
Разрабатываем мультивалютный советник (Часть 13): Автоматизация второго этапа — отбор в группы
Введение
Отвлёкшись немного на риск-менеджер в прошлой статье, вернёмся к основному направлению разработки — автоматизации тестирования. В одной из предыдущих статей мы наметили несколько этапов, которые должны быть пройдены в процессе оптимизации и поиска наилучших параметров итогового советника. Первый этап, на котором мы оптимизировали параметры одиночного экземпляра торговой стратегии, у нас уже был реализован. Его результаты были сохранены в базу данных.
Следующий этап — это подбор хороших групп из одиночных экземпляров торговых стратегий, которые при совместной работе позволят улучшить параметры торговли — снизить просадку, повысить линейность роста кривой баланса и так далее. В шестой части цикла статей мы уже рассматривали проведение этого этапа в ручном режиме. Сначала мы отбирали из результатов оптимизации параметров одиночных экземпляров торговых стратегий те, которые заслуживали внимания. Это можно было делать по различным критериям, но тогда мы ограничились просто удалением результатов с отрицательной прибылью. Затем разными способами пробовали брать разные комбинации из восьми экземпляров торговых стратегий, объединять их в одном советнике и запускать в тестере для оценки параметров их совместной работы.
Начав с ручного отбора, мы реализовали и автоматический подбор комбинаций входных параметров одиночных экземпляров торговых стратегий, которые выбирались из списка параметров, хранившегося в CSV-файле. Выяснилось, что даже в простейшем случае, когда мы просто запускаем генетическую оптимизацию, подбирающую восемь комбинаций, желаемый результат получается.
Давайте теперь модифицируем тот советник, который занимался оптимизацией подбора группы, так, чтобы он мог использовать результаты первого этапа из базы данных. Свои результаты он также должен сохранять в базу данных. Также рассмотрим создание заданий на проведение оптимизаций второго этапа путём добавления нужных записей в нашу базу данных.
Перенос данных на агенты тестирования
Для прошлого советника по подбору хороших групп нам пришлось немного повозиться, чтобы обеспечить возможность проведения оптимизации с использованием удалённых агентов тестирования. Проблема была в том, что оптимизируемый советник должен был читать данные из CSV-файла. При оптимизации только на локальном компьютере это не вызывало проблем — достаточно было разместить файл с данными в общей папке терминала, и все локальные агенты тестирования могли иметь к нему доступ.
Но удалённые агенты тестирования к таком файлу с данными доступа не имеют. Поэтому мы воспользовались директивой #property tester_file, которая позволяет передать любой указанный файл всем агентам тестирования в их папку данных. При запуске оптимизации, файл с данными копировался из общей папки в папку данных локального агента, запускающего процесс оптимизации. Затем файл с данными из папки данных локального агента рассылался автоматически в папки данных всех остальных агентов тестирования.
Поскольку теперь данные о результатах тестирования одиночных экземпляров торговых стратегий у нас содержатся в базе данных SQLite, то первым побуждением было поступить аналогично. Так как база данных SQLite представляет собой один файл на носителе, то его точно так же можно растиражировать на удалённые агенты тестирования с помощью вышеупомянутой директивы. Но тут есть небольшой нюанс — объём передаваемого CSV-файла составлял примерно 2 Мб, а объём файла с базой данных — уже более 300 Мб.
Такая разница обусловлена тем, что мы, во-первых, старались сохранить в базе данных максимально возможное количество статистической информации о каждом проходе, а в CSV-файле хранилась только несколько статистических параметров и данные о значениях входных параметров экземпляров стратегий. А во-вторых, в базе данных у нас уже собрана информация о результатах оптимизации стратегии на трёх разных символах и трёх различных таймфреймах для каждого символа. То есть количество проходов возросло примерно в девять раз.
Если учесть, что каждый агент тестирования получает свою собственную копию передаваемого файла, то для запуска тестирования на 32-х ядерном сервере нам понадобится разместить на нём свыше 9 ГБ данных. Если же на первом этапе у нас будет обработано ещё большее количество символов и таймфреймов, то объём файла с базой данных возрастет ещё в несколько раз. Это может привести к исчерпанию доступного дискового пространства на серверах агентов, не говоря уже о необходимости передачи по сети большого объема данных.
Однако большая часть из хранимой информации о результатах выполненных проходов тестера нам либо совсем не понадобится на втором этапе, либо не понадобится вся одновременно. То есть, из всего множества сохранённых значений для одного прохода нам нужно извлечь только строку инициализации эксперта, использованную в данном проходе. Также мы планируем собирать не одну группу одиночных экземпляров торговых стратегий, а несколько — по одной на каждую комбинацию символа и таймфрейма. Это значит, что при поиске, например, группы по EURGBP H1 нам не нужны данные о проходах на других символах, кроме EURGBP, и других таймфреймах, кроме H1.
Поэтому поступим следующим образом: при запуске каждой оптимизации мы будем создавать новую базу данных с предопределённым именем и наполнять её минимально необходимой информацией для данной задачи оптимизации. Уже имеющуюся базу данных будем называть основной базой данных, а создаваемую новую базу данных — базой данных задачи оптимизации или просто базой данных задачи.
Файл с этой базой данных будет предаваться на агенты тестирования, так как мы укажем его имя в директиве #property tester_file. Оптимизируемый советник при запуске на агенте тестирования будет работать с этой выжимкой из основной базы данных. А при запуске на локальном компьютере в режиме сбора фреймов данных, оптимизируемый советник будет по-прежнему сохранять принимаемые от агентов тестирования данные в основную базу данных.
Реализация такой схемы работы потребует, прежде всего, модификации класса работы с базой данных CDatabase.
Модификация CDatabase
При разработке этого класса, к сожалению, мы не предусмотрели, что нам понадобится из кода одного советника работать с несколькими базами данных. Казалось, что мы, наоборот, должны обеспечить работу только с одной базой данных, чтобы не запутаться потом, где что у нас хранится. Но реальность вносит свои коррективы, и нам приходится менять свой подход.
Для минимизации правок мы пока решили оставить класс CDatabase статическим. То есть мы не будем создавать объекты этого класса, а будем пользоваться его публичными методами просто как набором функций в заданном пространстве имён. Вместе с тем у нас останется возможность использовать в этом классе частные свойства и методы.
Для обеспечения возможности подключения к разным базам данных, мы модифицируем метод открытия Open(), переименовав его в Connect(). Переименование произошло по той причине, что сначала был добавлен новый метод Connect(), а потом выяснилось, что он фактически выполняет ту же работу, что и метод Open(). Поэтому от использования последнего метода мы решили отказаться.
Главным отличием нового метода от своего предшественника стало наличие возможности передать имя базы данных в качестве параметра. Метод Open() всегда открывал только базу данных с именем, указанным в свойстве s_fileName, которое было константой. Такое поведение сохраняет и новый метод, если ему не передать имя базы данных. Если же мы передаём непустое имя методу Connect(), то он не только откроет базу данных с переданным именем, но и запомнит его в свойстве s_fileName. Поэтому повторный вызов Connect() без указания имени будет открывать последнюю открывавшуюся базу данных.
Помимо передачи методу Connect() имени файла, будем так же передавать флаг использования общей папки. Это нужно потому, что нашу основную базу данных удобнее хранить в общей папке данных терминала, а базу данных задачи — в папке данных агента тестирования. Поэтому в одном случае нам нужно будет в функции открытия базы данных указывать флаг DATABASE_OPEN_COMMON, а в другом — нет. Для хранения этого флага добавим новое статическое свойство класса s_common. По умолчанию будем считать, что мы хотим открывать файл базы данных из общей папки. Имя основной базы мы по-прежнему задаём как начальное значение статического свойства s_fileName.
Тогда описание класса станет примерно таким:
//+------------------------------------------------------------------+ //| Класс для работы с базой данных | //+------------------------------------------------------------------+ class CDatabase { static int s_db; // Хендл соединения с БД static string s_fileName; // Имя файла БД static int s_common; // Флаг использования общей папки данных public: static int Id(); // Хендл соединения с БД static bool IsOpen(); // Открыта ли БД? static void Create(); // Создание пустой БД // Подключение к БД с заданным именем и положением static bool Connect(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON ); static void Close(); // Закрытие БД ... }; int CDatabase::s_db = INVALID_HANDLE; string CDatabase::s_fileName = "database892.sqlite"; int CDatabase::s_common = DATABASE_OPEN_COMMON;
В самом методе Connect() мы будем сначала проверять, не открыта ли сейчас какая-нибудь база данных. Если да, то будем её закрывать. Далее будем проверять, задано ли новое имя файла базы данных. Если да, то устанавливаем новое имя и флаг обращения к общей папке. После этого выполняем действия по открытию базы данных, создавая файл пустой базы при необходимости.
В этом месте мы убрали принудительное наполнение вновь созданной базы данных таблицами и данными через вызов метода Create(), как это было сделано раньше. Поскольку мы уже в основном работаем с существующей базой данных, то так будет удобнее. При необходимости всё-таки пересоздать и наполнить базу данных начальной информацией заново, можно воспользоваться вспомогательным скриптом CleanDatabase.
//+------------------------------------------------------------------+ //| Проверка подключения к базе данных с заданным именем | //+------------------------------------------------------------------+ bool CDatabase::Connect(string p_fileName, int p_common) { // Если база данных открыта, то закроем её if(IsOpen()) { Close(); } // Если задано имя файла, то запомним его и флаг общей папки if(p_fileName != NULL) { s_fileName = p_fileName; s_common = p_common; } // Открываем базу данных // Пробуем открыть существующий файл БД s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | s_common); // Если файл БД не найден, то пытаемся создать его при открытии if(!IsOpen()) { s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE | s_common); // Сообщаем об ошибке при неудаче if(!IsOpen()) { PrintFormat(__FUNCTION__" | ERROR: %s Connect failed with code %d", s_fileName, GetLastError()); return false; } } return true; }
Сохраним сделанные изменения в файле Database.mqh в текущей папке.
Советник первого этапа
В рамках данной статьи мы не будем использовать советника первого этапа, но для единообразия мы внесём и в него небольшие правки. Во-первых, мы уберём добавленные в рамках прошлой статьи входные параметры риск-менеджера. Они нам не понадобятся в этом советнике, так как на первом этапе мы точно не будем подбирать параметры риск-менеджера. Добавим их в советник какого-то из следующих этапов оптимизации. Сам объект риск-менеджера мы сразу будем создавать из строки инициализации в неактивном состоянии.
Также на первом этапе оптимизации нам нет необходимости варьировать такие входные параметры, как магический номер, фиксированный баланс для торговли и коэффициент масштабирования. Поэтому уберём у них слово input при объявлении. Получим следующий код:
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ input int idTask_ = 0; input group "=== Параметры сигнала к открытию" input int signalPeriod_ = 130; // Количество свечей для усреднения объемов input double signalDeviation_ = 0.9; // Относ. откл. от среднего для открытия первого ордера input double signaAddlDeviation_ = 1.4; // Относ. откл. от среднего для открытия второго и последующих ордеров input group "=== Параметры отложенных ордеров" input int openDistance_ = 231; // Расстояние от цены до отлож. ордера input double stopLevel_ = 3750; // Stop Loss (в пунктах) input double takeLevel_ = 50; // Take Profit (в пунктах) input int ordersExpiration_ = 600; // Время истечения отложенных ордеров (в минутах) input group "=== Параметры управление капиталом" input int maxCountOfOrders_ = 3; // Макс. количество одновременно отрытых ордеров ulong magic_ = 27181; // Magic double fixedBalance_ = 10000; double scale_ = 1; datetime fromDate = TimeCurrent(); CAdvisor *expert; // Указатель на объект эксперта //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CMoney::FixedBalance(fixedBalance_); CMoney::DepoPart(1.0); // Подготавливаем строку инициализации для одного экземпляра стратегии string strategyParams = StringFormat( "class CSimpleVolumesStrategy(\"%s\",%d,%d,%.2f,%.2f,%d,%.2f,%.2f,%d,%d)", Symbol(), Period(), signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_, ordersExpiration_, maxCountOfOrders_ ); // Подготавливаем строку инициализации для группы с одним экземпляром стратегии string groupParams = StringFormat( "class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " )", strategyParams, scale_ ); // Подготавливаем строку инициализации для риск-менеджера string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )", 0,0,0,0,0,0 ); // Подготавливаем строку инициализации для эксперта с группой из одной стратегии и риск-менеджером string expertParams = StringFormat( "class CVirtualAdvisor(\n" " %s,\n" " %s,\n" " %d,%s,%d\n" ")", groupParams, riskManagerParams, magic_, "SimpleVolumesSingle", true ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Создаем эксперта, работающего с виртуальными позициями expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Сохраним полученный код в файле с новым именем SimpleVolumesStage1.mq5 в текущей папке.
Советник второго этапа
Пора приступать к основному советнику данной статьи — советнику второго этапа оптимизации. Как уже было сказано, он будет заниматься оптимизацией подбора группы одиночных экземпляров торговых стратегий, полученных на первом этапе. Возьмём за основу советник OptGroupExpert.mq5 из шестой части и внесём в него необходимые изменения.
Прежде всего, зададим имя базы данных задачи тестирования в директиве #property tester_file. Выбор конкретного имени не важен, так как оно будет использоваться только для проведения одного запуска оптимизации и только внутри данного советника.
