
Previsione delle serie temporali mediante livellamento esponenziale (parte 2)

Introduzione
L'articolo "Previsione di serie temporali mediante livellamento esponenziale" [1] ha fornito un breve riassunto dei modelli di livellamento esponenziale, ha illustrato uno dei possibili approcci per ottimizzare i parametri del modello e infine ha proposto l'indicatore previsionale sviluppato sulla base del modello di crescita lineare con smorzamento. Questo articolo rappresenta un tentativo di aumentare in qualche modo l'accuratezza di questo indicatore di previsione.
È complicato prevedere le quotazioni valutarie o ottenere una previsione abbastanza affidabile anche per tre o quattro passi avanti. Tuttavia, come nel precedente articolo di questa serie, produrremo previsioni a 12 passi avanti, rendendoci chiaramente conto che sarà impossibile ottenere risultati soddisfacenti su un orizzonte così lungo. I primi passi della previsione con gli intervalli di confidenza più stretti dovrebbero quindi avere la massima attenzione.
Una previsione da 10 a 12 passi avanti è destinata principalmente alla dimostrazione delle caratteristiche comportamentali di diversi modelli e metodi di previsione. In ogni caso, l'accuratezza della previsione ottenuta per qualsiasi orizzonte può essere valutata utilizzando i limiti dell'intervallo di confidenza. Questo articolo ha essenzialmente lo scopo di dimostrare alcuni metodi che possono aiutare ad aggiornare l'indicatore come indicato nell'articolo [1].
L'algoritmo per trovare il minimo di una funzione di più variabili che viene applicato nello sviluppo degli indicatori è stato trattato nell'articolo precedente e quindi non sarà ripetutamente descritto qui. Per non sovraccaricare l'articolo, gli input teorici saranno mantenuti al minimo.
1. Indicatore iniziale
L'indicatore IndicatorES.mq5 (vedi articolo [1]) sarà utilizzato come punto di partenza.
Per la compilazione dell'indicatore avremo bisogno di IndicatorES.mq5, CIndicatorES.mqh e PowellsMethod.mqh, tutti situati nella stessa directory. I file possono essere trovati nell'archivio files2.zip alla fine dell'articolo.
Aggiorniamo le equazioni che definiscono il modello di livellamento esponenziale utilizzato nello sviluppo di questo indicatore: il modello di crescita lineare con smorzamento.
![]()
![]()
![]()
Dove:
-
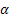 - parametro di livellamento per il livello della sequenza [0,1];
- parametro di livellamento per il livello della sequenza [0,1]; -
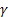 - parametro di livellamento per l'andamento [0,1];
- parametro di livellamento per l'andamento [0,1]; -
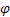 - parametro di smorzamento [0,1];
- parametro di smorzamento [0,1]; -
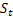 - livello livellato della sequenza calcolato nel momento t dopo che
- livello livellato della sequenza calcolato nel momento t dopo che 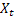 è stato osservato;
è stato osservato; -
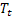 - andamento dell'additivo levigato calcolato al momento t;
- andamento dell'additivo levigato calcolato al momento t; -
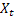 - valore della sequenza al momento t;
- valore della sequenza al momento t;
-
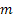 - numero di passi avanti per i quali è fatta la previsione;
- numero di passi avanti per i quali è fatta la previsione; -
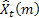 - previsioni m-step-ahead effettuate al momento t;
- previsioni m-step-ahead effettuate al momento t; -
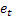 - errore di previsione di un passo avanti al momento t,
- errore di previsione di un passo avanti al momento t, 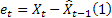 .
.
L'unico parametro di input dell'indicatore è il valore che determina la lunghezza dell'intervallo in base al quale i parametri del modello saranno ottimizzati e i valori iniziali (intervallo di studio) selezionati. Dopo la determinazione dei valori ottimali dei parametri del modello a un determinato intervallo e i calcoli richiesti, vengono prodotti la previsione, l'intervallo di confidenza e la linea corrispondente alla previsione di un passo avanti. Ad ogni nuova barra, i parametri vengono ottimizzati e viene fatta la previsione.
Poiché l'indicatore in questione verrà aggiornato, l'effetto delle modifiche che apporteremo verrà valutato utilizzando le sequenze di test dall'archivio Files2.zip situato alla fine dell'articolo. La directory di archivio \Dataset2 contiene i file con le quotazioni EURUSD, USDCHF, USDJPY salvate e US Indice del dollaro DXY. Ognuno di questi è previsto per tre intervalli di tempo, essendo M1, H1 e D1. I valori "open" salvati nei file si trovano in modo che il valore più recente si trovi alla fine del file. Ogni file contiene 1200 elementi.
Gli errori di previsione saranno stimati calcolando il coefficiente "Mean Absolute Percentage Error" (MAPE)
![]()
Dividiamo ciascuna delle dodici sequenze di test in 50 sezioni sovrapposte contenenti 80 elementi ciascuna e calcoliamo il valore MAPE per ciascuna di esse. La media delle stime così ottenute sarà utilizzata come indice di errore previsionale per quanto riguarda gli indicatori messi a confronto. I valori MAPE per gli errori di previsione a due e tre fasi avanti verranno calcolati nello stesso modo. Tali stime medie saranno ulteriormente indicate come segue:
- MAPE1 – stima media dell'errore di previsione one-step-ahead;
- MAPE2 – stima media dell'errore di previsione a due fasi;
- MAPE3 – stima media dell'errore di previsione a tre fasi;
- MAPE1-3 – media (MAPE1+MAPE2+MAPE3)/3.
Quando si calcola il valore MAPE, il valore di errore di previsione assoluto viene diviso ad ogni passo per il valore corrente della sequenza. Al fine di evitare la divisione per zero o ottenere valori negativi in tal modo, le sequenze di input sono tenute a prendere solo valori positivi diversi da zero, come nel nostro caso.
I valori stimati per il nostro indicatore iniziale sono mostrati nella Tabella 1.
| MAPE1 | MAPE2 | MAPE3 | MAPE1-3 | |
|---|---|---|---|---|
| IndicatorES | 0,2099 | 0,2925 | 0,3564 | 0,2863 |
Tabella 1. Stime iniziali degli errori di previsione dell'indicatore
I dati visualizzati nella Tabella 1 sono ottenuti utilizzando lo script Errors_IndicatorES.mq5 (dall'archivio files2.zip situato alla fine dell'articolo). Per compilare ed eseguire lo script, è necessario che CIndicatorES.mqh e PowellsMethod.mqh si trovino nella stessa directory di Errors_IndicatorES.mq5 e che le sequenze di input si trovino nella directory Files\Dataset2\.
Dopo aver ottenuto le stime iniziali degli errori di previsione, possiamo ora procedere all'aggiornamento dell'indicatore in esame.
2. Criterio di ottimizzazione
I parametri del modello nell'indicatore iniziale come indicato nell'articolo "Previsione di serie temporali mediante livellamento esponenziale" sono stati determinati riducendo al minimo la somma dei quadrati dell'errore di previsione one-step-ahead. Sembra logico che i parametri del modello ottimali per una previsione one-step-ahead potrebbero non produrre errori minimi per una previsione più step-ahead. Naturalmente, sarebbe auspicabile ridurre al minimo gli errori di previsione da 10 a 12 step-ahead, ma ottenere un risultato di previsione soddisfacente nell'intervallo dato per le sequenze in esame sarebbe una missione impossibile.
Essendo realistici, quando ottimizziamo i parametri del modello, utilizzeremo la somma dei quadrati degli errori di previsione di uno, due e tre passi avanti come primo aggiornamento del nostro indicatore. Ci si può aspettare che il numero medio di errori diminuisca leggermente nell'intervallo delle prime tre fasi della previsione.
Chiaramente, tale aggiornamento dell'indicatore iniziale non riguarda i suoi principali principi strutturali, ma cambia solo il criterio di ottimizzazione dei parametri. Pertanto, non possiamo aspettarci che l'accuratezza delle previsioni aumenti di diverse volte, anche se il numero di errori di previsione a due e tre passi avanti dovrebbe diminuire leggermente.
Per confrontare i risultati delle previsioni, abbiamo creato la classe CMod1 simile alla classe CIndicatorES introdotta nell'articolo precedente con la funzione obiettivo modificata func.
La funzione func della classe CIndicatorES iniziale:
double CIndicatorES::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,sse,ae,pt; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95;} // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 sse=0; for(i=0;i<Dlen;i++) { e=Dat[i]-(s+phi*t); sse+=e*e; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } return(Dlen*MathLog(k1*k2*k3*sse)); }
A seguito di alcune modifiche, la funzione func appare ora come segue
double CMod1::func(const double &p[]) { int i; double s,t,alp,gam,phi,k1,k2,k3,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; alp=p[2]; gam=p[3]; phi=p[4]; k1=1; k2=1; k3=1; if (alp>0.95){k1+=(alp-0.95)*200; alp=0.95; // Alpha > 0.95 else if(alp<0.05){k1+=(0.05-alp)*200; alp=0.05;} // Alpha < 0.05 if (gam>0.95){k2+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k2+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k3+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k3+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*k3*err); }
Ora, quando si calcola la funzione obiettivo, viene utilizzata la somma dei quadrati degli errori di previsione di uno, due e tre passi avanti.
Inoltre, sulla base di questa classe è stato sviluppato lo script Errors_Mod1.mq5 che consente di stimare gli errori di previsione, come fa lo script Errors_IndicatorES.mq5 già menzionato. CMod1.mqh e Errors_Mod1.mq5 si trovano nell'archivio files2.zip alla fine dell'articolo.
Nella tabella 2 vengono visualizzate le stime degli errori di previsione per le versioni iniziale e aggiornata.
| MAPE1 | MAPE2 | MAPE3 | MAPE1-3 | |
|---|---|---|---|---|
| IndicatorES | 0,2099 | 0,2925 | 0,3564 | 0,2863 |
| Mod1 | 0,2144 | 0,2898 | 0,3486 | 0,2842 |
Tabella 2. Confronto delle stime degli errori di previsione
Come si può vedere, i coefficienti di errore MAPE2 e MAPE3 e il valore medio MAPE1-3 in realtà si sono rivelati leggermente inferiori per le sequenze in esame. Quindi salviamo questa versione e procediamo a ulteriori modifiche del nostro indicatore.
3. Regolazione dei parametri nel processo di livellamento
L'idea di modificare i parametri di livellamento a seconda dei valori correnti della sequenza di input non è nuova o originale e nasce dal desiderio di regolare i coefficienti di livellamento in modo che rimangano ottimali dato qualsiasi cambiamento nella natura della sequenza di input. Alcuni modi per regolare i coefficienti di livellamento sono descritti dalla letteratura [2], [3].
Per aggiornare ulteriormente l'indicatore, utilizzeremo il modello con coefficiente di livellamento che cambia dinamicamente, aspettandoci che l'uso del modello di livellamento esponenziale adattivo ci consentirà di aumentare l'accuratezza delle previsioni del nostro indicatore.
Sfortunatamente, se utilizzati negli algoritmi di previsione, la maggior parte dei metodi adattivi non sempre produce i risultati desiderati. La selezione del metodo adattivo adeguato può sembrare troppo ingombrante e dispendiosa in termini di tempo; pertanto, nel nostro caso faremo uso dei risultati forniti dalla letteratura [4] e cercheremo di utilizzare l'approccio "Smooth Transition Exponential Smoothing" (STES) esposto nell'articolo [5].
L'essenza dell'approccio è chiaramente delineata nell'articolo specificato, quindi lo lasceremo fuori qui e procederemo direttamente alle equazioni per il nostro modello (vedi l'inizio dell'articolo specificato), prendendo in considerazione l'uso del coefficiente di livellamento adattivo.
![]()
![]()
![]()
![]()
Come possiamo vedere, il valore del coefficiente di livellamento alfa viene calcolato in ogni fase dell'algoritmo e dipende dall'errore di previsione al quadrato. I valori dei coefficienti b e g determinano l'effetto dell'errore di previsione sul valore alfa. Sotto tutti gli altri aspetti, le equazioni per il modello impiegato sono rimaste invariate. Ulteriori informazioni sull'uso dell'approccio STES sono disponibili nell'articolo [6].
Mentre nelle versioni precedenti, dovevamo determinare il valore ottimale del coefficiente alfa sulla sequenza di dati di input, ora ci sono due coefficienti adattivi b e g che sono soggetti a ottimizzazione e il valore alfa sarà determinato dinamicamente nel processo di livellamento della sequenza di input.
Questo aggiornamento viene implementato sotto forma di classe CMod2. I principali cambiamenti (come la volta precedente) hanno riguardato principalmente la funzione func che ora appare come segue.
double CMod2::func(const double &p[]) { int i; double s,t,alp,gam,phi,sb,sg,k1,k2,e,err,ae,pt,phi2,phi3,a; s=p[0]; t=p[1]; gam=p[2]; phi=p[3]; sb=p[4]; sg=p[5]; k1=1; k2=1; if (gam>0.95){k1+=(gam-0.95)*200; gam=0.95;} // Gamma > 0.95 else if(gam<0.05){k1+=(0.05-gam)*200; gam=0.05;} // Gamma < 0.05 if (phi>1.0 ){k2+=(phi-1.0 )*200; phi=1.0; } // Phi > 1.0 else if(phi<0.05){k2+=(0.05-phi)*200; phi=0.05;} // Phi < 0.05 phi2=phi+phi*phi; phi3=phi2+phi*phi*phi; err=0; for(i=0;i<Dlen-2;i++) { e=Dat[i]-(s+phi*t); err+=e*e; a=Dat[i+1]-(s+phi2*t); err+=a*a; a=Dat[i+2]-(s+phi3*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; } e=Dat[Dlen-2]-(s+phi*t); err+=e*e; a=Dat[Dlen-1]-(s+phi2*t); err+=a*a; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 ae=alp*e; pt=phi*t; s=s+pt+ae; t=pt+gam*ae; a=Dat[Dlen-1]-(s+phi*t); err+=a*a; return(k1*k2*err); }
Durante lo sviluppo di questa funzione, l'equazione che definisce il valore del coefficiente alfa è stata leggermente modificata. Questo è stato fatto per fissare il limite del valore massimo e minimo ammissibile di questo coefficiente a 0,05 e 0,95, rispettivamente.
Per stimare gli errori di previsione, come è stato fatto in precedenza, lo script Errors_Mod2.mq5 è stato scritto in base alla classe CMod2. CMod2.mqh e Errors_Mod2.mq5 si trovano nell'archivio files2.zip alla fine dell'articolo.
I risultati dello script sono mostrati nella Tabella 3.
| MAPE1 | MAPE2 | MAPE3 | MAPE1-3 | |
|---|---|---|---|---|
| IndicatorES | 0,2099 | 0,2925 | 0,3564 | 0,2863 |
| Mod1 | 0,2144 | 0,2898 | 0,3486 | 0,2842 |
| Mod2 | 0,2145 | 0,2832 | 0,3413 | 0,2797 |
Tabella 3. Confronto delle stime degli errori di previsione
Come suggerisce la Tabella 3, l'uso del coefficiente di livellamento adattivo ha in media permesso di ridurre ulteriormente gli errori di previsione per le nostre sequenze di test. Pertanto, a seguito di due aggiornamenti, siamo riusciti a ridurre il coefficiente di errore MAPE1-3 di circa il due percento.
Nonostante un risultato di aggiornamento piuttosto modesto, ci atterremo alla versione risultante e lasceremo ulteriori aggiornamenti fuori dallo scopo dell'articolo. Come passo successivo, sarebbe interessante provare a utilizzare la trasformazione Box-Cox. Questa trasformazione viene utilizzata principalmente per approssimare la distribuzione iniziale della sequenza alla distribuzione normale.
Nel nostro caso, potrebbe essere utilizzato per trasformare la sequenza iniziale, calcolare la previsione e trasformare inversamente la previsione. Il coefficiente di trasformazione applicato in tal modo deve essere selezionato in modo che l'errore di previsione risultante sia ridotto al minimo. Un esempio di utilizzo della trasformazione Box-Cox nelle sequenze di previsione può essere trovato nell'articolo [7].
4. Intervallo di confidenza previsto
L'intervallo di confidenza previsto nell'indicatore iniziale IndicatorES.mq5 (indicato nell'articolo precedente) è stato calcolato in base alle espressioni analitiche derivate per il modello di livellamento esponenziale selezionato [8]. Le modifiche apportate, nel nostro caso, hanno portato a cambiamenti nel modello in esame. Il coefficiente di livellamento variabile rende inappropriato l'uso delle espressioni analitiche sopra menzionate per la stima dell'intervallo di confidenza.
Il fatto che le espressioni analitiche utilizzate in precedenza siano state derivate sulla base dell'ipotesi che la distribuzione degli errori di previsione sia simmetrica e normale può costituire un ulteriore motivo per modificare il metodo di stima dell'intervallo di confidenza. Questi requisiti non sono soddisfatti per la nostra classe di sequenze e la distribuzione degli errori di previsione potrebbe non essere normale né simmetrica.
Quando si stima l'intervallo di confidenza nell'indicatore iniziale, la varianza dell'errore di previsione di un passo avanti è stata calcolata in primo luogo dalla sequenza di input, seguita dal calcolo della varianza per una previsione a due, tre e più passi avanti sulla base del valore di varianza dell'errore di previsione di un passo avanti ottenuto utilizzando le espressioni analitiche.
Al fine di evitare l'uso di espressioni analitiche, esiste una semplice via d'uscita in base alla quale la varianza per una previsione a due, tre e più passi avanti viene calcolata direttamente dalla sequenza di input e dalla varianza per una previsione di un passo avanti. Tuttavia, questo approccio presenta uno svantaggio significativo: in brevi sequenze di input, le stime dell'intervallo di confidenza saranno ampiamente disperse e il calcolo della varianza e dell'errore medio al quadrato non consentirà di alleviare i vincoli sulla normalità prevista degli errori.
Una soluzione in questo caso può essere trovata nell'uso di bootstrap non parametrico (ricampionamento) [9]. Questo è il fulcro dell'idea in parole semplici: quando si campiona in modo casuale (distribuzione uniforme) con sostituzione dalla sequenza iniziale, la distribuzione della sequenza artificiale così generata sarà la stessa di quella iniziale.
Supponiamo di avere una sequenza di input di N membri; generando una sequenza pseudo-casuale uniformemente distribuita nell'intervallo di [0,N-1] e usando questi valori come indici durante il campionamento dall'array iniziale, possiamo generare una sequenza artificiale di lunghezza sostanzialmente maggiore di quella iniziale. Detto questo, la distribuzione della sequenza generata sarà la stessa (quasi la stessa) di quella iniziale.
La procedura di bootstrap per la stima degli intervalli di confidenza può essere la seguente:
- Determinare i valori iniziali ottimali dei parametri del modello, i suoi coefficienti e coefficienti adattivi dalla sequenza di input per il modello di livellamento esponenziale ottenuto a seguito di modifica. I parametri ottimali sono, come prima, determinati utilizzando l'algoritmo che impiega il metodo di ricerca di Powell;
- Utilizzando i parametri ottimali del modello determinati, "passa" attraverso la sequenza iniziale e forma un array di errori di previsione one-step-ahead. Il numero degli elementi dell'array sarà uguale alla lunghezza della sequenza di input N;
- Allinea gli errori sottraendo da ciascun elemento dell’array di errori il valore medio dello stesso;
- Usando il generatore di sequenze pseudo-casuali, genera indici nell'intervallo di [0,N-1] e usali per formare una sequenza artificiale di errori lunga 9999 elementi (ricampionamento);
- Forma un array contenente 9999 valori della sequenza di pseudo-input inserendo i valori dell’array di errori generato artificialmente nelle equazioni che definiscono il modello attualmente utilizzato. In altre parole, mentre prima dovevamo inserire i valori della sequenza di input nelle equazioni del modello calcolando così l'errore di previsione, ora vengono effettuati i calcoli inversi. Per ogni elemento dell’array, viene inserito il valore di errore per calcolare il valore di input. Di conseguenza, otteniamo l’array di 9999 elementi contenenti la sequenza con la stessa distribuzione della sequenza di input, pur essendo di lunghezza sufficiente per stimare direttamente gli intervalli di confidenza previsti.
Quindi, stima gli intervalli di confidenza utilizzando la sequenza generata di lunghezza adeguata. A tal fine, sfrutteremo il fatto che se l'array di errori di previsione generato è ordinato in ordine crescente, le celle di array con indici 249 e 9749 per l'array contenente valori 9999 avranno i valori corrispondenti ai limiti dell'intervallo di confidenza del 95% [10].
Al fine di ottenere una stima più accurata degli intervalli di previsione, la lunghezza dell’array deve essere dispari. Nel nostro caso, i limiti degli intervalli di confidenza previsti sono stimati come segue:
- Utilizzando i parametri ottimali del modello come determinato in precedenza, "passa" attraverso la sequenza generata e forma un array di 9999 errori di previsione one-step-ahead;
- Ordina l’array risultante;
- Dall’array di errori ordinati, seleziona i valori con gli indici 249 e 9749 che rappresentano i limiti dell'intervallo di confidenza del 95%;
- Ripeti i passaggi 1, 2 e 3 per gli errori di previsione a due, tre e più passaggi avanti.
Questo approccio alla stima degli intervalli di confidenza presenta i suoi vantaggi e svantaggi.
Tra i suoi vantaggi c'è l'assenza di ipotesi riguardanti la natura della distribuzione degli errori di previsione. Non devono essere distribuiti normalmente o simmetricamente. Inoltre, questo approccio può essere utile laddove è impossibile derivare espressioni analitiche per il modello in uso.
Un drammatico aumento della portata richiesta dei calcoli e la dipendenza delle stime dalla qualità del generatore di sequenze pseudo-casuali utilizzato possono essere considerati i suoi svantaggi.
L'approccio proposto per stimare gli intervalli di confidenza utilizzando il ricampionamento e i quantili è piuttosto primitivo e ci devono essere modi per migliorarlo. Ma poiché gli intervalli di confidenza nel nostro caso sono destinati solo alla valutazione visiva, l'accuratezza fornita dall'approccio di cui sopra può sembrare abbastanza sufficiente.
5. Versione modificata dell'indicatore
Tenendo conto degli aggiornamenti introdotti nell'articolo, è stato sviluppato l'indicatore ForecastES.mq5. Per il ricampionamento, abbiamo usato il generatore di sequenze pseudo-casuali proposto in precedenza nell'articolo [11]. Il generatore standard MathRand() ha prodotto risultati leggermente più scarsi, probabilmente a causa del fatto che l'intervallo di valori generato [0,32767] non era abbastanza ampio.
Quando si compila l'indicatore, ForecastES.mq5, PowellsMethod.mqh, CForeES.mqh e RNDXor128.mqh si trovano insieme ad esso nella stessa directory. Tutti questi file possono essere trovati nell'archivio .zip.
Di seguito è riportato il codice sorgente dell'indicatore ForecastES.mq5.
//+------------------------------------------------------------------+ //| ForecastES.mq5 | //| Copyright 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg." #property link "https://www.mql5.com" #property version "1.02" #property description "Forecasting based on the exponential smoothing." #property indicator_chart_window #property indicator_buffers 4 #property indicator_plots 4 #property indicator_label1 "History" #property indicator_type1 DRAW_LINE #property indicator_color1 clrDodgerBlue #property indicator_style1 STYLE_SOLID #property indicator_width1 1 #property indicator_label2 "Forecast" // Forecast #property indicator_type2 DRAW_LINE #property indicator_color2 clrDarkOrange #property indicator_style2 STYLE_SOLID #property indicator_width2 1 #property indicator_label3 "ConfUp" // Confidence interval #property indicator_type3 DRAW_LINE #property indicator_color3 clrCrimson #property indicator_style3 STYLE_DOT #property indicator_width3 1 #property indicator_label4 "ConfDn" // Confidence interval #property indicator_type4 DRAW_LINE #property indicator_color4 clrCrimson #property indicator_style4 STYLE_DOT #property indicator_width4 1 input int nHist=80; // History bars, nHist>=24 #include "CForeES.mqh" #include "RNDXor128.mqh" #define NFORE 12 #define NBOOT 9999 double Hist[],Fore[],Conf1[],Conf2[]; double Data[],Err[],BSDat[],Damp[NFORE],BSErr[NBOOT]; int NDat; CForeES Es; RNDXor128 Rnd; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { NDat=nHist; if(NDat<24)NDat=24; MqlRates rates[]; CopyRates(NULL,0,0,NDat,rates); // Load missing data ArrayResize(Data,NDat); ArrayResize(Err,NDat); ArrayResize(BSDat,NBOOT+NFORE); SetIndexBuffer(0,Hist,INDICATOR_DATA); PlotIndexSetString(0,PLOT_LABEL,"History"); SetIndexBuffer(1,Fore,INDICATOR_DATA); PlotIndexSetString(1,PLOT_LABEL,"Forecast"); PlotIndexSetInteger(1,PLOT_SHIFT,NFORE); SetIndexBuffer(2,Conf1,INDICATOR_DATA); // Confidence interval PlotIndexSetString(2,PLOT_LABEL,"ConfUp"); PlotIndexSetInteger(2,PLOT_SHIFT,NFORE); SetIndexBuffer(3,Conf2,INDICATOR_DATA); // Confidence interval PlotIndexSetString(3,PLOT_LABEL,"ConfDN"); PlotIndexSetInteger(3,PLOT_SHIFT,NFORE); IndicatorSetInteger(INDICATOR_DIGITS,_Digits); return(0); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { int i,j,k,start; double s,t,alp,gam,phi,sb,sg,e,f,a,a1,a2; if(rates_total<NDat){Print("Error: Not enough bars for calculation!"); return(0);} if(prev_calculated==rates_total)return(rates_total); // New tick but not new bar start=rates_total-NDat; //----------------------- PlotIndexSetInteger(0,PLOT_DRAW_BEGIN,rates_total-NDat); PlotIndexSetInteger(1,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(2,PLOT_DRAW_BEGIN,rates_total-NFORE); PlotIndexSetInteger(3,PLOT_DRAW_BEGIN,rates_total-NFORE); for(i=0;i<NDat;i++)Data[i]=open[rates_total-NDat+i]; // Input data Es.CalcPar(Data); // Optimization of parameters s=Es.GetPar(0); t=Es.GetPar(1); gam=Es.GetPar(2); phi=Es.GetPar(3); sb=Es.GetPar(4); sg=Es.GetPar(5); //---- a=phi; Damp[0]=phi; for(j=1;j<NFORE;j++){a=a*phi; Damp[j]=Damp[j-1]+a;} // Phi table //---- f=s+phi*t; for(i=0;i<NDat;i++) // History { e=Data[i]-f; Err[i]=e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); Hist[start+i]=f; // History } for(j=0;j<NFORE;j++)Fore[rates_total-NFORE+j]=s+Damp[j]*t; // Forecast //---- a=0; for(i=0;i<NDat;i++)a+=Err[i]; a/=NDat; for(i=0;i<NDat;i++)Err[i]-=a; // alignment of the array of errors //---- f=Es.GetPar(0)+phi*Es.GetPar(1); for(i=0;i<NBOOT+NFORE;i++) // Resampling { j=(int)(NDat*Rnd.Rand_01()); if(j>NDat-1)j=NDat-1; e=Err[j]; BSDat[i]=f+e; alp=0.05+0.9/(1+MathExp(sb+sg*e*e)); // 0.05 < Alpha < 0.95 a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=s+phi*t; } //---- for(j=0;j<NFORE;j++) // Prediction intervals { s=Es.GetPar(0); t=Es.GetPar(1); f=s+phi*t; for(i=0,k=0;i<NBOOT;i++,k++) { BSErr[i]=BSDat[i+j]-(s+Damp[j]*t); e=BSDat[i]-f; a1=alp*e; a2=phi*t; s=s+a2+a1; t=a2+gam*a1; f=(s+phi*t); } ArraySort(BSErr); Conf1[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[249]; Conf2[rates_total-NFORE+j]=Fore[rates_total-NFORE+j]+BSErr[9749]; } return(rates_total); } //-----------------------------------------------------------------------------------
Per una migliore dimostrazione, l'indicatore è stato eseguito, per quanto possibile, come un codice in linea retta. Nessuna ottimizzazione era prevista durante la codifica.
Le figure 1 e 2 illustrano i risultati operativi dell'indicatore per due casi diversi.

Figura 1. Primo esempio di operazione dell'indicatore ForecastES.mq5

Figura 2. Secondo esempio di operazione dell'indicatore ForecastES.mq5
La figura 2 mostra chiaramente che l'intervallo di confidenza previsto del 95% è asimmetrico. Ciò è dovuto al fatto che la sequenza di input contiene notevoli valori anomali, i quali hanno portato a una distribuzione asimmetrica degli errori di previsione.
I siti www.mql4.com e www.mql5.com in precedenza hanno fornito indicatori di estrapolazione. Prendiamo uno di questi - ar_extrapolator_of_price.mq5 e impostiamo i suoi valori di parametro come mostrato nella Figura 3 per confrontare i suoi risultati con i risultati ottenuti utilizzando l'indicatore che abbiamo sviluppato.

Figure 3. Impostazioni dell'indicatore ar_extrapolator_of_price.mq5
Il funzionamento di questi due indicatori è stato confrontato visivamente su diversi intervalli di tempo per EURUSD e USDCHF. In superficie, sembra che la direzione della previsione da parte di entrambi gli indicatori coincida nella maggior parte dei casi. Tuttavia, nelle osservazioni più lunghe, si possono imbattere in gravi divergenze. Detto questo, ar_extrapolator_of_price.mq5 produrrà sempre una linea di previsione più spezzata.
Un esempio di funzionamento simultaneo degli indicatori ForecastES.mq5 e ar_extrapolator_of_price.mq5 è mostrato nella Figura 4.

Figura 4. Confronto dei risultati delle previsioni
La previsione prodotta dall'indicatore ar_extrapolator_of_price.mq5 è visualizzata nella Figura 4 come una linea rosso-arancio solida.
Conclusione
Riepilogo dei risultati relativi a questo e all'articolo precedente:
- Sono stati introdotti modelli di livellamento esponenziale utilizzati nella previsione di serie temporali;
- Sono state proposte soluzioni di programmazione per l'implementazione dei modelli;
- È stata fornita una rapida panoramica delle questioni relative alla selezione dei valori iniziali ottimali e dei parametri del modello;
- È stata fornita un'implementazione di programmazione dell'algoritmo per trovare il minimo di una funzione di più variabili utilizzando il metodo di Powell;
- Sono state proposte soluzioni di programmazione per l'ottimizzazione dei parametri del modello previsionale utilizzando la sequenza di input;
- Sono stati dimostrati alcuni semplici esempi di aggiornamento dell'algoritmo di previsione;
- È stato brevemente delineato un metodo per stimare gli intervalli di confidenza delle previsioni utilizzando il bootstrap e i quantili;
- È stato sviluppato l'indicatore previsionale ForecastES.mq5 contenente tutti i metodi e gli algoritmi descritti negli articoli;
- Sono stati forniti alcuni link ad articoli, riviste e libri relativi a questo argomento.
Per quanto riguarda l'indicatore risultante ForecastES.mq5, va notato che l'algoritmo di ottimizzazione che utilizza il metodo di Powell può in alcuni casi non riuscire a determinare il minimo della funzione obiettivo con una determinata accuratezza. Stando così le cose, verrà raggiunto il numero massimo consentito di iterazioni e nel registro verrà visualizzato un messaggio pertinente. Questa situazione non viene tuttavia elaborata in alcun modo nel codice dell'indicatore che è abbastanza accettabile per la dimostrazione degli algoritmi esposti nell'articolo. Tuttavia, quando si tratta di domande gravi, tali casi devono essere monitorati e trattati in un modo o nell'altro.
Per sviluppare e migliorare ulteriormente l'indicatore previsionale, potremmo suggerire di utilizzare diversi modelli di previsione contemporaneamente in ogni fase al fine di selezionare ulteriormente uno di essi utilizzando, ad esempio, il criterio di informazione di Akaike. O in caso di utilizzo di più modelli simili in natura, per calcolare il valore medio ponderato dei loro risultati previsionali. I coefficienti di ponderazione in questo caso possono essere selezionati in base al coefficiente di errore previsionale di ciascun modello.
L'argomento delle serie temporali di previsione è così ampio che sfortunatamente questi articoli hanno appena scalfito la superficie di alcune delle questioni pertinenti. Si spera che queste pubblicazioni contribuiscano ad attirare l'attenzione del lettore sulle questioni delle previsioni e dei lavori futuri in questo settore.
Fonti
- "Previsione di serie temporali mediante livellamento esponenziale".
- Yu. P. Lukashin. Adaptive Methods for Short-Term Forecasting of Time Series: Textbook. - М.: Finansy i Statistika, 2003.-416 pp.
- S.V. Bulashev. Statistics for Traders. - М.: Kompania Sputnik +, 2003. - 245 pp.
- Everette S. Gardner Jr., Exponential Smoothing: The State of the Art – Part II. June 3, 2005.
- James W. Taylor, Smooth Transition Exponential Smoothing. Journal of Forecasting, 2004, Vol. 23, pp. 385-394.
- James W. Taylor, Volatility Forecasting with Smooth Transition Exponential Smoothing. International Journal of Forecasting, 2004, Vol. 20, pp. 273-286.
- Alysha M De Livera. Automatic Forecasting with a Modified Exponential Smoothing State Space Framework. 28 April 2010, Department of Econometrics and Business Statistics, Monash University, VIC 3800 Australia.
- Rob J Hyndman et al. Prediction Intervals for Exponential Smoothing Using Two New Classes of State Space Models. 30 January 2003.
- The Quantile Journal. issue No. 3, September 2007.
- http://ru.wikipedia.org/wiki/Квантиль
- "Analysis of the Main Characteristics of Time Series".
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/346
 Creazione di un Expert Advisor mediante Expert Advisor Visual Wizard
Creazione di un Expert Advisor mediante Expert Advisor Visual Wizard
 Utilizzo dell'analisi discriminante per sviluppare sistemi di trading
Utilizzo dell'analisi discriminante per sviluppare sistemi di trading
 Trademinator 3: Ascesa delle macchine di trading
Trademinator 3: Ascesa delle macchine di trading
 Analisi dei parametri statistici degli indicatori
Analisi dei parametri statistici degli indicatori
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso