
Quantificação no aprendizado de máquina (Parte 2): Pré-processamento de dados, seleção de tabelas, treinamento do modelo CatBoost

Introdução
Este artigo trata da aplicação prática da quantização na construção de modelos baseados em árvores. O material será apresentado em linguagem acessível, sem fórmulas matemáticas complexas. Este artigo é a segunda parte do artigo "Quantização e outros métodos de pré-processamento de dados de entrada em aprendizado de máquina", portanto, é altamente recomendável começar por ele, e aqui discutiremos o seguinte:
- Na primeira parte, vamos nos familiarizar com os métodos de pré-processamento de dados implementados no MQL5.
- Na segunda parte, realizaremos um experimento para dar informações sobre a viabilidade da quantização de dados.
1. Métodos adicionais de pré-processamento de dados
Através da descrição da funcionalidade do script "Q_Error_Otbor", vamos nos familiarizar com os métodos de pré-processamento de dados que eu implemento.
Para descrever brevemente o objetivo do script "Q_Error_Otbor", ele serve para carregar a amostra do arquivo "train.csv", transferir o conteúdo para uma matriz, pré-processar os dados, e carregar sequencialmente as tabelas quantizadas e avaliar o erro dos dados restaurados em relação aos originais para cada preditor. Os resultados da avaliação de cada tabela quantizada serão salvos em um array. Após testar todas as opções, criaremos uma tabela resumo com os erros para cada preditor, selecionaremos as melhores opções de tabelas quantizadas para cada preditor conforme um critério definido. Criaremos e salvaremos uma tabela quantizada resumo, um arquivo de configurações do CatBoost, que incluirá os preditores excluídos da lista de treinamento, com a indicação dos números de suas colunas. Também serão criados outros arquivos relacionados, dependendo das configurações escolhidas para o script.
Vamos examinar mais detalhadamente as configurações do script, que listei abaixo por grupos.
Carregamento de dados
- Diretório da amostra1
- Diretório para quantização2
1 Indicamos o caminho para o diretório onde está localizado o diretório "Setup", que contém os arquivos csv com a amostra. Este diretório será referido como "diretório do projeto".
2 Indicamos o caminho para o diretório onde está localizado o diretório "Q", que contém os arquivos csv com as tabelas quantizadas.
Configuração do tratamento de outliers
- Usar verificação de outliers1
- Método de transformação de outliers:2
- O valor dos outliers é transformado para um valor próximo ao split2.1
- O valor dos outliers é transformado para um valor aleatório fora do alcance dos outliers2.2
- Substituir dados após o tratamento de outliers3
- Salvar ou não a amostra train com outliers transformados4
- Adicionar informação sobre outliers nas subamostras5
- Remover linhas com grande número de outliers5.1
- Porcentagem máxima de outliers nos preditores por linha de amostra5.2
1 Ao selecionar "true", é ativada a verificação de outliers. Valores atípicos são considerados valores raros dos preditores. Valores raros podem ser estatisticamente insignificantes, mas geralmente não são levados em conta em modelos, o que pode levar à formação de regras duvidosas para avaliar a probabilidade de classificação. Na Figura №1, você pode ver um exemplo desse outlier. Ao definir limites que separam outliers e dados normais, podemos agregar os outliers em um todo unificado, aumentando a confiabilidade estatística e permitindo que esses dados sejam tratados como normais ou completamente excluídos do treinamento.
2 Escolhemos um dos métodos de transformação de outliers, através do qual o valor do preditor será alterado, permitindo que esse exemplo seja incluído na amostra para treinamento, em vez de excluí-lo como anômalo. Para identificar outliers, usei 2,5% dos dados de cada lado da série numérica. Observo que valores numéricos idênticos previamente encontrados foram agrupados e aos grupos foram atribuídos rankings, e se o ranking subsequente exceder 2,5%, o último ranking com outliers é considerado o anterior. Os preditores com poucos rankings são reconhecidos como categóricos e não são processados para outliers. Informações na forma de uma lista de preditores categóricos são salvas no seguinte caminho em relação ao diretório do projeto: "..\CB\Categ.txt". Um método comum para determinar outliers é a regra das três sigmas, que envolve desviar três desvios padrões para a esquerda e para a direita a partir da média, e qualquer coisa fora desses limites é considerada um outlier. Nos gráficos abaixo, você pode ver em preto três linhas horizontais: o centro, a diferença e a soma de três sigmas a partir do centro. As linhas azuis no gráfico representarão os limites dentro dos quais os dados frequentemente encontrados estão de acordo com o algoritmo que propus.
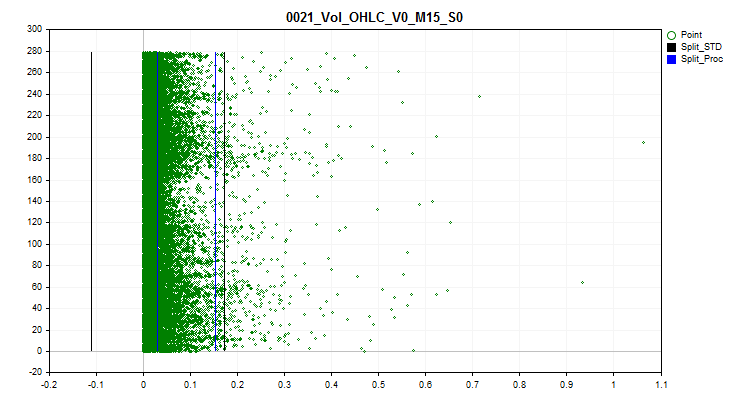
Figura 1 "Definição de limites para determinação de outliers"
2.1 Este método substitui todos os valores de outliers por um valor próximo ao limite (split). Essa abordagem permite não distorcer a estimativa de aproximação pela tabela quantizada dentro dos limites do outlier.
