カオスにはパターンがあるのか?それを探してみよう!特定のサンプルを例にした機械学習。 - ページ 25 1...181920212223242526272829303132 新しいコメント Aleksey Vyazmikin 2023.02.27 08:30 #241 Forester #:TP=SLでは約50%。TP=2*SLでは33%など。 常に1トレードの平均利益は非常に小さい。約0,00005です。しかし、それはスプレッド、スリッページ、スワップに費やされます。これらは先生のマークアップには考慮されていません(スプレッドは考慮されていますが、バーごとの最小値であり、実際のものはもっと高くなります)。 そして、このTP=SL=0,00400を使用します。すなわち、400のリスクで5ptの利益、すなわち1%の利益を得ます。 私は50ptの動きから少なくとも10ptを取りたいのですが、そこではすべてのオプションがプラマイゼロです。 しかし、これはすべて私のチップとターゲットによるものだ。もっといい選択肢があるかもしれない。この 戦略は2008年から2023年までEURUSDで43%の利益を出し、TP/SLレシオは61.8で、利益を出した取引の39%はブレークイーブンに十分です。まだ数字を確認していないので、どこかで間違っているかもしれないし、もちろんこれは理想的な条件である。しかし、ここには学習の視点があり、MOを犠牲にしてもより高いパーセンテージを引き出せるということです。予測因子についてですが、私の記事から私の予測因子を引用したのですか? それらは 、とりわけ私が持っているモデルによく見られます。 追記:はい、利益が出ていてもTPで決済されない取引があることは考慮していません。 Forester 2023.02.27 08:40 #242 Aleksey Vyazmikin #:この ストラテジーは2008年から2023年までEURUSDで43%の利益を出し、理想的な条件ではTP/SLレシオは61.8で、利益を出したトレードの39%はブレークイーブンに十分なものです。まだ数字を確認していないので、どこかで間違っているかもしれないし、もちろんこれは理想的な条件である。しかし、ここには学習の視点があり、MOを犠牲にしてもより高いパーセンテージを引き出せるということです。予測因子についてですが、私の記事から私の予測因子を引用したのですか? それらは 私が持っているモデル、とりわけ他のモデルによく見られます。 あなたの戦略はよくわからない。1日1回、シグナルを受け取ってエントリーしているように見えますが。。私はあなたのデータセットであなたの5000以上の予測子を訓練した。それらは同じ5ポイント以上を与えないので、私の単純な価格のデルタとジグザグ、同じく5ポイントを与えるものより良くないと思います。 とりあえず他のアイデアをチェックしてみます。もし何も得られなかったら、あなたの予測モデルを試して、私自身のモデルを作成します。 Aleksey Vyazmikin 2023.02.27 09:36 #243 Forester #:あなたの戦略が何なのかよくわからない。1日1回エントリーするシグナルのように見えます。 戦略は以下の通りです: この目的のためには、前日終値のATR(3)を使用することができますが、私は少し異なる計算式を使用しています。この値幅は、当日の始値(バー)を100%として計算します。 始値の上下にある重要なレベル(私は23.6で止めました。私の観察によると、異なる金融商品ではしばしばそのようになります)に到達したら、次の重要なレベル(私は61.8を使っています)でTPを付けてポジションを建て、その日の始値でSLを付けます。 利益確定で決済した場合は、シグナルが出たら再度エントリーする。 テイクアウトがうまくいかなかった場合は、その日の終わり(23:45)にクローズした方が良いが、実際にはTP/SLを待っている。 利益で決済した場合は1、損失で決済した場合は-1。 サンプルを分割する際、ターゲットを300pipsオフセットさせたので、利益が300pips以下なら0になる。 if(N_Siganal==10)//сейчас работает на открытие позиции при пересечении +23,6/-23,6 iDelta D1 { if(CountMarketOrder_OS==0 && CountMarketOrder_OB==0) { double Open=iOpen(Symbol(),PERIOD_CURRENT,0); double Open_S1=iOpen(Symbol(),PERIOD_CURRENT,1); double iDelta=iDeltaf(Symbol(),PERIOD_D1,3,1,0); double Open_Day=iOpen(Symbol(),PERIOD_D1,0); double iD_Day_Up=0.0; double iD_Day_Dn=0.0; bool Signal_Buy=false; bool Signal_Sell=false; iD_Day_Up=Open_Day+iDelta; iD_Day_Dn=Open_Day-iDelta; if(Open_S1<=iD_Day_Up && Open>iD_Day_Up)Signal_Buy=true; if(Open_S1>=iD_Day_Dn && Open<iD_Day_Dn)Signal_Sell=true; if(Signal_Buy==true || Signal_Sell==true)break; if(Signal_Buy==true || Signal_Sell==true) { Print("Основной сигнал:"," T_Zero=",TimeToString(T_Zero,TIME_DATE|TIME_MINUTES)," T_Signal=",TimeToString(T_Signal,TIME_DATE|TIME_MINUTES)); if(T_Zero<T_Signal) { Signal_Buy=false; Signal_Sell=false; Print("Блокировка T_Zero<T_Signal - открыта виртуальная позиция"); } else { if(Signal_Sell==true)SellNow=true; if(Signal_Buy==true)BuyNow=true; } } } } フォレスター#: この結果の統計的有意性について話すことはほとんどないと思います。 2008年のデータです。なぜなら、23.6の水準がランダムではなく、その交差がマーケットにとって重要であると考えるなら、各バーでエントリーを生成するときの状況とは異なり、互いに比較できる類似したイベントのようになるからです。 ですから、この方法で学習することは理にかなっていると思いますが、市場参加者の意思決定に影響を与えるイベントは、戦略によって異なるはずです。そして、さらにモデルのセットを取引する。 フォレスター#: あなたのデータセットで5000以上の予測モデルをトレーニングしました。それらは同じ5ポイント以上を与えないので、私の単純な価格のデルタとジグザグ、同じく5ポイントを与えるものより良くないと思います。 とりあえず他のアイデアをチェックしてみます。もし何も得られなければ、あなたの予測モデルを試して、私自身のモデルを作成します。 最初のサンプルのことですか、それとも2番目のサンプルのことですか?もし最初のサンプルであれば、私は良いバリアントに対して約30ポイントの期待行列を持っていました。 もちろん、CatBoostであなたのサンプルをトレーニングすることもできます。 Forester 2023.02.27 10:32 #244 Aleksey Vyazmikin #:これが戦略だ:この目的のために、前日末のATR(3)を使用することができますが、私は少し異なる式を使用します。この値幅を当日の始値(バー)から先送りし、100%と見なします。始値の上下で重要なレベルに達したら(私は23.6で止めました。私の観察によると、異なる商品ではしばしばそのようになります)、次の重要なレベル(私は61.8を使っています)でTPを設定してポジションを建て、その日の始値でSLを設定します。利益確定で決済した場合、シグナルが出たら再度エントリーする。利食いがうまくいかなかった場合は、その日の終わり(23:45)に決済した方が良いのですが、実際、今はTP/SLを待っています。利益で決済した場合は1、損失で決済した場合は-1。サンプルを分割する際、ターゲットを300pipsオフセットさせたので、利益が300pips以下なら0になる。2008年からデータを取りました。23.6の水準が偶然ではなく、その交差が市場にとって重要であると考えるなら、これらは互いに比較できる類似のイベントです。 結果をpipsで見積もりますか、それとも勝敗だけですか?後者のようです。pipsで見積もる方がよいでしょう。 そうすれば、75%を与えるモデルが実際には50/50で機能することはありません。 Aleksey Vyazmikin#: インプットがすべてのバーで生成される場合とは異なり、そのようなイベントがたくさんあるため、学習が複雑になるだけ です。 私は間引きを追加したいと思います - 類似のバーで、価格が100...1000ptによって行っていない場合は、スキップします。 Aleksey Vyazmikin#: 最初のサンプルのことですか、それとも2番目のサンプルのことですか?もし最初のサンプルについて話しているのであれば、私は良いバリアントに対して約30pipsの期待マトリックスを持っていました。 2つ目のサンプルはH1.まあ、最初のサンプルは良くなかった(しかし、私はそれをより少なく研究し、例えば、私は特徴を選択しなかった)。 Aleksey Vyazmikin#: もちろん、CatBoostであなたのサンプルをトレーニングすることもできます。 私は何百も持っています。そして、そのどれもがトレードに入れるのが好きではありません。私はTPやSLや他の何かを変更します - それは新しいバリアントです。だから意味がない。 Aleksey Vyazmikin 2023.02.27 15:32 #245 Forester #: 勝負の行方は、勝ち点で予想するのか、それとも勝敗で予想するのか。後者のようだ。ptsで見積もったほうがいい。 75%のモデルが本当に50/50で機能しないように。 私はお金で評価しています :)プラス目標。もっとポイントが欲しければ、ターゲットは後で動かすことができる。 具体的な戦略では、今はすべてが利益確定です。私は計算されたロットを作り、実際にはスプレッドが大幅に割合を悪化させることが判明したが、それは良いですが、超利益エントリの排出なしで安定性があるでしょう - リスクはどこでもほとんど同じです。その後、ポーズを使用する場合は、結果を改善することができます。 フォレスター#: 私は間引きを追加したいと思います - 類似のバー、価格が100...1000ptによって行っていない場合は、スキップします。 そして、各バーで評価し、よく適用するモデル? フォレスター#:まあ、最初のものは良くなかった、(しかし、私はそれをあまり研究しなかった、私は例えばチップを選択しなかった)。私はそれらの数百を持っています。そして、そのどれもがトレードに入れるのが好きではない。私はTPやSLや他の何かを変更します - それは新しいバリアントです。だから意味がない。 私が言いたいのは、サンプルを作成するための同じアルゴリズムがあれば、予測因子を比較することが可能になるということです。 Forester 2023.02.27 16:59 #246 Aleksey Vyazmikin #:そして、それぞれの小節で、どのモデルを適用するか? はい、トレーニングのように、少なくともXXピップスが経過している場合。しかし、歪みがあるでしょう - アップと999から979(899から979)の場合、100から120(200から220など)の最初のバーだけより頻繁に動作します。 Aleksey Vyazmikin#: My point is that if there is the same algorithm for creating a sample, it will be possible to compare predictors. 私は5000以上欲しいとは思っていません。しかし、有意な予測因子の検索として、それらをチェックすることは必要かもしれません。 RomFil 2023.03.25 13:05 #247 度々ありがとうございます! この問題を解決できる1つのアプローチがあるのですが、できればサンプルファイルは予測子を含まないものにしてください。つまり、5000以上の予測変数は必要なく、モーション・グラフそのものだけです。それがOHLCで構成されているか、1つの変数を持っているかは重要ではありません。しかし、私はサンプルから1つの変数、すなわち、D(i)=D(i-1)+ Target_100_Buy という式を使ってチャートに変換した5584列で既存の方法を試してみました。3つのファイルすべてについて、以下のグラフが得られた: 1) train: 2)テスト 3)試験: 私が正しくやったかどうかはわからないが、もしtopikstarterが予測変数なしで新しいサンプルを作ったら、新しいデータでこの方法をテストして、そのアプローチについて教えよう。 さて、そしてニューラルネットワークの委員会(全部で10個ある)をトレーニングした後の各サンプルの実際の利益。利益はポイント数で表し,スプレッド=0,手数料=0とする. 1) 訓練する: 2) テスト 3)試験 60000pips以上という結果はかなり納得のいくものだと思います。 私はtopikstarterに、最も "カオス "なシグナルのみで新しいサンプルを作ることを提案する。 この方法は新しいシグナルに適用され、結果が示されるでしょう。 それでは、ロムフィル! 追伸:未来はわからないが、それをコントロールする方法はいつでも見つけられる.:) Aleksey Vyazmikin 2023.03.25 13:43 #248 RomFil #:こんにちは!この問題を解決できる1つのアプローチがあるのですが、できればサンプルファイルは予測子を含まないものにしてください。つまり、5000以上の予測変数は必要なく、モーション・グラフそのものだけです。それがOHLCで構成されているか、1つの変数を持っているかは重要ではありません。しかし、私はサンプルから1つの変数、すなわち、D(i)=D(i-1)+ Target_100_Buy という式を使ってチャートに変換した5584列で既存の方法を試しました。3つのファイルすべてについて、グラフは以下のようになります: あなたの手法が純粋な価格で機能するのであれば、あなたが何をしたのか、なぜ新しいサンプルが必要なのか理解できません。 下のリストの列は、起こったイベントの結果です。せいぜい 5582 - しかし、そこは予測しやすいと思うので、そのままモデルによって回収されるだろう。 5581 補助 5582 補助 5583 ラベル 5584 補助 5585 補助 RomFil 2023.03.25 14:32 #249 Aleksey Vyazmikin #:あなたのやり方が純粋な価格で機能するのであれば、なぜ新しいサンプルが必要なのか理解できない。下のリストの列は、起こったイベントの結果です。最大でも5582ですが、予測は簡単なので、モデルによって回復されると思います。 5581 補助 5582 補助 5583 ラベル 5584 補助 5585 補助 "私が何をしたのか? サンプル・トレインのサイズは約1GB。ワークスペースに読み込むのにかなり時間がかかる。私はi5-3570に24GBのRAMと高速SSDを搭載しているが、Excelがこのファイルを開くのに数分かかる。だから、このファイルを短くするべきだと思ったんだ。5000以上の列の上付き添え字を考えるのが面倒だった。私は5584 5586列を取り出し、すべての行にシグナルを適用した。 例えばBUY(正直、どれかは覚えていない、多分SELL)。 こうして、この列は上記の計算式に従ってチャートを形成した。すなわち、最初はゼロ、次に0.00007、次に0.00007-0.00002=0.00005、次に0.00005+0.00007=0.00012などである。つまり、5584 5586の列から、束縛のない、いわば相対的な動きのチャートを形成したことになる。あたかもクローズ・チャートのように、つまり、チャートの各ステップの終了時に、資産の価格が対応する値だけ変化する。 追伸:列番号についてだまされた...直近の5586(エクセルで調べました)をSELLシグナルとしました。 "...なぜ新しいサンプル": その例でアプローチについて一定量で示し、伝えるために。OHLCが取れる列の数、またはClauseの価格だけを挙げれば十分でしょう。 その他について: サンプルファイルのデータは全く使っていない。各ファイルの5584 5586列を基に、上記のようなグラフを作成する。そして、得られたグラフに対して、すでにアプローチが適用されている。 さて、topikstarterは新しいサンプルを提供することを望んでいないので、興味のある人は自分のサンプルを投稿することを勧める.:) ありがとう、ロムフィル! Forester 2023.03.25 14:38 #250 RomFil #:こんにちは!この問題を解決できる1つのアプローチがあるのですが、できればサンプルファイルは予測子を含まないものにしてください。つまり、5000以上の予測変数は必要なく、モーション・グラフそのものだけです。それがOHLCで構成されているか、1つの変数を持っているかは重要ではありません。しかし、私はサンプルから1つの変数、すなわち、D(i)=D(i-1)+Target_100_Buy という式を使ってチャートに変換した5584列について、既存の方法を試してみました。3つのファイルすべてについて、グラフは以下のようになります: ターゲット・ファンクションの反復性は、トレーニング?例えば、20回成功した場合、21回成功しますか?、TP/SL=50 pts の買いと売りの最も単純なターゲットです。 M5 約 5 年間。 マークアップは各M5バーで、つまり、ほとんどの場合、最後のシグナル(5分前)からの取引はまだ終了していません。積み重ねが正しいかどうかはわかりません。スタッキングは、1つの瞬間に1つの取引しかないターゲットに対しては大丈夫でしょう。 追伸:私は彼らを訓練できないようにしています。彼らはいつも私の予測セットで失敗する。 ファイル: buy.csv 3516 kb sell.csv 3516 kb 1...181920212223242526272829303132 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
TP=SLでは約50%。TP=2*SLでは33%など。
常に1トレードの平均利益は非常に小さい。約0,00005です。しかし、それはスプレッド、スリッページ、スワップに費やされます。これらは先生のマークアップには考慮されていません(スプレッドは考慮されていますが、バーごとの最小値であり、実際のものはもっと高くなります)。
そして、このTP=SL=0,00400を使用します。すなわち、400のリスクで5ptの利益、すなわち1%の利益を得ます。
私は50ptの動きから少なくとも10ptを取りたいのですが、そこではすべてのオプションがプラマイゼロです。
しかし、これはすべて私のチップとターゲットによるものだ。もっといい選択肢があるかもしれない。
この 戦略は2008年から2023年までEURUSDで43%の利益を出し、TP/SLレシオは61.8で、利益を出した取引の39%はブレークイーブンに十分です。まだ数字を確認していないので、どこかで間違っているかもしれないし、もちろんこれは理想的な条件である。しかし、ここには学習の視点があり、MOを犠牲にしてもより高いパーセンテージを引き出せるということです。
予測因子についてですが、私の記事から私の予測因子を引用したのですか? それらは 、とりわけ私が持っているモデルによく見られます。
追記:はい、利益が出ていてもTPで決済されない取引があることは考慮していません。この ストラテジーは2008年から2023年までEURUSDで43%の利益を出し、理想的な条件ではTP/SLレシオは61.8で、利益を出したトレードの39%はブレークイーブンに十分なものです。まだ数字を確認していないので、どこかで間違っているかもしれないし、もちろんこれは理想的な条件である。しかし、ここには学習の視点があり、MOを犠牲にしてもより高いパーセンテージを引き出せるということです。
予測因子についてですが、私の記事から私の予測因子を引用したのですか? それらは 私が持っているモデル、とりわけ他のモデルによく見られます。
あなたの戦略はよくわからない。1日1回、シグナルを受け取ってエントリーしているように見えますが。
。私はあなたのデータセットであなたの5000以上の予測子を訓練した。それらは同じ5ポイント以上を与えないので、私の単純な価格のデルタとジグザグ、同じく5ポイントを与えるものより良くないと思います。
とりあえず他のアイデアをチェックしてみます。もし何も得られなかったら、あなたの予測モデルを試して、私自身のモデルを作成します。
あなたの戦略が何なのかよくわからない。1日1回エントリーするシグナルのように見えます。
戦略は以下の通りです:
この目的のためには、前日終値のATR(3)を使用することができますが、私は少し異なる計算式を使用しています。この値幅は、当日の始値(バー)を100%として計算します。
始値の上下にある重要なレベル(私は23.6で止めました。私の観察によると、異なる金融商品ではしばしばそのようになります)に到達したら、次の重要なレベル(私は61.8を使っています)でTPを付けてポジションを建て、その日の始値でSLを付けます。
利益確定で決済した場合は、シグナルが出たら再度エントリーする。
テイクアウトがうまくいかなかった場合は、その日の終わり(23:45)にクローズした方が良いが、実際にはTP/SLを待っている。
利益で決済した場合は1、損失で決済した場合は-1。
サンプルを分割する際、ターゲットを300pipsオフセットさせたので、利益が300pips以下なら0になる。
この結果の統計的有意性について話すことはほとんどないと思います。
2008年のデータです。なぜなら、23.6の水準がランダムではなく、その交差がマーケットにとって重要であると考えるなら、各バーでエントリーを生成するときの状況とは異なり、互いに比較できる類似したイベントのようになるからです。
ですから、この方法で学習することは理にかなっていると思いますが、市場参加者の意思決定に影響を与えるイベントは、戦略によって異なるはずです。そして、さらにモデルのセットを取引する。
あなたのデータセットで5000以上の予測モデルをトレーニングしました。それらは同じ5ポイント以上を与えないので、私の単純な価格のデルタとジグザグ、同じく5ポイントを与えるものより良くないと思います。
とりあえず他のアイデアをチェックしてみます。もし何も得られなければ、あなたの予測モデルを試して、私自身のモデルを作成します。
最初のサンプルのことですか、それとも2番目のサンプルのことですか?もし最初のサンプルであれば、私は良いバリアントに対して約30ポイントの期待行列を持っていました。
もちろん、CatBoostであなたのサンプルをトレーニングすることもできます。
これが戦略だ:
この目的のために、前日末のATR(3)を使用することができますが、私は少し異なる式を使用します。この値幅を当日の始値(バー)から先送りし、100%と見なします。
始値の上下で重要なレベルに達したら(私は23.6で止めました。私の観察によると、異なる商品ではしばしばそのようになります)、次の重要なレベル(私は61.8を使っています)でTPを設定してポジションを建て、その日の始値でSLを設定します。
利益確定で決済した場合、シグナルが出たら再度エントリーする。
利食いがうまくいかなかった場合は、その日の終わり(23:45)に決済した方が良いのですが、実際、今はTP/SLを待っています。
利益で決済した場合は1、損失で決済した場合は-1。
サンプルを分割する際、ターゲットを300pipsオフセットさせたので、利益が300pips以下なら0になる。
2008年からデータを取りました。23.6の水準が偶然ではなく、その交差が市場にとって重要であると考えるなら、これらは互いに比較できる類似のイベントです。
結果をpipsで見積もりますか、それとも勝敗だけですか?後者のようです。pipsで見積もる方がよいでしょう。
そうすれば、75%を与えるモデルが実際には50/50で機能することはありません。
インプットがすべてのバーで生成される場合とは異なり、そのようなイベントがたくさんあるため、学習が複雑になるだけ です。
私は間引きを追加したいと思います - 類似のバーで、価格が100...1000ptによって行っていない場合は、スキップします。
最初のサンプルのことですか、それとも2番目のサンプルのことですか?もし最初のサンプルについて話しているのであれば、私は良いバリアントに対して約30pipsの期待マトリックスを持っていました。
2つ目のサンプルはH1.まあ、最初のサンプルは良くなかった(しかし、私はそれをより少なく研究し、例えば、私は特徴を選択しなかった)。
もちろん、CatBoostであなたのサンプルをトレーニングすることもできます。
私は何百も持っています。そして、そのどれもがトレードに入れるのが好きではありません。私はTPやSLや他の何かを変更します - それは新しいバリアントです。だから意味がない。
勝負の行方は、勝ち点で予想するのか、それとも勝敗で予想するのか。後者のようだ。ptsで見積もったほうがいい。
75%のモデルが本当に50/50で機能しないように。
私はお金で評価しています :)プラス目標。もっとポイントが欲しければ、ターゲットは後で動かすことができる。
具体的な戦略では、今はすべてが利益確定です。私は計算されたロットを作り、実際にはスプレッドが大幅に割合を悪化させることが判明したが、それは良いですが、超利益エントリの排出なしで安定性があるでしょう - リスクはどこでもほとんど同じです。その後、ポーズを使用する場合は、結果を改善することができます。
私は間引きを追加したいと思います - 類似のバー、価格が100...1000ptによって行っていない場合は、スキップします。
そして、各バーで評価し、よく適用するモデル?
まあ、最初のものは良くなかった、(しかし、私はそれをあまり研究しなかった、私は例えばチップを選択しなかった)。
私はそれらの数百を持っています。そして、そのどれもがトレードに入れるのが好きではない。私はTPやSLや他の何かを変更します - それは新しいバリアントです。だから意味がない。
私が言いたいのは、サンプルを作成するための同じアルゴリズムがあれば、予測因子を比較することが可能になるということです。
そして、それぞれの小節で、どのモデルを適用するか?
はい、トレーニングのように、少なくともXXピップスが経過している場合。しかし、歪みがあるでしょう - アップと999から979(899から979)の場合、100から120(200から220など)の最初のバーだけより頻繁に動作します。
My point is that if there is the same algorithm for creating a sample, it will be possible to compare predictors.
私は5000以上欲しいとは思っていません。しかし、有意な予測因子の検索として、それらをチェックすることは必要かもしれません。
度々ありがとうございます!
この問題を解決できる1つのアプローチがあるのですが、できればサンプルファイルは予測子を含まないものにしてください。つまり、5000以上の予測変数は必要なく、モーション・グラフそのものだけです。それがOHLCで構成されているか、1つの変数を持っているかは重要ではありません。しかし、私はサンプルから1つの変数、すなわち、D(i)=D(i-1)+ Target_100_Buy という式を使ってチャートに変換した5584列で既存の方法を試してみました。3つのファイルすべてについて、以下のグラフが得られた:
1) train: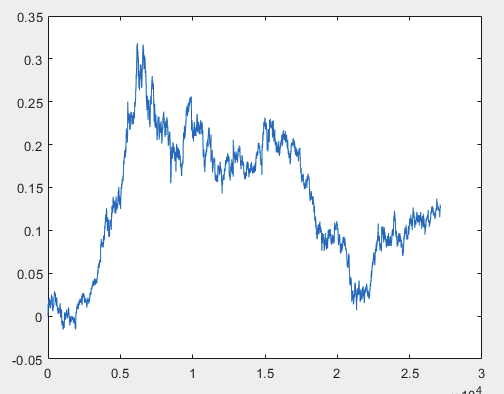
2)テスト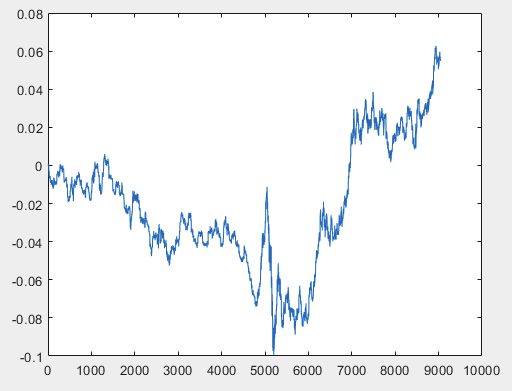
3)試験: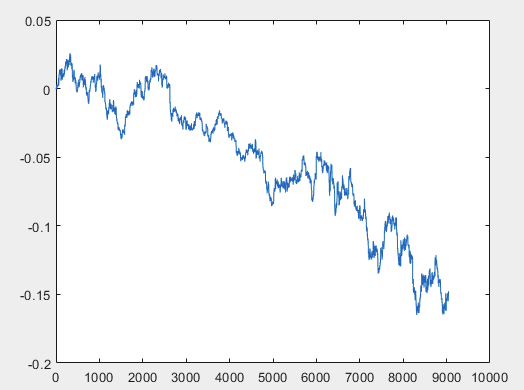
私が正しくやったかどうかはわからないが、もしtopikstarterが予測変数なしで新しいサンプルを作ったら、新しいデータでこの方法をテストして、そのアプローチについて教えよう。
さて、そしてニューラルネットワークの委員会(全部で10個ある)をトレーニングした後の各サンプルの実際の利益。利益はポイント数で表し,スプレッド=0,手数料=0とする.
1) 訓練する: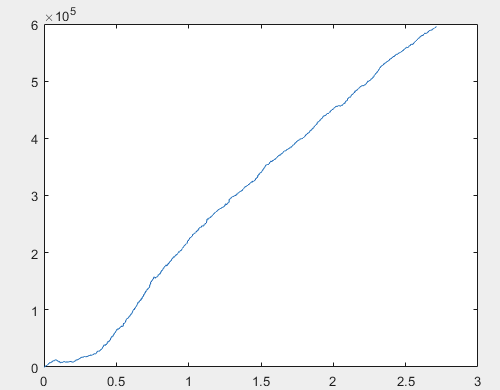
2) テスト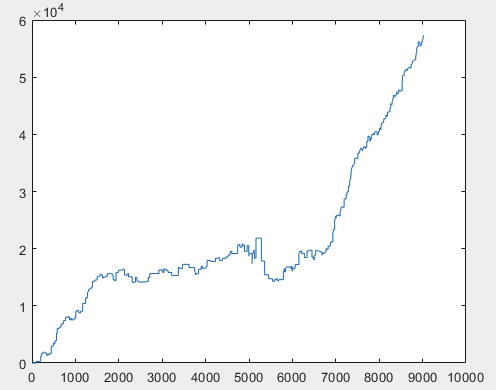
3)試験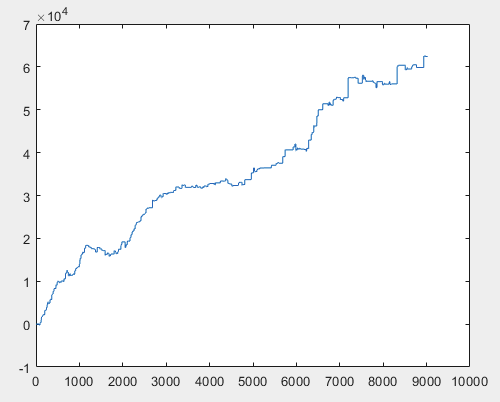
60000pips以上という結果はかなり納得のいくものだと思います。
私はtopikstarterに、最も "カオス "なシグナルのみで新しいサンプルを作ることを提案する。
この方法は新しいシグナルに適用され、結果が示されるでしょう。
それでは、ロムフィル!
追伸:未来はわからないが、それをコントロールする方法はいつでも見つけられる.:)
こんにちは!
この問題を解決できる1つのアプローチがあるのですが、できればサンプルファイルは予測子を含まないものにしてください。つまり、5000以上の予測変数は必要なく、モーション・グラフそのものだけです。それがOHLCで構成されているか、1つの変数を持っているかは重要ではありません。しかし、私はサンプルから1つの変数、すなわち、D(i)=D(i-1)+ Target_100_Buy という式を使ってチャートに変換した5584列で既存の方法を試しました。3つのファイルすべてについて、グラフは以下のようになります:
あなたの手法が純粋な価格で機能するのであれば、あなたが何をしたのか、なぜ新しいサンプルが必要なのか理解できません。
下のリストの列は、起こったイベントの結果です。せいぜい 5582 - しかし、そこは予測しやすいと思うので、そのままモデルによって回収されるだろう。
5581 補助
5582 補助
5583 ラベル
5584 補助
5585 補助
あなたのやり方が純粋な価格で機能するのであれば、なぜ新しいサンプルが必要なのか理解できない。
下のリストの列は、起こったイベントの結果です。最大でも5582ですが、予測は簡単なので、モデルによって回復されると思います。
5581 補助
5582 補助
5583 ラベル
5584 補助
5585 補助
"私が何をしたのか?
サンプル・トレインのサイズは約1GB。ワークスペースに読み込むのにかなり時間がかかる。私はi5-3570に24GBのRAMと高速SSDを搭載しているが、Excelがこのファイルを開くのに数分かかる。だから、このファイルを短くするべきだと思ったんだ。5000以上の列の上付き添え字を考えるのが面倒だった。私は5584 5586列を取り出し、すべての行にシグナルを適用した。 例えばBUY(正直、どれかは覚えていない、多分SELL)。 こうして、この列は上記の計算式に従ってチャートを形成した。すなわち、最初はゼロ、次に0.00007、次に0.00007-0.00002=0.00005、次に0.00005+0.00007=0.00012などである。つまり、5584 5586の列から、束縛のない、いわば相対的な動きのチャートを形成したことになる。あたかもクローズ・チャートのように、つまり、チャートの各ステップの終了時に、資産の価格が対応する値だけ変化する。
追伸:列番号についてだまされた...直近の5586(エクセルで調べました)をSELLシグナルとしました。
"...なぜ新しいサンプル":
その例でアプローチについて一定量で示し、伝えるために。OHLCが取れる列の数、またはClauseの価格だけを挙げれば十分でしょう。
その他について:
サンプルファイルのデータは全く使っていない。各ファイルの5584 5586列を基に、上記のようなグラフを作成する。そして、得られたグラフに対して、すでにアプローチが適用されている。
さて、topikstarterは新しいサンプルを提供することを望んでいないので、興味のある人は自分のサンプルを投稿することを勧める.:)
ありがとう、ロムフィル!
こんにちは!
この問題を解決できる1つのアプローチがあるのですが、できればサンプルファイルは予測子を含まないものにしてください。つまり、5000以上の予測変数は必要なく、モーション・グラフそのものだけです。それがOHLCで構成されているか、1つの変数を持っているかは重要ではありません。しかし、私はサンプルから1つの変数、すなわち、D(i)=D(i-1)+Target_100_Buy という式を使ってチャートに変換した5584列について、既存の方法を試してみました。3つのファイルすべてについて、グラフは以下のようになります:
ターゲット・ファンクションの反復性は、トレーニング?例えば、20回成功した場合、21回成功しますか?
、TP/SL=50 pts の買いと売りの最も単純なターゲットです。
M5 約 5 年間。
マークアップは各M5バーで、つまり、ほとんどの場合、最後のシグナル(5分前)からの取引はまだ終了していません。積み重ねが正しいかどうかはわかりません。スタッキングは、1つの瞬間に1つの取引しかないターゲットに対しては大丈夫でしょう。
追伸:私は彼らを訓練できないようにしています。彼らはいつも私の予測セットで失敗する。