Que mettre à l'entrée du réseau neuronal ? Vos idées... - page 53
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Quelques résumés :
- Le réseau neuronal n'est applicable qu'aux modèles stationnaires et statiques qui n'ont rien à voir avec la tarification.
Mon point de vue, tel que je le voisPour les séries stationnaires, tout fonctionne et il n'y a pas besoin de MO du tout.
Eh bien, tout est de retour là où le fil MO a commencé en 2016 - les séries non stationnaires ne contiennent pas de caractéristiques statistiques stables.
Je me souviens que lorsque j'ai écrit cela, Dmitrievsky courait autour du fil de discussion, piaffant et exigeant qu'on lui montre cela dans les manuels....
Sur les rangs fixes, tout fonctionne et vous n'avez pas besoin de MO du tout.
Eh bien, nous en sommes revenus au point de départ de la discussion sur la MO en 2016 : les séries non stationnaires ne contiennent pas de caractéristiques statistiques stables et, par conséquent, toutes les NS ne sont que des suppositions.
Je me souviens que lorsque j'ai écrit cela, Dmitrievsky courait autour du fil de discussion, piaffant et exigeant qu'on lui montre cela dans les manuels....
Les tentatives d'adapter les poids à l'histoire sont vouées à l'échec. Formation, optimisation. Peu importe.
Toute intervention telle que l'ajustement direct est une voie qui ne mène nulle part. Et il semble que la bonne direction soit l'ajustement....
La base : lorsque les données d'entrée prennent la forme de 0 à 1 ou de -1 à 1, nous disposons d'une certaine plage de valeurs possibles pour les nombres, qui est limitée de haut en bas.
La limite inférieure est le nombre de déc imales. Nous ne pouvons pas nous limiter et laisser les nombres réels tels qu'ils sont, et la limitation ne sera que technique - c'est le nombre maximum de décimales selon les terminaux MT4/MT5. Ou nous pouvons la limiter manuellement, par exemple parNormalizeDouble ou par des fonctions d'arrondi.
Nous aurons alors une fourchette encore plus étroite. Par conséquent, nous pouvons simplement rechercher toutes les valeurs dans l'optimiseur, attribuer l'une des trois valeurs à chaque chiffre : position ouverte, position fermée, saut, attente, etc. Cette méthode permet une optimisation absolue ou un recyclage absolu, ou tend vers ceux-ci.
En d'autres termes, à l'instar d'un tableau d'apprentissage Q, nous enregistrons également le résultat de chaque modèle et choisissons ensuite ce qu'il convient de faire en fonction des évaluations "passées". Le résultat de cette approche est une rupture de l'équilibre, une plongée vers le bas sur l'avant, et ainsi de suite.
L'ajout artificiel de bruit par la réduction de l'architecture (réduction du nombre de neurones, de couches, etc.) ou d'autres méthodes n'est rien d'autre qu'une béquille. Une sorte de demi-mesure. Et en regardant le résultat de l'optimiseur suivant sur le graphique, où un MLP normal était le sujet testé, je me suis gratté la tête et je n'arrivais pas à comprendre : pourquoi ?
Dans la science de l'apprentissage automatique, il existe une définition et un terme pour ce phénomène (lorsqu'une fuite expressive se produit en avant après une suroptimisation absolue ou un surentraînement). Mais ce n'est pas de cela que nous parlons aujourd'hui.
Quand une putain de MLP ouvre une position, une position bloquée, tardive, trop servie, elle rate par inadvertance .... les zones d'aplomb du graphique. C'est-à-dire que la position perdante moyenne chevauche à 50/50 la partie du graphique où la prune aurait pu se trouver si elle avait été ouverte dans l'autre sens. Une bonne prune.
Et le modèle recyclé est sûr d'ouvrir à cet endroit. Autrement dit, le MLP ne se contente pas d'établir une moyenne des poids pour toutes les situations sur le graphique, il lisse essentiellement tous les cas de force majeure, ce qui le rend plus convaincant sur le front. D'où la conclusion : l'optimisation devrait être effectuée de manière à ce qu'il y ait à la fois un calcul de moyenne et un recyclage.
De l'extérieur, il semble que je dise des choses évidentes, mais j'ai, par exemple, maintenant un MLP sous une forme pervertie, et il donne de meilleurs résultats que le MLP habituel, mais il a un module maison de surentraînement partiel absolu.
UPD
En option.
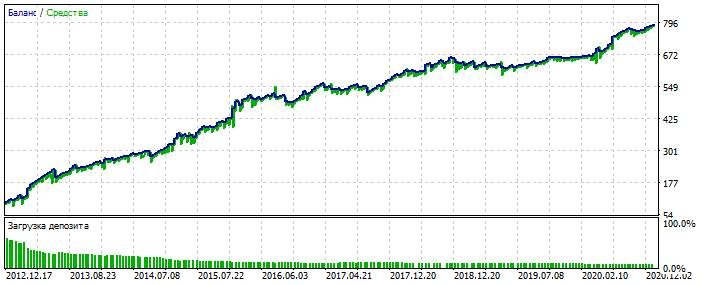
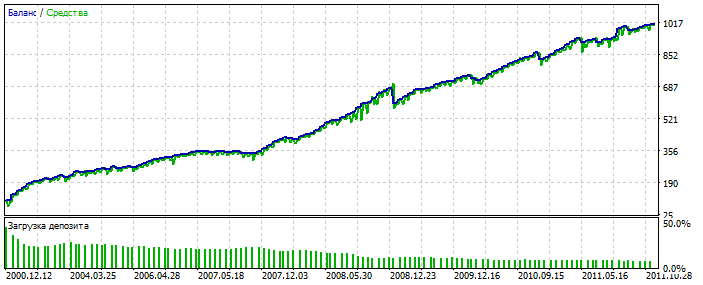
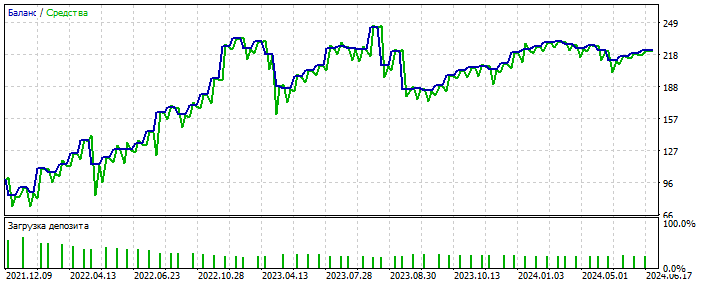
Sur-optimisation sur le graphique de l'EURUSD 2012-2021. Vous pouvez voir que le graphique d'équilibre est trop poli, sans asymétrie sévère. Un signe de sur-optimisation.
Pour MLP, c'est avec 3 neurones. Bektest 2000-2012 Pour une raison quelconque, c'est plus joli que l'optimisation.
Il a probablement détecté une anomalie. Forward 2021-2025 Les transactions sont peu nombreuses, mais il ne s'agit pas ici de polir le système. L'essentiel est important. Et vous pouvez combler le manque de transactions en ajoutant 28 paires de devises supplémentaires et le nombre des premières sera multiplié par 20. Encore une fois, ce n'est pas l'essentiel.
Le plus important, c'est qu'un tel système n'a pas besoin de données d'entrée qualitatives.
Il fonctionne avec presque tout : incréments, oscillateurs, zigzags, modèles, prix, etc. Je continue à avancer dans cette direction.
Et leplus important, c'est qu'un tel système n'a pas besoin de données d'entrée de haute qualité.
Il fonctionne avec presque tout : incréments, oscillateurs, zigzags, motifs, prix, etc. Je m'oriente dans cette direction pour l'instant.
Vous entraînez-vous en sélectionnant les poids du réseau dans MT5-optimiser ?
Oui. Occasionnellement, j'ai recours à un véritable apprentissage via la rétropropagation des erreurs.
Oui. De temps en temps, j'ai recours à un véritable apprentissage par la rétro-propagation des erreurs.
Quelle est la relation entre l'optimiseur de mt5 et la rétropropagation de error ?????
Cool Contourner les limitations de MT5, c'est comme optimiser une paire de couches de 10 neurones - un optimiseur MT5 normal se plaindra de la limitation à 64 bits.
Les conclusions que vous méritez :)
Parmi d'autres, je voudrais seulement souligner que moins il y a de transactions (observations), plus il est facile de faire du curwafitting (ajustement à l'historique) en incluant de nouvelles données. C'est une caractéristique du curwafitting basé sur les statistiques, et non sur la progression. 🫠