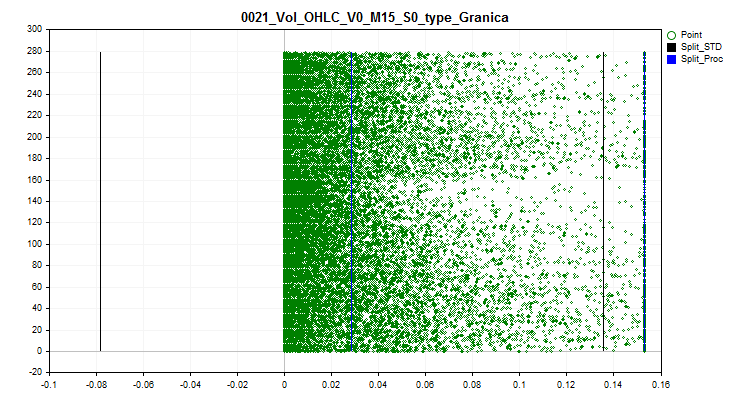
Figura 2 "Valores de outliers são transformados em valor próximo ao split"
2.2 Este método substitui todos os valores de outliers por valores aleatórios, de acordo com os rankings, dentro dos limites com dados normais. Essa abordagem permite dispersar o erro de estimativa de aproximação pela tabela quantizada.
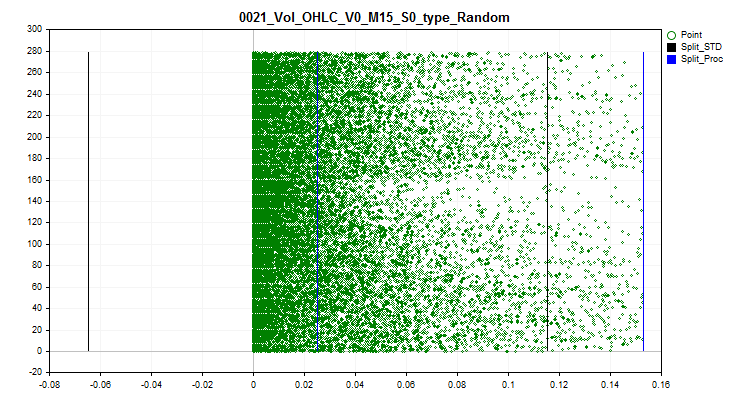
Figura 3 "Valores de outliers são transformados em valor aleatório fora do alcance dos outliers"
3 Se é necessário avaliar e escolher tabelas quantizadas considerando os outliers transformados, então escolhemos "true". Quando esta função é ativada, o array na forma de uma matriz com os dados de entrada será alterado, os valores dos preditores com outliers serão aqueles que foram selecionados de acordo com o método de transformação de outliers.
4 É possível salvar a amostra train.csv, que será salva no diretório "..\CB\Q_Vibros_Viborka". Isso pode ser necessário para realizar a quantização com a ajuda do CatBoost, pois os dados já estarão alterados para os transformados, e as tabelas de quantização podem diferir, além de poder permitir a redução do número de divisores (splits) para alcançar o limiar mínimo de erro ao avaliar a qualidade da aproximação pela tabela quantizada.
5 A ativação desta configuração e a definição da variável como "true" resultará no carregamento sequencial dos arquivos de subamostras train.csv, test.csv e exam.csv. Em cada linha da subamostra, será calculado o número de valores dos preditores na área de outliers, e o resultado total será registrado em uma coluna adicional "Proc_Vibros". A amostra modificada será salva no diretório "..\CB\ADD_Drop_Info_Viborka".
Independentemente da ativação desta configuração, um arquivo separado será criado no diretório do projeto no caminho "..\CB\Proc_Vibros_Train.csv". Este arquivo contém apenas informações sobre os outliers na amostra train.
5.1 A ativação desta configuração levará à remoção de linhas com outliers das amostras. Às vezes, vale a pena tentar treinar o modelo em dados sem outliers.
5.2 Se decidido remover linhas com outliers, é aconselhável avaliar a porcentagem de preditores cujos valores estão na zona de definição de outliers.
Configuração da estimativa de correlação
- Uso de estimativa de correlação para excluir preditores1
- Método de exclusão de preditores correlacionados - determina o método de seleção (exclusão de preditores) a escolher:2
- Seleção reversa de preditores2.1
- Seleção de preditores generalizantes2.2
- Seleção de preditores raros2.3
- Coeficiente de correlação3
1 Ao escolher "true", é ativada a estimativa de correlação de Pearson. O resultado desta funcionalidade será a obtenção de uma tabela de correlação dos preditores no seguinte caminho "../CB", onde o nome do arquivo consiste no nome "Corr_Matrix_" seguido do tamanho do coeficiente de correlação, "Corr_Matrix_70.csv". Preditores altamente correlacionados serão excluídos.
2 São oferecidos três métodos de exclusão de preditores.
2.1 Este método busca em ordem reversa preditores correlacionados e, se houver um anterior, a coluna atual com o preditor é excluída do treinamento.
2.2 Este método avalia o número de preditores correlacionados com cada preditor e iterativamente seleciona aquele que se correlaciona com o maior número de preditores, excluindo outros preditores correlacionados com ele. A lógica aqui é selecionar preditores que encapsulam a maior quantidade de informações de outros preditores, resultando em uma generalização de informações.
2.3 Este método é semelhante ao anterior, mas, ao contrário, seleciona aqueles preditores que têm a menor semelhança com os outros. Aqui, a tentativa é encontrar um preditor com informações únicas.
3 Aqui deve-se especificar o coeficiente de correlação de Pearson. Somente alcançando ou superando o valor especificado do coeficiente, os preditores são considerados semelhantes para manipulações para exclusão da amostra.
Configuração de tratamento de preditores instáveis ao longo do tempo
- Usar verificação para a média dos valores em cada parte da amostra1
- Porcentagem de variação das médias das subamostras2
1 Ao escolher "true", é ativada a verificação para flutuação do valor médio do indicador de cada preditor em cada 1/10 da amostra. Esta verificação permite excluir preditores cujos indicadores se deslocam significativamente ao longo do tempo. Preditores como estes, teoricamente, impedem o aprendizado. Um exemplo desse preditor pode ser visto na Figura №4, e o processo de avaliação é visualizado na Figura №5. O preditor exemplificado foi construído com base no indicador Variable Index Dynamic Average (iVIDyA), que essencialmente mostra o valor médio do preço, e seu uso no modelo resultará na memorização do comportamento a um preço absoluto específico.
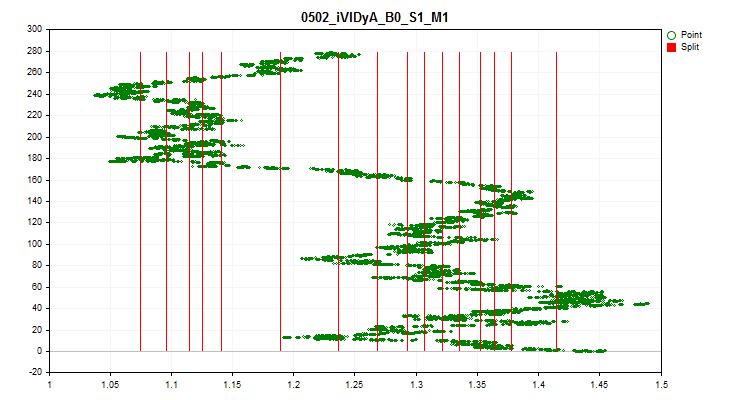
Figura №4 "O preditor iVIDyA_B0_S1_M1 tem um forte deslocamento"
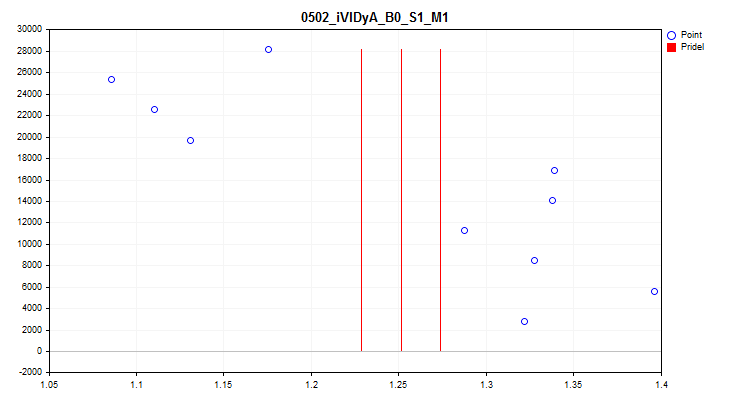
Figura №5 "Dispersão do valor médio do preditor iVIDyA_B0_S1_M1"
2 Aqui, especifica-se a largura da faixa em percentual para cada limite, que é determinada a partir de todo o intervalo de valores do preditor – em relação ao valor médio ao longo de todo o período.
Configuração da criação de uma tabela quantizada uniforme
- Criar uma tabela quantizada uniforme1
- Número de intervalos nos quais os dados de entrada devem ser divididos (quantizados)2
1 Ao escolher "true", é ativado o algoritmo de criação de uma tabela quantizada uniforme para todos os preditores na amostra. A tabela será salva na subdiretório do projeto "Q_Bit".
2 Especifica-se o número de intervalos nos quais o preditor será dividido.
Configuração da criação de uma tabela quantizada aleatória
- Criar uma tabela quantizada aleatória1
- Número inicial para o gerador de números aleatórios2
- Número de iterações para encontrar a melhor opção3
- Número de intervalos nos quais os dados de entrada devem ser divididos (quantizados)4
1 Ao escolher "true", é ativado o algoritmo de criação de uma tabela quantizada aleatória para todos os preditores na amostra. A tabela será salva na subdiretório do projeto "Q_Random".
2 O número permite que o resultado da geração aleatória seja repetível. Alterando o número, pode-se mudar a sequência de números gerados.
3 O algoritmo avalia o erro de aproximação após cada geração de uma tabela aleatória e seleciona a melhor opção. Quanto mais tentativas, maior a chance de encontrar a opção mais bem-sucedida.
4 Indica-se o número de intervalos nos quais o preditor será dividido.
Configuração da seleção de tabelas quantizadas
- Iniciar seleção de tabelas quantizadas1
- Usar limiar para seleção do preditor2
- Erro máximo permitido de quantização3
1 Ao escolher "true", o algoritmo de busca e avaliação de tabelas quantizadas no subdiretório "Q" do projeto é ativado, caso contrário, o programa cessará sua operação. O resultado dessa função do script será a criação de dois diretórios:
No diretório "..\CB\Setup" estarão localizados 3 arquivos:
- "Auxiliary.txt" – arquivo auxiliar com os números dos índices dos preditores que foram excluídos;
- "Quant_CB.csv" – arquivo com as tabelas quantizadas para os preditores que participarão do treinamento;
- "Test_CB_Setup_0_000000000" – arquivo com informações para o CatBoost – quais colunas excluir do treinamento e qual coluna considerar como alvo.
No diretório "Test_Error" estará localizado o arquivo "arr_Svod.csv" - ele contém os resultados consolidados do cálculo do erro de restauração (aproximação) para cada preditor ao aplicar diferentes tabelas quantizadas. A primeira coluna contém a lista de preditores, as subsequentes o resultado ao aplicar uma tabela quantizada específica, e a última coluna contém o índice da tabela quantizada que mostrou o melhor resultado. O melhor resultado foi usado para criar a tabela quantizada consolidada "Quant_CB.csv".
2 Se a configuração estiver em "false", apenas o erro de restauração (aproximação) é usado para avaliar as tabelas quantizadas, escolhendo-se aquela que resultou no menor erro.
Se estiver em "true", o erro de restauração (aproximação) dividido pelo número de splits na tabela quantizada é usado para avaliação. Esta abordagem permite considerar o número de tabelas quantizadas, a fim de evitar a situação de quantização excessiva. As tabelas só participarão da seleção se o erro for inferior ao definido no próximo parâmetro de configuração.
3 Aqui indicamos o erro máximo permitido de restauração (aproximação) dos valores do preditor.
Configuração de salvamento da amostra transformada
- Transformar e salvar amostra1
- Opção de transformação de dados:2
- Salvar em forma de índices2.1
- Salvar em forma de centroides2.2
1 Ao escolher "true", a amostra (três arquivos csv) será transformada e salva no subdiretório do projeto "..\CB\Index_Viborka". Esta configuração permite o uso de tabelas quantizadas em algoritmos de aprendizado de máquina onde originalmente não estavam previstas. Outra aplicação é a troca pública de dados para treinamento de modelos sem revelar os indicadores dos preditores, o que pode proteger contra a divulgação de informações competitivas sobre as fontes de dados utilizadas. Além disso, o salvamento em forma de índices pode significativamente reduzir o espaço de armazenamento necessário nos discos dos arquivos de amostra, bem como a quantidade de RAM necessária para manipular a amostra.
2 Escolhemos uma das duas opções de transformação dos valores dos preditores, após a aplicação da tabela quantizada consolidada final.
2.1 Serão salvos os valores dos índices dos segmentos da tabela quantizada, nos quais o número do preditor se enquadra.
2.2 Será salvo o valor entre duas fronteiras, no intervalo das quais o número do preditor se enquadra.
Configuração de salvamento de gráficos
- Salvar gráficos1
- Largura do gráfico2
- Altura do gráfico3
- Tamanho da fonte na legenda4
1 Ao escolher "true", é ativada a função de criação e salvamento de gráficos. No diretório "Grafics" serão criados arquivos gráficos contendo informações sobre cada preditor na amostra. O nome do arquivo começa com o número do preditor, seguido pelo nome do preditor do cabeçalho da coluna da amostra, e depois pelo nome convencional do gráfico. Vamos considerar os gráficos obtidos para o preditor "iCCI_B0_S1_M1":
- O primeiro gráfico mostra a densidade dos valores do preditor em um intervalo específico – quanto maior a densidade, mais inclinada para cima será a curva do gráfico nesse intervalo. No eixo X – o valor do preditor, e no eixo Y – o número da observação ordenado pelo seu valor. Com o gráfico, é possível avaliar a densidade de observações na amostra que caem em intervalos específicos e identificar outliers.
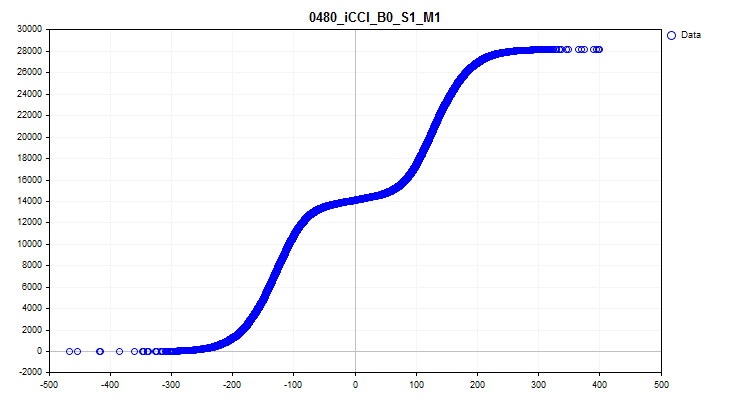
Figura №6 "Densidade dos valores do preditor"
O segundo gráfico mostra em quais intervalos os valores dos preditores foram observados com os alvos "0" e "1", resultando em valores azuis para zero e vermelhos para um. Assim, é possível ver em quais intervalos do preditor o valor alvo é mais frequentemente representado. Recomenda-se construir o gráfico mais amplo do que na ilustração para o artigo.
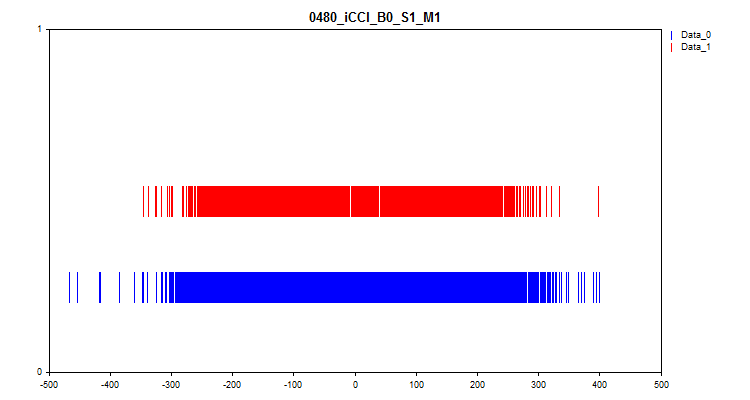
Figura №7 "Correspondência do valor do preditor à marcação alvo"
O terceiro gráfico é uma histograma, onde no eixo Y é plotada a porcentagem de observações de todas as observações na amostra. O gráfico permite avaliar os outliers e fazer uma suposição sobre a densidade da distribuição.
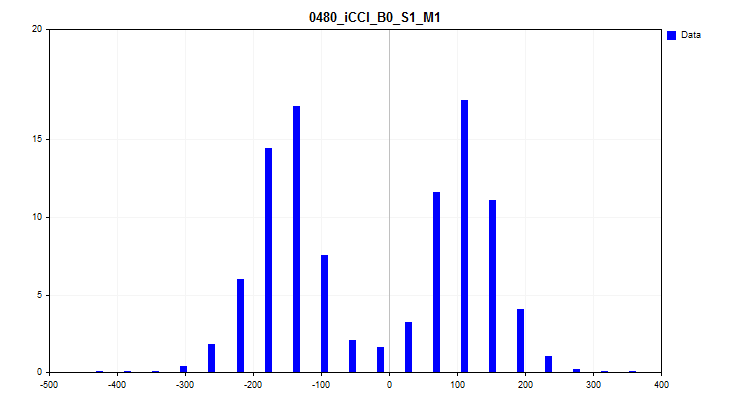
Figura №8 "Histograma de densidade de distribuição"
O quarto gráfico mostra o preenchimento do intervalo da escala do preditor por seus valores em ordem cronológica, bem como os níveis que foram selecionados para a quantização final. No eixo X – o valor do preditor, e no eixo Y – o número do grupo de 100 observações.
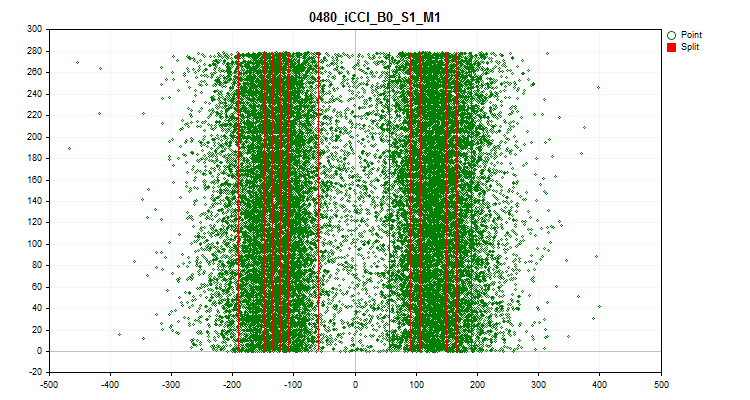
Figura №9 "Tabela quantizada"
O quinto gráfico exibe o valor médio do preditor ao longo de 10 intervalos da amostra. Em caso de grande dispersão, recomenda-se excluir o preditor. No eixo X – o valor médio do preditor, e no eixo Y – o número do grupo de N observações.
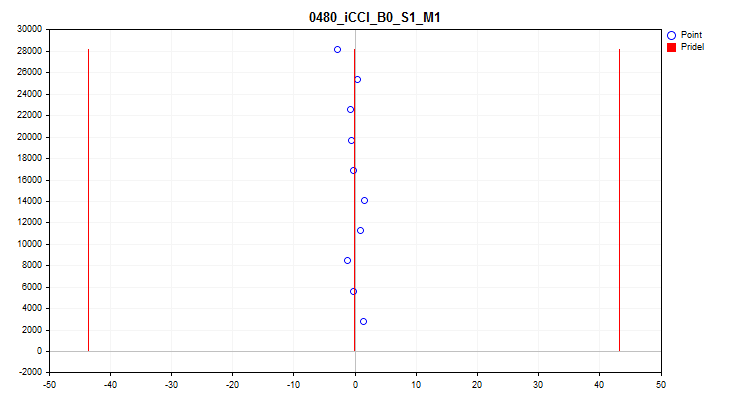
Figura №10 "Dispersão do valor médio"
O sexto gráfico mostra os outliers presumidos. No gráfico, três linhas pretas são plotadas – a média e mais e menos três desvios padrões. As fronteiras azuis representam os próximos 2,5% de observações, contadas do início e do final do intervalo da amostra. No eixo X – o valor do preditor, e no eixo Y – o número do grupo com um número fixo de observações.
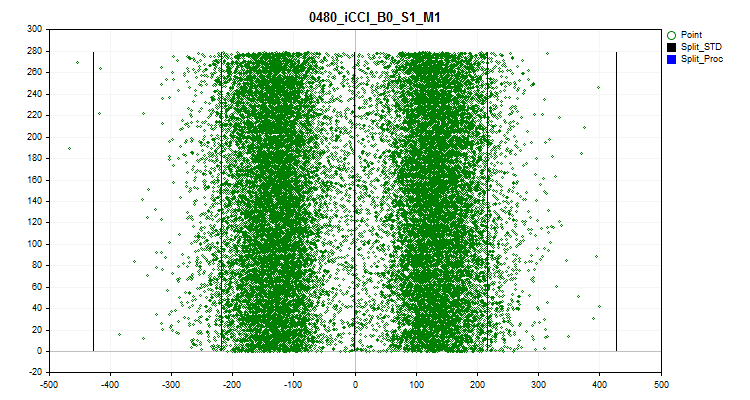
Figura №11 "Outliers"
2 A largura do gráfico é indicada em pixels.
3 A altura do gráfico é indicada em pixels.
4 São indicados o tamanho da fonte e o tamanho dos ícones nas curvas na legenda dos gráficos.
Configuração da busca de cenários de configuração
- Iterar cenários de configurações1
1Ativa a iteração de configurações, de acordo com o algoritmo embutido - leia mais no artigo para detalhes.
2. Realização de um experimento comparativo para avaliar o efeito da quantização
Definição do experimento – Objetivos
Temos uma ferramenta com bastante funcionalidade, é hora de avaliar suas capacidades no trabalho! Vamos realizar um experimento que responderá às seguintes questões:
- Há algum sentido em todas essas ações e manipulações com a seleção de tabelas quantizadas para os preditores, ou seria mais simples usar as configurações padrão do CatBoost?
- Quantos splits (fronteiras) são necessários no mínimo para alcançar um resultado semelhante ao das configurações padrão do CatBoost?
- Vale a pena usar métodos de quantização como "uniforme" e "aleatório"?
- Existe uma diferença significativa entre os métodos de seleção de tabelas quantizadas?
Para responder a essas perguntas, será necessário treinar com diferentes tabelas quantizadas, obtidas com diferentes configurações do script "Q_Error_Otbor". Sugiro iterar as seguintes configurações:
Método de seleção:
- Apenas o erro de restauração (aproximação) é usado para avaliar as tabelas quantizadas.
- O erro de restauração (aproximação) dividido pelo número de splits na tabela quantizada é usado para avaliação, com um erro máximo de 1%.
- O erro de restauração (aproximação) dividido pelo número de splits na tabela quantizada é usado para avaliação, com um erro máximo de 0.5%.
Fonte das tabelas quantizadas:
- Tabelas obtidas através do CatBoost.
- Tabelas obtidas pelo método de quantização uniforme.
- Tabelas obtidas pelo método de colocação aleatória de splits.
Conjunto de tabelas quantizadas:
- Conjunto "1" - são usadas todas as tabelas quantizadas disponíveis no diretório da fonte.
- Conjunto "2" - são usadas apenas tabelas quantizadas com 16 splits ou intervalos.
- Conjunto "3" - são usadas apenas tabelas quantizadas com 32 splits ou intervalos.
- Conjunto "4" - são usadas apenas tabelas quantizadas com 64 splits ou intervalos.
- Conjunto "5" - são usadas apenas tabelas quantizadas com 128 splits ou intervalos.
- Conjunto "6" - são usadas apenas tabelas quantizadas com 256 splits ou intervalos.
Todas as combinações de configurações são apresentadas em uma tabela na forma de figura №12, na qual a tarefa é implementada como três laços aninhados, alterando as configurações correspondentes, que são ativadas pela configuração da variável "Iterar Cenários de Configurações" para o modo true.
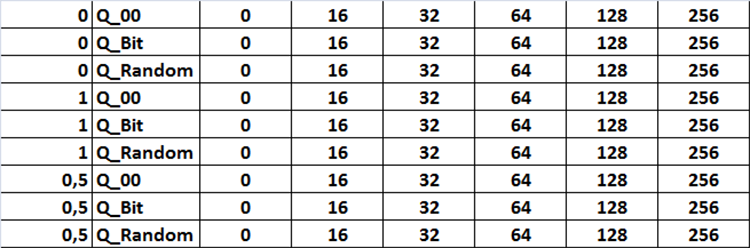
Figura №12 "Tabela de combinações de configurações de iteração"
Serão treinados 101 modelos com cada combinação de configurações, iterando o parâmetro Seed de 0 a 800 em incrementos de 8, o que permitirá médias dos resultados obtidos para avaliar as configurações com o objetivo de eliminar resultados aleatórios.
Estes são os indicadores que proponho usar para a análise comparativa:
- Lucro médio de todos os modelos – chamaremos este indicador de "Profit_Avr";
- Expectativa matemática média dos modelos – chamaremos este indicador de "MO_Avr";
- Precisão média de classificação dos modelos – chamaremos este indicador de "Precision_Avr";
- Recall médio dos modelos – chamaremos este indicador de "Recall_Avr";
- Número médio de modelos que mostraram um lucro superior a 3000 unidades – chamaremos este indicador de "N_Exam_Model";
- Lucro máximo médio de todos os modelos – chamaremos este indicador de "Profit_Max".
Após calcular esses indicadores, propõe-se somá-los e dividir pelo número de indicadores, assim obteremos um indicador abrangente da qualidade da configuração de seleção de tabelas quantizadas – chamaremos simplesmente de "Q_Avr".
Preparação de dados para o experimento
Para obter a amostra, usaremos o mesmo EA e scripts que foram usados anteriormente ao nos familiarizarmos com o CatBoost no artigo "Algoritmo de aprendizado de máquina CatBoost da Yandex sem conhecimento prévio de Python ou R".
Eu usei as seguintes configurações:
A. Configurações do testador:
- Símbolo: EURUSD
- Time Frame: M1
- Intervalo de 01.01.2010 a 01.09.2023
B. Configurações da estratégia do EA CB_Exp:
- Período: 104
- Time Frame: 2 Minutes
- Método das médias móveis: Smoothed
- Base de cálculo do preço: Close price
Após obter a amostra e dividi-la em 3 partes (train, test, exam), de forma similar à descrita anteriormente no meu artigo, será necessário obter as tabelas quantizadas. Para esse fim, modifiquei o script CB_Bat (anexado a este artigo) e agora ao selecionar no ajuste "Objeto de iteração" o valor "Brut_Quantilization_grid", o script criará o arquivo "_01_Quant_All.txt". As configurações de iteração de intervalo permaneceram as mesmas – define-se o valor inicial da variável, o valor final da variável e o passo de mudança, eu usei a iteração de 8 a 256 com passos de 8. Como resultado da execução do script, comandos serão preparados para obter tabelas quantizadas de todos os tipos com o número especificado de fronteiras. O arquivo da tabela quantizada terá a seguinte estrutura de nomeação: o nome do arquivo na forma de um nome semântico "quant", o número de divisores e o número de ordem do tipo de divisão, sendo os indicadores conectados por sublinhados, enquanto os próprios arquivos serão salvos no diretório "Q", que está no mesmo local que o diretório "Setup" do projeto.
quant_"+IntegerToString(Seed,3,'0')+"_"+IntegerToString(ENUM_feature_border_type_NAME(Q),0)+".csv";
O arquivo resultante "_01_Quant_All.txt", após a execução do script, precisa ter sua extensão alterada para "*.bat", ser colocado no diretório com a versão do CatBoost previamente indicada no script e ser executado – clicando duas vezes com o mouse.
Após a execução do script, um conjunto de arquivos aparecerá no subdiretório "Q" – estas são as tabelas quantizadas com as quais trabalharemos a seguir.

Figura № 13 "Conteúdo do subdiretório Q"
Com o script "Q_Error_Otbor", geramos tabelas quantizadas uniformes e aleatórias com números de intervalos de 16, 32, 64, 128, 256, e os arquivos correspondentes aparecerão nos diretórios "Q_Bit" e "Q_Random". Faremos uma cópia do diretório "Q" para o diretório do projeto e chamaremos o novo diretório de "Q_00".
Excelente, agora temos tudo que é necessário para criar um pacote de tarefas de treinamento. Executamos o script "Q_Error_Otbor" e em suas configurações mudamos o parâmetro "Iterar cenários de configurações" para o modo "true", e pressionamos "Ok". O script, conforme o cenário definido no código, criará arquivos com a tabela quantizada e configurações para o treinamento.
Para usar as tabelas quantizadas em cada configuração de ajustes do CatBoost, o script adicionará ao nome usual da tabela quantizada "Quant_CB.csv" o nome do arquivo de configuração.
Obteremos arquivos para treinamento com o script "CB_Bat_v_02" – escolhi iterar o Seed de 0 a 800 com passos de 8, e especifiquei o diretório do projeto.
Agora, precisamos editar um pouco o arquivo de treinamento, substituindo nele o nome do arquivo "Quant_CB.csv" por "Quant_CB_%%a.csv", essa mudança permitirá usar como variável o nome das configurações, do qual depende o número de ciclos de treinamento. Copiamos os arquivos criados para o diretório "Setup" do projeto e iniciamos o treinamento, renomeando o arquivo "_00_Start.txt" para "_00_Start.bat" e clicando duas vezes no arquivo "_00_Start.bat".
Avaliação dos resultados do experimento
Após a conclusão do treinamento, usaremos o script "CB_Calc_Svod", que calculará as métricas para cada modelo. As configurações do script foram descritas em detalhes no último artigo, portanto, não vou me repetir.
Também foi realizado o treinamento de 101 modelos com as configurações padrão da tabela quantizada, e estes foram os resultados obtidos:
- Profit_Avr=2810,17;
- МО_Avr=28,33;
- Precision _Avr=0,3625;
- Recall_Avr=0,023;
- N_Exam_Model=43;
-
Profit_Max=8026.
Vamos examinar em detalhes as tabelas de resultados e gráficos para cada indicador antes de fazermos conclusões generalizantes.
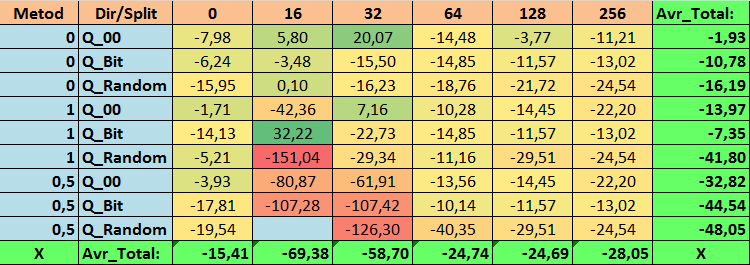
Tabela №14 "Valores consolidados do indicador Profit_Max"
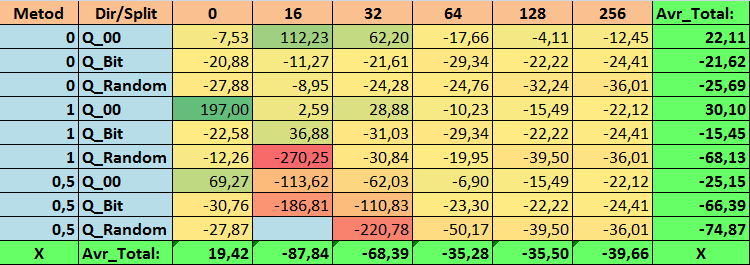
Tabela №15 "Valores consolidados do indicador MO_Avr"
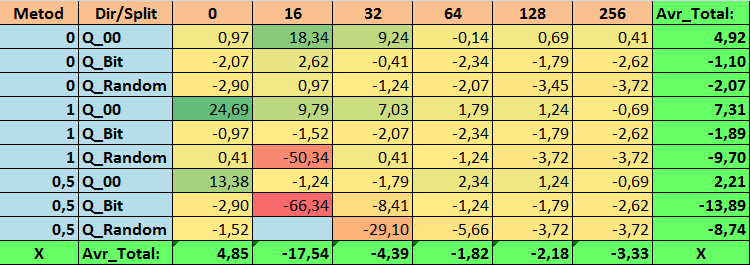
Tabela №16 "Valores consolidados do indicador Precision_Avr"
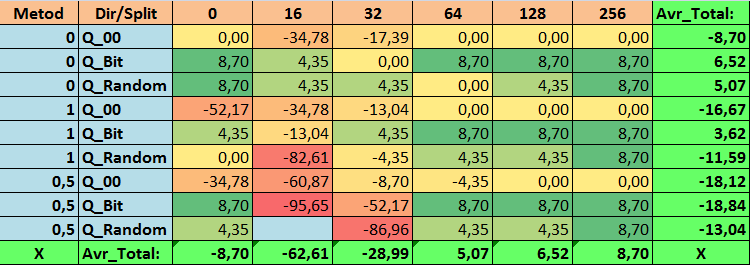
Tabela №17 "Valores consolidados do indicador Recall_Avr"
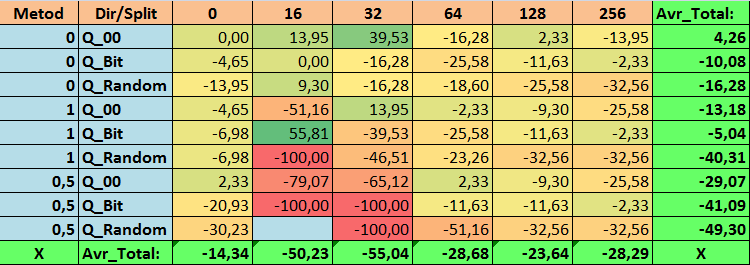
Tabela №18 "Valores consolidados do indicador N_Exam_Model"
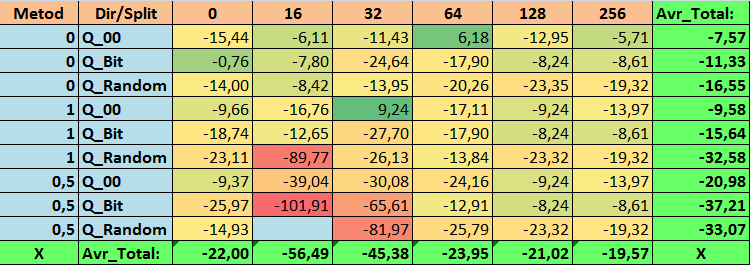
Tabela №19 "Valores consolidados do indicador Profit_Max"

Tabela №20 "Valores consolidados do indicador Q_Avr"
Ao revisar nossas tabelas informativas, pudemos ver que a variação dos indicadores é bastante significativa, o que indica o efeito das configurações em geral sobre o resultado do treinamento. Observamos que as tabelas obtidas por meio da colocação aleatória de splits (Q_Random) mostraram o pior resultado em relação às tabelas quantizadas criadas por outros métodos. É interessante notar que o aumento no número de splits geralmente leva à deterioração dos indicadores de nossas métricas, com exceção da métrica Recall_Avr. Isso provavelmente ocorre porque as informações nos segmentos quantizados estão muito dispersas, levando apenas a manipulações matemáticas durante o treinamento, o que resulta em aumento da confiança do modelo, mas uma queda na precisão e, subsequentemente, no lucro médio. Então, surge a pergunta justa "E como o modelo é treinado com sucesso com 254 splits por padrão?", o fato é que o método padrão utiliza uma abordagem de construção de grade como GreedyLogSum, que, como vimos antes, não constrói a grade com passos uniformes. Devido ao fato de a grade não ser construída uniformemente, a métrica frequentemente escolhida por nós para avaliar a qualidade da construção da grade mostra um resultado pior do que uma grade uniforme, resultando na rara escolha desse método ao selecionar tabelas quantizadas do conjunto obtido por todos os métodos do CatBoost. Até podemos verificar a estatística de quão frequentemente esse método foi escolhido. Assim, para a combinação (0; Q_00; 256) - isso foi apenas para 121 preditores de 2408. E por que as extremidades dos intervalos dos preditores acabam sendo tão significativas - escreva suas suposições nos comentários deste artigo!
Bem, tabelas com um grande número de splits e com colocação aleatória de splits mostraram um resultado não muito bom, mas o que podemos dizer sobre a diferença dos métodos de seleção de tabelas quantizadas? Comecemos pelo lado negativo - afinal, a exigência de erro de 0,5% acabou sendo excessiva para os valores de tabela de 16 a 64, resultando em significativamente menos preditores participando do treinamento do que inicialmente, mas ao mesmo tempo, tabelas com um maior número de splits conseguiram superar essa barreira, mas como já suspeitávamos, isso não foi eficaz. No entanto, ao escolher entre todas as tabelas disponíveis (primeiro conjunto - por ordem), obtivemos tabelas bem equilibradas, especialmente o conjunto das tabelas CatBoost. Ao mesmo tempo, o método de seleção de preditores que apresenta exigências menos rígidas - um mínimo de 1% de erro na aproximação, mostrou-se como uma solução que merece mais atenção.
Agora, vamos responder às perguntas levantadas - afinal, responder a essas questões é o objetivo deste experimento.
Respostas às perguntas:
1. A tabela de quantização padrão usada no CatBoost, objetivamente, mostra bons resultados em nossos dados, mas descobrimos que eles podem ser significativamente melhorados! Vamos considerar os indicadores de nossas métricas para os melhores métodos de obtenção de tabelas quantizadas:
- Profit_Avr - combinação (1;Q_Bit;16) com valor 32,22% melhor do que as configurações padrão.
- MO_Avr - combinação (1;Q_00;0) com valor 197,00% melhor do que as configurações padrão.
- Precision_Avr - combinação (1;Q_00;0) com valor 24,69% melhor do que as configurações padrão.
- Recall_Avr – várias combinações aqui, todas com valor 8,7% melhor do que as configurações padrão.
- N_Exam_Model - combinação (1;Q_Bit;16) com valor 55,81% melhor do que as configurações padrão.
- Profit_Max - combinação (1;Q_00;32) com valor 9,24% melhor do que as configurações padrão.
Assim, podemos objetivamente responder afirmativamente a esta pergunta - vale a pena tentar selecionar as melhores tabelas quantizadas, o que pode melhorar os resultados em métricas importantes para nós.
2. Descobriu-se que para nossa amostra, apenas 16 splits são suficientes para obter bons valores do indicador Q_Avr, assim para a combinação de configurações (1;Q_Bit;16) ele é 16,28, e para a combinação (0;Q_00;16) já é 18,24.
3. O método uniforme mostrou-se bastante aceitável, especialmente interessante é o fato de que ele permitiu obter mais modelos na combinação (1;Q_Bit;16), que é 55,81% mais do que as configurações padrão, e considerando que ele mostrou um dos melhores resultados em expectativa matemática - melhor do que as configurações padrão em 36,88%, acho que vale a pena usar este método ao escolher tabelas quantizadas e implementá-lo em outros projetos relacionados ao aprendizado de máquina. Quanto às tabelas obtidas pelo método de colocação aleatória de splits, este método deve ser usado com cautela, possivelmente de forma seletiva onde não é possível atender ao critério de seleção de tabelas quantizadas. Vale ressaltar que 10.000 opções podem ter sido insuficientes para encontrar a melhor divisão do preditor em segmentos quantizados.
4. Como os resultados do experimento mostraram - o método de seleção de tabelas quantizadas tem um impacto significativo nos resultados. No entanto, um único experimento não é suficiente para recomendar com confiança o uso de apenas um dos métodos. Diferentes métodos e suas configurações permitem que o modelo concentre atenção em diferentes segmentos de dados na amostra por meio da seleção de diferentes tabelas quantizadas, o que pode ajudar a encontrar a solução ótima.
Conclusão
Neste artigo, nos familiarizamos com o algoritmo de seleção de tabelas quantizadas e realizamos um grande experimento para avaliar a viabilidade de selecionar tabelas quantizadas. Outros métodos de pré-processamento de dados foram superficialmente considerados, sem análise de código ou avaliação da eficácia desses métodos, pois a realização de uma série de experimentos e a descrição de seus resultados exigiriam esforços significativos. Se este artigo for de interesse dos leitores, posso realizar mais experimentos e descrevê-los em outros artigos.
No artigo, não usei gráficos de saldo, embora existam modelos atraentes, mas recomendaria usar mais preditores para seleção e subsequente construção de modelos para negociação real nos mercados financeiros.
Para a seleção de tabelas quantizadas, foi usada a avaliação de aproximação, mas vale a pena tentar aplicar outras avaliações que podem medir a uniformidade e utilidade dos dados.
| № | Anexo | Descrição |
|---|---|---|
| 1 | Q_Error_Otbor.mq5 | Script responsável pelo pré-processamento de dados e pela seleção de tabelas quantizadas para cada preditor. |
| 2 | CB_Bat_v_02.mq5 | Script responsável pela geração de tarefas para treinar modelos usando o CatBoost - nova versão 2.0 |
| 3 | CSV fast.mqh | Classe para trabalhar com arquivos CSV, todos os direitos autorais do código pertencem a Aliaksandr Hryshyn. É necessário baixar os arquivos faltantes pelo link. |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13648
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso