Cosa inserire nell'ingresso della rete neurale? Le vostre idee... - pagina 37
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Immagino che questo sia il risultato senza filtri, ad esempio in base al tempo?
Hmm... Io, ovviamente, non ho testato con i filtri Ma il punto è che gli scambi sono a medio termine o intraday.
L'influenza del filtro temporale non sembra essere forte. Ma, in ogni caso, è possibile, naturalmente.
Hmm... Non ho testato con i filtri, ma il punto è che gli scambi sono a medio termine o intraday.
L'influenza del filtro temporale non sembra essere forte. Ma, in ogni caso, è possibile, naturalmente.
Un fenomeno interessante:
Se si utilizza la stessa architettura (qualsiasi architettura), su EURUSD, quando si utilizza Softmax, l'ottimizzazione fornisce sempre top set in cui BUY non viene utilizzato affatto. Tutto si limita a SELL e HOLD.
Guardo il grafico per 12 anni - è in discesa. In altre parole, l'ottimizzatore MT5 regola i pesi a livello macro per adattarli al lungo termine.
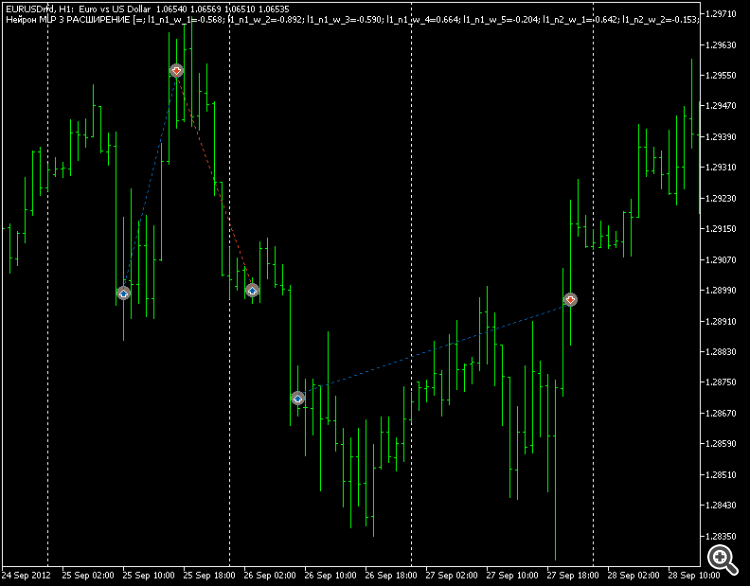
Di conseguenza, le aree di tendenza al rialzo BUY-eval rimangono "non negoziate" correttamente, ma se si utilizza una tangente regolare come uscita, non ci sono problemi.
I top set vengono scambiati sia in acquisto che in vendita. Perciò ho abbandonato questo softmax, ora mi sto dedicando alle architetture e agli ingressi solo con la tangente. UPD Un'altra cosa: gli scambi sono sia al rialzo che al ribasso.
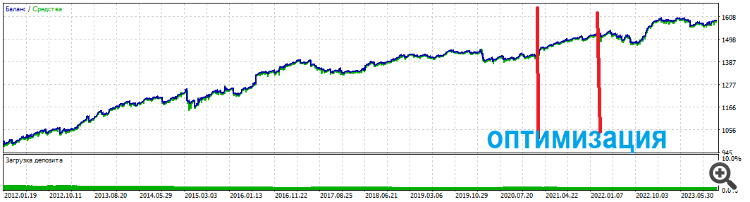
E i top set tengono per molto tempo
Fenomeno interessante:
...
E i top set durano a lungo
Architettura MLP? Immagino che i pesi siano ottimizzati dall'ottimizzatore interno? Qual è il criterio di ottimizzazione, se non un segreto? E se la stessa maglia, ma con qualche algo backprope, a parità di altre condizioni?
Architettura MLP? Se ho capito bene, i pesi sono ottimizzati dall'ottimizzatore interno? Qual è il criterio di ottimizzazione, se non è segreto? E se si utilizza la stessa griglia ma con un algoritmo di backprope a parità di altre condizioni?
E i set superiori durano a lungo
E se oltre a questo si allena di nuovo il secondo modello?
Cosa succede se si sovrallena il secondo modello?
Come sarebbe? Prendere due set dall'elenco di ottimizzazione (non correlati), combinarli ed eseguirli? Oppure c'è qualcos'altro in mente
Troppe parole intelligenti
Gli esperti del ramo MO sostengono che: 1. Non si può cercare un estremo globale su una funzione di fitness.
2. Gli algoritmi di ottimizzazione a ricerca globale (il GA standard è uno di questi) non sono adatti alle reti neurali, per le quali è necessario utilizzare ogni sorta di gradient backprops.
In breve, a quanto pare, state sbagliando tutto (secondo le idee degli esperti del ramo MO).
Gli esperti del ramo MO sostengono che: 1. Non si può cercare un estremo globale della funzione di fitness.
2. Gli algoritmi di ottimizzazione a ricerca globale (tra cui il GA standard) non sono adatti alle reti neurali, per le quali si dovrebbero usare tutti i tipi di gradient backprops.
In breve, a quanto pare, state sbagliando tutto (secondo le idee degli esperti del ramo MO).
Quindi vincerò questa battaglia
Allora vincerò questa battaglia