
時系列の非定常性の指標としての2標本コルモゴロフ–スミルノフ検定

はじめに
金融時系列の分析を始めると、研究者は常にデータの非定常性の問題に直面します。為替レート、株式、先物の時系列は定常的ではありません。これらの系列を定常形式にするために、通常、価格対数の第一差分Ln(Xn/Xn-1)が使用され、修正されたデータで作業が続けられます。
しかし、このように修正された時系列は本当に定常的と言えるのでしょうか。ここではこの質問に答えようと思いますが、その前に定常性とは何かを思い出してみましょう。正式な定義がない場合、定常性は、時系列の数学的期待値や分散などの統計的特性が時間にわたって不変であることとして説明できます。これらの特性に加え、分布関数の時間的不変性が仮定される場合、その過程は狭義の定常過程と呼ばれます。
本研究では、経験分布関数を用いて、金融時系列が狭義の意味で定常性を持つかどうかを検証します。確率論と数理統計学は、前者の特定のセクションとして定常性の仮定に基づいています。定常過程の分析には、回帰分析、自己相関分析、スペクトル分析、ニューラルネットワークの利用など、多くの方法があります。しかし、これらの方法を非定常データに適用すると、予測誤差が大きくなる可能性があります。
トレーダーにとって、定常性の問題は、様々な指標を計算するためのデータ量の選択と密接に関係しています。定常過程であれば、データ量が多いほど統計的特性を正確に計算できますが、非定常過程の場合は最適なデータ量を決定するのが難しくなります。データが多すぎると、現状に影響を与えない古い情報が含まれている可能性がありますし、少なすぎると代表性が不十分で、プロセスの統計的特性を十分に評価できません。
ランダム過程の最も包括的な特徴は、その分布法則(確率関数)です。したがって、時系列の分布関数の経時変化を追跡できる指標を構築することは重要な課題です。この指標は、標準的なテクニカル分析指標を算出するためのデータ量を再検討する必要性についてのシグナルを提供します。数理統計学では、確率変数の分布関数が時間とともに変化しているかどうかを検定する問題を「同質性仮説の検定」と呼びます。
均質性仮説
サンプルデータの均質性は、均質性検定を用いて検定します。現在、多くの基準が開発されていますが、代表的なものとして次のような方法があります。
-
2標本コルモゴロフ–スミルノフ検定
-
アンダーソン同質性検定
-
ピアソンカイ二乗同質性検定
同質性仮説とは、無作為に得られたX変数とY変数に対応する2つのデータ標本(x1,x2,x3,...xn)および(y1,y2,y3,...ym)が同じ分布法則に従う、つまり、2つの標本が同一の母集団から抽出されたと仮定するものです。形式的には、この仮説はH0 :F(x) = G(y)のように表されます。対立仮説は、2つの標本が異なる母集団に属し、どの集団に属するかは特定されていないという内容で、H1:F(x)≠G(y)のように書かれます。
-
Fn(x)およびGm(y):それぞれ無作為なX変数とY変数の経験的累積分布関数
-
n、m:計算のためのデータ量
2標本コルモゴロフ–スミルノフ検定
2標本コルモゴロフ–スミルノフ検定は、2つの標本が同じ連続分布から抽出されたという仮説を検証するために用いられる統計的検定です。この検定は、2つの独立したサンプルの経験分布関数を比較することに基づいています。
この検定は、分布の等質性に関する仮説を評価するため、統計分析において広く利用されています。生物統計学や計量経済学など、2つの異なる標本の統計的性質を比較する必要がある様々な分野で有用です。特に、利用可能なデータが限られており、より洗練されたパラメトリック手法が適用できない場合に関連性が高いです。
2つの経験分布関数間の不一致の尺度として何を使用すべきかという点が重要です。スミルノフは、この不一致を測るために次のような統計量を提案しました。
Dn,m = sup | Fn(x) - Gm(y) |
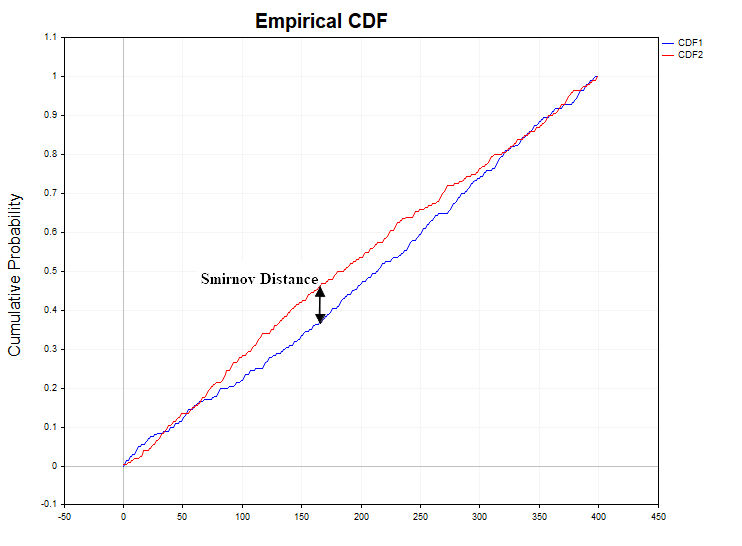
この統計量は、分布関数間の差の絶対値の正確な上限(最大値)を表しています。確率変数の分布法則が標本ごとに変化しないのであれば、Dn,m統計量の値が低くなるのは当然です。この統計量の値が過度に大きいと、データの均質性の帰無仮説を否定することになります。実際には、統計的仮説を検定するために、D統計量の代わりに、少し修正した統計量が計算されます。
lambda = D * ( sqrt(k) + 0,12 + 0,11/sqrt(k) )
ここで、k = (m*n/(m+n))です。k → ∞のラムダ統計量の分布は、コルモゴロフ分布関数に収束します。

