
Previsão de séries temporais utilizando suavização exponencial (continuação)

Introdução
O artigo "Time Series Forecasting Using Exponential Smoothing" (Previsão de séries temporais utilizando suavização exponencial, em tradução livre) [1] fez um breve resumo dos modelos de suavização exponencial, ilustrou uma das possíveis abordagens para otimizar os parâmetros do modelo e, finalmente, propôs o indicador de previsão desenvolvido com base no modelo de crescimento linear com amortecimento . Este artigo representa uma tentativa de aumentar um pouco a precisão do indicador de previsão.
é complicado prever cotações de moedas ou para obter uma previsão bastante confiável mesmo para três ou quatro passos à frente. No entanto, como no artigo anterior desta série, vamos produzir 12 previsões um passo à frente, percebendo claramente que será impossível obter resultados satisfatórios sobre de um horizonte tão longo. Os primeiros passos da previsão com intervalos de confiança mais estreitos deve, portanto, ser dado mais atenção.
Uma previsão 10- a 12 passos à frente é destinada principalmente para a manifestação de características comportamentais de diferentes modelos e métodos de previsão. Em qualquer caso, a precisão da previsão obtida para qualquer horizonte pode ser avaliada através dos limites de intervalo de confiança. Este artigo visa essencialmente a demonstração de alguns métodos que podem ajudar a melhorar o indicador conforme estabelecido no artigo [1].
O algoritmo para encontrar o mínimo de uma função de várias variáveis que é aplicada no desenvolvimento dos indicadores foi abordada no artigo anterior e, portanto, não será repetidamente descrito aqui. Para não sobrecarregar o artigo, insumos teóricos serão reduzidos ao mínimo.
1. Indicador inicial
O indicador IndicatorES.mq5 (ver artigo [1]) vai ser usado como um ponto de partida.
Para a compilação do indicador precisaremos IndicatorES.mq5, CIndicatorES.mqh e PowellsMethod.mqh, todos localizados no mesmo diretório. Os arquivos podem ser encontrados no arquivo files2.zip no final do artigo.
Vamos atualizar as equações que definem o modelo de suavização exponencial utilizado no desenvolvimento deste indicador - o modelo de crescimento linear com amortecimento.
![]()
![]()
![]()
Onde:
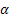 - parâmetro de suavização para o nível da sequência de [0,1];
- parâmetro de suavização para o nível da sequência de [0,1];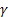 - parâmetro de suavização para a tendência [0,1];
- parâmetro de suavização para a tendência [0,1];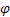 - parâmetro de amortecimento [0,1];
- parâmetro de amortecimento [0,1];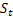 - nível suavizado da sequência calculado no momento t após
- nível suavizado da sequência calculado no momento t após 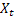 ter sido observado;
ter sido observado;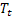 - tendência aditiva suavizada calculada no momento t;
- tendência aditiva suavizada calculada no momento t;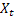 - valor da sequência no tempo t;
- valor da sequência no tempo t;
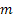 - número de passos à frente para qual a previsão é feita;
- número de passos à frente para qual a previsão é feita;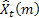 - previsão efetuada m-passo à frente no tempo t;
- previsão efetuada m-passo à frente no tempo t;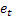 - erro de previsão um passo à frente no tempo t
- erro de previsão um passo à frente no tempo t 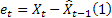 .
.
O único parâmetro de entrada do indicador é o valor que determina a duração do intervalo de acordo com qual os parâmetros do modelo serão optimizados e os valores iniciais (intervalo de estudo) selecionados. Após a determinação dos valores ideais dos parâmetros do modelo em um determinado intervalo e os cálculos necessários, a previsão, intervalo de confiança e a linha correspondente à previsão de um passo à frente são produzidos. A cada nova barra, os parâmetros são otimizados e a previsão é feita.
