Брутфорс-подход к поиску закономерностей (Часть VI): Циклическая оптимизация

Содержание
- Введение
- Комплекс
- Новый оптимизационный алгоритм
- Важнейший критерий оптимизации
- Автоматический поиск торговых конфигураций
- Заключение
- Ссылки
Введение
Исходя из краткого экскурса предыдущей статьи, могу сказать, что это лишь поверхностное описание всех функций, которые я ввел в свой алгоритм. Они касаются не только полной автоматизации создания советников, но также таких важных функций, как полная автоматизация процесса оптимизации и отбора результатов с последующим применением для автоматической торговли, или же создания более прогрессивных советников, которые я покажу чуть позже.
Благодаря симбиозу торговых терминалов, универсальных советников и самого алгоритма, при наличии вычислительных возможностей можно полностью избавиться от ручной разработки, или же, в худшем случае, на порядок снизить трудоемкость возможных доработок. В этой статье я начну описывать наиболее важные аспекты этих новшеств.
Комплекс
Важнейшим фактором при создании и последующих модификациях подобных решений со временем для меня стало понимание возможности обеспечения максимальной автоматизации рутинных действий. К рутинным действиям, в данном случае, относится вся необязательная работа человека:
- Генерация идей.
- Создание теории.
- Написание кода по теории.
- Корректировка кода.
- Постоянный процесс переоптимизации советников.
- Постоянный процесс отбора советников.
- Обслуживание советников.
- Работа с терминалами.
- Эксперименты и практика.
- Прочее.
Как видно, номенклатура всей этой рутины достаточно широка. Я отношусь к этому именно как к рутине, потому что все эти вещи, как мне удалось доказать, абсолютно автоматизируемы. Я привел общий список. Совершенно не важно, кто вы – алготрейдер, программист или все вместе. Совершенно не важно, умеете вы программировать или нет, даже если нет, то в любом случае вы столкнетесь, как минимум, с половиной из этого списка. Я сейчас не говорю о случаях, когда вы купили советник в маркете, повесили на график и успокоились, нажав одну кнопку. Так, конечно, бывает, но крайне редко.
Понимая все это, сначала мне пришлось автоматизировать то, что лежит на поверхности. Я концептуально описывал всю эту оптимизацию в предыдущей статье. Тем не менее, когда делаешь что-то подобное, начинаешь понимать, как все это дело улучшить, исходя из уже реализованного функционала. Основными идеями, в этой связи, для меня были следующие несколько вещей:
- Улучшение механизма оптимизации.
- Создание механизма слияния советников (склейка ботов).
- Правильная архитектура путей взаимодействия всех компонентов.
Это все очень сжато. Сейчас я опишу подробнее. Под улучшением оптимизации я понимаю сразу набор нескольких факторов. Все это продумывается в рамках выбранной парадигмы построения всей системы:
- Ускорение оптимизации благодаря избавлению от тиков.
- Ускорение оптимизации благодаря избавлению от контроля кривой прибыли между точками принятия торговых решений.
- Улучшение качества оптимизации благодаря введению собственных критериев оптимизации.
- Максимизация эффективности форвард-периода.
В закоулках портала до сих пор не могут стихнуть споры о том, нужна ли оптимизация вообще и что она дает. Раньше у меня было довольно категоричное отношение к данному действию, в большей степени, обусловленное влиянием отдельных людей, обитающих на форумах и вообще на портале. Теперь же меня это мнение не волнует совсем, и я скажу так, все зависит от того, умеете ли вы правильно пользоваться оптимизацией и смотря для чего вы ее используете и как вы это делаете. При условии правильного применения, это действие дает желаемый результат. В целом получается, что действие это крайне полезное.
Многие недолюбливают оптимизацию, есть две объективные причины данного факта:
- Непонимание основ (зачем, что и как делать, как отбирать результаты и все, что с этим связано, в том числе отсутствие опыта).
- Несовершенство оптимизационных алгоритмов.
На самом деле, оба фактора усиливают друг друга. Справедливости ради, хочу сказать, что оптимизатор MetaTrader 5 конструкционно исполнен безукоризненно, но с точки зрения критериев оптимизации и возможных фильтров, там еще поле непаханое. Пока весь этот функционал на уровне детской песочницы. Мало кто задумывается о том, как достигать плюсовых форвард-периодов и как, самое главное, контролировать этот процесс. Я давно задумываюсь, и можно сказать, добрая половина моего материала именно об этом.
Новый оптимизационный алгоритм
Помимо основных известных оценочных критериев любого бэктеста, для более эффективного отбора результатов и последующего применения настроек, можно придумать некоторые комбинированные характеристики, которые могут помочь многократно увеличить ценность любого алгоритма. Плюс данных характеристик в том, что они могут ускорять процессы поиска рабочих настроек. Для этого я создал некое подобие отчета тестера стратегий, примерно как в MetaTrader:
рисунок 1

С помощью данного инструмента я могу выбирать понравившийся вариант с помощью обычного клика. По клику происходит генерация настройки, которую я могу сразу брать и перемещать в соответствующую папку терминала, для того чтобы универсальные советники прочитали ее и начали по ней торговать. А также, если захочу, могу нажать на кнопку генерации советника и он будет построен в том случае, если мне нужен отдельный советник с зашитой внутрь настройкой. Также там есть и график кривой прибыли, который перерисовывается при выборе очередного варианта из таблицы.
Давайте разберемся с тем, что же считается в этой таблице. Первичными элементами для расчета данных характеристик являются следующие данные:
- Points: прибыль всего бэктеста в "_Point" соответствующего инструмента.
- Orders: количество полностью открытых и закрытых ордеров (идут друг за другом в строгом порядке, по правилу "может быть лишь один открытый ордер").
- Drawdown: просадка по балансу.
Исходя из этих величин считаются следующие торговые характеристики:
- Math Waiting: математическое ожидание в пунктах.
- P Factor: аналог профит фактора нормированный в диапазон [-1 ... 0 ... 1] (мой критерий).
- Martingale: показатель применимости мартингейла (мой критерий).
- MPM Complex: составной показатель из предыдущих трех (мой критерий).
Давайте теперь посмотрим, как считаются данные критерии:
формулы 1

Как видно, все критерии, которые я создал, являются очень простыми и, что самое главное, удобными для восприятия. Благодаря тому, что возрастание каждого из критериев говорит о том, что результат бэктеста лучше с точки зрения рассмотрения в рамках теории вероятностей, становится возможным перемножать данные критерии, как я сделал в критерии "MPM Complex". Общий показатель будет более эффективно производить сортировку результатов по их важности, и при массированных оптимизациях позволит сохранить больше качественных вариантов и удалить больше некачественных соответственно.
Отдельно хочу сказать, что в данных вычислениях все происходит именно в пунктах. Это только позитивно влияет на процесс оптимизации. Для вычислений используются строго положительные первичные величины, которые всегда вычисляются в начале, и уже на основе них вычисляется все остальное. Я думаю, стоит перечислить данные первичные величины, которых нет в таблице:
- Points Plus: сумма прибылей каждого прибыльного или нулевого ордера в пунктах
- Points Minus: сумма модулей убытков каждого убыточного ордера в пунктах
- Drawdown: просадка по балансу (считаю по своему)
Здесь самое интересное, как считается просадка. В нашем случае, это максимальная относительная просадка по балансу. Учитывая тот факт, что мой алгоритм тестирования отказывается от мониторинга кривой средств, то остальные виды просадок невозможно вычислить. Тем не менее, я думаю, что полезно было показать, как я считаю данную просадку:
рисунок 2

Определяется очень просто:
- Считаем стартовую точку бэктеста (старт отсчета первой просадки).
- Если торговля начинается с прибыли, то передвигаем эту точку наверх вслед за ростом баланса, до тех пор пока не появится первый минус (он знаменует начало вычисления просадки).
- Ждем, пока баланс не достигнет уровня точки отсчета, после чего фиксируем эту точку как новое начало отсчета.
- Возвращаемся на последний участок поиска просадки и ищем самую нижнюю точку на нем (от нее и считается величина просадки на данном участке).
- Повторяем весь процесс для всего бэктеста или кривой торговли.
Важно еще отметить, что последний цикл всегда останется незавершенным. Тем не менее, его просадка также учитывается, несмотря на то, что есть потенциальная возможность ее увеличения в случае продолжения тестирования в будущем. Но это не особо важный нюанс в данном случае.
Важнейший критерий оптимизации
Отдельно хочу коснуться самого важного фильтра. На самом деле, данный критерий является самым важным при отборе результатов оптимизации. Данного критерия нет в функционале оптимизатора MetaTrader 5, но я могу сказать, что это очень зря. Тем не менее, понимая, что никто меня не послушает, хочу дать теоретический материал для того, чтобы все желающие могли воспроизвести данный алгоритм у себя в коде. На самом деле, данный критерий мультифункционален к любому виду торговли и работает для абсолютно любых кривых прибыли, включая ставки на спорт, криптовалюту и все, что вы можете придумать. Критерий таков:
формулы 2

Давайте разберемся, что внутри данной формулы:
- N — количество полностью открытых и закрытых торговых позиций на протяжении всего бэктеста или участка торговли.
- B(i) — значение линии баланса после соответствующей закрытой позиции "i".
- L(i) — прямая, проведенная из нуля в самую последнюю точку баланса (финальный баланс).
Особенностью вычисления данного показателя является то, что для его вычисления необходимо произвести два бэктеста. Первый бэктест вычислит конечный баланс, и только после этого можно будет произвести вычисление соответствующего показателя, сохранив значение каждой точки баланса, чтобы не нужно было производить лишние вычисления. Тем не менее, так или иначе, данное вычисление можно назвать повторным бэктестом. Данную формулу можно применять в кастомных тестерах, которые можно встраивать в свои советники (те, кто знают, зачем).
Важно отметить, что данный показатель в целом можно видоизменить для большего понимания. Например, вот так:
формулы 3

С точки зрения восприятия и понимания, данная формула тяжелее. Но если рассматривать чисто прикладную плоскость, то подобный критерий удобен тем, что чем он выше, тем значит наша кривая баланса больше походит на прямую. Я касался подобных вопросов в предыдущих статьях, но не объяснял заложенный в них смысл. Так то, интуитивно, я думаю, многим понятно что и зачем, но далеко не всем. Для понимания, давайте сначала посмотрим на следующий рисунок:
рисунок 3

На данном рисунке изображена линия баланса и две кривые: одна из которых относится к нашей формуле (та, которая красного цвета), а вторая - для следующего модифицированного критерия (формулы 11). Я покажу его дальше, а сейчас давайте сфокусируемся на формуле, смысл которой я вам раскрываю.
Если представить наш бэктест в виде простого массива точек с балансами, то мы можем представить его как статистическую выборку и применять к ней формулы теории вероятностей. Прямую линию мы будем считать моделью, к которой мы стремимся, а саму кривую прибыли - реальным потоком данных, который стремится к нашей модели.
Важно понимать, что фактор линейности указывает на достоверность всего имеющегося набора торговых критериев. А в свою очередь, более высокая достоверность данных может свидетельствовать о возможном более длительном и качественном форвард-периоде (прибыльная торговля в будущем). Строго говоря, изначально рассмотрение подобных вещей мне следовало бы начать с рассмотрения случайных величин, но мне показалось, что такая подача должна упростить усвоение.
Давайте составим альтернативный аналог нашего фактора линейности с учетом возможных случайных выбросов. Для этого нам понадобится введение удобной для нас случайной величины и ее среднего для последующего вычисления дисперсии:
формулы 4

Для понимания, следует уточнить, что у нас имеется "N" полностью открытых и закрытых позиций, которые следуют строго друг за другом. А это значит, что у нас есть "N+1" точек, которые соединяют данные сегменты линии баланса. Нулевая точка у всех линий является общей, поэтому ее данные будут искажать результаты в сторону улучшения, как и последняя точка. Поэтому мы их выкидываем из расчетов, и у нас остается "N-1" точек, по которым мы будем производить вычисления.
Очень интересно получился выбор выражения для преобразования массивов значений двух линий в одну. Обратите внимание на следующую дробь:
формулы 5

Важно здесь то, что во всех случаях мы делим все на конечный баланс. Таким образом, мы приводим все к относительной величине, которая обеспечивает равноценность вычисляемых характеристик для всех тестируемых стратегий, без исключения. Та же дробь присутствует в самом первом и простом критерии фактора линейности не случайно, так как он построен на том же самом соображении. Но давайте завершим построение нашего альтернативного критерия. Для этого можно воспользоваться таким широко известным понятием, как дисперсия:
формулы 6

Дисперсия - это ни что иное, как среднее арифметическое квадрата отклонения от среднего всей выборки. Я сразу туда подставил наши случайные величины, выражения для которых были определены выше. У идеальной кривой среднее отклонение равно нулю, и, как следствие, дисперсия данной выборки также будет равна нулю. Исходя из этих данных, несложно догадаться, что данную дисперсию благодаря своей структуре - используемой случайной величине или выборке (кому как угодно) - можно использовать в качестве альтернативного фактора линейности. Более того, оба критерия можно использовать тандемом для более эффективного ограничения параметров выборки, хотя, честно говоря, я использую лишь первый критерий.
Ну и справедливости ради, давайте посмотрим на аналогичный, более удобный для восприятия критерий, в основе которого также лежит новый, определенный нами фактор линейности:
формулы 7
![]()
Как видно, он идентичен аналогичному критерию, который построен на основе первого (формулы 2). Тем не менее, и эти два критерия далеко не предел того, что можно придумать. Очевидным фактом, свидетельствующим в пользу данного соображения, является то, что данный критерий слишком идеализирован и больше годится для идеальных моделей, и подстроить тот или иной советник к более-менее значимому соответствию будет крайне сложно. Думаю, стоит перечислить негативные факторы, которые будут очевидны спустя некоторое время после применения данных формул:
- Критическое уменьшение количества трейдов (уменьшает достоверность результатов)
- Отброс максимального количества эффективных сценариев (в зависимости от стратегии, не всегда кривая стремится именно к прямой)
Данные недостатки весьма критичны, поскольку цель не в том, чтобы отбросить хорошие стратегии, а, наоборот, находить новые улучшенные критерии, лишенные данных недостатков. Эти недостатки можно полностью или частично нивелировать, вводя сразу несколько предпочтительных линий, каждая из которых может считаться допустимой или предпочтительной моделью. Чтобы понять новый улучшенный критерий, избавленный от данных недостатков, нужно лишь понять соответствующую замену:
формулы 8

После чего мы можем вычислить фактор соответствия для каждой кривой из списка:
формулы 9

Ну, и аналогично, точно также можно посчитать альтернативный критерий, учитывающий случайные выбросы, также для каждой из кривой:
формулы 10

После чего нужно будет посчитать следующее:
формулы 11

Здесь я ввожу критерий, называемый фактором семейства кривых. Фактически, данным действием мы одновременно находим наиболее похожую кривую для нашей кривой торговли и сразу находим фактор соответствия ей же. Кривая с минимальным фактором соответствия и является наиболее близкой к реальной ситуации. Ее значение мы и принимаем в качестве значения модифицированного критерия, ну и, само собой, вычисление может быть произведено двумя способами, в зависимости от того, какая из двух вариаций нам нравится больше.
Это все очень здорово, но здесь, как многие заметили, есть нюансы с отбором подобного семейства кривых. Для того чтобы правильно описать такое семейство, можно придерживаться различных соображений, но вот вам мои соображения:
- Все кривые не должны иметь точек перегиба (каждая следующая промежуточная точка должна быть строго выше предшествующей).
- Кривая должна быть вогнута (крутость кривой может либо быть постоянной, либо может только расти).
- Вогнутость кривой должна быть регулируемой (например, величина прогиба должна регулироваться с помощью некоторой относительной величины или в процентах).
- Простота модели кривой (модель лучше основывать на изначально простых и понятных графических моделях).
Отдельно хочу сказать, что это лишь первоначальная вариация такого семейства кривых, с которой я начал, но можно сделать и другие, более обширные и учитывающие все желаемые конфигурации, которые могут полностью избавить нас от потерь качественных настроек. В будущем я возьмусь за данную задачку, а пока я буду касаться лишь той первоначальной стратегии семейства вогнутых кривых. Такое семейство мне удалось создать довольно легко, применив свои знания в области математики. Давайте сразу покажу вам, как в итоге выглядит данное семейство кривых:
рисунок 4

При построении подобного семейства, я использовал абстракцию упругого стержня, который лежит на вертикальных опорах. Степень прогиба такого стержня зависит от точки приложения силы и её величины. Понятно, что это лишь чем-то напоминает подобную ситуацию, но вполне достаточно для выработки некой визуально похожей модели. В данной ситуации, конечно, следует в первую очередь определить координату экстремума, которая должна совпадать с одной из точек на графике бэк-теста, а там ось абсцисс представлена как раз индексами трейдов, начиная с нуля. Я вычисляю её так:
формулы 12

Здесь предусмотрено два случая: для четных и нечетных "N". В случае, если "N" получается четным, то невозможно просто разделить его на два, так как индекс должен являться целым числом. Я именно этот случай, кстати говоря, изобразил на последнем рисунке. Там точка приложения силы чуть ближе к началу. Можно, конечно, сделать и наоборот, чуть ближе к концу, но это будет существенно только при малом количестве трейдов, как я и изобразил на рисунке. При увеличении количества трейдов все это не будет играть сколь угодно ощутимой роли для оптимизационных алгоритмов.
Задав величину прогиба "P" в процентах и конечный баланс бэктеста "B", предварительно определив координату экстремума, можно приступать к последовательному вычислению дальнейших компонентов для построения выражений для каждой из принятого семейства кривых. Дальше нам понадобится крутость прямой, соединяющей начало и конец бэктеста:
формулы 13

Кстати, говоря, еще одной особенностью данных кривых является тот факт, что тангенс угла наклона касательной к каждой из кривых в точках с абсциссой "N0" идентичен "K". При построении формул я требовал этого условия от задачи. Это можно увидеть и графически на последнем рисунке (рисунок 4), и какие-то формулы и тождества там тоже есть. Давайте идти дальше. Теперь нужно вычислить следующую величину:
формулы 14

Здесь важно отметить, что "P" для каждой кривой из семейства задается свой. Строго говоря, это формулы для построения одной кривой из семейства. Данные расчеты следует повторить для каждой кривой из семейства. После нужно вычислить еще один важный коэффициент:
формулы 15
![]()
В смысл данных конструкций не нужно вникать. Они лишь созданы для упрощения процесса построения кривых. Осталось вычислить последний вспомогательный коэффициент:
формулы 16

Теперь, на основе полученных данных, можно получить математическое выражение для вычисления точек сконструированной кривой. Однако, предварительно необходимо уточнить, что кривая не описывается одной формулой. Слева от точки "N0" работает одна формула, а справа - другая. Для упрощения понимания можно сделать следующее:
формулы 17
![]()
Теперь, можно увидеть итоговые формулы:
формулы 18

Еще, это можно переписать вот так:
формулы 19

Строго говоря, эту функцию следует использовать в качестве дискретной и вспомогательной. Но тем не менее, она позволяет вычислять значения в дробных "i". Что, конечно же, вряд ли имеет какие-либо полезные для нас плюшки в контексте рассматриваемой задачи.
Раз, уж я даю такую математику, я обязан дать и примеры реализации данного алгоритма. Думаю, всем будет интересно получить готовый код, который будет легче адаптировать под свои системы. Начнем с того, что определим основные переменные и методы, которые упростят вычисление необходимых величин:
//+------------------------------------------------------------------+ //| Количество линий в модели баланса | //+------------------------------------------------------------------+ #define Lines 11 //+------------------------------------------------------------------+ //| Инициализация переменных | //+------------------------------------------------------------------+ double MaxPercent = 10.0; double BalanceMidK[,Lines]; double Deviations[Lines]; int Segments; double K; //+------------------------------------------------------------------+ //| Метод для инициализации необходимых переменных и массивов | //| Параметры: количество сегментов и начальный баланс | //+------------------------------------------------------------------+ void InitLines(int SegmentsInput, double BalanceInput) { Segments = SegmentsInput; K = BalanceInput / Segments; ArrayResize(BalanceMidK,Segments+1); ZeroStartBalances(); ZeroDeviations(); BuildBalances(); } //+------------------------------------------------------------------+ //| Сброс переменных для инкремента балансов | //+------------------------------------------------------------------+ void ZeroStartBalances() { for (int i = 0; i < Lines; i++ ) { for (int j = 0; j <= Segments; j++) { BalanceMidK[j,i] = 0.0; } } } //+------------------------------------------------------------------+ //| Сброс отклонений | //+------------------------------------------------------------------+ void ZeroDeviations() { for (int i = 0; i < Lines; i++) { Deviations[i] = -1.0; } }
Код рассчитан на возможность повторного использования. После очередного расчета можно производить расчет показателя для иной кривой баланса, предварительно вызвав метод "InitLines". В него нужно дать конечный баланс бэктеста и количество трейдов, после чего можно приступать к построению наших кривых на основе этих данных:
//+------------------------------------------------------------------+ //| Построение всех балансов | //+------------------------------------------------------------------+ void BuildBalances() { int N0 = MathFloor(Segments / 2.0) - Segments / 2.0 == 0 ? Segments / 2 : (int)MathFloor(Segments / 2.0);//вычисление первого необходимого N0 for (int i = 0; i < Lines; i++) { if (i==0)//самая первая и прямая линия { for (int j = 0; j <= Segments; j++) { BalanceMidK[j,i] = K*j; } } else//построение изогнутых линий { double ThisP = i * (MaxPercent / 10.0);//вычисление процента изогнутости текущей линии double KDelta = ( (ThisP /100.0) * K * Segments) / (MathPow(N0,2)/2.0 );//вычисление первого вспомогательного коэффициента double Psi0 = -KDelta * N0;//вычисление второго вспомогательного коэффициента double KDelta1 = ((ThisP / 100.0) * K * Segments) / (MathPow(Segments-N0, 2) / 2.0);//вычисление последнего вспомогательного коэффициента //на этом закончено вычисление вспомогательных коэффициентов для конкретной линии, можно приступать к ее построению for (int j = 0; j <= N0; j++)//построение первой половины кривой { BalanceMidK[j,i] = (K + Psi0 + (KDelta * j) / 2.0) * j; } for (int j = N0; j <= Segments; j++)//построение второй половины кривой { BalanceMidK[j,i] = BalanceMidK[i, N0] + (K + (KDelta1 * (j-N0)) / 2.0) * (j-N0); } } } }
Обратите внимание, что "Lines" определяет, сколько кривых будет в нашем семействе. Вогнутость постепенно растет от нуля (прямая) и так далее до "MaxPercent", ровно так, как я показывал на соответствующем рисунке. После чего можно посчитать отклонение для каждой из кривых и выбрать минимальное:
//+------------------------------------------------------------------+ //| Вычисление минимального отклонения от всех линий | //| Параметры: исходный баланс, переданный по ссылке | //| Возвращает: минимальное отклонение | //+------------------------------------------------------------------+ double CalculateMinDeviation(double &OriginalBalance[]) { //определить максимальное относительное отклонение для каждой кривой for (int i = 0; i < Lines; i++) { for (int j = 0; j <= Segments; j++) { double CurrentDeviation = OriginalBalance[Segments] ? MathAbs(OriginalBalance[j] - BalanceMidK[j, i]) / OriginalBalance[Segments] : -1.0; if (CurrentDeviation > Deviations[i]) { Deviations[i] = CurrentDeviation; } } } //определить кривую с минимальным отклонением и само отклонение double MinDeviation=0.0; for (int i = 0; i < Lines; i++) { if ( Deviations[i] != -1.0 && MinDeviation == 0.0) { MinDeviation = Deviations[i]; } else if (Deviations[i] != -1.0 && Deviations[i] < MinDeviation) { MinDeviation = Deviations[i]; } } return MinDeviation; }
Пользоваться этим стоит так:
- Определение массива оригинального баланса "OriginalBalance".
- На его основе определяем его длину "SegmentsInput" и конечный баланс "BalanceInput" и вызываем метод "InitLines".
- После чего строим кривые, вызвав метод "BuildBalances".
- Так как кривые построены, можно считать наш усовершенствованный критерий семейства кривых "CalculateMinDeviation".
На этом расчет критерия будет завершен. Я думаю, как посчитать "Curve Family Factor", все разберутся очень легко. Это уже здесь приводить не обязательно.
Автоматический поиск торговых конфигураций
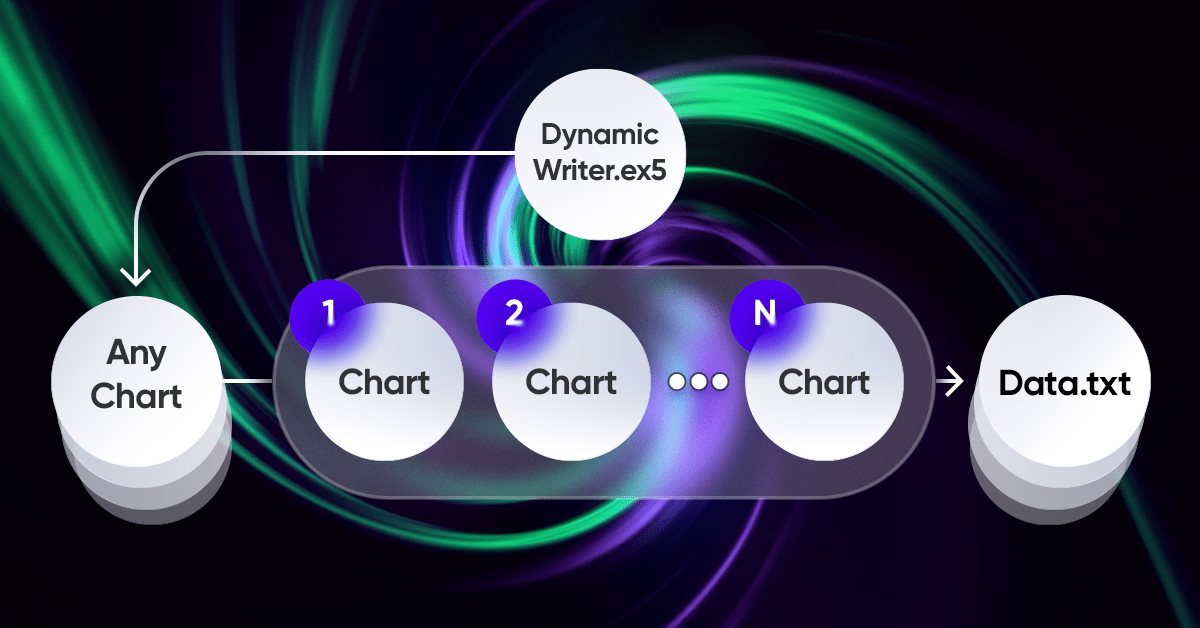
Самым главным элементом во всей идее является система взаимодействия между терминалом и моей программой. Фактически, она является циклическим оптимизатором с расширенными оптимизационными критериями, самому важному из которых я посветил весь предыдущий раздел. Для того, чтобы вся система функционировала, сперва необходим источник котировок, коим и выступает один из терминалов MetaTrader 5. Как я уже показывал в предыдущей статье, котировки записываются в файл с удобным мне форматом. Это делается с помощью советника, который функционирует довольно странно на первый взгляд:
. 
Я посчитал довольно интересным и полезным опытом применение своей уникальной схемы функционирования советников. Здесь представлена лишь демонстрация на примере тех задач, которые нужно было решать именно мне, но это все можно применять и для торговых советников:

Особенностью данной схемы является то, что мы выбираем один любой график на выбор. Этот график не будет использоваться в качестве торгового инструмента, во избежание дублирования данных, а выступает лишь в качестве обработчика тика или таймера. А остальные графики олицетворяют собой те инструменты-периоды, котировки по которым нам нужно генерировать.
Процесс записи котировок представляет собой случайный выбор котировок с помощью генератора случайных чисел. Можно оптимизировать этот процесс, если требуется. Запись происходит через определенный промежуток времени с помощью данной основной функции:
//+------------------------------------------------------------------+ //| Функция для записи данных, если они присутствуют | //| Записывает котировки в файл | //+------------------------------------------------------------------+ void WriteDataIfPresent() { // Объявляем массив для хранения котировок MqlRates rates[]; ArraySetAsSeries(rates, false); // Выбираем случайный график из тех, что мы добавили в рабочую область ChartData Chart = SelectAnyChart(); // Если строка имени файла не пуста if (Chart.FileNameString != "") { // Копируем котировки и рассчитываем реальное количество баров int copied = CopyRates(Chart.SymbolX, Chart.PeriodX, 1, int((YearsE*(365.0*(5.0/7.0)*24*60*60)) / double(PeriodSeconds(Chart.PeriodX))), rates); // Рассчитываем идеальное количество баров int ideal = int((YearsE*(365.0*(5.0/7.0)*24*60*60)) / double(PeriodSeconds(Chart.PeriodX))); // Рассчитываем процент полученных данных double Percent = 100.0 * copied / ideal; // Если полученные данные не сильно отличаются от желаемых, // то мы их принимаем и записываем в файл if (Percent >= 95.0) { // Открываем файл (создаем, если его нет, // в противном случае затираем все данные, что были в нем) OpenAndWriteStart(rates, Chart, CommonE); WriteAllBars(rates); // Записываем все данные в файл WriteEnd(rates); // Дописываем в конец CloseFile(); // Закрываем и сохраняем файл с данными } else { // Если котировок гораздо меньше, чем требуется для расчета Print("Слишком мало данных"); } } }
Функция "WriteDataIfPresent" записывает в файл информацию о котировках с выбранного графика, если копированные данные составляют не менее 95% от идеального количества баров, рассчитанного на основе заданных параметров. В случае, если копированных данных меньше 95%, функция выводит сообщение "Слишком мало данных". Если файл с заданным именем не существует, функция создаёт его.
Для функционирования этого кода необходимо дополнительно описать следующее:
//+------------------------------------------------------------------+ //| Структура ChartData | //| Цель: Хранение необходимых данных графика | //+------------------------------------------------------------------+ struct ChartData { string FileNameString; string SymbolX; ENUM_TIMEFRAMES PeriodX; }; //+------------------------------------------------------------------+ //| Функция Randomindex | //| Цель: Получить случайное число с равномерным распределением | //+------------------------------------------------------------------+ int Randomindex(int start, int end) { return start + int((double(MathRand())/32767.0)*double(end-start+1)); } //+------------------------------------------------------------------+ //| Функция SelectAnyChart | //| Цель: Просмотр всех графиков, кроме текущего, и выбор одного из | //| них для записи котировок | //+------------------------------------------------------------------+ ChartData SelectAnyChart() { ChartData chosenChart; chosenChart.FileNameString = ""; int chartCount = 0; long currentChartId, previousChartId = ChartFirst(); // Подсчет количества графиков while (currentChartId = ChartNext(previousChartId)) { if(currentChartId < 0) { break; } previousChartId = currentChartId; if (currentChartId != ChartID()) { chartCount++; } } int randomChartIndex = Randomindex(0, chartCount - 1); chartCount = 0; currentChartId = ChartFirst(); previousChartId = currentChartId; // Выбор случайного графика while (currentChartId = ChartNext(previousChartId)) { if(currentChartId < 0) { break; } previousChartId = currentChartId; // Заполнение данных выбранного графика if (chartCount == randomChartIndex) { chosenChart.SymbolX = ChartSymbol(currentChartId); chosenChart.PeriodX = ChartPeriod(currentChartId); chosenChart.FileNameString = "DataHistory" + " " + chosenChart.SymbolX + " " + IntegerToString(CorrectPeriod(chosenChart.PeriodX)); } if (chartCount > randomChartIndex) { break; } if (currentChartId != ChartID()) { chartCount++; } } return chosenChart; }
Этот код используется для записи и анализа исторических данных финансового рынка (котировок) по разным валютам с различных графиков, которые могут быть открыты в терминале в данный момент.
- Структура "ChartData" используется для хранения данных о каждом графике, включая имя файла, символ (валютную пару) и временной промежуток (таймфрейм).
- Функция "Randomindex(start, end)" генерирует случайное число между "start" и "end". Это используется для случайного выбора одного из доступных графиков.
- "SelectAnyChart()" перебирает все открытые и доступные графики, исключая текущий, а потом случайно выбирает один из них для обработки.
Сгенерированные котировки автоматически подхватываются программой, после чего происходит автоматический поиск прибыльных конфигураций. Автоматизация всего процесса довольно сложна, но я постарался ужать ее в одной картинке:
рисунок 5

Существует три состояния данного алгоритма:
- Деактивирован.
- Ожидание котировок.
- Активен.
Если советник для записи котировок еще не сгенерировал ни одного файла или мы удалили все котировки из указанной папки, то алгоритм просто ждет их появления и приостанавливается на время. Что касается нашего усовершенствованного критерия, который я реализовал для вас в стиле MQL5, он также реализован как для брутфорса, так и для оптимизации:
рисунок 6

Продвинутый режим, как раз, оперирует фактором семейства кривых, в то время как стандартный алгоритм использует лишь фактор линейности. Остальные доработки слишком обширны, чтобы поместиться в данную статью. В следующей статье я покажу свой новый алгоритм склейки советников, который построен на основе универсального мультивалютного шаблона. Шаблон вешается на один график, но обрабатывает все склеенные торговые системы, не требуя запуска каждого советника на своем графике. Часть его функционала перекочевала в данную статью.
Заключение
Более детально рассмотрены новые возможности и идеи в области автоматизации процесса разработки и оптимизации торговых систем. Основными достижениями являются разработка нового оптимизационного алгоритма, создание механизма синхронизации терминалов и автоматического оптимизатора, а также важного критерия оптимизации - фактора кривой и семейства кривых. Это позволяет сократить время на разработку и улучшить качество получаемых результатов.
Важным дополнением стало также семейство вогнутых кривых, которые представляют собой более реалистическую модель баланса в контексте обратных форвард-периодов. Вычисление фактора соответствия каждой из кривых позволяет более точно выбирать оптимальные настройки для автоматической торговли.
Ссылки
- Брутфорс-подход к поиску закономерностей (Часть V): Взгляд с другой стороны
- Брутфорс-подход к поиску закономерностей (Часть IV): Минимальная функциональность
- Брутфорс-подход к поиску закономерностей (Часть III): Новые горизонты
- Брутфорс-подход к поиску закономерностей (Часть II): Погружение
- Брутфорс-подход к поиску закономерностей
А нужно
1) Разработать систему симуляций, доверительных интервалов и брать кривульку как результат не одно расчета торговли ТС как у вас, а например 50 симуляций ТС в разных средах, среднее этих 50 симуляций брать как результат фитнес функции который надо максимизировать/минимизировать.
2) В ходе поиска лучшей кривульки ( из п.1 ) алгоритмом оптимизации , каждую итерацию нужно коррекировать на прдмет множественного тестирования
А есть примеры, когда кто-либо применял такой подход и доводил его до практического результата? Вопрос без издевки, правда интересно.
А есть примеры, когда кто-либо применял такой подход и доводил его до практического результата? Вопрос без издевки, правда интересно.
Я применял и применяю.
Интересно было бы увидеть конкретные примеры. Понятно, что многие просто применяют (пусть и успешно) и молчат. Но должны же у кого-то быть и развернутые описания, что человек делал, что получил, и как это дальше торговало.
Интересно было бы увидеть конкретные примеры. Понятно, что многие просто применяют (пусть и успешно) и молчат. Но должны же у кого-то быть и развернутые описания, что человек делал, что получил, и как это дальше торговало.
Конкретные примеры вы можете увидеть в науке, медицыне как я и писал выше..
Что и как применять на рынке можете почитать в тех публикациях что выше..
Из за тотальной безграмотности трейдеров и околотредерских писак, примеры применения этих методов на рынках вы еще не скоро увидите в открытом доступе...
Но все эти методы уже много лет доступны и открыты в виде опенсорс проектов по науке о даных на нормальных ЯП..
На нормальном ЯП это все пишеться в 15 строк кода
А что за нормальность у языков программирования, как она определяется?
Вы знаете, на каком языке писал автор статьи основной код своей программы?
Думаете, что наличие специфичных библиотек признак нормальности языка?
Хотелось бы видеть обсуждения материала статьи. Автор выложил ряд формул для оценки работы стратегии, вот и пишите конкретно, про их недостатки, обоснованно.
Подгонка там у него будет или нет - неизвестно, так как отбор правил стратегии неизвестен. Мало ли там что под капотом. Может там отобранные какими то иными методами предикторы...
Автор ничего не навязывает, а рассказывает о своём виденье и своих достижениях, что приветствуется на этом ресурсе и даже материально поощряется.