What to feed to the input of the neural network? Your ideas... - page 30
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
A normal network will sort the necessary and unnecessary data by itself.
The main thing is what to teach!
Learning with a teacher is not a good fit here. Networks with backward error propagation are simply useless.
Is there an understanding of how the mechanism should be trained?
So, basically, we go over weights, fit them to a graph.
But, at the same time, there is another set of weights, a set that is not just fitted to this graph, but "fitted" to the next one, and the next one, and the next one, and so on. And it ends up "breaking" somewhere out there, far ahead.
Here, learning is presented as finding the difference between a set of sets that don't work, and those that do. And, further, the trained network doesn't need any more "fine-tuning", it already edits the numbers of weights by itself.
What other ideas are there about what machine learning looks like, how it is presented?
A normal network will sort the necessary and unnecessary data by itself.
The main thing is what to teach!
Learning with a teacher is not a good fit here. Networks with backward error propagation are simply useless.
The network will not sort anything - the network will select those variables that best fit the training sample.
A large number of variables is a major evil
The network will not sort anything - the network will select those variables that best fit the training sample.
Alarge number of variables is the main evil
For memorising the path - the best
For learning (in the current understanding) - the most evil.
train two grids - one in buy only, one in sell.
switch on both :-)
then add a collision resolution network (or just alg.) so that they do not trade in different directions at the same time.
I've been thinking, you could script the markup. Write down all the dates where entry and close occurs. If the optimiser sets weights that give a signal outside these dates, we open with the maximum lot to lose. Or do not open at all.
It turns out that it will be a method with a teacher, but by MT5 forces
Neural network can work even on 1 value of one trait, if you select the parameters
but we need grail conditions (dts) with almost no spread. I think that any TS will work on such conditions :)
Is there any way to describe requiring the machine to open a position when it sees fit?
How would we explain it: we force the neural network to open positions ourselves.... "if, then." We specify when to open "If the output of the neural network is greater than 0.6", "if of the two output neurons, the top one has the higher value". "If - then, if - then."
And so on.
And here, so that there are no opening boundaries, conditions. There are inputs, there are weights. Inside the neural network there is some kind of mush brewing. Is it possible to somehow describe to the machine, based on its work with inputs and weights (to be searched in the optimiser), to open positions when it decides to do so?
How can this condition be prescribed? So that it chooses when to open positions.
UPD
Add some second neural network. Then how to link it...
Or several neural nets. Some way to link them.
Or is there some other way to describe such a task
UPD
Add an experience block. Then it turns out to be some kind of q-table.
And we need everything to be inside the neural network.
... How do I set this condition? For it to choose when to open....
I can help you here: give buy and sell signals at the same time, and the neuron will decide where to go. Don't thank me...
For the first time I managed to get a set in the top by a worker. Moreover, a worker for as much as 3 years forward.
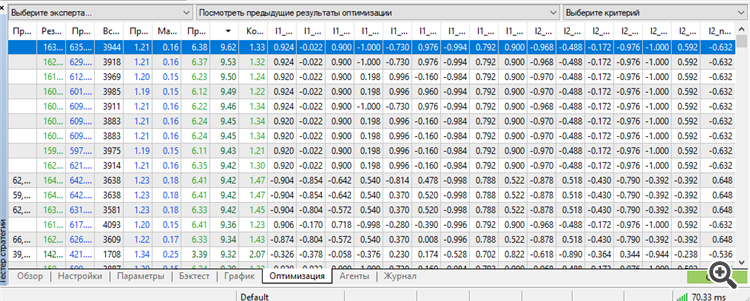
Training for 9 years from 2012 to 2021
Forward 2021
Forward 2022
Forward 2023
All 3 years of forward 2021-2023.12.13.
True, we had to use the full potential of MT5: the maximum number of optimisable parameter-weights. More - MT5 swears.
Eh, if it was possible to optimise more parameters, it would be more interesting to know the results. I am stumped by this inscription "64 bits to long" or something like that. If genetic algorithm allows to optimise even more, it would be interesting to know how to bypass this limitation
if more parameters could be optimised
Moved from Toyota to an old sports car
Since MT5 is limited in the number of optimisable parameters, I switched to NeuroPro 1999, from the article here - Neural Networks for Free and Easy - Connecting NeuroPro and MetaTrader 5.
I increased the architecture in quantity: in MT5 it was 5-5-5-5, and here it is 10-10-10, and the training is already real (to be more precise - standard, by the method of error back propagation and other internal features inside the programme. The author of the programme spit on it and is not even going to update the rarity - based on his answers to my questions, he has no interest in developing NeoroPro, introducing multithreading, modern methods, etc.).
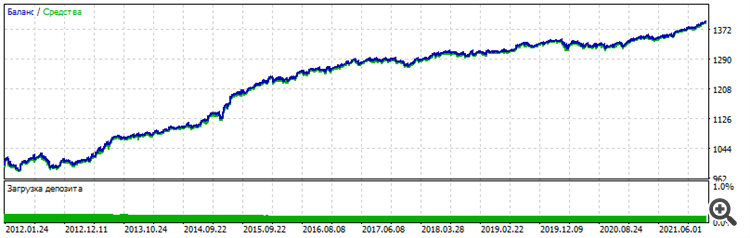


Surprisingly, the programme can produce results similar to MT5. But it's easy to break the forward - add another neuron/add another layer/reduce the data size by a month and everything will go to random. That is, we need to find some golden mean between overtraining and undertraining.
Moreover, after training the model still does not work. We need post-optimisation of MT5 parameters - opening thresholds for BUY and SELL. Something similar was done by NeuroMachine from the creators of MeGatrader in its time. That is, some kind of post-processing.
Without it, the balance chart barely moves upwards on the taught period and drains on the forward.
Conditions have changed: 6 entries already, EURUSD H1, at opening prices, 10 years of teaching from 2012 to 2022.
Forward - last two years 2022-2023-12-16
Overall chart - you can see that similar stability, character is identical, it doesn't look like luck
I will try other pairs and increase the architecture to completely exclude the luck factor and confirm the performance of the method.
Well and most importantly - postoptimisation - the working set was in the top in sorting by the "Recovery factor" parameter. If it doesn't at a later date - there will be no confirmation. Again I will be stuck in random, luck, luck.
The method of creative poking led me to an idea:
A layer of neurons in the classical sense is a heap of malaise.
Especially the first layer, which receives input data. The most important layer.
The input is heterogeneous data. Or homogeneous - it doesn't matter. Every digit, every number is a representation of form, content, dependency - in the original. It's like a source, like a film, like a photograph.
And imagine, an ordinary neural network takes each number, each attribute - and stupidly sums it up, additionally multiplied by weight, into one pile of rubbish, called an adder.
It's like blurring a photo and trying to restore the image - nothing will work. That's it. The source is lost, erased. It's gone. All restoration is reduced to one thing - additional drawing. That's how modern neural networks work to restore old photos, or to improve them, upscale them - it just draws them out. Just creative work of neural network, it has no source, it draws what it had in its database of pictures once, something similar, even if by 99%, but not the source.
And so, we feed prices, price increments, transformed prices, indicator data, numbers in which some figure, some state on the chart is encoded - and it takes and stupidly erases the uniqueness of each number, throwing all numbers into one pit and making a conclusion (output) on the basis of this huge rubbish, in which it is impossible to make out what is what.
Such a number of adder from now on will be identical to different figures, with different numbers. That is, we have two figures - they are displayed in a different sequence of numbers. The contents of these figures are different, but the volume can be the same. The volume is numerical. And then in the adder this heap-mala can mean both one figure and another. We will never know which one exactly - at this stage we have erased the unique information. We smeared it, threw it into one pot, now it's soup.
And if the input is rubbish? Then with 1000% probability the first adder will turn that rubbish into rubbish squared. And with 1000% probability such a neural network will never single out anything from this rubbish, will never find it, will never extract it. Because in this case it does not just dig through the rubbish, it also breaks it in a meat grinder called "next layers".
My layman's approach tells me that we need to change the way we approach architectures and the way we treat inputs.
As a proof - my graphs above. One input, two inputs, three inputs - one neuron, two neurons, three neurons. That's it, the next thing is retraining - memorising the path rather than working on new data.
The second confirmation is retraining itself. The more neurons, the more layers - the worse on new data. That is, with each new layer, with each new neuron, we turn the original data into rubbish squared, and all that is left for the neural network is to simply memorise the path. Which it copes with perfectly well during retraining.
Such a small flight of fancy.