
Redes neurais em trading: Transformer contrativo de padrões (Conclusão)

Introdução
O framework Atom-Motif Contrastive Transformer (AMCT) pode ser considerado um sistema capaz de aprimorar a qualidade da previsão de tendências e movimentos do mercado por meio da combinação de dois níveis de análise: objetos elementares e estruturas complexas. A ideia central é que as velas e os padrões formados por eles representam a mesma situação de mercado de formas diferentes. Isso permite alinhar naturalmente essas duas representações durante o treinamento do modelo. A extração de informações adicionais, próprias de representações de níveis distintos, ajuda a aumentar a qualidade das previsões geradas.
Além disso, padrões de mercado semelhantes em gráficos de diferentes intervalos de tempo ou instrumentos geralmente fornecem sinais semelhantes. Por isso, o uso de métodos de aprendizado contrastivo permite identificar padrões-chave e melhorar sua interpretação. E, para identificar com mais precisão os padrões que desempenham um papel importante na definição das tendências de mercado, os desenvolvedores do framework AMCT introduziram um mecanismo de atenção que considera as propriedades, no qual são aplicadas abordagens de atenção cruzada.
A visualização autoral do framework Atom-Motif Contrastive Transformer é apresentada abaixo.
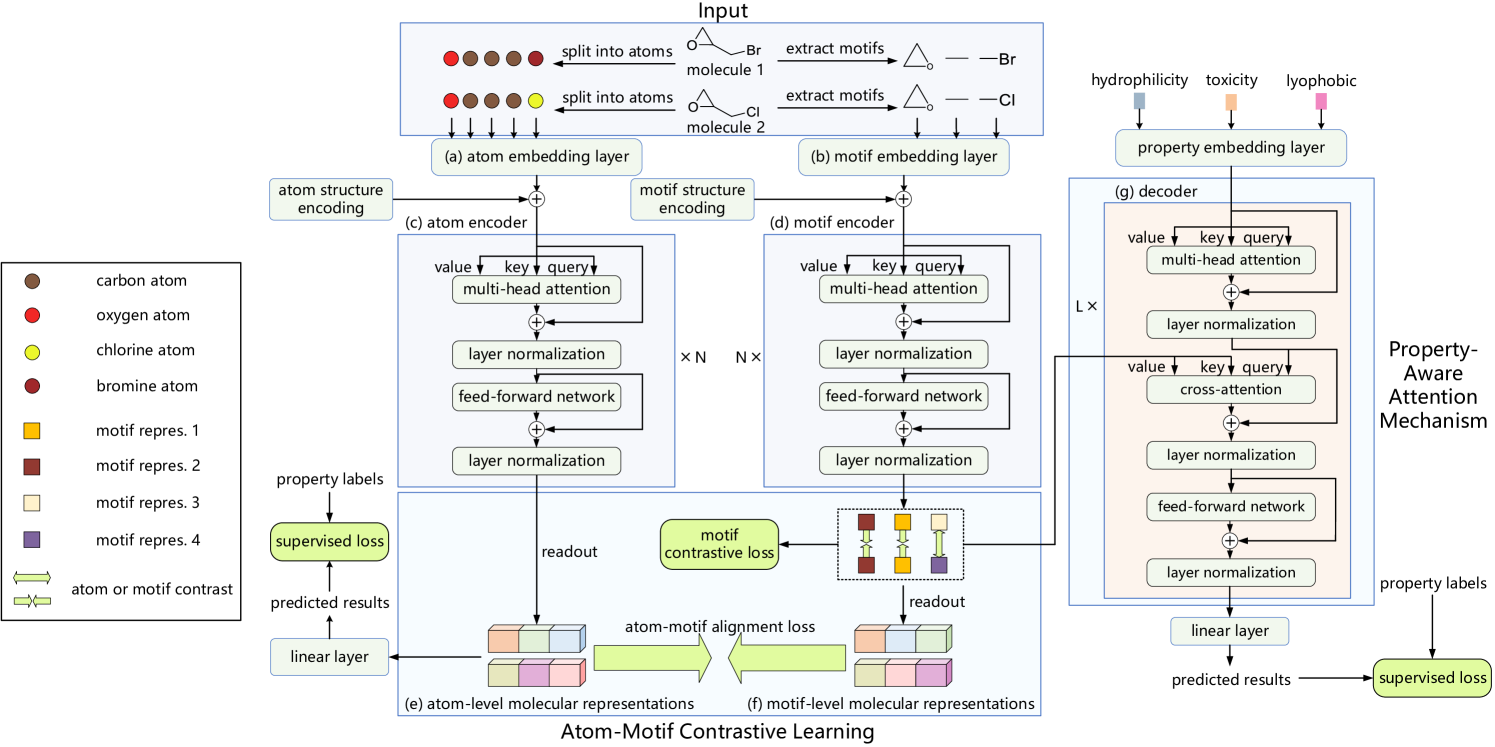
No artigo anterior, discutimos a implementação de velas e padrões, além de termos construído a classe de atenção cruzada relativa, que planejamos usar no módulo de análise das interdependências entre as propriedades das situações de mercado e os padrões de velas. E hoje vamos dar continuidade ao trabalho iniciado.
1. Análise das interdependências entre Propriedades e Motivos
Vamos falar um pouco sobre o módulo de análise das interdependências entre propriedades e motivos. Uma das questões-chave é: o que queremos dizer com "propriedades"? À primeira vista, essa pode parecer uma pergunta simples, mas, na prática, ela se revela bastante complexa. Os autores do framework AMCT utilizaram diferentes propriedades das substâncias que desejavam identificar e analisar nas moléculas. No entanto, como podemos defini-las no contexto das situações de mercado e, além disso, como descrevê-las corretamente?
Vamos tomar como exemplo uma tendência. Na literatura clássica sobre análise técnica de mercados, as tendências geralmente são divididas em três categorias: de alta, de baixa e lateral (consolidação). Mas surge a pergunta: será que essa classificação é suficiente para uma análise mais aprofundada? Como podemos descrever com precisão a dinâmica do movimento de preços e a força da tendência?
Ao tentar selecionar propriedades características de uma situação de mercado no contexto da resolução de tarefas práticas específicas, surgem ainda mais perguntas.
