Was soll in den Eingang des neuronalen Netzes eingespeist werden? Ihre Ideen... - Seite 52
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Wenn man sich das Bild anschaut, ja, es ist warm und weich, aber im Code ist es in Ordnung.
Die Klammern auf dem Bild sind falsch. Es sollte so sein.
Ola ke tal. Ich dachte, ich würde meine Ideen einbringen.
Mein neuestes Modell besteht darin, normalisierte Preise von 10 Symbolen zu sammeln und so ein Rekursionsnetzwerk zu trainieren. Als Eingabe dienen 20 Balken des Monats, der Woche und des Tages.
Das ist das Bild, das ich erhalte. Der Unterschied zum separaten Training ist, dass der Gesamtgewinn 3-mal geringer ist und der Drawdown.... wow, der Drawdown im Kontrollzeitraum beträgt kaum 1%.
Mir scheint, das löst das Problem der Datenknappheit.
Ola ke tal. Ich dachte, ich bringe mal meine Ideen ein.
Mein neuestes Modell besteht darin, normalisierte Preise von 10 Symbolen zu sammeln und so ein Rekursionsnetzwerk zu trainieren. Es gibt 20 Balken des Monats, der Woche und des Tages pro Eingabe.
Das ist das Bild, das ich erhalte. Der Unterschied zum separaten Training ist, dass der Gesamtgewinn dreimal geringer ist und der Drawdown.... wow, der Drawdown in der Kontrollperiode beträgt kaum 1%.
Mir scheint, das löst das Problem der Datenknappheit.
Ich denke, Sie haben ein extrem hohes Niveau an Wissen über das Thema.
Ich fürchte, ich werde nichts verstehen. Bitte sagen Sie mir, was diese Schönheit auf dem Chart ist: ist es Python?
LSTM-Architektur? Ist es möglich, so etwas auf MT5 darzustellen?
normalisierte Preise von 10 Symbolen
Auch hier, wie die Preise normalisiert werden. Was ist "ante" Im Allgemeinen, alles, was nicht ein Geschäftsgeheimnis ist, bitte teilen)
Ich denke, Sie beherrschen das Thema auf einem sehr hohen Niveau.
Ich fürchte, ich werde nichts verstehen. Bitte sagen Sie mir, was diese Schönheit auf dem Chart ist: ist es Python?
LSTM-Architektur? Ist es möglich, so etwas auf MT5 darzustellen?
Auch hier, wie die Preise normalisiert. Was ist "ante" Im Allgemeinen, alles, was nicht ein Geschäftsgeheimnis ist, bitte teilen).
Natürlich ist es Python. In µl5, um Daten nach einer Bedingung auszuwählen, muss man eine Aufzählung machen und all das iff iff iff iff iff. Und in Python braucht man nur eine Zeile, um Daten nach einer beliebigen Bedingung auszuwählen. Ich spreche nicht über die Geschwindigkeit der Arbeit. Es ist zu bequem. Mcl5 wird benötigt, um Geschäfte mit einem vorgefertigten Netzwerk zu eröffnen.
Die Normalisierung ist die häufigste. Minus den Mittelwert, geteilt durch die Standardabweichung. Das Geschäftsgeheimnis ist hier der Normalisierungszeitraum, es ist wichtig, ihn so zu wählen, dass die Preise 10 Jahre lang um Null liegen. Aber nicht so, dass sie am Anfang der 10 Jahre unter Null und am Ende über Null liegen. Das ist nicht die richtige Art zu vergleichen...
Zwei Testperioden - ante und test. Der Ante-Zeitraum vor der Ausbildung beträgt 6 Monate. Das ist sehr praktisch. Das Ante ist immer da. Und der Test ist die Zukunft, er existiert nicht. Das heißt, es gibt sie, aber nur in der Vergangenheit. Und in der Zukunft gibt es ihn nicht. Das heißt, sie existiert nicht.
Was ist Ihrer Meinung nach wichtiger: die Architektur oder die Eingabedaten?
Was ist Ihrer Meinung nach wichtiger: die Architektur oder die Eingabedaten?
Ich denke, die Eingaben. Hier versuche ich es mit 6 Zeichen, nicht mit 10. Und ich passe nicht in den Kontrollzeitraum August-Dezember 2023. Unabhängig davon ist es auch schwer. Und ein 10-Zeichen-Durchgang kann auf der Grundlage der Trainingsergebnisse legitimerweise gewählt werden. Das Netz ist immer rekurrent in 1 Schicht mit 32 Zuständen, nur Full-Link wird verwendet.
Einige Zusammenfassungen:
Mir wurde klar, dass ich gerade ein algorithmisches Muster gefunden hatte, während ich verschiedene Eingabedaten auswählte und damit die Frage meiner Verzweigung "Was soll in das neuronale Netz eingespeist werden?" teilweise beantwortete. Aber das neuronale Netz erwies sich als unnötig. Weder MLP, noch RNN, noch LSTM, noch BiLSTM, noch CNN, noch Q-learning, noch all diese kombiniert und gemischt.
In einem dieser Experimente optimierte ich 2 Eingaben auf 3 Neuronen. Das Ergebnis war, dass eines der oberen Sets das folgende Bild zeigte
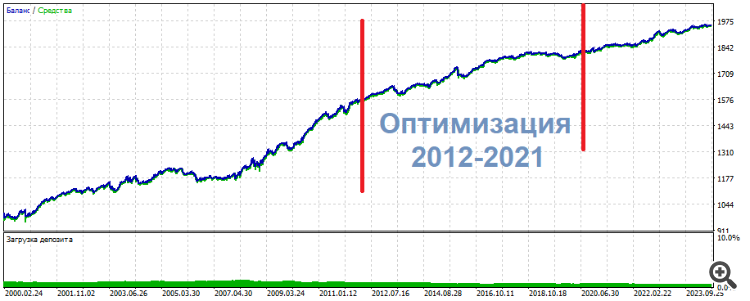
* ******* **************
UPD Hier ist eine andere Gruppe, die gleiche Sache: Mitte - Optimierung, Ergebnisse - an den Seiten. Fast dasselbe, nur gleichmäßiger
**********************
Die Trades sind nicht Pips oder Scalp. Eher intraday.
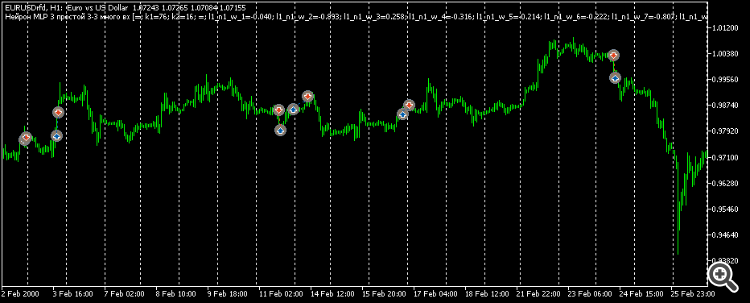
So, meine subjektiven Schlussfolgerungen für den aktuellen Moment:
Ich habe noch nie in meinem Leben schlechtere Ergebnisse gesehen als mit Glättungsindikatoren . Es ist wie ein Sehender, der blind wird. Eben noch konnte er eine klare Silhouette sehen, und jetzt kann er nicht verstehen, was - ein Schlieren in seinen Augen. Keine Information.
Meine Meinung, wie ich sie sehe
Neuronale Netze sind nur auf stationäre, statische Muster anwendbar, die nichts mit der Preisbildung zu tun haben.
Welche Art von Vorverarbeitung, Normalisierung führen Sie durch? Haben Sie eine Standardisierung versucht?
I van Butko #: Das neuronale Netz merkt sich den Pfad. Nicht mehr als das.
Versuchen Sie Transformatoren, die sollen gut für Sie sein....
I van Butko #: Oszillatoren sind böse!
