
Recetas de estadística para el trader - Hipótesis

Introducción
Cualquier trader que tenga ganas de crear su propio sistema comercial, tarde o temprano se convierte en un analítico. Intenta encontrar regularidades en el mercado y comprobar tal o cual idea comercial. La simulación de una idea puede basarse en diferentes enfoques, comenzando por la búsqueda común de los mejores valores de parámetros en el modo de optimización del Simulador de estrategias, y terminando por la investigación científica (y a veces pseudocientífica) de los datos de mercado.
En este artículo le propongo ver a fondo un instrumento de análisis estadístico para la investigación y la comprobación de conclusiones, tal como la hipótesis estadística. Probaremos con ejemplos a simular diferentes hipótesis con ayuda del paquete Statistica y la biblioteca portable de análisis numérico ALGLIB MQL5.
1. Hipótesis, concepto
Existen varias determinaciones del concepto de "hipótesis estadística". Alguno de ellos se acercan a la presuposición sobre las propiedades estadísticas del objeto o fenómeno estudiado.
Una hipótesis estadística es un juicio hipotético sobre las normas probables a las que supedita el fenómeno estudiado.
Otros indican que estas propiedades deben estar relacionadas con la distribución de una cierta magnitud aleatoria o los parámetros de esta distribución.
La hipótesis estadística es una presuposición con respecto a los parámetros de la distribución estadística o la ley de distribución de la magnitud aleatoria.
En la literatura especializada en matemática estadística, el concepto de "hipótesis" mayormente se trata según la segunda variante. Entonces hay:
- Hipótesis paramétrica (hipótesis sobre los valores de los parámetros de distribución o de la magnitud comparativa de los parámetros de dos distribuciones);
- Hipótesis no paramétrica (hipótesis sobre el tipo de distribución de una magnitud aleatoria).
En el siguiente apartado nos familiarizaremos con los procedimientos de comprobación de las hipótesis.
2. Comprobación de hipótesis, teoría
La hipótesis que hay que comprobar, se llama nula (Н0). Para esta se elige una alternativa, la hipótesis alternativa (Н1). Esta constituiría el otro lado de la moneda para Н0, es decir, niega lógicamente la hipótesis nula.
Imagine que se dispone de un conjunto de datos según stop loss de un cierto sistema comercial. Formamos un par de hipótesis que componen la base para la comprobación.
Н0 – valor medio del stop loss igual a 30 puntos;
Н1 – valor medio del stop loss no igual a 30 puntos.
Variantes de aceptación-refutación de una hipótesis:
- Н0 es verdadera, y es aceptada;
- Н0 no es verdadera, y es rechazada en favor de Н1;
- Н0 es verdadera, pero es rechazada en favor de Н1;
- Н0 no es verdadera, pero es aceptada.
Las últimas dos variantes están relacionadas con errores.
Ahora hay que elegir el valor del nivel de significación. Es la probabilidad de que se tome una hipótesis alternativa cuando la verdadera resulte nula (tercera variante). Como es natural, es deseable minimizar esta probabilidad.
En nuestro ejemplo, este error sucederá si consideramos que el stop loss de media no es igual a 30 pp, con la condición de que verdaderamente sea igual a esta cantidad de puntos.
Normalmente, el valor del nivel de significación (α) es igual a 0,05. Es decir, en no más de 5 casos de 100 se permite la entrada del valor del criterio de comprobación de la hipótesis nula en la zona crítica.
En nuestro ejemplo, valoraremos el criterio según el gráfico del libro de texto (fig.1).

Fig. 1. Distribución del criterio según la ley normal
Para que la hipótesis nula sea aceptada, el criterio no debe entrar en las zonas rojas. Para los objetivos del ejemplo, supongamos que el propio criterio está distribuido normalmente.
Para cada test estadístico existe su propia fórmula, según la cual se calcula el criterio.
La variante 4 presupone que tiene lugar un error del segundo tipo (β). En nuestro ejemplo, este error sucederá si consideramos que el stop loss de media es igual a 30 pp, con la condición de que verdaderamente no sea igual a esta cantidad de puntos.
3. Comprobación de hipótesis, ejemplos
Todos los datos de origen usados para los ejemplos, se encuentran en el archivo Data.xls.
3.1. Comprobación de extractos dependientes
Imaginemos la situación siguiente. Supongamos que hay un sistema comercial que genera un cierto conjunto de transacciones comerciales. Componemos un extracto de transacciones con beneficios, con un volumen de 100 unidades. Los datos de origen se encuentran en la hoja "Profits".
La estadística descriptiva del extracto Profits tras la eliminación de deshechos se representa en el recuadro 1:

Recuadro 1. Estadística del extracto Profits
El histograma del extracto tiene el siguiente aspecto (fig.2).

