Was soll in den Eingang des neuronalen Netzes eingespeist werden? Ihre Ideen... - Seite 53
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Einige Zusammenfassungen:
- Neuronale Netze sind nur auf stationäre, statische Muster anwendbar, die nichts mit der Preisgestaltung zu tun haben.
Mein Fazit, wie ich es seheBei stationären Reihen funktioniert alles und dann braucht man auch kein MO mehr.
Nun, alles ist wieder da, wo der MO-Thread 2016 begann - nicht-stationäre Reihen enthalten keine stabilen statistischen Merkmale. also sind alle NS nur Vermutungen.
Ich erinnere mich, als ich dies schrieb, rannte Dmitrievsky durch den Thread, schrie und verlangte, dies in Lehrbüchern gezeigt zu bekommen....
Bei stationären Reihen funktioniert alles, und dann braucht man MO überhaupt nicht.
Nun, alles ist wieder da, wo der MO-Thread im Jahr 2016 begann - nicht-stationäre Reihen enthalten keine stabilen statistischen Merkmale. daher sind alle NS nur Vermutungen.
Ich erinnere mich, als ich das schrieb, rannte Dmitrievsky durch den Thread, schimpfte und verlangte, dass man ihm das in Lehrbüchern zeigt....
Der Versuch, Gewichte an die Geschichte anzupassen, ist zum Scheitern verurteilt: Training, Optimierung. Das spielt keine Rolle.
Jeder Eingriff wie die direkte Anpassung ist ein Weg ins Leere. Und es scheint, dass die richtige Richtung die Anpassung ist....
Die Grundlage dafür: Wenn die Eingabedaten die Form von 0 bis 1 oder -1 bis 1 haben, haben wir einen bestimmten Bereich möglicher Zahlenwerte, der von oben nach unten begrenzt ist.
Die untere Grenze ist die Anzahl der Nachkommastellen. Wir können uns nicht einschränken lassen und die realen Zahlen so belassen, wie sie sind, und die Einschränkung wird nur technisch sein - es ist die maximale Anzahl der Nachkommastellen gemäß den MT4/MT5-Terminals. Oder wir können sie manuell einschränken, zum Beispiel durchNormalizeDouble oder Rundungsfunktionen.
Und dann haben wir einen noch engeren Bereich. Als Ergebnis können wir einfach alle Werte im Optimierer durchsuchen und jeder Zahl einen von drei Werten zuweisen: Position öffnen, schließen, überspringen, warten usw. Diese Methode ergibt eine absolute Optimierung oder ein absolutes Retraining, oder tendiert dazu.
Das heißt, wie bei einer Q-Learning-Tabelle wird auch hier das Ergebnis jedes Musters aufgezeichnet, und dann wird auf der Grundlage der "vergangenen" Bewertungen entschieden, was als nächstes zu tun ist. Das Ergebnis dieses Ansatzes ist ein Zusammenbruch des Gleichgewichts, ein Abtauchen nach vorne usw.
Künstliches Rauschen durch Verringerung der Architektur (Verringerung der Anzahl der Neuronen, der Schichten usw.) oder andere Methoden ist nichts weiter als eine Krücke. Eine Art halbe Maßnahme. Und als ich mir das Ergebnis des nächsten Optimierers im Diagramm ansah, bei dem ein normaler MLP das Testobjekt war, kratzte ich mich am Kopf und konnte nicht verstehen: Warum?
Warum funktioniert ein verdammter MLP besser als ein absolutes Overfitting? In der Wissenschaft des maschinellen Lernens gibt es eine Definition und einen Begriff für dieses Phänomen (wenn nach einer absoluten Überoptimierung oder einem Übertraining ein ausdrucksstarker Abfluss auf dem Forward auftritt). Aber das ist nicht das, worüber wir jetzt reden.
Wenn eine verdammte MLP eine Position eröffnet, eine verklemmte, verspätete, überversorgte Position, verpasst sie versehentlich ... die Pflaumenbereiche des Charts. Das heißt, die durchschnittliche Verlustposition überschneidet sich 50/50 mit dem Teil des Diagramms, in dem die Pflaume hätte auftreten können, wenn sie in die andere Richtung geöffnet worden wäre. Eine gute Pflaume.
Und das neu trainierte Modell wird mit Sicherheit dort öffnen. Das heißt, MLP mittelt nicht nur die Gewichte für alle Situationen auf dem Chart, sondern glättet im Wesentlichen alle Fälle höherer Gewalt, was es auf dem Forward überzeugender aussehen lässt. Daraus ergibt sich die Schlussfolgerung: Die Optimierung sollte so erfolgen, dass sowohl eine Mittelwertbildung als auch eine Umschulung stattfindet.
Das heißt, wir müssen immer noch Teile von Zahlenbereichen extrahieren und beschriften, aber gleichzeitig - um sie in den Kessel zu werfen, zu verwischen, zu verwischen. Von außen betrachtet scheint es, dass ich offensichtliche Dinge sage, aber ich zum Beispiel habe jetzt MLP in einer pervertierten Form, und es zeigt bessere Ergebnisse als das übliche MLP, aber es hat ein hausgemachtes Modul des partiellen absoluten Übertrainings.
UPD
Als Option.
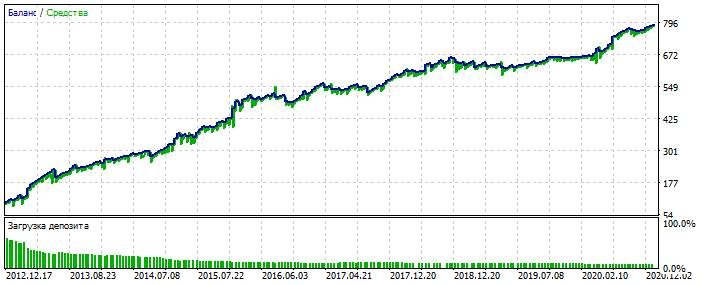
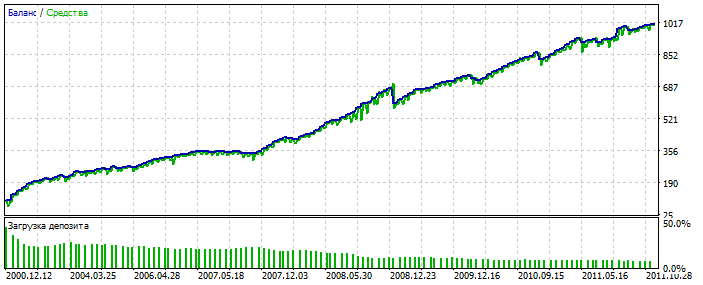
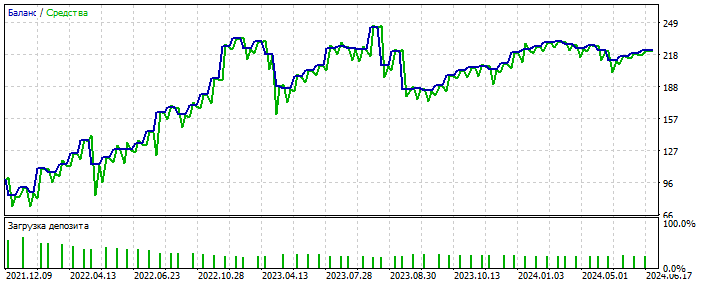
Überoptimierung auf dem EURUSD-Diagramm 2012-2021: Sie sehen, dass das Gleichgewichtschart zu glatt ist, ohne starke Schiefe. Ein Zeichen für Überoptimierung.
Für MLP ist es mit 3 Neuronen. Bektest 2000-2012 Aus irgendeinem Grund ist es hübscher als die Optimierung.
Wahrscheinlich wurde eine Anomalie erkannt. 2021-2025 Es gibt nur wenige Deals, aber es geht hier nicht darum, das System zu polieren. Das Wesentliche ist wichtig. Und man kann die Lücke in der Anzahl der Deals füllen, indem man 28 weitere Währungspaare hinzufügt und die Anzahl der ersten Deals wird sich um das 20-fache erhöhen. Nochmals - das ist nicht der Punkt.
Und was das Wichtigste ist - ein solches System braucht keine qualitativen Eingangsdaten.
Es funktioniert auf fast alles: Inkremente, Oszillatoren, Zigzags, Muster, Preise, alle. Ich bin immer noch in diese Richtung bewegen.
Und dasWichtigste ist, dass ein solches System keine hochwertigen Eingangsdaten benötigt.
Es funktioniert auf fast alles: Inkremente, Oszillatoren, Zigzags, Muster, Preise, alle. Ich bin in diese Richtung für jetzt bewegen.
Trainieren Sie durch Auswahl der Netzgewichte in MT5-optimiser?
Ja. Gelegentlich greife ich auf echtes Lernen durch Fehlerrückvermehrung zurück.
Ja. Hin und wieder greife ich auf echtes Lernen durch Fehlerfortpflanzung zurück.
Was ist die Beziehung zwischen dem Optimierer von mt5 und der Rückwärtspropagation von error????
Cool Die Umgehung der MT5-Beschränkungen ist wie die Optimierung eines Paares von Schichten aus 10 Neuronen - ein regulärer MT5-Optimierer wird sich über die 64bit-Beschränkung beschweren.
Schlussfolgerungen, die Sie verdienen :)
Neben anderen Worten möchte ich nur darauf hinweisen, dass es umso einfacher ist, Curwafitting (Anpassung an die Geschichte) unter Einbeziehung neuer Daten durchzuführen, je weniger Transaktionen (Beobachtungen) vorliegen. Das ist ein Merkmal von Curwafitting, das auf Statistik basiert, nicht auf Vorwärtsbewegung. 🫠