Uma vez que o indicador em questão vai ser atualizado, o efeito das alterações que faremos serão avaliadas utilizando as sequências de teste a partir do arquivo Files2.zip localizado no final do artigo. O diretório do arquivo \Dataset2 contém arquivos com as citações salvas EURUSD, USDCHF, USDJPY e U.S. Dollar Index DXY. Cada um desses é fornecido por três períodos de tempo, sendo M1, H1 e D1. Os valores "abertos" salvos nos arquivos estão localizados de modo que o valor mais recente está no final do arquivo. Cada arquivo contém 1200 elementos.
Erros de previsão serão estimados pelo cálculo do coeficiente "Erro Percentual Absoluto Médio" (MAPE)
![]()
Vamos dividir cada uma das doze sequências de teste em 50 seções sobrepostas contendo 80 elementos cada e calcular o valor MAPE para cada um deles. A média das estimativas assim obtidas serão utilizadas como um índice de erro de previsão no que diz respeito aos indicadores colocados em comparação. Valores MAPE para dois e três erros de previsão um passo à frente, serão calculados da mesma maneira. Tais estimativas médias serão mais indicadas como segue:
- MATE1 - estimativa média do erro de previsão um passo à frente;
- MATE2 - estimativa média do erro de previsão dois passos à frente;
- MATE3 - estimativa média do erro de previsão três passos à frente;
- MAPE1-3 – significa (MAPE1+MAPE2+MAPE3)/3.
Ao calcular o valor de MAPE, o valor do erro de previsão absoluto é a cada passo dividido pelo valor atual da sequência. A fim de evitar a divisão por zero ou a obtenção de valores negativos ao fazer isso, as sequências de entrada são obrigadas a tomar apenas valores positivos diferentes de zero, como no nosso caso.
Os valores estimados para o indicador inicial são mostrados na Tabela 1.
| MAPE1 |
MAPE2 |
MAPE3 |
MAPE1-3 |
|
|---|---|---|---|---|
| IndicadorES |
0,2099 |
0,2925 |
0,3564 |
0,2863 |
Tabela 1. Indicador inicial de estimativas de previsão de erro
Os dados apresentados no Quadro 1 são obtidos usando o script Errors_IndicatorES.mq5 (a partir do arquivo files2.zip localizado no fim do artigo). Para compilar e executar o script, é necessário que CIndicatorES.mqh e PowellsMethod.mqh estejam localizados no mesmo diretório que Errors_IndicatorES.mq5, e as sequências de entrada estejam no diretório Files\Dataset2\.
Após a obtenção das estimativas iniciais dos erros de previsão, podemos agora proceder à atualização do indicador em consideração.
2. Critério de otimização
Os parâmetros do modelo do indicador inicial, conforme estabelecido no artigo "Previsão de séries temporais utilizando suavização exponencial" foram determinados pela minimização da soma dos quadrados dos erros de previsão um passo a frente. Parece lógico que o modelo de parâmetros ideais para uma previsão um passo a frente pode não produzir o mínimo de erros para uma previsão mais passo à frente. Seria, é claro, desejável minimizar erros de previsão 10 a 12 passos a frente, mas a obtenção de um resultado satisfatório previsional sobre o intervalo dado para as sequências em consideração seria uma missão impossível.
Sendo realista, ao otimizar os parâmetros do modelo, vamos usar a soma dos quadrados dos erros de previsão de um, dois e três passos a frente como a primeira atualização do nosso indicador. O número médio de erros pode ser esperado que diminua um pouco ao longo do intervalo das três primeiras etapas da previsão.
Claramente, tal atualização do indicador inicial não diz respeito a seus princípios estruturais, mas só muda o critério de otimização de parâmetros. Portanto, não podemos esperar que a precisão das previsões aumente várias vezes, embora o número da previsão de erros de dois e três passos à frente deve cair um pouco.
A fim de comparar os resultados de previsão, criamos a classe CMod1 semelhante à classe CIndicatorES introduzida no artigo anterior com a função objetiva func modificada.
A função func da classe CIndicatorES inicial:
double CIndicatorES::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,sse,ae,pt; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95;} // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 sse=0; for(i=0;i<Dlen;i++) { e=Dat[i]-(s+phi*t); sse+=e*e; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } return(Dlen*MathLog(k1*k2*k3*sse)); }
Após algumas modificações, a função func agora aparece da seguinte forma
double CMod1::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95; // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*k3*err); }
Agora, ao calcular a função objetiva, a soma dos quadrados dos erros de previsão de um, dois e três passos a frente é utilizada.
Além disso, com base nesta classe, o script Errors_Mod1.mq5 foi desenvolvido permitindo estimar os erros de previsão como o já mencionado Errors_IndicatorES.mq5 script faz. CMod1.mqh e Errors_Mod1.mq5 estão localizados no arquivo files2.zip no final do artigo.
A Tabela 2 apresenta as estimativas de erro de previsão para as versões iniciais e atualizadas.
| MAPE1 |
MAPE2 |
MAPE3 |
MAPE1-3 |
|
|---|---|---|---|---|
| IndicadorES |
0,2099 |
0,2925 |
0,3564 |
0,2863 |
| Mod1 |
0,2144 |
0,2898 |
0,3486 |
0,2842 |
Tabela 2. Comparação das estimativas de previsão de erro
Como pode ser visto, os coeficientes de erro MAPE2 e MAPE3 e o valor médio MAPE1-3, na verdade, acabaram se tornando ligeiramente inferior para as sequências em questão. Por isso, vamos salvar essa versão e avançar para uma nova modificação do nosso indicador.
3. O ajuste dos parâmetros do processo de suavização
A ideia de mudar os parâmetros de suavização dependendo dos valores atuais da sequência de entrada não é novo ou original e vem do desejo de ajustar os coeficientes de suavização para que eles permaneçam ideal dado qualquer mudança na natureza da sequência de entrada. Algumas maneiras de ajustar os coeficientes de suavização são descritos na literatura [2], [3].
Para melhorar ainda mais o indicador, vamos usar o modelo com mudança dinâmica do coeficiente de suavização na expectativa de que o uso do modelo de suavização exponencial adaptativo nos permitirá aumentar a precisão das previsões do nosso indicador.
Infelizmente, quando utilizadas em algoritmos de previsão, a maioria dos métodos de adaptação nem sempre produzem os resultados desejados. A seleção do método de adaptação adequado pode parecer muito complicada e demorada, por isso, no nosso caso, vamos fazer uso dos resultados previstos na literatura [4] e tentar empregar "Transição harmoniosa de suavização exponencial" (STES) abordagem estabelecida no artigo [5].
A essência da abordagem é claramente descrita no artigo especificado, por isso vamos excluí-lo aqui e avançar diretamente para as equações para o nosso modelo (ver o início do artigo especificado) levando em consideração a utilização do coeficiente de suavização adaptativa.
![]()
![]()
![]()
![]()
Como podemos ver agora, o valor do coeficiente alfa de suavização é calculado a cada passo do algoritmo e depende do erro de previsão quadrado. Valores dos coeficientes b e g determinam o efeito do erro de previsão sobre o valor alfa. Em todos os outros aspectos, as equações para o modelo empregado permaneceram inalterada. Informação adicional sobre o uso da abordagem STES pode ser encontrada no artigo [6].
Considerando que nas versões anteriores, tivemos que determinar o valor ideal do coeficiente alfa sobre a sequência de entrada dada, há agora dois coeficientes adaptativos B e G, que estão sujeitos a otimização e o valor de alfa será determinado de forma dinâmica no processo de suavização da sequência de entrada.
Esta atualização é implementado na forma de classe CMod2. As principais mudanças (como o tempo anterior) interessa principalmente a função func, que agora aparece da seguinte maneira.
double CMod2::func(const double &p[]) { int i; double s,t,alp,gam,phi,sb,sg,k1,k2,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; gam=p[2]; phi=p[3]; sb=p[4]; sg=p[5]; k1=1; k2=1; if (gam>0.95){k1+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k1+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k2+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k2+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*err); }
Ao desenvolver esta função, a equação que define o valor do coeficiente alfa foi ligeiramente modificado. Isto foi feito para definir o limite do valor máximo e mínimo admissível deste coeficiente de 0,05 e 0,95, respectivamente.