Fig.2. Histograma para el extracto Profits
El valor medio del extracto es igual a 83,4 pp, la mediana, de 83 pp.
¿Y qué pasará si cambiamos un poco el punto de entrada en el mercado, en unos cuantos puntos? Por ejemplo, después de aparecer la señal comercial se puede establecer una orden límite, que mejore el precio de entrada.
¿Cómo cambiarán los resultados? A esta pregunta se puede responder con la ayuda de hipótesis estadísticas.
En el paquete Statistica comprobamos formalmente si no han sido sacados los extractos del conjunto general:
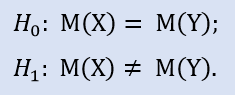
Cambiamos el precio de entrada en 15 puntos, obtenemos el extracto NewProfits. De manera ideal, deberíamos obtener una imagen así (fig.3).

Fig.3. Gráfico para los extractos Profits y NewProfit
Existe una alta probabilidad de que se adopte la hipótesis alternativa, dado que las medianas de los extractos se diferencian.
Pero difícilmente lograremos obtener una imagen así, ya que el mercado puede no dar precios mejores. En mi caso, al cambiar el precio de entrada, en el segundo extracto entraron 84 transacciones. Y las otras 15 transacciones no se realizaron. Lo llamaremos extracto corregido NewProfitsReal.
En un gráfico del tipo "diagrama de caja" no existe prácticamente ninguna diferencia entre extractos..

Fig.4. Fig.4 Gráfico para los extractos Profits y NewProfitsReal
Realizamos un test no paramétrico según el criterio de Wilkokson para extractos relacionados.
Los resultados han sido presentados en el recuadro.2:

Recuadro.2. Resultados del test según el criterio de Wilkokson para los extractos Profits, NewProfitsReal
El nivel de significación es muy elevado, lo que indica que hay que aceptar la hipótesis nula.
De esta forma se puede llegar a la conclusión de que el cambio del punto de entrada no ha influido en la rentabilidad del sistema. Esto en un sentido relativo. En términos absolutos, debido a los puntos de entrada que se han dejado pasar, el sistema ha resultado menos beneficioso.
Resulta interesante que en MQL5 se pueda realizar el test de Wilkokson en forma de programa. Si bien es verdad que compara la mediana de la distribución con el valor establecido m. Pero esta diferencia no es sustancial.
Lo comprobamos formalmente:
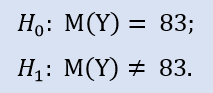
En la biblioteca ALGLIB existe el siguiente procedimiento: CAlglib::WilcoxonSignedRankTest(). Nos da el resultado directamente para 3 tipos de test: bilateral, del lado izquierdo y del lado derecho.
En el script test_profits.mq5 hay un ejemplo del cálculo. En la revista "Expertos" veremos los siguientes resultados para el extracto NewProfitsReal:
OO 0 12:04:08.814 test_profits (EURUSD.e,H1) valor p para el test bilateral: 0.7472 HD 0 12:04:08.814 test_profits (EURUSD.e,H1) valor p para el test del lado izquierdo: 0.6285 CM 0 12:04:08.814 test_profits (EURUSD.e,H1) valor p para el test del lado derecho: 0.3736
El test del lado izquierdo tiene la forma:
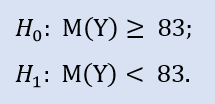
Aqui comprobamos la alternativa en que la mediana del extracto NewProfitsReal puede ser mayor o igual a 83. La probabilida de error en el rechazo de H0 es igual a 0,63. Por eso H0 se acepta.
El test del lado derecho tiene la forma:
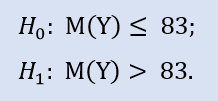
Aqui comprobamos la alternativa en que la mediana del extracto NewProfitsReal puede ser mayor o igual a 83. La probabilida de error en el rechazo de H0 es igual a 0,37. Por eso H0 se acepta.
3.2. Comprobación de extractos independientes
Supongamos que hay que comprobar cómo de rápido se procesan las órdenes comerciales con diferentes brókers, y si hay diferencia entre brókers con respecto al tiempo de ejecución de la orden comercial.
De esta forma, para los objetivos del análisis se han creado 2 extractos de datos de origen. En cada extracto se encontraban al principio 50 observaciones. Tras eliminar los desechos, en el primer extracto (bróker А) quedan 48 observaciones, en el segundo (bróker B), 49 observaciones. Los datos se encuentran en la hoja "ExecutionTime".
Lo comprobamos formalmente:
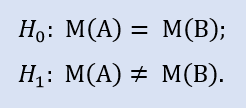
Visualizamos los índices de los extractos (Fig.5). A juzgar por el gráfico, los valores de las medianas, aunque no mucho, se diferencian.

Fig.5. Gráfico para los extractos de datos del bróker A y B
Dado que no sabemos a priori con qué distribución se relaciona cada extracto, entonces recurrimos a los tests no paramétricos para comparar.
Por ejemplo, usamos el criterio U de Mann-Whitney (recuadro 3). Entre los no paramétricos, se considera uno de los más potentes.

Recuadro 3. Resultados de la prueba según el criterio U de Mann-Whitney para los extractos de los datos A y B
La conclusión es la diferencia en los tests, la hipótesis nula sobre la igualdad de los extractos es rechazada a favor de H1.
En MQL5 se puede realizar también en forma de programa el test de Mann-Whitney. En la bliblioteca ALGLIB existe el procedimiento CAlglib:: MannWhitneyUTest(). Nos da el resultado directamente para 3 tipos de test: bilateral, del lado izquierdo y del lado derecho.
En el script test_time_execution.mq5 hay un ejemplo del cálculo. En la revista "Expertos" veremos los siguientes resultados para la comparación de los extractos:
MR 0 12:55:08.577 test_time_execution (EURUSD.e,H1) valor p para el test bilateral: 0.0001 QF 0 12:55:08.577 test_time_execution (EURUSD.e,H1) valor p para el test del lado izquierdo: 1.0000 PF 0 12:55:08.577 test_time_execution (EURUSD.e,H1) valor p para el test del lado derecho: 0.0001
El test del lado izquierdo tiene la forma:
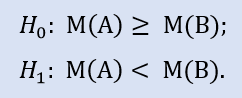
Hipótesis nula - la mediana del extracto de los datos del bróker A puede ser mayor o igual a la mediana del extracto de los datos del bróker B. La alternativa es su negación. La probabilida de error en el rechazo de H0 es igual a 1,0. Por eso H0 se acepta.
El test del lado derecho tiene la forma:
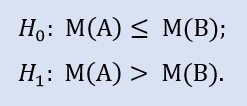
Hipótesis nula - la mediana del extracto de los datos del bróker A puede ser menor o igual a la mediana del extracto de los datos del bróker B. La alternativa es su negación.
La probabilida de error en el rechazo de H0 es igual a 0,0. Por eso H0 es rechazada en favor de Н1.
3.3. Comprobación de la correlación
Imagine que disponemos de una cierta cartera de estrategias. La tarea consiste en acortar el número de estas estrategias en la cartera.
El criterio de solución puede ser el siguiente: si al comparar las series de stop loss de dos estrategias resultan iguales, entonces quitamos una estrategia de la cartera. Para la investigación tomaremos dos extractos que representen los datos de stop loss de dos sistemas comerciales diferentes. Supuesto: los sistemas reaccionan igualmente a la entrada en el mercado, pero reaccionan de manera diferente a la salida del mismo.
Utilizaremos la prueba de correlación de rango de Spearman. En el archivo de datos, hoja "Correlation", tenemos 3 extractos.
Comparamos formalmente si el valor del coeficiente de correlación es igual a cero.
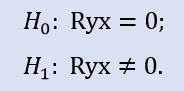
Si comparamos la pareja de extractos Stops1-Stops2, entonces obtenemos los resultados siguientes (recuadro 4).

Recuadro 4 Resultados de la prueba de correlación de rango de Spearman para los extractos Stops1, Stops2
Aquí es imposible rechazar la hipótesis nula sobre la ausencia de relación entre los elementos de los extractos en favor de la alternativa. Eso significa que se acepta.
En el gráfico (fig.6) se puede percibir que los datos no forman ninguna configuración notable. Estos se encuentran más bien dispersos por todo el plano del gráfico.

Fig.6. Diagrama de dispersión para los extractos Stops1, Stops2
Los resultados de la comprobación de la relación entre los extractos Stops1-Stops3 se muestran en el recuadro 5:

Recuadro 5 Resultados de la prueba de correlación de rango de Spearman para los extractos Stops1, Stops3
Aquí se puede rechazar la hipótesis nula, la probabilidad de error es demasiado baja.
Eso significa que se acepta la alternativa sobre la existencia de relación. De manera visual, la dependencia tiene el aspecto siguiente (fig.7).

Fig.7. Diagrama de dispersión para los extractos Stops1, Stops3
Confirmamos los resultados mendiante código en MQL5. En el script test_correlation.mq5.hay un ejemplo del cálculo.
En la propia biblioteca ALGLIB se dispone del procedimiento CAlglib::SpearmanRankCorrelationSignificance(), que implementa el test de significación del coeficiente de correlación de rango de Spearman
En el registro aparecerán las siguientes anotaciones:
OO 0 12:57:43.545 test_correlation (EURUSD.e,H1) ---===Extractos Stops1 y Stops2===--- GO 0 12:57:43.545 test_correlation (EURUSD.e,H1) valor p para el test bilateral: 0.9840 KK 0 12:57:43.545 test_correlation (EURUSD.e,H1) valor p para el test del lado izquierdo: 0.4920 JJ 0 12:57:43.545 test_correlation (EURUSD.e,H1) valor p para el test del lado derecho: 0.5080 DM 0 12:57:43.545 test_correlation (EURUSD.e,H1) HJ 0 12:57:43.545 test_correlation (EURUSD.e,H1) ---===Extractos Stops1 y Stops3===--- NS 0 12:57:43.545 test_correlation (EURUSD.e,H1) valor p para el test bilateral: 0.0002 RO 0 12:57:43.545 test_correlation (EURUSD.e,H1) valor p para el test del lado izquierdo: 0.9999 FG 0 12:57:43.545 test_correlation (EURUSD.e,H1) valor p para el test del lado derecho: 0.0001
El test del lado izquierdo tiene la forma:
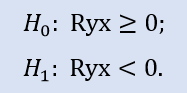
Aquí se comprueba la hipótesis nula sobre el hecho de que entre variables haya una correlación no negativa (es decir, o bien una correlación nula, o bien positiva).
Para la pareja de extractos Stops1-Stops2 el test del lado izquierdo ha mostrado que la hipótesis nula se acepta. Para la pareja de extractos Stops1-Stops3 el test del lado izquierdo ha mostrado que la hipótesis nula también se acepta. ¿Por qué es así, si entre los extractos Stops1-Stops2 no hay relación, y entre los extractos Stops1-Stops3 si la hay? El motivo es que se comprueba la afirmación "mayor o igual a cero". En el primer caso, en el lado H0 juega "igual a cero", y en el segundo, "mayor".
El test del lado derecho tiene la forma:
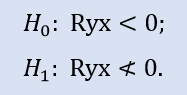
Aquí se comprueba la hipótesis nula sobre si hay correlación negativa.
Para la pareja de extractos Stops1-Stops2 el test del lado derecho ha mostrado que la hipótesis nula se acepta. Para la pareja de extractos Stops1-Stops3 el test del lado derecho ha mostrado que la hipótesis nula se rechaza.
Y una observación más. En el transcurso del test se desveló que entre los extractos Stops1-Stops3 existe una relación probable positiva. Pero la fuerza de esta relación posee probablemente un carácter medio. Por eso la decisión de renunciar a la estrategia 1 o 3 en la cartera queda a la discreción del trader.
Conclusión
En este artículo he intentado mostrar con ejemplos que es posible razonar y sacar conclusiones con los parámetros cuantitativos, usando el aparato de la matemática estadística. Espero que el material del artículo sea útil para los desarrolladores principiantes en sus sistemas comerciales futuros, y lo más importante, conscientes. Asimismo, espero que la serie de artículos sobre la utilización de métodos de matemática estadística encuentre continuación.
Los archivos de la biblioteca ALGLIB deben ser descargados por separado.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/1240
 Principios de formación de precios en el mercado bursátil tomando de ejemplo la Sección de Derivados de la Bolsa de Moscú
Principios de formación de precios en el mercado bursátil tomando de ejemplo la Sección de Derivados de la Bolsa de Moscú
 Gráfico líquido
Gráfico líquido
 Trabajo con el SGBD MySQL desde MQL5 (MQL4)
Trabajo con el SGBD MySQL desde MQL5 (MQL4)
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso