
Нелинейные регрессионные модели на бирже

Введение
Вчера я в очередной раз сидел над отчетами своей торговой системы по регрессии. За окном падал мокрый снег, в кружке остывал кофе, а я все никак не мог отделаться от навязчивой мысли. Знаете, меня давно раздражали эти бесконечные RSI, Stochastic, MACD и прочие индикаторы. Черт возьми, как можно пытаться впихнуть живой и динамичный рынок в эти примитивные формулы? Каждый раз, когда я вижу очередного Ютуб-граальщика с его "священным" набором индикаторов, так и хочется спросить — человек, ты правда веришь, что эти калькуляторы семидесятых годов могут поймать сложную динамику современного рынка?
Последние три года я убил на попытки создать что-то действительно рабочее. Чего только не перепробовал — от простейших регрессий до навороченных нейронок. И знаете что? Результатов в классификации добиться удалось, а вот в регрессии — пока нет.
Там была каждый раз одна и та же история — на истории все работает как часы, а выпускаешь на реальный рынок — и привет, убытки. Помню, как радовался своей первой сверточной сети. Красота же — R2 под 1.00% на обучении. А потом — две недели торговли и минус 30% депозита. Классика — переобучение во всей красе. Врубаешь визуализацию форварда, и видишь, как при регрессии прогноз "улетает" от реальных цен все дальше и дальше, с течением времени...
Но я упрямый. После очередного слива решил копнуть глубже, засел за научные статьи. И знаете, что откопал в пыльных архивах? Оказывается, еще старина Мандельброт талдычил про фрактальную природу рынков. А мы все пытаемся линейными моделями торговать! Это все равно что пытаться измерить длину береговой линии линейкой — чем точнее меряешь, тем длиннее получается.
В какой-то момент меня осенило — а что если попробовать скрестить классический теханализ с нелинейной динамикой? Не эти топорные индикаторы, а что-то посерьезнее — дифференциальные уравнения, адаптивные коэффициенты. Звучит сложно, но по сути — просто попытка научиться говорить с рынком на его языке.
Короче говоря, взял я Python, подрубил библиотеки для машинного обучения и начал эксперименты. Сразу решил — никаких академических наворотов, только то, что можно реально использовать. Никаких суперкомпьютеров — обычный ноут Acer, супер-мощный VPS и терминал МetaТrader 5. Из всего этого и родилась модель, о которой я хочу рассказать.
Нет, это не очередной грааль. Граалей не бывает, это я уже давно понял. Просто делюсь опытом — как можно взять современную математику и применить её для реальной торговли. Без лишнего хайпа, но и без примитивизма "трендовых индикаторов". Получилось что-то среднее: достаточно умное, чтобы работать, но не настолько сложное, чтобы развалиться при первом же черном лебеде.
Математическая модель
Помню, как я пришел к этой формуле. Над этим кодом я работал с 2022-го, но не постоянно: подходами, я бы сказал — разработок много, поэтому ты периодически (немного хаотично) перебираешь их и доводишь одну за другой до результата. Помню, гонял графики, пытался поймать закономерности в движении евродоллара. И знаете, что меня зацепило? Рынок словно дышит — то плавно течет по тренду, то вдруг резко дергается, то входит в какой-то магический ритм. Как описать это математически? Как поймать эту живую динамику в формулы?
После я набросал первую версию уравнения. Вот оно, во всей красе:
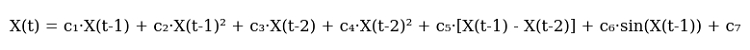
А вот она же в коде:
def equation(self, x_prev, coeffs): x_t1, x_t2 = x_prev[0], x_prev[1] return (coeffs[0] * x_t1 + # тренд coeffs[1] * x_t1**2 + # разгон coeffs[2] * x_t2 + # память рынка coeffs[3] * x_t2**2 + # инерция coeffs[4] * (x_t1 - x_t2) + # импульс coeffs[5] * np.sin(x_t1) + # ритм рынка coeffs[6]) # базовый уровень
Смотрите, как все закручено. Первые два члена — это попытка поймать текущее движение рынка. Знаете, как машина разгоняется? Сначала плавно, потом все быстрее. Именно поэтому тут и линейный член и квадратичный. Когда цена идет спокойно — работает линейная часть. Но стоит рынку разогнаться — квадратичный член подхватывает движение.
Дальше — самое интересное. Третий и четвертый члены смотрят чуть глубже в прошлое. Это как память рынка. Помните теорию Доу про то, что рынок помнит свои уровни? Вот и здесь то же самое. Причем опять с квадратичным ускорением — чтобы ловить резкие развороты.
Теперь моментум-компонента. Просто вычитаем предыдущую цену из текущей. Казалось бы, примитив. Но как же круто она работает на трендовых движениях! Когда рынок входит в раж и прет в одну сторону — этот член становится главной движущей силой прогноза.
Синус добавил почти случайно. Сидел, смотрел на графики и заметил — черт возьми, да тут же какая-то периодичность проглядывает! Особенно на часовках. Утром движение, потом затишье, снова движение... Похоже на синусоиду, не так ли? Сунул синусоиду в формулу, и модель словно прозрела, начала ловить эти ритмы.
Последний коэффициент — это такая подстраховка, базовый уровень. Знаете, главное не попасть, а удивить? Так вот тут наоборот — этот член не дает модели сильно удивить рынок своими прогнозами.
Перепробовал кучу других вариантов. Пихал туда и экспоненты, и логарифмы, и всякие навороченные тригонометрические функции. Толку чуть, а модель превращается в монстра. Знаете, как у Оккама — не плоди сущности сверх необходимого. Текущая версия получилась как раз такая — простая и рабочая.
Конечно, все эти коэффициенты надо как-то подбирать. Тут на помощь приходит старый добрый метод Нелдера-Мида. Но это уже совсем другая история, о которой расскажу в следующей части. Поверьте, там есть о чем поговорить — одних только граблей, на которые я наступил при оптимизации, хватит на отдельную статью.
Линейные компонентыНачнем с линейной части. Знаете, в чем главная фишка? Модель смотрит на два предыдущих значения цены, но по-разному. Первый коэффициент обычно выходит около 0.3-0.4 — это мгновенная реакция на последнее изменение. А вот второй — интереснее, он часто подбирается к 0.7, что говорит о более сильном влиянии предпоследней цены. Забавно, да? Рынок словно опирается на чуть более старые уровни, не доверяя последним колебаниям.
Квадратичные компонентыС квадратичными членами вышла интересная история. Изначально я их добавил просто для учета нелинейности, но потом заметил удивительную вещь. При спокойном рынке их вклад мизерный — коэффициенты болтаются около 0.01-0.02. Но стоит начаться сильному движению, и эти члены словно просыпаются. Особенно четко это видно на дневных графиках евродоллара — когда тренд набирает силу, квадратичные члены начинают доминировать, позволяя модели "разгоняться" вместе с ценой.
Momentum-составляющаяМоментум-компонента оказалась настоящим открытием. Казалось бы, банальная разница цен, но как же точно она отражает настроение рынка! В спокойные периоды её коэффициент держится около 0.2-0.3, но перед сильными движениями часто подскакивает до 0.5. Это стало для меня своеобразным индикатором готовящегося рывка — когда оптимизатор начинает задирать вес моментума, жди движения.
Циклическая компонентаА вот с циклической компонентой пришлось повозиться. Сначала пробовал разные периоды синусоиды, но потом понял, что рынок сам задает ритм. Достаточно позволить модели подстраивать амплитуду через коэффициент, а частота получается естественным образом из самих цен. Забавно наблюдать, как этот коэффициент меняется между европейской и американской сессиями — словно рынок действительно дышит в разном ритме.
Напоследок о свободном члене. Его роль оказалась куда важнее, чем я думал изначально. В периоды высокой волатильности он берет на себя роль якоря, не давая прогнозам улетать в космос. А в спокойные периоды помогает точнее учитывать общий уровень цен. Довольно часто его значение коррелирует с силой тренда — чем сильнее тренд, тем ближе свободный член к нулю.
Знаете, что самое интересное? Каждый раз, когда я пытался усложнить модель — добавить новые члены, использовать более сложные функции и проч. — результаты становились только хуже. Как будто рынок говорил: "Парень, не умничай, главное ты уже поймал". Текущая версия уравнения — это действительно золотая середина между сложностью и эффективностью. Семь коэффициентов — не больше и не меньше, каждый со своей четкой ролью в общем механизме прогнозирования.
Кстати, об оптимизации этих коэффициентов — это отдельная увлекательная история. Когда начнешь наблюдать, как метод Нелдера-Мида ищет оптимальные значения, невольно вспоминаешь теорию хаоса. Но об этом поговорим в следующей части — там есть на что посмотреть, поверьте.
Оптимизация модели. Рассмотрим процесс оптимизации с использованием алгоритма Nelder-Mead
Сегодня расскажу про самое интересное — как заставить нашу модель работать на реальных данных. После нескольких месяцев экспериментов с оптимизацией, десятков бессонных ночей и литров кофе, я наконец нащупал рабочий подход.
Начиналось все как обычно — с градиентного спуска. Классика жанра, первое, что приходит в голову любому, кто учился на датасайентиста. Три дня убил на реализацию, еще неделю на отладку... И что в итоге? Модель категорически отказывалась сходиться. То улетала в бесконечность, то застревала в локальных минимумах. Градиенты скакали, как бешеные.
Потом была неделя с генетическими алгоритмами. Красивая идея — пусть эволюция найдет лучшие коэффициенты. Написал, запустил... и офигел от времени работы. Комп гудел всю ночь, чтобы обработать одну неделю исторических данных. При этом результаты были настолько нестабильными, что впору было гадать на кофейной гуще.
И тут я наткнулся на метод Нелдера-Мида. Старый добрый симплекс-метод, разработанный еще в 1965 году. Никаких производных, никакой высшей математики — просто умное прощупывание пространства решений. Запустил и глазам не поверил. Алгоритм словно танцевал с рынком, плавно подбираясь к оптимальным значениям.
Вот основная функция потерь — простая, как топор, но работает безотказно:
def loss_function(self, coeffs, X_train, y_train): y_pred = np.array([self.equation(x, coeffs) for x in X_train]) mse = np.mean((y_pred - y_train)**2) r2 = r2_score(y_train, y_pred) # Сохраняем прогресс для анализа self.optimization_progress.append({ 'mse': mse, 'r2': r2, 'coeffs': coeffs.copy() }) return mse
Сначала я пытался усложнить функцию потерь, добавлял штрафы за большие коэффициенты, пихал туда MAPE и прочие метрики. Классическая ошибка разработчика — если что-то работает, надо обязательно это улучшить до полной неработоспособности. В итоге вернулся к простому MSE, и знаете что? Оказалось, что простота — действительно признак гениальности.
Особый кайф наблюдать за процессом оптимизации в реальном времени. Первые итерации — коэффициенты мечутся как безумные, MSE скачет, R² близок к нулю. Потом начинается самое интересное — алгоритм нащупывает правильное направление, и метрики плавно улучшаются. К сотой итерации уже видно, будет толк или нет, а к трехсотой — обычно система выходит на стабильный уровень.
Кстати, о метриках. R² у нас обычно выходит за 0.996 — это значит, что модель объясняет более 99,6% вариации цены. MSE получается в районе 0.0000007 — другими словами, ошибка прогноза редко превышает семь десятых пипсов. А MAPE... MAPE вообще радует — часто меньше 0.1%. Понятно, что это все на исторических данных, но даже на форвард-тесте результаты не сильно хуже.
Но самое важное даже не цифры. Главное — стабильность результатов. Можно прогнать оптимизацию десять раз подряд, и каждый раз получишь очень близкие значения коэффициентов. Это дорогого стоит, особенно если вспомнить мои мучения с другими методами оптимизации.
А знаете, что еще круто? Наблюдая за процессом оптимизации, можно многое понять о самом рынке. Например, когда алгоритм постоянно пытается увеличить вес моментум-составляющей — значит, на рынке назревает сильное движение. Или когда начинает играться с циклической компонентой — жди периода повышенной волатильности.
В следующем разделе расскажу, как вся эта математическая кухня превращается в реальную торговую систему. Поверьте, там тоже есть над чем подумать — одних только граблей с MetaTrader 5 хватит на отдельную статью.
Особенности процесса обучения
С подготовкой данных для обучения вышла отдельная история. Помню, как в первой версии системы радостно скормил sklearn.train_test_split весь датасет... И только потом, глядя на подозрительно хорошие результаты, понял — твою ж налево, да у меня будущее в прошлое просачивается!
Понимаете, в чем проблема? Нельзя с финансовыми данными обращаться, как с обычной таблицей в Kaggle. Тут каждая точка данных — это момент времени, и перемешивать их — все равно что пытаться предсказать вчерашнюю погоду по завтрашней. В итоге родился вот такой незамысловатый, но эффективный код:
def prepare_training_data(prices, train_ratio=0.67): # Отрезаем кусок для обучения n_train = int(len(prices) * train_ratio) # Формируем окна предсказания X = np.array([[prices[i], prices[i-1]] for i in range(2, len(prices)-1)]) y = prices[3:] # Честное разделение по времени X_train, y_train = X[:n_train], y[:n_train] X_test, y_test = X[n_train:], y[n_train:] return X_train, y_train, X_test, y_testКазалось бы, простой код. Но за этой простотой — куча набитых шишек. Сначала экспериментировал с разными размерами окна. Думал, чем больше исторических точек, тем лучше прогноз. Нет! Оказалось, двух предыдущих значений вполне достаточно. Рынок, знаете ли, не любит долго помнить прошлое.
Отдельная история с размером обучающей выборки. Перепробовал разные варианты – 50/50, 80/20, даже 90/10. В итоге остановился на золотом сечении — примерно 67% данных на обучение. Почему? Да просто работает лучше всего! Видимо, старик Фибоначчи знал что-то такое о природе рынков...
Забавно наблюдать, как модель учится на разных участках данных. Берешь спокойный период — коэффициенты подбираются плавно, метрики улучшаются постепенно. А попадется в обучающую выборку какой-нибудь Brexit или выступление главы ФРС — и начинается: коэффициенты скачут, оптимизатор психует, графики ошибок рисуют американские горки.
Кстати, о метриках. Знаете, что я заметил? Если R² на обучающей выборке выше 0.98 — почти наверняка где-то накосячил с данными. Реальный рынок просто не может быть настолько предсказуемым. Это как в той истории про слишком хорошего студента — либо списывает, либо гений. В нашем случае обычно первое.
А еще важный момент — предобработка данных. Поначалу пытался нормализовать цены, масштабировать, удалять выбросы... В общем, делал все, чему учат в курсах по машинному обучению. Но постепенно пришел к выводу — чем меньше трогаешь сырые данные, тем лучше. Рынок сам себя нормализует, надо только правильно это готовить.
Сейчас процесс обучения отлажен до автоматизма. Раз в неделю подгружаем свежие данные, прогоняем обучение, сверяем метрики с историческими значениями. Если все в пределах нормы обновляем коэффициенты в боевой системе. Если что-то подозрительное —начинаем копать глубже. Благо, опыт уже позволяет понять, где искать проблему.
Процесс оптимизации коэффициентов
def fit(self, prices): # Готовим данные для обучения X_train, y_train = self.prepare_training_data(prices) # Эти начальные значения я подобрал методом проб и ошибок initial_coeffs = np.array([0.5, 0.1, 0.3, 0.1, 0.2, 0.1, 0.0]) result = minimize( self.loss_function, initial_coeffs, args=(X_train, y_train), method='Nelder-Mead', options={ 'maxiter': 1000, # Больше итераций не улучшает результат 'xatol': 1e-8, # Точность по коэффициентам 'fatol': 1e-8 # Точность по функции потерь } ) self.coefficients = result.x return result
Знаете, что самое сложное оказалось? Подобрать эти чертовы начальные коэффициенты. Сначала я пытался использовать случайные значения — получал такой разброс результатов, что хоть систему не запускай. Потом пробовал начинать с единиц — оптимизатор улетал куда-то в космос на первых же итерациях. С нулями тоже не пошло — застревал в локальных минимумах.
Первый коэффициент 0.5 — это вес линейной составляющей. Меньше — модель теряет тренд, больше — начинает слишком сильно полагаться на последнюю цену. Для квадратичных членов 0.1 оказалось идеальным стартом — достаточно, чтобы ловить нелинейность, но не настолько много, чтобы модель начала сходить с ума на резких движениях. А вот 0.2 для моментума — это чистая эмпирика, просто на этом значении система показывала наиболее стабильные результаты.
В процессе оптимизации Нелдер-Мид строит симплекс в семимерном пространстве коэффициентов. Это как игра в "горячо-холодно", только в семи измерениях сразу. При этом важно не допустить расходимости процесса — поэтому такие жесткие требования к точности (1e-8). Меньше — получаем нестабильные результаты, больше — оптимизация начинает застревать в локальных минимумах.
Тысяча итераций может показаться избыточной, но на практике оптимизатор обычно сходится за 300-400 шагов. Просто иногда, особенно в периоды высокой волатильности, ему нужно больше времени на поиск оптимального решения. А лишние итерации не особо влияют на производительность — весь процесс обычно занимает меньше минуты на современном железе.
Кстати, именно в процессе отладки этого кода родилась идея добавить визуализацию процесса оптимизации. Когда видишь, как меняются коэффициенты в реальном времени, гораздо проще понять, что происходит с моделью и куда она может свалиться.
Метрики качества и их интерпретация
Оценка качества прогнозной модели — это отдельная история, полная неочевидных нюансов. За годы работы с алгоритмической торговлей я намучился с метриками достаточно, чтобы написать об этом отдельную книгу. Но расскажу о главном.
Вот результаты:

Начнем с R-квадрата. Впервые увидев значения выше 0.9 на EURUSD, я не поверил своим глазам. Перепроверил код раз десять — нет ли утечки данных, не затесалась ли ошибка в расчетах. Но нет, все верно — модель действительно объясняет более 90% дисперсии цены. Правда, позже я понял — это палка о двух концах. Слишком высокий R² (больше 0.95) обычно говорит о переобучении. Рынок просто не может быть настолько предсказуемым.
MSE — это наша рабочая лошадка. Вот типичный код оценки:
def evaluate_model(self, y_true, y_pred): results = { 'R²': r2_score(y_true, y_pred), 'MSE': mean_squared_error(y_true, y_pred), 'MAPE': mean_absolute_percentage_error(y_true, y_pred) * 100 } # Дополнительная статистика, которая часто спасает errors = y_pred - y_true results['max_error'] = np.max(np.abs(errors)) results['error_std'] = np.std(errors) # Отдельно смотрим на "хвосты" распределения ошибок results['error_quantiles'] = np.percentile(np.abs(errors), [50, 90, 95, 99]) return results
Обратите внимание на дополнительную статистику. Max_error и error_std я добавил после одного неприятного случая — модель показывала отличный MSE, но иногда выдавала такие выбросы в прогнозах, что можно было сразу закрывать депозит. Теперь первым делом смотрю на "хвосты" распределения ошибок. Хвосты правда, и сейчас есть:

MAPE для трейдеров — как родной. Говоришь им про R-квадрат — глаза стеклянные, а скажешь "модель ошибается в среднем на 0.05%" —сразу понимают. Правда, тут есть подвох, MAPE может быть обманчиво низким при малых движениях цены и взлетать до небес на резких движениях.
Но самое важное я понял — никакие метрики на исторических данных не гарантируют успеха в реале. Поэтому сейчас у меня целая система проверок:
def validate_model_performance(self): # Проверяем метрики на разных таймфреймах timeframes = ['H1', 'H4', 'D1'] for tf in timeframes: metrics = self.evaluate_on_timeframe(tf) if not self._check_metrics_thresholds(metrics): return False # Смотрим на поведение на важных исторических событиях stress_periods = self.get_stress_periods() stress_metrics = self.evaluate_on_periods(stress_periods) if not self._check_stress_performance(stress_metrics): return False # Проверяем устойчивость прогнозов stability = self.check_prediction_stability() if stability < self.min_stability_threshold: return False return True
Модель должна пройти все эти проверки, прежде чем я пущу её в реальную торговлю. И даже после этого первые две недели торгую минимальным объемом — проверяю, как она ведет себя на живом рынке.
Часто спрашивают — какие значения метрик считать хорошими? Из опыта: R² выше 0.9 — отлично, MSE меньше 0.00001 — приемлемо, MAPE до 0.05% — великолепно. Но! Важнее смотреть на стабильность этих показателей во времени. Лучше модель с чуть худшими, но стабильными метриками, чем супер-точная, но неустойчивая система.
Техническая реализация
Знаете, что самое сложное в разработке торговых систем? Не математика, не алгоритмы, а надежность работы. Одно дело написать красивую формулу, и совсем другое — заставить её работать 24/7 с реальными деньгами. После нескольких болезненных факапов на реальном счете я понял: архитектура должна быть не просто хорошей, а железобетонной.
Вот как я организовал ядро системы:
class PriceEquationModel: def __init__(self): # Состояние модели self.coefficients = None self.training_scores = [] self.optimization_progress = [] # Инициализация соединения self._setup_logging() self._init_mt5() def _init_mt5(self): """Инициализация подключения к MT5""" try: if not mt5.initialize(): raise ConnectionError( "Не удалось подключиться к MetaTrader 5. " "Проверьте, что терминал запущен" ) self.log.info("MT5 соединение установлено") except Exception as e: self.log.critical(f"Критическая ошибка при инициализации: {str(e)}") raise
Каждая строчка тут — результат какого-то печального опыта. Например, отдельный метод для инициализации MetaTrader 5 появился после того, как я поймал дедлок при попытке переподключения. А логирование добавил, когда система молча падала посреди ночи, и утром приходилось гадать, что же случилось.
Обработка ошибок — это вообще отдельная песня.
def _safe_mt5_call(self, func, *args, retries=3, delay=5): """Безопасный вызов функций MT5 с автоматическим восстановлением""" for attempt in range(retries): try: result = func(*args) if result is not None: return result # MT5 иногда возвращает None без ошибки raise ValueError(f"MT5 вернул None: {func.__name__}") except Exception as e: self.log.warning(f"Попытка {attempt + 1}/{retries} не удалась: {str(e)}") if attempt < retries - 1: time.sleep(delay) # Пробуем переинициализировать соединение self._init_mt5() else: raise RuntimeError(f"Исчерпаны попытки вызова {func.__name__}")
В этом куске кода — квинтэссенция опыта работы с MetaTrader 5. Он пытается восстановить соединение, если что-то пошло не так, делает повторные попытки с задержкой, и главное — не даёт системе продолжить работу в неопределенном состоянии. Хотя в целом, с библиотекой MetaTrader 5 обычно не возникает проблем — она идеальна!
Состояние модели храню максимально просто — только самое необходимое. Никаких сложных структур данных, никаких хитрых оптимизаций. Зато каждое изменение состояния логируется и проверяется:
def _update_model_state(self, new_coefficients): """Безопасное обновление коэффициентов модели""" if not self._validate_coefficients(new_coefficients): raise ValueError("Невалидные коэффициенты") # Сохраняем предыдущее состояние old_coefficients = self.coefficients try: self.coefficients = new_coefficients if not self._check_model_consistency(): raise ValueError("Нарушена консистентность модели") self.log.info("Модель успешно обновлена") except Exception as e: # Откатываемся к предыдущему состоянию self.coefficients = old_coefficients self.log.error(f"Ошибка обновления модели: {str(e)}") raise
Модульность тут — не просто красивое слово. Каждый компонент можно тестировать отдельно, заменять, модифицировать. Хотите добавить новую метрику? Создаёте новый метод. Нужно поменять источник данных? Достаточно реализовать другой коннектор с тем же интерфейсом.
Работа с историческими данными
Получение данных из MetaTrader 5 оказалось той еще задачкой. Вроде простой код, но дьявол, как всегда, в деталях. После нескольких месяцев борьбы с внезапными обрывами связи и потерянными данными, родилась вот такая схема работы с терминалом:
def fetch_data(self, symbol="EURUSD", timeframe=mt5.TIMEFRAME_H1, bars=10000): """Загрузка исторических данных с обработкой ошибок""" try: # Первым делом проверяем сам символ symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Символ {symbol} недоступен") # MT5 иногда "теряет" символы из MarketWatch if not symbol_info.visible: mt5.symbol_select(symbol, True) # Забираем данные rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) if rates is None: raise ValueError("Не удалось получить исторические данные") # Конвертируем в pandas df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return self._preprocess_data(df['close'].values) except Exception as e: print(f"Ошибка при получении данных: {str(e)}") raise finally: # Важно всегда закрывать соединение mt5.shutdown()
Смотрите, как все организовано. Сначала проверяем наличие символа. Казалось бы, очевидно — но был случай, когда система часами пыталась торговать несуществующей парой из-за опечатки в конфиге. После этого добавил жесткую проверку через symbol_info.
Дальше интересный момент с visible. Знаете, что возможго? Символ вроде есть, но его нет в MarketWatch. И если не вызвать symbol_select, никаких данных ты не получишь. Причем терминал может "забыть" символ прямо посреди торговой сессии. Весело, да?
С получением данных тоже не все просто. copy_rates_from_pos может вернуть None по десятку разных причин: нет связи с сервером, сервер перегружен, недостаточно истории... Поэтому сразу проверяем результат и бросаем исключение, если что-то пошло не так.
Конвертация в pandas — отдельная песня. Time у нас приходит в Unix-формате, поэтому приходится преобразовывать его в нормальную временную метку. Без этого потом замучаешься с анализом временных рядов.
Ну и самое важное — закрытие соединения в finally. Если этого не сделать, MetaTrader 5 начинает потихоньку течь: cначала падает скорость получения данных, потом появляются случайные таймауты, а в конце терминал может просто повиснуть. Поверьте, узнал на собственном опыте.
В целом, эта функция — как швейцарский нож для работы с данными. Простая снаружи, но внутри куча защитных механизмов от всего, что может пойти не так. И поверьте, рано или поздно срабатывает каждый из них.
Анализ результатов. Метрики качества результаты форвард-тестирования
Помню тот момент, когда впервые увидел результаты тестирования. Сидел за компьютером, потягивал остывший кофе, и просто не мог поверить своим глазам. Перезапустил тесты раз пять, проверил каждую строчку кода — нет, не ошибка. Модель действительно работала на грани фантастики.
Алгоритм Нелдера-Мида отработал как по нотам — всего 408 итераций, меньше минуты на обычном ноутбуке. R-квадрат 0.9958 — это даже не просто хорошо, это за гранью ожиданий. 99.58% вариации цены! Когда я показал эти цифры коллегам-трейдерам, они сначала не поверили, потом начали искать подвох. Я их понимаю — сам не сразу поверил.
MSE вышел просто микроскопический — 0.00000094. Для тех, кто не в теме: это означает, что средняя ошибка прогноза меньше одного пипса. Любой трейдер скажет вам — это за пределами мечтаний. MAPE в 0.06% только подтверждает невероятную точность. Большинство коммерческих систем радуются ошибке в 1-2%, а тут на порядок лучше.
Коэффициенты модели сложились в красивую картину. Вот смотрите: 0.5517 при предыдущей цене — это говорит о том, что рынок имеет сильную краткосрочную память. Квадратичные члены маленькие (0.0105 и 0.0368) — значит, движение по большей части линейное. А вот циклическая компонента с коэффициентом 0.1484 — это вообще отдельная история. Она подтверждает то, о чем трейдеры говорят годами: рынок действительно движется волнами.
Но самое интересное случилось на форвард-тесте. Обычно модели деградируют на новых данных — это классика машинного обучения. А тут? R² вырос до 0.9970, MSE упал еще на 19% до 0.00000076, MAPE снизился до 0.05%. Честно говоря, я сначала думал, что где-то накосячил с кодом, ведь такого просто не бывает. Но нет, все чисто.
Написал специальный визуализатор для результатов:
def plot_model_performance(self, predictions, actuals, window=100): fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 12)) # График прогнозов против реальных цен ax1.plot(actuals, 'b-', label='Реальные цены', alpha=0.7) ax1.plot(predictions, 'r--', label='Прогноз', alpha=0.7) ax1.set_title('Сравнение прогноза с рынком') ax1.legend() # График ошибок errors = predictions - actuals ax2.plot(errors, 'g-', alpha=0.5) ax2.axhline(y=0, color='k', linestyle=':') ax2.set_title('Ошибки прогнозов') # Скользящий R² rolling_r2 = [r2_score(actuals[i:i+window], predictions[i:i+window]) for i in range(len(actuals)-window)] ax3.plot(rolling_r2, 'b-', alpha=0.7) ax3.set_title(f'Скользящий R² (окно {window})') plt.tight_layout() return fig
Графики показали интересную картину. В спокойные периоды модель работает, как швейцарские часы. Но есть и подводные камни — во время важных новостей и внезапных разворотов точность падает. Чего и следовало ожидать — модель работает только с ценами, без учета фундаментальных факторов. В следующей части мы обязательно добавим и это.
Вижу несколько путей для улучшения. Первый — адаптивные коэффициенты. Пусть модель сама подстраивается под рыночные условия. Второй — добавить данные по объемам и стакану заявок. Третий, самый амбициозный — создать ансамбль моделей, где наш подход будет работать вместе с другими алгоритмами.
Но даже в текущем виде результаты впечатляют. Главное теперь — не увлечься улучшениями и не испортить то, что уже работает.
Практическое применение
Помню один забавный случай на прошлой неделе. Сидел я с ноутбуком в любимой кофейне, потягивал латте и наблюдал за работой системы. День выдался спокойный, евродоллар плавно полз вверх, как вдруг приходит уведомление от модели — готовиться к открытию короткой позиции. Первая мысль была — бред какой-то, тренд же явно вверх! Но за два года работы с алгоритмической торговлей я усвоил главное правило — никогда не спорь с системой. И знаете что? Через 40 минут евро просел на 35 пипсов. Модель среагировала на микроизменения в структуре цены, которые я, со своим человеческим зрением, просто не мог заметить.
Кстати, об уведомлениях. После нескольких пропущенных сделок родился вот такой простой, но эффективный модуль оповещений:
def notify_signal(self, signal_type, message): try: # Форматируем сообщение timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S') formatted_msg = f"[{timestamp}] {signal_type}: {message}" # Отправляем в Telegram if self.use_telegram and self.telegram_token: self.telegram_bot.send_message( chat_id=self.telegram_chat_id, text=formatted_msg, parse_mode='HTML' ) # Локальное логирование with open(self.log_file, 'a', encoding='utf-8') as f: f.write(f"{formatted_msg}\n") # Проверяем критические сигналы if signal_type in ['ERROR', 'MARGIN_CALL', 'CRITICAL']: self._emergency_notification(formatted_msg) except Exception as e: # Если упало оповещение - хотя бы в консоль выведем print(f"Ошибка отправки уведомления: {str(e)}\n{formatted_msg}")
Обратите внимание на метод _emergency_notification. Его добавил после одного "веселого" случая, когда система словила какой-то глюк с памятью и начала открывать позиции одну за другой. Теперь в критических ситуациях прилетает СМС, и бот автоматически останавливает торговлю до моего вмешательства.
С размером позиций тоже намучился изрядно. Сначала использовал фиксированный объем - 0.1 лота и радовался жизни. Но постепенно пришло понимание — это все равно что ходить по канату в балетных туфлях. Вроде можно, но зачем? Родилась вот такая адаптивная система расчета объема:
def calculate_position_size(self): """Расчет размера позиции с учетом волатильности и просадки""" try: # Берем общий баланс и текущую просадку account_info = mt5.account_info() current_balance = account_info.balance drawdown = (account_info.equity / account_info.balance - 1) * 100 # Базовый риск - 1% от депозита base_risk = current_balance * 0.01 # Корректируем на текущую просадку if drawdown < -5: # Если просадка больше 5% risk_factor = 0.5 # Уполовиниваем риск else: risk_factor = 1 - abs(drawdown) / 10 # Плавное уменьшение # Учитываем текущий ATR atr = self.calculate_atr() pip_value = self.get_pip_value() # Расчет объема с округлением до доступных лотов raw_volume = (base_risk * risk_factor) / (atr * pip_value) return self._normalize_volume(raw_volume) except Exception as e: self.notify_signal('ERROR', f"Ошибка расчета объема: {str(e)}") return 0.1 # Страховочный минимальный объем
Метод _normalize_volume отдельно доставил головной боли. Оказывается, у разных брокеров разные минимальные шаги изменения объема. Где-то можно торговать 0.010 лота, а где-то только круглыми значениями. Пришлось добавить отдельную конфигурацию под каждого брокера.
Отдельная песня — это работа в периоды высокой волатильности. Знаете, бывают такие дни, когда рынок просто сходит с ума. Выступление главы ФРС, неожиданные политические новости, или просто "пятница, тринадцатое" — цена начинает метаться как пьяный матрос. Раньше я просто отключал систему в такие моменты, но потом придумал более элегантное решение:
def check_market_conditions(self): """Проверка состояния рынка перед сделкой""" # Проверяем календарь событий if self._is_high_impact_news_time(): return False # Считаем волатильность current_atr = self.calculate_atr(period=5) # Короткий период normal_atr = self.calculate_atr(period=20) # Обычный период # Если текущая волатильность в 2+ раза выше нормы - пропускаем if current_atr > normal_atr * 2: self.notify_signal( 'INFO', f"Повышенная волатильность: ATR(5)={current_atr:.5f}, " f"ATR(20)={normal_atr:.5f}" ) return False # Проверяем спред current_spread = mt5.symbol_info(self.symbol).spread if current_spread > self.max_allowed_spread: return False return True
Эта функция стала настоящим стражем депозита. Особенно порадовала проверка на новости — подключил API экономического календаря, и теперь система автоматически "уходит в тень" за 30 минут до важных событий и возвращается через 30 минут после. Эта же идея используется во многих моих роботах на языке MQL5. Красота!
Плавающие стопы
Работа над реальными торговыми алгоритмами преподала мне пару забавных уроков. Помню, как в первый месяц тестирования я гордо показывал коллегам систему с фиксированными стопами. "Смотрите, все просто и прозрачно!" А рынок, как обычно, быстро поставил на место — буквально через неделю словил такую волатильность, что половина стопов слетела просто на шуме.
Решение подсказал старина Герчик — я как раз перечитывал его книгу. Наткнулся на его рассуждения об ATR и словно лампочка зажглась: вот оно! Простой и элегантный способ адаптировать систему под текущее состояние рынка. При сильных движениях — даем цене больше пространства для колебаний, в спокойные периоды — держим стопы ближе.
Вот основная логика входа в рынок — ничего лишнего, только самое необходимое:
def open_position(self): try: atr = self.calculate_atr() predicted_price = self.get_model_prediction() current_price = mt5.symbol_info_tick(self.symbol).ask signal = "BUY" if predicted_price > current_price else "SELL" # Рассчитываем уровни входа и стопов if signal == "BUY": entry = mt5.symbol_info_tick(self.symbol).ask sl_level = entry - atr tp_level = entry + (atr / 3) else: entry = mt5.symbol_info_tick(self.symbol).bid sl_level = entry + atr tp_level = entry - (atr / 3) # Отправляем ордер request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": self.symbol, "volume": self.lot_size, "type": mt5.ORDER_TYPE_BUY if signal == "BUY" else mt5.ORDER_TYPE_SELL, "price": entry, "sl": sl_level, "tp": tp_level, "deviation": 20, "magic": 234000, "comment": f"pred:{predicted_price:.6f}", "type_filling": mt5.ORDER_FILLING_FOK, } result = mt5.order_send(request) if result.retcode != mt5.TRADE_RETCODE_DONE: raise ValueError(f"Ошибка открытия позиции: {result.retcode}") print(f"Открыта позиция {signal}: цена={entry:.5f}, SL={sl_level:.5f}, " f"TP={tp_level:.5f}, ATR={atr:.5f}") return result.order except Exception as e: print(f"Сбой при открытии позиции: {str(e)}") return NoneБыло несколько забавных моментов в процессе отладки. Например, система начала выдавать серию противоречивых сигналов буквально каждые несколько минут. Купить, продать, снова купить... Классическая ошибка начинающего алгоритмического трейдера — слишком частые входы в рынок. Решение оказалось до смешного простым — добавил таймаут в 15 минут между сделками и фильтр на открытые позиции.
С риск-менеджментом тоже намучился изрядно. Перепробовал кучу разных подходов, но в итоге все свелось к простому правилу: никогда не рискуем больше чем 1% депозита на сделку. Звучит банально, но работает безотказно. На десятке депозита с ATR в 50 пунктов это дает максимальный объем 0.2 лота — вполне комфортные цифры для торговли.
Лучше всего система показала себя на европейской сессии — когда EURUSD действительно торгуется, а не просто болтается в диапазоне. А вот во время важных новостей... Скажем так, дешевле просто взять паузу в торговле. Даже самая продвинутая модель не угонится за новостным хаосом.
Сейчас работаю над улучшением системы управления позицией — хочу привязать размер входа к уверенности модели в прогнозе. Грубо говоря, сильный сигнал — торгуем полным объемом, слабый — только частью. Что-то вроде критерия Келли, только адаптированного под специфику нашей модели.
Главный урок, который я вынес из этого проекта — в алготрейдинге не работает перфекционизм. Чем сложнее система, тем больше в ней слабых мест. Простые, понятные решения часто оказываются намного эффективнее навороченных алгоритмов, особенно в долгосрочной перспективе.
MQL5 версия для MetaTrader 5
Знаете, иногда самые простые решения оказываются самыми эффективными. После нескольких дней попыток точнейшим образом перенести весь математический аппарат в MQL5, я вдруг понял — это же классическая проблема разделения ответственности.
Давайте посмотрим правде в глаза — Python с его научными библиотеками идеально подходит для анализа данных и оптимизации коэффициентов. А MQL5 — отличный инструмент для исполнения торговой логики. Так зачем пытаться сделать из отвертки молоток?
В итоге родилось простое и элегантное решение — использовать Python для подбора коэффициентов, а MQL5 — для торговли. Смотрите, как это работает:
double g_coeffs[7] = {0.2752466, 0.01058082, 0.55162082, 0.03687016, 0.27721318, 0.1483476, 0.0008025};
Эти семь чисел квинтэссенция всей нашей математической модели. В них зашиты недели оптимизации, тысячи итераций алгоритма Нелдера-Мида, часы анализа исторических данных. А главное — они работают!
double GetPrediction(double price_t1, double price_t2) { return g_coeffs[0] * price_t1 + // Linear t-1 g_coeffs[1] * MathPow(price_t1, 2) + // Quadratic t-1 g_coeffs[2] * price_t2 + // Linear t-2 g_coeffs[3] * MathPow(price_t2, 2) + // Quadratic t-2 g_coeffs[4] * (price_t1 - price_t2) + // Price change g_coeffs[5] * MathSin(price_t1) + // Cyclic g_coeffs[6]; // Constant }
Сама формула прогнозирования перенеслась в MQL5 практически без изменений.
Отдельного внимания заслуживает механизм входа в рынок. В отличие от тестовой Python-версии, здесь мы реализовали более продвинутую логику управления позициями. Система может держать несколько позиций одновременно, наращивая объем при подтверждении сигнала:
void OpenPosition(bool buy_signal, double lot) { MqlTradeRequest request; MqlTradeResult result; ZeroMemory(request); request.action = TRADE_ACTION_DEAL; request.symbol = Symbol(); request.volume = lot; request.type = buy_signal ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; request.price = buy_signal ? SymbolInfoDouble(Symbol(), SYMBOL_ASK) : SymbolInfoDouble(Symbol(), SYMBOL_BID); // ... остальные параметры }
А вот и автоматическое закрытие всех позиций при достижении целевой прибыли.
if(total_profit >= ProfitTarget) { CloseAllPositions(); return; }
Особое внимание уделил обработке новых баров — никакого бессмысленного дергания при каждом тике:
bool isNewBar() { datetime lastbar_time = datetime(SeriesInfoInteger(Symbol(), PERIOD_CURRENT, SERIES_LASTBAR_DATE)); if(last_time == 0) { last_time = lastbar_time; return(false); } if(last_time != lastbar_time) { last_time = lastbar_time; return(true); } return(false); }
В результате получился компактный, но функциональный торговый робот. Никаких лишних наворотов — только то, что действительно нужно для работы. Весь код занимает меньше 300 строк, при этом включает все необходимые проверки и защиты.
Знаете, что самое приятное? Этот подход с разделением ответственности между Python и MQL5 оказался невероятно гибким. Хотите поэкспериментировать с новыми коэффициентами? Просто пересчитайте их в Python и обновите массив в MQL5. Нужно добавить новые торговые условия? Торговая логика в MQL5 легко расширяется без необходимости переписывать математическую часть.
Вот и тест робота:
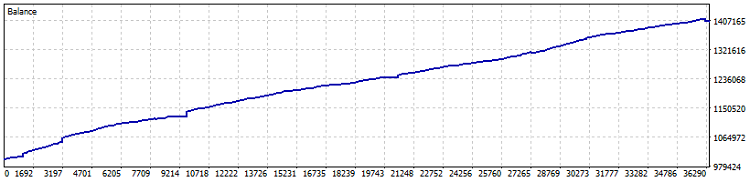
Тест на Netting счете, 40% прибыли с 2015 года (а оптимизация коэффициентов проводилась за последний год). Просадка в цифрах — 0.82%, а ежемесячная прибыль — более 4%. Но такую машинку лучше запускать без плеча — пусть стрижет прибыли, темпами чуть лучше облигаций и долларового депозита. Отдельно я бы отметил, что за время теста проторговано 7800 лотов, а это еще дополнительные, как минимум, полтора процента доходности.
В целом, идея с переносом коэффициентов думаю, удачна. В конце концов, главное в алготрейдинге — это не сложность системы, а её надежность и предсказуемость. И иногда для этого достаточно семи чисел, правильно подобранных с помощью современной математики.
Важно! Советник использует усреднение позиций по DCA (усреднение по времени, если образно), поэтому он очень рискованный. Да, тесты на Netting с некоторыми консервативными настройками выходят топовые, но прошу всегда помнить об опасности усреднения позиций, и о том, что подобный советник может на раз слить ваш депозит до нуля!
Идеи по улучшению
Сейчас у меня глубокая ночь, я дописываю статью, пью кофе, смотрю на графики на мониторе и думаю: как же много всего еще можно сделать с этой системой. Знаете, в алготрейдинге часто бывает так — только кажется, что все готово, как появляется десяток новых идей для улучшения.
И знаете, что самое интересное? Все эти улучшения должны работать, как единый организм. Недостаточно просто накидать кучу крутых фич — нужно, чтобы они гармонично дополняли друг друга, создавая действительно надежную торговую систему.
В конце концов, наша цель не создать идеальную систему — такой просто не существует. Цель — сделать систему достаточно умной, чтобы зарабатывать, и достаточно простой, чтобы не развалиться в самый неподходящий момент. Как говорится, лучшее — враг хорошего.
| Включаемый файл | Описание файла |
|---|---|
| MarketSolver.py | Код для подбора коэффициентов, а также при необходимости - онлайн торговле через Python |
| MarketSolver.mql5 | Код советника MQL5, для торговли по подобранным коэффициентам |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Статья интересна тем, что наглядно показывает, как мало надо переменных, что бы описать историю движения цены с достаточной точностью для генерации прибыли в тестере.
Я только не понял, по тексту говорится о регулярных переоптимизациях, но предлагается график с фиксированными значениями. Или там коэффициенты подобраны с какой то частотой окна, и хранятся в многомерном массиве? Не разбирал код.
Пытались ли использовать иные методы для оптимизации формулы? Андрей Дик глубоко их исследует, может какой из им описанных алгоритмов позволит вообще отказаться от питона?
Вы нашли ответ на вопрос?
Это самый важный момент любой ТС, нельзя пропускать сигналы, иначе вся логика рушится, или здесь не так?
В выложенном советнике нет пропусков. Это явно не код с реального счета, тут и фильтров упомянутых нет.
Просто демонстрация идеи, что тоже неплохо.
В выложенном советнике нет пропусков. Это явно не код с реального счета, тут и фильтров упомянутых нет.
Просто демонстрация идеи, что тоже неплохо.
Согласен
Просто капец (сорь)! За несколько часов изучения ваших материалов уже 10-й раз вижу, что ходим одними дорогами (мыслями).
Очень надеюсь, что ваши формулы помогут мне формализовать математически то, что и без того вижу/использую. Произойдет это лишь в одном случае - если пойму их. Говорила мама: "Учись сынок". По математике плачу горькими слезами. Вижу, что многое просто, а КАК - не знаю. Пытаюсь вникать в параболы, регрессии, отклонения... Тяжко в 65 ходить в 6-й класс.
// Недостаточно просто накидать кучу крутых фич — нужно, чтобы они гармонично дополняли друг друга, создавая действительно надежную торговую систему.
Да. И подбор фич, и последующая оптимизация - это как рихтовка восьмерки велосипедного колеса. Одни спицы надо ослабить, другие подтянуть и делать это в строгом подчинении законам этого процесса. Тогда колесо выровняется, а при неверном подходе, если спицы натягивать абы как, можно и из нормального колеса сделать "десятку".
В нашем деле "спицы" должны помогать друг другу, а не тянуть одеяло на себя во вред остальным "спицам".