
机器学习中的量化(第 2 部分):数据预处理、表格选择、训练 CatBoost 模型

本文探讨了量化在树模型构建中的实际应用,没有使用复杂的数学方程。这是“机器学习中量化和其他预处理输入数据的方法”文章的第二部分,因此我强烈建议您开始了解它。这里我们将讨论以下内容:
- 在第一部分中,我们将探讨用 MQL5 实现的预处理样本数据的方法。
- 在第二部分中,我们将进行一项实验,它将提供有关数据量化可行性的信息。
1.其它数据预处理方法
让我们使用描述 Q_Error_Selection 脚本功能的示例来探讨我已经实现的数据预处理方法。
简而言之,“Q_Error_Selection”脚本的目标是从“train.csv”文件加载样本,将内容传输到矩阵中,预处理数据,交替加载量化表,并评估每个预测器的恢复数据相对于原始数据的误差。每个量化表的评估结果都保存到数组中。检查完所有选项后,我们将为每个预测变量创建一个包含误差的汇总表,并根据给定的标准为每个预测变量选择最佳的量化表选项。让我们创建并保存一个摘要量化表,这是一个具有 CatBoost 设置的文件,从训练列表中排除的预测因子将与其列的序列号一起添加到其中。此外,根据选定的脚本设置创建附带文件。
让我们仔细看看我下面按组列出的脚本设置。
加载数据
- 样本目录1
- 量化目录2
1 指示包含样本的 csv 文件所在设置目录的目录路径。下文中将该目录称为“项目目录”。
2 指示包含带有量化表的 csv 文件所在 Q 目录的目录的路径。
配置尖峰值处理
- 使用尖峰值检查1
- 尖峰值转换方式:2
- 尖峰值转换为接近分割点 2.1的值
- 尖峰值转换为尖峰2.2范围之外的随机值
- 处理尖峰值后替换数据3
- 保存/不保存带有转换尖峰值的“训练”样本4
- 向子样本添加有关尖峰值的信息5
- 删除有大量尖峰值的行5.1
- 样本字符串中预测异常值的最大百分比5.2
1 当选择“true”时,尖峰值处理被激活。预测因子的罕见值在此被视为尖峰值。罕见值可能在统计上不显著,但模型通常不会考虑到这一点,这可能导致评估分类概率的规则值得怀疑。图 1 显示了这种尖峰值。通过设置分离尖峰和正常数据的边界,我们将能够将异常值聚合为一个整体,从而提高统计可靠性,我们可以尝试像处理正常数据一样处理数据,或者将其完全排除在训练之外。
2 选择一种尖峰值变换方法,借助该方法,预测器的值将被改变,从而允许在训练样本中考虑该示例,而不是作为异常示例排除。为了确定尖峰值,我使用了数字序列每一侧 2.5% 的数据。将之前遇到的相同数字值分组,并为每组分配排名。如果下一个排名超过 2.5%,那么前一个排名将被视为具有尖峰值的最后一个排名。等级较少的预测器被视为分类型的并且不能处理峰值,以分类预测变量列表形式的信息保存在相对于“..\CB\Categ.txt”项目目录的以下路径中。识别尖峰的常用方法是 3-sigma 规则,即当从数据区域左侧和右侧的平均值缩进三个标准差时,该边界之外的所有内容都被视为尖峰值。在下图中,您可以看到三条黑色水平线 - 中心、差异以及距中心三个 sigma 的总和。根据我提出的算法,图表上的蓝线将指示边界,频繁出现的数据位于该边界内。
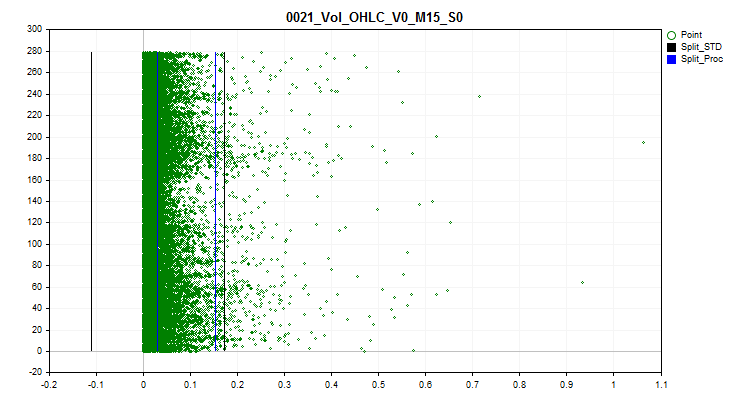
图 1.确定尖峰值定义限值
2.1 该方法将所有尖峰值替换为接近边界(分裂)的值。这种方法使得不会扭曲尖峰边界内的量化表近似估计。
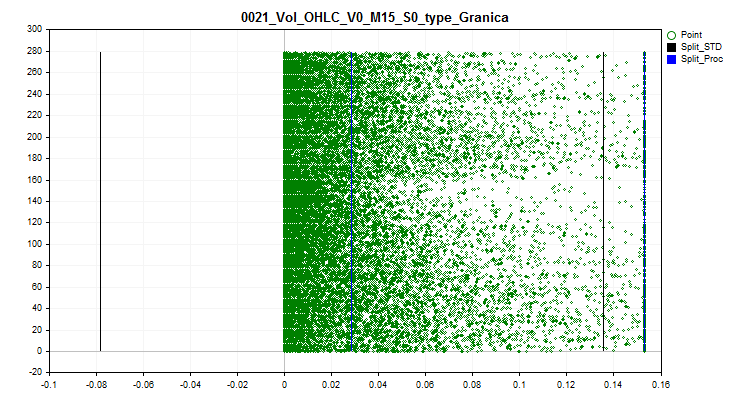
图 2.将尖峰值转换为接近分隔点的值
2.2 该方法根据正常数据边界内的等级,将所有尖峰值替换为随机值。这种方法可以消除通过量化表估计近似值的误差。
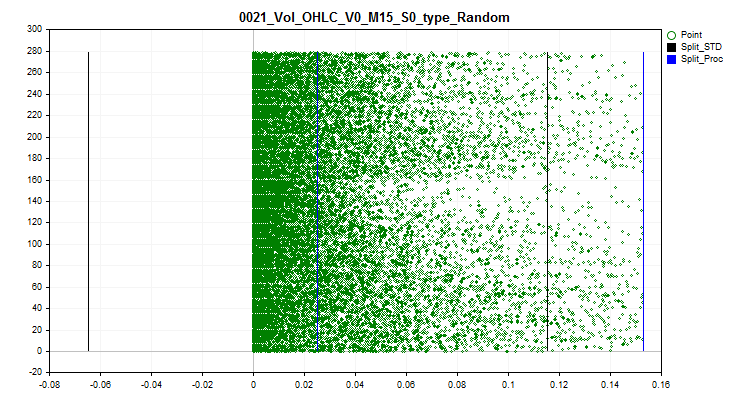
图 3.将尖峰值转换为尖峰范围之外的随机值
3 如果需要考虑转换后的尖峰值来评估和选择量化表,则选择“true”。当激活该函数时,包含原始数据的矩阵形式的数组将被改变,带有尖峰值的预测因子的值将被设置为根据尖峰变换方法选择的值。
4 您可以保存train.csv样本。它将被保存到“..\CB\Q_Vibros_Viborka”目录。这可能是使用 CatBoost 进行量化所必需的。由于数据已经被更改为转换后的数据,量化表可能会有所不同,这也可能允许减少分离器(分割点)的数量,以在评估量化表的近似质量时实现最小误差阈值。
5 激活此参数并将变量设置为“true”将会按顺序加载包含 train.csv、test.csv 和 exam.csv 子样本的文件。在子样本的每一行中,将计算尖峰值区域中的预测值的数量,并将总结果记录在额外创建的“Proc_Vibros”列中。改变的选择将保存到“..\CB\ADD_Drop_Info_Viborka”目录。
无论此设置是否激活,都会在项目目录中创建一个单独的文件“ ..\CB\Proc_Vibros_Train.csv”。该文件仅包含有关“train”样本中的尖峰值的信息。
5.1 激活此设置将从选择中删除带有尖峰值的行。有时值得尝试在没有尖峰值的数据上训练模型。
5.2 如果您决定删除包含异常值的行,则值得评估值位于尖峰定义区域内的预测因子的百分比。
配置相关性估计
- 使用相关性估计消除预测因子 1
- 排除相关预测因子的方法定义了可供选择的选择方法(排除预测因子):2
- 预测因子的后向选择2.1
- 选择泛化预测因子2.2
- 选择稀有预测因子2.3
- 相关比率3
1 当选择“true”时,Pearson 相关性估计被激活。此功能的结果将是获得“../CB”处的预测相关表,其中文件名由“Corr_Matrix_”名称和“Corr_Matrix_70.csv”相关比率大小组成。高度相关的预测因子将被排除。
2 有三种预测排除方法可供选择。
2.1 该方法以相反的顺序搜索相关的预测因子,如果存在更早的预测因子,则将具有该预测因子的当前列排除在训练之外。
2.2 该方法估计与每个预测因子相关的预测因子的数量,并迭代地选择与大量预测因子相关的预测因子,从而消除与其相关的其他预测因子。这里的逻辑是,我们选择具有包含有关其他预测因子的最多信息的预测因子。这样,我们就获得了数据的泛化。
2.3 此方法与前一种方法类似,但在这里我们选择与其它预测因子最不相似的预测因子。这里尝试做相反的事情——找到具有独特数据的预测因子。
3 这里我们应该标明 Pearson 相关比率。仅当达到或超过指定的比例值后,预测因子才被视为相似,从而可以将其排除在样本之外。
配置处理时间不稳定预测因子
- 使用测试样本 1中各部分的平均值
- 子样本平均扩散百分比2
1当选择“true”时,将激活对样本中每 1/10 部分中预测指标平均值波动的检查。该检验可以排除那些指标随时间发生很大变化的预测因子。从理论上来说,这样的预测因子会阻碍训练。图 4 中可以看到这种预测因子的一个示例,图 5 中可以看到可视化评估。示例预测因子是基于可变指数动态平均值 (iVIDyA) 指标构建的,该指标实际上显示的是平均价格值,在模型中使用该指标将导致以某个绝对价格进行的训练行为。
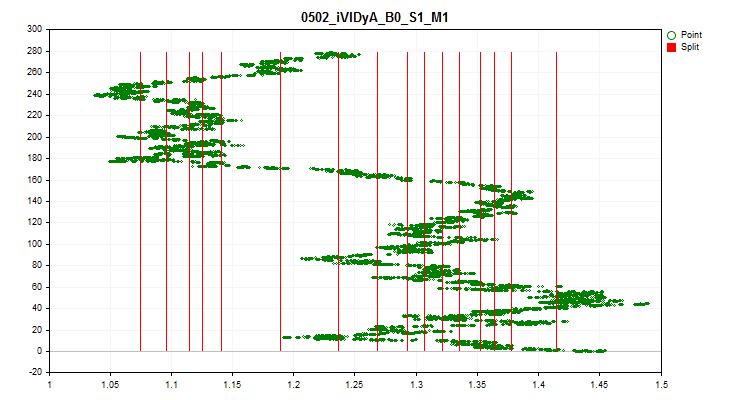
图 4.iVIDyA_B0_S1_M1 预测因子显示出相当大的转换
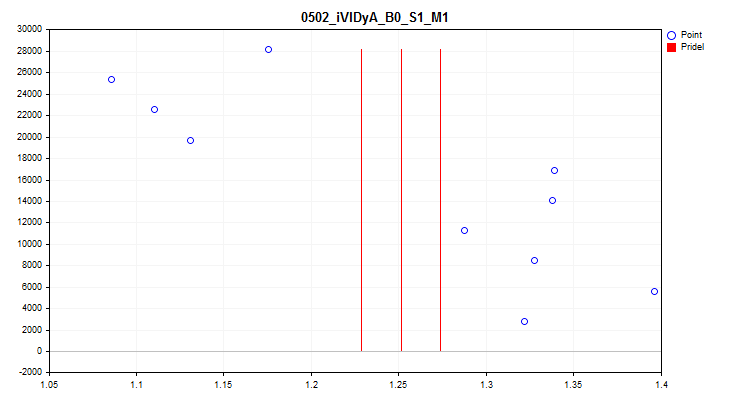
图 5.iVIDyA_B0_S1_M1 预测因子(平均散布)
2 这里,范围的宽度被指示为每个边界的百分比,该百分比由整个预测值范围相对于整个期间的平均值确定。
配置统一量化表的创建
- 创建统一量化表1
- 原始数据应划分(量化)成的间隔数2
1 当选择“true”时,将激活为样本中的所有预测因子创建统一量化表的算法。该表将保存到 Q_Bit 项目子目录。
2 设置预测因子将被划分的区间数。
配置具有随机性元素的量化表的创建
- 创建随机量化表1
- 随机数生成器的初始数字 2
- 找到最佳选项的迭代次数3
- 原始数据应划分(量化)成的间隔数4
1 当选择“true”时,将激活为样本中的所有预测因子创建随机量化表的算法。该表将被保存到 Q_Random 项目中。
2 该数字使得随机生成的结果可重复,通过改变数字,我们可以改变生成的数字的顺序。
3 该算法在每次生成随机表后评估近似误差并选择最佳选项。尝试的次数越多,找到最成功选项的机会就越大。
4 设置预测因子将被划分的区间数。
配置量化表的选择
- 开始选择量化表1
- 使用阈值选择预测因子2
- 最大允许的量化误差3
1 当选择“true”时,从项目的Q子目录中搜索和评估量化表的算法被激活,否则程序停止工作。执行此脚本函数的结果将创建两个目录:
“..\CB\Setup” 目录包含 3 个文件:
- Auxiliary.txt – 包含被排除的预测因子索引编号的辅助文件
- Quant_CB.csv – 包含参与训练的预测因子的量化表的文件
- Test_CB_Setup_0_000000000 – 包含 CatBoost 信息的文件 – 要从训练中排除的列和要被视为目标的列。
Test_Error 目录将包含 arr_Svod.csv 文件。它包含使用不同量化表时计算每个预测因子的重建(近似)误差的汇总结果。第一列包含预测因子列表,即应用特定量化表时的后续结果,而最后一列包含显示最佳结果的量化表的索引。最佳结果用于创建 Quant_CB.csv 摘要量化表。
2 如果为“false”,则仅使用重建(近似)误差来评估量化表,并选择产生最小误差的表。
如果为“true”,则重建(近似)误差除以量化表中的分割数用于评估量化表。这种方法使我们能够在估算过程中考虑量化表的数量,以避免过度量化。只有当表的误差低于下一个设置参数中指定的误差时,表才会参与选择。
3 这里我们指出了重建(近似)预测因子的最大可接受误差。
配置保存转换后的选择
- 转换并保存样本1
- 数据转换选项:2
- 保存为索引2.1
- 保存为质心2.2
1 如果为“true”,则样本(三个 csv 文件)将被转换并保存到“..\CB\Index_Viborka”项目子目录中。此设置使得在最初未提供量化表的机器训练算法中使用量化表成为可能。另一个用例是公开共享模型训练数据,而不披露预测因子得分,以防止有关所用数据源的竞争信息被披露。此外,以索引的形式保存可以显著减少样本文件占用的磁盘空间量,以及减少用于操作样本的 RAM 量。
2 应用最终量化摘要表后,选择两个选项之一来转换预测因子。
2.1 保存预测因子所属的量化表段的索引。
2.2 保存预测因子所在的两个边界之间的值。
配置图表保存
- 保存图表1
- 图形宽度2
- 图形高度3
- 图例中的字体大小4
1如果为“true”,则激活创建和保存图表的功能。将在 Graphics 目录中创建包含样本中每个预测因子信息的图形文件。文件名以预测因子编号开头,后跟样本列标题中的预测因子名称和条件图名称。让我们看一下 iCCI_B0_S1_M1 预测因子获得的图表:
- 第一个图表显示了特定间隔内的预测因子密度 - 密度越高,图表曲线在此间隔上的向上倾斜越强烈。X 轴是预测值,Y 轴是按其值排序的观测数。利用图表,我们可以估计样本中落在特定间隔内的观测值的密度并查看尖峰值。
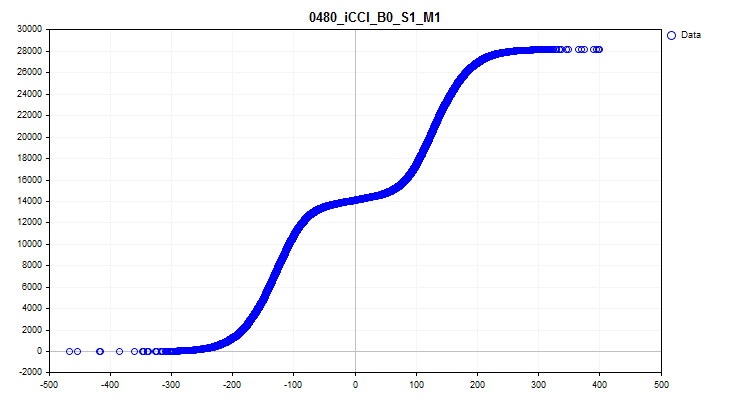
图 6.预测因子值的密度
- 第二张图表显示在目标“0”和“1”处观察到的预测因子值的间隔。因此,“0”的值显示为蓝色,而“1”的值显示为红色。因此,可以看到在哪些预测因子区间内目标值能够得到更大程度的体现。我建议构建一个比这里显示的图表更宽的图表。
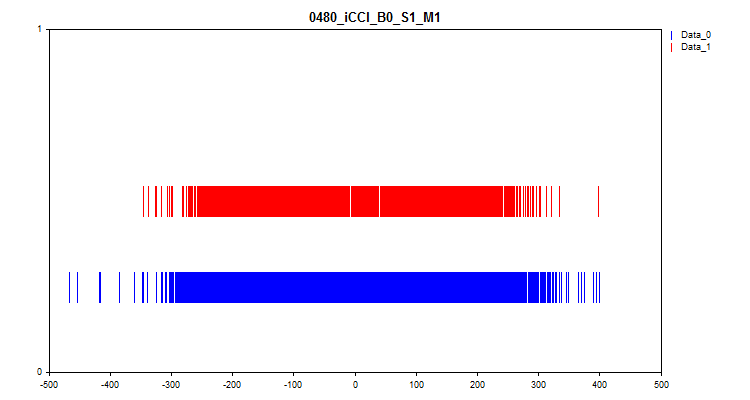
图 7.预测因子值与目标标记的对应关系
- 第三张图表构建了一个直方图,其中 Y 轴绘制了样本中所有观测值的百分比。该图表可以帮助我们评估尖峰值并对分布密度做出假设。
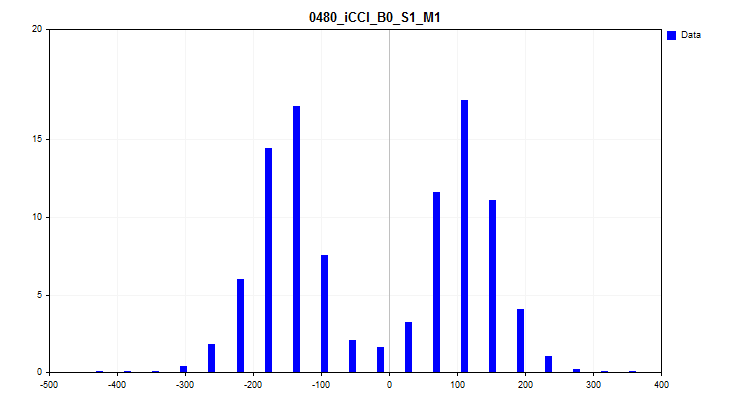
图 8.分布密度直方图
- 第四张图显示了预测因子尺度范围按时间顺序填充的值,还显示了为最终量化选择的级别。X 轴是预测变量的值,Y 轴是 100 个观测值的组的数量。
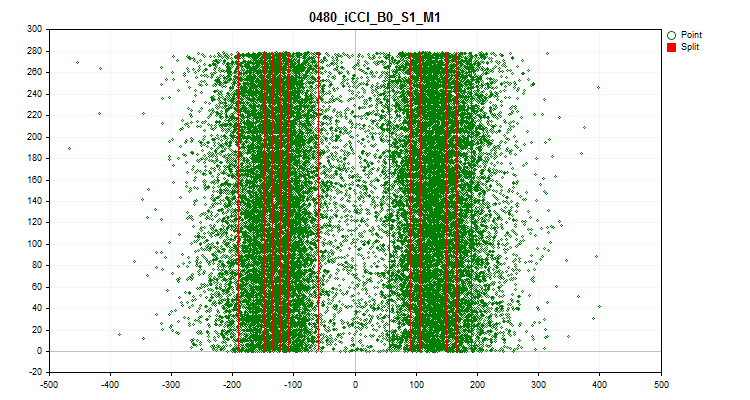
图 9.量化表
- 第五张图显示了 10 个采样间隔的平均预测因子值。如果存在强烈的分散,建议排除预测因子。X 轴是预测变量的值,Y 轴是 N 个观测值的组的数量。
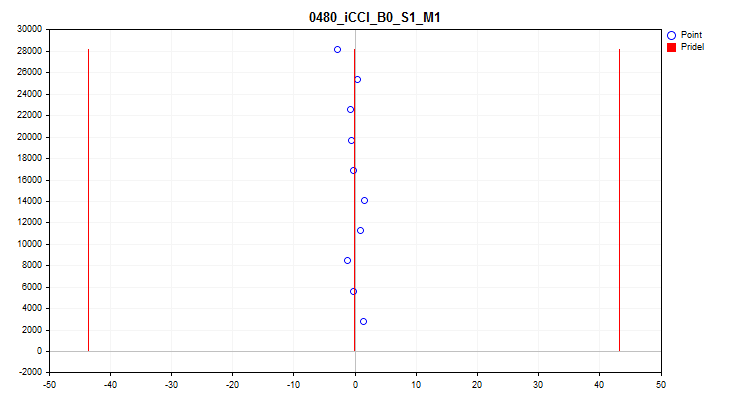
图 10.平均值的散布
- 第六张图显示了估计的尖峰值。图表上有 3 条黑线 - 这是平均值,以及正负三个标准差。蓝色边界是从样本范围的开始和结束测量的接近 2.5% 的观测值。X 轴是预测变量的值,Y 轴是具有固定观测值数量的组的数量。
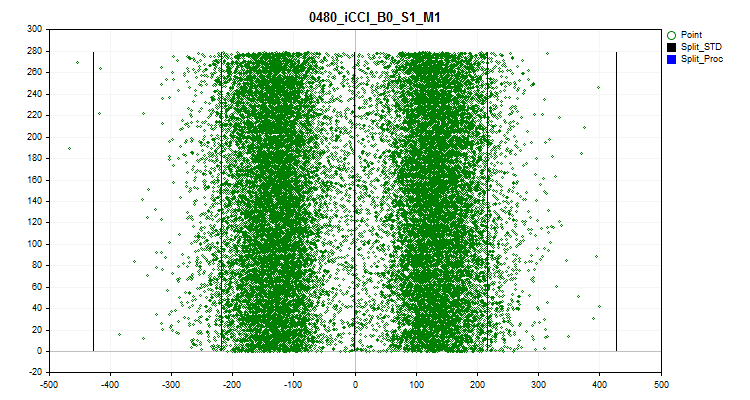
图 11.尖峰值
2 图形宽度(以像素为单位)。
3 图形高度(以像素为单位)。
4 图表图例中的字体大小和曲线符号的大小。
配置设置场景的搜索
- 进行场景设置1
1根据嵌入算法激活设置搜索。了解下面的详细信息。
2.进行比较实验以评估量化的效果
设置实验 - 目标
我们有一个功能相当强大的工具,现在是时候评估它的功能了!让我们进行一个实验来回答以下紧迫的问题:
- 通过为预测因子选择量化表,所有这些行动和操作是否有意义?也许使用默认的 CatBoost 设置会更容易?
- 需要多少个最小分割(边界)才能达到与默认 CatBoost 设置类似的结果?
- 我们是否应该使用量化方法,例如“均匀”和“随机”?
- 量化表选择方法之间有显著差异吗?
