What to feed to the input of the neural network? Your ideas... - page 37
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
I guess, this is the result without filters, for example, by time?
Hmm...
I, of course, have not tested with filters
But the point is that the trades are medium-term or intraday. The influence of the time filter does not seem to be strong.
But, in any case, it is possible, of course.
Hmm...
I have not tested with filters
But the point is that the trades are medium-term or intraday. The influence of the time filter does not seem to be strong.
But, in any case - you can, of course.
An interesting phenomenon:
If you use the same architecture (any architecture), then on EURUSD, when using Softmax, the optimisation always gives top sets where BUY is not used at all. Everything sticks only to SELL and HOLD.
I look at the chart for 12 years - it is descending. That is, the MT5 optimiser adjusts the weights at the macro level to fit the long term. As a result, BUY-eval upward trend areas remain "untraded" properly.
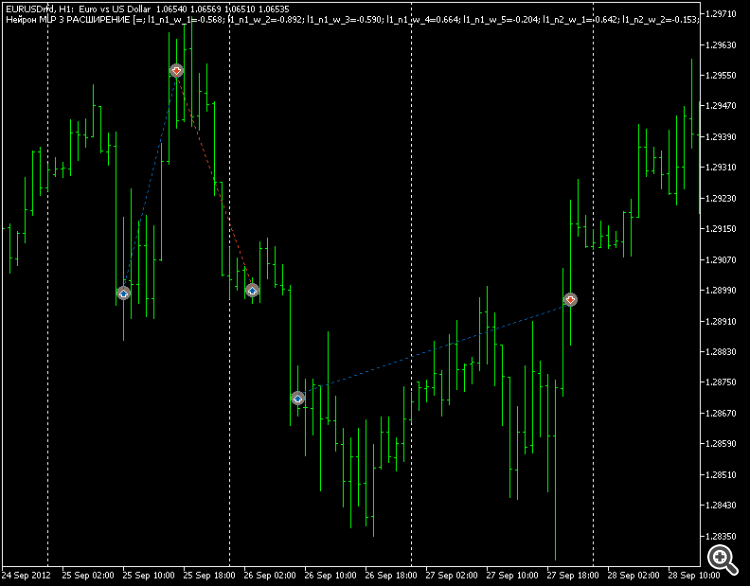
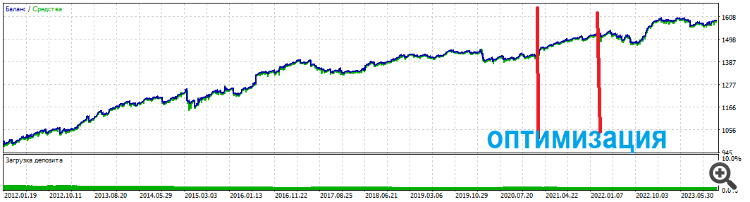
But if you use a regular tangent as an exit, there are no problems. The top sets trade both buy and sell.
So I have abandoned this softmax, now I am digging into architectures and inputs only with tangent.
UPD
Another thing - trades up and down.
And top sets hold for a long time
Interesting phenomenon:
...And the top sets last a long time
MLP architecture? I take it the weights are optimised by the in-house optimiser? What is the optimisation criterion, if not secret? And if the same mesh, but with some backprope algo, all other things being equal?
MLP architecture? So I understand the weights are optimised by the in-house optimiser? What is the optimisation criterion, if not secret? And if the same grid but with some backprope algorithm is used with all other things being equal?
And the top sets last a long time
What if on top of that you train the second model again?
What if you over train the second model again?
Please specify in the context of a regular MT5 optimiser and a regular EA.
How would it look like?
Take two sets from the optimisation list (uncorrelated), combine them and run? Or is something else in mind
Too many clever words
Experts from the MO branch claim that:
1. You cannot search for a global extremum on a fitness function.
2. Global search optimisation algorithms (the standard GA is one of them) are not suitable for neural networks, you should use all sorts of gradient backprops for this purpose.
In short, from the looks of it, you are doing it all wrong (according to the ideas of the experts of the MO branch).
Experts from the MO branch argue that:
1. One cannot look for a global extremum on the fitness function.
2. Global search optimisation algorithms (this includes the standard GA) are not suitable for neural networks, you should use all sorts of gradient backprops for this.
In short, from the looks of it, you are doing it all wrong (according to the ideas of the experts of the MO branch).
So I will win this battle
Then I will win this battle