모르겠어. 먼저 VR 모델을 식별해야 합니다. 여기에는 작동하는 것부터 모델이 작동하지 않는 것까지 다양한 매개변수가 있는 추세, 주기, 노이즈가 포함될 수 있습니다. Box는 매개변수 세트가 다른 여러 모델을 고려합니다. 적어도 그가 Boxing으로 식별한 것을 취하고 Hurst를 계산하면 동일한 Hurst이거나 다른 값이나 알고리즘으로 다를 것입니다. 나는 여러 포럼과 문헌에서 Hurst를 계산하려는 시도를 보았습니다. 실행 가능한 하나가 아닙니다. 이것은 위의 생각으로 이어졌습니다.
나는 당신의 "일할 수 있는 사람이 하나도 없다"는 것이 부끄럽습니다. "... 그리고 문학에서"라는 단어 뒤에. 문헌에는 서로 약간 다른 결과를 제공하는 다양한 접근 방식이 있으며, 이는 놀라운 일이 아닙니다. 이것은 모두 추정치입니다. 그러나 표본이 클수록 이러한 추정치가 더 정확해야 하고 서로 더 "동일"해야 한다는 것도 사실입니다. 포럼에서 실행 가능한 Hurst 알고리즘을 찾기가 어렵다는 사실에만 동의합니다.
알고리즘의 입력에 무엇을 제출할 것인지에 관해서는 알고리즘은 신경 쓰지 않습니다. 가격을 제출하십시오 - 주위에 무언가를 얻으십시오. 그래도 알고리즘의 본질상 가격은 장기기억이 강하기 때문에 원래 값에서 비교적 멀리 떨어져 있습니다. 가격 증분 제출 - 0.5와 같은 값을 얻습니다. 이는 다시 정당화되기 때문입니다. 그들의 비교 변화는 크고 거의 무작위입니다. 추세 및/또는 주기를 일치시키십시오 - 지속성을 얻으십시오. 노이즈는 일반적으로 지수를 줄입니다. 질문은 "우리 가격이 시끄럽습니까 아니면 정직한 시장 가격입니까?"입니다. - 이것은 Hurst 알고리즘의 주제가 아니라 다른 영역입니다.
1. 프로세스에는 "안정된" 허스트 지수가 있습니다. 저것들. 표시기는 일정하며 시간이 흘러도 변하지 않습니다(전체 프로세스가 존재하는 동안). 이 경우 이를 결정하기 위해 적어도 통계적으로 중요한 영역, 즉 프로세스 분포를 자신 있게 평가할 수 있는 섹션입니다. 또는 귀찮게하지 않고 가능한 한 많이.
2. 표시기는 매우 복잡하고 무작위일 수 있는 기능입니다. 이 경우 VR의 길이를 선택하는 객관적인 기준은 없습니다. 일반적인 경우에 대한 지표의 평가는 심령이 아닌 경우 시간 또는 주파수 영역에서 불가능합니다.
중요하게도, RS 분석은 가장 조잡한 방법 중 하나이며 추정치는 항상 편향되어 있으며 표본 크기는 어떤 식으로도 도움이 되지 않습니다. Hurst 지수의 정확한 계산을 얻으려면 웨이블릿 기반 추정을 사용하십시오(알고리즘은 예를 들어 Mathlab에서 찾을 수 있음).
_Forex19_>> : Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда. Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы. Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо! PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
가격에 허스트 ~ 1,하지만 그것은 무엇입니까?
이 경우 내가 도울 수 있는 유일한 것은 _hurst_classik 파일에 Hurst 또는 R/S 분석이 없다는 점을 지적하는 것입니다. 시리즈의 리스케일링에서 "R / S"라는 이름의 본질. _RS_Analiz에 대한 주장이 있는 _hurst_classik의 텍스트에서는 재조정이 수행되지 않지만 예를 들어 최고가와 최저 가격의 차이는 진부합니다.
또한 R/S 분석은 Hurst에 도달하기 위해 곡선의 기울기를 계산하는데, 이를 위해서는 각 막대의 log(R/S) - log(n) 평면에 한 점이 아니라 여러 점이 필요합니다. . 같은 기적 _RS_Analiz'에는 그런 것이 전혀 없습니다.
ARFIMA 클래스(매개변수) 또는 이와 유사한 모델에 대해 이야기하는 경우 실제로 이것은 흥미롭지 않습니다. 왜냐하면 왜냐하면. 이 모델은 "nakui"를 성장시키며, 그 목적은 투자 자금을 모으기 위한 것입니다. 이러한 "과학"을 캐비닛 과학이라고 합니다. 그들은 과학적 근거를 분명히 원하는 결과, 일반적으로 가격 예측으로 조정하기 위해서만 만들어집니다.
ARFIMA 클래스(매개변수) 또는 이와 유사한 모델에 대해 이야기하는 경우 실제로 이것은 흥미롭지 않습니다. 왜냐하면 왜냐하면. 이 모델은 "nakui"를 성장시키며, 그 목적은 투자 자금을 모으기 위한 것입니다. 이러한 "과학"을 캐비닛 과학이라고 합니다. 그들은 과학적 근거를 분명히 원하는 결과, 일반적으로 가격 예측으로 조정하기 위해서만 만들어집니다.
우리는 평가하지 않을 것입니다. 이제 우리는 VR 모델을 사용하고 전혀 사용하지 않는 접근 방식에 대해 이야기하고 있습니다.
나는 전체 스레드를 처음부터 끝까지 읽었습니다. 예, 존경받는 전문가부터 평범한 구경꾼에 이르기까지 모든 사람 이 Hirst가 무엇이며 어떻게 고려되고 해석되어야 하는지에 대한 자신의 의견을 가질 것이라고 기대하지 않았습니다. 원본에 가장 가까운 것은 Eric Nyman의 기사 와 책 입니다. 그러나... 러시아에서는 Peter의 책에 나와 있는 그래프를 생성하기 위한 적절한 도구가 아직 없습니다.
1. 1950년 1월 1일부터 1988년 1월 7일까지의 S&P 500 월간 주식 차트를 사용합니다.
2. 우리는 그것들을 기술 분석 프로그램에 로드합니다(저는 WealthLab과 C#를 사용합니다. 이하 WL/C# 코드를 줄 것입니다)
3. Peters의 책에 제시된 공식에 따라 가격을 수익률로 변환해 보겠습니다.
4. Peters 자신은 수익률이 계산된 후 다시 누적된 시리즈로 변환된다고 언급하지 않습니다. . 그러나 이것은 R/S 범위의 값을 기반으로 하는 것이 분명합니다. 게다가 소스 도 명시적으로 이렇게 말합니다. "각 자연 n에 대해 값을 구성할 것입니다. (위의 공식 참조) 결과 부분 수열의 다음 수치적 특성을 계산하십시오."
5. 결과 시리즈를 k 기간으로 나누고 각 기간의 길이는 6개월에서 231개월까지 N입니다.
6. 이제 중요한 점입니다. 정수의 기간을 얻지 못하면(사용하지 않은 데이터가 남음) 폐기됩니다. 그러나 나머지가 너무 크면(예: 나머지가 462 / 232 = 233이고 230) 잘못된 값을 얻습니다. 제가 알기로는 Peters는 shift를 사용하지만 이것은 프로그래밍 측면에서 매우 힘든 옵션이며 나머지가 6보다 크면 마침표를 버립니다. 인접한 기간은 거의 동일한 R/S 값을 가지므로 이것은 올바른 옵션.
7. 다음으로 R은 다음 공식으로 계산됩니다.
8. R은 표준 편차(WL 표시기로 계산)로 나누어 로그화: log10(R/S).
9. 현재 기간은 로그입니다. log10(N);
10. log10(R/S) 대 log10(N)의 결과 비율이 파일에 입력됩니다.
옵티마이저가 N을 6(Peters와 같은)에서 231(최소 실험 횟수는 2)까지 정렬하면 이중 로그 스케일의 두 열 테이블을 얻습니다. 1. 기간 2. R/S 값.
이제 재미가 시작됩니다. 이 테이블을 엑셀로 작성하면 다음과 같이 나옵니다.
원본은 오른쪽에 표시됩니다. 보시다시피 약간의 유사점이 있지만 여전히 동일하지는 않습니다. 특히 초기 지표는 다소 과대 평가된 것으로 밝혀졌으며(0.33 대 약 0.31), 두 번째로 최종 값이 갑자기 급격히 떨어지기 시작하는데 원칙적으로는 안됩니다. 그의 일정에 따르면 행 끝에서 기울기 각도만 변경되어야 하므로 기억 효과가 제한적임을 알려줍니다.
내가 거기에서 멈출 때까지. 원본과 부분적으로만 일치하기 때문에 아직 U/V 통계를 적용하기로 결정하지 않았습니다.
R/S 점수를 Hurst로 변환하는 것도 다소 과대평가된 결과를 제공합니다. 허스트 지수가 다음과 같은 경우: , 그런 다음 Excel 공식에 의해 LOG(POWER(10;B1);C1*0.5)를 얻습니다. 여기서 B1은 현재 R/S 점수입니다.
다음은 R/S 통계 계산을 구현하는 WL/C# 코드입니다.
using System;
using System.Collections.Generic;
using System.Text;
using System.Drawing;
using System.IO;
using WealthLab;
using WealthLab.Indicators;
namespace WealthLab.Strategies
{
publicclass PetersHerst : WealthScript
{
public StrategyParameter Period;
publicstring path = @"c:\Users\Василий\Documents\Wealth-Lab\Reports\Strategys\Herst\herst.csv" ;
public PetersHerst()
{
//StreamWriter sw = new System.IO.StreamWriter(path);
Period = CreateParameter( "Period" , 6 , 6 , 240 , 1 );
if (File.Exists(path))File.Delete(path);
}
protectedoverridevoid Execute()
{
int N = Period.ValueInt;
// Так как мы преобразуем исходный ряд в доходности, то количество наблюдений у нас будет на 1 меньше, чем баров на графике.// Отслеживаем, что бы количество отброшенных данных не превышало 6 наблюдений.// Если отбрашиваемых данных слишком много,то период выбран неудачно, и расчет R/S статистики для него не производится.int ost = Bars.Count - 1 - ( int )Math.Floor(( double )(Bars.Count- 1 )/N)*N;
if (ost > 6 )
{
PrintDebug( "Слишком много пропущенных данных (" + ost + "). Необходимо выбрать другой период." );
return ;
}
//PrintDebug("Пропущенных данных для рассчета");
DataSeries Returns = new DataSeries( "Returns" );
DataSeries ret2price = new DataSeries( "ret2proce" );
// Расcчитываем логарифмические доходности// и собираем из них накопленный ряд.
Returns.Add( 0.0 , Date[ 0 ]);
double acum = 0.0 ;
for ( int i = 1 ; i < Bars.Count; i++)
{
acum += Math.Log(Close[i]/Close[i- 1 ]);
Returns.Add(Math.Log(Close[i]/Close[i- 1 ]), Date[i]);
ret2price.Add(acum, Date[i]);
}
//ret2price.
PrintDebug(ret2price.Count);
if (Returns.Count < 1 ) return ;
if (N > ret2price.Count)N = ret2price.Count;
double logRS = 0.0 ;
int count= 0 ; //количество периодов
PrintDebug(Bars.Count);
for ( int i = 0 ; i < ret2price.Count; i++)
{
//Делим ряд на K групп по N доходностей в каждойif ((i+ 1 )%N == 0 )
{
count++;
if (i - N < 0 ) continue ;
//Находим среднее значение sma или математическое ожидание доходностей за период kdouble sma = SMA.Value(i, ret2price, N);
//Находим стандартное отклонение за период kdouble S = StdDev.Value(i, ret2price, N, WealthLab.Indicators.StdDevCalculation.Sample);
//Находим накопленную разницу между текущим значением и средним.double s = 0.0 ;
DataSeries acum_div = new DataSeries( "" );
for ( int k = i - N+ 1 ; k <= i; k++)
{
s += (ret2price[k] - sma);
//Не учитываем последнее значение, т.к. оно всегда будет равно нулю.//if(k!=i)
acum_div.Add(s);
//PrintDebug(Returns.Date[k].ToShortDateString() +"\tret: "+ Returns[k].ToString("F6") + "\tStd: " + S.ToString("F6") + "\t" + s.ToString("F6"));
}
double R = acum_div.MaxValue - acum_div.MinValue;
//Конечная оценка log(R/S)
logRS += Math.Log(R/S, 10 );
//PrintDebug(Returns.Date[i].ToShortDateString() + "\t" + "SMA: " + sma.ToString("F6")// + "\tStd: " + S.ToString("F6") + "\tMaxV: " + acum_div.MaxValue.ToString("F6") +// "\tMinV: " + acum_div.MinValue.ToString("F6")// + "\tR: " + R.ToString("F6") + "\tlog(R/S): " + logRS.ToString("F6"));
}
}
logRS /= count;
double logPeriod = Math.Log(N, 10 );
PrintDebug(logPeriod + "\t" + logRS + "\tCount:" + count);
if (count >= 2 )
File.AppendAllText( @"c:\Users\Василий\Documents\Wealth-Lab\Reports\Strategys\Herst\herst.csv" , logPeriod + "\t" + logRS + "\n" );
}
}
}
ps 재미있습니다. MQL4에는 재정의가 없고 키워드 사용이 있지만 구문은 어쨌든 키워드를 강조 표시합니다. :)
모르겠어. 먼저 VR 모델을 식별해야 합니다. 여기에는 작동하는 것부터 모델이 작동하지 않는 것까지 다양한 매개변수가 있는 추세, 주기, 노이즈가 포함될 수 있습니다. Box는 매개변수 세트가 다른 여러 모델을 고려합니다. 적어도 그가 Boxing으로 식별한 것을 취하고 Hurst를 계산하면 동일한 Hurst이거나 다른 값이나 알고리즘으로 다를 것입니다.
나는 여러 포럼과 문헌에서 Hurst를 계산하려는 시도를 보았습니다. 실행 가능한 하나가 아닙니다. 이것은 위의 생각으로 이어졌습니다.
나는 당신의 "일할 수 있는 사람이 하나도 없다"는 것이 부끄럽습니다. "... 그리고 문학에서"라는 단어 뒤에. 문헌에는 서로 약간 다른 결과를 제공하는 다양한 접근 방식이 있으며, 이는 놀라운 일이 아닙니다. 이것은 모두 추정치입니다. 그러나 표본이 클수록 이러한 추정치가 더 정확해야 하고 서로 더 "동일"해야 한다는 것도 사실입니다. 포럼에서 실행 가능한 Hurst 알고리즘을 찾기가 어렵다는 사실에만 동의합니다.
알고리즘의 입력에 무엇을 제출할 것인지에 관해서는 알고리즘은 신경 쓰지 않습니다. 가격을 제출하십시오 - 주위에 무언가를 얻으십시오. 그래도 알고리즘의 본질상 가격은 장기기억이 강하기 때문에 원래 값에서 비교적 멀리 떨어져 있습니다. 가격 증분 제출 - 0.5와 같은 값을 얻습니다. 이는 다시 정당화되기 때문입니다. 그들의 비교 변화는 크고 거의 무작위입니다. 추세 및/또는 주기를 일치시키십시오 - 지속성을 얻으십시오. 노이즈는 일반적으로 지수를 줄입니다. 질문은 "우리 가격이 시끄럽습니까 아니면 정직한 시장 가격입니까?"입니다. - 이것은 Hurst 알고리즘의 주제가 아니라 다른 영역입니다.
RS-분석에서 분석된 VR의 길이가 어떻게 선택되는지 알려주세요.
일반적으로 많을수록 좋습니다. Peters의 책에 있는 알고리즘에 따르면 정수 제수가 가장 많은 길이가 더 좋습니다.
RS-분석에서 분석된 VR의 길이가 어떻게 선택되는지 알려주세요.
두 가지 모델이 있습니다.
1. 프로세스에는 "안정된" 허스트 지수가 있습니다. 저것들. 표시기는 일정하며 시간이 흘러도 변하지 않습니다(전체 프로세스가 존재하는 동안). 이 경우 이를 결정하기 위해 적어도 통계적으로 중요한 영역, 즉 프로세스 분포를 자신 있게 평가할 수 있는 섹션입니다. 또는 귀찮게하지 않고 가능한 한 많이.
2. 표시기는 매우 복잡하고 무작위일 수 있는 기능입니다. 이 경우 VR의 길이를 선택하는 객관적인 기준은 없습니다. 일반적인 경우에 대한 지표의 평가는 심령이 아닌 경우 시간 또는 주파수 영역에서 불가능합니다.
중요하게도, RS 분석은 가장 조잡한 방법 중 하나이며 추정치는 항상 편향되어 있으며 표본 크기는 어떤 식으로도 도움이 되지 않습니다. Hurst 지수의 정확한 계산을 얻으려면 웨이블릿 기반 추정을 사용하십시오(알고리즘은 예를 들어 Mathlab에서 찾을 수 있음).
Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда.
Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы.
Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо!
PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
가격에 허스트 ~ 1,하지만 그것은 무엇입니까?
이 경우 내가 도울 수 있는 유일한 것은 _hurst_classik 파일에 Hurst 또는 R/S 분석이 없다는 점을 지적하는 것입니다. 시리즈의 리스케일링에서 "R / S"라는 이름의 본질. _RS_Analiz에 대한 주장이 있는 _hurst_classik의 텍스트에서는 재조정이 수행되지 않지만 예를 들어 최고가와 최저 가격의 차이는 진부합니다.
또한 R/S 분석은 Hurst에 도달하기 위해 곡선의 기울기를 계산하는데, 이를 위해서는 각 막대의 log(R/S) - log(n) 평면에 한 점이 아니라 여러 점이 필요합니다. . 같은 기적 _RS_Analiz'에는 그런 것이 전혀 없습니다.
내 게시물의 요점은 "VR 모델 식별"이었지만 당신의 관심을 끌지 못했습니다.
ARFIMA 클래스(매개변수) 또는 이와 유사한 모델에 대해 이야기하는 경우 실제로 이것은 흥미롭지 않습니다. 왜냐하면 왜냐하면. 이 모델은 "nakui"를 성장시키며, 그 목적은 투자 자금을 모으기 위한 것입니다. 이러한 "과학"을 캐비닛 과학이라고 합니다. 그들은 과학적 근거를 분명히 원하는 결과, 일반적으로 가격 예측으로 조정하기 위해서만 만들어집니다.
ARFIMA 클래스(매개변수) 또는 이와 유사한 모델에 대해 이야기하는 경우 실제로 이것은 흥미롭지 않습니다. 왜냐하면 왜냐하면. 이 모델은 "nakui"를 성장시키며, 그 목적은 투자 자금을 모으기 위한 것입니다. 이러한 "과학"을 캐비닛 과학이라고 합니다. 그들은 과학적 근거를 분명히 원하는 결과, 일반적으로 가격 예측으로 조정하기 위해서만 만들어집니다.
우리는 평가하지 않을 것입니다. 이제 우리는 VR 모델을 사용하고 전혀 사용하지 않는 접근 방식에 대해 이야기하고 있습니다.허스트 인디케이터 계산을 도와주세요!!!*
*작은 참고: Peter처럼
나는 전체 스레드를 처음부터 끝까지 읽었습니다. 예, 존경받는 전문가부터 평범한 구경꾼에 이르기까지 모든 사람 이 Hirst가 무엇이며 어떻게 고려되고 해석되어야 하는지에 대한 자신의 의견을 가질 것이라고 기대하지 않았습니다. 원본에 가장 가까운 것은 Eric Nyman의 기사 와 책 입니다. 그러나... 러시아에서는 Peter의 책에 나와 있는 그래프를 생성하기 위한 적절한 도구가 아직 없습니다.
그래서 나는 S&P 500 지수에 대한 R/S 통계를 계산하기 위해 Peter의 첫 번째 책인 " Chaos and Order in the World of Capital "에서 설명한 일련의 행동을 최대한 가깝게 모방하려고 노력했습니다.
1. 1950년 1월 1일부터 1988년 1월 7일까지의 S&P 500 월간 주식 차트를 사용합니다.
2. 우리는 그것들을 기술 분석 프로그램에 로드합니다(저는 WealthLab과 C#를 사용합니다. 이하 WL/C# 코드를 줄 것입니다)
3. Peters의 책에 제시된 공식에 따라 가격을 수익률로 변환해 보겠습니다.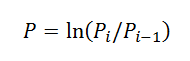
4. Peters 자신은 수익률이 계산된 후 다시 누적된 시리즈로 변환된다고 언급하지 않습니다.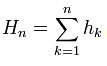 . 그러나 이것은 R/S 범위의 값을 기반으로 하는 것이 분명합니다. 게다가 소스 도 명시적으로 이렇게 말합니다. "각 자연 n에 대해 값을 구성할 것입니다. (위의 공식 참조) 결과 부분 수열의 다음 수치적 특성을 계산하십시오."
. 그러나 이것은 R/S 범위의 값을 기반으로 하는 것이 분명합니다. 게다가 소스 도 명시적으로 이렇게 말합니다. "각 자연 n에 대해 값을 구성할 것입니다. (위의 공식 참조) 결과 부분 수열의 다음 수치적 특성을 계산하십시오."
5. 결과 시리즈를 k 기간으로 나누고 각 기간의 길이는 6개월에서 231개월까지 N입니다.
6. 이제 중요한 점입니다. 정수의 기간을 얻지 못하면(사용하지 않은 데이터가 남음) 폐기됩니다. 그러나 나머지가 너무 크면(예: 나머지가 462 / 232 = 233이고 230) 잘못된 값을 얻습니다. 제가 알기로는 Peters는 shift를 사용하지만 이것은 프로그래밍 측면에서 매우 힘든 옵션이며 나머지가 6보다 크면 마침표를 버립니다. 인접한 기간은 거의 동일한 R/S 값을 가지므로 이것은 올바른 옵션.
7. 다음으로 R은 다음 공식으로 계산됩니다.
8. R은 표준 편차(WL 표시기로 계산)로 나누어 로그화: log10(R/S).
9. 현재 기간은 로그입니다. log10(N);
10. log10(R/S) 대 log10(N)의 결과 비율이 파일에 입력됩니다.
옵티마이저가 N을 6(Peters와 같은)에서 231(최소 실험 횟수는 2)까지 정렬하면 이중 로그 스케일의 두 열 테이블을 얻습니다. 1. 기간 2. R/S 값.
이제 재미가 시작됩니다. 이 테이블을 엑셀로 작성하면 다음과 같이 나옵니다.
원본은 오른쪽에 표시됩니다. 보시다시피 약간의 유사점이 있지만 여전히 동일하지는 않습니다. 특히 초기 지표는 다소 과대 평가된 것으로 밝혀졌으며(0.33 대 약 0.31), 두 번째로 최종 값이 갑자기 급격히 떨어지기 시작하는데 원칙적으로는 안됩니다. 그의 일정에 따르면 행 끝에서 기울기 각도만 변경되어야 하므로 기억 효과가 제한적임을 알려줍니다.
내가 거기에서 멈출 때까지. 원본과 부분적으로만 일치하기 때문에 아직 U/V 통계를 적용하기로 결정하지 않았습니다.
R/S 점수를 Hurst로 변환하는 것도 다소 과대평가된 결과를 제공합니다. 허스트 지수가 다음과 같은 경우: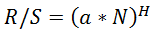 , 그런 다음 Excel 공식에 의해 LOG(POWER(10;B1);C1*0.5)를 얻습니다. 여기서 B1은 현재 R/S 점수입니다.
, 그런 다음 Excel 공식에 의해 LOG(POWER(10;B1);C1*0.5)를 얻습니다. 여기서 B1은 현재 R/S 점수입니다.
다음은 R/S 통계 계산을 구현하는 WL/C# 코드입니다.
ps 재미있습니다. MQL4에는 재정의가 없고 키워드 사용이 있지만 구문은 어쨌든 키워드를 강조 표시합니다. :)matkad에 Hurst 지수 계산이 있습니까(이산 형식의 공식이 필요함)?
여기까지만 찾았어요
시계열 분석에 대한 접근 방식이 포함된 파일을 첨부합니다. 나는 거기에서이 공식을 가져 왔습니다.
물론 죄송합니다.
그리고 흥미로운 점은 무엇입니까? 공식을 보면 Forex에 적용하는 데 전혀 의미가 없습니다.
Forex를 설명하는 행을 직접 던지는 것이 더 쉽습니다. 예, 그는 이미 존재하여 사람들이 그를 위해 노벨상을 받았습니다. 그러나 결과는 매우 매우 평균적입니다. 먼저 항상 평균, 즉 오류를 추정한 다음 오류로 인한 확률에서 빼기를 시도한 다음 귀찮게 해야 합니다.
물론 죄송합니다.
그리고 흥미로운 점은 무엇입니까? 공식을 보면 Forex에 적용하는 데 전혀 의미가 없습니다.
Forex를 설명하는 행을 직접 던지는 것이 더 쉽습니다. 예, 그는 이미 존재하여 사람들이 그를 위해 노벨상을 받았습니다. 그러나 결과는 매우 매우 평균적입니다. 먼저 항상 평균, 즉 오류를 추정한 다음 오류로 인한 확률에서 빼기를 시도한 다음 귀찮게 해야 합니다.
죄송합니다. 그러나 미래를 위해 이 스레드에 쓸데없는 생각을 게시하지 않기로 동의합시다. 누군가는 "Forex 시리즈"에 관심이 있고 누군가는 Hurst의 통계에 관심이 있습니다. 모든 사람이 자신의 지점을 갖게 하십시오.
이중 로그 척도로 CSV 형식 테이블을 게시하고 있습니다. 기간별 R/S 추정치입니다.