为了回答这些问题,我们需要使用 Q_Error_Selection 脚本的不同设置获得的不同量化表进行训练。我建议尝试以下设置:
选择方法:
- 仅使用重建(近似)误差来评估量化表。
- 重建(近似)误差除以量化表中的分割数用于评估量化表。最大误差为 1%。
- 重建(近似)误差除以量化表中的分割数用于评估量化表。最大误差为0.5%。
量化表来源:
- 使用 CatBoost 获得的表。
- 通过均匀量化方法获得的表。
- 使用随机分割方法获得的表。
量化表设置:
- 设置为“1”-使用源目录中所有可用的量化表。
- 设置为“2”-仅使用具有 16 个分割或间隔的量化表。
- 设置为“3”-仅使用具有 32 个分割或间隔的量化表。
- 设置为“4”-仅使用具有 64 个分割或间隔的量化表。
- 设置为“5”-仅使用具有 128 个分割或间隔的量化表。
- 设置为“6”-仅使用具有 256 个分割或间隔的量化表。
所有设置组合均以图 12 的形式显示在表格中。在代码中,此任务以三个嵌套循环的形式实现,通过将设置中名为“Iterate through settings scenarios”的变量设置为“true”来改变激活的相应设置。
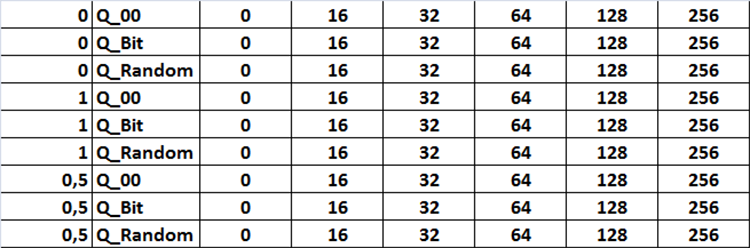
图 12.搜索设置组合表
我们将使用每种设置组合训练 101 个模型,以 8 的步长将种子参数从 0 移动到 800,这将使我们能够对获得的结果取平均值以评估设置,从而排除随机结果。
这些是我建议用于比较分析的参数:
- Profit_Avr - 所有模型的平均利润;
- MO_Avr - 模型的平均数学期望;
- Precision_Avr - 模型的平均分类精度;
- Recall_Avr - 模型召回的平均完整性;
- N_Exam_Model - 利润超过3000个单位的模型平均数量;
- Profit_Max - 所有模型的平均最大利润。
在计算完指标之后,我建议把它们加起来,然后除以指标的数量。这样,我们将获得一个设置量化表选择的质量的总体指标 - 我们简单地称之为 Q_Avr。
准备实验数据
为了获得样本,我们将使用之前在文章“无需学习 Python 或 R 即可从 Yandex 获得 CatBoost 机器学习算法”中熟悉 CatBoost 时使用的相同 EA 和脚本。
我使用了以下设置:
A.测试器设置:
- Symbol: EURUSD
- Timeframe: M1
- Interval from 01.01.2010 to 01.09.2023
B.CB_Exp EA策略设置:
- Period:104
- Timeframe:2 Minutes
- MA method: Smoothed
- Price calculation base: Close price
收到样本并将其分为 3 个部分(训练、测试、检验)后,我们需要以与我之前在文章中描述的方式类似的方式获取量化表。为了实现这一点,我修改了 CB_Bat 脚本(附于本文)。现在,在“Search object”设置中选择 Brut_Quantilization_grid 时,脚本会创建 _01_Quant_All.txt 文件。搜索范围的设置保持不变 - 设置变量的初始值和最终值以及变化步长。我使用从 8 到 256 的搜索,步长为 8。脚本运行的结果是,获取所有类型的量化表的命令将以指定数量的边界来准备。量化表文件将具有以下命名结构:“quant”语义文件名形式的文件名、分隔符数量和划分类型的序号。参数将以下划线链接,文件本身将保存在 Q 目录中,该目录与项目设置目录相同。
quant_"+IntegerToString(Seed,3,'0')+"_"+IntegerToString(ENUM_feature_border_type_NAME(Q),0)+".csv";
运行脚本后,将生成的_01_Quant_All.txt文件的扩展名更改为*.bat,将脚本中先前指定的 CatBoost 版本放在文件目录中,然后双击运行该文件。
当脚本完成其工作时,Q 子目录中会出现一组文件 - 这些是我们将继续使用的量化表。
图 13.Q 子目录内容
使用 Q_Error_Otbor 脚本,生成间隔数为 16、32、64、128 和 256 的均匀和随机量化表。相应的文件将出现在 Q_Bit 和 Q_Random 目录中。将 Q 目录复制到项目目录中,并将新目录命名为 Q_00。
现在我们已经拥有创建训练任务包所需的一切。启动 Q_Error_Otbor 脚本,将“Search settings scenarios”参数切换为“true”,然后单击“Ok”。该脚本将根据代码中指定的场景创建包含量化表和训练设置的文件。
为了在训练期间对 CatBoost 设置的每个配置使用量化表,脚本将设置文件的名称添加到“Quant_CB.csv”量化表的名称中。
让我们使用 CB_Bat_v_02 脚本获取用于训练的文件。我选择以8为步长从0到800搜索种子,并指明项目目录。
现在我们需要稍微编辑一下训练文件,将文件名 Quant_CB.csv 替换为 Quant_CB_%%a.csv。这一变化将允许我们使用设置的名称作为变量,其数量决定了训练周期的数量。将创建的文件复制到 Setup 项目目录,通过将文件 _00_Start.txt 重命名为 _00_Start.bat 并双击 _00_Start.bat 来开始训练。
实验结果评估
训练完成后,我们将使用 CB_Calc_Svod 脚本来计算每个模型的指标。脚本的设置在之前的 文章中已经详细描述过了,就不再重复了。
我还使用默认的量化表设置训练了 101 个模型。结果如下:
- Profit_Avr=2810.17;
- МО_Avr=28.33;
- Precision_Avr=0.3625;
- Recall_Avr=0.023;
- N_Exam_Model=43;
-
Profit_Max=8026。
在得出总的结论之前,让我们仔细看看每个参数的结果表和图表。
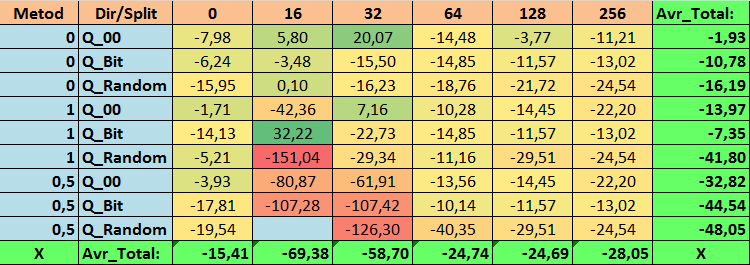
表 14.Profit_Avr 参数的汇总值
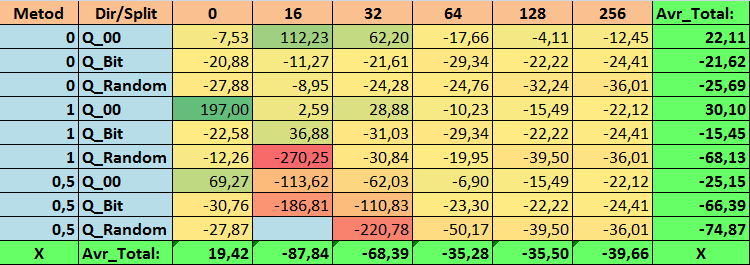
表 15.MO_Avr 参数的汇总值
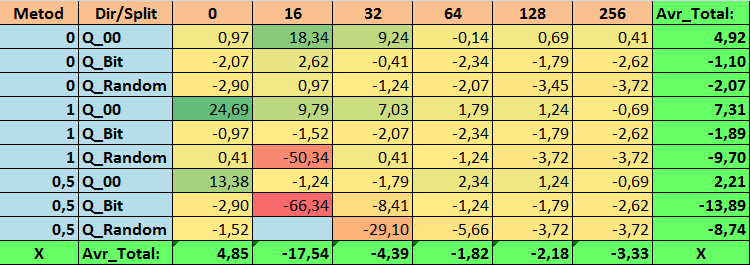
表 16.Precision_Avr 参数的汇总值
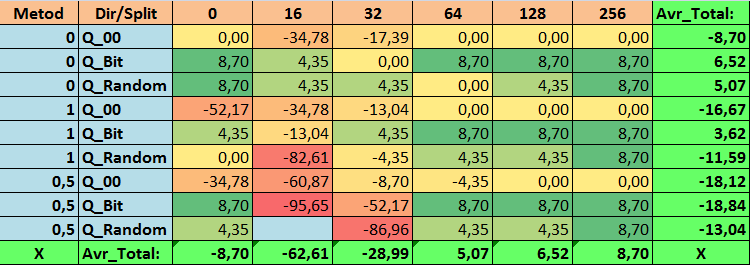
表 17.Recall_Avr 参数的汇总值
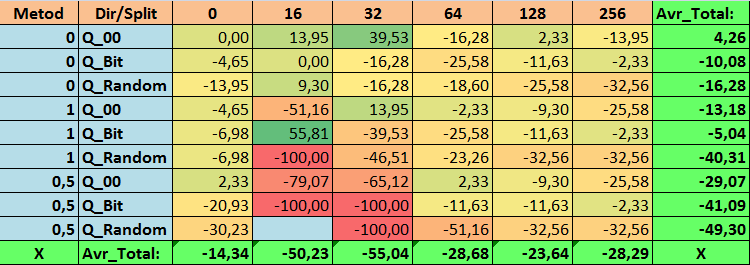
表 18.N_Exam_Model 参数的汇总值
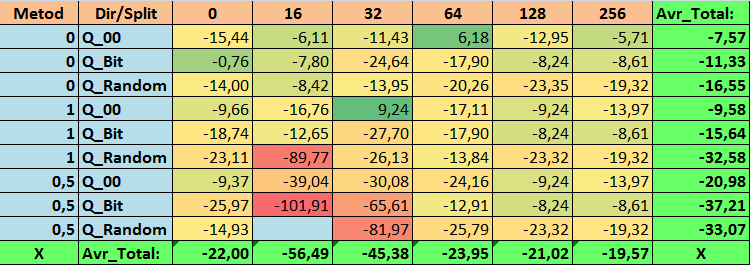
表 19.Profit_Max 参数的汇总值

表 20.Q_Avr 参数的汇总值
查看了我们的信息表后,我们可以看到参数的分布相当大,这表明了整体设置对训练结果的影响。我们看到,通过随机设置分割(Q_Random)获得的表相对于通过其他方法创建的量化表显示出最差的结果。有趣的是,分割数量的增加通常会导致我们的指标性能下降,Recall_Avr 指标除外。这可能是因为量化段中的信息高度分散,这不仅导致训练期间的数学操作(最终导致模型置信度的增加),而且导致准确度的下降,进而导致平均利润的下降。你可能会问,“默认情况下,使用 254 个分割,模型如何成功训练?”事实上,我使用了名为 GreedyLogSum 的默认网格构造方法,正如我们之前看到的,该方法并不以均匀的步长构造网格。由于网格构建的不均匀,我们经常选择的评估网格构建质量的指标显示的结果比均匀的网格更差。因此,在从所有 CatBoost 方法获得的集合中选择量化表时,我们很少选择 GreedyLogSum 这样的方法。我们甚至可以查看选择该方法的频率的统计数据。例如,在 (0;Q_00;256) 组合的情况下,这仅适用于 2408 个预测因子中的 121 个。为什么预测范围的极值部分会变得如此重要?请在评论中写下你的假设!
分割次数较多且分割设置方法随机的表格并没有显示出很好的结果。但是,选择量化表的方法有什么不同呢?我们先从坏消息开始吧。对于表值 16 至 64 而言,0.5% 的误差要求太高了。结果,参与训练的预测因子明显少于最初的数量,但与此同时,具有大量分割的表成功突破了这个阈值,但正如我们已经提到的,这并不高效。但是,从所有可用表中进行选择时,结果是相对均衡的表(尤其是 CatBoost 表集)。同时,对于要求不太严格的预测因子的选择方法(近似值误差至少为 1%)已被证明是一种值得更多关注的解决方案。
现在让我们继续回答所提出的问题——毕竟,回答这些问题是这个实验的目标。
答案:
1.CatBoost 中的默认量化表在我们的数据上客观地显示出良好的结果,但事实证明它还可以显著改善!让我们看看获取量化表的最佳方法的指标:
- Profit_Avr - (1;Q_Bit;16) 组合超过基本设置 32.22%。
- MO_Avr - (1;Q_00;0) 组合超过基本设置 197.00%。
- Precision_Avr - (1;Q_00;0) 组合超出基本设置 24.69%。
- Recall_Avr - 这里有很多种组合。全部都超出基本设定8.7%。
- N_Exam_Model - (1;Q_Bit;16) 组合超出基本设置 55.81%。
- N_Profit_Max -(1;Q_00;32)组合超过基本设置 9.24%。
因此,我们可以客观地对这个问题作出肯定的回答。值得尝试选择最佳的量化表,这可以改善对我们很重要的指标的结果。
2.事实证明,对于我们的样本,仅 16 次分割就足以获得 Q_Avr 参数的良好值。例如,如果 (1;Q_Bit;16),它等于 16.28,而如果 (0;Q_00;16),它等于 18.24。
3.事实证明,这种均匀分割的方法非常有效。特别有趣的是,它使我们能够获得具有 (1;Q_Bit;16) 组合的最多模型,这比基本设置高出 55.81%。鉴于它在数学期望方面表现出最好的结果之一,超出基本设置 36.88%,我认为在选择量化表并将其应用于其他与机器学习相关的项目时,值得使用此方法。对于通过随机分割方法获得的表,在无法通过选择量化表的给定标准的阈值的情况下,应谨慎(可能有选择地)使用这种方法。10000 个选项可能不足以找到将预测因子最佳地划分为量化段的方法。
4.实验结果表明,量化表的选择方法对结果有显著的影响。然而,一次实验不足以自信地推荐仅使用其中一种方法。不同的方法及其设置使得模型通过选择不同的量化表将注意力集中在样本中数据的不同部分,从而有助于找到最优解决方案。
结论
本文介绍了选择量化表的算法,并进行了大量实验来评估选择量化表的可行性。对其他数据预处理方法进行了粗略的回顾,没有分析代码,也没有评估这些方法的效率。进行一系列实验并描述其结果是一项劳动密集型任务。如果读者对这篇文章感兴趣,那么我可能会在其他文章中进行实验并提供描述。
我在文章中没有使用余额图。虽然有一些不错的模型示例,但我建议使用更多的预测因子来选择并随后构建金融市场真实交易的模型。
近似分数用于选择量化表,但值得尝试其他可以评估数据同质性和有用性的分数。
| # | 应用程序 | 描述 |
|---|---|---|
| 1 | Q_Error_Otbor.mq5 | 负责数据预处理和每个预测器量化表选择的脚本。 |
| 2 | CB_Bat_v_02.mq5 | 负责使用 CatBoost 生成训练模型任务的脚本 - 新版本 2.0 |
| 3 | CSV fast.mqh | 用于处理 CSV 文件的类,程序代码的所有版权均属于Aliaksandr Hryshyn。您需要 在此处下载缺失的文件。 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/13648
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 如何利用 MQL5 创建简单的多币种智能交易系统(第 4 部分):三角移动平均线 — 指标信号
如何利用 MQL5 创建简单的多币种智能交易系统(第 4 部分):三角移动平均线 — 指标信号