
在任何市场中获得优势(第三部分):Visa消费指数

概述
在大数据时代,现代投资者几乎可以获取无限的备选数据来源。每个数据集都有潜力在预测市场回报时提供更高的准确度。然而,很少有数据集能够兑现这一承诺。在本系列的文章中,我们将帮助您探索广阔的替代数据领域,以协助您决定是否应在分析中包含这些数据集。另一方面,如果这些数据集的结果不尽如人意,那么我们可能会帮助您节省时间。
我们的理由是,通过考虑在MetaTrader 5终端中无法直接获得的备选数据集,我们可能会发现一些变量,与仅依赖市场报价的普通市场参与者相比,这些变量能够相对更准确地预测价格水平。
交易策略概述
VISA是一家美国跨国支付服务公司。它成立于1958年,如今该公司运营着世界上最大的交易处理网络之一。VISA非常适合成为可靠的备选数据来源,因为它们几乎渗透了发达世界的每一个市场。此外,圣路易斯联邦储备银行也从VISA收集部分宏观经济数据。
在本次讨论中,我们将分析VISA消费动力指数(SMI)。该指数是消费者支出行为的宏观经济指标。这些数据由VISA使用其专有网络和VISA借记卡及信用卡品牌进行汇总。所有数据都经过匿名处理,主要收集于美国境内。随着VISA继续从不同市场汇总数据,这一指数最终可能会成为全球消费者行为的基准。
我们使用圣路易斯联邦储备银行提供的API服务来检索VISA SMI数据集。圣路易斯联邦储备经济数据库(FRED)API使我们能够访问来自世界各地的数十万种不同的经济时间序列数据。
方法论概述
VISA每月发布SMI数据,截至撰写本文时,该数据包含不到200行。因此,我们需要一种既能抵抗过拟合又足够灵活以捕捉复杂关系的建模技术。这可能是神经网络的理想任务。
我们优化了一个深度神经网络的5个参数,以便根据一组常规的开盘价、最高价、最低价和收盘价以及3个附加输入(即VISA数据集)对EURUSD的变化进行分类。我们的优化模型在验证中达到了71%的准确率,远远超过了默认模型。然而,值得注意的是,这一准确率是基于月度数据而得出的!
我们运用了随机搜索算法的1000次迭代来优化深度神经网络,并成功地训练了模型,使其没有对训练数据产生过拟合。尽管这些结果听起来令人印象深刻,但我们不能自信地断言所观察到的关系是可靠的。我们的特征选择算法在以非参数方式选择最重要的特征时,舍弃了所有3个VISA数据集。此外,所有3个VISA数据集的互信息得分都相对较低,这可能表明这些数据集可能是独立的,或者我们未能以有意义的方式为模型揭示这种关系。
数据提取
为了获取我们需要的数据,您必须首先在FRED网站上创建一个账户。创建账户后,您可以使用您的FRED API密钥访问圣路易斯联邦储备银行持有的经济时间序列数据,并跟随我们的讨论。我们的EURUSD报价市场数据将直接通过MetaTrader 5 Python API从终端获取。
准备开始,请首先加载我们需要的库。
#Import the libraries we need import pandas as pd import seaborn as sns import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
现在设置您的FRED API密钥并获取我们需要的数据。
#Let's setup our FredAPI
fred = Fred(api_key="ENTER YOUR API KEY")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
定义预测范围。
#Define how far ahead we want to forecast look_ahead = 10
可视化数据
让我们可视化所有三个数据集。
visa_discretionary.plot(title="VISA Spending Momentum Index: Discretionary") 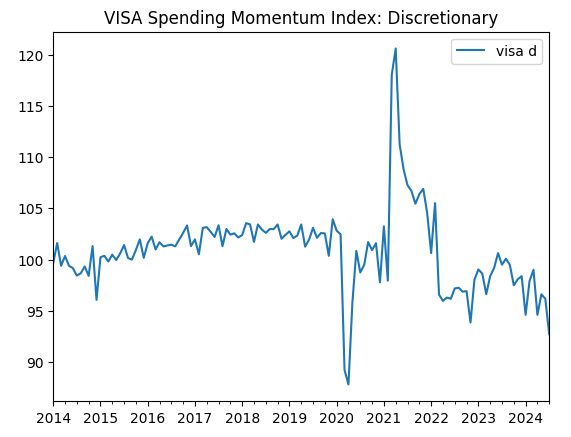
图1:第一个VISA数据集
现在让我们可视化第二个数据集。
visa_headline.plot(title="VISA Spending Momentum Index: Headline") 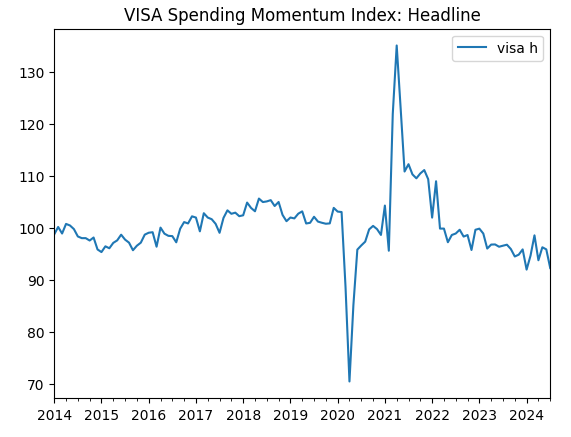
图2:第二个VISA数据集
最后,我们的第三个VISA数据集。
visa_non_discretionary.plot(title="VISA Spending Momentum Index: Non-Discretionary") 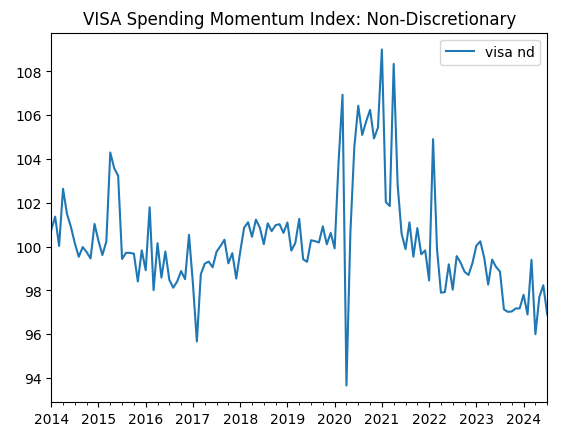
图3:第三个VISA数据集
前两个数据集看起来几乎一模一样,而且正如我们稍后在讨论中将看到的,它们的相关性水平为0.89,这意味着它们可能包含相同的信息。这表明我们可以舍弃其中一个,而保留另一个。然而,我们将让特征选择算法来决定是否有这个必要。
从我们的MetaTrader 5终端获取数据
我们现在将终端初始化。
#Initialize the terminal
mt5.initialize()
我们现在将指定时区。
#Set timezone to UTC timezone = pytz.timezone("Etc/UTC")
创建一个日期时间对象。
#Create a 'datetime' object in UTC utc_from = datetime(2024,7,1,tzinfo=timezone)
从MetaTrader 5获取数据并将其封装在一个pandas数据结构中。
#Fetch the data eurusd = pd.DataFrame(mt5.copy_rates_from("EURUSD",mt5.TIMEFRAME_MN1,utc_from,visa_headline.shape[0]))
让我们对数据做标识,并使用时间戳作为索引。
#Label the data eurusd["target"] = np.nan eurusd.loc[eurusd["close"] > eurusd["close"].shift(-look_ahead),"target"] = 0 eurusd.loc[eurusd["close"] < eurusd["close"].shift(-look_ahead),"target"] = 1 eurusd.dropna(inplace=True) eurusd.set_index("time",inplace=True)
现在我们将使用它们共有的日期来合并数据集。
#Let's merge the datasets merged_data = eurusd.merge(visa_headline,right_index=True,left_index=True) merged_data = merged_data.merge(visa_discretionary,right_index=True,left_index=True) merged_data = merged_data.merge(visa_non_discretionary,right_index=True,left_index=True)
探索性数据分析
我们已准备好探索数据。散点图有助于可视化两个变量之间的关系。让我们观察由每个VISA数据集与收盘价对比生成的散点图。蓝色点汇总了接下来10根K线图中价格下跌的情况,而橙色点则汇总了价格上涨的情况。
尽管在图表的中心部分,这种区分仍有些模糊,但在极限水平下,VISA数据集能够相当好地区分上涨和下跌的趋势。
#Let's create scatter plots sns.scatterplot(data=merged_data,y="close",x="visa h",hue="target").set(title="EURUSD Close Against VISA Momentum Index: Headline")
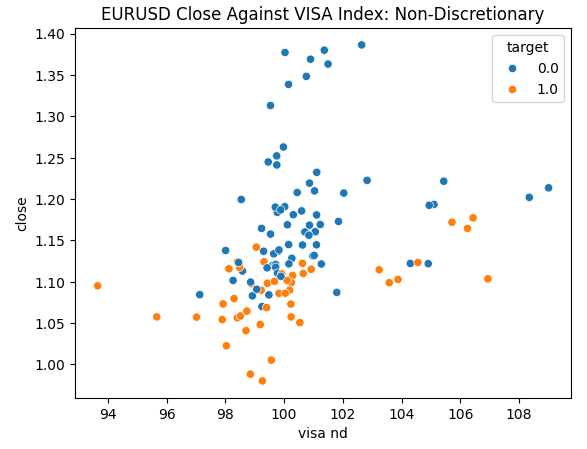
图4:我们的非自主决定型VISA数据集与EURUSD收盘价对比图
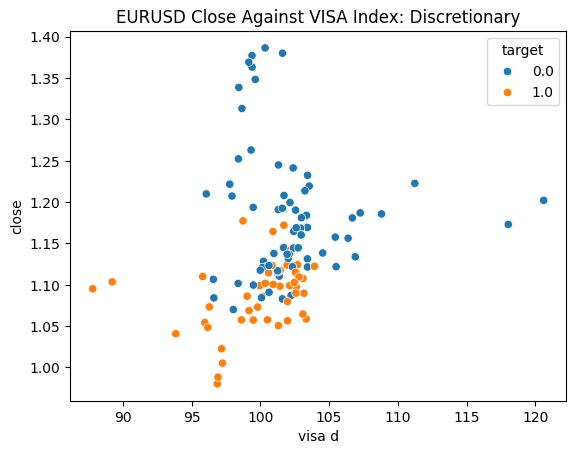
图5:我们的自主决定型VISA数据集与EURUSD收盘价对比图
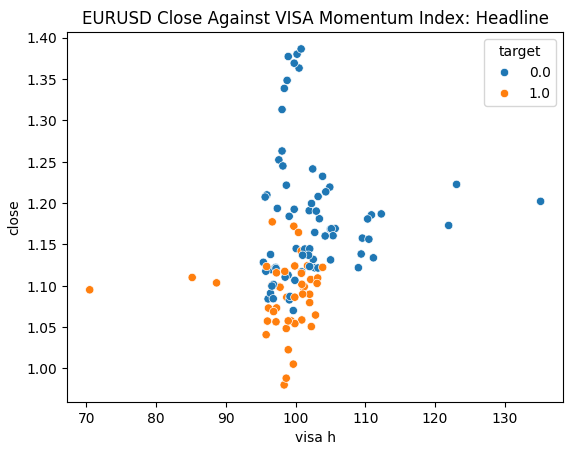
图6:我们的头条VISA数据集与EURUSD收盘价对比图
VISA数据集与EURUSD市场之间的相关性水平适中且均为正值。这些相关性水平对我们而言没有特别吸引人之处。然而,值得注意的是,正值表明这两个变量往往同时上升和下降。这与我们对宏观经济的理解是一致的,即美国的消费者支出在一定程度上会影响汇率。如果消费者集体选择不消费,那么他们的行为将减少流通中的货币总量,这可能会导致美元升值。
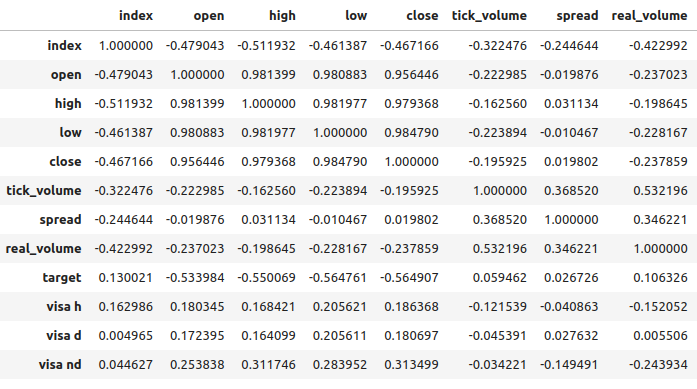
图7:我们的数据集的相关性分析
特征选择
我们的目标与新特征之间的关系有多重要?让我们观察特征选择算法是否会消除这些新特征。如果我们的算法没有选择任何新变量,那么这可能表明这种关系并不可靠。
前向选择算法从一个空模型开始,然后一次添加一个特征。之后,它选择最佳的单变量模型,然后开始搜索第二个变量,以此类推。它会将构建的最佳模型返回给我们。在我们的研究中,算法仅选择了开盘价,这表明这种关系可能并不稳定。
导入我们需要的库。
#Let's see which features are the most important from mlxtend.feature_selection import SequentialFeatureSelector as SFS from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
创建前向选择对象。
#Create the forward selection object sfs = SFS( MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"]), k_features=(1,train_X.shape[1]), forward=False, scoring="accuracy", cv=5 ).fit(train_X,train_y)
让我们绘制结果图。
fig1 = plot_sfs(sfs.get_metric_dict(),kind="std_dev") plt.title("Neural Network Backward Feature Selection") plt.grid()
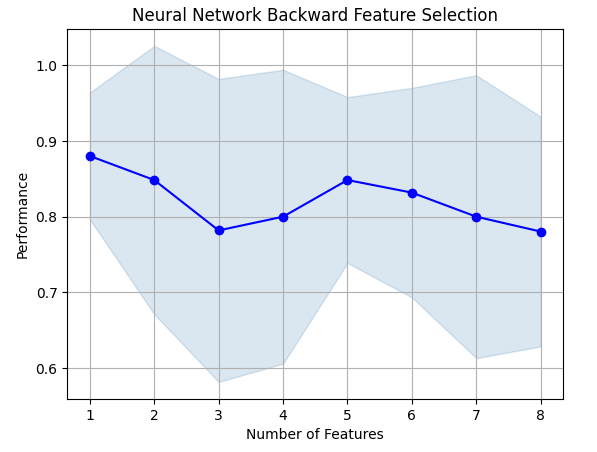
图8:随着我们在模型中特征数量的增加,性能反而下降。
遗憾的是,随着我们增加更多的特征,准确性一直在下降。这可能意味着要么这种关联性本身就不强,或者我们没有以模型能够解释的方式来展现出这种关联性。因此,看起来只具有一个特征的模型能够完成这项任务。
我们确定的最佳特征。
sfs.k_feature_names_
现在让我们观察我们的互信息(MI)分数。MI告诉我们每个变量预测目标的潜力有多大。MI分数是正值,理论上范围从0到无穷大,但在实践中,我们很少观察到MI分数超过2,而MI分数大于1已经比较优秀。
从scikit-learn中导入MI分类器。
#Mutual information
from sklearn.feature_selection import mutual_info_classif 头条数据集的MI分数。
#Mutual information from the headline visa dataset, print(f"VISA Headline dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa h']],train_y)[0]}")
自由支配数据集(Discretionary dataset)的MI分数。
#Mutual information from the second visa dataset, print(f"VISA Discretionary dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa d']],train_y)[0]}")
我们所有数据集的MI分数都很低,这可能是对VISA数据集尝试应用不同转换的一个充分理由。希望这样我们能发现更强的关联性。
参数调整
现在,让我们尝试调整我们的深度神经网络以预测EURUSD汇率。在此之前,我们需要对数据进行缩放。首先,重置合并数据集的索引。
#Reset the index
merged_data.reset_index(inplace=True)
定义目标变量和预测变量。
#Define the target target = "target" ohlc_predictors = ["open","high","low","close","tick_volume"] visa_predictors = ["visa d","visa h","visa nd"] all_predictors = ohlc_predictors + visa_predictors
现在我们将对数据进行缩放和转换。对于数据集中的每个值,我们将减去其所在列的均值,并除以该列的标准差。值得注意的是,这种转换对异常值很敏感。
#Let's scale the data scale_factors = pd.DataFrame(index=["mean","standard deviation"],columns=all_predictors) for i in np.arange(0,len(all_predictors)): #Store the mean and standard deviation for each column scale_factors.iloc[0,i] = merged_data.loc[:,all_predictors[i]].mean() scale_factors.iloc[1,i] = merged_data.loc[:,all_predictors[i]].std() merged_data.loc[:,all_predictors[i]] = ((merged_data.loc[:,all_predictors[i]] - scale_factors.iloc[0,i]) / scale_factors.iloc[1,i]) scale_factors
查看缩放后的数据。
#Let's see the normalized data merged_data
导入标准库。
#Lets try to train a deep neural network to uncover relationships in the data from sklearn.neural_network import MLPClassifier from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
创建训练-测试集划分。
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"],test_size=0.5,shuffle=False)
根据可用的输入调整模型。请记住,我们首先需要传入我们想要调整的模型,然后指定我们感兴趣的模型参数。之后,我们需要指明我们打算使用多少次折叠来进行交叉验证。
tuner = RandomizedSearchCV(MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="accuracy", return_train_score=False )
安装调优器。
tuner.fit(train_X,train_y)
让我们看看训练数据上获得的结果,按从好到差的顺序排列。
tuner_results = pd.DataFrame(tuner.cv_results_) params = ["param_activation","param_solver","param_alpha","param_learning_rate","param_learning_rate_init","mean_test_score"] tuner_results.loc[:,params].sort_values(by="mean_test_score",ascending=False)

图9:我们的优化结果
在训练数据上,我们的最高准确率达到了88%。请注意,由于我们选择的优化算法具有随机性,因此可能难以重现本演示中获得的结果。
过拟合测试
现在,让我们比较一下我们的默认模型和自定义模型,看看是否存在过拟合训练数据的情况。如果存在过拟合,默认模型在验证集上的表现将优于我们的自定义模型,否则,我们的自定义模型将表现更好。
让我们准备这两个模型。
#Let's compare the default model and our customized model on the hold out set default_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
测量默认模型的准确率。
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
accuracy_score(test_y,default_model.predict(test_X))
我们自定义模型的准确率。
#The accuracy of the defualt model
customized_model.fit(train_X,train_y)
accuracy_score(test_y,customized_model.predict(test_X))
看起来我们训练模型时没有出现过拟合训练数据的情况。同时也要注意,通常我们的训练误差总是高于测试误差,但两者之间的差异不应该太大。我们的训练误差是88%,测试误差是74%,这是合理的。训练和测试误差之间存在较大差距是令人担忧的,这可能表明我们出现了过拟合!
实施该策略
首先,我们定义将使用的全局变量。
#Let us now start building our trading strategy SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_MN1 DEVIATION = 1000 VOLUME = 0 LOT_MULTIPLE = 1
现在让我们初始化MetaTrader 5交易平台。
#Get the system up
if not mt5.initialize():
print('Failed To Log in')
现在我们需要了解有关市场的更多详情。
#Let's fetch the trading volume
for index,symbol in enumerate(mt5.symbols_get()):
if symbol.name == SYMBOL:
print(f"{symbol.name} has minimum volume: {symbol.volume_min}")
VOLUME = symbol.volume_min * LOT_MULTIPLE
该函数将为我们获取当前的市场价格。
#A function to get current prices def get_prices(): start = datetime(2024,1,1) end = datetime.now() data = pd.DataFrame(mt5.copy_rates_range(SYMBOL,TIMEFRAME,start,end)) data['time'] = pd.to_datetime(data['time'],unit='s') data.set_index('time',inplace=True) return(data.iloc[-1,:])
我们也创建了一个函数,用于从FRED API获取最新的备选数据。
#A function to get our alternative data def get_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] return(visa_d,visa_h,visa_n)
我们需要一个函数来负责对输入的数据进行归一化和缩放。
#A function to prepare the inputs for our model def get_model_inputs(): LAST_OHLC = get_prices() visa_d , visa_h , visa_n = get_alternative_data() return( np.array([[ ((LAST_OHLC['open'] - scale_factors.iloc[0,0]) / scale_factors.iloc[1,0]), ((LAST_OHLC['high'] - scale_factors.iloc[0,1]) / scale_factors.iloc[1,1]), ((LAST_OHLC['low'] - scale_factors.iloc[0,2]) / scale_factors.iloc[1,2]), ((LAST_OHLC['close'] - scale_factors.iloc[0,3]) / scale_factors.iloc[1,3]), ((LAST_OHLC['tick_volume'] - scale_factors.iloc[0,4]) / scale_factors.iloc[1,4]), ((visa_d - scale_factors.iloc[0,5]) / scale_factors.iloc[1,5]), ((visa_h - scale_factors.iloc[0,6]) / scale_factors.iloc[1,6]), ((visa_n - scale_factors.iloc[0,7]) / scale_factors.iloc[1,7]) ]]) )
让我们用全部数据来训练我们的模型。
#Let's train our model on all the data we have model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation="logistic",solver="lbfgs",alpha=0.00001,learning_rate="constant",learning_rate_init=0.00001) model.fit(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"])
该函数将从我们的模型中获取预测结果。
#A function to get a prediction from our model def ai_forecast(): model_inputs = get_model_inputs() prediction = model.predict(model_inputs) return(prediction[0])
现在到了算法的核心部分。首先,我们将检查开仓的数量。然后,我们将从模型中获取预测结果。如果我们没有开仓,那么将使用模型的预测来开仓。反之,如果已有开仓,我们将使用模型的预测作为平仓信号。
while True: #Get data on the current state of our terminal and our portfolio positions = mt5.positions_total() forecast = ai_forecast() BUY_STATE , SELL_STATE = False , False #Interpret the model's forecast if(forecast == 0.0): SELL_STATE = True BUY_STATE = False elif(forecast == 1.0): SELL_STATE = False BUY_STATE = True print(f"Our forecast is {forecast}") #If we have no open positions let's open them if(positions == 0): print(f"We have {positions} open trade(s)") if(SELL_STATE): print("Opening a sell position") mt5.Sell(SYMBOL,VOLUME) elif(BUY_STATE): print("Opening a buy position") mt5.Buy(SYMBOL,VOLUME) #If we have open positions let's manage them if(positions > 0): print(f"We have {positions} open trade(s)") for pos in mt5.positions_get(): if(pos.type == 1): if(BUY_STATE): print("Closing all sell positions") mt5.Close(SYMBOL) if(pos.type == 0): if(SELL_STATE): print("Closing all buy positions") mt5.Close(SYMBOL) #If we have finished all checks then we can wait for one day before checking our positions again time.sleep(24 * 60 * 60)
我们有 0 个开仓
开立一个卖出仓位
在MQL5中的实现
为了在MQL5中实现我们的策略,我们首先需要将模型导出为Open Neural Network Exchange(ONNX)格式。ONNX是一种将机器学习模型表示为图和边组合的协议。这种标准化的协议使得开发者能够轻松地使用不同的编程语言构建和部署机器学习模型。然而,遗憾的是,当前的ONNX API并不完全支持所有的机器学习模型和框架。
首先,我们将导入一些库。
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
然后我们需要输入我们的FRED API密钥,以获取所需的数据。
#Let's setup our FredAPI
fred = Fred(api_key="")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
请注意,在获取数据后,我们使用上面概述过的相同方式进行了数据缩放。为避免重复相同的信息,我们省略了这些步骤。唯一的细微的差别是,我们现在训练模型来预测实际的收盘价,而不仅仅是二进制目标。
在对数据进行缩放后,现在让我们尝试调整模型的参数。
#A few more libraries we need from sklearn.neural_network import MLPRegressor from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error
我们需要将数据划分为两部分:一部分作为训练集,用于优化模型;另一部分作为验证集,用于检测模型是否过拟合。
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"close target"],test_size=0.5,shuffle=False)
现在我们将进行超参数调优,请注意,我们将评分指标设置为“负均方误差”(neg mean squared error),该评分指标会识别出产生最低均方误差(MSE)的模型,将其作为表现最佳的模型。
tuner = RandomizedSearchCV(MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,early_stopping=True), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="neg_mean_squared_error", return_train_score=False, n_jobs=-1 )
拟合调优器对象。
tuner.fit(train_X,train_y)
现在让我们测试是否存在过拟合。
#Let's compare the default model and our customized model on the hold out set default_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
我们默认模型的准确度。
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
我们在保留的验证集上超过了默认模型,这是一个好迹象,表明没有出现过拟合。
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
0.006138795093781729
在将自定义模型导出为ONNX格式之前,让我们先使用全部数据对其进行拟合。
#Fit the model on all the data we have
customized_model.fit(test_X,test_y)
导入ONNX转换库。
#Convert to ONNX
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx import convert_sklearn
import netron
import onnx 定义我们模型的输入类型和形状。
#Define the initial types initial_types = [("float_input",FloatTensorType([1,train_X.shape[1]]))]
在内存中创建模型的ONNX表示。
#Create the onnx representation onnx_model = convert_sklearn(customized_model,initial_types=initial_types,target_opset=12)
将ONNX表示存储于硬盘上。
#Save the ONNX model onnx_model_name = "EURUSD VISA MN1 FLOAT.onnx" onnx.save(onnx_model,onnx_model_name)
在Netron中查看ONNX模型。
#View the ONNX model
netron.start(onnx_model_name) 
图10:以ONNX表示的深度神经网络

图11:我们ONNX模型的元数据细节
我们差不多准备好开始构建我们的EA。然而,我们首先需要创建一个后台Python服务,该服务将从FRED获取数据并将其传递给我们的程序。
首先,我们导入所需的库。
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred from datetime import datetime
然后我们使用FRED凭证登录。
#Let's setup our FredAPI fred = Fred(api_key="")
我们需要定义一个函数,该函数用于获取数据并将数据写入CSV文件中。
#A function to write out our alternative data to CSV def write_out_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] data = pd.DataFrame(np.array([visa_d,visa_h,visa_n]),columns=["Data"],index=["Discretionary","Headline","Non-Discretionary"]) data.to_csv("C:\\Users\\Westwood\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\fred_visa.csv")
我们现在需要编写一个循环,该循环将每天检查一次新数据并更新CSV文件。
while True: #Update the fred data for our MT5 EA write_out_alternative_data() #If we have finished all checks then we can wait for one day before checking for new data time.sleep(24 * 60 * 60)一旦我们能够访问最新的FRED数据,就可以开始构建我们的EA。
我们首先将ONNX模型作为资源加载到应用程序中。 //+------------------------------------------------------------------+ //| VISA EA.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Resorces | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD VISA MN1 FLOAT.onnx" as const uchar onnx_buffer[];
然后我们将加载交易库,以帮助开仓和管理仓位。
//+------------------------------------------------------------------+ //| Libraries we need | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
到目前为止,我们的应用程序进展顺利,让我们创建一些全局变量,在应用程序的不同模块中使用它们。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; double mean_values[8],std_values[8]; float visa_data[3]; vector model_forecast = vector::Zeros(1); double trading_volume = 0.3; int state = 0;
在我们开始使用ONNX模型之前,我们需要首先从程序开始时所需的资源中创建ONNX模型。之后,我们需要定义模型的输入和输出形状。
//+------------------------------------------------------------------+ //| Load the ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- Try create the ONNX model from the buffer we have onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the model if(onnx_model == INVALID_HANDLE) { Comment("Failed to create the ONNX model. ",GetLastError()); return(false); } //--- Set the I/O shape ulong input_shape[] = {1,8}; ulong output_shape[] = {1,1}; //--- Validate the I/O shapes if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape. ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape. ",GetLastError()); return(false); } return(true); }
回想一下,我们通过减去列均值并除以每列的标准差来标准化我们的数据。我们需要将这些值存储于内存中。由于这些值永远不会改变,我简单地将它们硬编码到程序中。
//+------------------------------------------------------------------+ //| Mean & Standard deviation values | //+------------------------------------------------------------------+ void load_scaling_values(void) { //--- Mean & standard deviation values for the EURUSD OHLCV mean_values[0] = 1.146552; std_values[0] = 0.08293; mean_values[1] = 1.165568; std_values[1] = 0.079657; mean_values[2] = 1.125744; std_values[2] = 0.083896; mean_values[3] = 1.143834; std_values[3] = 0.080655; mean_values[4] = 1883520.051282; std_values[4] = 826680.767222; //--- Mean & standard deviation values for the VISA datasets mean_values[5] = 101.271017; std_values[5] = 3.981438; mean_values[6] = 100.848506; std_values[6] = 6.565229; mean_values[7] = 100.477269; std_values[7] = 2.367663; }
我们创建的Python后台服务将始终提供最新的可用数据,让我们创建一个函数来读取该CSV文件并将值存储于一个数组中。
//+-------------------------------------------------------------------+ //| Read in the VISA data | //+-------------------------------------------------------------------+ void read_visa_data(void) { //--- Read in the file string file_name = "fred_visa.csv"; //--- Try open the file int result = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,","); //Strings of ANSI type (one byte symbols). //--- Check the result if(result != INVALID_HANDLE) { Print("Opened the file"); //--- Store the values of the file int counter = 0; string value = ""; while(!FileIsEnding(result) && !IsStopped()) //read the entire csv file to the end { if(counter > 10) //if you aim to read 10 values set a break point after 10 elements have been read break; //stop the reading progress value = FileReadString(result); Print("Trying to read string: ",value); if(counter == 3) { Print("Discretionary data: ",value); visa_data[0] = (float) value; } if(counter == 5) { Print("Headline data: ",value); visa_data[1] = (float) value; } if(counter == 7) { Print("Non-Discretionary data: ",value); visa_data[2] = (float) value; } if(FileIsLineEnding(result)) { Print("row++"); } counter++; } //--- Show the VISA data Print("VISA DATA: "); ArrayPrint(visa_data); //---Close the file FileClose(result); } }
最后,我们必须定义一个负责从模型中获取预测结果的函数。首先,我们将当前输入存储到一个浮点向量中,因为我们模型的输入类型是浮点数,这正如我们在创建ONNX初始类型时所定义的。
回想一下,在将输入传递给模型之前,我们必须通过减去列均值并除以列标准差来缩放每个输入值。
//+--------------------------------------------------------------+ //| Get a prediction from our model | //+--------------------------------------------------------------+ void model_predict(void) { //--- Fetch input data read_visa_data(); vectorf input_data = {(float)iOpen("EURUSD",PERIOD_MN1,0), (float)iHigh("EURUSD",PERIOD_MN1,0), (float)iLow("EURUSD",PERIOD_MN1,0), (float)iClose("EURUSD",PERIOD_MN1,0), (float)iTickVolume("EURUSD",PERIOD_MN1,0), (float)visa_data[0], (float)visa_data[1], (float)visa_data[2] }; //--- Scale the data for(int i =0; i < 8;i++) { input_data[i] = (float)((input_data[i] - mean_values[i])/std_values[i]); } //--- Show the input data Print("Input data: ",input_data); //--- Obtain a forecast OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT|ONNX_DEFAULT,input_data,model_forecast); } //+------------------------------------------------------------------+
现在让我们定义初始化程序。我们首先将加载ONNX模型,然后读取VISA数据集,最后,我们将加载缩放值。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX file if(!load_onnx_model()) { //--- We failed to load the ONNX model return(INIT_FAILED); } //--- Read the VISA data read_visa_data(); //--- Load scaling values load_scaling_values(); //--- We were successful return(INIT_SUCCEEDED); }
每当程序不再使用时,让我们释放不再需要的资源。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we don't need OnnxRelease(onnx_model); ExpertRemove(); }
每当我们有新的可用价格数据时,我们首先从模型中获取一个预测。如果我们没有开仓,那么将遵循模型生成的入场信号。最后,如果我们已有开仓,将使用AI模型提前检测价格的潜在反转。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Get a prediction from our model model_predict(); Comment("Model forecast: ",model_forecast[0]); //--- Check if we have any positions if(PositionsTotal() == 0) { //--- Note that we have no trades open state = 0; //--- Find an entry and take note if(model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Sell(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,"Gain an Edge VISA"); state = 1; } if(model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Buy(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,"Gain an Edge VISA"); state = 2; } } //--- If we have positions open, check for reversals if(PositionsTotal() > 0) { if(((state == 1) && (model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0))) || ((state == 2) && (model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)))) { Alert("Reversal detected, closing positions now"); Trade.PositionClose(_Symbol); } } } //+------------------------------------------------------------------+

图12:我们VISA的EA

图13:我们程序的示例输出

图14:我们运行中的应用
结论
在本文中,我们展示了如何选择可能对您的交易策略有帮助的数据。我们已经讨论了如何衡量您备选数据中的潜在长处,以及如何优化您的模型,以便您能够尽可能多地提取性能,同时避免过度拟合。有成千上万的数据集可供探索,我们致力于帮助您识别最有信息量的数据集。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/15575