Есть ли закономерность в хаосе? Попробуем поискать! Машинное обучение на примере конкретной выборки.
Собственно, предлагаю скачать файл по ссылке. В архиве 3 файла формата csv:
- train.csv - выборка, на которой нужно обучится.
- test.csv - вспомогательная выборка, допустимо её применять при обучении, в том числе слитно с train.
- exam.csv - выборка, которая никак не участвует в обучении.
Сама выборка содержит 5581 столбцов с предикторами, целевая в 5583 столбце "Target_100", столбцы 5581, 5582, 5584, 5585 являются вспомогательными, и содержат:
- 5581 столбец "Time" - дата сигнала
- 5582 столбец "Target_P" - направление сделки "+1" - покупка / "-1" - продажа
- 5584 столбец "Target_100_Buy" - фин. результат от покупки
- 5585 столбец "Target_100_Sell" - фин. результат от продажи
Цель - создать модель, которая будет "зарабатывать" на выборке exam.csv более 3000 пунктов.
Решение должно быть без подсматривания в exam, т.е. без использования данных этой выборки.
Для поддержки интереса - желательно рассказать о методе, который позволил добиться такого результата.
Выборки можно преобразовывать как угодно, в том числе меняя целевую, но следует пояснить суть преобразования, что б это не было чистой подгонкой под выборку exam.
Обучение, что называется из коробки с помощью CatBoost, с настройками ниже - с перебором Seed дает такое распределение вероятности.
FOR %%a IN (*.) DO ( catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_8\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 8 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 16 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_24\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 24 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 32 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_40\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 40 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 48 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_56\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 56 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 64 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_72\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 72 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 80 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
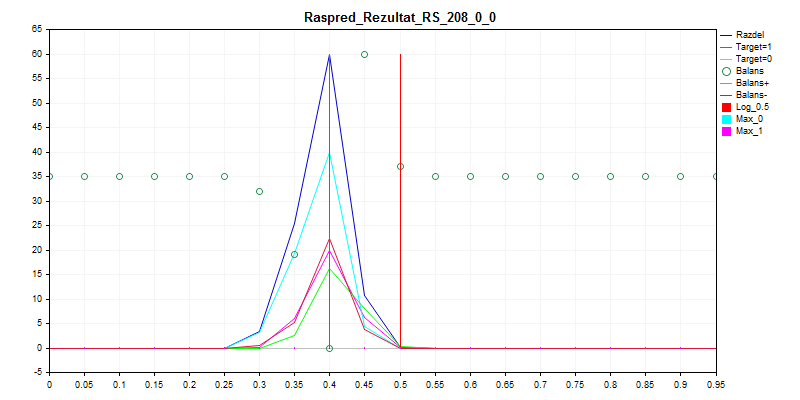
1. Выборка train

2. Выборка test
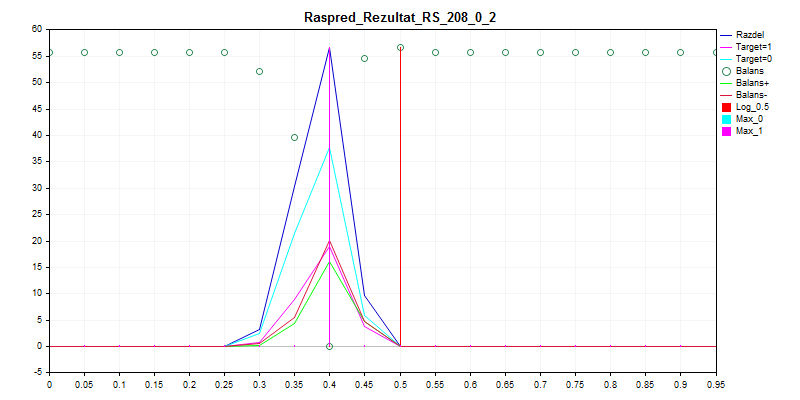
3. Выборка exam
Как видно, модель предпочитает все практически классифицировать нулём - так меньше шансов ошибиться.
Последние 4 столбца
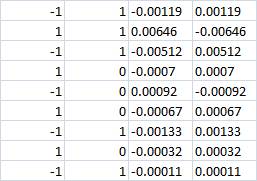
При 0 классе видимо проигрыш должен быть в обоих случаях? Т.е. -0,0007 в обоих случаях. Или если все таки будет сделана ставка buy|sell, то получим прибыль при правильном направлении?
Последние 4 столбца
При 0 классе видимо проигрыш должен быть в обоих случаях? Т.е. -0,0007 в обоих случаях. Или если все таки будет сделана ставка buy|sell, то получим прибыль при правильном направлении?
При нулевом классе - не входим в сделку.
Раньше я использовал 3 целевых - от того два последних столбца с фин результатом, а не один, но с CatBoost'ом пришлось перейти на две целевых.
Направление 1/-1 выбирается другой логикой, т.е. МО в выборе направления не участвует? Нужно просто научиться 0/1 торговать/не торговать (при жестко выбранном направлении)?
Да, модель только принимает решение - входить или нет. Однако, в рамках данного эксперимента не возбраняется учить модель с тремя целевыми, для этого достаточно преобразовать целевую с учетом направления входа.
При нулевом классе - не входим в сделку.
Раньше я использовал 3 целевых - от того два последних столбца с фин результатом, а не один, но с CatBoost'ом пришлось перейти на две целевых.
Да, модель только принимает решение - входить или нет. Однако, в рамках данного эксперимента не возбраняется учить модель с тремя целевыми, для этого достаточно преобразовать целевую с учетом направления входа.
При нулевом классе - не входим в сделку.
Раньше я использовал 3 целевых - от того два последних столбца с фин результатом, а не один, но с CatBoost'ом пришлось перейти на две целевых.
Да, модель только принимает решение - входить или нет. Однако, в рамках данного эксперимента не возбраняется учить модель с тремя целевыми, для этого достаточно преобразовать целевую с учетом направления входа.
В катбусте есть мультикласс, странно, что отказались от 3 классов
Т.е. если при 0 классе(не входить) будет выбрано правильное направление сделки, то будет получена прибыль или нет?
Прибыли не будет (если делать переоценку то будет маленький процент прибыли на нуле).
Переделать целевую корректно можно только разбив "1" на "-1" и "1", иначе это уже другая стратегия.
Есть, но нет интеграции в MQL5.
Там вообще нет выгрузки модели в любой язык.
Наверное, можно прикрутить библиотеку dll, но самостоятельно не разберусь.
Прибыли не будет (если делать переоценку то будет маленький процент прибыли на нуле).
Тогда мало смысла в столбцах фин. результата. Ошибки прогноза 0 класса тоже будут (вместо 0 спрогнозируем 1). А цена ошибки получается, - неизвестна. Т.е. линию баланса построить не выйдет. Тем более, что у вас 70% класса 0. Т.е. 70% ошибок с неизвестным фин. результатом.
О 3000 пунктов можно забыть. Если и будет, то будет недостоверно.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Собственно, предлагаю скачать файл по ссылке. В архиве 3 файла формата csv:
Сама выборка содержит 5581 столбцов с предикторами, целевая в 5583 столбце "Target_100", столбцы 5581, 5582, 5584, 5585 являются вспомогательными, и содержат:
Цель - создать модель, которая будет "зарабатывать" на выборке exam.csv более 3000 пунктов.
Решение должно быть без подсматривания в exam, т.е. без использования данных этой выборки.
Для поддержки интереса - желательно рассказать о методе, который позволил добиться такого результата.
Выборки можно преобразовывать как угодно, в том числе меняя целевую, но следует пояснить суть преобразования, что б это не было чистой подгонкой под выборку exam.