Mas se não temos uma solução aceitável para essa questão, então vamos abordá-la de outra forma. Pediremos para que o modelo aprenda por conta própria as propriedades das situações de mercado presentes no conjunto de treinamento relevantes para resolver a tarefa proposta. Assim como os primitivos linguísticos aprendidos no framework RefMask3D, vamos gerar um tensor de propriedades treinável, pertinente à solução de uma tarefa prática específica. É justamente esse algoritmo que implementamos na classe CNeuronPropertyAwareAttention, cuja estrutura está apresentada abaixo.
class CNeuronPropertyAwareAttention : public CNeuronRMAT { protected: CBufferFloat cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPropertyAwareAttention(void) {}; ~CNeuronPropertyAwareAttention(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronPropertyAwareAttention; } };
Como classe-pai, utilizamos a CNeuronRMAT, na qual está implementado o algoritmo de modelo linear. Como você sabe, os objetos internos da nossa classe-pai estão organizados em um único array dinâmico. Isso nos permite modificar a arquitetura interna que estamos construindo sem precisar declarar novos objetos na estrutura da classe. Basta sobrescrever o método virtual de inicialização do objeto, no qual será criada a sequência necessária de objetos internos. A única limitação é a linearidade da arquitetura.
Infelizmente, a arquitetura de atenção cruzada ultrapassa um pouco os limites da linearidade, já que utiliza 2 fontes de dados brutos. Por isso, somos obrigados a sobrescrever os métodos virtuais de propagação para frente e propagação reversa. Vamos analisar os algoritmos desses métodos sobrescritos.
Nos parâmetros do método de inicialização do novo objeto Init, recebemos constantes que permitem definir de forma inequívoca a arquitetura do objeto que está sendo criado.
bool CNeuronPropertyAwareAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * properties, optimization_type, batch)) return false;
E no corpo do método, chamamos imediatamente o método com o mesmo nome da classe base da camada de neurônio totalmente conectada CNeuronBaseOCL.
Note que, neste caso, estamos chamando o método da camada de neurônio base, e não o da classe-pai direta. Afinal de contas, queremos inicializar apenas as interfaces básicas ao chamarmos esse método. Já a sequência de objetos internos será completamente sobrescrita por nós.
Em seguida, vamos preparar um array dinâmico para registrar os ponteiros dos objetos internos.
cLayers.Clear(); cLayers.SetOpenCL(OpenCL);
E declaramos variáveis locais para armazenar temporariamente os ponteiros dos objetos que serão criados.
CNeuronBaseOCL *neuron=NULL; CNeuronRelativeSelfAttention *self_attention = NULL; CNeuronRelativeCrossAttention *cross_attention = NULL; CResidualConv *ff = NULL;
Com isso, concluímos o trabalho preparatório e partimos para a construção da sequência de objetos internos. Primeiro, criaremos duas camadas totalmente conectadas em sequência para gerar o tensor de incorporação treinável das propriedades que podem caracterizar a situação de mercado.
int idx = 0; neuron = new CNeuronBaseOCL(); if (!neuron || !neuron.Init(window * properties, idx, OpenCL, 1, optimization, iBatch) || !cLayers.Add(neuron)) return false; CBufferFloat *temp = neuron.getOutput(); if (!temp.Fill(1)) return false; idx++; neuron = new CNeuronBaseOCL(); if (!neuron || !neuron.Init(0, idx, OpenCL, window * properties, optimization, iBatch) || !cLayers.Add(neuron)) return false;
Aqui utilizamos abordagens já testadas com sucesso em trabalhos anteriores. A primeira camada contém apenas um neurônio com valor fixo igual a "1". A segunda camada neural gera a sequência de incorporações de que precisamos, e utilizamos a funcionalidade básica do objeto criado para o treinamento dessas incorporações. Adicionamos os ponteiros para ambos os objetos ao nosso array dinâmico, seguindo a ordem em que são chamados.
Em seguida, construiremos a estrutura de um decodificador Transformer quase puro. Apenas substituiremos os módulos de atenção pelos equivalentes com codificação relativa da estrutura da sequência analisada. Para isso, criaremos um laço com número de iterações igual ao número de camadas internas definidas.
for (uint i = 0; i < layers; i++) { idx++; self_attention = new CNeuronRelativeSelfAttention(); if (!self_attention || !self_attention.Init(0, idx, OpenCL, window, window_key, properties, heads, optimization, iBatch) || !cLayers.Add(self_attention) ) { delete self_attention; return false; }
No corpo do laço, começamos criando e inicializando a camada de Self-Attention relativa, que analisa as interdependências entre as incorporações das nossas propriedades treináveis, caracterizando a situação de mercado no contexto da tarefa em questão. Por isso, o comprimento da sequência analisada é definido pelo parâmetro properties. O ponteiro para o objeto criado também é adicionado ao nosso array dinâmico.
Depois disso, criamos a camada de atenção cruzada relativa.
idx++; cross_attention = new CNeuronRelativeCrossAttention(); if (!cross_attention || !cross_attention.Init(0, idx, OpenCL, window, window_key, properties, heads, window, units_count, optimization, iBatch) || !cLayers.Add(cross_attention) ) { delete cross_attention; return false; }
Aqui, como fluxo principal, também utilizamos a informação da incorporação das propriedades, o que, na prática, determina o tamanho do tensor de resultados. Portanto, o comprimento da sequência no bloco FeedForward também será definido de acordo com a quantidade de propriedades geradas.
idx++; ff = new CResidualConv(); if (!ff || !ff.Init(0, idx, OpenCL, window, window, properties, optimization, iBatch) || !cLayers.Add(ff) ) { delete ff; return false;}
}
Adicionamos os ponteiros dos objetos criados ao array dinâmico e avançamos para a próxima iteração do laço.
Após executar com sucesso o número necessário de iterações do laço, nosso array dinâmico conterá todo o conjunto de objetos necessários para implementar corretamente o algoritmo do módulo de análise das interdependências entre as propriedades treináveis e os padrões encontrados. Resta apenas substituir os ponteiros dos buffers de dados, o que reduz significativamente a quantidade de operações no processo de treinamento dos modelos.
if (!SetOutput(ff.getOutput()) || !SetGradient(ff.getGradient())) return false; //--- return true;}
E finalizamos o trabalho do método, retornando o resultado lógico da execução das operações ao programa que o chamou.
Após a inicialização do novo objeto de nossa classe, passamos à construção do algoritmo de propagação para frente, implementado no método feedForward. E aqui é importante observar desde já que, apesar do uso do módulo de atenção cruzada na arquitetura do nosso bloco, o método de propagação para frente recebe apenas um ponteiro para o objeto de dados brutos. Isso acontece porque a segunda fonte de dados brutos ("propriedades") é gerada diretamente pelos objetos da nossa classe.
bool CNeuronPropertyAwareAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
No corpo do método, verificamos imediatamente a validade do ponteiro recebido. Afinal, o objeto obtido será usado como uma fonte adicional de dados. Isso significa que acessaremos diretamente os buffers desse objeto e, no caso de um ponteiro inválido, corremos o risco de gerar um erro crítico.
Declaramos uma variável local para armazenar temporariamente os ponteiros para o objeto.
CNeuronBaseOCL *neuron = NULL;
Observe que declaramos a variável com o tipo base dos nossos neurônios. Vale lembrar que esse tipo é o ancestral comum de todos os nossos objetos de camadas neurais. Isso nos permite armazenar nela o ponteiro para qualquer um dos objetos das camadas neurais internas e utilizar suas interfaces básicas e métodos sobrescritos.
Em seguida, passamos a trabalhar com nosso modelo de geração de incorporações de propriedades. Lembramos que os objetos estão registrados nos dois primeiros elementos do nosso array dinâmico. Como a primeira camada neural contém um valor fixo, passamos diretamente à chamada do método de propagação para frente do segundo objeto, fornecendo como dados brutos o ponteiro do objeto da primeira camada.
if (bTrain) { neuron = cLayers[1]; if (!neuron || !neuron.FeedForward(cLayers[0])) return false; }
No entanto, chamamos o método de propagação para frente da segunda camada apenas durante o treinamento do objeto, pois é nessa fase que analisamos os estados do mercado do conjunto de treinamento em busca das propriedades relevantes para a tarefa definida. Já durante a utilização prática, usaremos as incorporações de propriedades previamente aprendidas, o que significa que o resultado dessa camada será sempre o mesmo. Portanto, não há necessidade de gerar o tensor de incorporações a cada execução. Dessa forma, durante a fase de utilização, omitimos essa etapa, o que nos permite reduzir o tempo de tomada de decisão do modelo.
Em seguida, simplesmente criamos um laço para percorrer as camadas internas restantes, chamando sequencialmente seus métodos de propagação para frente. Como fontes de dados brutos, passamos os resultados da camada anterior e o buffer de resultados do objeto recebido nos parâmetros do método.
for (int i = 2; i < cLayers.Total(); i++) { neuron = cLayers[i]; if (!neuron.FeedForward(cLayers[i - 1], NeuronOCL.getOutput())) return false; } //--- return true; }
É importante observar que a principal fonte de dados brutos é o resultado da camada anterior. É por esse caminho que passam as incorporações das propriedades treináveis das situações de mercado. Elas são analisadas por todos os módulos de atenção e pelo bloco FeedForward do nosso decodificador. As incorporações dos padrões, recebidas nos parâmetros do método e extraídas da descrição da situação de mercado analisada, nos ajudarão a destacar as propriedades relevantes para a situação de mercado atual. Dessa forma, na saída do Decodificador, obtemos mais uma representação da situação de mercado sob a forma de propriedades com ênfases adequadas.
Após executar todas as iterações do nosso laço, finalizamos o método de propagação para frente, retornando previamente o resultado lógico da execução das operações ao programa que o chamou.
Em seguida, vamos trabalhar na organização dos processos de propagação reversa da nossa classe. A implementação do método updateInputWeights, que atualiza os pesos da entrada, não apresenta dificuldades. Aqui, basta chamarmos sequencialmente os métodos de mesmo nome dos objetos internos. No entanto, o método de cálculo e distribuição dos gradientes do erro, calcInputGradients, possui uma particularidade.
Como você sabe, o algoritmo do método de distribuição dos gradientes do erro deve repetir integralmente o fluxo de informação da propagação para frente, só que em ordem reversa, distribuindo o gradiente do erro entre todos os objetos conforme sua contribuição no resultado geral da execução do modelo. E se algum objeto for fonte de dados brutos para vários fluxos de informação, ele deve receber sua parcela do gradiente de erro de cada um deles.
Observe a implementação do método de propagação para frente. Nela, o ponteiro para o objeto de incorporações dos padrões é passado como parâmetro para todas as camadas neurais internas do nosso Decodificador. É claro que os módulos Self-Attention e FeedForward irão simplesmente ignorá-lo, pois não utilizam a segunda fonte de dados brutos. Porém, o módulo de atenção cruzada usará esse ponteiro em cada camada interna do Decodificador. Portanto, no processo de propagação do erro, precisaremos somar a parcela do gradiente do erro proveniente de cada módulo de atenção cruzada no objeto de incorporações dos padrões.
Nos parâmetros do método, recebemos o ponteiro para o objeto que representa=os padrões detectados. E no corpo do método, verificamos imediatamente a validade do ponteiro recebido.
bool CNeuronPropertyAwareAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Depois, realizaremos uma etapa preparatória. Primeiro, verificamos se já existe um buffer auxiliar de dados previamente inicializado, no qual planejamos gravar os valores intermediários dos gradientes do erro. E é fundamental garantirmos que o tamanho desse buffer seja suficiente. Caso o resultado dessa verificação seja negativo, em qualquer ponto de controle, inicializaremos um novo buffer de dados com tamanho adequado.
if (cTemp.GetIndex() < 0 || cTemp.Total() < NeuronOCL.Neurons()) { cTemp.BufferFree(); if (!cTemp.BufferInit(NeuronOCL.Neurons(), 0) || !cTemp.BufferCreate(OpenCL)) return false; }
Em seguida, zeramos o buffer de gradientes de erro do objeto recebido nos parâmetros.
if (!NeuronOCL.getGradient() || !NeuronOCL.getGradient().Fill(0)) return false;
Normalmente, não executamos esse tipo de operação, pois durante a distribuição dos gradientes do erro substituímos os valores anteriormente salvos por novos. E isso é uma boa solução para modelos lineares. Por outro lado, essa implementação nos obriga a buscar alternativas quando precisamos reunir os gradientes de erro vindos de múltiplas vias de informação.
Após concluir com sucesso o trabalho preparatório, fazemos um laço para percorrer os blocos internos do nosso módulo em ordem reversa, com o objetivo de distribuir o gradiente do erro entre eles.
CNeuronBaseOCL *neuron = NULL; for (int i = cLayers.Total() - 2; i > 0; i--) { neuron = cLayers[i]; if (!neuron.calcHiddenGradients(cLayers[i + 1], NeuronOCL.getOutput(), GetPointer(cTemp), (ENUM_ACTIVATION)NeuronOCL.Activation())) return false;
Dentro do laço, chamamos o método de distribuição dos gradientes do erro de cada camada interna, passando os parâmetros correspondentes. Temos que, em vez do buffer de gradientes do erro, passamos o ponteiro para o nosso buffer temporário de armazenamento. Após a execução bem-sucedida do método do objeto interno, verificamos o tipo da camada neural. Afinal, lembramos que nem todas as camadas internas utilizaram a segunda fonte de dados. Quando identificamos um módulo de atenção cruzada, somamos o gradiente do erro referente à segunda fonte de dados aos valores já acumulados no buffer do objeto de incorporações dos padrões.
if (neuron.Type() == defNeuronRelativeCrossAttention) { if (!SumAndNormilize(NeuronOCL.getGradient(), GetPointer(cTemp), NeuronOCL.getGradient(), 1, false, 0, 0, 0, 1)) return false; } //--- return true;}
Depois de completar com sucesso todas as iterações do nosso laço, retornamos ao programa chamador o resultado lógico da execução das operações e encerramos o método.
Com isso, finalizamos o trabalho sobre o bloco de atenção com consideração das propriedades. O código completo dessa classe e de todos os seus métodos está disponível no anexo.
2. Framework AMCT
Realizamos um grande trabalho e implementamos os blocos individuais que compõem o framework Atom-Motif Contrastive Transformer. E chegou o momento de unificar os módulos criados em uma única estrutura. Para isso, vamos criar o objeto CNeuronAMCT, cuja estrutura é apresentada a seguir.
class CNeuronAMCT : public CNeuronBaseOCL { protected: CNeuronRMAT cAtomEncoder; CNeuronMotifEncoder cMotifEncoder; CLayer cMotifProjection; CNeuronPropertyAwareAttention cPropertyDecoder; CLayer cPropertyProjection; CNeuronBaseOCL cConcatenate; CNeuronMHAttentionPooling cPooling; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronAMCT(void) {}; ~CNeuronAMCT(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronAMCT; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Na estrutura apresentada, vemos a declaração dos objetos que implementamos, aos quais se somam dois arrays dinâmicos. Falaremos sobre a funcionalidade deles um pouco mais adiante. Todos os objetos são declarados de forma estática, o que nos permite manter o construtor e o destrutor da classe vazios. A inicialização de todos os objetos herdados e declarados é feita no método Init.
Nos parâmetros do método de inicialização, recebemos as constantes principais que nos permitem definir com precisão a arquitetura do objeto que está sendo criado.
bool CNeuronAMCT::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
E no corpo do método, chamamos imediatamente o método de mesmo nome da classe-pai, passando a ele parte dos parâmetros recebidos.
Como você deve ter notado, não há variáveis internas para armazenar os valores dos parâmetros recebidos na estrutura apresentada do objeto. Todas as constantes que definem a arquitetura da nossa classe serão utilizadas para inicializar os objetos internos, nos quais esses valores serão armazenados. Nos métodos de propagação para frente e propagação reversa, operaremos apenas com os objetos internos. Por isso, não criaremos variáveis desnecessárias.
Em seguida, passamos à inicialização dos objetos internos. E os primeiros que vamos inicializar são os objetos das nossas duas pipelines: velas e padrões.
int idx = 0; if (!cAtomEncoder.Init(0, idx, OpenCL, window, window_key, units_count, heads, layers, optimization, iBatch)) return false; idx++; if (!cMotifEncoder.Init(0, idx, OpenCL, window, window_key, units_count, heads, layers, optimization, iBatch)) return false;
Apesar das diferenças na arquitetura dessas pipelines, ambas trabalharão com a mesma fonte de dados brutos e, neste estágio, receberão parâmetros idênticos.
Na saída das pipelines, esperamos obter duas representações da situação de mercado analisada: uma no nível das velas e outra no nível dos padrões. Os autores do framework propõem compará-las para que possam se enriquecer mutuamente e refinar suas representações. Mas aqui é importante destacar que os tamanhos dos tensores de saída são diferentes nos dois casos. E esse fato, sem dúvida, complica o processo de comparação dos resultados. Por isso, utilizaremos um pequeno modelo de redimensionamento dos dados, que será aplicado aos resultados da pipeline de padrões. Os ponteiros para os objetos do modelo de redimensionamento serão armazenados no array dinâmico cMotifProjection.
Primeiro, preparamos esse array dinâmico.
cMotifProjection.Clear(); cMotifProjection.SetOpenCL(OpenCL);
E definimos o comprimento da sequência de padrões. Como você sabe, a saída da pipeline de padrões é um tensor concatenado de incorporações em dois níveis.
int motifs = int(cMotifEncoder.Neurons() / window);
Observe que os tensores das representações diferem apenas no comprimento da sequência. Mantivemos o tamanho do vetor de descrição de cada elemento da sequência. Portanto, é perfeitamente lógico trabalharmos com séries unitárias individuais da sequência durante o processo de redimensionamento. Para isso, primeiro transpomos o tensor de representações no nível dos padrões.
idx++; CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, motifs, window, optimization, iBatch) || !cMotifProjection.Add(transp)) return false;
Depois, usamos uma camada convolucional para redimensionar as sequências unitárias.
idx++; CNeuronConvOCL *conv = new CNeuronConvOCL(); if (!conv || !conv.Init(0, idx, OpenCL, motifs, motifs, units_count, 1, window, optimization, iBatch) || !cMotifProjection.Add(conv)) return false; conv.SetActivationFunction((ENUM_ACTIVATION)cAtomEncoder.Activation());
Note que o tamanho da janela dos dados brutos e seu passo são iguais ao comprimento da sequência de representação no nível dos padrões. Enquanto isso, a quantidade de filtros é igual ao comprimento da sequência de representação no nível das velas.
Outro ponto que merece atenção são os parâmetros do comprimento da sequência e da quantidade de sequências unitárias. Neste caso, indicamos que a sequência de dados brutos é composta por um único elemento. E o número de séries unitárias na sequência é igual ao tamanho do vetor de descrição de um único elemento da sequência de dados brutos. Esse conjunto de parâmetros nos permite criar matrizes de pesos treináveis separadas para cada série unitária dos dados brutos recebidos. Em outras palavras, para redimensionar as sequências de diferentes elementos, o vetor de descrição de um único elemento da sequência de entrada usará diferentes matrizes de redimensionamento. Isso nos permitirá configurar um processo de redimensionamento mais flexível.
E é claro que não podemos esquecer de sincronizar as funções de ativação nas saídas da camada convolucional de redimensionamento e da pipeline de representação no nível das velas.
Depois disso, retornamos os dados já redimensionados à sua forma original utilizando uma camada de transposição de dados.
idx++; transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, window, units_count, optimization, iBatch) || !cMotifProjection.Add(transp)) return false; transp.SetActivationFunction((ENUM_ACTIVATION)conv.Activation());
Em seguida, inicializamos o bloco de atenção cruzada entre propriedades e padrões, cuja saída esperamos que seja a representação do estado de mercado analisado no nível das propriedades.
idx++; if (!cPropertyDecoder.Init(0, idx, OpenCL, window, window_key, properties, motifs, heads, layers, optimization, iBatch)) return false;
E agora chegamos ao ponto culminante. O resultado dos três blocos nos dá três representações diferentes do mesmo estado de mercado analisado. Além disso, todas essas representações estão em tensores com tamanhos diferentes. E agora? Como usá-las para resolver tarefas práticas específicas? Qual delas escolher para obter os melhores resultados?
Acredito que devemos utilizar os resultados dos três blocos. Já inicializamos o modelo de redimensionamento da representação de padrões. Vamos criar um modelo semelhante para redimensionar a representação das propriedades. Os ponteiros para os objetos desse modelo de redimensionamento serão armazenados no array dinâmico cPropertyProjection.
cPropertyProjection.Clear(); cPropertyProjection.SetOpenCL(OpenCL); idx++; transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, properties, window, optimization, iBatch) || !cPropertyProjection.Add(transp)) return false; idx++; conv = new CNeuronConvOCL(); if (!conv || !conv.Init(0, idx, OpenCL, properties, properties, units_count, 1, window, optimization, iBatch) || !cPropertyProjection.Add(conv)) return false; conv.SetActivationFunction((ENUM_ACTIVATION)cAtomEncoder.Activation()); idx++; transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, window, units_count, optimization, iBatch) || !cPropertyProjection.Add(transp)) return false; transp.SetActivationFunction((ENUM_ACTIVATION)conv.Activation());
As três representações, agora ajustadas para uma mesma dimensionalidade, serão concatenadas em um único tensor.
idx++; if (!cConcatenate.Init(0, idx, OpenCL, 3 * window * units_count, optimization, iBatch)) return false;
Veja só: obtivemos um tensor concatenado que reúne três visões complementares sobre uma única situação de mercado. Isso não lembra os resultados da atenção multi-cabeça? De fato, temos os resultados de três "cabeças", e para obter os valores finais utilizaremos uma camada de pooling baseada em dependências.
idx++; if(!cPooling.Init(0, idx, OpenCL, window, units_count, 3, optimization, iBatch)) return false;
Agora, só nos resta substituir os buffers de dados nas interfaces herdadas pelos buffers correspondentes ao objeto de pooling, o que nos permitirá evitar operações de cópia de dados desnecessárias.
if (!SetOutput(cPooling.getOutput(), true) || !SetGradient(cPooling.getGradient(), true)) return false; //--- return true; }
E encerramos o método de inicialização, retornando previamente o resultado lógico da execução das operações ao programa chamador.
Após finalizar a construção do método de inicialização do nosso objeto, passamos à organização dos processos de propagação para frente. Como de costume, esse algoritmo será implementado no método feedForward.
bool CNeuronAMCT::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cAtomEncoder.FeedForward(NeuronOCL)) return false; if(!cMotifEncoder.FeedForward(NeuronOCL)) return false;
Nos parâmetros do método, recebemos o ponteiro para o objeto de dados brutos, que imediatamente repassamos às nossas pipelines de representação da situação de mercado nos níveis de velas e padrões.
Os resultados da pipeline de padrões serão encaminhados ao módulo de atenção cruzada entre propriedades e padrões.
if(!cPropertyDecoder.FeedForward(cMotifEncoder.AsObject())) return false;
Neste ponto, obtivemos três representações da situação analisada. Vamos trazê-las para a mesma escala de dados. Para isso, primeiro redimensionamos a representação no nível dos padrões.
//--- Motifs projection CNeuronBaseOCL *prev = cMotifEncoder.AsObject(); CNeuronBaseOCL *current = NULL; for(int i = 0; i < cMotifProjection.Total(); i++) { current = cMotifProjection[i]; if(!current || !current.FeedForward(prev, NULL)) return false; prev = current; }
E organizamos um processo semelhante para a representação no nível das propriedades.
//--- Property projection prev = cPropertyDecoder.AsObject(); for(int i = 0; i < cPropertyProjection.Total(); i++) { current = cPropertyProjection[i]; if(!current || !current.FeedForward(prev, NULL)) return false; prev = current; }
Agora podemos unir as três representações em um único tensor.
//--- Concatenate uint window = cAtomEncoder.GetWindow(); uint units = cAtomEncoder.GetUnits(); prev = cMotifProjection[cMotifProjection.Total() - 1]; if(!Concat(cAtomEncoder.getOutput(), prev.getOutput(), current.getOutput(), cConcatenate.getOutput(), window, window, window, units)) return false;
E utilizamos a camada de pooling para realizar a soma ponderada dos resultados das três representações.
//--- Out if(!cPooling.FeedForward(cConcatenate.AsObject())) return false; //--- return true; }
Graças à substituição dos ponteiros dos buffers de dados realizada no método de inicialização, não precisamos copiar os dados para os buffers das interfaces da nossa classe. Simplesmente encerramos o método, retornando o resultado lógico da execução das operações ao programa chamador.
A próxima etapa do nosso trabalho é a construção dos métodos de propagação reversa. E o que mais chama atenção, do ponto de vista da construção do algoritmo, é o método de distribuição do gradiente do erro calcInputGradients. O motivo é que a estrutura ramificada das dependências entre os fluxos de informação, proposta pelos autores do framework AMCT, deixou sua marca no algoritmo desse método. Vamos analisar mais de perto sua implementação no código.
Nos parâmetros do método, como de costume, recebemos o ponteiro para o objeto da camada anterior, ao qual precisamos repassar o gradiente do erro de acordo com a influência dos dados brutos no resultado final.
bool CNeuronAMCT::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Logo verificamos a validade do ponteiro recebido. Afinal, se ele estiver inválido, todas as operações seguintes perdem o sentido.
Em seguida, passamos à distribuição sequencial do gradiente do erro entre os objetos internos. Aqui vale destacar que, graças à substituição dos ponteiros dos buffers das interfaces, não precisamos copiar os dados das interfaces externas para os objetos internos. Podemos começar diretamente a distribuir o gradiente do erro entre os objetos internos. Primeiro, definimos o gradiente do erro no nível do tensor concatenado das três representações do estado de mercado analisado.
if(!cConcatenate.calcHiddenGradients(cPooling.AsObject())) return false;
Depois, distribuímos o gradiente do erro entre as pipelines de representações individuais. O gradiente da representação no nível das velas é enviado diretamente ao Codificador. Os outros dois são encaminhados aos respectivos modelos de redimensionamento.
uint window = cAtomEncoder.GetWindow(); uint units = cAtomEncoder.GetUnits(); CNeuronBaseOCL *motifs = cMotifProjection[cMotifProjection.Total() - 1]; CNeuronBaseOCL *prop = cPropertyProjection[cPropertyProjection.Total() - 1]; if (!motifs || !prop || !DeConcat(cAtomEncoder.getGradient(), motifs.getGradient(), prop.getGradient(), cConcatenate.getGradient(), window, window, window, units)) return false;
Em seguida, ajustamos os gradientes das representações individuais com base nas funções de ativação correspondentes.
if (cAtomEncoder.Activation() != None) { if (!DeActivation(cAtomEncoder.getOutput(), cAtomEncoder.getGradient(), cAtomEncoder.getGradient(), cAtomEncoder.Activation())) return false; if (motifs.Activation() != None) { if (!DeActivation(motifs.getOutput(), motifs.getGradient(), motifs.getGradient(), motifs.Activation())) return false; if (prop.Activation() != None) { if (!DeActivation(prop.getOutput(), prop.getGradient(), prop.getGradient(), prop.Activation())) return false;
E adicionamos o gradiente de erro do processo de alinhamento entre as representações de velas e padrões.
if(!motifs.calcAlignmentGradient(cAtomEncoder.AsObject(), true)) return false;
Depois disso, distribuímos o gradiente do erro pelos modelos de redimensionamento, estabelecendo laços de iteração reversa pelas camadas neurais dos modelos.
for (int i = cMotifProjection.Total() - 2; i >= 0; i--) { motifs = cMotifProjection[i]; if (!motifs || !motifs.calcHiddenGradients(cMotifProjection[i + 1])) return false; }
for (int i = cPropertyProjection.Total() - 2; i >= 0; i--) { prop = cPropertyProjection[i]; if (!prop || !prop.calcHiddenGradients(cPropertyProjection[i + 1])) return false; }
O gradiente de erro do modelo de redimensionamento da representação das propriedades é repassado ao módulo de atenção cruzada entre propriedades e padrões. E, a partir daí, segue até o Codificador de padrões.
if (!cPropertyDecoder.calcHiddenGradients(cPropertyProjection[0]) || !cMotifEncoder.calcHiddenGradients(cPropertyDecoder.AsObject())) return false;
Mas é importante destacar que os resultados do Codificador de padrões também foram utilizados no modelo de redimensionamento da representação dos padrões. Sendo assim, precisamos adicionar o gradiente de erro do segundo fluxo de informação. Para isso, primeiro salvamos o ponteiro para o buffer de gradientes de erro do nosso Codificador de padrões em uma variável local. Em seguida, substituímos esse ponteiro pelo buffer do “doador”.
Como objeto doador, escolhemos a camada de concatenação das três representações. O gradiente de erro dela já foi distribuído entre os respectivos fluxos de informação. Essa camada não possui parâmetros treináveis. Por isso, podemos descartar tranquilamente os valores de seu buffer. Além disso, é a camada com o maior tamanho de buffer entre todos os objetos internos do nosso bloco, o que a torna a melhor candidata como “doadora”.
Depois de substituir o buffer, recebemos o gradiente de erro do modelo de redimensionamento. Somamos os dados dos dois fluxos de informação e restauramos os ponteiros para os buffers de dados ao seu estado original. Em seguida, transmitimos o gradiente de erro ao nível dos dados brutos.
CBufferFloat *temp = cMotifEncoder.getGradient(); if (!cMotifEncoder.SetGradient(cConcatenate.getGradient(), false) || !cMotifEncoder.calcHiddenGradients(cMotifProjection[0]) || !SumAndNormilize(temp, cMotifEncoder.getGradient(), temp, window, false, 0, 0, 0, 1) || !cMotifEncoder.SetGradient(temp, false) || !NeuronOCL.calcHiddenGradients(cMotifEncoder.AsObject())) return false;
Uma situação semelhante ocorre também no nível dos dados brutos: ao gradiente de erro recebido do Codificador de padrões, precisamos adicionar a contribuição proveniente da pipeline do Codificador de velas. Repetimos o truque da substituição do ponteiro do buffer de dados, mas agora para outro objeto.
temp = NeuronOCL.getGradient(); if (!NeuronOCL.SetGradient(cConcatenate.getGradient(), false) || !NeuronOCL.calcHiddenGradients(cAtomEncoder.AsObject()) || !SumAndNormilize(temp, NeuronOCL.getGradient(), temp, window, false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false)) return false; //--- return true; }
Agora, com o gradiente de erro completamente distribuído entre todos os objetos do modelo e os dados brutos, podemos encerrar o método, mas antes devolvemos o resultado lógico da execução das operações ao programa chamador.
Quero chamar sua atenção para dois pontos importantes desta implementação. Primeiro: ao substituir os ponteiros dos buffers de gradientes, é imprescindível salvar antes o ponteiro original do buffer de dados. E ao chamar o método de substituição do ponteiro, é igualmente essencial definir o parâmetro false na flag que evita a exclusão do objeto previamente armazenado. Isso garante que o objeto do buffer seja preservado e que possamos restaurar o ponteiro mais adiante. Caso utilizássemos a flag true, como fizemos no método de inicialização, o objeto do buffer seria deletado, e acessá-lo posteriormente causaria um erro crítico.
O segundo ponto diz respeito à arquitetura do método. No algoritmo apresentado, não implementamos a criação explícita do contraste entre representações de padrões, como sugerido pelos autores do framework AMCT. No entanto, vale lembrar que já introduzimos a diversificação das representações dentro do objeto de atenção cruzada relativa. Portanto, na prática, apenas transferimos o ponto de aplicação do erro do aprendizado contrastivo.
Com isso, encerramos a análise dos algoritmos de construção do framework Atom-Motif Contrastive Transformer. O código completo de todas as classes apresentadas e seus respectivos métodos pode ser consultado no anexo. Nele também estão incluídos os programas de interação com o ambiente e de treinamento dos modelos. Todos foram mantidos inalterados em relação aos trabalhos anteriores. Apenas ajustes pontuais foram feitos na arquitetura do Codificador do ambiente. Neste caso, substituímos uma camada.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAMCT; descr.window = BarDescr; // Window (Indicators to bar) { int temp[] = {HistoryBars, 100}; // Bars, Properties if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window_out = EmbeddingSize / 2; // Key Dimension descr.layers = 5; // Layers descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A descrição completa da arquitetura dos modelos treináveis está disponível no anexo.
3. Testes
Realizamos um grande trabalho ao implementar o framework Atom-Motif Contrastive Transformer com os recursos do MQL5, e chegou o momento de verificar na prática a eficácia das abordagens desenvolvidas. Para isso, treinamos o modelo com os novos objetos usando dados históricos reais e, em seguida, testamos a política treinada no testador de estratégias do MetaTrader 5 em um intervalo de tempo fora do conjunto de treino.
Como de costume, o treinamento do modelo é feito offline, com uma amostra de treinamento previamente coletada a partir de execuções ao longo de todo o ano de 2023. O treinamento ocorre de forma iterativa e, após algumas iterações, realizamos a atualização da amostra de treinamento. Isso nos permite obter uma avaliação mais precisa das ações do Agente com base na política atual.
Durante o treinamento, conseguimos obter um modelo capaz de gerar lucro tanto no conjunto de treino quanto no conjunto de teste. Mas há um detalhe: o modelo que obtivemos realiza pouquíssimas operações. Inclusive, estendemos o período de teste para 3 meses. Os resultados do teste são apresentados a seguir.
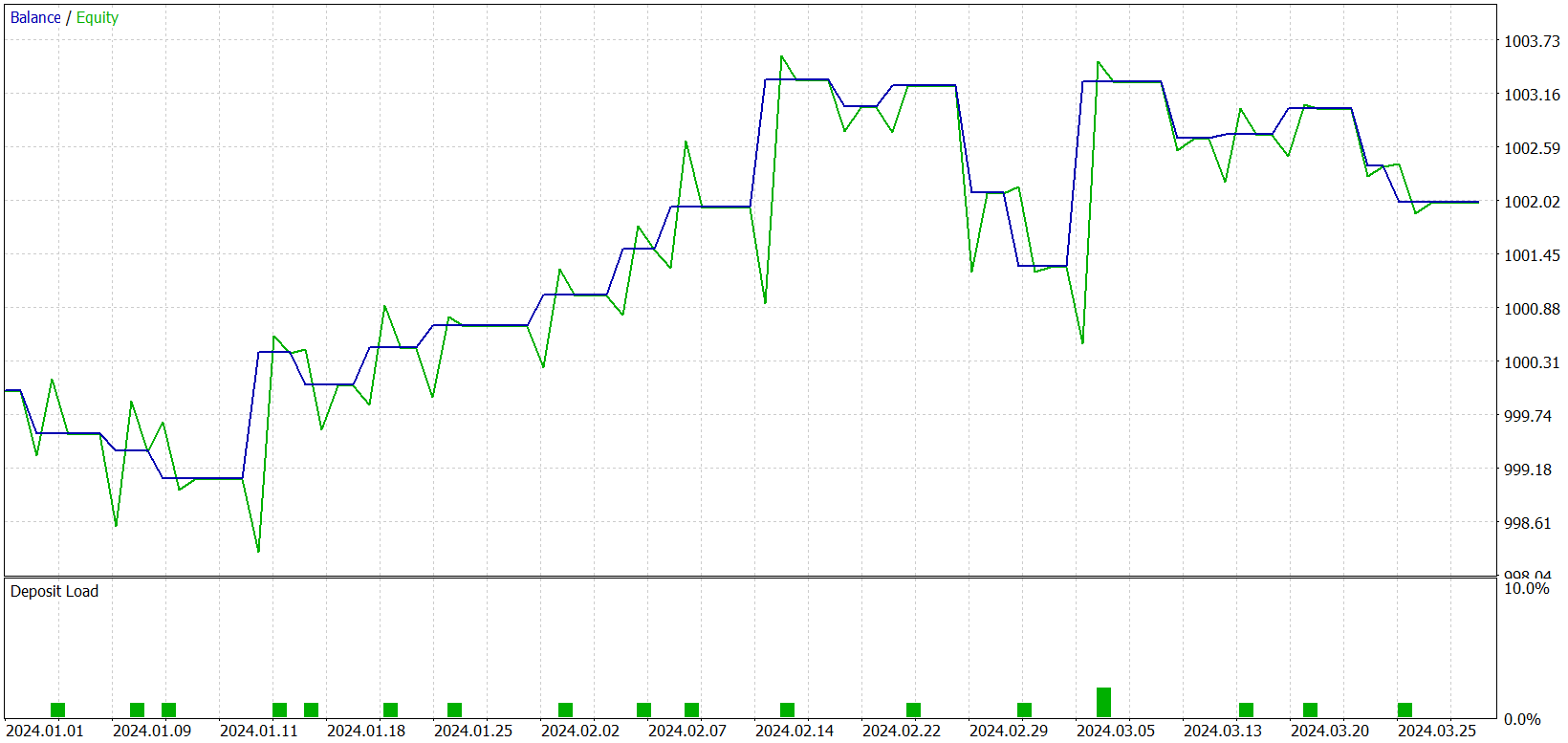
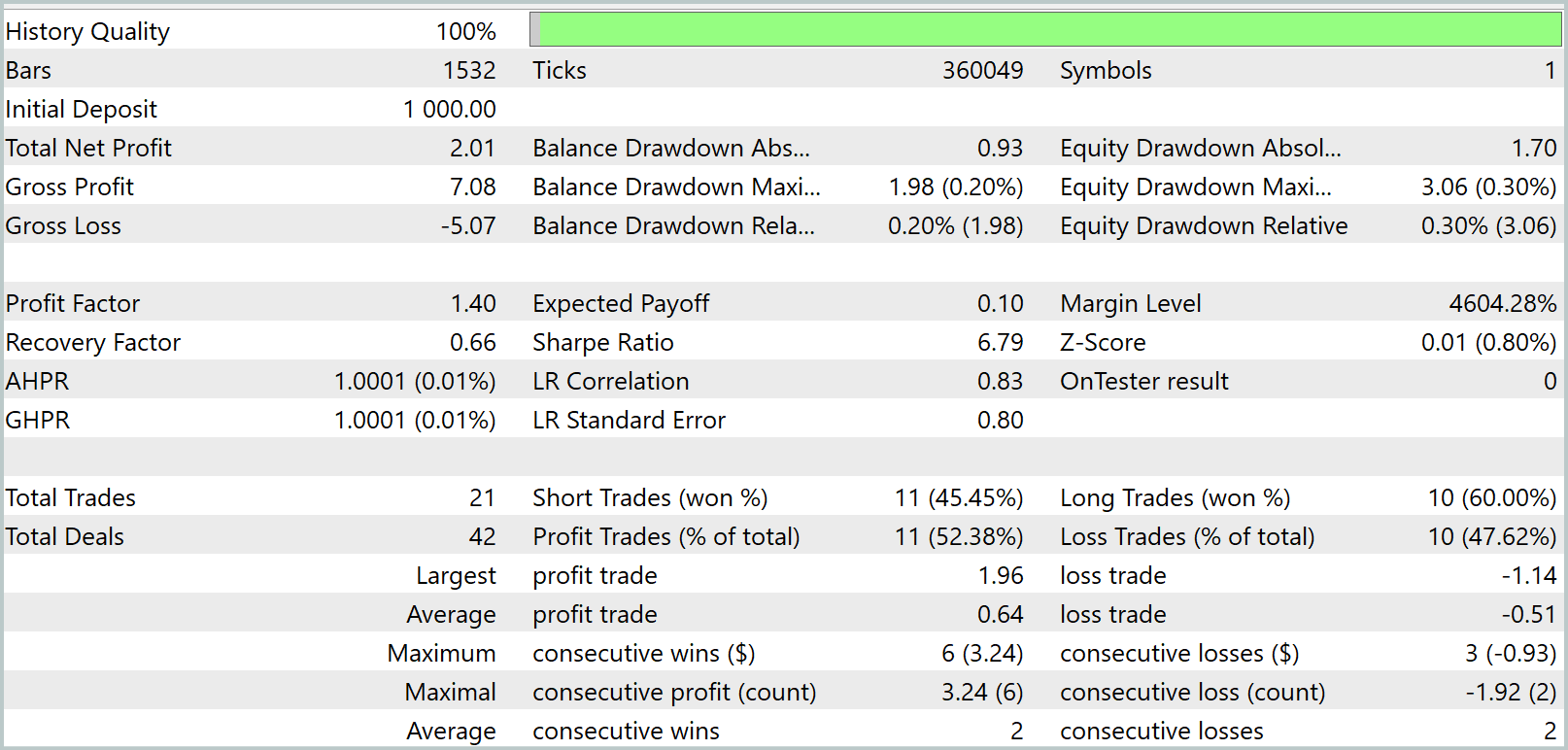
Como se pode ver nos dados apresentados, durante o intervalo de três meses de teste, o modelo realizou apenas 21 operações, das quais pouco mais da metade foi encerrada com lucro. Mas, vamos olhar para o gráfico de saldo. Nos primeiros um mês e meio, observamos um crescimento no saldo, seguido por um movimento lateral. Na verdade, esse comportamento é bastante esperado. Nosso modelo apenas coleta estatísticas a partir dos estados de mercado do conjunto de treino. E, como em qualquer modelo estatístico, a amostra de treinamento precisa ser representativa. E pelo gráfico de saldo, concluímos que uma amostra de 1 ano é representativa por um período de aproximadamente 1,2 a 1,5 meses.
Então, podemos supor que treinar o modelo com uma amostra de 10 anos pode gerar um modelo com desempenho estável ao longo de 1 ano. Também é possível supor que uma amostra de treinamento maior permitirá identificar um número maior de padrões-chave e propriedades treináveis. E isso pode, potencialmente, aumentar a quantidade de operações realizadas. No entanto, para confirmar ou refutar essas hipóteses, será necessário realizar trabalhos adicionais com o modelo.
Considerações finais
Nas duas últimas partes, exploramos o framework Atom-Motif Contrastive Transformer (AMCT), que se baseia nas concepções de elementos atômicos (velas) e motivos (padrões). A ideia central do método está no uso de aprendizado contrastivo para destacar padrões informativos e não informativos em diferentes níveis: desde os componentes mais elementares até estruturas mais complexas. Isso permite ao modelo considerar não apenas os movimentos locais de preço no mercado, mas também identificar padrões relevantes que possam fornecer informações adicionais para uma previsão mais precisa do comportamento futuro do mercado. A arquitetura Transformer, que fundamenta esse framework, reconhece de forma eficaz dependências de longo prazo e relações complexas entre velas e padrões.
Na parte prática, implementamos nossa interpretação das abordagens propostas usando recursos do MQL5, treinamos o modelo e realizamos testes com dados históricos reais. Infelizmente, o modelo que obtivemos se mostrou “pobre em operações”. No entanto, há um potencial visível, que esperamos desenvolver em trabalhos futuros.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos com o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA de treinamento de modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca com código para programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16192
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso