O que alimentar a entrada da rede neural? Suas ideias... - página 52
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Se você observar a imagem, sim, ela é quente e macia, mas no código ela é boa.
Os colchetes na imagem estão errados. Deveria ser assim.
Ola ke tal. Pensei em dar minhas ideias.
Meu modelo mais recente consiste em coletar preços normalizados de 10 símbolos e, assim, treinar uma rede de recorrência. Para a entrada de 20 barras do mês, da semana e do dia.
Essa é a imagem que obtenho. A diferença em relação ao treinamento separado é que o lucro total é 3 vezes menor e o drawdown.... uau, o rebaixamento no período de controle é de apenas 1%.
Parece-me que isso resolve o problema da escassez de dados.
Ola ke tal. Pensei em dar minhas ideias.
Meu modelo mais recente consiste em coletar preços normalizados de 10 símbolos e, assim, treinar uma rede de recorrência. Há 20 barras do mês, da semana e do dia por entrada.
Essa é a imagem que obtenho. A diferença em relação ao treinamento separado é que o lucro total é 3 vezes menor e o rebaixamento.... uau, o rebaixamento no período de controle é de apenas 1%.
Parece-me que isso resolve o problema da escassez de dados.
Acho que você tem um nível de conhecimento extremamente alto sobre o assunto.
Receio não entender nada. Por favor, diga-me o que é essa beleza no gráfico: é Python?
É possível mostrar uma coisa dessas no MT5?
Preços normalizados de 10 símbolos
Aqui também, como os preços foram normalizados. O que é "ante"? Em geral, qualquer coisa que não seja um segredo comercial, por favor, compartilhe)
Acho que você tem um nível extremamente alto de domínio do assunto.
Receio não entender nada. Por favor, diga-me o que é essa beleza no gráfico: é Python?
É possível mostrar uma coisa dessas no MT5?
O que é "ante"? Em geral, qualquer coisa que não seja um segredo comercial, por favor, compartilhe).
É claro que é python. No µl5, para selecionar dados em uma condição, é preciso fazer uma enumeração e tudo isso iff iff iff iff iff iff iff. E no python, em uma linha, é possível selecionar dados por qualquer condição. Não estou falando da velocidade do trabalho. É muito conveniente. O Mcl5 é necessário para abrir negociações com uma rede pronta.
A normalização é a mais comum. Menos a média, dividida pelo desvio padrão. O segredo comercial aqui é o período de normalização, é importante abordá-lo de forma que os preços fiquem em torno de zero por 10 anos. Mas não de forma que no início dos 10 anos eles estejam abaixo de zero e no final estejam acima de zero. Essa não é a maneira de comparar...
Dois períodos de teste - ante e teste. O período ante antes do treinamento é de 6 meses. É muito conveniente. O ante está sempre lá. E o teste é o futuro, ele não existe. Ou seja, ele existe, mas apenas no passado. E no futuro não existe. Ou seja, não existe.
O que você acha que é mais importante: a arquitetura ou os dados de entrada?
O que você acha que é mais importante: a arquitetura ou os dados de entrada?
Acho que as entradas. Aqui estou tentando 6 caracteres, não 10. E não estou passando o período de controle de agosto a dezembro de 2023. Separadamente, também é difícil. E uma passagem de 10 caracteres pode ser legitimamente escolhida com base nos resultados do treinamento. A rede é sempre recorrente em uma camada de 32 estados, o link completo só é usado.
Alguns resumos:
Percebi que tinha acabado de encontrar um padrão algorítmico enquanto examinava vários dados de entrada, respondendo parcialmente à pergunta do meu ramo: "O que alimentar a entrada da rede neural?" Mas a rede neural acabou sendo desnecessária. Nem MLP, nem RNN, nem LSTM, nem BiLSTM, nem CNN, nem Q-learning, nem todos esses combinados e misturados.
Em um desses experimentos, otimizei 2 entradas em 3 neurônios. Como resultado, um dos conjuntos superiores mostrou a seguinte imagem
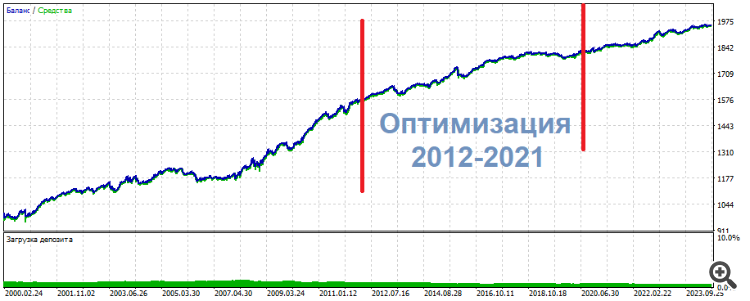
* ******* **************
UPD Aqui está outro conjunto, a mesma coisa: meio - otimização, resultados - nas laterais. Quase o mesmo, apenas mais homogêneo
**********************
As negociações não são de pips ou de couro cabeludo. Em vez disso, são intraday.
Portanto, minhas conclusões subjetivas para o momento atual:
Nunca vi resultados piores do que com indicadores de suavização em minha vida. É como se uma pessoa com visão ficasse cega. Agora mesmo ele podia ver uma silhueta nítida e agora não consegue entender o que é - uma mancha em seus olhos. Nenhuma informação.
Minha opinião, como eu a vejo
A rede neural só é aplicável a padrões estáticos e estacionários que não têm nada a ver com preços
Que tipo de pré-processamento e normalização você faz? Você já tentou a padronização?
I van Butko #: A rede neural se lembra do caminho. Não mais do que isso.
Experimente os Transformers, dizem que são bons para você....
Ivan Butko #: Os osciladores são ruins!
Bem, nem tudo é tão inequívoco. É que a NS é conveniente para trabalhar com funções contínuas, mas precisamos de uma arquitetura que funcione com funções por partes/intervalo, e então a NS poderá considerar os intervalos dos osciladores como informações significativas.
Que tipo de pré-processamento e normalização você faz? Você já tentou a padronização?
Experimente os Transformers, dizem que são bons para você....
Bem, nem tudo é tão claro. É que o NS é conveniente para trabalhar com funções contínuas, mas precisamos de uma arquitetura que funcione com funções por partes/intervalo, e então o NS poderá considerar as faixas do oscilador como informações significativas.
1. e quando como: se a janela de dados, alguns incrementos, eu trago o intervalo -1...1. não ouvi falar de padronização 2.
Aceito, obrigado 3. Concordo, mas não tenho provas cabais do contrário.
É por isso que escrevo de minha própria torre de sino, como vejo e imagino aproximadamente. A simples suavização é um apagamento de fato das informações. Não é generalização. É exatamente um apagamento. Pense em uma fotografia: assim que você degrada seu conteúdo, a informação é irremediavelmente perdida. E restaurá-la com IA é um esforço artístico, não uma restauração no verdadeiro sentido. É um redesenho arbitrário.
" Suavização: quando um número é o resultado de duas unidades de informação independentes: o padrão -1/1, digamos, e o padrão -6/6. O valor médio de cada um será o mesmo, mas originalmente havia dois padrões. Eles podem ou não significar algo, podem significar sinais opostos.
E aqui estão os mashki, osciladores e assim por diante - eles apenas apagam/borram estupidamente a "imagem" inicial do mercado. E nessa "mancha" assustamos o NS, fazendo com que ele tente incessantemente trabalhar como deveria. A generalização e a suavização são fenômenos heterogêneos extremamente hostis.
Alguns resumos:
Percebi que tinha acabado de encontrar um padrão algorítmico enquanto examinava vários dados de entrada e, de fato, respondi parcialmente à pergunta do meu ramo: "O que alimentar a entrada da rede neural?" Mas a rede neural acabou sendo desnecessária. Nem MLP, nem RNN, nem LSTM, nem BiLSTM, nem CNN, nem Q-learning, nem todos esses combinados e misturados.
Em um desses experimentos, otimizei 2 entradas em 3 neurônios. Como resultado, um dos conjuntos superiores mostrou a seguinte imagem
* ******* **************
UPD Aqui está outro conjunto, a mesma coisa: meio - otimização, resultados - nas laterais. Quase o mesmo, apenas mais homogêneo
**********************
As negociações não são nem de pips nem de couro cabeludo.
Portanto, minhas conclusões subjetivas no momento:
Nunca vi resultados piores do que com indicadores de suavização em minha vida. É como se uma pessoa com visão ficasse cega. Agora mesmo ele podia ver uma silhueta nítida e agora não consegue entender o que é - uma mancha em seus olhos. Nenhuma informação.
Minha opinião, como eu a vejo
não é um pips fraco.
Está na hora de costurar bolsas?