Para estimar os erros de previsão, como foi feito anteriormente, o script Errors_Mod2.mq5 foi escrito com base na classe CMod2. CMod2.mqh e Errors_Mod2.mq5 estão localizados no arquivo files2.zip no final do artigo.
Os resultados de script são mostrados na Tabela 3.
| MAPE1 |
MAPE2 |
MAPE3 |
MAPE1-3 |
|
|---|---|---|---|---|
| IndicadorES |
0,2099 |
0,2925 |
0,3564 |
0,2863 |
| Mod1 |
0,2144 |
0,2898 |
0,3486 |
0,2842 |
| Mod2 |
0,2145 |
0,2832 |
0,3413 |
0,2797 |
Tabela 3. Comparação das estimativas de previsão de erro
Como a Tabela 3 sugere, a utilização do coeficiente de suavização adaptativo tem em média, ligeiramente permitido diminuir ainda mais os erros de previsão para nossas sequências de teste. Assim, após duas atualizações, conseguimos diminuir o coeficiente de erro MAPE1-3 em cerca de dois por cento.
Apesar de um resultado de atualização bastante modesto, vamos ficar com a versão resultante e deixar mais atualizações fora do âmbito do artigo. Como próximo passo, seria interessante tentar usar a transformação Box-Cox. Esta transformação é usada principalmente para aproximar a distribuição inicial de sequência para a distribuição normal.
No nosso caso, poderia ser utilizada para transformar a sequência inicial, calcular a previsão e a transformação inversa da previsão. O coeficiente de transformação aplicada ao fazer isso deverá ser selecionado de modo que o erro de previsão resultante seja minimizado. Um exemplo do uso da transformação de Box-Cox em sequências de previsão pode ser encontrada no artigo [7].
4. Previsão do intervalo de confiança
O intervalo de confiança na previsão do indicador inicial IndicatorES.mq5 (previsto no artigo anterior) foi calculado de acordo com as expressões analíticas derivadas para o modelo de suavização exponencial selecionado [8]. As alterações feitas no nosso caso levaram a mudanças no modelo em questão. O coeficiente de suavização variável torna impróprio para uso as expressões analíticas acima mencionadas para estimar o intervalo de confiança.
O fato de que as expressões analíticas anteriormente utilizadas foram derivadas com base no pressuposto de que a distribuição do erro de previsão é simétrica e normal, pode constituir uma razão adicional para mudar o método de estimativa do intervalo de confiança. Estes requisitos não foram atendidos para a nossa classe de sequências e a distribuição do erro de previsão não pode ser normal nem simétrica.
Ao estimar o intervalo de confiança no indicador inicial, a variância do erro da previsão um passo à frente foi calculada em primeiro lugar, a partir da sequência de entrada, seguida do cálculo da variância da previsão para dois, três e mais passos à frente, com base no erro de previsão do valor de variância de um só passo a frente obtido utilizando as expressões analíticas.
A fim de evitar o uso das expressões analíticas, existe uma forma simples através do qual a variância da previsão de dois, três e mais passos à frente é calculada diretamente a partir da sequência de entrada, bem como a variância da previsão de um só passo a frente. No entanto, esta abordagem tem uma desvantagem significativa: em sequência de entradas curtas, as estimativas de intervalo de confiança serão amplamente dispersas e o cálculo de variância e erro médio quadrado não permitirão aliviar as restrições sobre a normalidade esperada de erros.
Uma solução neste caso pode ser encontrada na utilização de inicialização não paramétrica (reamostragem) [9]. A espinha dorsal da idéia expressa de forma simples: no momento da amostragem de um modo aleatório (distribuição uniforme) com a substituição da sequência inicial, a distribuição da sequência artificial assim produzida será a mesma de que a inicial.