nがmに等しい場合のラムダの計算には、次のより簡略化された式が使われることもあります。
lambda = D *sqrt(n/2)
次に、一定の統計値を得た後、サンプルデータを用いて均質性仮説を検証します。
統計的仮説は以下のように検証されます。
-
帰無仮説H0(標本は均質である)と対立仮説H1(標本は不均質である)が定式化される
-
アルファ有意水準が採用される(通常、0.1、0.05、0.01の標準値が使用される)
-
u(α)の臨界値は、コルモゴロフ分布に従って計算される(例えば、αが0.05の場合、u(α)は1.3581)
-
ラムダ統計量の標本値が計算される
-
もしλ<u(α)であれば、帰無仮説が受け入れられる
-
もしλ > u(α)であれば、帰無仮説はα有意水準で棄却され、観測されたデータと矛盾することになる
この構造には、もうひとつの論理的な結末も考えられます。u(α)臨界値の代わりに、確率PValue = 1 - K(λ)が計算され、指定されたα有意水準と比較されます。α≧PValueの場合、帰無仮説は棄却されます。なぜなら、ランダム性の概念とは相容れない、ありえない出来事が起こったと考えられ、したがって標本は異なると認識されるべきであるからです。

この図は、帰無仮説が真であるという条件下で計算されたコルモゴロフ分布関数の導関数、つまり確率密度関数を示しています。サンプルデータに対して計算されたスミルノフ距離確率密度関数がコルモゴロフ関数と異なる場合、これはデータの不均一性を示している可能性があります。
2標本コルモゴロフ–スミルノフ検定は、1標本検定と混同してはなりません。前者では2つの経験的分布関数を比較し、後者では経験的分布関数と仮説的分布関数を比較します。
非常に重要な点として、コルモゴロフ分布関数は特定の仮定の下で計算されるため、経験分布関数はグループ化されていない観測データを使用して計算されなければならないということが挙げられます。また、2標本コルモゴロフ–スミルノフ検定が特定の分布関数に依存しないことも強調すべきです。金融時系列の分析において、観測されたデータがある仮説的な分布に属するのか、別の仮説的な分布に属するのかを判断するのが難しいことがあり、そうした場合にこの基準の価値は大いに高まります。この基準を用いることで、観測されたデータがどの仮説分布に属するかを仮定することなく、経験分布関数に基づいて均質性仮説を検証できます。時系列分析において、スミルノフ基準はプロセスの定常性を評価する指標としても利用できます。最終的には、定常性の定義によれば、確率分布関数が時間の経過に伴って変化しない場合、そのプロセスは定常的と見なされます。
簡単な計算方法の説明
ビー玉の入った大きな袋が2つあるとします。一方の袋にはある国で作られたビー玉が、もう一方の袋には別の国で作られたビー玉が入っています。私たちの課題は、両方の袋に入っているビー玉が同じか違うかを見つけることです。
-
ビー玉の並び替え:まず、両方の袋からボールを出し、それぞれを小さい順に並べます。
-
ビー玉の比較:そして、1つ目の袋のビー玉を見て、2つ目の袋の中から同じ大きさのビー玉を探し始めます。似たようなビー玉が2列に並んでいて、どれだけ離れているかを測ります。この文脈で「距離」とは、ビー玉の位置を見たときに、列の中でどれだけ離れているかを意味します。
最初の袋からビー玉が出て、それが列の5番目の位置を占めているとします。2番目の袋から同じ大きさのビー玉が20番目の位置にある場合、この2つのビー玉の間の距離は15個の位置に等しくなります(20 - 5 = 15)。この数字は、2つの異なる袋(または2つのデータサンプル)の中で、似たビー玉がどれだけ離れているかを示しています。
コルモゴロフ–スミルノフ統計検定では、すべてのビー玉についてこのような「距離」を比較し、その最大値を探します。この最大距離がある値(これは袋の中のビー玉の数に依存する)より大きい場合、これは袋の中のビー玉が何らかの性質において異なっていることを示している可能性があります。 -
最大の差異を見つける:ここでは2列のビー玉の差(「距離」)が最大になる場所を探しています。例えば、ある場所ではビー玉の大きさが非常に近く、別の場所では大きく異なる場合、その場所に印をつけます。
-
差異を評価する:ビー玉間の最大の距離が非常に大きい場合、これは袋の中のビー玉が確かに異なっていることを意味するかもしれません。すべてのビー玉が、列の長さ全体にわたってかなり近い位置にある場合、それらは確かに同じ場所のものかもしれません。
したがって、2列のビー玉の差が大きい場合、ビー玉の袋は異なっていると言います。違いが小さければ、ビー玉は同じである可能性が高くなります。これは、2つの異なる場所で採れたビー玉が同じものとみなされるかどうかを理解するのに役立ちます。
2標本コルモゴロフ–スミルノフ検定によるデータ分析
実相場で計算されたDスミルノフ距離の分析に進む前に、まず、この統計量が定常過程のモデルでどのように振る舞うかを、従属増分と独立増分の両方について検証します。この目的のために、与えられた分布関数を持つ時系列のサンプル(Samples)を1000個、各系列のデータ量を1440個生成します。その後、これらの標本間のDスミルノフ距離を計算し、帰無仮説が棄却されるケース(H1/ Samples)の割合をチェックし、またコルモゴロフ密度関数と比較するために、これらの距離の経験的確率密度関数を構築します。下図は、正規分布と一様分布から得られたN=1440のデータサンプルに対するスミルノフ距離系列を示しています。


正規分布と一様分布からの標本において、均質性仮説の誤棄却は、第1種の誤差(α = 0.05)の範囲内、つまり、1000標本中50例以内で発生します。H1/ Samples = 50/1000 = 0.05です。以下に、正規分布と一様分布のスミルノフ距離の標本確率密度のグラフを示します。

X軸はラムダ値を示す
ご覧の通り、一様および正規データ標本に対するスミルノフ距離の標本分布とコルモゴロフ分布は完全に一致しており、同質性の帰無仮説が真であれば、これらは収束するはずです。
先ほど扱った正規分布と一様分布は、定常独立過程の例です。定常的であるが依存的な過程として、決定論的カオスの分野でよく例に挙げられる離散的非線形方程式、ロジスティック写像を取り上げます。
Xn= R*Xn-1 *(1 - Xn-1), X0 = (0;1), R = 4
これは1次元の非線形力学系で、パラメータR=4のとき、ホワイトノイズとほとんど区別がつかないカオス的な振る舞いを示します。この方程式によって生成される時系列の自己相関関数は、ゼロ付近で変動します。しかし、この過程には非線形依存性があり、これがスミルノフ距離の分布にどのような影響を与えるかを確認するのは興味深いことです。金融データには非線形の依存関係が存在すると多くの人が考えているため、この方程式を分析に含めました。

もちろん、この分析には、線形依存関係を持つモデルも必要であり、これは実際のデータにも見られる可能性があります。したがって、定常従属過程の2番目のモデルとして、1次の線形自己回帰モデルを採用します。
ARt = 0.5 * ARt-1 + et
-
et:ゼロ平均、単位分散の確率変数、ガウスホワイトノイズ
この場合の自己回帰過程は、依存関係があるもののガウス過程でもあります。
スミルノフ距離")
従属増分のあるプロセスでは、均質性仮説の棄却の状況は少し異なります。ロジスティック写像では、第1種の誤差の許容値である0.058 (H1/Samples= 58/1000) をわずかに超過していますが、第1次自己回帰モデルでは、この誤差がすでに約0.25 (H1/Samples= 250/1000) となっており、帰無仮説のもとでの許容水準よりも5倍も大きくなります。
非常に興味深い結果が得られました。2標本コルモゴロフ–スミルノフ検定によれば、ロジスティック写像もAR(1)も非一様(非定常)過程と認識されることがわかりました。しかし、もちろん実際にはそうではありません。なぜそのようなことが起こるのでしょうか。観測データが統計的に独立である場合に限り、定常分布に対するスミルノフ距離の確率密度関数は、研究対象のプロセスの分布の種類に依存しないことが判明しました。ロジスティック写像も自己回帰も従属増分による過程なので、この場合、スミルノフ距離の確率密度はコルモゴロフ分布とは異なります。このことは、2標本コルモゴロフ–スミルノフ検定が、異質性(プロセスの非定常性)の指標であるだけでなく、データ依存性(線形または非線形)の存在の指標にもなることを意味します。
実際のデータの分析に移りましょう。例として、EURUSD通貨ペアとXAUUSD(金)の分足バーを取ってみました。


分足の場合、帰無仮説の乖離率はXAUUSDでH1/Samples=466/1000=0.46、EURUSDでH1/Samples=640/1000=0.64と定常過程と有意に異なります。わかりやすくするために、以下は実データと自動回帰とロジスティック写像の従属過程に対するスミルノフ距離の標本確率密度関数のグラフです。

見てわかるように、定常従属過程と実際のEURUSD_M1およびXAUUSD_M1の相場では、質的に異なる図式が観察されます。これらの過程におけるスミルノフ距離の標本確率密度は、コルモゴロフ分布とは大きく異なります。ロジスティック写像と一次自己回帰過程は、これらのデータに統計的依存性が存在するため、コルモゴロフ分布に収束しません。
金融商品の価格については、第一差分を用いて定常型に戻そうとしても、依然として非定常型のままです。このような帰無仮説の大きな乖離には、定常従属過程の分析で見たように、実際の相場において存在する可能性のある従属性が影響している可能性が高いです。私見では、データの依存性による影響と、金融商品の時系列に存在する非定常成分による影響の度合いを評価することは難しいですが、主な影響はデータの異質性と、価格増分の確率分布関数が常に変化していることに関連していると考えられます。
2つの異質な標本に対するスミルノフ距離の確率密度がどのような形をとりうるかを明確にするために、別の実験を行い、異なる一般集団に属する2つの正規分布から得られた標本のデータを比較します。たとえば、N(0,1)とN(0.1,1.2)のように、これらの分布は数学的期待値と分散が異なります。2標本コルモゴロフ–スミルノフ検定は、一般に同質性の帰無仮説を棄却するはずですが、ここでの間違いは、対立仮説が真であるにもかかわらず帰無仮説を受け入れてしまうことです。
 vs N(0.1,1.2)スミルノフ距離")
この場合、帰無仮説の棄却率は0.98(H1/ Samples = 980/1000)となります。下のグラフは、実際の相場に対するスミルノフ距離分布、2つの非一様正規分布のモデル、コルモゴロフ分布の確率密度関数を示しています。
 vs N(0.1,1.2)")
予想通り、2つの正規標本の不均一性のモデルケースでは、スミルノフ距離の確率密度関数は、均質なデータが収束すべきコルモゴロフ分布とは大きく異なります。2標本コルモゴロフ–スミルノフ検定が、分布パラメータの比較的小さな変化に対してもいかに敏感であるかに注意してください。
iSmirnovDistance指標
iSmirnovDistance指標は、上記の分析とは異なり、他の取引セッションとデータが重複することなく、隣接する2つの取引日それぞれに含まれるデータ量のみに基づいて計算を実行します。指標自体は日足で実行され、すべての計算は同じ商品の5分足データでおこなわれます。為替相場の場合、これは1日あたり287データポイントに相当します。計算のために十分な相場データがない日(私は270データを限界とした)には、指標値はゼロに設定されます。
したがって、各取引日の開始時に、2日前の取引日の値に基づいて計算されたスミルノフ統計量の値を受け取ります。この指標で最適化できるパラメータは、実際にはアルファ有意水準のみです。このバージョンでは、標準値を0.05としました。指標ウィンドウの青い点線は、有意水準α=0.05、つまり帰無仮説に対するスミルノフ距離u(α)を示しています。これは、上記の式λ=D*sqrt(n/2)を使用して計算されています。コルモゴロフ分布のλの臨界値を1.3581(コルモゴロフ分布関数の表に基づく)とし、5分間のデータ量を287とすると、対応する距離D = λ / sqrt(n/2) = 1.3581/sqrt(287/2) = 0.1133となります。この値を実際の計算値で上回ると、データ分布の構造が質的に変化していることを示します。青い点線以下の指標値は均質とみなすことができます。

スミルノフ距離が計算される時間枠も重要であることは言うまでもありません。これまで見てきたように、分足データでは系列に有意な非定常性が見られますが、5分足データでは系列がより定常的であり、同質性仮説が棄却される頻度ははるかに低いです。これは、M1が1440件であるのに対し、M5は287件とデータ量が少ないことも一因です。データが287から1440へと徐々に増加するにつれて、帰無仮説の棄却率は増加します。しかし、M1チャートでは同質性仮説が棄却されることが多いです。
結論
本稿では、証券取引所の時系列分析に関するいくつかの重要な疑問に答えることを目的としました。
-
最初の疑問は、対数価格増分の時系列が定常的とみなせるかどうかです。私の意見では、数値計算によって確認された説得力のある答えが得られました。結論としては、少なくとも1分間の時間枠では定常性は達成できません。5分足に関しては、1分足と比較してより定常的に見えるものの、依然として非定常的な動きを示しています。
-
この研究が答えようとしている2番目の質問は、最初の質問の論理的な続きです。つまり、特定の指標を計算するために必要なデータ量はどのくらいかということです。私見では、iSmirnovDistance指標は次のような解釈を提供します。計算のためには、均質性の帰無仮説の2つの偏差間に該当するデータ量を取る必要があります。帰無仮説が棄却されるまで、分析すべきデータ量は徐々に増加します。帰無仮説が棄却されると、以前のデータは古いものとして破棄され、新たにデータ量の計算がやり直されます。したがって、分析するデータ量は固定値ではなく、非定常ランダム過程の性質に基づき、時間の経過とともに常に変化する値です。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14813

 エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索