Vamos a heredar las capacidades de la clase CList usando la clase derivada CIntList. La última va a tener sólo un método para crear el elemento nuevo CIntList::CreateElement().
//+------------------------------------------------------------------+ //| Clase CIntList | //+------------------------------------------------------------------+ class CIntList : public CList { public: virtual CObject *CreateElement(void); }; //+------------------------------------------------------------------+ //| Nuevo elemento de la lista | //+------------------------------------------------------------------+ CObject *CIntList::CreateElement(void) { CObject *new_node=new CNodeInt(); return new_node; }
Tenemos que añadir también los métodos virtuales CNodeInt::Save() y CNodeInt::Load() en el tipo derivado del nodo CNodeInt. Van a invocarse de las funciones miembro CList::Save() y CList::Load(), respectivamente.
Como resultado, tenemos el siguiente ejemplo (Ejemplo 5):
//--- Example 5 (saving list data) //--- the CIntList type list CList *p_int_List=new CIntList; int randArr[1000]; // randoms array ArrayInitialize(randArr,0); //--- fill the randoms array for(int t=0;t<1000;t++) randArr[t]=(int)myRand.int32(); //--- fill the list for(uint q=0;q<1000;q++) { CNodeInt *p_node_int=new CNodeInt(randArr[q]); p_int_List.Add(p_node_int); } //--- save the list into the file int file_ha=FileOpen("List_data.bin",FILE_WRITE|FILE_BIN); p_int_List.Save(file_ha); FileClose(file_ha); p_int_List.FreeMode(true); p_int_List.Clear(); //--- load the list from the file file_ha=FileOpen("List_data.bin",FILE_READ|FILE_BIN); p_int_List.Load(file_ha); int Loaded_List_size=p_int_List.Total(); PrintFormat("As much as many nodes loaded from the file: %d",Loaded_List_size); //--- free the memory delete p_int_List;
Una vez iniciado el script en el gráfico, en el log aparecerá la siguiente entrada:
ND 0 11:59:35 test_MQL5_List (EURUSD,H1) As many as 1000 nodes loaded from the file.
Así, hemos implementado los métodos de la entrada y salida para el miembro de datos del nodo tipo CNodeInt.
En la siguiente sección, verá los ejemplos de aplicación de las listas en su trabajo con el lenguaje MQL5 para resolver los problemas planteados.
4. Ejemplos del uso de las listas en MQL5
En la sección anterior, al considerar los métodos de la clase de listas CList de la Librería estándar, puse algunos ejemplos.
Ahora propongo a la atención del lector los casos cuando la lista se usa para resolver unos problemas específicos. Y aquí, no puedo sin mencionar otra vez más las ventajas que ofrece una lista como tipo de datos de contenedor. Podemos trabajar con el código de forma eficaz utilizando la flexibilidad de la lista.
4.1 Procesamiento de objetos gráficos
Imagínese que tenemos que crear los objetos gráficos de manera programada en el gráfico. Pueden ser objetos diferentes, y pueden aparecer en el gráfico por varias razones.
Me viene a la memoria un caso cuando fue precisamente la lista que me ayudó resolver una situación con objetos gráficos. Y ahora me gustaría compartir esta experiencia con Ustedes.
Tenía una tarea para crear unas línea verticales según la condición especificada. Según esta condición, las verticales limitaban un intervalo de tiempo determinado. Además, el intervalo de tiempo variaba de vez en cuando su duración. Aparte de eso, no siempre estaba completamente formado.
Yo estaba estudiando el comportamiento de la media móvil (EMA21), y para eso tenía que recopilar las estadísticas.
Particularmente, estaba interesado en la duración de inclinación de la media móvil (MA). Por ejemplo, para el movimiento descendiente el punto de inicio se identificaba así: se registraba el cambio negativo de la MA (es decir, reducción del valor) y se dibujaba la vertical. En la Fig. 17 para EURUSD, H1 este punto ha sido encontrado el 5 de septiembre de 2013 en el momento de apertura de la barra a las 16:00.

Рис.17 El primer punto del intervalo descendiente
El segundo punto que indicaba el final del movimiento descendiente se identificaba basándose en el principio inverso: se registraba el movimiento positivo de la MA, es decir, el aumento del valor (Fig. 18).

Рис.18 El segundo punto del intervalo descendiente
De esta manera, este intervalo empezaba el 5 de septiembre de 2013 a las 16:00 y se terminaba el 6 de septiembre de 2013 a las 17:00.
El sistema de búsqueda de diferentes intervalos se puede hacer más complejo o más sencillo. Aquí no se trata de eso. Lo que más importa es que esta técnica de trabajo con los objetos gráficos y recopilación de estadísticas concierne a una de las principales ventajas de la lista: flexibilidad de composición.
En cuanto al ejemplo en cuestión, para empezar he creado el nodo del tipo CVertLineNode que se encarga de 2 objetos gráficos "línea vertical".
La definición de la clase es la siguiente:
//+------------------------------------------------------------------+ //| Clase CVertLineNode | //+------------------------------------------------------------------+ class CVertLineNode : public CObject { private: SVertLineProperties m_vert_lines[2]; // array de estructuras de propiedades de la línea vertical uint m_duration; // duración de frames bool m_IsFrameFormed; // bandera de formación de frames public: void CVertLineNode(void); void ~CVertLineNode(void){}; //--- métodos set void SetLine(const SVertLineProperties &_vert_line,bool IsFirst=true); void SetDuration(const uint _duration){this.m_duration=_duration;}; void SetFrameFlag(const bool _frame_flag){this.m_IsFrameFormed=_frame_flag;}; //--- métodos get void GetLine(SVertLineProperties &_vert_line_out,bool IsFirst=true) const; uint GetDuration(void) const; bool GetFrameFlag(void) const; //--- trazado de líneas bool DrawLine(bool IsFirst=true) const; };
Básicamente, esta clase de nodo describe un frame (aquí yo interpreto este concepto como una cierta cantidad de velas limitadas por dos verticales). Los límites del frame están representados por dos estructuras de propiedades de la línea vertical, duración y la bandera de formación.
Además del constructor y destructor estándar, la clase tiene unos métodos set y get. También hay método para trazar la línea en el gráfico.
Bueno, permítanme volver a recordarles que el nodo de verticales (frame) en mi ejemplo puede considerarse formado cuando tenemos la primera vertical que registra el inicio del movimiento descendiente de la MA y la segunda que registra el inicio del movimiento ascendiente de la MA.
Usando el script Stat_collector.mq5, visualicé en el gráfico todos los frames y conté qué número de nodos (frames) correspondía a uno u otro límite de duración en las últimas 2 mil barras.
Como ejemplo creé 4 listas que podrían contener cualquier frame. La primera lista contenía los frames cuyo número de velas no superaba 5, la segunda - 10, la tercera - 15, la cuarta - sin límite.
NS 0 15:27:32 Stat_collector (EURUSD,H1) =======List #1======= RF 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 5 ML 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 65 HK 0 15:27:32 Stat_collector (EURUSD,H1) OO 0 15:27:32 Stat_collector (EURUSD,H1) =======List #2======= RI 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 10 NP 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 15 RG 0 15:27:32 Stat_collector (EURUSD,H1) FH 0 15:27:32 Stat_collector (EURUSD,H1) =======List #3======= GN 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 15 FG 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 6 FR 0 15:27:32 Stat_collector (EURUSD,H1) CD 0 15:27:32 Stat_collector (EURUSD,H1) =======List #4======= PS 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 20
Como resultado, en el gráfico me salió lo siguiente (Fig. 19). Para que la percepción fuera más cómoda, la segunda vertical del frame la visualicé con el color azul.
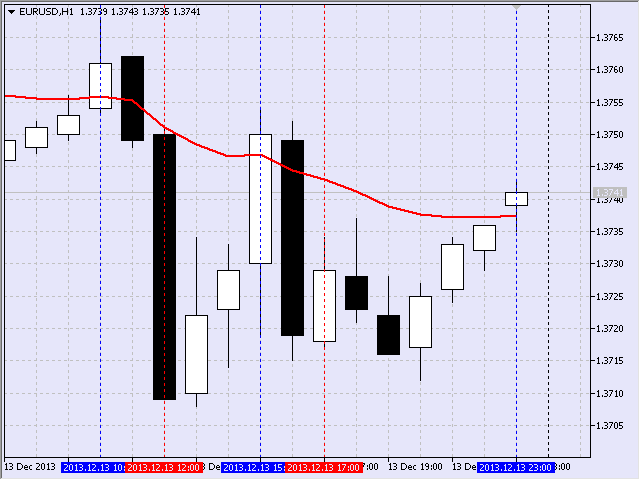
Fig.19 Visualización de frames
Es curioso que el último frame fue formado a la última hora del viernes del 13 de diciembre de 2013. Entró en la segunda lista porque su duración era igual a 6 horas.
4.2 Procesamiento del trading virtual
Imagínese que necesitamos crear un Asesor Experto que implemente varias estrategias independientes respecto a una herramienta en un flujo de ticks. Claro que en realidad se puede implementar simultáneamente sólo 1 estrategia respecto a una herramienta. Todas las demás estrategias van a tener el carácter virtual. Por eso diré desde el principio que eso se implementa exclusivamente para la simulación y optimización de la idea de trading.
Aquí, tengo que hacer referencia a un artículo fundamental en el que se describen al detalle los conceptos básicos referentes tanto al trading en general, como al terminal MetaTrader 5 en particular. Se trata del artículo "Órdenes, posiciones y transacciones en MetaTrader 5".
Pues, si para solucionar este problema, utilizamos el concepto de trading, sistema de administración de objetos de trading y la metodología de almacenamiento de la información sobre los objetos de trading que son habituales en el entorno de MetaTrader 5, probablemente necesitamos pensar en la creación de una base de datos virtual.
Permítanme recordarles que el desarrollador clasifica todos los objetos de trading en las órdenes, posiciones, transacciones y órdenes históricas. Algún crítico puede decir que el término "objeto de trading" ha sido introducido en el uso por el autor a su antojo. Y tendrá toda la razón...
Propongo utilizar para el trading virtual el mismo planteamiento de la cuestión y obtener los siguientes objetos de trading: órdenes virtuales, posiciones virtuales, transacciones virtuales y órdenes de trading virtuales.
Creo que este tema merece una discusión más detallada y profunda. Entretanto, volviendo al objeto de nuestro artículo, quiero decir que precisamente los tipo de datos de contenedor y también las listas pueden facilitar la vida al programador durante la implementación de estrategias virtuales.
Imagine que aparece una nueva posición virtual que naturalmente no puede estar en la parte del servidor comercial. Eso significa que hay que guardar toda la información sobre ella en la parte del terminal. De base de datos aquí puede servir una lista que a su vez se compone de varias listas una de las cuales va a contener los nodos de la posición virtual.
Usando el planteamiento del desarrollador, las clases del trading virtual podrían ser las siguientes:
Clase/grupo |
Descripción |
CVirtualOrder |
Clase para trabajar con la orden pendiente virtual |
CVirtualHistoryOrder |
Clase para trabajar con la orden "histórica" virtual |
CVirtualPosition |
Clase para trabajar con la posición abierta virtual |
CVirtualDeal |
Clase para trabajar con la transacción "histórica" virtual |
CVirtualTrade |
Clase para ejecutar operaciones virtuales de trading |
Tabla 1. Clases del trading virtual
No voy a entrar en detalles de la composición de cualquiera de las clases del trading virtual. Pero, probablemente pueda contener todos, o casi todos, los métodos que tiene una clase de trading estándar. Quiero hacer hincapié en una cosa, el desarrollador no utiliza la clase del propio objeto, sino de sus propiedades.
Pues bien, para utilizar las listas en sus algoritmos, hacen falta también los nodos. Por eso tendremos que envolver la clase del objeto virtual de trading en el nodo.
Qué el nodo de la posición abierta virtual pertenezca al tipo CVirtualPositionNode. Entonces, la definición de este tipo inicialmente podría ser la siguiente:
//+------------------------------------------------------------------+ //| Clase CVirtualPositionNode | //+------------------------------------------------------------------+ class CVirtualPositionNode : public CObject { protected: CVirtualPositionNode *m_virt_position; // puntero al trading virtual public: void CVirtualPositionNode(void); // constructor por defecto void ~CVirtualPositionNode(void); // destructor };
Ahora, en cuanto se abra una posición virtual, se puede añadirla en la lista de posiciones virtuales.
Una cosa más, con este planteamiento de trabajo con los objetos virtuales de trading se pierde la necesidad de usar la caché ya que la misma base de datos va a almacenarse en la memoria operativa. Por supuesto, se puede implementar su almacenamiento en otros medios de almacenamiento.
Conclusión
En este artículo he intentado demostrar las ventajas de un tipo de datos de contenedor como la "lista". Tampoco he podido omitir sus desventajas. En cualquier caso, espero que este material sea útil para los que están estudiando la POO en general, y uno de sus principios fundamentales que es el polimorfismo, en particular.
Ubicación de archivos:
Desde mi punto de vista, lo más conveniente sería crear y guardar los archivos en una carpeta del proyecto. Por ejemplo, la ruta puede ser así: %MQL5\Projects\UserLists. Es donde guardaba todos mis archivos de códigos fuente. Si va a utilizar las carpetas predefinidas, en el código de algunos archivos tendrá que cambiar el modo de designación del archivo de inclusión (en vez de comillas poner corchetes angulares).
| # | Archivo | Ruta | Descripción |
|---|---|---|---|
| 1 | CiSingleNode.mqh | %MQL5\Projects\UserLists | Clase del nodo para la lista simplemente enlazada |
| 2 | CDoubleNode.mqh | %MQL5\Projects\UserLists | Clase del nodo para la lista doblemente enlazada |
| 3 | CiUnrollDoubleNode.mqh | %MQL5\Projects\UserLists | Clase del nodo para la lista doblemente enlazada usando nodos de arrays |
| 4 | test_nodes.mq5 | %MQL5\Projects\UserLists | Script con ejemplos de trabajo con nodos |
| 5 | CiSingleList.mqh | %MQL5\Projects\UserLists | Clase de la lista simplemente enlazada |
| 6 | CDoubleList.mqh | %MQL5\Projects\UserLists | Clase de la lista doblemente enlazada |
| 7 | CiUnrollDoubleList.mqh | %MQL5\Projects\UserLists | Clase de la lista doblemente enlazada usando nodos de arrays |
| 8 | CiCircleDoublList.mqh | %MQL5\Projects\UserLists | Clase de la lista circular doblemente enlazada |
| 9 | test_sList.mq5 | %MQL5\Projects\UserLists | Script con ejemplos de trabajo con la lista simplemente enlazada |
| 10 | test_dList.mq5 | %MQL5\Projects\UserLists | Script con ejemplos de trabajo con la lista doblemente enlazada |
| 11 | test_UdList.mq5 | %MQL5\Projects\UserLists | Script con ejemplos de trabajo con la lista doblemente enlazada usando nodos de arrays |
| 12 | test_CdList.mq5 | %MQL5\Projects\UserLists | Script con ejemplos de trabajo con la lista circular doblemente enlazada |
| 13 | test_MQL5_List.mq5 | %MQL5\Projects\UserLists | Script con ejemplos de trabajo con la clase CList |
| 14 | CNodeInt.mqh | %MQL5\Projects\UserLists | Clase del nodo del tipo integer |
| 15 | CIntList.mqh | %MQL5\Projects\UserLists | Clase de la lista para los nodos CNodeInt |
| 16 | CRandom.mqh | %MQL5\Projects\UserLists | Clase del generador de números aleatorios |
| 17 | CVertLineNode.mqh | %MQL5\Projects\UserLists | Clase del nodo para el procesamiento del frame de verticales |
| 18 | Stat_collector.mq5 | %MQL5\Projects\UserLists | Script del ejemplo de recopilación de estadísticas |
Referencias:
- A. Friedman, L. Klander, M. Michaelis, H. Schildt, C/C++ Annotated Archives. Mcgraw-Hill Osborne Media, 1999. 1008 pages.
- V.D. Daleka, A.S. Derevyanko, O.G. Kravets, L.E. Timanovskaya. Data Models and Structures. Study Guide. Kharkov, KhGPU, 2000. 241 pages (en ruso).
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/709
 Gráfico informativo "Qué supone MetaTrader Market"
Gráfico informativo "Qué supone MetaTrader Market"
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso