
Red neuronal en la práctica: Esbozando una neurona

Introducción
Hola a todos, y bienvenidos a un nuevo artículo sobre Redes Neuronales.
En el artículo anterior Red neuronal en la práctica: Pseudo inversa (II), mostré la importancia y la razón por la cual se desarrollan sistemas de cálculo dedicados. En este artículo iniciaremos una nueva fase sobre redes neuronales. Desarrollar material para esta fase no es algo sencillo. Aunque pueda parecerlo, es difícil explicar de manera simple un tema que genera tanta confusión.
¿Y qué veremos en esta fase? Bueno, aquí quiero mostrarte cómo una red neuronal aprende. Hasta ahora, hemos visto cómo una red neuronal puede establecer una correlación entre diferentes datos. Sin embargo, lo que hemos visto hasta el momento es útil cuando ya tienes una base de datos con información y registros previamente filtrados y seleccionados, permitiendo así que la red neuronal encuentre la mejor solución para representar esos datos. Pero, ¿cómo una red neuronal puede establecer una correlación cuando los datos no están filtrados? Esta es la parte donde muchos, con toda seguridad, piensan que una red neuronal es una entidad inteligente, ya que imaginan que está aprendiendo a clasificar las cosas.
Y es precisamente por esta mala interpretación que las personas tienen sobre el tema que resulta tan difícil de explicar. Muchas veces, quienes buscan entenderlo no tienen los conocimientos básicos sobre cómo clasificar diferentes tipos de información, aunque estos datos tengan alguna correlación entre sí. Esta es la parte confusa, no para quienes trabajan con esto, sino para aquellos que no lo hacen. Al explicar algo, el oyente puede llegar a pensar en algo completamente desconectado de la explicación original, y por esta razón, no logran comprender realmente cómo una red neuronal clasifica la información.
Ten en cuenta lo siguiente: en ningún momento estoy diciendo que una red neuronal aprende, ni que posee algún tipo de inteligencia oculta. Cualquiera que piense así estará completamente equivocado. Una red neuronal no es más que una gran ecuación matemática. Y esta ecuación, de alguna manera que veremos en esta fase de los artículos, entiende los datos y los clasifica de alguna forma. Una vez que los datos están clasificados, cualquier información similar o cercana a algo ya clasificado será considerada como un dato con cierto nivel de probabilidad de estar relacionado con algo ya conocido.
Sobre esta cuestión, ya hablé en artículos anteriores. Pero aquí veremos algo un poco diferente. No mucho, solo un poco, pero igualmente interesante. Así que comencemos por lo más básico y avanzaremos hasta construir una red neuronal basada en las neuronas que crearemos al inicio.
Lo más básico de lo básico
Para entender realmente cómo una red neuronal aprende, a medida que le vamos mostrando información, te pido, querido lector, que olvides todo lo que crees saber sobre inteligencia artificial y redes neuronales. Gran parte de lo que piensas que sabes, muy probablemente es pura tontería o información errónea, especialmente si lo has visto en sitios de noticias o fuentes similares. El tema de redes neuronales se hizo público principalmente porque algunos empresarios vieron una oportunidad para ganar dinero. Pero las redes neuronales llevan décadas en desarrollo. No es algo reciente, ni funciona como muchos dicen. Son herramientas útiles, pero orientadas principalmente a quienes realmente se interesan por la programación.
Básicamente, cualquier red neuronal, y puedes entenderlo como inteligencia artificial, se basa en un concepto muy simple, del cual ya hablé en los artículos anteriores. Aquí nos adentraremos más en este concepto. Se trata de la recta secante. No importa lo que digan, todo en redes neuronales se reduce a este concepto: encontrar una recta secante que se aproxime a la recta tangente. Así de simple.
En los artículos anteriores omitimos esta parte y fuimos directamente a encontrar la recta tangente. De ahí provienen las fórmulas que mostramos anteriormente. Su objetivo es crear un atajo hacia la recta tangente. Todo ese material se refiere a un hecho muy específico: cuando tenemos en nuestra base de datos información filtrada y seleccionada. Cuando esto sucede, no necesitamos la recta secante, vamos directamente a la tangente, generando la fórmula que mejor representa el contenido de esa base de datos, o si lo prefieres, de ese "banco de conocimiento". Así, cuando un programa de búsqueda consulta este banco, nos puede devolver un resultado casi perfecto sobre cierta información. Este tipo de programa es lo que muchos llaman inteligencia artificial. Sin embargo, hay casos en los que no tenemos todas las informaciones necesarias para construir el banco de datos o banco de conocimiento. Aun así, necesitamos que la red neuronal establezca alguna correlación entre los datos que se están incorporando al banco. Este mecanismo es lo que llamamos entrenamiento. Es decir, tienes un montón de datos aparentemente sin correlación, pero que puedes clasificar de forma sencilla. Entonces, envías estos datos de manera aleatoria a la red neuronal y le enseñas cómo encontrar la famosa recta tangente. Al final, esto generará una ecuación matemática. Esta ecuación es la que permitirá que la inteligencia artificial pueda generar resultados a partir de ella. Esto se verifica cuando los datos desconocidos para la red, pero clasificados por un humano, son utilizados para probar dicha ecuación.
No sé si tú, querido lector, has logrado comprender cómo funciona todo esto. Pero intentaré dejarlo más claro, para aquellos que no son programadores, pero ya tienen experiencia en el mercado financiero. Cuando comienzas en el mercado, lo primero que debes hacer es el llamado BackTest. Eliges un modelo que vas a operar, vas al gráfico y buscas todas las señales en las que ese modelo aparece. Esto equivale a la fase de entrenamiento de la red neuronal. Una vez que el modelo ha sido completamente probado dentro de un período de tiempo, pasas a la fase de testeo. Aquí seleccionas días aleatorios y verificas si el modelo se presentó o no. Si logras reconocer el modelo, incluso cuando parece no estar presente, significa que lo has comprendido, y puedes expresarlo con una fórmula matemática. Ahora bien, llega la fase tres, que es el testeo a ciegas. Entras en el mercado y, usando una cuenta demo, verificas si esa fórmula matemática funciona o no para identificar tu modelo de operación. Si ya has hecho esto, sabrás que nunca es 100% exacto. Siempre hay un margen de error en el sistema. Pero si ese margen es pequeño, está bien: tu fórmula funciona.
Esto es lo que una red neuronal intenta hacer. Encontrar esa fórmula, ya sea para el reconocimiento de escritura, rostros, moléculas, plantas, animales, sonidos, imágenes o cualquier otra cosa que desees que reconozca.
Entonces vamos a un nuevo tema, para comenzar a ver cómo podemos hacer esto.
Una neurona
Entendiendo el tema anterior, comencemos por lo más sencillo que se puede crear: una única neurona. Pero no te desanimes pensando que una sola neurona no tiene utilidad alguna. Verás cómo todo crecerá rápidamente. No intentes apresurarte. Tómalo con calma, querido lector. Comienza despacio, entendiendo qué hace cada cosa para realmente comprender cuando estemos construyendo arquitecturas neuronales.
Muy bien, vamos a empezar con el siguiente código.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ void OnStart() { Print("The first neuron..."); } //+------------------------------------------------------------------+
Este código, que parece poco interesante, simplemente imprime un mensaje en el terminal. Eso es todo. Pero ten en cuenta que se trata de un script, aunque también podría convertirse en un servicio. Por ahora, lo dejaremos como un simple script. Muy bien, ¿qué necesita hacer una neurona? Puedes pensar en mil cosas distintas, pero intenta reducirlas a una sola cosa que todas tengan en común. Esta es la primera parte, reducir todo a una única tarea que la neurona debe realizar.
Bien, una neurona necesita saber cómo realizar un cálculo. Esto es importante, ya que nos debe devolver alguna información. Sin embargo, no sabemos aún qué cálculo es, solo tenemos los datos necesarios para entrenar la neurona. Así que el código anterior se modifica para convertirse en el código que se muestra a continuación.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; Print("The first neuron..."); } //+------------------------------------------------------------------+
Obviamente, al observar los datos de entrenamiento, notas de inmediato que existe un patrón allí. Es decir, estamos multiplicando el primer número por dos. Sin embargo, nuestra neurona no sabe esto. Pero queremos que aprenda a desarrollar una ecuación, de modo que pueda responder cuando le proporcionemos un número. Entonces, nuestra neurona utilizará la ecuación que ha creado, y nos devolverá una información, basada en el conocimiento que ha generado.
Genial, pero ¿cómo haremos para que la neurona encuentre dicha fórmula? Detalle: No vale usar el conocimiento mostrado en los artículos anteriores. Entonces, querido lector, ¿cómo podemos hacer que la neurona encuentre la ecuación que mejor represente los datos de entrenamiento?
Una vez más, puedes enfrentarte a algo que genera mucha confusión. Lo que haremos es simplemente indicarle a la neurona que use un valor aleatorio cualquiera, y con base en ese valor intente encontrar la ecuación matemática. Esta es la parte donde muchos se confunden. No estamos diciéndole a la neurona que busque el valor que debe ser usado en la multiplicación. Además, podríamos estar usando una suma, una división o cualquier otra cosa. Incluso datos aleatorios. Lo que queremos es que la neurona busque y encuentre una ecuación matemática, no un valor específico. El valor que permitimos que comience usando es simplemente un punto de partida. Nada más. Luego mejoramos el código un poco más, como puedes ver a continuación.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; double weight; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; } //+------------------------------------------------------------------+
Bien, estamos avanzando. Pero antes, entendamos algo. Normalmente, en la función MathSrand, usamos un valor proveniente del reloj del sistema. Esto es para que, cada vez que iniciemos el generador de números aleatorios, comience con un valor diferente. Un recordatorio: los números generados no son realmente aleatorios, son pseudoaleatorios. Es decir, aunque no sean verdaderamente aleatorios, es difícil encontrar un patrón que permita saber cuál será el próximo número en la lista. Pero como queremos que siempre comience con algún valor, indicamos ese valor a MathSrand. Así podremos probar las cosas con más calma. Pero lo que nos interesa es el valor que está en la variable weight. Este es el valor que le indica a nuestra neurona si está en el camino correcto o en el equivocado. Como es un valor aleatorio, todavía no tiene una dirección definida.
Ahora presta atención a otro hecho. El valor de weight está entre 0 y 1, porque en la macro, el valor de la función rand se está dividiendo por el valor máximo que puede devolver rand. Consulta la documentación para más detalles sobre esto. Pero estoy limitando weight entre 0 y 1 para facilitar lo que veremos después. Sin embargo, nada te impide usar el valor de rand directamente; solo será necesario hacer algunos ajustes en el futuro, cuando veamos otras cuestiones de cálculo.
Muy bien, ahora vamos a empezar a hacer que las cosas sucedan. Nuestra neurona está comenzando a tomar forma. Pero para avanzar, primero necesitamos decirle a la neurona que use una fórmula matemática inicial. Observa que esto no surge de la nada. Debemos decirle a la red neuronal cómo debe funcionar. No es capaz de crearse por sí sola. Bien, si tienes un conocimiento mínimo de cálculos matemáticos, sabes que todo, absolutamente todo, desde lo más simple hasta lo más complejo en los polinomios, puede resumirse en una sola cosa. Esa cosa son las derivadas. Pero no cualquier derivada. Estamos buscando una muy específica, que sea tan simple como sea posible. En los artículos anteriores, mostré que la ecuación de la recta es la ecuación más simple posible. Cualquier polinomio o ecuación puede resumirse en esta ecuación de la recta si derivamos la ecuación hasta su límite máximo. En el último caso, podríamos llegar a una constante. Pero lo que necesitamos es una derivada que podamos usar como cálculo mínimo. Así que volvemos a la ecuación que se muestra a continuación.
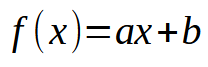
Aquí no importa el orden de esta derivada. Lo que nos importa es que si la simplificamos más, llegamos a una constante. Y eso no es lo que queremos, ya que una constante no nos sirve de nada. Sin embargo, el valor de la constante < b >, que es el punto de intersección, deberá pensarse en este primer momento como igual a cero. Mientras que el valor de la constante < a >, que es el coeficiente angular, usaremos el valor que esté en la variable weight. Con esto, tenemos un nuevo código como se muestra a continuación.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; double weight, fx, x; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; for (uint c = 0; c < Train.Size() / 2; c++) { x = Train[c][0]; fx = x * weight; Print("Actual: ", fx , " expected: ", x); } } //+------------------------------------------------------------------+
Ok, al ejecutar este código verás en el terminal de MetaTrader una imagen similar a la que se muestra más abajo.
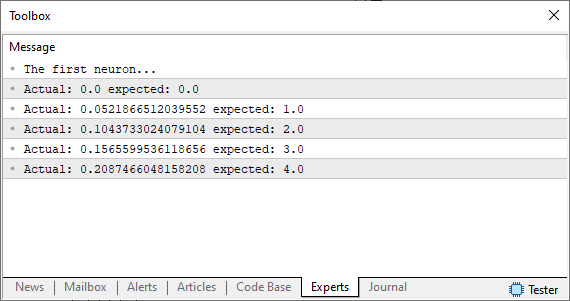
Observa que el hecho de que estemos usando una suposición, que es ese número aleatorio, no está ni cerca de lo que queremos o esperábamos obtener. Entonces, ¿cómo podemos mejorar esto? Bien, nuestra neurona básica está bien encaminada. Lo que necesitamos hacer ahora es básicamente usar el mismo principio que vimos en los artículos anteriores. Es decir, definiremos un sistema de error para que la neurona sepa hacia dónde avanzar para encontrar la ecuación más adecuada. Hacer esto es algo bastante simple, como puedes notar en el código siguiente.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ void OnStart() { double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; double weight, fx, dx, x, err; const uint nTrain = Train.Size() / 2; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; err = 0; for (uint c = 0; c < nTrain; c++) { x = Train[c][0]; fx = x * weight; Print("Actual: ", fx , " expected: ", x); dx = fx - Train[c][1]; err += MathPow(dx, 2); } Print("Err: ", err / nTrain); } //+------------------------------------------------------------------+
Ok, al ejecutar este código verás algo parecido a la imagen que aparece abajo.
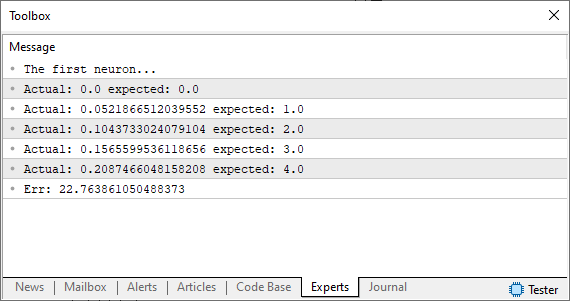
Muy bien, en este punto, estamos en una encrucijada. Esto se debe a que estamos exactamente en ese punto donde hacíamos ajustes manuales para buscar el menor error. Si no sabes de qué estoy hablando, consulta los artículos anteriores para entenderlo. Pero, a diferencia de lo que hacíamos, que era un ajuste manual, aquí forzaremos al ordenador a buscar el mejor ajuste por nosotros. No buscaremos la recta tangente de la manera en que lo hacíamos antes. Buscaremos la recta tangente usando la recta secante. Y a partir de este momento es cuando la máquina comenzará a "enloquecer", pudiendo en algunos momentos converger y en otros divergir de la solución correcta.
Recuerda el siguiente hecho: Queremos hacer que el valor de la variable err disminuya. Y es este hecho lo que permitirá que la máquina "enloquezca". Pero para entender mejor esto, pasemos a un nuevo tema.
Usando la recta secante
En el artículo "Red neuronal en la práctica: Recta Secante" mencioné brevemente que la recta secante es la principal recta en la red neuronal. Allí mostré una figura que puedes revisar a continuación.
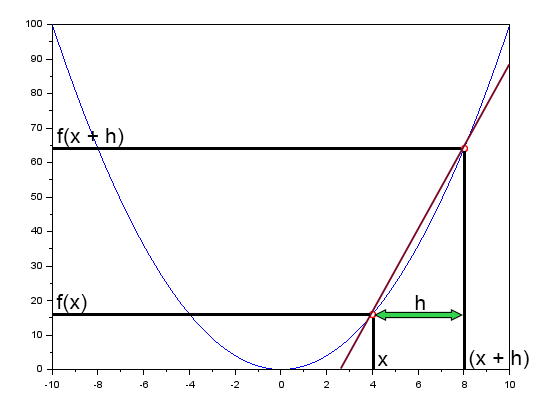
Esta figura muestra la curva de error, así como también una recta. Esta es la recta secante. Al limpiar la figura anterior, dejando en destaque solo la recta secante, podemos ver la imagen siguiente.
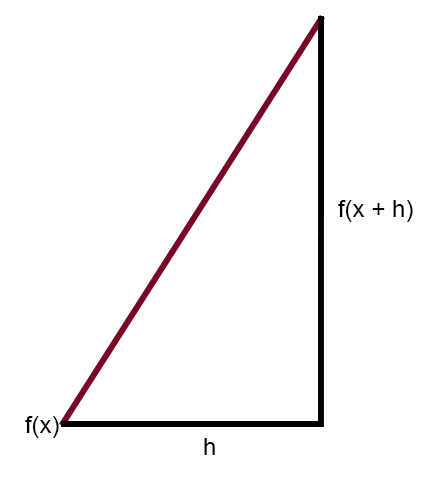
Si formulas esta misma imagen, de modo que el valor de la constante < h > sea igual a cero, llegarás a la siguiente expresión que se muestra a continuación.
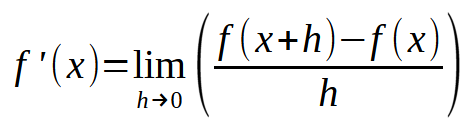
Ahora viene la parte divertida. Esta fórmula que se muestra arriba es precisamente la fórmula mágica de la red neuronal que aprende de sus errores. Es decir, si utilizas esta ecuación, podrás forzar al ordenador a encontrar una ecuación de recta que mejor represente los datos que ingresan a la red neuronal, y con esto forzar a la máquina a aprender a resolver un determinado problema, sea cual sea. No importa qué datos estés introduciendo en la red neuronal, el cálculo será siempre el mismo. Ahora presta atención: el secreto está en usar un valor adecuado para < h >. Si el valor es mayor que un cierto límite, la máquina se volverá "loca" intentando encontrar la mejor ecuación de recta. Si el valor es demasiado pequeño, la máquina tardará muchas horas en encontrar la ecuación más adecuada. Así que un poco de sentido común te ayudará mucho en este momento. No seas demasiado exigente, pero tampoco descuidado. Sé prudente.
¿Cómo vamos a añadir esto a la neurona? Bien, antes de hacerlo, hagamos una pequeña prueba. Observa cómo debe quedar el código.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ double Train[][2] { {0, 0}, {1, 2}, {2, 4}, {3, 6}, {4, 8}, }; //+------------------------------------------------------------------+ const uint nTrain = Train.Size() / 2; const double eps = 1e-3; //+------------------------------------------------------------------+ double Cost(const double w) { double err; err = 0; for (uint c = 0; c < nTrain; c++) err += MathPow((Train[c][0] * w) - Train[c][1], 2); return err / nTrain; } //+------------------------------------------------------------------+ void OnStart() { double weight; Print("The first neuron..."); MathSrand(512); weight = (double)macroRandom; Print("Err: ", Cost(weight)); Print("Err: ", Cost(weight + eps)); } //+------------------------------------------------------------------+
¡Uy! Ahora sí, esto se ha convertido en un programa realmente interesante. Al ejecutarlo, verás algo similar a la imagen siguiente.
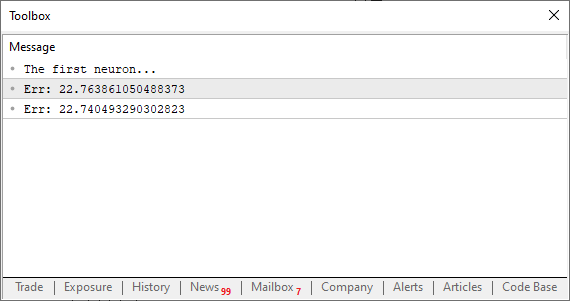
Lo que nos importa aquí es si el valor del error está creciendo o disminuyendo. El valor en sí no nos interesa. Ahora presta atención: el valor de eps es nuestro < h > en la fórmula vista más arriba. Cuanto más se acerque este valor a cero, más cerca estaremos de la recta tangente en cada iteración ejecutada. Esto se debe a que la recta secante comenzará a converger hacia un punto límite. Entonces, lo que necesitamos hacer ahora es algo muy simple: solo necesitamos crear un bucle, de manera que este valor de error, o costo, sea cada vez menor. Llegará un punto en que dejará de disminuir y comenzará a aumentar. En ese momento exacto, el programa deberá darse cuenta y salir del bucle; de lo contrario, entrará en un bucle infinito. Pero también podemos crear otro tipo de limitación para evitar el bucle infinito. Normalmente, pedimos que el bucle realice un cierto número de iteraciones antes de finalizar, en caso de que el programa no logre converger o se vuelva "loco". Pero puede suceder que el programa se vuelva inestable debido al valor utilizado para ejecutar los pasos. Veremos esto en un momento oportuno. Por ahora, no te preocupes por este hecho. Pero independientemente de esto, nada te impide forzar al programa a buscar el menor valor de costo. Depende de ti decidir cuándo terminar el bucle. De cualquier manera, para evitar la fatiga, veamos cómo sería esto en la práctica. Revisa el código a continuación para entender.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. //+------------------------------------------------------------------+ 06. double Train[][2] { 07. {0, 0}, 08. {1, 2}, 09. {2, 4}, 10. {3, 6}, 11. {4, 8}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 2; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w) 18. { 19. double err; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. err += MathPow((Train[c][0] * w) - Train[c][1], 2); 24. 25. return err / nTrain; 26. } 27. //+------------------------------------------------------------------+ 28. void OnStart() 29. { 30. double weight, err; 31. 32. Print("The first neuron..."); 33. MathSrand(512); 34. weight = (double)macroRandom; 35. 36. for(ulong c = 0; c < 10; c++) 37. { 38. err = ((Cost(weight + eps) - Cost(weight)) / eps); 39. weight -= (err * eps); 40. Print(c, " --> ", weight, " :: ", err); 41. } 42. Print("Weight: ", weight); 43. } 44. //+------------------------------------------------------------------+
Al ejecutar este código, podrás ver en el terminal algo similar a la imagen siguiente.
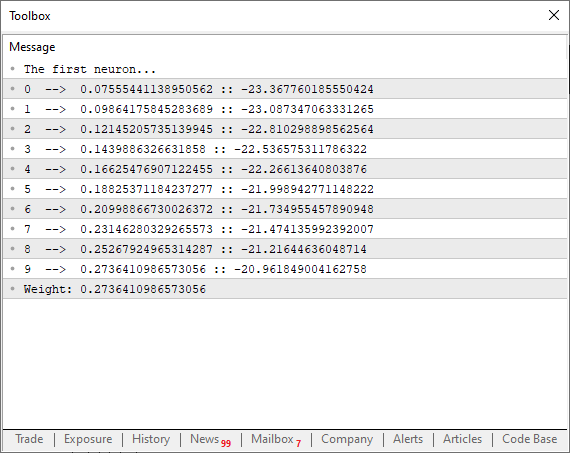
Observa algo interesante que está sucediendo aquí. En la línea 38, estamos ejecutando precisamente el cálculo mostrado más arriba, donde estamos forzando a la recta secante a buscar un punto límite mínimo para que la función logre converger. Sin embargo, nota que en la línea 39 no estoy simplemente modificando el punto en la curva de la función usando únicamente el valor de error o el costo total. ¿Por qué? El motivo es que, si lo haces de esa manera, el programa comenzará a saltar de un lado a otro en la curva parabólica, lo cual no es lo que queremos. Queremos que el valor se modifique de manera suave, sin sobresaltos. ¿Por qué no usamos el valor de eps para ajustar el siguiente punto en la curva de la parábola? La razón es que, si lo hiciéramos así, tendríamos que saber si el error está aumentando o disminuyendo, algo que se vuelve completamente innecesario si realizamos la factorización que se muestra en la línea 39. Además, esto fuerza a la neurona a intentar converger más rápido al inicio del proceso, y conforme se va acercando al valor ideal, la curva de decaimiento comienza a suavizarse, tendiendo así a crear una función de decaimiento logarítmico invertido. Esto es muy bueno, por cierto, ya que lograremos llegar a un valor de error adecuado mucho más rápido.
Ok, pero este mismo código que se muestra arriba puede mejorarse aún más. Podemos añadir algunas otras cosas para analizar mejor lo que está sucediendo. Al mismo tiempo, podemos agregar una prueba extra cuyo objetivo será hacer que el bucle finalice tan pronto como se alcance el punto mínimo de convergencia, incluso antes de que el contador haya alcanzado el número máximo de iteraciones. De esta manera, el nuevo código se puede ver a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. //+------------------------------------------------------------------+ 06. double Train[][2] { 07. {0, 0}, 08. {1, 2}, 09. {2, 4}, 10. {3, 6}, 11. {4, 8}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 2; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w) 18. { 19. double err; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. err += MathPow((Train[c][0] * w) - Train[c][1], 2); 24. 25. return err / nTrain; 26. } 27. //+------------------------------------------------------------------+ 28. void OnStart() 29. { 30. double weight, err, e1; 31. int f = FileOpen("Cost.csv", FILE_COMMON | FILE_WRITE | FILE_CSV); 32. 33. Print("The first neuron..."); 34. MathSrand(512); 35. weight = (double)macroRandom; 36. 37. for(ulong c = 0; (c < ULONG_MAX) && ((e1 = Cost(weight)) > eps); c++) 38. { 39. err = (Cost(weight + eps) - e1) / eps; 40. weight -= (err * eps); 41. if (f != INVALID_HANDLE) 42. FileWriteString(f, StringFormat("%I64u;%f;%f\n", c, err, e1)); 43. } 44. if (f != INVALID_HANDLE) 45. FileClose(f); 46. Print("Weight: ", weight); 47. } 48. //+------------------------------------------------------------------+
La diversión de este código es que es extremadamente interesante, ya que te permite estudiarlo y jugar con él. Me tomé la libertad de hacer que los valores no se muestren en el terminal de MetaTrader 5, sino en un archivo. Al hacerlo, podemos generar un gráfico para estudiar con calma lo que está sucediendo. En este caso, tal como está configurado el código, el gráfico resultante se puede ver a continuación:
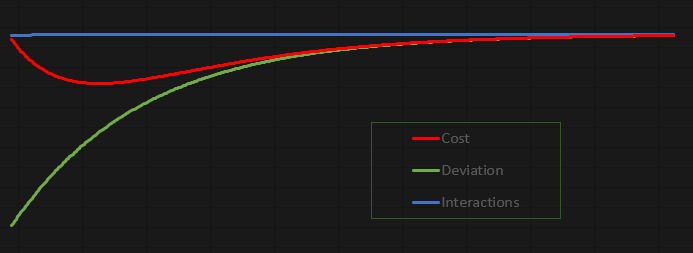
Este gráfico se hizo en Excel, basándose en los valores que se almacenan en el archivo creado por la neurona. Es cierto que la forma en que se está creando el archivo es un poco rudimentaria, pero dado que se trata de una aplicación diseñada para ser lo más didáctica y divertida posible, no veo problema en cómo estamos transfiriendo los datos al archivo.
Consideraciones finales
En este artículo, hemos construido una neurona básica. Aunque sea algo muy simple, y muchos piensen que el código es completamente trivial y sin ningún propósito, quiero que tú, querido lector y entusiasta del tema de redes neuronales, juegues y te diviertas estudiando esta simple neurona. No tengas miedo de modificar el código para entenderlo mejor. El código está en el anexo precisamente para eso, para que logres comprender cómo funciona una neurona básica. Quiero que leas este artículo con calma. Trata de escribir el código desde el principio y prueba cada paso hasta llegar al código final que se presenta en el artículo. Hazlo sin copiar directamente el código, sino creando tu propia versión, asegurándote de que funcione como lo muestro en el artículo. Crea tu propia versión, de manera que la entiendas, no trates de imitarme, sino de obtener el mismo resultado: un valor que establezca una correlación entre los datos presentes en el array de entrenamiento. Así de simple.
Como g el código está en el anexo, quiero darte algunos consejos sobre puntos que puedes modificar, lo cual será bastante interesante en este primer contacto. Recuerda estudiar cada cambio con calma. El primer punto es el array de entrenamiento que se encuentra en la línea seis del código del anexo. Puedes colocar valores diferentes allí para que la neurona intente encontrar alguna correlación entre ellos.
Otro punto muy interesante es cambiar el valor de la constante en la línea 15. Cámbialo por valores mayores o menores y observa el resultado que la neurona reporta al final de su trabajo. Notarás que los valores menores toman más tiempo de procesamiento, pero como compensación, el resultado se aproxima mucho más al valor ideal.
Otro punto igualmente interesante para modificar está en la línea 35, donde estamos asignando un peso que varía entre cero y uno. Pero puedes modificarlo multiplicando el valor devuelto por la macro. Por ejemplo, prueba poner en la línea 35 algo como lo que se muestra a continuación.
weight = (double)macroRandom * 50;
Notarás que las cosas serán muy diferentes, simplemente por haber cambiado el peso inicial con el que la neurona comenzará. Y cuando te sientas completamente seguro de lo que está sucediendo, cambia el código de la línea 34 por lo que se indica más abajo.
MathSrand(GetTickCount());
Al hacer esto, notarás que las cosas son mucho más interesantes de lo que muchos suelen decir. Pero, lo más importante es que comenzarás a entender cómo una simple neurona en una red neuronal puede aprender algo. En el próximo artículo, convertiremos esta simple neurona en algo aún más interesante. Así que, antes de pasar al siguiente artículo, estudia y juega mucho con este código. Porque esto recién empieza.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/13744
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso