What to feed to the input of the neural network? Your ideas... - page 32
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
The grail I see is not summation, but number splitting
UPD
And the task of neurons is not to get a set of numbers, but to get one number as input. Multiply it by a weight and feed it through a non-linear function. Then you get data analysis, not soup cooking.
That is, there is one number (input value, or neuron output), and this number is split by two or more neurons of the next layer. They must be independent of the other neurons.
This is a department that does its own thing.
Then all these departments must report to a boss - the output neuron. It draws an inference based on the outputs of all the final neurons. With its own weights.
In this way we reduce the distortion of information and increase its reading.
Now this idea seems incomplete.
On the one hand, the idea of not distorting input data seems sensible. After all, by distorting with adder and weights, it's as if we are tampering with other data, replacing it with something random rather than what the graph shows. And this has to be expressed somehow.
On the other hand, number splitting is good for some set of numbers combined into one number. And those numbers inside should be static, so that they can be "pulled" from the total number, rather than making up their own.
Ordinary splitting in the version I imagined is the same as ordinary multiplication of one number by another. That is, the amount of splitting doesn't change the result. If the input number is 7, then no matter how you split it, all the split operations will be equal to one single multiplication in the output neuron. As a result, increasing branching becomes meaningless, as there is no movement from the input data. So there should be at least 2 inputs to relate them to each other.
So I'll twist and turn the new architecture.
Igave up on the architecture and decided to play with one neuron.
1neuron. As in the articleNeural Networks - from Theory to Practice
Tangent activation.
The inputs are not 3, as before, but 6. And here I came to a situation, for the first time, when increasing the inputs only improved the results, not overtraining. That is, the picture we see when we say "more is better". But this is only about inputs, there is no architecture as such, just one neuron.
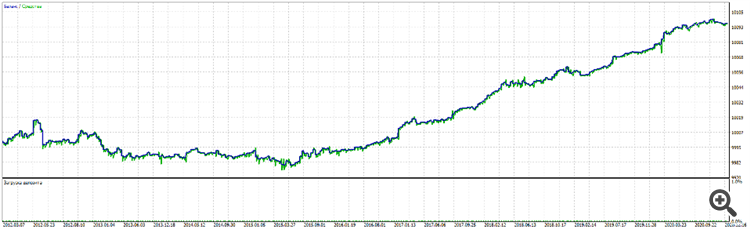
Optimisation over 9 years: 2012 to 2021. EURUSD.
Why exactly this one? From 2021 the long-term trend opposite to 2020 starts and all systems optimising or training on 2020 immediately and violently lose in 2021.
But there are also the previous 8 years to "gain" experience.
It would seem that the set is a bit dreadful.
The beginning is lousy, almost up to the middle.
But if you look at it from the other side: yes, at the beginning it doesn't work, and then it starts to work. The question arises: how long will this trade last and will it improve? And, if it does, will it be able to repeat its success on other currency pairs?
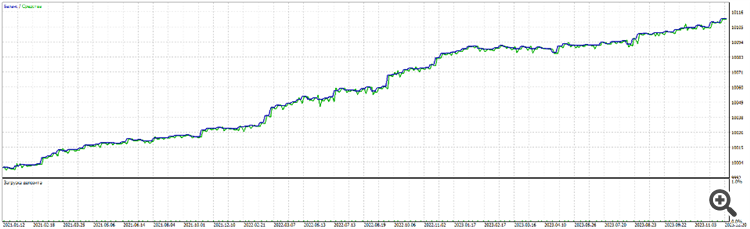
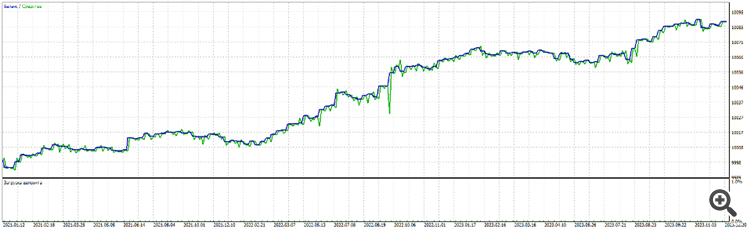
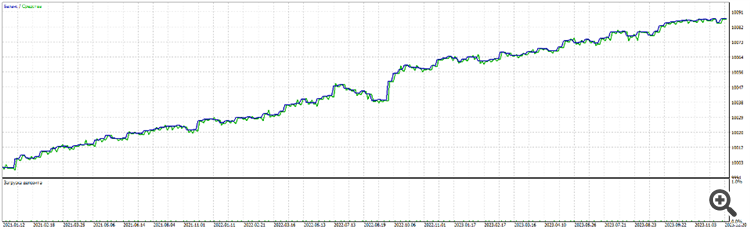
Forward 3 years: from 2021 to 2024.
On other pairs:
GBPUSD
NZDUSD
AUDUSD
What is curious about this one is that it is 1 neuron. Again it performs better than 2 , 3, 10 neurons. Than 2, 3, 5 layers.
The problem, as always, is the same old one - the set was somewhere on the 50th lines.
A second problem has been added to it - quotes of metaquotes. MQL has loyal to traders quotes, they either have no commission or spread, or both, but such results are much more difficult to repeat in the same ISMarket, it stupidly turns all the sets into unprofitable ones and the ones with longer trades remain afloat.
Let's assume that a set is at the top of the optimiser's list. Let's assume that all brokers have the same quotes as metaquotes. The result shows that whatever the architecture is, the main thing is"What to feed to the input of the neural network?".
The number should be compared to a sorted array of the same numbers. For example, you take the last 30 waves, line them up by motion magnitude, and compare the size of the last wave to this array. Which decile does it fall into? What's happening? Now there is a universal scale for any chart.
Yes, I have an indicator on this basis.
Soon I will try to put it into neuronka as well.
Yes, I have a turkey on this basis.
Soon I will try to put it into neuronka as well.
You can get such beautiful charts without neuronka.
First of all, all this should be done on real ticks (if it is not so), and secondly, look at the growth. For 3 years I could not earn even 10%.
And you should also look at the size of the maximum drawdown.
...and secondly, look at the gains. In 3 years I couldn't even earn 10%.
And you also have to look at the maximum drawdown.
It doesn't matter.
You're way off. We are at the stage of "getting this machine started."
And then we look at gains and drawdowns. The main thing is that it should be up, no matter how much, as long as it is stable.
And then we will level it out.
First of all, all this should be done on real ticks (if it is not so).
I don't know how to do it on real ticks. To be more precise, I am not technically ready.
No idea, no thesis, no idea of the algorithm, and hence, in fact, no code to twist and turn it in my hands.
It doesn't matter.
You've come a long way. We are at the stage of "getting this machine started".
And then we'll look at gains and drawdowns. The main thing is that it should be up, no matter how much, as long as it is stable.
And then we will level it out.
I don't know how to use real ticks. To be more precise, I am not technically ready.
I have no idea, no theses, no idea of the algorithm, and hence, in fact, no code to twist and turn it in my hands.
If you want to try on this or study neural networks, then yes, that's different.
But I would add that MO or NS or AI can only be used in forex to optimise a trading strategy.
And if the strategy is bad they cannot improve your strategy. You have to do it yourself.
But everything is already available on MT5 tester. Why don't you use MT5 optimiser?
If you want to try on that or study neural networks, then yes, that's different.
But I would add that MO or NS or AI can only be used in forex to optimise a trading strategy.
And if the strategy is bad, they cannot improve your strategy. You have to do it yourself.
But everything is already available on MT5 tester. Why don't you use MT5 optimiser?
On the contrary!
I wrote earlier that I use both MT5 and NeuroPro.
At the moment I am sitting exclusively on MT5 and the optimiser is overweighting. I just play with inputs and architectures.
On the contrary!
I wrote earlier that I use both MT5 and NeuroPro.
At the moment I am sitting exclusively on MT5 and the optimiser is overweighting. I just play with inputs and architectures.
If you are doing all this in "Every Tick" mode, I do not advise you to continue.
You know very well that in this mode tick values are modelled (generated) according to certain laws.
And any middle-class Expert Advisor, through optimisation, will be able to find such combinations of input parameters that you can get unrealistic results.
And it is pointless to waste time on it.
You did not say what is the maximum drawdown by means ?