#define PARAMS_FILE "database892.stage2.sqlite" #property tester_file PARAMS_FILE
Вместо имени CSV-файла, которое задавалось во входных параметрах, мы будем теперь задавать имя нашей основной базы данных:
input group "::: Отбор в группу" sinput string fileName_ = "database892.sqlite"; // - Файл с основной базой данных
Поскольку мы хотим подбирать группы из одиночных экземпляров торговых стратегий, работающих на одном и том же символе и таймфрейме, которые, в свою очередь, определяются в основной базе данных в таблице работ (jobs), то добавим во входные параметры возможность указывать идентификатор той работы (job), задачи которой сформировали набор одиночных экземпляров торговых стратегий для отбора в текущую группу:
input int idParentJob_ = 1; // - Идентификатор родительской работы
Раньше мы использовали подбор групп из восьми экземпляров, а теперь увеличим их количество до шестнадцати. Для этого добавим ещё восемь входных параметров для дополнительных индексов экземпляров стратегий и увеличим значение по умолчанию для параметра count_:
input int count_ = 16; // - Количество стратегий в группе (1 .. 16) input int i1_ = 1; // - Индекс стратегии #1 input int i2_ = 2; // - Индекс стратегии #2 input int i3_ = 3; // - Индекс стратегии #3 input int i4_ = 4; // - Индекс стратегии #4 input int i5_ = 5; // - Индекс стратегии #5 input int i6_ = 6; // - Индекс стратегии #6 input int i7_ = 7; // - Индекс стратегии #7 input int i8_ = 8; // - Индекс стратегии #8 input int i9_ = 9; // - Индекс стратегии #9 input int i10_ = 10; // - Индекс стратегии #10 input int i12_ = 11; // - Индекс стратегии #11 input int i11_ = 12; // - Индекс стратегии #12 input int i13_ = 13; // - Индекс стратегии #13 input int i14_ = 14; // - Индекс стратегии #14 input int i15_ = 15; // - Индекс стратегии #15 input int i16_ = 16; // - Индекс стратегии #16
Создадим отдельную функцию, которая будет заниматься созданием базы данных текущей задачи оптимизации. В ней мы будем подключаться к базе данных задачи с созданием при её отсутствии в папке данных терминала, вызывая метод DB::Connect(). В эту базу мы добавим только одну таблицу с двумя полями:
- id_pass — идентификатор прохода тестера на первом этапе
- params — строка инициализации эксперта для данного прохода тестера на первом этапе
Если таблица уже была добавлена ранее (то есть это уже не первый запуск оптимизации второго этапа), то мы будем её удалять и пересоздавать, так как для новой оптимизации нам понадобятся другие проходы из первого этапа.
Затем мы подключаемся к основной базе данных и извлекаем и неё данные тех проходов тестера, из которых мы сейчас будем подбирать группу. Имя файла основной базы данных передаётся в эту функцию как параметр fileName. Запрос на извлечение нужных данных соединяет таблицы passes, tasks, jobs и stages и возвращает строки, удовлетворяющие следующим условиям:
- название этапа для прохода равно "First". Так мы назвали первый этап, и по этому имени мы можем отфильтровать только проходы, относящиеся к первому этапу;
- идентификатор работы равен идентификатору, переданному в параметре idParentJob функции;
- значение нормированной прибыли для прохода превышает 2500;
- количество сделок больше 20;
- коэффициент Шарпа больше 2.
Последние три условия не являются обязательными. Их параметры подбирались под результаты конкретных проходов первого этапа так, чтобы, с одной стороны, у нас довольно много проходов попало в результаты запроса, а с другой стороны, эти проходы были бы неплохого качества.
В процессе извлечения результатов запроса мы сразу создаём массив SQL-запросов на вставку данных в базу данных задачи. Когда все результаты извлечены, мы переключаемся с основной базы данных на базу данных задачи и выполняем в одной транзакции все сформированные запросы на вставку данных. После этого снова переключаемся на основную базу данных.
//+------------------------------------------------------------------+ //| Создание базу данных для отдельной задачи этапа | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Создаём новую базу данных для текущей задачи оптимизации DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Подключаемся к основной базе данных DB::Connect(fileName); // Запрос на получение необходимой информации из основной базы данных string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE (s.name='First' AND " " j.id_job = %d AND" " p.custom_ontester > 2500 AND " " trades > 20 AND " " p.sharpe_ratio > 2)" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC;", idParentJob); // Выполнем запрос int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return; } // Структура для результатов запроса struct Row { string params; } row; // Массив для запросов на вставку данных в новую базу данных string queries[]; // Заполняем массив запросов: будем сохранять только строки инициализации while(DatabaseReadBind(request, row)) { APPEND(queries, StringFormat("INSERT INTO passes VALUES(NULL, '%s');", row.params)); } // Переподключаемся к новой базе данных и заполняем её DB::Connect(PARAMS_FILE, 0); DB::ExecuteTransaction(queries); // Переподключаемся к основной базе данных DB::Connect(fileName); DB::Close(); }
Эта функция будет вызываться в двух местах. Основное её место вызова — в обработчике OnTesterInit(), который запускается перед началом оптимизации на отдельном графике терминала. Его задача — создать и наполнить базу данных задачи оптимизации, проверить наличие наборов параметров одиночных экземпляров торговых стратегий в созданной базе данных задачи и установить правильные диапазоны перебора индексов одиночных экземпляров:
//+------------------------------------------------------------------+ //| Инициализация перед оптимизацией | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Создаём базу данных для отдельной задачи этапа CreateTaskDB(fileName_, idParentJob_); // Получаем количество наборов параметров стратегий int totalParams = GetParamsTotal(); // Если ничего не загрузили, то сообщим об ошибке if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Параметру scale_ устанавливаем значение 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Параметрам перебора индексов наборов задаём диапазоны изменения for(int i = 1; i <= 16; i++) { if(i <= count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 1, 1, totalParams); } else { // Для лишних индексов отключаем перебор ParameterSetRange("i" + (string) i + "_", false, 0, 1, 1, totalParams); } } return CVirtualAdvisor::TesterInit(idTask_); }
Задачу получения количества наборов параметров одиночных экземпляров торговых стратегий мы поручили отдельной функции GetParamsTotal(). Её задача очень проста: подсоединившись к базе данных задачи, выполнить один SQL-запрос на получение нужного количества и вернуть его результат:
//+------------------------------------------------------------------+ //| Количество наборов параметров стратегий в базе данных задачи | //+------------------------------------------------------------------+ int GetParamsTotal() { int paramsTotal = 0; // Если база данных задачи открыта, то if(DB::Connect(PARAMS_FILE, 0)) { // Создаём запрос на получение количества проходов для данной задачи string query = "SELECT COUNT(*) FROM passes p"; int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Структура данных для результата запроса struct Row { int total; } row; // Получаем результат запроса из первой строки if (DatabaseReadBind(request, row)) { paramsTotal = row.total; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } return paramsTotal; }
Далее перепишем функцию загрузки наборов параметров одиночных экземпляров торговых стратегий LoadParams(). В отличие от предыдущей реализации, когда мы читали файл целиком, создавали массив со всеми наборами параметров, а затем из этого массива выбирали несколько нужных, теперь поступим по-другому. Мы передадим этой функции список нужных индексов наборов и сформируем SQL-запрос, который вытащит из базы данных задачи только наборы с данными индексами. Полученные из базы наборы параметров (в виде строк инициализации) мы соединим через запятую в одну строку инициализации, которую будет возвращать эта функция:
//+------------------------------------------------------------------+ //| Загрузка наборов параметров стратегий | //+------------------------------------------------------------------+ string LoadParams(int &indexes[]) { string params = NULL; // Получаем количество наборов int totalParams = GetParamsTotal(); // Если они есть, то if(totalParams > 0) { if(DB::Connect(PARAMS_FILE, 0)) { // Формируем строку из индексов наборов, взятых из входных параметров советника // через запятую для дальнейшей подстановки в SQL-запрос string strIndexes = ""; FOREACH(indexes, strIndexes += IntegerToString(indexes[i]) + ","); strIndexes += "0"; // Дополняем несуществующим индексом, чтобы не удалять последнюю запятую // Формируем запрос на получение наборов параметров с нужными индексами string query = StringFormat("SELECT params FROM passes p WHERE id_pass IN(%s)", strIndexes); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Структура данных для результатов запроса struct Row { string params; } row; // Читаем результаты запроса и соединяем их через запятую while(DatabaseReadBind(request, row)) { params += row.params + ","; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } } return params; }
Ну и наконец, дошла очередь до функции инициализации советника. Помимо установки параметров управления капиталом, мы в самом начале собираем массив из нужного количества индексов наборов параметров одиночных экземпляров торговых стратегий. Нужное количество задаётся во входном параметре советника count_, а сами индексы — во входных параметрах с именами вида i{N}_, где {N} принимает значения от 1 до 16.
Затем мы проверяем полученный массив индексов на отсутствие дубликатов, помещая все индексы в контейнер типа множество (CHashSet) и проверяя, что во множестве оказалось столько же индексов, сколько и в массиве. Если это так, то все индексы являются уникальными. Если во множестве оказалось меньше индексов, чем было в массиве, то сообщаем о некорректных входных параметрах и не запускаем этот проход.
Если с индексами всё в порядке, то проверяем, в каком режиме сейчас запущен советник. Если это проход в составе процедуры оптимизации, то база данных задачи точно была создана перед началом оптимизации и сейчас она уже доступна. Если же это обычный одиночный проход тестера, то гарантировать наличие базы данных задачи мы не можем, поэтому просто пересоздадим её, вызвав функцию CreateTaskDB().
После этого загружаем из базы данных задачи наборы параметров с нужными индексами в виде одной строки инициализации (точнее, её части, которую мы подставим уже в итоговую строку инициализации объекта эксперта). Остаётся только сформировать итоговую строку инициализации и создать объект эксперта из неё.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Устанавливаем параметры в классе управления капиталом CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Массив всех индексов из входных параметров советника int indexes_[] = {i1_, i2_, i3_, i4_, i5_, i6_, i7_, i8_, i9_, i10_, i11_, i12_, i13_, i14_, i15_, i16_ }; // Массив для индексов, которые будут участвовать в оптимизации int indexes[]; ArrayResize(indexes, count_); // Копируем в него индексы из входных параметров FORI(count_, indexes[i] = indexes_[i]); // Множество для индексов наборов параметров CHashSet<int> setIndexes; // Добавляем все индексы во множество FOREACH(indexes, setIndexes.Add(indexes[i])); // Сообщаем об ошибке, если if(count_ < 1 || count_ > 16 // количество экземпляров не в диапазоне 1 .. 16 || setIndexes.Count() != count_ // не все индексы уникальные ) { return INIT_PARAMETERS_INCORRECT; } // Если это не оптимизация, то надо пересоздать базу данных задачи if(!MQLInfoInteger(MQL_OPTIMIZATION)) { CreateTaskDB(fileName_, idParentJob_); } // Загружаем наборы параметров стратегий string strategiesParams = LoadParams(indexes); // Если ничего не загрузили, то сообщим об ошибке if(strategiesParams == NULL) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", "database892.sqlite"); return(INIT_PARAMETERS_INCORRECT); } // Подготавливаем строку инициализации для эксперта с группой из нескольких стратегий string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Создаем эксперта, работающего с виртуальными позициями expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }Сохраним сделанные изменения в файле с именем SimpleVolumesStage2.mq5 в текущей папке. Советник, который будет оптимизироваться на втором этапе, готов. Теперь приступим к созданию задач на проведение второго этапа оптимизации в основной базе данных.
Создание задач второго этапа
Сначала создадим сам второй этап оптимизации. Для этого добавим в таблицу stages основной базы данных новую строку и заполним её значения таким образом:

Рис. 1. Строка таблицы stages со вторым этапом.
Пока что нам отсюда понадобится значение id_stage для второго этапа, который равен 2, и значение name для второго этапа, которое мы сделали равным "Second". Для создания работ (jobs) второго этапа нам надо взять все работы первого этапа и для каждой создать соответствующую работу второго этапа с таким же символом и таймфреймом. Значение поля tester_inputs мы сформируем как строку, в которой будет устанавливаться во входной параметр советника idParentJob_ значение идентификатора соответствующей работы первого этапа.
Для этого выполним такой SQL-запрос в основной базе данных:
INSERT INTO jobs SELECT NULL, 2 AS id_stage, j.symbol, j.period, 'idParentJob_=' || j.id_job || '||0||1||10||N' AS tester_inputs, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='First';
Выполнить его надо лишь один раз, и работы второго этапа будут созданы для всех имеющихся работ первого этапа:
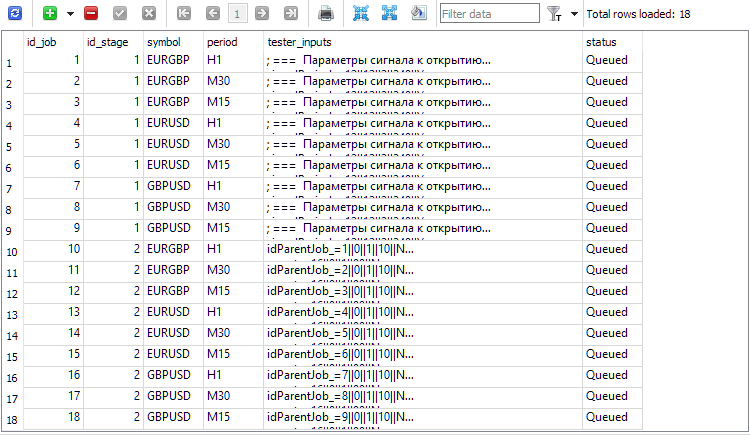
Рис. 2. Добавленные записи для работ второго этапа (id_job = 10 .. 18)
Отметим ещё такой момент. Внимательный читатель, возможно, заметил, что и у первого этапа, и у задач первого этапа в основной базе данных стоит статус "Queued", хотя мы говорили, что первый этап оптимизации мы уже выполнили. Нет ли тут противоречия? К сожалению, есть. Пока есть. Дело в том, что мы не позаботились ещё об обновлении статусов работ при завершении всех задач оптимизации, входящих в работы, и статусов этапов при завершении всех работ, входящих в этапы. Сделать это можно двумя путями:
- добавив дополнительный код в наш оптимизирующий советник, чтобы при завершении каждой задачи оптимизации выполнялись проверки необходимости обновления статуса не только задач, но и работ, и этапов;
- добавив триггер в базу данных, отслеживающий событие изменения задачи. При возникновении этого события код триггера должен будет проверять необходимость обновления статусов работ и этапов и заниматься их обновлением.
Остаётся ещё создать задачи для каждой работы, и можно запускать второй этап. В отличие от первого этапа, на втором этапе мы не будем в рамках одной работы использовать несколько задач с разными критериями оптимизации. Воспользуемся только одним критерием — нашим критерием средней нормированной годовой прибыли. Для установки этого критерия, нам нужно выбрать индекс 6 в поле критерия оптимизации.
