import catboost
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from catboost import CatBoostRegressor
x = [[1,2],[2,2],[3,2],[4,2],[5,2],[6,2],[7,2],[8,2],[9,2]]
y = [2,4,6,8,10,12,14,16,18]
print('-------- 1 DecisionTree')
tree = DecisionTreeRegressor().fit(x,y)
for ix in x: print(' {:2.2f}*{:2.2f}={:2.2f} '.format(ix[0],ix[1],tree.predict([ix])[0]))
print('-------- RandomForest 10 Tree')
regr = RandomForestRegressor(n_estimators=10).fit(x,y)
for ix in x: print(' {:2.2f}*{:2.2f}={:2.2f} '.format(ix[0],ix[1],regr.predict([ix])[0]))
print('-------- CatBoost 10 Tree')
cat = CatBoostRegressor(iterations=10, verbose=False).fit(x,y)
for ix in x: print(' {:2.2f}*{:2.2f}={:2.2f} '.format(ix[0],ix[1],cat.predict([ix])[0]))
Ivan Negreshniy,我不明白,我在CatBoost中创建了模型,但它应该如何连接,是不是从EA到python的桥梁/通道,预测值将被传递,而在相反的方向,计算结果将被接收 - 一个具体的类?
据我所知,CatBoost允许卸载模型的代码,我不明白,但我将附上它,以估计专业性,除非它能以某种方式整合到MQL中,而不是使用python?而且,CatBoost有C++的库,他们不能让它们在MQL中工作,也不使用python和控制台命令?
不清楚的是,直接从Expert Advisor获得数据和模型的端到端自动化工作需要这座桥梁,包括创建、设置、训练等。而CatBoost转入文件的是特定模型的序列化,只能用于计算。
当然,你可以在编辑器中基于这些文件创建一个EA,但它与通常的逻辑僵化的EA不会有太大区别,如果这是目的,IMHO,通过使用模板的训练更容易实现,这是我建议的。https://www.mql5.com/ru/forum/270216
因为那里的所有东西都是自动训练和生成的,而且每棵树的代码都被转换成一个独立的、有逻辑的函数,如果你完成的话,可能更容易分析,执行起来也更快,我们以后可以进行比较。
对我来说,首先是劳动密集型。
大多数预测器都是将指标捆绑在一起,并将其拟合到ATR日线 上。其余的时间序列工作是表征预测器。
我有两个问题
1)请解释一下它的含义--一堆指标并将它们装入ATR日记。
2) 为什么是猫咪?你确定它比其他助推器好吗?
这里不清楚的是,直接从EA处理数据和模型的端到端自动化需要桥梁,包括创建、配置、培训等。
我明白了,也就是说,主要是能够创建自己的界面,与MoD库一起工作,对吗?这相当于我现在打算做同样的界面,但通过激活一个exe文件并向其输入命令。总的来说,是的,通过python来做是很有趣的,但不幸的是,我没有这样的知识。
而CatBoost转储到文件中的是一个特定模型的序列化,它只能用于计算。
当然,我们可以在编辑器中基于这些文件创建一个EA,但它将与具有僵化逻辑的普通EA没有太大区别,如果这是目标,那么IMHO,在模板的帮助下,通过训练实现它要容易得多,我建议。https://www.mql5.com/ru/forum/270216
如果你理解这段代码,也许你可以告诉我如何将它翻译成可读的形式,例如给每个规则一个完整的描述,就像我在从R处理模型后对叶子所做的那样
我只是不能理解这段代码中的加密算法--你能做它的描述/解释器吗(也许要收费)?
而如果这就是目标,IMHO,通过模式学习来实现它要容易得多,这是我建议的。https://www.mql5.com/ru/forum/270216
因为那里所有的东西都是自动训练和生成的,而且每棵树的代码都被转换成独立的逻辑函数,这也许更容易分析,在运行时也更快,如果你会完成,我们可以稍后进行比较。
我们的目标不仅仅是得到一个模型,而是得到树叶,评估它们,然后在这些树叶的基础上生成新模型。
我在看那个题目,我不太明白,自动建网的过程是在裸露的指标和标记的基础上建立的,信息被转移到模板上,而我有指标的后处理,加上我使用了我的一些指标,我不想公开,所以事实证明,这个方法是不可用的,同样--你不能从中得到叶子...
我有两个问题
1) 请解释什么是捆绑指标并将其纳入ATR日线的 意思
2)为什么是猫咪?你确定它比其他助推器更好吗? 或者说脚手架
1.这是我对市场的看法,即价格有一个运动计划,在一天开始时由ATR定义,然后根据障碍(阻力水平(市场参与者做出/修改交易决定的水平),这是,包括指标),这个计划被执行或不执行。预测者描述了这些关于运动计划的障碍。因此,这是图形上的样子--沿着ATR范围的网格,里面有不同的指标
来自MetaTrader平台的截图
Si-9.18, M1, 2018.08.30
JSC ''Otkritie Broker'', MetaTrader 5, Real
用于记忆
2.CatBoost--刚刚有一些人帮助设置了它。另外,它显然比我以前在R中创建模型的方法工作得更快,同时也更有效率,有文档和通过DOS的命令:)与其他工具相比,例如Deductor Studio,它更稳定,模型也更好出,再加上最后一个是收费的,这里一切都免费。
你可能感兴趣,我遇到了
我想建立一个关于树形优化的系统,或者说通过用优化器建立树形......有趣的话题,但我不知道从哪里开始 :) )
https://explained.ai/
谢谢你的关心!
语言障碍使阅读变得非常痛苦,而译者又使文本变得愚蠢或可笑......。唉。
使用google翻译插件(chrome),一次翻译一个单词。
我在chrome中使用ImTranslator 插件,当你一次性翻译一个段落时,当你选择单词并在上下文菜单上点击右键时,它可以正常工作
不需要谷歌点击
这是个什么样的插件?它曾经在Chrome浏览器中工作,后来停止了,我不知道如何设置它。
我明白了,也就是说,这首先是一个创建你自己的界面来与MoD库合作的机会,对吗?这相当于我现在打算做同样的界面,但通过激活一个exe文件并向其输入命令。总的来说,是的,通过python来做是很有趣的,但不幸的是,我没有这样的知识。
如果你理解这段代码,你能告诉我如何把它翻译成可读的形式,例如给每个规则一个完整的描述,例如,我在从R处理模型后对叶子所做的描述
我只是不能理解这段代码中的加密算法--你能做它的说明/解释器吗(也许要收费)?
我们的目标不仅仅是得到一个模型,而是得到树叶,评估它们,然后在这些树叶的基础上生成新模型。
我读过那个主题,但我不明白,自动建网的过程是在裸露的指标和标记的基础上建立的,信息被转移到模板上,在我的情况下,有指标的后期处理,加上我使用了我的一些指标,我不想公开,所以事实证明,这个方法是不可用的,同样--你不能从它那里得到叶子...
我不明白为什么可能需要手动编辑分裂和叶子决定树,是的,我有所有的分支自动转换为逻辑运算符,但说实话,不记得我自己曾纠正过。
而一般来说,值得挖掘的是CatBoost 代码,我怎么能确定呢。
例如,我把上述测试放在python上,我的神经网络通过乘法表学习,现在把它用于测试树和森林(DecisionTree、RandomForest、CatBoost)。
这就是结果--显然这对CatBoost不利,因为2乘以2等于0.5...:)
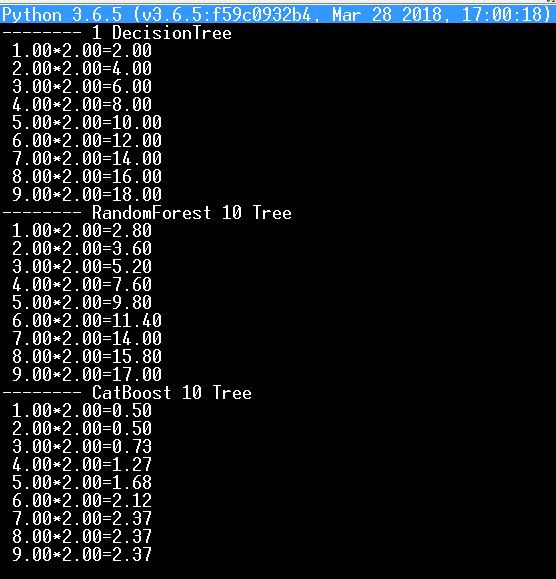
诚然,如果你采取成千上万的树木,结果就会改善。我不明白为什么需要手动编辑决策树的分叉和叶子,是的,我把所有的分支都自动转换为逻辑运算符,但坦率地说,我不记得,我曾经自己纠正过它们。
而一般来说,值得挖掘的是CatBoost代码,我怎么能确定呢。
例如,我把上述测试放在python上,我的神经网络通过乘法表学习,现在把它用于测试树和森林(DecisionTree、RandomForest、CatBoost)。
这就是结果--显然它不支持CatBoost,就像2乘以2等于0.5...:)
来吧,不可能的,森林或助推器不能应付乘法表。
不可能,森林或提升不可能处理好乘法表的问题。