Suponha que temos uma seqüência de entrada de N membros; ao gerar uma sequência pseudo-aleatória uniformemente distribuída ao longo do intervalo de [0, N-1] e utilizando estes valores como índices quando fizermos a amostragem a partir da série inicial, nós podemos gerar uma sequência artificial de um comprimento substancialmente maior do que a inicial. Dito isso, a distribuição da sequência gerada será a mesma (quase a mesma) que a inicial.
O procedimento de auto inicialização para a estimativa dos intervalos de confiança podem ser da seguinte forma:
- Determinar os valores iniciais ideais dos parâmetros do modelo, seus coeficientes e coeficientes de adaptação da sequência de entrada para o modelo de suavização exponencial obtido como um resultado da modificação. Os parâmetros ideais são, como antes, determinados usando o algoritmo que utiliza o método de procura de Powell;
- Usando os parâmetros determinados do modelo ideal, "vá", através da sequência inicial e forme uma série de erros de previsão um passo a frente. O número de elementos da série será igual ao comprimento da sequência de entrada N;
- Alinhe os erros subtraindo cada elemento da série de erro, o valor médio dos mesmos;
- Utilizando o gerador de sequência pseudo-aleatória, gerar índices dentro do intervalo de [0,N-1], e utilizá-los para formar uma sequência artificial de erros sendo 9999 elementos de comprimento (reamostragem);
- Formar uma série contendo 9999 valores de sequência de pseudo-entrada inserindo os valores da série de erro gerada artificialmente nas equações que definem o modelo atualmente utilizado. Em outras palavras, enquanto que anteriormente tinha que se inserir os valores de sequência de entrada para as equações do modelo de cálculo e assim, o erro de previsão, agora os cálculos inversos são feitos. Para cada elemento da série, o valor do erro é inserido para calcular o valor de entrada. Como resultado, temos a série de 9999 elementos que contêm a sequência com a mesma distribuição que a seqüência de entrada enquanto sendo de comprimento suficiente para estimar diretamente os intervalos de previsão de confiança.
Em seguida, estimar os intervalos de confiança usando a sequência gerada de comprimento adequado. Para isso, vamos explorar o fato de que, se a série de erro de previsão gerada é classificada em ordem crescente, as células da série com índices 249 e 9749 para a série contendo os valores de 9999 terá os valores correspondentes aos limites do intervalo de confiança de 95% [10].
A fim de obter uma estimativa mais precisa dos intervalos de previsão, o comprimento da série deve ser ímpar. No nosso caso, os limites dos intervalos de confiança de previsão são calculados da seguinte forma:
- Usando os parâmetros do modelo ideal, conforme determinado anteriormente, "vá", através da sequência gerada e forme uma série de erros de previsão um passo a frente.
- Classificar a série resultante;
- A partir da série de erro classificado, selecione valores com índices 249 e 9749 que representam os limites de 95% do intervalo de confiança;
- Repita os passos 1, 2 e 3 para erros de previsão dois, três e mais passos à frente.
Esta abordagem para estimar os intervalos de confiança tem as suas vantagens e desvantagens.
Entre as suas vantagens está a ausência de pressupostos relativos à natureza da distribuição dos erros de previsão. Eles não tem que ser normalmente ou simetricamente distribuídos. Além disso, esta abordagem pode ser útil sempre que seja impossível derivar expressões analíticas para o modelo em uso.
Um aumento dramático no âmbito requerido de cálculos e dependência das estimativas sobre a qualidade do gerador de sequência pseudo-aleatória utilizada pode ser considerado suas desvantagens.
A abordagem proposta para estimar os intervalos de confiança usando reamostragem e quantils é bastante primitiva e deve haver maneiras de melhorá-la. Mas desde que os intervalos de confiança em nosso caso são destinados apenas para a avaliação visual, a precisão proporcionada pela abordagem acima pode parecer suficiente.
5. Versão modificada do indicador
Tendo em conta as atualizações introduzidas no artigo, o indicador ForecastES.mq5 foi desenvolvido. Para reamostragem, foi utilizado o gerador de seqüência pseudo-aleatória proposto anteriormente no artigo [11]. O gerador padrão MathRand() rendeu resultados ligeiramente mais pobres, provavelmente devido ao fato de que o intervalo de valores que gerou [0,32767] não era amplo o suficiente.
Quando compilar o indicador ForecastES.mq5, PowellsMethod.mqh, CForeES.mqh e RNDXor128.mqh devem estar localizados no mesmo diretório que ele. Todos esses arquivos podem ser encontrados no arquivo fore.zip.
Abaixo está o código-fonte do indicador ForecastES.mq5.
//+------------------------------------------------------------------+ //| ForecastES.mq5 | //| Copyright 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg." #property link "https://www.mql5.com" #property version "1.02" #property description "Forecasting based on the exponential smoothing." #property indicator_chart_window #property indicator_buffers 4 #property indicator_plots 4 #property indicator_label1 "History" #property indicator_type1 DRAW_LINE #property indicator_color1 clrDodgerBlue #property indicator_style1 STYLE_SOLID #property indicator_width1 1 #property indicator_label2 "Forecast" // Forecast #property indicator_type2 DRAW_LINE #property indicator_color2 clrDarkOrange #property indicator_style2 STYLE_SOLID #property indicator_width2 1 #property indicator_label3 "ConfUp" // Confidence interval #property indicator_type3 DRAW_LINE #property indicator_color3 clrCrimson #property indicator_style3 STYLE_DOT #property indicator_width3 1 #property indicator_label4 "ConfDn" // Confidence interval #property indicator_type4 DRAW_LINE #property indicator_color4 clrCrimson #property indicator_style4 STYLE_DOT #property indicator_width4 1 input int nHist=80; // History bars, nHist>=24 #include "CForeES.mqh" #include "RNDXor128.mqh" #define NFORE 12 #define NBOOT 9999 double Hist[],Fore[],Conf1[],Conf2[]; double Data[],Err[],BSDat[],Damp[NFORE],BSErr[NBOOT]; int NDat; CForeES Es; RNDXor128 Rnd; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { NDat=nHist; if(NDat<24)NDat=24; MqlRates rates[]; CopyRates(NULL,0,0,NDat,rates); // Load missing data ArrayResize(Data,NDat); ArrayResize(Err,NDat); ArrayResize(BSDat,NBOOT+NFORE); SetIndexBuffer(0,Hist,INDICATOR_DATA); PlotIndexSetString(0,PLOT_LABEL,"History"); SetIndexBuffer(1,Fore,INDICATOR_DATA); PlotIndexSetString(1,PLOT_LABEL,"Forecast"); PlotIndexSetInteger(1,PLOT_SHIFT,NFORE); SetIndexBuffer(2,Conf1,INDICATOR_DATA); // Confidence interval PlotIndexSetString(2,PLOT_LABEL,"ConfUp"); PlotIndexSetInteger(2,PLOT_SHIFT,NFORE); SetIndexBuffer(3,Conf2,INDICATOR_DATA); // Confidence interval PlotIndexSetString(3,PLOT_LABEL,"ConfDN"); PlotIndexSetInteger(3,PLOT_SHIFT,NFORE); IndicatorSetInteger(INDICATOR_DIGITS,_Digits); return(0); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { int i,j,k,start; double s,t,alp,gam,phi,sb,sg,e,f,a,a1,a2; if(rates_total<NDat){Print("Error: Not enough bars for calculation!"); return(0);} if(prev_calculated==rates_total)return(rates_total); // New tick but not new bar start=rates_total-NDat; //----------------------- PlotIndexSetInteger(0,PLOT_DRAW_BEGIN,rates_total-NDat); PlotIndexSetInteger(1,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(2,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(3,PLOT_DRAW_BEGIN,rates_total-NFORE); for(i=0;i<NDat;i++)Data[i]=open[rates_total-NDat+i]; // Input data Es.CalcPar(Data); // Optimization of parameters s=Es.GetPar(0); t=Es.GetPar(1); gam=Es.GetPar(2); phi=Es.GetPar(3); sb=Es.GetPar(4); sg=Es.GetPar(5); //---- a=phi; Damp[0]=phi; for(j=1;j<NFORE;j++){a=a*phi; Damp[j]=Damp[j-1]+a;} // Phi table //---- f=s+phi*t; for(i=0;i<NDat;i++) // History { e=Data[i]-f; Err[i]=e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); Hist[start+i]=f; // History } for(j=0;j<NFORE;j++)Fore[rates_total-NFORE+j]=s+Damp[j]*t; // Forecast //---- a=0; for(i=0;i<NDat;i++)a+=Err[i]; a/=NDat; for(i=0;i<NDat;i++)Err[i]-=a; // alignment of the array of errors //---- f=Es.GetPar(0)+phi*Es.GetPar(1); for(i=0;i<NBOOT+NFORE;i++) // Resampling { j=(int)(NDat*Rnd.Rand_01()); if(j>NDat-1)j=NDat-1; e=Err[j]; BSDat[i]=f+e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=s+phi*t; } //---- for(j=0;j<NFORE;j++) // Prediction intervals { s=Es.GetPar(0); t=Es.GetPar(1); f=s+phi*t; for(i=0,k=0;i<NBOOT;i++,k++) { BSErr[i]=BSDat[i+j]-(s+Damp[j]*t); e=BSDat[i]-f; a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); } ArraySort(BSErr); Conf1[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[249]; Conf2[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[9749]; } return(rates_total); } //-----------------------------------------------------------------------------------
Para fins de demonstração melhores, o indicador foi executado, na medida do possível, como um código linear. Nenhuma otimização foi pretendida durante a codificação.
Figuras 1 e 2 mostram os resultados de operação do indicador para dois casos diferentes.

Figura 1. Primeiro exemplo de operação do indicador ForecastES.mq5

Figura 2. Segundo exemplo de operação do indicador ForecastES.mq5
A Figura 2 mostra claramente que o 95% de intervalo de confiança é assimétrico. Isto é devido ao fato de a sequência de entrada conter valores aberrantes consideráveis que resultaram na distribuição assimétrica dos erros de previsão.
Sites www.mql4.com e www.mql5.com anteriormente forneceram indicadores extrapoladores. Vamos pegar um desses - ar_extrapolator_of_price.mq5 e definir seus valores de parâmetros como mostrado na Figura 3 para comparar seus resultados com os resultados obtidos utilizando o indicador que desenvolvemos.

Figura 3. Configurações do indicador ar_extrapolator_of_price.mq5
A operação destes dois indicadores foi comparada visualmente em prazos diferentes para o EURUSD e USDCHF. Superficialmente, parece que a direção da previsão de ambos os indicadores coincide na maioria dos casos. No entanto, em observações mais longas, pode-se deparar com divergências graves. Dito isto, ar_extrapolator_of_price.mq5 sempre produzirá uma linha de previsão mais quebrada.
Um exemplo de operação simultânea de ForecastES.mq5 e indicadores ar_extrapolator_of_price.mq5 é mostrado na Figura 4.

Figura 4. Comparação dos resultados de previsão
A previsão produzida pelo indicador ar_extrapolator_of_price.mq5 é apresentada na Figura 4 como uma linha sólida vermelho alaranjado.
Conclusão
Resumo dos resultados referentes à este e ao artigo anterior:
- Modelos de suavização exponencial utilizados na previsão de séries temporais foram introduzidas;
- Foram propostas soluções de programação para implementação dos modelos;
- Uma visão rápida foi dada sobre questões relacionadas à seleção dos valores iniciais ideais e parâmetros do modelo;
- A implementação de programação do algoritmo para encontrar o mínimo de uma função de diversas variáveis, utilizando o método de Powell foi fornecida;
- Foram propostas soluções de programação para otimização de parâmetros do modelo de previsão usando a sequência de entrada;
- Alguns exemplos simples de atualizar o algoritmo de previsão foram demonstrados;
- Um método para estimar intervalos de confiança de previsão usando auto inicialização e quantis foi brevemente descrito;
- O indicador de previsão ForecastES.mq5 foi desenvolvido contendo todos os métodos e algoritmos descritos nos artigos;
- Alguns links para artigos, revistas e livros foram dados referentes a este assunto.
No que diz respeito ao indicador resultante ForecastES.mq5, deve se notar que o algoritmo de otimização empregando o método de Powell pode, em certos casos, não conseguir determinar o mínimo da função objetiva com uma determinada precisão. Sendo este o caso, o número máximo permitido de interações será alcançado e uma mensagem relevante aparecerá no log. Esta situação, porém, não é processada de qualquer forma no código do indicador, que é bastante aceitável para demonstração dos algoritmos estabelecidos no artigo. No entanto, quando se trata de aplicações sérias, tais casos devem ser monitorados e processados de uma forma ou de outra.
Para desenvolver ainda mais e melhorar o indicador de previsão, podemos sugerir o uso de vários modelos de previsão diferentes simultaneamente em cada passo, tendo em vista uma maior seleção de um deles usando por exemplo, o Critério de Informação de Akaike. Ou, no caso da utilização de vários modelos similares por natureza, para calcular o valor médio ponderado dos seus resultados de previsão. Os coeficientes de ponderação neste caso, podem ser selecionados dependendo do coeficiente de erro de previsão de cada um dos modelos.
O tema da previsão de séries temporais é tão amplo que, infelizmente, esses artigos tem apenas arranhado a superfície de algumas das questões pertinentes. Espera-se que estas publicações ajudem a chamar a atenção do leitor para as questões de previsão e de futuros trabalhos nesta área.
Referências
- "Time Series Forecasting Using Exponential Smoothing" (Previsão de séries temporais utilizando suavização exponencial, em tradução livre).
- Yu. P. Lukashin. Métodos favoráveis à adaptação para previsão de curto prazo de séries temporais: Textbook. - М.: Finansy i Statistika, 2003.-416 pp.
- S.V. Bulashev. Estatística para negociadores. - М.: Kompania Sputnik +, 2003. - 245 pp.
- Everette S. Gardner Jr., Exponential Smoothing: The State of the Art – Part II. 3 de Junho, 2005.
- James W. Taylor, Smooth Transition Exponential Smoothing. Journal of Forecasting, 2004, Vol. 23, pp. 385-394.
- James W. Taylor, Volatility Forecasting with Smooth Transition Exponential Smoothing. International Journal of Forecasting, 2004, Vol. 20, pp. 273-286.
- Alysha M De Livera. Automatic Forecasting with a Modified Exponential Smoothing State Space Framework. 28 April 2010, Department of Econometrics and Business Statistics, Monash University, VIC 3800 Australia.
- Rob J Hyndman et al. Prediction Intervals for Exponential Smoothing Using Two New Classes of State Space Models. 30 de Janeiro 2003.
- The Quantile Journal. issue No. 3, September 2007.
- http://ru.wikipedia.org/wiki/Квантиль
- "Analysis of the Main Characteristics of Time Series".
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/346
 Criando Expert Advisors usando o assistente visual Expert Advisor
Criando Expert Advisors usando o assistente visual Expert Advisor
 Usando a Análise Discriminante para Desenvolver Sistemas de Negociação
Usando a Análise Discriminante para Desenvolver Sistemas de Negociação
 Trademinator 3: ascensão das máquinas comerciais
Trademinator 3: ascensão das máquinas comerciais
 Analisando os parâmetros estatísticos dos indicadores
Analisando os parâmetros estatísticos dos indicadores
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso