Was soll in den Eingang des neuronalen Netzes eingespeist werden? Ihre Ideen... - Seite 31
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Zur Bestätigung meine obigen Diagramme. Ein Input, zwei Inputs, drei Inputs - ein Neuron, zwei Neuronen, drei Neuronen. Das war's, als Nächstes kommt das Umlernen - das Einprägen des Pfades, nicht die Arbeit an neuen Daten.
Ähnlich verhält es sich mit Holzmodellen. Mit 3-5 (vielleicht bis zu 10, aber wahrscheinlicher bis zu 5) Eingaben/Merkmalen kann das Modell noch einen Gewinn vorweisen, bei mehr ist es bereits zufällig oder Pflaume.
Diese 3-5 besten Chips wurden durch eine vollständige Suche nach Paaren, Dreiern usw. und das Training von Modellen auf ihnen und die Auswahl der besten bei der Vorwärtsbewertung erhalten.
I van Butko #:
Und stellen Sie sich vor, ein gewöhnliches neuronales Netz nimmt jede Zahl, jedes Merkmal - und summiert es dummerweise, zusätzlich multipliziert mit dem Gewicht, zu einem Haufen Müll, genannt Addierer.
Bäume verwenden auch den Durchschnitt von Blättern: Wenn es ein Wald ist, bildet es den Durchschnitt mit anderen Bäumen, wenn es ein Strauch ist, fasst es mit anderen Bäumen zusammen. D.h. die Situation ist bei neuronalen Netzen die gleiche wie bei Baummodellen. Alles Mittelwertbildung. Wenn es viel Rauschen gibt, kann man normalerweise nur auf 3-5 Chips trainieren.
Mittelwertbildung mit Rauschen ist eine Umschulung auf Rauschen. P.S. Anstelle des über 20 Jahre alten NeuroPro können Sie etwas Neueres verwenden. R, Python, oder wenn es schwierig ist, mit ihnen umzugehen, verwenden Sie die EXE von Catbusta, wie hierhttps://www.mql5.com/ru/articles/8657. Sie können die EXE direkt aus dem EA automatisch ausführen, d.h. den Prozess vollständig automatisieren.
Beispiel https://www.mql5.com/ru/forum/86386/page3282#comment_49771059 P.P.S. Es ist besser, nachts zu schlafen. Sie können sich Ihre Gesundheit nicht kaufen, auch wenn Sie in diesen Netzwerken Millionen verdienen.
Ähnlich bei Holzmodellen. Mit 3-5 (vielleicht bis zu 10, aber wahrscheinlicher bis zu 5) Eingaben/Merkmalen kann das Modell noch einen Gewinn auf dem Vorwärts zeigen, wenn mehr, dann ist es schon zufällig oder Pflaume.
Diese 3-5 besten Fichas wurden durch eine vollständige Suche nach Paaren, Dreiern usw. und das Trainieren von Modellen auf ihnen und die Auswahl der besten auf dem Vorwärtsgang erhalten.
Die Bäume verwenden ebenfalls den Durchschnittswert der Blätter: Wenn es sich um einen Wald handelt, wird der Durchschnitt mit anderen Bäumen gebildet, wenn es sich um einen Busch handelt, wird der Durchschnitt mit anderen Bäumen gebildet, d.h. die Situation ist bei neuronalen Netzen die gleiche wie bei Baummodellen. Alle Mittelwertbildung. Wenn es viel Rauschen gibt, kann man normalerweise nur auf 3-5 Chips trainieren.
Mittelwertbildung mit Rauschen ist Umschulung auf Rauschen. P.S. Anstelle des über 20 Jahre alten NeuroPro können Sie auch etwas Neueres verwenden. R, Python, oder wenn es schwierig ist, mit ihnen umzugehen, verwenden Sie die EXE von Catbusta, wie hierhttps://www.mql5.com/ru/articles/8657. Sie können die EXE direkt aus dem EA automatisch ausführen, d.h. den Prozess vollständig automatisieren.
Beispiel https://www.mql5.com/ru/forum/86386/page3282#comment_49771059 P.P.S. Es ist besser, nachts zu schlafen. Sie können sich Ihre Gesundheit nicht kaufen, auch wenn Sie in diesen Netzwerken Millionen verdienen.
Vielen Dank für diesen Beitrag
Ich sehe den Gral nicht in der Summierung, sondern in der Aufteilung der Zahl
UPD
Und die Aufgabe der Neuronen besteht nicht darin, eine Reihe von Zahlen zu erhalten, sondern eine Zahl als Eingabe zu bekommen. Diese wird mit einem Gewicht multipliziert und durch eine nichtlineare Funktion gejagt.
Das heißt, es gibt eine Zahl (Eingabewert oder Neuronenausgang), und diese Zahl wird durch zwei oder mehr Neuronen der nächsten Schicht geteilt.
Sie müssen von den anderen Neuronen unabhängig sein. Dies ist eine Abteilung, die ihr eigenes Ding macht. Dann müssen alle diese Abteilungen einem Chef Bericht erstatten - dem Ausgangsneuron. Es zieht eine Schlussfolgerung auf der Grundlage der Ausgaben aller Endneuronen. Mit seinen eigenen Gewichten.
Auf diese Weise reduzieren wir die Verzerrung der Informationen und erhöhen ihre Aussagekraft.
Der Gral, den ich sehe, ist nicht die Summierung, sondern die Zahlenteilung
Nun, Blätter erhält man durch Aufteilung der Daten, sogar in 1000000 verschiedene Teile/Blätter.
Aber das Ergebnis/Antwort eines Blattes ist der Durchschnitt der darin enthaltenen Beispiele/Zeilen. Die Aufteilung ist also vorhanden, aber die Summierung auch. Man kann 1 Beispiel in einem Blatt aufspalten, aber das ist 100% Übertraining bei Rauschen. Bäume sollten auch bei Rauschen nicht tief aufgesplittet werden, um einen guten Fortschritt zu erzielen (so wird die Anzahl der Neuronen besser - klein).
Bin in so etwas wie Spread und Kommission gestolpert.
Die machen das neuronale Netz schnell kaputt. Danke MT5, du weißt, wie man nüchtern wird. Ich hätte schon vor langer Zeit von MT4 zu euch wechseln sollen
@ Andrey Dik hatte schon vor vielen Jahren recht - der Gral liegt immer noch im Spread und in der Kommission. Sobald man sie entfernt, grast das neuronale Netz weiter vor sich hin.
Nun, Blätter erhält man durch Aufteilung der Daten in 1000000 verschiedene Teile/Blätter.
Aber das Ergebnis/die Antwort eines Blattes ist der Durchschnitt der darin enthaltenen Beispiele/Zeilen. Es gibt also eine Aufteilung, aber auch eine Zusammenfassung. Man kann auf 1 Beispiel in einem Blatt aufteilen, aber das ist 100% Übertraining bei Rauschen. Bäume sollten auch bei Rauschen nicht tief aufgespalten werden, um einen guten Fortschritt zu erzielen (so hat man die Anzahl der Neuronen besser - klein).
Mann, was für ein riesiges Thema. Jetzt google ich Blätter. In etwa 5 Jahren werde ich den MO-Zweig erreichen, aber ich werde ihn nicht wieder lesen
Umstieg von Toyota auf einen alten Sportwagen Da MT5 in der Anzahl der optimierbaren Parameter begrenzt ist, bin ich auf NeuroPro 1999 umgestiegen, aus dem Artikel hier -Neuronale Netze kostenlos und einfach - Verbindung von NeuroPro und MetaTrader 5.
Ich habe die Architektur in der Quantität erhöht: in MT5 war es 5-5-5-5, und hier ist es 10-10-10, und das Training ist bereits real (um genauer zu sein - Standard, durch die Methode der Fehlerrückvermehrung und andere interne Funktionen innerhalb des Programms. Sein Autor kümmert sich nicht darum und wird nicht einmal die Seltenheit aktualisieren - basierend auf seinen Antworten auf meine Fragen hat er kein Interesse daran, NeoroPro weiterzuentwickeln, Multithreading, moderne Methoden einzuführen, etc.
Bin in so etwas wie Spread und Kommission gestolpert.
Die machen das neuronale Netz schnell kaputt. Danke MT5, du weißt, wie man nüchtern wird. Ich hätte schon vor langer Zeit von MT4 zu euch wechseln sollen.
@ Andrey Dik hatte schon vor vielen Jahren recht - der Gral liegt immer noch beim Spread mit der Kommission. Sobald man sie entfernt - grast das neuronale Netz vorwärts.
Merkwürdiges Phänomen: Das Training mit der "Erweiterungs"-Architektur, bei der die erste Schicht aus einem Neuron besteht, dann die zweite Schicht aus zwei, die dritte Schicht aus drei usw., ergab eine so lustige und doch merkwürdige Menge: Die Ergebnisse der Menge für den EURUSD-Optimierungszeitraum sind genau dieselben für andere Dollarpaare: Optimierung für 2021 auf EURUSD
Test auf GBPUSD für 2021
Test auf AUDUSD für 2021
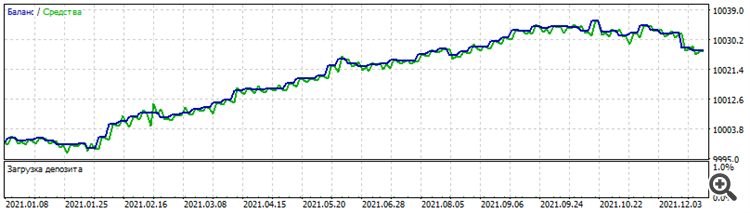

Test auf NZDUSD für 2021
Warum nur die Neugierigen? Weil es ein toter Satz ist, er funktioniert weder vorher noch nachher. Aber allein die Tatsache, dass es bei mehreren Dollar-Paaren im gleichen Zeitraum funktioniert, zeigt, dass es zwar eine gewisse Korrelation zwischen ihnen gibt, die Preise der einzelnen Paare aber dennochunterschiedlich sind.
Merkwürdiges Phänomen: Das Training auf der "Erweiterungs"-Architektur, bei der die erste Schicht aus einem Neuron besteht, dann die zweite Schicht aus zwei, die dritte Schicht aus drei usw., ergab eine so lustige und doch merkwürdige Menge: Die Ergebnisse der Menge für den EURUSD-Optimierungszeitraum sind genau dieselben für andere Dollarpaare: Optimierung für 2021 auf EURUSD
Test auf GBPUSD für 2021
Test auf AUDUSD für 2021 Test auf NZDUSD für 2021 Warum nur das Kuriose? Ja, weil es ein toter Satz ist, er funktioniert weder vorher noch nachher. Aber allein die Tatsache, dass er bei mehreren Dollar-Paaren im gleichen Zeitraum funktioniert, zeigt, dass es zwar eine gewisse Korrelation zwischen ihnen gibt, die Preise der einzelnen Paare aber dennochunterschiedlich sind.
Nein, sie sind unterschiedlich.
Bei allen Paaren, mit Ausnahme des Euro, ist ein Drittel des Saldos am Ende an der gleichen Stelle.