Was soll in den Eingang des neuronalen Netzes eingespeist werden? Ihre Ideen... - Seite 37
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Ich vermute, das ist das Ergebnis ohne Filter, zum Beispiel nach Zeit?
Hmm... Ich habe natürlich nicht mit Filtern getestet, aber der Punkt ist, dass die Trades mittelfristig oder intraday sind.
Der Einfluss des Zeitfilters scheint nicht stark zu sein, aber möglich ist es natürlich trotzdem.
Hmm... Ich habe nicht mit Filtern getestet, aber der Punkt ist, dass die Trades mittelfristig oder intraday sind.
Der Einfluss des Zeitfilters scheint nicht stark zu sein. Aber in jedem Fall - Sie können, natürlich.
Ein interessantes Phänomen:
Wenn Sie dieselbe Architektur verwenden (egal welche), dann ergibt die Optimierung bei EURUSD bei Verwendung von Softmax immer Top-Sets, bei denen KAUFEN überhaupt nicht verwendet wird. Alles bleibt bei SELL und HOLD.
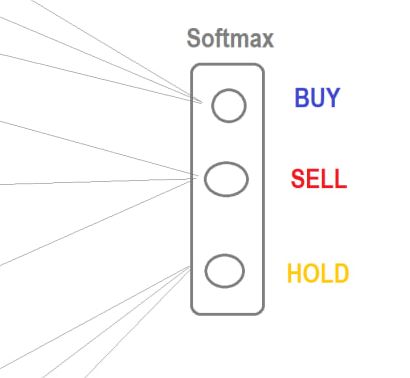
Ich schaue mir den Chart seit 12 Jahren an - er ist absteigend. Das heißt, der MT5-Optimierer passt die Gewichte auf der Makroebene an, um sie an die lange Laufzeit anzupassen.
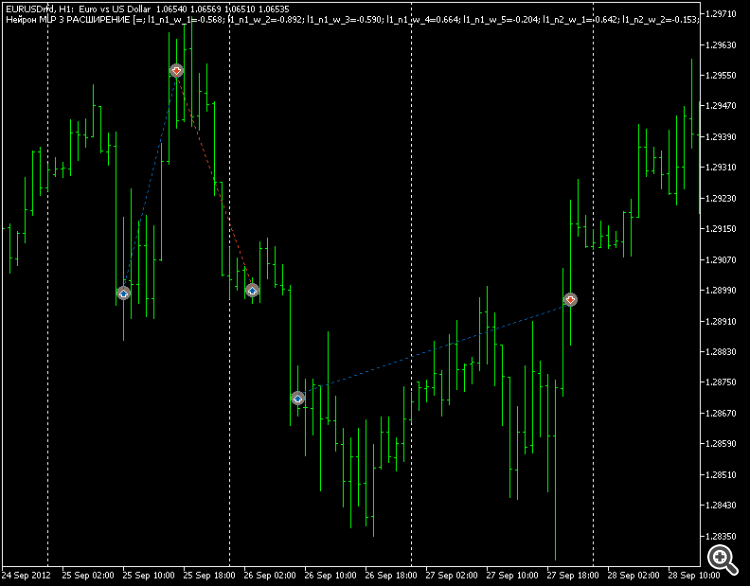
Das hat zur Folge, dass BUY-eval-Aufwärtstrendbereiche ordnungsgemäß "untraded" bleiben. Wenn Sie aber eine reguläre Tangente als Ausstieg verwenden, gibt es keine Probleme.
Die Top-Sets handeln sowohl kaufen als auch verkaufen. Also habe ich diese Softmax aufgegeben, jetzt grabe ich in Architekturen und Eingaben nur mit Tangente. UPD Eine andere Sache - Trades nach oben und unten.
Und Top-Sets halten für eine lange Zeit
Interessantes Phänomen:
...
Und die Top-Sets halten lange Zeit
MLP-Architektur? Ich nehme an, die Gewichte werden durch den internen Optimierer optimiert? Was ist das Optimierungskriterium, wenn es nicht geheim ist? Und wenn es das gleiche Netz ist, aber mit einem Backprope-Algorithmus, wenn alle anderen Dinge gleich sind?
MLP-Architektur? Soweit ich weiß, werden die Gewichte durch den internen Optimierer optimiert? Was ist das Optimierungskriterium, wenn es nicht geheim ist? Und wenn das gleiche Gitter, aber mit einem Backprope-Algorithmus verwendet wird, wenn alle anderen Dinge gleich sind?
Und die Oberteile halten lange Zeit
Was ist, wenn Sie das zweite Modell noch einmal trainieren?
Was ist, wenn Sie das zweite Modell erneut übertrainieren?
Bitte klären Sie das im Zusammenhang mit einem regulären MT5-Optimierer und einem regulären EA. Wie würde das aussehen? Nehmen Sie zwei Sets aus der Optimierungsliste (unkorreliert), kombinieren Sie sie und führen Sie sie aus? Oder haben Sie etwas anderes im Sinn
Zu viele kluge Worte
Experten aus der MO-Branche behaupten, dass: 1. Man kann nicht nach einem globalen Extremum einer Fitnessfunktion suchen.
2. globale Suchoptimierungsalgorithmen (der Standard-GA ist einer davon) nicht für neuronale Netze geeignet sind, man sollte alle Arten von Gradienten-Backprops für diesen Zweck verwenden.
Kurz gesagt, so wie es aussieht, machen Sie alles falsch (nach den Vorstellungen der Experten aus der MO-Branche).
Experten aus der MO-Branche argumentieren, dass: 1. Man kann nicht nach einem globalen Extremum der Fitnessfunktion suchen.
2. globale Suchoptimierungsalgorithmen (einschließlich der Standard-GA) nicht für neuronale Netze geeignet sind, sondern alle Arten von Gradienten-Backprops verwendet werden sollten.
Kurz gesagt, so wie es aussieht, machen Sie alles falsch (nach den Vorstellungen der Experten aus der MO-Branche).
Ich werde diese Schlacht also gewinnen
Dann werde ich diese Schlacht gewinnen