Nun, nicht alles ist so eindeutig. Es ist nur so, dass NS bequem mit kontinuierlichen Funktionen arbeiten kann, aber wir brauchen eine Architektur, die mit stückweisen/intervallweisen Funktionen arbeitet, dann kann NS Oszillatorbereiche als sinnvolle Information nehmen.
Welche Art von Vorverarbeitung, Normalisierung führen Sie durch? Haben Sie eine Standardisierung versucht?
Versuchen Sie Transformers, die sollen gut für Sie sein....
Nun, nicht alles ist so eindeutig. Es ist nur so, dass NS bequem mit kontinuierlichen Funktionen arbeiten kann, aber wir brauchen eine Architektur, die mit stückweisen/intervallweisen Funktionen arbeitet, damit NS in der Lage ist, Oszillatorbereiche als sinnvolle Informationen zu betrachten.
1. und wenn wie: wenn das Datenfenster, einige Inkremente, ich bringe in den Bereich -1..1. ich habe nicht über die Standardisierung gehört 2.
Akzeptiert, danke 3. Ich stimme zu, ich habe nicht den vollen Beweis für das Gegenteil.
Deshalb schreibe ich von meinem eigenen Glockenturm aus, so wie ich es sehe und mir ungefähr vorstelle. Eine einfache Glättung ist de facto eine Auslöschung von Informationen. Nicht Verallgemeinerung. Auslöschung eben. Denken Sie nur an ein Foto: Sobald man seinen Inhalt verschlechtert, ist die Information unwiederbringlich verloren. Und die Wiederherstellung durch KI ist ein künstlerisches Unterfangen, keine Restaurierung im eigentlichen Sinne. Es handelt sich um eine willkürliche Neuberechnung.
"Glättung: Wenn eine Zahl das Ergebnis zweier unabhängiger Informationseinheiten ist: Muster -1/1, sagen wir, und Muster -6/6. Der Durchschnittswert der beiden ist gleich, aber es gab ursprünglich zwei Muster. Sie können etwas bedeuten oder auch nicht, sie können entgegengesetzte Signale bedeuten.
Und hier kommen Mashki, Oszillatoren usw. ins Spiel, die das ursprüngliche "Bild" des Marktes dummerweise auslöschen/verwischen. Und mit dieser "Verwischung" erschrecken wir den NS, so dass er endlos versucht, so zu arbeiten, wie er sollte. Verallgemeinerung und Glättung sind extrem unfreundliche, heterogene Phänomene.
Einige Zusammenfassungen:
Mir wurde klar, dass ich gerade ein algorithmisches Muster gefunden hatte, während ich verschiedene Eingabedaten durchsuchte, und damit die Frage meiner Verzweigung "Was soll in das neuronale Netz eingespeist werden?" teilweise beantwortet hatte. Aber das neuronale Netz erwies sich als unnötig. Weder MLP, noch RNN, noch LSTM, noch BiLSTM, noch CNN, noch Q-learning, noch all diese kombiniert und gemischt.
In einem dieser Experimente optimierte ich 2 Eingaben auf 3 Neuronen. Das Ergebnis war, dass eines der oberen Sets das folgende Bild zeigte
* ******* **************
UPD Hier ist eine andere Gruppe, die gleiche Sache: Mitte - Optimierung, Ergebnisse - an den Seiten. Fast dasselbe, nur gleichmäßiger
**********************
Die Trades sind weder Pips noch Scalp.
Eher intraday. Daher meine subjektiven Schlussfolgerungen im Moment:
Ich habe noch nie in meinem Leben schlechtere Ergebnisse gesehen als mit Glättungsindikatoren . Es ist wie ein Sehender, der blind wird. Eben noch konnte er eine klare Silhouette sehen, und jetzt kann er nicht verstehen, was - irgendein Schlieren in seinen Augen. Keine Information.
Meine Meinung, wie ich es sehe
nicht ein schwacher Kern.
Ist es Zeit, Taschen zu nähen?