What to feed to the input of the neural network? Your ideas... - page 53
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
Some summaries:
- Neural network is only applicable to stationary, static patterns that have nothing to do with pricing
My imho, as I see itOn stationary rows everything works and then no need for MO at all.
Well, everything is back to where the MO thread started in 2016 - non-stationary series do not contain stable statistical characteristics. so all NS are just guessing.
I remember when I wrote this Dmitrievsky was running around the thread, squealing and demanding to be shown this in textbooks....
On stationary rows everything works and then you don't need MO at all.
Well, everything is back to where the MO thread started in 2016 - non-stationary series do not contain stable statistical characteristics. therefore, all NS are just guessing.
I remember when I wrote this Dmitrievsky was running around the thread, squealing and demanding to be shown this in textbooks....
Attempts to fit weights to history are bound to fail.
Training, optimisation. Doesn't matter. Any intervention like direct fitting is a path to nowhere.
And it seems that the right direction is fitting....
The basis for it:
When the input data takes the form from 0 to 1 or -1 to 1, we have a certain range of possible values of numbers, which is limited from top to bottom. The bottom is the number of decimal places.
We can not limit and leave real numbers as they are, and the limitation will be only technical - it is the maximum number of decimal places according to MT4/MT5 terminals.
Or we can limit it manually, for example by NormalizeDouble or rounding functions.
And then we will have an even narrower range.
As a result, we can simply search all the values in the optimiser, assign one of three values to each number: open position, close, skip, wait, and so on.
This method gives absolute optimisation or absolute retraining, or tends to them. That is, like a Q-learning table, we also record the result of each pattern in it, and then choose what to do next based on the "past" evaluations.
The result of this approach is a breakdown in balance, a dive down on the forward, and so on.
Artificial noise addition by reducing architecture (reducing the number of neurons, layers, etc.) or other methods is nothing but a crutch.
Some kind of half-measure.
And looking at the next optimiser's result on the graph, where a regular MLP was the test subject, I scratched my head and could not understand: why? Why does a fucking MLP work better than absolute overfitting?
In the science of machine learning there is a definition and a term for this phenomenon (when an expressive drain occurs on the forward after absolute overoptimisation or overtraining). But that's not what we're talking about now.
When a fucking MLP opens a position, a jammed, late, over-served position, it inadvertently misses ... the plum areas of the chart. That is, the average losing position 50/50 overlaps the portion of the chart where the plum could have occurred if opened the other way. A good plum. And the retrained model is sure to open there.
That is, MLP not only averages weights for all situations on the chart, it essentially smooths out all force majeure, which makes it look more convincing on the forward.
Hence the conclusion:
Optimisation should be done in such a way that there is both averaging and retraining. That is, we still need to extract parts of numerical ranges and label them, but at the same time - to throw them into the boiler, smear, blur.
From the outside it seems that I am saying obvious things, but I, for example, now have MLP in a perverted form, and it shows better results than the usual MLP, but it has a homemade module of partial absolute overtraining.
UPD
As an option. Over-optimisation on the 2012-2021 stretch on EURUSD.
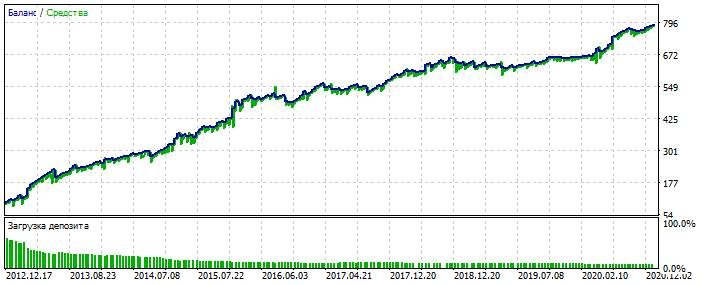
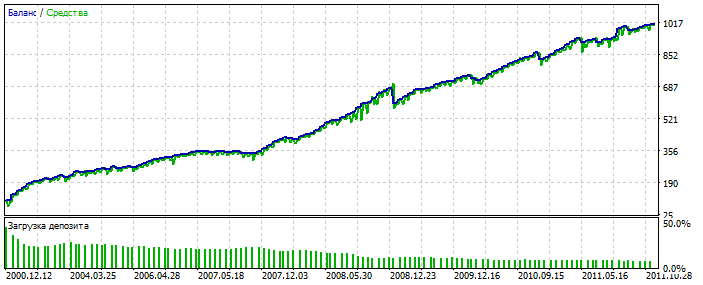
You can see that the balance chart is too polished, without strong skews. A sign of over-optimisation. For MLP it is with 3 neurons.
Bektest 2000-2012
For some reason it is prettier than optimisation. Probably picked up an anomaly.
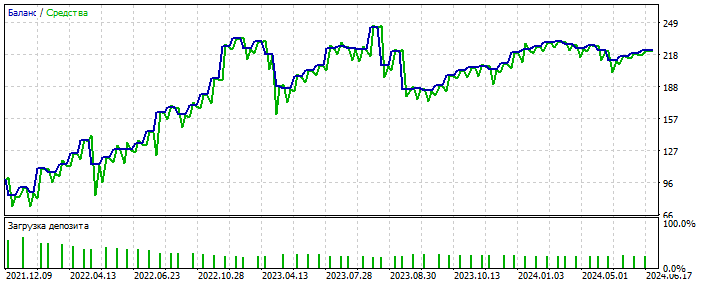
Forward 2021-2025
Deals are few, but we are not talking about polishing the system here. The essence is important. And you can fill the gap in the number of deals by adding 28 more currency pairs and the number of the first ones will increase by 20 times. Again - not the point.
And the most important thing is that such a system does not need qualitative input data. It works on almost everything: increments, oscillators, zigzags, patterns, prices, any.
I am still moving in this direction.
And themost important thing is that such a system does not need high-quality input data. It works on almost everything: increments, oscillators, zigzags, patterns, prices, any.
I am moving in this direction for now.
Do you train by selecting network weights in MT5-optimiser?
Yes. Occasionally I resort to real learning via error back propagation
Yes. Once in a while I resort to real learning through error back propagation.
What is the relation of optimiser from mt5 and back propagation of error????
Cool
Bypassing MT5 limitations is like optimising a pair of layers of 10 neurons - a regular MT5 optimizer will complain about the 64bit limitation.
Conclusions you deserve :)
Among other set of words, I would only point out that the fewer transactions (observations), the easier it is to do curwafitting (fitting to history) including new data. That's a feature of curwafitting based on statistics, not moving forward. 🫠