Создать задачи второго этапа для всех работ с критерием оптимизации 6 можно с помощью такого SQL-запроса:
INSERT INTO tasks SELECT NULL, j.id_job AS id_job, 6 AS optimization, NULL AS start_date, NULL AS finish_date, 'Queued' AS status FROM jobs j JOIN stages s ON j.id_stage = s.id_stage WHERE s.name='Second';
Запустим его один раз и получим в таблице задач (tasks) новые записи, соответствующие задачам, выполняемым на втором этапе. После этого добавляем советник Optimization.ex5 на любой график терминала и идем заниматься другими делами, пока терминал не выполнит все задачи оптимизации. Время выполнения может сильно варьироваться, в зависимости от самого советника, продолжительности интервала тестирования, количества символов и таймфреймов и, конечно, количества задействованных агентов.
Для используемого в этом проекте советника, на интервале продолжительностью 2 года (2021 и 2022), при оптимизации по трём символам и трём таймфреймам на 32 агентах, все задачи оптимизации второго этапа были завершены примерно за 5 часов. Давайте посмотрим на их результаты.
Советник для заданных проходов
Чтобы нам было удобнее это сделать, создадим ещё один советник, а точнее, внесём небольшие правки в уже существующий. Сделаем в нём входной параметр passes_, в котором мы будем указывать через запятую идентификаторы проходов тестера, наборы стратегий из которых мы хотели бы соединить в одну группу в данном советнике.
Тогда в методе инициализации советника нам достаточно получить параметры (строки инициализации групп стратегий) этих проходов из основной базы данных и подставить их в строку инициализации объекта эксперта в этом советнике:
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ input group "::: Управление капиталом" sinput double expectedDrawdown_ = 10; // - Максимальный риск (%) sinput double fixedBalance_ = 10000; // - Используемый депозит (0 - использовать весь) в валюте счета input double scale_ = 1.00; // - Масштабирующий множитель для группы input group "::: Отбор в группу" input string passes_ = "734469,735755,736046,736121,761710,776928,786413,795381"; // - Идентификаторы проходов через запятую ulong magic_ = 27183; // - Magic bool useOnlyNewBars_ = true; // - Работать только на открытии бара datetime fromDate = TimeCurrent(); CVirtualAdvisor *expert; // Объект эксперта //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Устанавливаем параметры в классе управления капиталом CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Строка инициализации с наборами параметров стратегий string strategiesParams = NULL; // Если соединение с основной базой данных установлено, то if(DB::Connect()) { // Формируем запрос на получение проходов с указанными идетификаторами string query = StringFormat( "SELECT DISTINCT p.params" " FROM passes p" " WHERE id_pass IN (%s);" , passes_); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Структура для чтения результатов struct Row { string params; } row; // Для всех строк результата запроса, соединяем строки инициализации while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // Если наборов параметрв не найдено, то прерываем тестирование if(strategiesParams == NULL) { return INIT_FAILED; } // Подготавливаем строку инициализации для эксперта с группой из нескольких стратегий string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " class CVirtualRiskManager(\n" " %d,%.2f,%d,%.2f,%d,%.2f" " )\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, 0, 0, 0, 0, 0, 0, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Создаем эксперта, работающего с виртуальными позициями expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Сохраним полученный объединённый советник в файле SimpleVolumesExpert.mq5 в текущей папке.
Получить идентификаторы наилучших проходов второго этапа можно, например, с помощью такого SQL-запроса:
SELECT p.id_pass, j.symbol, j.period, p.custom_ontester, p.profit, p.profit_factor, p.sharpe_ratio, p.equity_dd, p.params FROM ( SELECT p0.*, ROW_NUMBER() OVER (PARTITION BY id_task ORDER BY custom_ontester DESC) AS rn FROM passes p0 ) AS p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage WHERE rn = 1 AND s.name = 'Second';
В нём мы опять используем соединение наших таблиц из основной базы данных, чтобы можно было выбрать те проходы, которые относятся к этапу с именем "Second", то есть второму. Также применяем соединение таблицы проходов (passes) со своей копией, которая разбита на разделы с одинаковым идентификатором задачи, и внутри каждого раздела строки отсортированы по убыванию значения нашего критерия оптимизации (custom_ontester) и пронумерованы. Номер строки в разделах будет попадать в столбец rn. В конечном результате мы оставляем только первые строки из каждого раздела, то есть с самым большим значением критерия оптимизации.

Рис. 3. Список идентификаторов проходов для самых лучших показателей в каждой работе второго этапа
Возьмём значения идентификаторов из первого столбца id_pass и подставим во входной параметр passes_ объединённого советника. Запустим тестирование и получим следующие результаты:
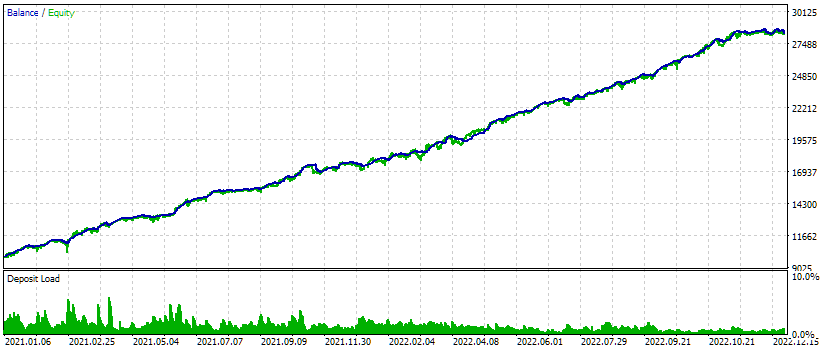

Рис. 4. Результаты тестирования объединённого советника для трёх символов и трёх таймфреймов.
На данном интервале тестирования внешний вид графика роста средств выглядит довольно неплохо: скорость роста остаётся примерно одинаковой на всём интервале, просадка находится в пределах допустимой ожидаемой просадки. Но нас сейчас больше интересует не это, а то, что мы можем теперь почти автоматически сформировать строку инициализации советника, объединяющего несколько самых лучших групп одиночных экземпляров торговых стратегий для разных символов и таймфреймов.
Заключение
Итак, второй этап нашей намеченной процедуры оптимизации тоже реализован в черновом варианте. Для дальнейшего удобства хорошо бы сделать отдельный веб-интерфейс для создания и управления проектами по оптимизации торговых стратегий. Но перед тем, как приступать к различного рода повышениям комфортности, желательно полностью пройти намеченный путь, не отвлекаясь на вещи, без которых пока можно обойтись. К тому же в процессе разработки черновых вариантов реализации мы зачастую вынуждены вносить какие-либо коррективы в исходный план из-за новых, открывающихся по мере движения, обстоятельств.
Сейчас мы провели оптимизацию первого и второго этапа только на относительно небольшом временном интервале. Желательно, конечно, расширить интервал тестирования и оптимизировать всё заново. Также мы не попробовали ещё подключить кластеризацию на втором этапе, которую опробовали в шестой части цикла и получили ускорение процесса оптимизации по сравнению с оптимизацией без кластеризации. Но это потребовало бы гораздо больших усилий по разработке, так как нам придётся разработать механизм автоматического выполнения действий, которые сложно реализовать в MQL5, но очень легко в Python или R.
Трудно решить, в какую сторону нам стоит сделать следующий шаг. Поэтому давайте возьмем небольшую паузу, и может быть то, что было неясным сегодня, станет прозрачным завтра.
Спасибо за внимание, до новых встреч!
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Юрий здравствуйте. Провожу сейчас вот оптимизацию второго этапа и в логе периодически проскакивает ошибка занятости базы данных:
Советник оригинальный, из статьи. Оптимизацию провожу на локальных агентах пк и по локальной сети на агентах другого пк. В целом процесс идёт и проходы в базу заполняются, но хотелось бы понять от чего происходит эта ошибка, ну и как то её исправить?
Ещё бывает некоторые задачи второго этапа очень быстро заканчиваются. Вот к примеру:
Вот здесь к примеру NZDCAD H1 M30 и NZDCHF H1 закончились буквально за один проход оптимизатора как я понимаю. Хотя там в базе проходов первого этапа для них много есть. Почему так происходит и что с этим можно сделать?
А NZDCAD M15 вообще ошибку выдал. Как я понимаю он не находит данных в базе данных, но как такое возможно? Ведь на первом этапе оптимизация этих пар была и проходы должны быть в базе...
Юрий а можно так вот к примеру сделать: вот я провёл первый и второй этап и сохранил всё в одну базу. А можно потом (после второго этапа) поменять, в базе данных, статус задач первого этапа для тех пар и тф на которых второй этап дал плохие результаты, чтобы для этих пар и тф как бы поверх второго этапа добавить проходов первого этапа ещё, а потом для них провести повторно второй этап? Просто при таком действии id новых проходов первого этапа будет выше чем id проходов второго этапа для всех остальных пар в этой базе. Я имею веду таблицу passes. Можно так сделать, и найдёт ли оптимизатор проходы превого этапа для этих пар и тф?
Где-то открыта и заблокирована база данных. Это может быть и внешнее приложение по отношению к тестеру, например, MetaEditor. Не помню, чтобы сталкивался с подобным.
Это действительно говорит о том, что проходов первого этапа для NZDCAD M15 почему-то не нашлось.
Да, так делать можно сколько угодно раз. Если хочется, чтобы старых проходов от предыдущих первых этапов не осталось, то их можно удалить из таблицы passes по нужным id_task.