Econométrie : bibliographie
Les références suivantes sont disponibles sur le sujet des "Principes de base de l'analyse de régression".
Davidson,Russell et James G. MacKinnon (1993). Estimation and Inference inEconometrics, Oxford : Oxford University Press.
Greene, William H. (2008). Econometric Analysis, 6th Edition, Upper Saddle River, NJ : Prentice-Hall.
Johnston, Jack et John Enrico DiNardo (1997). Econometric Methods, 4e édition, New York : McGraw-Hill.
Pindyck, Robert S. et Daniel L. Rubinfeld (1998). Econometric Models and Economic Forecasts, 4e édition, New York : McGraw-Hill.
Wooldridge, Jeffrey M. (2000). Introductory Econometrics : A Modern Approach. Cincinnati, OH : South-Western College Publishing.
Laissez-moi vous donner un exemple de régression, qui n'est rien d'autre qu'une fonction (variable dépendante) qui dépend de ses arguments (variables indépendantes, régresseurs). Il y a plusieurs étapes à suivre pour calculer une régression :
1. Il faut écrire une équation.
Je prends la très populaire MA, mais pondérée, donc indulgente pour moi, en la calculant à partir des 5 barres précédentes (valeurs de décalage). J'écris la formule dans le formulaire :
EURUSD = C(1)*EURUSD(-1) + C(2)*EURUSD(-2) + C(3)*EURUSD(-3) + C(4)*EURUSD(-4) + C(5)*EURUSD(-5)
2. estimer
Il est nécessaire d'estimer le coefficient c(i) de cette équation afin que la courbe de notre MA corresponde le mieux possible à la série initiale EURUSD_H1-year. On obtient le résultat de l'évaluation des coefficients inconnus.
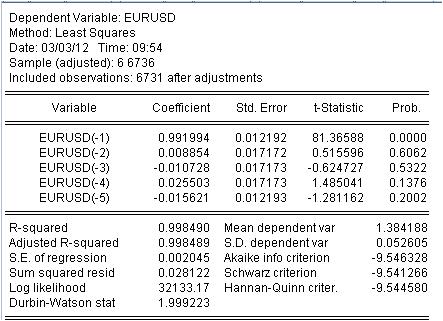
Nous avons obtenu les valeurs de notre MA pondérée. Nous avons l'équation :
EURUSD = 0,991993934254*EURUSD(-1) + 0,00885362355538*EURUSD(-2) - 0,0107282369642*EURUSD(-3) + 0,0255027160774*EURUSD(-4) - 0,0156205779585*EURUSD(-5)
3. Résultats.
Quels résultats voyons-nous ?
3.1 Tout d'abord, l'équation de Mach elle-même. Je veux prêter attention à une petite nuance. Lorsque nous calculons un masque simple en calculant la moyenne, nous ne l'enregistrons pas au milieu de l'intervalle mais à sa fin pour une raison quelconque. La régression est utilisée pour calculer la dernière valeur sur la base des précédentes.
3.2 Il s'avère que les ratios ne sont pas des constantes, mais des variables aléatoires avec leur propre déviation.
3.3 La dernière colonne indique qu'il existe une probabilité non nulle que les coefficients donnés soient nuls.
4. Travailler avec l'équation
Jetons un coup d'œil à notre mélange pondéré.

Le mashka a tellement recouvert le cotier qu'on ne peut pas le voir, mais il y a encore des divergences entre le cotier et le mashka. Voici les statistiques de ces divergences

Nous voyons une énorme dispersion de -137 points à 215 points. Écart-type moyen = 20 points.
Conclusion.
Nous avons reçu une qualité inhabituellement élevée du masque avec les caractéristiques statistiques connues en utilisant la régression.
Le dernier. Yusuf ! Ne vous mettez pas sous le tramway, ne faites pas rire le public sur un fil de plus.
Prêt à discuter de la littérature et de l'application du sujet de la régression.
3. Résultats.
Quels résultats voyons-nous ?
3.1 Tout d'abord, l'équation de Mach elle-même. Je tiens à souligner une subtilité ici. Lorsque nous calculons un masque simple en obtenant la moyenne, pour une raison quelconque, nous ne plaçons pas cette moyenne au milieu de l'intervalle, mais à son extrémité. La régression est utilisée pour calculer la dernière valeur sur la base des précédentes.
3.2 Il s'avère que les ratios ne sont pas des constantes, mais des variables aléatoires !
3.3 La dernière colonne indique qu'il existe une probabilité non nulle que les coefficients donnés soient nuls.
1. désolé pour le sel supplémentaire dans la plaie - la série originale est de toute façon non stationnaire.
2) Cette probabilité est presque toujours non nulle.
3. avez-vous vérifié la multicollinéarité ? IMHO, si vous éliminez la multicollinéarité, il ne reste qu'une seule variable. Avez-vous déterminé les facteurs significatifs ?
4. Combien d'observations avez-vous pour 5 variables ?
Comment êtes-vous si instruit ?
1. désolé pour le sel supplémentaire dans la plaie - la série originale est de toute façon non stationnaire.
Bien sûr, les autres ne nous intéressent pas.
2) Cette probabilité est presque toujours non nulle.
C'est faux. Si elle est différente de zéro, il s'agit d'une erreur de forme fonctionnelle.
3. avez-vous vérifié la multicollinéarité ? IMHO, si vous éliminez la multicollinéarité, il ne reste qu'une seule variable. Avez-vous identifié les facteurs significatifs ?
Je ne comprends pas ce que sont des "facteurs significatifs", mais regardez les coefficients de corrélation.
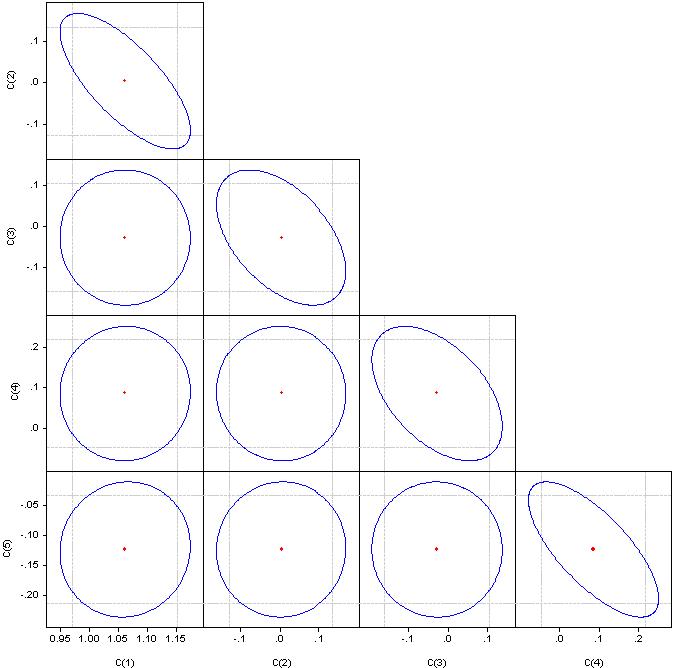
Si c'est un cercle, la corrélation est nulle. Si on les fusionne en une ligne droite, la corrélation entre la paire de coefficients correspondante est de 100%.
4. Combien d'observations avez-vous pour 5 variables ?
6736 observations
La première étape de tout modèle de régression est la sélection des facteurs. Si vous n'appliquez pas la régression par étapes (avec inclusions ou exceptions), vous devez les sélectionner manuellement.
Multicollinéarité - dépendance étroite entre les variables du facteur incluses dans le modèle. Pas la corrélation des coefficients, mais la corrélation des facteurs.
La présence de la multicollinéarité entraîne :
- déformation de la valeur de les paramètres du modèle, qui ont tendance à surestimer;
- conditionnement faible du système d'équations normales ;
- complication de le processus de détermination des caractéristiques dufacteur le plus significatif .
Un indicateur de multicollinéarité est que les coefficients de corrélation par paire dépassent la valeur de 0,8. Ici, les facteurs ont clairement une forte corrélation. Pour l'éliminer, nous devons supprimer les facteurs redondants. Soit manuellement, soit par régression par étapes.
Regardez dans le paquet - régression par étapes ou régression ridge.
Et 6736/4, c'est trop d'observations. Nous devons aller sur Google - je ne me souviens pas comment déterminer le nombre optimal d'observations en fonction du nombre de facteurs.
Ayez l'amabilité de participer à mes discussions sur l'économétrie.
Continuons avec la sélection de la littérature.
Le sujet suivant est les décalages d'Almon.
Comme indiqué plus haut, les coefficients de régression calculés par la méthode des moindres carrés posent des difficultés. Une idée a émergé pour imposer des contraintes supplémentaires sur les coefficients de régression dans lesquels la variable dépendante est déterminée par plusieurs retards de la variable indépendante comme dans l'équation ci-dessus.
L'idée est d'imposer des contraintes sur les coefficients aux valeurs de retard de sorte qu'ils obéissent à une certaine distribution polynomiale. EViews appelle cette approche "polynômes à décalage distribué (PDL)". Le choix du degré particulier du polynôme est déterminé expérimentalement.
Cette approche est décrite ici.
Voici un exemple concret.
Construisons l'analogue d'une échelle avec une période de 5, mais les coefficients de la barre doivent être sur un polynôme d'ordre 3.
Dans EViews, il s'écrit comme suit pour l'EURUSD
EURUSD PDL(EURUSD(-1), 5,3)
Sous une forme plus familière :
EURUSD = + C(5)*EURUSD(-1) + C(6)*EURUSD(-2) + C(7)*EURUSD(-3) + C(8)*EURUSD(-4) + C(9)*EURUSD(-5) + C(10)*EURUSD(-6)
Nous estimons les coefficients par MCO et obtenons le résultat de l'estimation des coefficients :
EURUSD = + 0.934972661616*EURUSD(-1) + 0.139869148138*EURUSD(-2) - 0.093599954464*EURUSD(-3) - 0.0264992987207*EURUSD(-4) + 0.0801064628352*EURUSD(-5) - 0.0348473223286*EURUSD(-6)
Les statistiques sur l'estimation de l'équation sont les suivantes :
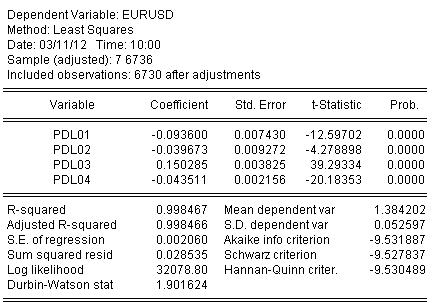
D'après les statistiques, nous pouvons constater un très bon niveau de correspondance du quotient initial par notre ondulation d'Almon R-carré = 0.998467
Graphiquement, ça ressemble à ça :

La régression (l'ondulation d'Almon) a complètement recouvert le quotient d'origine.
Et une dernière cuillère de miel.
Voyons quel est le résidu, c'est-à-dire la différence entre notre moût d'Almon et le cotier original. La stationnarité/non-stationnarité de ce résidu est très importante.

Le test de racine unitaire indique que le résidu est stationnaire.
Les mash-ups que nous utilisons n'ont pas ce niveau d'adéquation avec le quotient original et la propriété de stationnarité de l'erreur d'ajustement.
Je voudrais déplacer les liens d'un fil voisin.
Ces liens concernent le domaine le plus problématique - le pronostic.
Le premier est une pièce jointe. Il y a une liste de références.
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous cherchez le mot "économétrie" sur Google, vous obtiendrez une énorme liste de documents, difficiles à comprendre même pour un expert. Un livre dit une chose, un autre - une autre, le troisième - juste une compilation des deux premiers avec quelques inexactitudes. Mais l'approche "à partir des livres" ne permet pas d'appliquer clairement ces livres dans la pratique. Je ne suis pas intéressé par les intellectuels qui descendent dans l'absurdité ringarde.
À l'instar d'autres listes de livres dans ce forum, par exemple sur les statistiques, je propose que nous compilions collectivement une liste de manuels, de monographies, de thèses, d'articles, de ressources Internet et de progiciels qui, de l'avis des participants, seraient pertinents pour la mesure des données économiques - pour l'économétrie. Toutefois, n'oublions pas que la statistique mathématique est la grande sœur de l'économétrie. Je suggère de ne pas inclure dans cette liste tout ce qui a trait à l'analyse technique.
Pour exclure tout glissement vers la botanique, je propose une approche spécifique de la liste de livres. Nous publions les liens (les livres eux-mêmes) uniquement si je connais un logiciel qui met en œuvre les algorithmes de ces livres. Je me suis limité à EViews. Ce programme n'a pas d'avantage par rapport aux autres, il a des avantages et des inconvénients, mais je le prends comme une référence pour l'économétrie. J'ai joint la table des matières du deuxième volume du manuel de l'utilisateur, afin d'exposer d'emblée le plus large éventail possible de problèmes. En raison de l'approche proposée, plusieurs domaines utilisés en économétrie, mais non inclus dans EVIEWS, par exemple NS, ondelettes, etc. Naturellement, les références à de tels programmes et livres sont également les bienvenues.
Si nous pouvons non seulement fournir un lien vers la source de l'algorithme, mais aussi effectuer des calculs spécifiques, ce fil de discussion n'aura aucune valeur.
Je suggère d'utiliser les numéros de chapitre de la pièce jointe pour regrouper les livres.
Alors, s'il vous plaît, soutenez-nous.