
Основы программирования на MQL5 - Списки

Введение
Новая версия языка MQL дала программисту, работающему над своими проектами МТС, эффективные инструменты для реализации сложных задач. Нельзя отрицать тот факт, что программные возможности языка стали намного шире. Чего стоит хотя бы наличие арсенала ООП в MQL5. Да и нельзя, пожалуй, не упомянуть Стандартную библиотеку. Судя по тому, что есть ошибка за кодом 359, скоро появятся шаблоны классов.
В своей статье я хотел бы затронуть тему, которая может явиться своего рода расширением или продолжением тем, описывающих типы данных и их совокупности. Здесь сошлюсь на статейный материал MQL5.community. Принципы и логику работы с массивами очень подробно и системно описал Дмитрий Федосеев (Integer) в своей статье «Основы программирования на MQL5 - Массивы».
Итак, предлагаю заняться сегодня списками, а точнее связными линейными списками. Мы начнём с того, что изучим состав, смысл и логику построения списка. Затем посмотрим на уже имеющиеся инструменты в Стандартной библиотеке, касающиеся нашей темы. В заключительной части я представлю примеры того, как можно использовать списки в своей работе на языке MQL5.
- Понятия "список" и "узел": теория
- 1.1 Узел для односвязного списка
- 1.2 Узел для двусвязного списка
- 1.3 Узел для кольцевого двусвязного списка
- 1.4 Основные операции в списке
- Понятия "список" и "узел": программирование
- 2.1 Узел для односвязного спискаа
- 2.2 Узел для двусвязного списка
- 2.3 Узел для двусвязного развёрнутого списка
- 2.4 Односвязный список
- 2.5 Двусвязный список
- 2.6 Двусвязный развёрнутый список
- 2.7 Двусвязный кольцевой список
- Списки в Стандартной библиотеке MQL5
- Примеры использования списков в MQL5
1. Понятия "список" и "узел": теория
Итак, что же такое список для программиста и с чем его едят? Обращусь к публичному источнику Википедии для примерного определения этого понятия:
В информатике, спи́сок (англ. list) — это абстрактный тип данных, представляющий собой упорядоченный набор значений, в котором некоторое значение может встречаться более одного раза. Экземпляр списка является компьютерной реализацией математического понятия конечной последовательности — кортежа. Экземпляры значений, находящихся в списке, называются элементами списка (англ. item, entry либо element); если значение встречается несколько раз, каждое вхождение считается отдельным элементом.
Термином список также называется несколько конкретных структур данных, применяющихся при реализации абстрактных списков, особенно связных списков.
Надеюсь, что вы со мной согласитесь, что определение несколько заумное.
Для целей статьи интерес скорее представляет последнее предложение в определении. Поэтому давайте на нём и остановимся:
В информатике, свя́зный спи́сок — базовая динамическая структура данных, состоящая из узлов, каждый из которых содержит как собственно данные, так и одну или две ссылки («связки») на следующий и/или предыдущий узел списка.[1] Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Попробуем разобраться с ним поэтапно.
Список в программировании сам по себе это уже какой-то тип данных. С этим определились. И причём, это скорее синтетический тип, потому как он включает в себя другие типы данных. Есть какое-то сходство между списком и массивом. Если бы мы массив каких-то однотипных данных стали бы относить к новому типу данных, то и получили бы список. Но не совсем так.
Принципиальное преимущество списка заключается в его способности расти или уменьшаться по мере необходимости. И здесь список похож на динамический массив. Но только для списка не нужно постоянно применять
функцию ArrayResize().
Если вспомнить о расположении элементов в памяти, то узлы списка не хранятся так или не обязаны храниться так, как хранятся элементы массива в смежных участках памяти.
Вот примерно и всё. Едем дальше. По списку.
1.1 Узел для односвязного списка
В списке можно хранить не элементы, а узлы. Узел – это такой тип данных, который собственно состоит из двух частей.
Первая часть отведена под цели данных, а вторая – под связи с другими узлами или узлом (рис. 1). Первый узел списка называется head (голова), а последний – tail (хвост). Указатель хвоста равен NULL. По идее, он намекает на узел, находящийся вне списка. В других профильных источниках хвостом считают всю остальную часть списка кроме головы.

Рис.1 Узлы для односвязного списка
Кроме узла для односвязного списка есть ещё другие. Пожалуй, самым популярным является узел для двусвязного списка.
1.2 Узел для двусвязного списка
Ещё нам понадобится такой узел, который будет обслуживать потребности двусвязного списка. От предыдущего вида он отличается тем, что вмещает в себя ещё один указатель, который ссылается на предыдущий узел. И естественно, что такой узел головного элемента списка будет равен NULL. На схеме списка из таких узлов (рис. 2) указатели, ссылающиеся на предыдущие узлы, отображены красными стрелками.

Рис.2 Узлы для двусвязного списка
Итак, возможности узла для двусвязного списка будут аналогичны тем, которыми обладает односвязный узел, разве что нужно будет ещё обработать указатель на предыдущий узел.
1.3 Узел для кольцевого двусвязного списка
Бывают ещё такие случаи, когда перечисленные узлы можно использовать и для построения нелинейных списков. Хотя речь в статье будет идти в основном о линейных списках, я приведу пример и кольцевого списка.

Рис.3 Узлы для кольцевого двусвязного списка
На схеме кольцевого двусвязного списка (рис. 3) можно заметить, что узлы с двумя указателями просто зациклены. Это сделано с помощью оранжевой и зелёной стрелок. Таким образом, головной узел с помощью одного из указателей будет ссылаться на хвост (как на предыдущий элемент). А вот в хвостовом узле ссылка на следующий пустой не будет, т.к. она заполнится указателем на голову.
1.4 Основные операции в списке
Как отмечается в профильной литературе, все операции в списке можно разделить на 3 базовых группы:
- Добавление (появляется новый узел в списке);
- Удаление (удаляется какой-то узел из списка);
- Проверка (запрашиваются данные какого-либо узла).
К методам добавления можно отнести следующие:
- разместить новый узел в начале списка;
- разместить новый узел в конце списка;
- вставить узел в указанное место списка;
- добавить узел в пустой список;
- конструктор с параметрами.
Что касается операций удаления, то они практически дублируют аналогичные из группы добавления:
- удалить головной узел;
- удалить хвостовой узел;
- удалить узел из указанного места списка;
- деструктор.
Здесь отметил бы деструктор, который должен корректно завершить не только работу самого списка, но и правильно удалить все его элементы.
И третья группа, связанная с различными проверками, по сути дела даёт доступ к самим узлам либо к значениям узлов списка:
- поиск заданного значения;
- проверка списка на пустоту;
- получить значение i-го узла в списке;
- получить указатель на i-й узел в списке;
- получить размер списка;
- распечатать значения элементов списка.
В дополнение к базовым группам я выделил бы четвёртую, сервисную группу. Она связана с обслуживанием интересов предыдущих групп:
- оператор присваивания;
- конструктор копирования;
- работа с динамическим указателем;
- копирование списка по значениям;
- сортировка.
Вот, пожалуй, и всё. Да, конечно же, программист по своему желанию всегда может расширить возможности и функционал списочного класса.
2. Понятия "список" и "узел": программирование
В этой части я предлагаю непосредственно перейти к программированию узлов и списков. По мере необходимости буду иллюстрировать код схематическими связями.
2.1 Узел для односвязного списка
Создадим задел для класса узла (рис. 4), обслуживающего потребности односвязного списка. C нотацией диаграммы (макета) класса можно познакомиться в статье "Разработка эксперта средствами UML" (см. рис. 5. UML-модель класса CTradeExpert).

Рис.4 Макет класса CiSingleNode
Теперь попробуем поработать с кодом. За основу был взят листинг из книги Фридмана А. и др. "C/C+. Архив программ".
//+------------------------------------------------------------------+ //| Класс CiSingleNode | //+------------------------------------------------------------------+ class CiSingleNode { protected: int m_val; // данные CiSingleNode *m_next; // указатель на следующий узел public: void CiSingleNode(void); // конструктор по умолчанию void CiSingleNode(int _node_val); // конструктор c параметрами void ~CiSingleNode(void); // деструктор void SetVal(int _node_val); // метод-set для данных void SetNextNode(CiSingleNode *_ptr_next); // метод-set для следующего узла virtual void SetPrevNode(CiSingleNode *_ptr_prev){}; // метод-set для предыдущего узла virtual CiSingleNode *GetPrevNode(void) const {return NULL;}; // метод-get для предыдущего узла CiSingleNode *GetNextNode(void) const; // метод-get для следующего узла int GetVal(void){TRACE_CALL(_t_flag) return m_val;} // метод-get для данных };
Не буду расшифровывать каждый метод класса CiSingleNode. Детально с ними можно будет познакомиться в файле CiSingleNode.mqh. Отметил бы интересный нюанс. В классе есть виртуальные методы, работающие с предыдущими узлами. По сути, здесь они являются пустышками. И скорее их присутствие объясняется целями полиморфизма для будущих потомков.
В коде используется директива препроцессора TRACE_CALL(f). Нужна для целей трассировки, чтобы наблюдать за вызовом каждого используемого метода.
#define TRACE_CALL(f) if(f) Print("Calling: "+__FUNCSIG__);
Имея всего лишь класс CiSingleNode уже можно создать односвязный список. Приведу пример кода.
//=========== Example 1 (processing the CiSingleNode type ) CiSingleNode *p_sNodes[3]; // #1 p_sNodes[0]=NULL; srand(GetTickCount()); // initialize a random values generator //--- create nodes for(int i=0;i<ArraySize(p_sNodes);i++) p_sNodes[i]=new CiSingleNode(rand()); // #2 //--- links for(int j=0;j<(ArraySize(p_sNodes)-1);j++) p_sNodes[j].SetNextNode(p_sNodes[j+1]); // #3 //--- check values for(int i=0;i<ArraySize(p_sNodes);i++) { int val=p_sNodes[i].GetVal(); // #4 Print("Node #"+IntegerToString(i+1)+ // #5 " value = "+IntegerToString(val)); } //--- check next-nodes for(int j=0;j<(ArraySize(p_sNodes)-1);j++) { CiSingleNode *p_sNode_next=p_sNodes[j].GetNextNode(); // #9 int snode_next_val=p_sNode_next.GetVal(); // #10 Print("Next-Node #"+IntegerToString(j+1)+ // #11 " value = "+IntegerToString(snode_next_val)); } //--- delete nodes for(int i=0;i<ArraySize(p_sNodes);i++) delete p_sNodes[i]; // #12
На строке #1 объявим массив указателей на объекты типа CiSingleNode. На строке #2 заполним массив созданными указателями. Для данных каждого узла возьмём псевдослучайное целое число в диапазоне от 0 до 32767 с помощью функции rand(). На строке #3 свяжем узлы посредством next-указателя. На строках #4-5 проверим значения узлов. А вот на строках #9-11 проверим, как отработали сами связки. Удалим указатели на строке #12.
И вот что получилось распечатать в журнале.
DH 0 23:23:10 test_nodes (EURUSD,H4) Node #1 value = 3335 KP 0 23:23:10 test_nodes (EURUSD,H4) Node #2 value = 21584 GI 0 23:23:10 test_nodes (EURUSD,H4) Node #3 value = 917 HQ 0 23:23:10 test_nodes (EURUSD,H4) Next-Node #1 value = 21584 HI 0 23:23:10 test_nodes (EURUSD,H4) Next-Node #2 value = 917
Схематично структуру полученных узлов можно представить следующим образом (рис. 5).
!["Отношения между узлами в массиве CiSingleNode *p_sNodes[3]"](https://c.mql5.com/2/6/4.png "\"Отношения между узлами в массиве CiSingleNode *p_sNodes[3]\"")
Рис.5 Отношения между узлами в массиве CiSingleNode *p_sNodes[3]
Теперь займёмся узлом для двусвязного списка.
2.2 Узел для двусвязного списка
Для начала снова вспомним, что узел для двусвязного списка отличается тем, что имеет 2 указателя: один на next-узел (следующий), а другой - на previous-узел (предыдущий). Т.е. к обычному узлу для односвязного списка нужно добавить один указатель на предыдущий узел.
Предлагаю при этом использовать такое отношение классов, как наследование. Тогда макет для класса узла, обслуживающего потребности двусвязного списка, может выглядеть следующим образом (рис. 6).

Рис.6 Макет класса CDoubleNode
Ну и теперь пришла очередь разобраться с кодом.
//+------------------------------------------------------------------+ //| Класс CDoubleNode | //+------------------------------------------------------------------+ class CDoubleNode : public CiSingleNode { protected: CiSingleNode *m_prev; // указатель на предыдущий узел public: void CDoubleNode(void); // конструктор по умолчанию void CDoubleNode(int node_val); // конструктор c параметрами void ~CDoubleNode(void){TRACE_CALL(_t_flag)};// деструктор virtual void SetPrevNode(CiSingleNode *_ptr_prev); // метод-set для предыдущего узла virtual CiSingleNode *GetPrevNode(void) const; // метод-get для предыдущего узла CDoubleNode };
Дополнительных методов здесь совсем немного - они являются виртуальными и связаны с работой с предыдущим узлом. Полное определение класса находится в файле CDoubleNode.mqh.
На основе класса CDoubleNode попробуем создать двусвязный список. Приведу пример кода.
//=========== Example 2 (processing the CDoubleNode type) CiSingleNode *p_dNodes[3]; // #1 p_dNodes[0]=NULL; srand(GetTickCount()); // initialize a random values generator //--- create nodes for(int i=0;i<ArraySize(p_dNodes);i++) p_dNodes[i]=new CDoubleNode(rand()); // #2 //--- links for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { p_dNodes[j].SetNextNode(p_dNodes[j+1]); // #3 p_dNodes[j+1].SetPrevNode(p_dNodes[j]); // #4 } //--- check values for(int i=0;i<ArraySize(p_dNodes);i++) { int val=p_dNodes[i].GetVal(); // #4 Print("Node #"+IntegerToString(i+1)+ // #5 " value = "+IntegerToString(val)); } //--- check next-nodes for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { CiSingleNode *p_sNode_next=p_dNodes[j].GetNextNode(); // #9 int snode_next_val=p_sNode_next.GetVal(); // #10 Print("Next-Node #"+IntegerToString(j+1)+ // #11 " value = "+IntegerToString(snode_next_val)); } //--- check prev-nodes for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { CiSingleNode *p_sNode_prev=p_dNodes[j+1].GetPrevNode(); // #12 int snode_prev_val=p_sNode_prev.GetVal(); // #13 Print("Prev-Node #"+IntegerToString(j+2)+ // #14 " value = "+IntegerToString(snode_prev_val)); } //--- delete nodes for(int i=0;i<ArraySize(p_dNodes);i++) delete p_dNodes[i]; // #15
В принципе, это то же самое, что и при создании односвязного списка, но есть несколько нюансов. Посмотрите, как в строке #1 объявляется массив указателей p_dNodes[]. Тип указателей можно задавать как у базового класса. Принцип полиморфизма в строке #2 поможет потом их распознать в будущем. В строках #12-14 происходит проверка prev-узлов (предыдущих).
В журнал была записана следующая информация.
GJ 0 16:28:12 test_nodes (EURUSD,H4) Node #1 value = 17543 IQ 0 16:28:12 test_nodes (EURUSD,H4) Node #2 value = 1185 KK 0 16:28:12 test_nodes (EURUSD,H4) Node #3 value = 23216 DS 0 16:28:12 test_nodes (EURUSD,H4) Next-Node #1 value = 1185 NH 0 16:28:12 test_nodes (EURUSD,H4) Next-Node #2 value = 23216 FR 0 16:28:12 test_nodes (EURUSD,H4) Prev-Node #2 value = 17543 LI 0 16:28:12 test_nodes (EURUSD,H4) Prev-Node #3 value = 1185
Схематично структуру полученных узлов можно представить следующим образом (рис. 7):
!["Отношения между узлами в массиве CDoubleNode *p_sNodes[3]"](https://c.mql5.com/2/6/5.png "\"Отношения между узлами в массиве CDoubleNode *p_sNodes[3]\"")
Рис.7 Отношения между узлами в массиве CDoubleNode *p_sNodes[3]
Теперь предлагаю посмотреть на узел, который пригодится для "постройки" двусвязного развёрнутого списка.
2.3 Узел для двусвязного развёрнутого списка
Представьте себе, что есть такой узел, который имеет член-данные, относящийся не к одному значению, а к целому массиву, т.е. содержит и описывает целый массив. И тогда такой узел можно использовать для формирования развёрнутого списка. Я не стал схематично представлять этот узел, т.к. он в точности похож на обычный узел для двусвязного списка. Отличие лишь в том, что атрибут "данные" инкапсулирует целый массив.
Снова воспользуюсь наследованием. Базовым классом для узла двусвязного развёрнутого списка сделаю класс CDoubleNode. И макет для класса такого узла, обслуживающего потребности двусвязного развёрнутого списка, будет выглядеть так (рис. 8).

Рис. 8 Макет класса CiUnrollDoubleNode
Определить класс CiUnrollDoubleNode можно с помощью следующего кода:
//+------------------------------------------------------------------+ //| Класс CiUnrollDoubleNode | //+------------------------------------------------------------------+ class CiUnrollDoubleNode : public CDoubleNode { private: int m_arr_val[]; // массив данных public: void CiUnrollDoubleNode(void); // конструктор по умолчанию void CiUnrollDoubleNode(int &_node_arr[]); // конструктор c параметрами void ~CiUnrollDoubleNode(void); // деструктор bool GetArrVal(int &_dest_arr_val[])const; // метод-get для массива данных bool SetArrVal(const int &_node_arr_val[]); // метод-set для массива данных };
Каждый метод детально можно изучить в файле CiUnrollDoubleNode.mqh.
В качестве примера рассмотрим конструктор c параметрами.
//+------------------------------------------------------------------+ //| Конструктор c параметрами | //+------------------------------------------------------------------+ void CiUnrollDoubleNode::CiUnrollDoubleNode(int &_node_arr[]) : CDoubleNode(ArraySize(_node_arr)) { ArrayCopy(this.m_arr_val,_node_arr); TRACE_CALL(_t_flag) }
Здесь в член-данные this.m_val мы занесём размер одномерного массива с помощью списка инициализации.
А теперь "вручную" создадим двусвязный развёрнутый список и проверим, как налажены связи в нём.
//=========== Example 3 (processing the CiUnrollDoubleNode type) //--- data arrays int arr1[],arr2[],arr3[]; // #1 int arr_size=15; ArrayResize(arr1,arr_size); ArrayResize(arr2,arr_size); ArrayResize(arr3,arr_size); srand(GetTickCount()); // initialize a random values generator //--- fill the arrays with pseudorandom integers for(int i=0;i<arr_size;i++) { arr1[i]=rand(); // #2 arr2[i]=rand(); arr3[i]=rand(); } //--- create nodes CiUnrollDoubleNode *p_udNodes[3]; // #3 p_udNodes[0]=new CiUnrollDoubleNode(arr1); p_udNodes[1]=new CiUnrollDoubleNode(arr2); p_udNodes[2]=new CiUnrollDoubleNode(arr3); //--- links for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { p_udNodes[j].SetNextNode(p_udNodes[j+1]); // #4 p_udNodes[j+1].SetPrevNode(p_udNodes[j]); // #5 } //--- check values for(int i=0;i<ArraySize(p_udNodes);i++) { int val=p_udNodes[i].GetVal(); // #6 Print("Node #"+IntegerToString(i+1)+ // #7 " value = "+IntegerToString(val)); } //--- check arrays values for(int i=0;i<ArraySize(p_udNodes);i++) { int t_arr[]; // destination array bool isCopied=p_udNodes[i].GetArrVal(t_arr); // #8 if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Node #"+IntegerToString(i+1)+ // #9 " array values = "+arr_str); } } //--- check next-nodes for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { int t_arr[]; // destination array CiUnrollDoubleNode *p_udNode_next=p_udNodes[j].GetNextNode(); // #10 bool isCopied=p_udNode_next.GetArrVal(t_arr); if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Next-Node #"+IntegerToString(j+1)+ " array values = "+arr_str); } } //--- check prev-nodes for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { int t_arr[]; // destination array CiUnrollDoubleNode *p_udNode_prev=p_udNodes[j+1].GetPrevNode(); // #11 bool isCopied=p_udNode_prev.GetArrVal(t_arr); if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Prev-Node #"+IntegerToString(j+2)+ " array values = "+arr_str); } } //--- delete nodes for(int i=0;i<ArraySize(p_udNodes);i++) delete p_udNodes[i]; // #12 }
Количество строк кода немного увеличилось. Это связано с тем, что нужно создать и заполнить массив для каждого из узлов.
Работа с массивами данных начинается на строке #1. В принципе, то же самое, что и у предыдущих узлов. Только распечатать значения данных каждого узла придётся для целого массива (например, строка #9).
Вот что вышло у меня:
IN 0 00:09:13 test_nodes (EURUSD.m,H4) Node #1 value = 15 NF 0 00:09:13 test_nodes (EURUSD.m,H4) Node #2 value = 15 CI 0 00:09:13 test_nodes (EURUSD.m,H4) Node #3 value = 15 FQ 0 00:09:13 test_nodes (EURUSD.m,H4) Node #1 array values = 31784, 4837, 25797, 29079, 4223, 27234, 2155, 32351, 12010, 10353, 10391, 22245, 27895, 3918, 12069 EG 0 00:09:13 test_nodes (EURUSD.m,H4) Node #2 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756 MK 0 00:09:13 test_nodes (EURUSD.m,H4) Node #3 array values = 18100, 26358, 31020, 23881, 11256, 24798, 31481, 14567, 13032, 4701, 21665, 1434, 1622, 16377, 25778 RP 0 00:09:13 test_nodes (EURUSD.m,H4) Next-Node #1 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756 JD 0 00:09:13 test_nodes (EURUSD.m,H4) Next-Node #2 array values = 18100, 26358, 31020, 23881, 11256, 24798, 31481, 14567, 13032, 4701, 21665, 1434, 1622, 16377, 25778 EH 0 00:09:13 test_nodes (EURUSD.m,H4) Prev-Node #2 array values = 31784, 4837, 25797, 29079, 4223, 27234, 2155, 32351, 12010, 10353, 10391, 22245, 27895, 3918, 12069 NN 0 00:09:13 test_nodes (EURUSD.m,H4) Prev-Node #3 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756
На этом работу с узлами предлагаю завершить и перейти непосредственно к определениям классов различных списков. Примеры 1-3 находятся в скрипте test_nodes.mq5.
2.4 Односвязный список
Настало время из представленных групп основных операций списка спроектировать макет класса односвязного списка (рис. 9).

Рис.9 Макет класса CiSingleList
Несложно заметить, что в классе CiSingleList задействован узел типа CiSingleNode. Если вспомнить виды взаимодействия между классами, то можно сказать, что:
- класс CiSingleList включает в свой состав класс CiSingleNode (композиция);
- класс CiSingleList обращается к методам класса CiSingleNode (использование).
Схема перечисленных отношений представлена на рис. 10.

Рис.10 Виды взаимодействия между классами CiSingleList и CiSingleNode
Создадим новый класс CiSingleList. Немного забегу вперёд и скажу, что этот класс будет базовым для всех прочих списочных классов, используемых в статье. Поэтому он такой насыщенный.
//+------------------------------------------------------------------+ //| Класс CiSingleList | //+------------------------------------------------------------------+ class CiSingleList { protected: CiSingleNode *m_head; // голова CiSingleNode *m_tail; // хвост uint m_size; // количество узлов в списке public: //--- конструктор и деструктор void CiSingleList(); // конструктор по умолчанию void CiSingleList(int _node_val); // конструктор с параметрами void ~CiSingleList(); // деструктор //--- добавление узлов void AddFront(int _node_val); // новый узел в начало списка void AddRear(int _node_val); // новый узел в конец списка virtual void AddFront(int &_node_arr[]){TRACE_CALL(_t_flag)}; // новый узел в начало списка virtual void AddRear(int &_node_arr[]){TRACE_CALL(_t_flag)}; // новый узел в конец списка //--- удаление узлов int RemoveFront(void); // удалить головной узел int RemoveRear(void); // удалить узел в конце списка void DeleteNodeByIndex(const uint _idx); // удалить i-ый узел в списке //--- проверка virtual bool Find(const int _node_val) const; // поиск заданного значения bool IsEmpty(void) const; // проверка списка на пустоту virtual int GetValByIndex(const uint _idx) const; // значение i-го узла в списке virtual CiSingleNode *GetNodeByIndex(const uint _idx) const; // получить i-ый узел в списке virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // вставить новый i-ый узел в список CiSingleNode *GetHeadNode(void) const; // получить головной узел CiSingleNode *GetTailNode(void) const; // получить хвостовой узел virtual uint Size(void) const; // размер списка //--- сервис virtual void PrintList(string _caption=NULL); // вывод списка на печать virtual bool CopyByValue(const CiSingleList &_sList); // копирование списка по значениям virtual void BubbleSort(void); // пузырьковая сортировка //---шаблоны template<typename dPointer> bool CheckDynamicPointer(dPointer &_p); // шаблон проверки динамического указателя template<typename dPointer> bool DeleteDynamicPointer(dPointer &_p); // шаблон удаления динамического указателя protected: void operator=(const CiSingleList &_sList) const; // оператор присваивания void CiSingleList(const CiSingleList &_sList); // конструктор копирования virtual bool AddToEmpty(int _node_val); // добавить узел в пустой список virtual void addFront(int _node_val); // новый "родной" узел в начало списка virtual void addRear(int _node_val); // новый "родной" узел в конец списка virtual int removeFront(void); // удалить "родной" головной узел virtual int removeRear(void); // удалить "родной" узел в конце списка virtual void deleteNodeByIndex(const uint _idx); // удалить "родной" i-ый узел в списке virtual CiSingleNode *newNode(int _val); // новый "родной" узел virtual void CalcSize(void) const; // подсчитать размер списка };
Полное определение методов класса находится в файле CiSingleList.mqh.
Когда я только разрабатывал этот класс, то изначально было 3 члена-данных и всего лишь несколько методов. Но ввиду того, что на основе этого класса были созданы другие, пришлось добавлять несколько виртуальных членов-функций. Не буду детально описывать методы. Пример использования этого класса односвязного списка, можно увидеть в скрипте test_sList.mq5.
Если его запустить без флага трассировки, то в журнале появятся следующие строки:
KG 0 12:58:32 test_sList (EURUSD,H1) =======List #1======= PF 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=14 RL 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=666 MD 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=13 DM 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=11 QE 0 12:58:32 test_sList (EURUSD,H1) KN 0 12:58:32 test_sList (EURUSD,H1) LR 0 12:58:32 test_sList (EURUSD,H1) =======List #2======= RE 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=14 DQ 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=666 GK 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=13 FP 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=11 KF 0 12:58:32 test_sList (EURUSD,H1) MK 0 12:58:32 test_sList (EURUSD,H1) PR 0 12:58:32 test_sList (EURUSD,H1) =======renewed List #2======= GK 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=11 JP 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=13 JI 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=14 CF 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=34 QL 0 12:58:32 test_sList (EURUSD,H1) Node #5, val=35 OE 0 12:58:32 test_sList (EURUSD,H1) Node #6, val=36 MR 0 12:58:32 test_sList (EURUSD,H1) Node #7, val=37 KK 0 12:58:32 test_sList (EURUSD,H1) Node #8, val=38 MS 0 12:58:32 test_sList (EURUSD,H1) Node #9, val=666 OF 0 12:58:32 test_sList (EURUSD,H1) QK 0 12:58:32 test_sList (EURUSD,H1)
Скрипт заполнил 2 односвязных списка, затем расширил и отсортировал второй список.
2.5 Двусвязный список
Попробуем теперь создать двусвязный список на основе списка предыдущего типа. Макет класса двусвязного списка проиллюстрирован на рис. 11:

Рис.11 Макет класса CDoubleList
В классе-потомке стало гораздо меньше методов, а вот члены-данные и вовсе отсутствуют. Приведу определение класса CDoubleList.
//+------------------------------------------------------------------+ //| Класс CDoubleList | //+------------------------------------------------------------------+ class CDoubleList : public CiSingleList { public: void CDoubleList(void); // конструктор по умолчанию void CDoubleList(int _node_val); // конструктор с параметрами void ~CDoubleList(void){}; // деструктор virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // вставить новый i-ый узел в список protected: virtual bool AddToEmpty(int _node_val); // добавить узел в пустой список virtual void addFront(int _node_val); // новый "родной" узел в начало списка virtual void addRear(int _node_val); // новый "родной" узел в конец списка virtual int removeFront(void); // удалить "родной" головной узел virtual int removeRear(void); // удалить "родной" хвостовой узел virtual void deleteNodeByIndex(const uint _idx); // удалить "родной" i-ый узел в списке virtual CiSingleNode *newNode(int _node_val); // новый "родной" узел };
Полное определение методов класса CDoubleList находится в файле CDoubleList.mqh.
Виртуальные функции, по большому счёту, здесь нужны только для того, чтобы обрабатывать потребности указателя на предыдущий узел, который отсутствует в односвязном списке.
Пример использования списка типа CDoubleList можно будет найти в скрипте test_dList.mq5. Там проводятся все популярные операции со списками этого типа. В коде скрипта есть такая интересная строчка, как:
CiSingleNode *_new_node=new CDoubleNode(666); // создать новый узел типа CDoubleNode
Ошибки не будет, потому что такая конструкция вполне допустима в случае, когда указатель базового класса описывает объект класса-потомка. В этом заключается одно из преимуществ наследования.
В MQL5, впрочем как и в С++, указатель на базовый класс может указывать на объект производного класса, полученного из этого базового класса. Обратная конструкция недопустима.
Если записать строчку так:
CDoubleNode*_new_node=new CiSingleNode(666);
то компилятор ругаться не будет, а программа будет работать до тех пор, пока не столкнётся именно с такой строкой. В этом случае появится сообщение об ошибочном приведении типов, на которые ссылаются указатели. Поскольку механизм позднего связывания включается в действие на этапе выполнения программы, нужно внимательно учитывать иерархию отношений между классами.
Запуск скрипта выдаст следующие строки в журнале:
DN 0 13:10:57 test_dList (EURUSD,H1) =======List #1======= GO 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=14 IE 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=666 FM 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=13 KD 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=11 JL 0 13:10:57 test_dList (EURUSD,H1) DG 0 13:10:57 test_dList (EURUSD,H1) CK 0 13:10:57 test_dList (EURUSD,H1) =======List #2======= IL 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=14 KH 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=666 PR 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=13 MI 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=11 DO 0 13:10:57 test_dList (EURUSD,H1) FR 0 13:10:57 test_dList (EURUSD,H1) GK 0 13:10:57 test_dList (EURUSD,H1) =======renewed List #2======= PR 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=11 QI 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=13 QP 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=14 LO 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=34 JE 0 13:10:57 test_dList (EURUSD,H1) Node #5, val=35 HL 0 13:10:57 test_dList (EURUSD,H1) Node #6, val=36 FK 0 13:10:57 test_dList (EURUSD,H1) Node #7, val=37 DR 0 13:10:57 test_dList (EURUSD,H1) Node #8, val=38 FJ 0 13:10:57 test_dList (EURUSD,H1) Node #9, val=666 HO 0 13:10:57 test_dList (EURUSD,H1) JR 0 13:10:57 test_dList (EURUSD,H1)
Как и в случае с односвязным списком, скрипт заполнил первый список (только двусвязный), сделал его копию и передал её во второй список. Затем увеличил число узлов во втором списке, отсортировал и вывел список на печать.
2.6 Двусвязный развёрнутый список
Этот тип списка удобен тем, что можно в одном узле хранить не просто какое-то одно значение, а целый массив.
Создадим задел для списка типа CiUnrollDoubleList (рис. 12).

Рис.12 Макет класса CiUnrollDoubleList
Здесь, ввиду того что имеем дело с массивом данных, придётся переопределять методы, ещё заданные в непрямом базовом классе CiSingleList.
Имеем следующее определение класса CiUnrollDoubleList.
//+------------------------------------------------------------------+ //| Класс CiUnrollDoubleList | //+------------------------------------------------------------------+ class CiUnrollDoubleList : public CDoubleList { public: void CiUnrollDoubleList(void); // конструктор по умолчанию void CiUnrollDoubleList(int &_node_arr[]); // конструктор с параметрами void ~CiUnrollDoubleList(void){TRACE_CALL(_t_flag)}; // деструктор //--- virtual void AddFront(int &_node_arr[]); // новый узел в начало списка virtual void AddRear(int &_node_arr[]); // новый узел в конец списка virtual bool CopyByValue(const CiSingleList &_udList); // копирование по значениям virtual void PrintList(string _caption=NULL); // вывод списка на печать virtual void BubbleSort(void); // пузырьковая сортировка protected: virtual bool AddToEmpty(int &_node_arr[]); // добавить узел в пустой список virtual void addFront(int &_node_arr[]); // новый "родной" узел в начало списка virtual void addRear(int &_node_arr[]); // новый "родной" узел в конец списка virtual int removeFront(void); // удалить "родной" узел в начало списка virtual int removeRear(void); // удалить "родной" узел в конец списка virtual void deleteNodeByIndex(const uint _idx); // удалить "родной" i-ый узел в списке virtual CiSingleNode *newNode(int &_node_arr[]); // новый "родной" узел };
Полное определение методов класса находится в файле CiUnrollDoubleList.mqh.
Посмотрим, как работают методы класса с помощью скрипта test_UdList.mq5. Здесь задействуются аналогичные операции с узлами, что и в предыдущих скриптах. Отдельно, пожалуй, стоит сказать о методах сортировки и вывода на печать. Первый сортирует узлы по количеству элементов. Тогда узел, содержащий наименьший по размеру массив значений, окажется в голове списка.
Метод вывода на печать занимается тем, что распечатывает в одной строке значения массива, входящего в конкретный узел.
После запуска скрипта в журнале появятся следующие строки:
II 0 13:22:23 test_UdList (EURUSD,H1) =======List #1======= FN 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 OO 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 GG 0 13:22:23 test_UdList (EURUSD,H1) GP 0 13:22:23 test_UdList (EURUSD,H1) GR 0 13:22:23 test_UdList (EURUSD,H1) =======List #2 before sorting======= JO 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 CH 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 CF 0 13:22:23 test_UdList (EURUSD,H1) List node #3, array: -89, -131, -141, -139, -129, -25, -105, -24, -122, -120, -118, -116, -114, -112, -110 GD 0 13:22:23 test_UdList (EURUSD,H1) GQ 0 13:22:23 test_UdList (EURUSD,H1) LJ 0 13:22:23 test_UdList (EURUSD,H1) =======List #2 after sorting======= FN 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 CJ 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 II 0 13:22:23 test_UdList (EURUSD,H1) List node #3, array: -89, -131, -141, -139, -129, -25, -105, -24, -122, -120, -118, -116, -114, -112, -110 MD 0 13:22:23 test_UdList (EURUSD,H1) MQ 0 13:22:23 test_UdList (EURUSD,H1)
Как можно увидеть, после сортировки список udList2 выводился на печать от узла с наименьшим по размеру массивом до узла с наибольшим.
2.7 Двусвязный кольцевой список
Нелинейные списки в статье не рассматриваются, но всё же, давайте тоже с ними поработаем. Как можно "закольцевать" узлы, приводил на схеме (рис. 3).
Создадим макет для класса CiCircleDoubleList (рис. 13). Сам класс будет являться потомком класса CDoubleList.

Рис.13 Макет класса CiCircleDoubleList
Ввиду того, что узлы в таком списке имеют свою специфику (голова и хвост залинкованы), придётся сделать виртуальными почти все методы исходного базового класса CiSingleList.
//+------------------------------------------------------------------+ //| Класс CiCircleDoubleList | //+------------------------------------------------------------------+ class CiCircleDoubleList : public CDoubleList { public: void CiCircleDoubleList(void); // конструктор по умолчанию void CiCircleDoubleList(int _node_val); // конструктор с параметрами void ~CiCircleDoubleList(void){TRACE_CALL(_t_flag)}; // деструктор //--- virtual uint Size(void) const; // размер списка virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // вставить новый i-ый узел в список virtual int GetValByIndex(const uint _idx) const; // значение i-го узла в списке virtual CiSingleNode *GetNodeByIndex(const uint _idx) const; // получить i-ый узел в спискеi-ый узел в списке virtual bool Find(const int _node_val) const; // поиск заданного значения virtual bool CopyByValue(const CiSingleList &_sList); // копирование списка по значениям protected: virtual void addFront(int _node_val); // новый "родной" узел в начало списка virtual void addRear(int _node_val); // новый "родной" узел в конец списка virtual int removeFront(void); // удалить "родной" головной узел virtual int removeRear(void); // удалить "родной" хвостовой узел virtual void deleteNodeByIndex(const uint _idx); // удалить "родной" i-ый узел в списке protected: void CalcSize(void) const; // подсчитать размер списка void LinkHeadTail(void); // связать голову с хвостом };
Полное определение класса находится в файле CiCircleDoubleList.mqh.
Рассмотрим несколько методов класса. Метод CiCircleDoubleList::LinkHeadTail() занимается тем, что связывает хвостовой узел с головным. Его вызов оправдан тогда, когда появляется новый хвост либо голова, а предыдущая связь теряется.
//+------------------------------------------------------------------+ //| Cвязать голову с хвостом | //+------------------------------------------------------------------+ void CiCircleDoubleList::LinkHeadTail(void) { TRACE_CALL(_t_flag) this.m_head.SetPrevNode(this.m_tail); // связка головы с хвостом this.m_tail.SetNextNode(this.m_head); // связка хвоста с головой }
Подумайте, как должен был бы выглядеть этот метод, если бы список был кольцевым односвязным.
Рассмотрим, например, метод CiCircleDoubleList::addFront().
//+------------------------------------------------------------------+ //| Новый "родной" узел в начало списка | //+------------------------------------------------------------------+ void CiCircleDoubleList::addFront(int _node_val) { TRACE_CALL(_t_flag) CDoubleList::addFront(_node_val); // вызов аналогичного метода базового класса this.LinkHeadTail(); // залинковать голову и хвост }
В теле метода видно, что вызывается аналогичный метод базового класса CDoubleList. На этом можно было бы завершить работу метода (а точнее сам метод здесь практически не нужен), если бы не одно "но". Между головой и хвостом теряется связь, а без таковой список не будет кольцевым. Вот и приходится обращаться к методу залинковки головы и хвоста.
Скрипт test_UdList.mq5 тестирует работу с кольцевым двусвязным списком.
Используются такие же по целям и задачам методы, что и в прошлых примерах.
На выходе в журнале получим такие записи:
PR 0 13:34:29 test_CdList (EURUSD,H1) =======List #1======= QS 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=14 QI 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=666 LQ 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=13 OH 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=11 DP 0 13:34:29 test_CdList (EURUSD,H1) DK 0 13:34:29 test_CdList (EURUSD,H1) DI 0 13:34:29 test_CdList (EURUSD,H1) =======List #2 before sorting======= MS 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=38 IJ 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=37 IQ 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=36 EH 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=35 EO 0 13:34:29 test_CdList (EURUSD,H1) Node #5, val=34 FF 0 13:34:29 test_CdList (EURUSD,H1) Node #6, val=14 DN 0 13:34:29 test_CdList (EURUSD,H1) Node #7, val=666 GD 0 13:34:29 test_CdList (EURUSD,H1) Node #8, val=13 JK 0 13:34:29 test_CdList (EURUSD,H1) Node #9, val=11 JM 0 13:34:29 test_CdList (EURUSD,H1) JH 0 13:34:29 test_CdList (EURUSD,H1) MS 0 13:34:29 test_CdList (EURUSD,H1) =======List #2 after sorting======= LE 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=11 KL 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=13 QS 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=14 NJ 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=34 NQ 0 13:34:29 test_CdList (EURUSD,H1) Node #5, val=35 NH 0 13:34:29 test_CdList (EURUSD,H1) Node #6, val=36 NO 0 13:34:29 test_CdList (EURUSD,H1) Node #7, val=37 NF 0 13:34:29 test_CdList (EURUSD,H1) Node #8, val=38 JN 0 13:34:29 test_CdList (EURUSD,H1) Node #9, val=666 RJ 0 13:34:29 test_CdList (EURUSD,H1) RE 0 13:34:29 test_CdList (EURUSD,H1)
В итоге окончательная схема наследственных отношений между представленными списочными классами выглядит следующим образом (рис. 14).
Не уверен, что стоит все классы связывать между собой наследственными отношениями, но решил оставить как есть.

Рис.14 Наследственные отношения между списочными классами
Завершая раздел статьи, в котором были представлены пользовательские списки, хотел бы отметить, что практически неосвещёнными остались семейства нелинейных списков, мультисписков и пр. По мере накопления материала и опыта работы с такими динамическими структурами данных попробую написать ещё одну статью.
3. Списки в Стандартной библиотеке MQL5
Давайте посмотрим на списочный класс, который имеется в Стандартной библиотеке (рис. 15).
Он входит в раздел Классы для организации данных.

Рис.15 Макет класса CList
Любопытно, что класс CList является потомком класса CObject. Т.е. список наследует данные и методы класса, который является узлом.
Списочный класс достаточно внушителен по набору методов. Честно, не ожидал, что в Стандартной библиотеке будет такой немаленький класс.
В классе CList есть 8 членов-данных. Отметил бы несколько моментов. В атрибутах класса есть индекс текущего узла (int m_curr_idx) и указатель на текущий узел (CObject* m_curr_node). Можно сказать, что список является «умным» - он может выдать место, где сосредоточено управление. Затем есть такие инструменты, как: орудие работы с памятью (можем физически удалить узел или просто его исключить из списка), признак отсортированного списка, режим сортировки списка.
Что касается методов. Разработчик классифицирует все методы класса CList на следующие группы:
- атрибуты;
- создание нового элемента;
- наполнение;
- удаление;
- навигация;
- перемещение элементов;
- сравнение;
- поиск;
- ввод/вывод.
Типично, что есть штатные конструктор и деструктор.
Первый опустошает (NULL) все указатели. Флаг управления памятью взводится в положение «удалить физически». Новый список не будет отсортированным.
Деструктор в своём теле лишь обращается к методу Clear(), освобождая список от узлов. Да, необязательно, что прекращение существования списка влечёт «смерть» его элементов (узлов). Наличие флага управления памятью при удалении элементов списка, таким образом, отношение «композиция» между классами превращает в отношение «агрегация».
Как раз оперировать таким флагом мы можем посредством set- и get-методов FreeMode().
В классе есть 2 метода увеличения списка: Add() и Insert(). Первый похож на метод AddRear(), который я использовал в первом разделе статьи, а второй подобен методу SetNodeByIndex().
Начнём работу с небольшого примера. Но сначала создадим класс узла CNodeInt, являющийся потомком класса-интерфейса CObject. В нём будет храниться значение типа integer.
//+------------------------------------------------------------------+ //| Класс CNodeInt | //+------------------------------------------------------------------+ class CNodeInt : public CObject { private: int m_val; // данные узла public: void CNodeInt(void){this.m_val=WRONG_VALUE;}; // конструктор по умолчанию void CNodeInt(int _val); // конструктор c параметрами void ~CNodeInt(void){}; // деструктор int GetVal(void){return this.m_val;}; // метод-get для данных узла void SetVal(int _val){this.m_val=_val;}; // метод-set для данных узла }; //+------------------------------------------------------------------+ //| Конструктор c параметрами | //+------------------------------------------------------------------+ void CNodeInt::CNodeInt(int _val):m_val(_val) { };
Итак, работать со списком CList будем в скрипте test_MQL5_List.mq5.
В Примере 1 динамически создаётся список и узлы. Затем список заполняется узлами, проверяется значение первого узла до и после удаления списка.
//--- Example 1 (testing memory management) CList *myList=new CList; // myList.FreeMode(false); // reset flag bool _free_mode=myList.FreeMode(); PrintFormat("\nList \"myList\" - memory management flag: %d",_free_mode); CNodeInt *p_new_nodes_int[10]; p_new_nodes_int[0]=NULL; for(int i=0;i<ArraySize(p_new_nodes_int);i++) { p_new_nodes_int[i]=new CNodeInt(rand()); myList.Add(p_new_nodes_int[i]); } PrintFormat("List \"myList\" has as much nodes as: %d",myList.Total()); Print("=======Before deleting \"myList\"======="); PrintFormat("The 1st node value is: %d",p_new_nodes_int[0].GetVal()); delete myList; int val_to_check=WRONG_VALUE; if(CheckPointer(p_new_nodes_int[0])) val_to_check=p_new_nodes_int[0].GetVal(); Print("=======After deleting \"myList\"======="); PrintFormat("The 1st node value is: %d",val_to_check);
Если строка сброса флага останется закомментированной (неактивной), то в журнале получим такие записи:
GS 0 14:00:16 test_MQL5_List (EURUSD,H1) EO 0 14:00:16 test_MQL5_List (EURUSD,H1) List "myList" - memory management flag: 1 FR 0 14:00:16 test_MQL5_List (EURUSD,H1) List "myList" has as much nodes as: 10 JH 0 14:00:16 test_MQL5_List (EURUSD,H1) =======Before deleting "myList"======= DO 0 14:00:16 test_MQL5_List (EURUSD,H1) The 1st node value is: 7189 KJ 0 14:00:16 test_MQL5_List (EURUSD,H1) =======After deleting "myList"======= QK 0 14:00:16 test_MQL5_List (EURUSD,H1) The 1st node value is: -1
Отмечу, что после динамического удаления списка myList все узлы в нём из памяти также физически были удалены.
А вот если раскомментировать строку:
// myList.FreeMode(false); // reset flagто получим такой вывод в журнал:
NS 0 14:02:11 test_MQL5_List (EURUSD,H1) CN 0 14:02:11 test_MQL5_List (EURUSD,H1) List "myList" - memory management flag: 0 CS 0 14:02:11 test_MQL5_List (EURUSD,H1) List "myList" has as much nodes as: 10 KH 0 14:02:11 test_MQL5_List (EURUSD,H1) =======Before deleting "myList"======= NL 0 14:02:11 test_MQL5_List (EURUSD,H1) The 1st node value is: 20411 HJ 0 14:02:11 test_MQL5_List (EURUSD,H1) =======After deleting "myList"======= LI 0 14:02:11 test_MQL5_List (EURUSD,H1) The 1st node value is: 20411 QQ 1 14:02:11 test_MQL5_List (EURUSD,H1) 10 undeleted objects left DD 1 14:02:11 test_MQL5_List (EURUSD,H1) 10 objects of type CNodeInt left DL 1 14:02:11 test_MQL5_List (EURUSD,H1) 400 bytes of leaked memory
Несложно заметить, что до удаления списка и после узел, находящийся и находившийся в голове, не теряет своё значение. В этом случае в куче останутся ещё неудалённые объекты, если в скрипте не будет больше кода, обрабатывающего их корректное удаление.
Попробуем теперь поработать с методом сортировки.
//--- Example 2 (sorting) CList *myList=new CList; CNodeInt *p_new_nodes_int[10]; p_new_nodes_int[0]=NULL; for(int i=0;i<ArraySize(p_new_nodes_int);i++) { p_new_nodes_int[i]=new CNodeInt(rand()); myList.Add(p_new_nodes_int[i]); } PrintFormat("\nList \"myList\" has as much nodes as: %d",myList.Total()); Print("=======List \"myList\" before sorting======="); for(int i=0;i<myList.Total();i++) { CNodeInt *p_node_int=myList.GetNodeAtIndex(i); int node_val=p_node_int.GetVal(); PrintFormat("Node #%d is equal to: %d",i+1,node_val); } myList.Sort(0); Print("\n=======List \"myList\" after sorting======="); for(int i=0;i<myList.Total();i++) { CNodeInt *p_node_int=myList.GetNodeAtIndex(i); int node_val=p_node_int.GetVal(); PrintFormat("Node #%d is equal to: %d",i+1,node_val); } delete myList;
В журнале записи оказались следующими:
OR 0 22:47:01 test_MQL5_List (EURUSD,H1) FN 0 22:47:01 test_MQL5_List (EURUSD,H1) List "myList" has as much nodes as: 10 FH 0 22:47:01 test_MQL5_List (EURUSD,H1) =======List "myList" before sorting======= LG 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #1 is equal to: 30511 CO 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #2 is equal to: 17404 GF 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #3 is equal to: 12215 KQ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #4 is equal to: 31574 NJ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #5 is equal to: 7285 HP 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #6 is equal to: 23509 IH 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #7 is equal to: 26991 NS 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #8 is equal to: 414 MK 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #9 is equal to: 18824 DR 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #10 is equal to: 1560 OR 0 22:47:01 test_MQL5_List (EURUSD,H1) OM 0 22:47:01 test_MQL5_List (EURUSD,H1) =======List "myList" after sorting======= QM 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #1 is equal to: 26991 RE 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #2 is equal to: 23509 ML 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #3 is equal to: 18824 DD 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #4 is equal to: 414 LL 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #5 is equal to: 1560 IG 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #6 is equal to: 17404 PN 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #7 is equal to: 30511 II 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #8 is equal to: 31574 OQ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #9 is equal to: 12215 JH 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #10 is equal to: 7285
Если какая-то сортировка и состоялась, то её методика для меня осталась неизвестной. И вот в чём дело. Не буду вдаваться в подробности очерёдности вызовов, но метод CList::Sort() обращается к методу CObject::Compare(), который является виртуальным и никак не реализован в базовом классе. Таким образом, программист должен самостоятельно заняться реализацией метода упорядочивания.
Несколько слов о методе Total(). Он возвращает число элементов (узлов), за которое отвечает член-данные m_data_total. Очень короткий и лаконичный метод. В такой версии подсчёт элементов будет работать гораздо быстрее, нежели в той, которую предлагал я. И действительно, зачем каждый раз делать проходы по списку и подсчитывать узлы, если точное число узлов в списке можно задавать при добавлении либо удалении узлов.
В Примере 3 приводится сравнение скорости заполнения списков типа CList и CiSingleList. И рассчитывается время для получения размера каждого списка.
//--- Example 3 (nodes number) int iterations=1e7; // 10 million iterations //--- the new CList CList *p_mql_List=new CList; uint start=GetTickCount(); // starting value for(int i=0;i<iterations;i++) { CNodeInt *p_node_int=new CNodeInt(rand()); p_mql_List.Add(p_node_int); } uint time=GetTickCount()-start; // spent time, msec Print("\n=======the CList type list======="); PrintFormat("Filling the list of %.3e nodes has taken %d msec",iterations,time); //--- get the size start=GetTickCount(); int list_size=p_mql_List.Total(); time=GetTickCount()-start; PrintFormat("Getting the size of the list has taken %d msec",time); delete p_mql_List; //--- the new CiSingleList CiSingleList *p_sList=new CiSingleList; start=GetTickCount(); // starting value for(int i=0;i<iterations;i++) p_sList.AddRear(rand()); time=GetTickCount()-start; // spent time, msec Print("\n=======the CiSingleList type list======="); PrintFormat("Filling the list of %.3e nodes has taken %d msec",iterations,time); //--- get the size start=GetTickCount(); list_size=(int)p_sList.Size(); time=GetTickCount()-start; PrintFormat("Getting the size of the list has taken %d msec",time); delete p_sList;
Вот что у меня вышло в журнале:
KO 0 22:48:24 test_MQL5_List (EURUSD,H1) CK 0 22:48:24 test_MQL5_List (EURUSD,H1) =======the CList type list======= JL 0 22:48:24 test_MQL5_List (EURUSD,H1) Filling the list of 1.000e+007 nodes has taken 2606 msec RO 0 22:48:24 test_MQL5_List (EURUSD,H1) Getting the size of the list has taken 0 msec LF 0 22:48:29 test_MQL5_List (EURUSD,H1) EL 0 22:48:29 test_MQL5_List (EURUSD,H1) =======the CiSingleList type list======= KK 0 22:48:29 test_MQL5_List (EURUSD,H1) Filling the list of 1.000e+007 nodes has taken 2356 msec NF 0 22:48:29 test_MQL5_List (EURUSD,H1) Getting the size of the list has taken 359 msec
Метод получения размера в списке CList работает мгновенно. Кстати, добавление узлов в список тоже происходит достаточно быстро.
В следующем блоке (Пример 4) предлагаю обратить внимание на один из главных недостатков такого контейнера данных, как список, - скорость доступа к элементам. Дело в том, что доступ к элементам списка осуществляется линейно, а в случае со списочным классом CList - с пониженным коэффициентом (N/2), что уменьшает трудоёмкость алгоритма.
При линейном поиске имеем трудоёмкость вида O(N).
Вот такой код для примера доступа к элементам совокупности данных:
//--- Example 4 (speed of accessing the node) const uint Iter_arr[]={1e3,3e3,6e3,9e3,1e4,3e4,6e4,9e4,1e5,3e5,6e5}; for(uint i=0;i<ArraySize(Iter_arr);i++) { const uint cur_iterations=Iter_arr[i]; // iterations number uint randArr[]; // randoms array uint idxArr[]; // indexes array //--- set the arrays size ArrayResize(randArr,cur_iterations); ArrayResize(idxArr,cur_iterations); CRandom myRand; // randoms generator //--- fill the randoms array for(uint t=0;t<cur_iterations;t++) randArr[t]=myRand.int32(); //--- fill the indexes array with the randoms (from 0 to 10 million) int iter_log10=(int)log10(cur_iterations); for(uint r=0;r<cur_iterations;r++) { uint rand_val=myRand.int32(); // random value (from 0 to 4 294 967 295) if(rand_val>=cur_iterations) { int val_log10=(int)log10(rand_val); double log10_remainder=val_log10-iter_log10; rand_val/=(uint)pow(10,log10_remainder+1); } //--- check the limit if(rand_val>=cur_iterations) { Alert("Random value error!"); return; } idxArr[r]=rand_val; } //--- time spent for the array uint start=GetTickCount(); //--- accessing the array elements for(uint p=0;p<cur_iterations;p++) uint random_val=randArr[idxArr[p]]; uint time=GetTickCount()-start; // spent time, msec Print("\n=======the uint type array======="); PrintFormat("Random accessing the array of elements %.1e has taken %d msec",cur_iterations,time); //--- the CList type list CList *p_mql_List=new CList; //--- fill the list for(uint q=0;q<cur_iterations;q++) { CNodeInt *p_node_int=new CNodeInt(randArr[q]); p_mql_List.Add(p_node_int); } start=GetTickCount(); //--- accessing the list nodes for(uint w=0;w<cur_iterations;w++) CNodeInt *p_node_int=p_mql_List.GetNodeAtIndex(idxArr[w]); time=GetTickCount()-start; // spent time, msec Print("\n=======the CList type list======="); PrintFormat("Random accessing the list of nodes %.1e has taken %d msec",cur_iterations,time); //--- free the memory ArrayFree(randArr); ArrayFree(idxArr); delete p_mql_List; }
По итогам работы этого блока получилось вывести следующие записи в журнал:
MR 0 22:51:22 test_MQL5_List (EURUSD,H1) QL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= IG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+003 has taken 0 msec QF 0 22:51:22 test_MQL5_List (EURUSD,H1) IQ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= JK 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+003 has taken 0 msec MJ 0 22:51:22 test_MQL5_List (EURUSD,H1) QD 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= GO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+003 has taken 0 msec QN 0 22:51:22 test_MQL5_List (EURUSD,H1) II 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= EP 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+003 has taken 16 msec OR 0 22:51:22 test_MQL5_List (EURUSD,H1) OL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= FG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+003 has taken 0 msec CF 0 22:51:22 test_MQL5_List (EURUSD,H1) GQ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= CH 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+003 has taken 31 msec QJ 0 22:51:22 test_MQL5_List (EURUSD,H1) MD 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= MO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 9.0e+003 has taken 0 msec EN 0 22:51:22 test_MQL5_List (EURUSD,H1) MJ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= CP 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 9.0e+003 has taken 47 msec CR 0 22:51:22 test_MQL5_List (EURUSD,H1) KL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= JG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+004 has taken 0 msec GF 0 22:51:22 test_MQL5_List (EURUSD,H1) KR 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= MK 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+004 has taken 343 msec GJ 0 22:51:22 test_MQL5_List (EURUSD,H1) GG 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= LO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+004 has taken 0 msec QO 0 22:51:24 test_MQL5_List (EURUSD,H1) MJ 0 22:51:24 test_MQL5_List (EURUSD,H1) =======the CList type list======= NP 0 22:51:24 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+004 has taken 1217 msec OS 0 22:51:24 test_MQL5_List (EURUSD,H1) KO 0 22:51:24 test_MQL5_List (EURUSD,H1) =======the uint type array======= CP 0 22:51:24 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+004 has taken 0 msec MG 0 22:51:26 test_MQL5_List (EURUSD,H1) ER 0 22:51:26 test_MQL5_List (EURUSD,H1) =======the CList type list======= PG 0 22:51:26 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+004 has taken 2387 msec GK 0 22:51:26 test_MQL5_List (EURUSD,H1) OG 0 22:51:26 test_MQL5_List (EURUSD,H1) =======the uint type array======= NH 0 22:51:26 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 9.0e+004 has taken 0 msec JO 0 22:51:30 test_MQL5_List (EURUSD,H1) NK 0 22:51:30 test_MQL5_List (EURUSD,H1) =======the CList type list======= KO 0 22:51:30 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 9.0e+004 has taken 3619 msec HS 0 22:51:30 test_MQL5_List (EURUSD,H1) DN 0 22:51:30 test_MQL5_List (EURUSD,H1) =======the uint type array======= RP 0 22:51:30 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+005 has taken 0 msec OD 0 22:52:05 test_MQL5_List (EURUSD,H1) GS 0 22:52:05 test_MQL5_List (EURUSD,H1) =======the CList type list======= DE 0 22:52:05 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+005 has taken 35631 msec NH 0 22:52:06 test_MQL5_List (EURUSD,H1) RF 0 22:52:06 test_MQL5_List (EURUSD,H1) =======the uint type array======= FI 0 22:52:06 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+005 has taken 0 msec HL 0 22:54:20 test_MQL5_List (EURUSD,H1) PD 0 22:54:20 test_MQL5_List (EURUSD,H1) =======the CList type list======= FN 0 22:54:20 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+005 has taken 134379 msec RQ 0 22:54:20 test_MQL5_List (EURUSD,H1) JI 0 22:54:20 test_MQL5_List (EURUSD,H1) =======the uint type array======= MR 0 22:54:20 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+005 has taken 15 msec NE 0 22:58:48 test_MQL5_List (EURUSD,H1) FL 0 22:58:48 test_MQL5_List (EURUSD,H1) =======the CList type list======= GE 0 22:58:48 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+005 has taken 267589 msec
Можно заметить, что по мере увеличения размера списка, вырастало время доступа случайным образом к элементам списка (рис. 16).

Рис.16 Временные затраты на случайный доступ к элементам массива и списка
Обратимся теперь к методам сохранения и загрузки данных.
В базовом списочном классе CList такие методы есть, однако они являются виртуальными. Поэтому, чтобы проверить их работу на примере, придётся провести небольшую подготовительную работу.
Унаследуем от класса CList его возможности с помощью класса-потомка CIntList. В последнем будет только 1 метод для создания нового элемента CIntList::CreateElement().
//+------------------------------------------------------------------+ //| Класс CIntList | //+------------------------------------------------------------------+ class CIntList : public CList { public: virtual CObject *CreateElement(void); }; //+------------------------------------------------------------------+ //| Новый элемент списка | //+------------------------------------------------------------------+ CObject *CIntList::CreateElement(void) { CObject *new_node=new CNodeInt(); return new_node; }
Ещё нужно будет добавить виртуальные методы CNodeInt::Save() и CNodeInt::Load() в производный тип узла CNodeInt. Они будут вызываться из членов-функций CList::Save() и CList::Load() соответственно.
И тогда получится такой пример (Пример 5):
//--- Example 5 (saving list data) //--- the CIntList type list CList *p_int_List=new CIntList; int randArr[1000]; // randoms array ArrayInitialize(randArr,0); //--- fill the randoms array for(int t=0;t<1000;t++) randArr[t]=(int)myRand.int32(); //--- fill the list for(uint q=0;q<1000;q++) { CNodeInt *p_node_int=new CNodeInt(randArr[q]); p_int_List.Add(p_node_int); } //--- save the list into the file int file_ha=FileOpen("List_data.bin",FILE_WRITE|FILE_BIN); p_int_List.Save(file_ha); FileClose(file_ha); p_int_List.FreeMode(true); p_int_List.Clear(); //--- load the list from the file file_ha=FileOpen("List_data.bin",FILE_READ|FILE_BIN); p_int_List.Load(file_ha); int Loaded_List_size=p_int_List.Total(); PrintFormat("As much as many nodes loaded from the file: %d",Loaded_List_size); //--- free the memory delete p_int_List;
После запуска скрипта на графике в Журнале были выведена такая строка:
ND 0 11:59:35 test_MQL5_List (EURUSD,H1) As many as 1000 nodes loaded from the file.
Таким образом, были реализованы методы ввода и вывода члена-данных узла типа CNodeInt.
В следующем разделе будут приведены примеры того, как можно использовать списки в своей работе на языке MQL5 для решения поставленных задач.
4. Примеры использования списков в MQL5
В предыдущем разделе при рассмотрении методов списочного класса CList Стандартной библиотеки я приводил несколько примеров.
Теперь вниманию читателя предлагаю случаи использования списка, где решается какая-то узкая специфическая задача. И здесь снова не могу не вспомнить о преимуществе списка, как контейнерного типа данных. Эксплуатируя гибкость списка, можно эффективно работать с кодом.
4.1 Обработка графических объектов
Представьте себе, что нужно на чарте программным образом создавать графические объекты. Они могут попадать на график по разным причинам, а сами объекты могут быть различными.
Я вспоминаю один случай, когда именно список помог мне в работе с графическими объектами. И сейчас об этом хотел бы рассказать.
Стояла передо мной задача создания вертикальных линий по заданному условию. Условие заключалось в том, что вертикали ограничивали определённый промежуток времени. Причём временной промежуток от случая к случаю менял свою длительность. И не всегда он был окончательно сформирован.
Изучал я поведение скользящей средней (EMA21) и для этого приходилось собирать статистику.
В частности, меня интересовала продолжительность наклона мувинга. Так, для нисходящего движения точка начала хода идентифицировалась так: регистрировался отрицательный переход мувинга (т.е. уменьшение значения) и отрисовывалась вертикаль. На рис. 17 для пары EURUSD на часовом таймфрейме такая точка найдена 5 сентября 2013 в момент открытия свечи в 16:00.
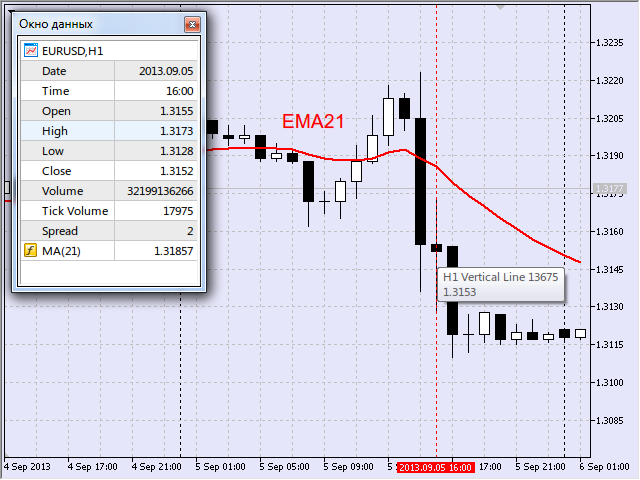
Рис.17 Первая точка нисходящего отрезка
Вторая точка, которая сигнализировала об окончании искомого движения, находилась по обратному принципу: регистрировался положительный переход мувинга, т.е. увеличение значения (рис. 18).
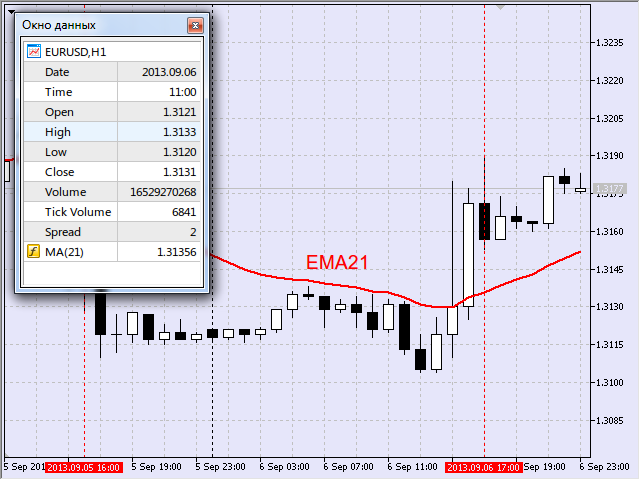
Рис.18 Вторая точка нисходящего отрезка
Таким образом, искомый отрезок начинался 5 сентября 2013 в 16:00, а заканчивался 6 сентября 2013 в 17:00.
Систему поиска различных отрезков можно создать более сложную или простую. Здесь дело не в этом. А скорее в том, что данная методика работы с графическими объектами и попутного сбора статистики касается одного из главных преимуществ списка - гибкости состава.
Что касается текущего примера, то для начала я создал узел типа CVertLineNode, который отвечает за 2 графических объекта "вертикальная линия".
Определение класса выглядит следующим образом:
//+------------------------------------------------------------------+ //| Класс CVertLineNode | //+------------------------------------------------------------------+ class CVertLineNode : public CObject { private: SVertLineProperties m_vert_lines[2]; // массив структур свойств вертикальной линии uint m_duration; // продолжительность фрейма bool m_IsFrameFormed; // флаг формирования фрейма public: void CVertLineNode(void); void ~CVertLineNode(void){}; //--- set-методы void SetLine(const SVertLineProperties &_vert_line,bool IsFirst=true); void SetDuration(const uint _duration){this.m_duration=_duration;}; void SetFrameFlag(const bool _frame_flag){this.m_IsFrameFormed=_frame_flag;}; //--- get-методы void GetLine(SVertLineProperties &_vert_line_out,bool IsFirst=true) const; uint GetDuration(void) const; bool GetFrameFlag(void) const; //--- отрисовка линии bool DrawLine(bool IsFirst=true) const; };
Этот узловой класс по существу описывает некоторый фрейм (здесь трактую это понятие как ограниченное двумя вертикалями некоторое число свечей). Границы фрейма представлены парой структур свойств вертикальной линии, продолжительностью и флагом формирования.
Также класс имеет несколько set- и get-методов в добавление к стандартным конструктору и деструктору. И ещё есть метод отрисовки самой линии на графике.
Итак, позвольте снова напомнить, что в моём примере считать сформированным узел вертикалей (фрейм) можно тогда, когда есть первая вертикаль, регистрирующая понижение мувинга, и вторая, регистрирующая повышение мувинга.
С помощью скрипта Stat_collector.mq5 я отобразил на графике все фреймы и подсчитал, какой количество узлов (фреймов) отвечает тому или иному лимиту продолжительности на последних 2-ух тысячах баров.
Для примера создал 4 списка, в который мог бы попасть любой фрейм. Первый список включал фреймы, где число свечей не превышало 5, второй - 10, третий - 15, четвёртый - без лимита.
NS 0 15:27:32 Stat_collector (EURUSD,H1) =======List #1======= RF 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 5 ML 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 65 HK 0 15:27:32 Stat_collector (EURUSD,H1) OO 0 15:27:32 Stat_collector (EURUSD,H1) =======List #2======= RI 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 10 NP 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 15 RG 0 15:27:32 Stat_collector (EURUSD,H1) FH 0 15:27:32 Stat_collector (EURUSD,H1) =======List #3======= GN 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 15 FG 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 6 FR 0 15:27:32 Stat_collector (EURUSD,H1) CD 0 15:27:32 Stat_collector (EURUSD,H1) =======List #4======= PS 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 20
В итоге на графике получилась такая картинка (рис. 19). Для удобства восприятия вторую вертикаль фрейма выделил синим цветом.
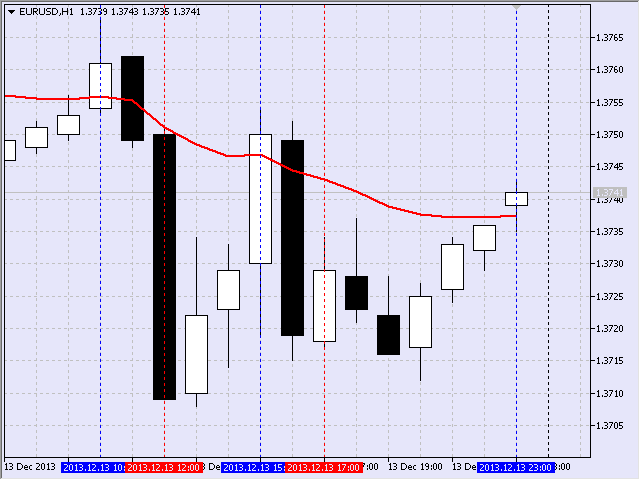
Рис.19 Отображение фреймов
Любопытно, что последний фрейм был сформирован в последний час пятницы 13 декабря 2013. Он попал во второй список, т.к. его продолжительность была равна 6 часам.
4.2 Обработка виртуальной торговли
Представьте, что нужно сделать такой советник, который бы реализовывал, что называется, в одном тиковом потоке несколько независимых стратегий относительно одного инструмента. Понятно, что в реальности единовременно может быть реализована только 1 стратегия на одном инструменте. И все остальные стратегии могут носить виртуальный характер. Поэтому сразу скажу, что такая идея реализуется именно для целей тестирования и оптимизации торговой идеи.
Здесь не могу не сослаться на фундаментальную статью, которая подробно описывает базовые понятия, относящиеся как трейдингу в общем, так и к терминалу MetaTrader 5 в частности: "Ордерa, позиции и сделки в MetaTrader 5".
Так вот, если при решении данной задачи использовать торговую концепцию, систему управления торговыми объектами и методологию хранения информации о торговых объектах, принятые в среде MetaTrader 5, то наверное необходимо подумать о создании виртуальной базы данных.
Позвольте напомнить, что разработчик разделяет все торговые объекты на ордерa, позиции, сделки и исторические ордерa. Критический взгляд скажет, что термин "торговый объект" автор ввёл в употребление самовольно. И будет прав...
Предлагаю для виртуальной торговли использовать аналогичный подход и получать следующие виртуальные торговые объекты: виртуальные ордера, виртуальные позиции, виртуальные сделки и виртуальные исторические ордерa.
Думаю, что данная тема заслуживает более детального и глубокого обсуждения. А пока, вспоминая предмет статьи, хочу сказать, что именно контейнерные типы данных, и списки в том числе, могут облегчить жизнь программисту при реализации виртуальных стратегий.
Представьте, что появилась виртуальная позиция, которая естественно не может находиться на стороне торгового сервера. Значит, всю информацию о ней нужно сохранять на стороне терминала. Роль базы данных здесь может играть список, состоящий с свою очередь из нескольких списков, один из которых будет включать узлы виртуальной позиции.
Если воспользоваться снова подходом разработчика, то классы виртуальной торговли могут выглядеть примерно так:
Класс/группа |
Описание |
CVirtualOrder |
Класс для работы с виртуальным отложенным ордером |
CVirtualHistoryOrder |
Класс для работы с виртуальным "историческим" ордером |
CVirtualPosition |
Класс для работы с виртуальной открытой позицией |
CVirtualDeal |
Класс для работы с виртуальной "исторической" сделкой |
CVirtualTrade |
Класс для совершения виртуального торговых операций |
Таблица 1. Классы виртуальной торговли
Не буду подробно рассматривать, из чего может состоять любой из классов виртуальной торговли. Но наверное он может включать в себя все или почти все те же методы, что и обычный торговый класс. Тут отмечу такой нюанс, что разработчик использует класс не самого торгового объекта, а его свойств.
Итак, чтобы задействовать списки в своих алгоритмах, нужны ещё и узлы. Поэтому придётся класс виртуального торгового объекта обернуть в узел.
Пусть узел виртуальной открытой позиции будет относиться к типу CVirtualPositionNode. Само определение этого типа изначально могло бы выглядеть следующим образом:
//+------------------------------------------------------------------+ //| Класс CVirtualPositionNode | //+------------------------------------------------------------------+ class CVirtualPositionNode : public CObject { protected: CVirtualPositionNode *m_virt_position; // указатель на виртуальную позицию public: void CVirtualPositionNode(void); // конструктор по умолчанию void ~CVirtualPositionNode(void); // деструктор };
И теперь, когда виртуальная позиция будет открыта, то можно будет добавлять её в список виртуальных позиций.
Заметил бы ещё, что при таком подходе к работе с виртуальными торговыми объектами пропадает потребность в обращении к кэшу, потому как сама база данных будет храниться в оперативной памяти. Конечно, можно реализовать её хранение и на других носителях.
Заключение
В данной статье я стремился продемонстрировать преимущества такого контейнерного типа данных, как "список". Не обошлось и без упоминания недостатков. В любом случае, надеюсь, что материал будет полезен для тех, кто изучает ООП в общем, и один из его основополагающих принципов - полиморфизм - в частности.
Расположение файлов:
На мой взгляд, удобнее всего создать и хранить файлы в папке проекта. Например, путь может быть таким: %MQL5\Projects\UserLists. Именно по такому пути я сохранял все исходники. Если использовать стандартные каталоги расположения, то в коде некоторых файлов потребуется изменить способ обозначения файла включения (с кавычек на угловые скобки).
| # | Файл | Путь | Описание |
|---|---|---|---|
| 1 | CiSingleNode.mqh | %MQL5\Projects\UserLists | Класс узла для односвязного списка |
| 2 | CDoubleNode.mqh | %MQL5\Projects\UserLists | Класс узла для двусвязного списка |
| 3 | CiUnrollDoubleNode.mqh | %MQL5\Projects\UserLists | Класс узла для двусвязного развёрнутого списка |
| 4 | test_nodes.mq5 | %MQL5\Projects\UserLists | Скрипт примеров работы с узлами |
| 5 | CiSingleList.mqh | %MQL5\Projects\UserLists | Класс односвязного списка |
| 6 | CDoubleList.mqh | %MQL5\Projects\UserLists | Класс двусвязного списка |
| 7 | CiUnrollDoubleList.mqh | %MQL5\Projects\UserLists | Класс двусвязного развёрнутого списка |
| 8 | CiCircleDoublList.mqh | %MQL5\Projects\UserLists | Класс кольцевого двусвязного списка |
| 9 | test_sList.mq5 | %MQL5\Projects\UserLists | Скрипт примеров работы с односвязным списком |
| 10 | test_dList.mq5 | %MQL5\Projects\UserLists | Скрипт примеров работы с двусвязным списком |
| 11 | test_UdList.mq5 | %MQL5\Projects\UserLists | Скрипт примеров работы с двусвязным развёрнутым списком |
| 12 | test_CdList.mq5 | %MQL5\Projects\UserLists | Скрипт примеров работы с кольцевым двусвязным списком |
| 13 | test_MQL5_List.mq5 | %MQL5\Projects\UserLists | Скрипт примеров работы с классом CList |
| 14 | CNodeInt.mqh | %MQL5\Projects\UserLists | Класс узла для типа integer |
| 15 | CIntList.mqh | %MQL5\Projects\UserLists | Класс списка для узлов CNodeInt |
| 16 | CRandom.mqh | %MQL5\Projects\UserLists | Класс генератора случайных величин |
| 17 | CVertLineNode.mqh | %MQL5\Projects\UserLists | Класс узла для обработки фрейма вертикалей |
| 18 | Stat_collector.mq5 | %MQL5\Projects\UserLists | Скрипт примера сбора статистики |
Используемая литература:
- Л.Кландер, М.Михаэлис, А.Фридман, Х.Шильдт C/C++. Архив программ-М.:ЗАО "Издательство БИНОМ",2001 г.-640 с.: ил.
- В.Д.Далека, А.С.Деревянко, О.Г.Кравец, Л.Е.Тимановская Модели и cтруктуры данных. Учебное пособие-Харьков:ХГПУ,2000.-241с.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
 Работа с GSM-модемом из эксперта на MQL5
Работа с GSM-модемом из эксперта на MQL5
 Создание мультивалютного мультисистемного советника
Создание мультивалютного мультисистемного советника
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Здравствуйте,
Пытаюсь скомпилировать test_MQL5_List.mq5 , получаю следующие ошибки:
'm_head' - член константного объекта не может быть изменен CiSingleList.mqh 504 9
'm_tail' - член константного объекта не может быть изменен CiSingleList.mqh 505 9
'm_size' - член константного объекта не может быть изменен CiSingleList.mqh 496 9
Вот исправленный код. Пожалуйста, замените старую версию.
Ошибка заключалась в объявлении некоторых методов константными, в то время как они таковыми не являются.
Вот исправленный код. Пожалуйста, замените старую версию.
Ошибка заключалась в объявлении некоторых методов константными, в то время как они таковыми не являются.
Ошибок больше нет.
Спасибо Деннис.